手搓可訪問性修復AI:自動修復無障礙問題
本文详细介绍了如何从零开始构建一个可访问性修复AI系统,该系统能自动检测并修复网页无障碍问题。文章涵盖技术架构设计、算法原理和完整实现代码,主要包括以下内容: 系统架构:采用模块化设计,包含检测引擎、修复引擎和AI模块,技术栈包括Python、FastAPI、React等。 核心功能: 检测引擎实现DOM解析和规则检查 修复引擎提供多种修复策略 AI模块集成深度学习模型用于图像描述生成 完整实现:
手搓可訪問性修復AI:自動修復無障礙問題
摘要
本文詳細探討如何從零開始構建一個可訪問性修復AI系統,該系統能夠自動檢測網頁中的無障礙問題並提供修復方案。我們將深入分析技術架構、算法原理、代碼實現,並提供完整的實現代碼。本文約15000字,涵蓋從理論到實踐的全方位內容。
目錄
-
引言:可訪問性的重要性
-
可訪問性問題分類
-
系統架構設計
-
檢測引擎實現
-
修復引擎實現
-
AI模型集成
-
完整代碼實現
-
部署與優化
-
案例研究
-
未來展望
1. 引言:可訪問性的重要性
1.1 什麼是網頁可訪問性?
網頁可訪問性(Web Accessibility)是指網站、工具和技術的設計和開發方式,確保殘障人士能夠感知、理解、導航並與之互動,同時也能為普通用戶提供更好的使用體驗。
1.2 法律與標準
-
WCAG 2.1(Web Content Accessibility Guidelines)
-
Section 508(美國康復法案)
-
EN 301 549(歐盟標準)
-
無障礙網頁開發規範(台灣)
1.3 市場需求
全球有超過10億殘障人士,佔世界人口的15%。忽視可訪問性不僅是道德問題,也意味著放棄巨大的市場機會。
1.4 自動化修復的必要性
手動修復可訪問性問題耗時且容易出錯。AI驅動的自動修復系統可以:
-
大規模檢測和修復
-
降低人力成本
-
確保一致性
-
持續監控和維護
2. 可訪問性問題分類
2.1 感知性問題
-
圖像缺少替代文本
-
視頻缺少字幕
-
顏色對比度不足
-
文本大小不可調整
2.2 可操作性問題
-
鍵盤導航障礙
-
時間限制不足
-
閃爍內容可能引發癲癇
-
表單標籤缺失
2.3 理解性問題
-
語言未定義
-
表單驗證錯誤不明確
-
導航不一致
2.4 健壯性問題
-
HTML語法錯誤
-
ARIA屬性誤用
-
與輔助技術不兼容
3. 系統架構設計
3.1 整體架構
text
┌─────────────────────────────────────────┐
│ 用戶界面 │
│ ┌─────────┐ ┌─────────┐ ┌─────────┐ │
│ │ URL輸入 │ │ 文件上傳 │ │ 實時掃描 │ │
│ └─────────┘ └─────────┘ └─────────┘ │
└─────────────────┬───────────────────────┘
│
┌─────────────────▼───────────────────────┐
│ API網關層 │
│ (RESTful API + WebSocket) │
└─────────────────┬───────────────────────┘
│
┌─────────────────▼───────────────────────┐
│ 核心處理引擎 │
│ ┌────────────┬────────────┬──────────┐ │
│ │ 檢測引擎 │ 修復引擎 │ AI引擎 │ │
│ └────────────┴────────────┴──────────┘ │
└─────────────────┬───────────────────────┘
│
┌─────────────────▼───────────────────────┐
│ 數據存儲層 │
│ ┌──────┐ ┌──────┐ ┌────────────────┐ │
│ │ 緩存 │ │ 數據庫│ │ 文件存儲 │ │
│ └──────┘ └──────┘ └────────────────┘ │
└─────────────────────────────────────────┘
3.2 技術棧選擇
-
後端: Python + FastAPI(高性能API框架)
-
前端: React + TypeScript(響應式界面)
-
AI/ML: TensorFlow.js + PyTorch
-
檢測引擎: axe-core + Puppeteer
-
數據庫: PostgreSQL + Redis
-
部署: Docker + Kubernetes
3.3 模塊設計
3.3.1 檢測模塊
python
class DetectionModule:
"""檢測模塊基類"""
def __init__(self):
self.rules = self.load_rules()
def load_rules(self):
"""載入檢測規則"""
pass
def scan(self, html_content):
"""掃描HTML內容"""
pass
def analyze(self, dom_tree):
"""分析DOM樹"""
pass
3.3.2 修復模塊
python
class RepairModule:
"""修復模塊基類"""
def __init__(self):
self.strategies = self.load_strategies()
def load_strategies(self):
"""載入修復策略"""
pass
def apply_fix(self, issue, context):
"""應用修復"""
pass
def validate_fix(self, original, repaired):
"""驗證修復結果"""
pass
3.3.3 AI模塊
python
class AIModule:
"""AI模塊"""
def __init__(self, model_path):
self.model = self.load_model(model_path)
self.nlp_engine = self.init_nlp()
def predict_fix(self, issue):
"""預測修復方案"""
pass
def generate_alt_text(self, image_data):
"""生成圖片替代文本"""
pass
def suggest_semantic_structure(self, html):
"""建議語義結構"""
pass
4. 檢測引擎實現
4.1 規則引擎設計
python
import re
import json
from typing import Dict, List, Any, Optional
from dataclasses import dataclass
from enum import Enum
class IssueSeverity(Enum):
CRITICAL = "critical"
HIGH = "high"
MEDIUM = "medium"
LOW = "low"
INFO = "info"
class IssueCategory(Enum):
PERCEPTIBLE = "perceptible"
OPERABLE = "operable"
UNDERSTANDABLE = "understandable"
ROBUST = "robust"
@dataclass
class AccessibilityIssue:
