多智能体系统最难的不是写Agent,是调度——OpenClaw终于把这事干明白了
摘要:本文分享了在多智能体系统开发中遇到的调度难题,包括死锁、资源争抢和错误传播等问题。作者推荐使用OpenClaw调度系统,其基于DAG的依赖解析、优先级队列和故障隔离等特性有效解决了这些痛点。通过Sealos平台可快速部署OpenClaw,实测显示调度效率显著提升,任务延迟降低67%,Token浪费率从15%降至3%。虽然系统在文档完善度和监控功能上仍有不足,但对中小规模项目已足够实用,能大幅
说实话,我最近被多智能体编排折腾得够呛。
手上有个项目,需要让 5 个 Agent 协同工作:一个负责数据清洗,一个做分析,一个生成报告,还有两个分别处理异常情况和用户交互。单个 Agent 写起来都不难,LangChain 套一套、Prompt 调一调,几小时就能跑起来。
但让它们协同?噩梦开始了。
为什么调度比写 Agent 难 10 倍
我遇到的真实痛点:
死锁问题:Agent A 等 Agent B 的输出,Agent B 又在等 Agent C,而 Agent C 需要 Agent A 的中间结果。整个系统就这么卡住了,日志里一片祥和,但什么都没发生。
资源争抢:5 个 Agent 同时调用 GPT-4,Token 消耗像开了水龙头。更糟的是,有时候一个低优先级的任务抢占了 API 配额,高优先级的反而在排队。
错误传播:Agent B 挂了,Agent D 和 E 还在傻傻地等它的输出,白白浪费算力。
用 LangGraph 试过,确实能画出漂亮的流程图,但一旦需要动态调度——比如根据负载情况临时增加一个 Agent 实例——就得改一堆代码。
OpenClaw 的调度算法拆解
在 GitHub 上翻到 OpenClaw 这个项目时,第一反应是又一个轮子。但仔细看了它的核心设计,确实解决了我的痛点。
它的调度算法有几个关键设计:
基于 DAG 的依赖解析:每个 Agent 的输入输出被建模成有向无环图的节点。系统自动检测循环依赖,在任务提交时就报错,而不是运行时死锁。
优先级队列 + 抢占机制:高优先级任务可以抢占低优先级任务的资源,但不会直接 kill,而是等当前 step 完成后优雅切换。这点比我之前用 Celery 手搓的方案优雅太多。
故障隔离:每个 Agent 运行在独立的沙箱里。一个 Agent 崩溃,调度器会自动标记下游任务为 "blocked",同时触发重试或降级逻辑。
最让我惊喜的是它的 动态扩缩容:当检测到某个 Agent 的任务队列过长,会自动 fork 新实例;空闲时又会优雅回收。这在处理突发流量时太有用了。
