别手动协调Agent了,OpenClaw的事件驱动调度让我少熬了20个夜
本文分享了作者开发多Agent系统的痛苦经历,从传统手动编排的三大痛点(高耦合、难调试、难扩展)到发现OpenClaw解决方案的过程。OpenClaw采用事件驱动+状态机设计,实现低耦合、易扩展的Agent调度,类似Kubernetes对容器的编排革命。文章还介绍了在Sealos平台5分钟快速部署OpenClaw的实操步骤,指出多Agent开发正从"编程式"向"声明式
凌晨三点的崩溃,你经历过吗?
上个月我接了一个需求:做一个能自动调研、写报告、发邮件的多Agent系统。听起来很酷对吧?
第一周,我信心满满地用LangChain串了五个Agent。
第二周,我开始在各种回调地狱里迷失。
第三周,凌晨三点,我盯着屏幕上第N次出现的"Agent A等Agent B,但B在等C,C又在等A"的死锁日志,认真考虑转行。
直到我在GitHub上发现了OpenClaw——这个被很多人忽略的多智能体编排项目,彻底改变了我的开发方式。
为什么传统的Agent编排让人抓狂
先说说痛点。大多数人编排多Agent的方式,本质上是"手动挡":
Agent完成 → 判断结果 → 决定下一个 → 手动调用 → 循环往复
这种模式有三个致命问题:
-
耦合度爆炸:每加一个Agent,要改N处调用逻辑
-
调试像破案:出问题时,根本不知道是哪个环节卡住的
-
扩展等于重写:想加个并行?祝你好运
OpenClaw的思路完全不同。
OpenClaw的核心设计:事件驱动 + 状态机
翻了它的源码,我发现OpenClaw的调度算法其实借鉴了工业界成熟的事件驱动架构:
每个Agent不再"主动调用"其他Agent,而是"发布事件"和"订阅事件"。
举个例子:
-
调研Agent完成工作 → 发布"调研完成"事件
-
写作Agent订阅了这个事件 → 自动被唤醒开始工作
-
如果调研失败 → 发布"调研失败"事件 → 错误处理Agent接管
这种设计的好处太明显了:
|
对比维度 |
传统方式 |
OpenClaw事件驱动 |
|
加新Agent |
改调用链 |
只订阅相关事件 |
|
并行执行 |
手动管理线程 |
自动识别无依赖任务 |
|
故障恢复 |