"""可訪問性問題數據類"""
id: str
type: str
severity: IssueSeverity
category: IssueCategory
element: Dict[str, Any]
description: str
help_url: Optional[str] = None
context: Optional[Dict[str, Any]] = None
suggested_fixes: List[Dict[str, Any]] = None
def __post_init__(self):
if self.suggested_fixes is None:
self.suggested_fixes = []
class RuleEngine:
"""規則引擎"""
def __init__(self, rules_file: str = None):
self.rules = self._load_rules(rules_file)
self.issues = []
def _load_rules(self, rules_file: str) -> Dict:
"""載入檢測規則"""
default_rules = {
"missing_alt_text": {
"selector": "img:not([alt]), img[alt='']",
"severity": IssueSeverity.CRITICAL,
"category": IssueCategory.PERCEPTIBLE,
"description": "圖片缺少替代文本",
"test": self._check_missing_alt_text,
"help_url": "https://www.w3.org/WAI/tutorials/images/"
},
"low_contrast": {
"selector": "*",
"severity": IssueSeverity.HIGH,
"category": IssueCategory.PERCEPTIBLE,
"description": "顏色對比度不足",
"test": self._check_contrast_ratio,
"help_url": "https://www.w3.org/WAI/WCAG21/Understanding/contrast-minimum.html"
},
"missing_form_labels": {
"selector": "input, select, textarea",
"severity": IssueSeverity.HIGH,
"category": IssueCategory.OPERABLE,
"description": "表單控件缺少標籤",
"test": self._check_form_labels,
"help_url": "https://www.w3.org/WAI/tutorials/forms/labels/"
},
"keyboard_trap": {
"selector": "[tabindex]:not([tabindex='-1'])",
"severity": IssueSeverity.HIGH,
"category": IssueCategory.OPERABLE,
"description": "鍵盤焦點陷阱",
"test": self._check_keyboard_trap,
"help_url": "https://www.w3.org/WAI/WCAG21/Understanding/no-keyboard-trap.html"
},
"missing_lang_attribute": {
"selector": "html",
"severity": IssueSeverity.MEDIUM,
"category": IssueCategory.UNDERSTANDABLE,
"description": "HTML缺少語言屬性",
"test": self._check_lang_attribute,
"help_url": "https://www.w3.org/International/questions/qa-html-language-declarations"
}
}
if rules_file:
try:
with open(rules_file, 'r', encoding='utf-8') as f:
custom_rules = json.load(f)
default_rules.update(custom_rules)
except FileNotFoundError:
print(f"規則文件 {rules_file} 未找到,使用默認規則")
return default_rules
def _check_missing_alt_text(self, element: Dict) -> Optional[AccessibilityIssue]:
"""檢查缺失的替代文本"""
if element.get('tagName', '').lower() == 'img':
alt = element.get('attributes', {}).get('alt')
if alt is None or alt.strip() == '':
return AccessibilityIssue(
id="missing_alt_text",
type="missing_alt_text",
severity=IssueSeverity.CRITICAL,
category=IssueCategory.PERCEPTIBLE,
element=element,
description=f"圖片缺少替代文本: {element.get('attributes', {}).get('src', '未知圖片')}",
help_url=self.rules["missing_alt_text"]["help_url"],
suggested_fixes=[
{
"type": "attribute_addition",
"description": "添加alt屬性",
"implementation": lambda el: f'<img src="{el.get("src")}" alt="描述圖片內容">'
},
{
"type": "attribute_modification",
"description": "如果圖片是裝飾性的,使用空alt屬性",
"implementation": lambda el: f'<img src="{el.get("src")}" alt="">'
}
]
)
return None
def _check_contrast_ratio(self, element: Dict) -> Optional[AccessibilityIssue]:
"""檢查顏色對比度"""
# 獲取元素的計算樣式
styles = element.get('computedStyles', {})
color = styles.get('color', 'rgb(0, 0, 0)')
bg_color = styles.get('backgroundColor', 'rgb(255, 255, 255)')
# 計算對比度
contrast_ratio = self._calculate_contrast_ratio(color, bg_color)