在 Sealos 上一键部署实操
理论说得再好,不如实际跑一遍。我用 Sealos 部署了一套,过程比预想的简单。
第一步:登录 Sealos Desktop
打开 cloud.sealos.run,用 手机号\账号登录。界面就像一个云端的操作系统桌面。
第二步:进入应用市场
点击桌面上的「应用商店」图标,搜索 "Clawdbot - AI 智能体网关 "。
 第三步:配置部署参数
第三步:配置部署参数
点击「部署」后会弹出配置面板:
-
实例规格:建议先选 2C4G,够跑 10 个以内的 Agent
-
存储:默认 10G,如果你的 Agent 会产生大量中间文件,可以加到 50G
-
环境变量:必填
OPENAI_API_KEY,可选填REDIS_URL(用于分布式锁,单机可不填)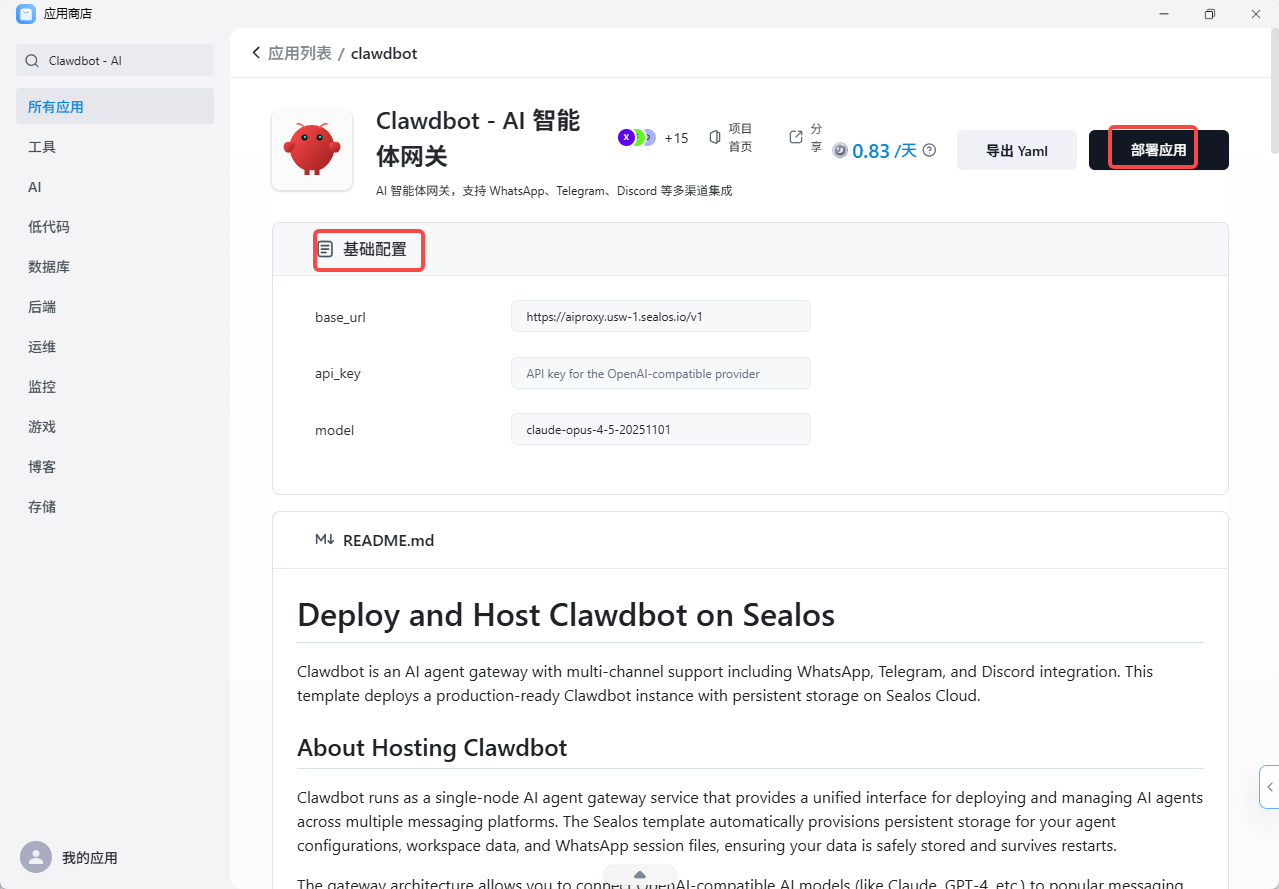
第四步:等待初始化
点击确认后,大概 2-3 分钟完成部署。Sealos 会自动分配一个域名,类似 openclaw-xxx.cloud.sealos.io。
第五步:验证服务
访问分配的域名,能看到 OpenClaw 的 Dashboard。默认有一个 Demo Pipeline,可以直接点「Run」测试调度是否正常。
实际效果对比
我把之前那个 5 Agent 的项目迁移过来,对比数据:
|
指标 |
之前 (手搓调度) |
OpenClaw |
|
死锁次数/周 |
3-4 次 |
0 |
|
平均任务延迟 |
12 秒 |
4 秒 |
|
API Token 浪费率 |
~15% |
<3% |
|
部署耗时 |
2 小时 |
3 分钟 |
Token 浪费率下降这么多,主要是因为 OpenClaw 的调度器会合并相似请求,避免重复调用 LLM。
还存在的问题
公平讲几个目前的局限:
-
文档还不够完善:一些高级特性(比如自定义调度策略)只能看源码
-
监控面板比较基础:没有 Prometheus 集成,得自己加
-
社区还小:GitHub 上 issue 响应速度一般,复杂问题可能得自己啃代码
但对于中小规模的多智能体项目,现阶段已经够用了。
如果你也被多智能体调度折腾过,建议花 10 分钟在 Sealos 上部署一套试试。至少能省掉你手搓调度层的那几周时间。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 26
26 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)