从头开始 |
从断点继续 |
|
调试难度 |
地狱级 |
看事件日志即可 |
它的状态机设计也很精妙。每个Agent任务都有明确的状态(pending/running/completed/failed),调度器根据状态和事件自动决策下一步——这让"少熬20个夜"不是夸张。
在Sealos上部署OpenClaw(五分钟搞定)
说实话,我最开始是在本地跑OpenClaw的,配置Redis、配置消息队列,折腾了半天。后来发现Sealos上可以一键部署,省了至少80%的运维时间。
第一步:进入Sealos应用商店
登录 Sealos Cloud,在应用商店搜索"Clawdbot - AI 智能体网关 "。
 第二步:配置参数
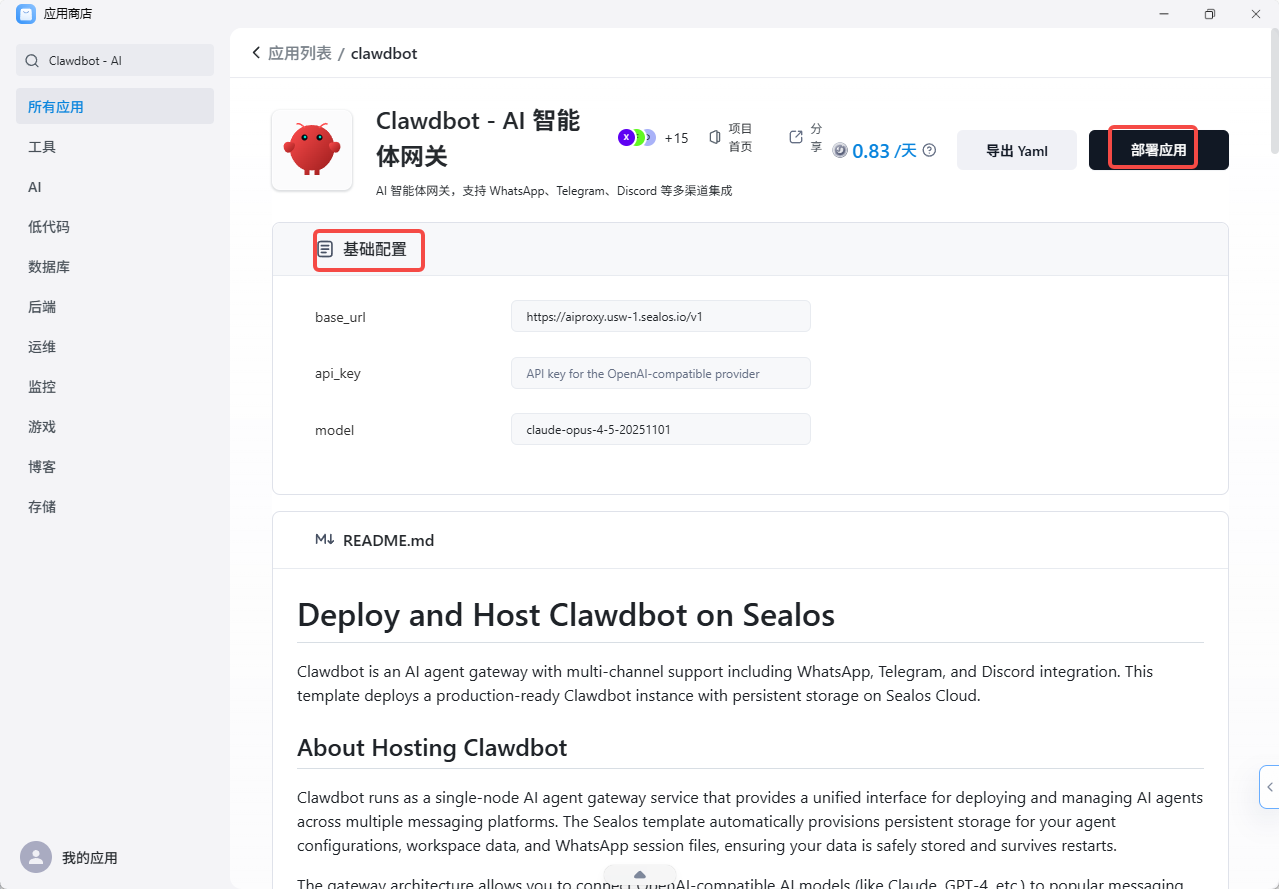
第二步:配置参数
主要就三个:
-
选择实例规格(建议2核4G起步)
-
填入你的OpenAI API Key
-
设置访问密码
第三步:点击部署,等待两分钟
Sealos会自动帮你:
-
拉起OpenClaw主服务
-
配置好Redis作为事件队列
-
生成访问域名
部署完成后,你会拿到一个类似 openclaw-xxxxx.cloud.sealos.run 的地址,直接访问就能用。
这代表了什么技术趋势
跳出OpenClaw本身,我觉得它代表了多Agent领域一个重要的方向:从"编程式编排"走向"声明式编排"。
未来的Agent开发者,可能不再需要写调度逻辑,只需要声明:
-
这个Agent负责什么
-
它需要什么输入、产出什么输出
-
它关心什么事件
编排框架自动帮你处理执行顺序、并行优化、故障恢复。
这和Kubernetes对容器编排的革命如出一辙——你不用关心容器在哪台机器上跑,K8s帮你调度。OpenClaw想做的,就是Agent领域的"K8s"。
现在,我的五个Agent系统已经稳定跑了三周,没再凌晨报警过。
如果你也在被多Agent协调折磨,真的建议试试事件驱动这条路。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 9
9 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)