# WCAG 2.1 AA標準:文本至少4.5:1,大字體至少3:1
font_size = float(styles.get('fontSize', '16px').replace('px', ''))
is_large_text = font_size >= 18 or (font_size >= 14 and styles.get('fontWeight', '400') >= '700')
required_ratio = 3.0 if is_large_text else 4.5
if contrast_ratio < required_ratio:
return AccessibilityIssue(
id="low_contrast",
type="low_contrast",
severity=IssueSeverity.HIGH,
category=IssueCategory.PERCEPTIBLE,
element=element,
description=f"顏色對比度不足: {contrast_ratio:.2f}:1 (要求: {required_ratio}:1)",
help_url=self.rules["low_contrast"]["help_url"],
context={"contrast_ratio": contrast_ratio, "required_ratio": required_ratio},
suggested_fixes=[
{
"type": "style_modification",
"description": "調整文字顏色",
"implementation": lambda el, ctx: f'color: {self._suggest_better_color(el, ctx)};'
},
{
"type": "style_modification",
"description": "調整背景顏色",
"implementation": lambda el, ctx: f'background-color: {self._suggest_better_bg_color(el, ctx)};'
}
]
)
return None
def _calculate_contrast_ratio(self, color1: str, color2: str) -> float:
"""計算兩個顏色的對比度"""
def hex_to_rgb(hex_color):
if hex_color.startswith('#'):
hex_color = hex_color[1:]
if len(hex_color) == 3:
hex_color = ''.join([c*2 for c in hex_color])
return tuple(int(hex_color[i:i+2], 16) for i in (0, 2, 4))
def rgb_to_luminance(rgb):
"""將RGB轉換為相對亮度"""
r, g, b = rgb
rsrgb = r / 255.0
gsrgb = g / 255.0
bsrgb = b / 255.0
r = rsrgb / 12.92 if rsrgb <= 0.03928 else ((rsrgb + 0.055) / 1.055) ** 2.4
g = gsrgb / 12.92 if gsrgb <= 0.03928 else ((gsrgb + 0.055) / 1.055) ** 2.4
b = bsrgb / 12.92 if bsrgb <= 0.03928 else ((bsrgb + 0.055) / 1.055) ** 2.4
return 0.2126 * r + 0.7152 * g + 0.0722 * b
# 解析顏色
def parse_color(color_str):
if color_str.startswith('rgb'):
numbers = re.findall(r'\d+', color_str)
if len(numbers) >= 3:
return tuple(int(n) for n in numbers[:3])
elif color_str.startswith('#'):
return hex_to_rgb(color_str)
return (0, 0, 0) # 默認黑色
rgb1 = parse_color(color1)
rgb2 = parse_color(color2)
l1 = rgb_to_luminance(rgb1)
l2 = rgb_to_luminance(rgb2)
# 確保l1是較亮的顏色
if l1 < l2:
l1, l2 = l2, l1
return (l1 + 0.05) / (l2 + 0.05)
def _check_form_labels(self, element: Dict) -> Optional[AccessibilityIssue]:
"""檢查表單標籤"""
tag_name = element.get('tagName', '').lower()
if tag_name in ['input', 'select', 'textarea']:
# 檢查是否有關聯的label
element_id = element.get('attributes', {}).get('id')
if not element_id:
return AccessibilityIssue(
id="missing_form_label",
type="missing_form_label",
severity=IssueSeverity.HIGH,
category=IssueCategory.OPERABLE,
element=element,
description="表單控件缺少ID,無法關聯標籤",
help_url=self.rules["missing_form_labels"]["help_url"],
suggested_fixes=[
{
"type": "structure_addition",
"description": "添加label元素",
"implementation": lambda el: f'<label for="{self._generate_id(el)}">描述文字</label>\n{self._element_to_html(el)}'
}
]
)
# 檢查是否有aria-label或aria-labelledby
aria_label = element.get('attributes', {}).get('aria-label')
aria_labelledby = element.get('attributes', {}).get('aria-labelledby')
if not (aria_label or aria_labelledby):
# 需要檢查DOM中是否有對應的label
return AccessibilityIssue(
id="missing_form_label",
type="missing_form_label",
severity=IssueSeverity.HIGH,
category=IssueCategory.OPERABLE,
element=element,
description="表單控件缺少明確標籤",
help_url=self.rules["missing_form_labels"]["help_url"],
suggested_fixes=[
{
"type": "attribute_addition",
"description": "添加aria-label屬性",
"implementation": lambda el: f'<{el.get("tagName")} id="{el.get("attributes", {}).get("id")}" aria-label="控件描述">'
},
{
"type": "structure_addition",
"description": "添加label元素",
"implementation": lambda el: f'<label for="{el.get("attributes", {}).get("id")}">控件描述</label>'
}
]
)
return None
def _check_keyboard_trap(self, element: Dict) -> Optional[AccessibilityIssue]:
"""檢查鍵盤陷阱"""
# 這裡是簡化版本,實際需要更複雜的檢測
tabindex = element.get('attributes', {}).get('tabindex')
if tabindex and tabindex != '-1':
# 檢查元素是否在彈窗或對話框中
parent = element.get('parent')
while parent:
if parent.get('tagName', '').lower() in ['dialog', '[role="dialog"]', '[role="modal"]']:
# 需要確保有逃生機制
return AccessibilityIssue(
id="keyboard_trap",
type="keyboard_trap",
severity=IssueSeverity.HIGH,
category=IssueCategory.OPERABLE,
element=element,
description="可能存在的鍵盤焦點陷阱",
help_url=self.rules["keyboard_trap"]["help_url"],
suggested_fixes=[
{
"type": "script_addition",
"description": "添加ESC鍵關閉功能",
"implementation": lambda el: self._add_escape_handler(el)
}
]
)
parent = parent.get('parent')
return None
def _check_lang_attribute(self, element: Dict) -> Optional[AccessibilityIssue]:
"""檢查語言屬性"""
if element.get('tagName', '').lower() == 'html':
lang = element.get('attributes', {}).get('lang')
if not lang:
return AccessibilityIssue(
id="missing_lang",
type="missing_lang",
severity=IssueSeverity.MEDIUM,
category=IssueCategory.UNDERSTANDABLE,
element=element,
description="HTML文檔缺少語言屬性",
help_url=self.rules["missing_lang_attribute"]["help_url"],
suggested_fixes=[
{
"type": "attribute_addition",
"description": "添加lang屬性",
"implementation": lambda el: '<html lang="zh-TW">'
}
]
)
return None
def _generate_id(self, element: Dict) -> str:
"""生成唯一的ID"""
tag_name = element.get('tagName', '').lower()
name = element.get('attributes', {}).get('name', '')
return f"{tag_name}_{name}_{hash(str(element))}"
def _suggest_better_color(self, element: Dict, context: Dict) -> str:
"""建議更好的顏色"""
# 簡化版本:返回黑色或白色
bg_color = element.get('computedStyles', {}).get('backgroundColor', 'rgb(255, 255, 255)')
if bg_color.startswith('rgb'):
numbers = re.findall(r'\d+', bg_color)
if numbers:
r, g, b = map(int, numbers[:3])
# 計算亮度
brightness = (r * 299 + g * 587 + b * 114) / 1000
return '#000000' if brightness > 128 else '#ffffff'
return '#000000'
def _add_escape_handler(self, element: Dict) -> str:
"""添加ESC鍵處理器"""
element_id = element.get('attributes', {}).get('id', 'element_' + str(hash(str(element))))
return f"""
<script>
document.getElementById('{element_id}').addEventListener('keydown', function(e) {{
if (e.key === 'Escape') {{
// 關閉對話框或釋放焦點
this.blur();
}}
}});
</script>
"""
def scan(self, dom_tree: Dict) -> List[AccessibilityIssue]:
"""掃描DOM樹"""
self.issues = []
def traverse(node):
# 對每個節點應用所有規則
for rule_name, rule_config in self.rules.items():
test_func = rule_config.get('test')
if test_func and callable(test_func):
issue = test_func(node)
if issue:
self.issues.append(issue)
# 遍歷子節點
for child in node.get('children', []):
traverse(child)
traverse(dom_tree)
return self.issues
def get_issues_by_severity(self, severity: IssueSeverity) -> List[AccessibilityIssue]:
"""按嚴重程度篩選問題"""
return [issue for issue in self.issues if issue.severity == severity]
def get_issues_by_category(self, category: IssueCategory) -> List[AccessibilityIssue]:
"""按類別篩選問題"""
return [issue for issue in self.issues if issue.category == category]
4.2 DOM解析器實現
python
from bs4 import BeautifulSoup
import re
from typing import Dict, List, Any
class DOMParser:
"""DOM解析器"""
def __init__(self):
self.soup = None
def parse_html(self, html_content: str) -> Dict:
"""解析HTML為DOM樹"""
self.soup = BeautifulSoup(html_content, 'html.parser')
def parse_node(node):
"""遞歸解析節點"""
result = {
'tagName': node.name if node.name else 'text',
'attributes': {},
'children': [],
'textContent': node.string if node.string else '',
'computedStyles': self._get_computed_styles(node)
}
# 處理屬性
if hasattr(node, 'attrs'):
for key, value in node.attrs.items():
result['attributes'][key] = value
# 遞歸處理子節點
if hasattr(node, 'children'):
for child in node.children:
if child.name or (hasattr(child, 'string') and child.string and child.string.strip()):
result['children'].append(parse_node(child))
return result
return parse_node(self.soup)
def _get_computed_styles(self, node) -> Dict[str, str]:
"""獲取計算樣式(簡化版本)"""
# 實際應用中應使用瀏覽器引擎或CSS解析器
styles = {}
if hasattr(node, 'attrs') and 'style' in node.attrs:
style_string = node.attrs['style']
# 解析內聯樣式
for style in style_string.split(';'):
if ':' in style:
key, value = style.split(':', 1)
styles[key.strip()] = value.strip()
# 添加一些默認值
styles.setdefault('color', 'rgb(0, 0, 0)')
styles.setdefault('backgroundColor', 'rgb(255, 255, 255)')
styles.setdefault('fontSize', '16px')
styles.setdefault('fontWeight', '400')
return styles
def get_element_by_xpath(self, xpath: str):
"""通過XPath獲取元素"""
# 簡化版本,實際應用中應使用lxml等庫
pass
def get_elements_by_selector(self, selector: str) -> List[Dict]:
"""通過CSS選擇器獲取元素"""
elements = []
soup_elements = self.soup.select(selector)
for elem in soup_elements:
elements.append(self._soup_to_dict(elem))
return elements
def _soup_to_dict(self, node) -> Dict:
"""將BeautifulSoup節點轉換為字典"""
return {
'tagName': node.name,
'attributes': node.attrs,
'textContent': node.text,
'computedStyles': self._get_computed_styles(node)
}
4.3 檢測器集成
python
import asyncio
from concurrent.futures import ThreadPoolExecutor
import time
from typing import Dict, List, Any
class AccessibilityDetector:
"""可訪問性檢測器"""
def __init__(self):
self.parser = DOMParser()
self.rule_engine = RuleEngine()
self.executor = ThreadPoolExecutor(max_workers=4)
async def scan_url(self, url: str) -> Dict[str, Any]:
"""掃描URL"""
import aiohttp
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
html = await response.text()
return await self.scan_html(html, url)
async def scan_html(self, html_content: str, source: str = None) -> Dict[str, Any]:
"""掃描HTML內容"""
start_time = time.time()
# 解析DOM
dom_tree = await asyncio.get_event_loop().run_in_executor(
self.executor, self.parser.parse_html, html_content
)
# 執行檢測
issues = await asyncio.get_event_loop().run_in_executor(
self.executor, self.rule_engine.scan, dom_tree
)
# 統計信息
severity_counts = {
'critical': 0,
'high': 0,
'medium': 0,
'low': 0,
'info': 0
}
category_counts = {
'perceptible': 0,
'operable': 0,
'understandable': 0,
'robust': 0
}
for issue in issues:
severity_counts[issue.severity.value] += 1
category_counts[issue.category.value] += 1
end_time = time.time()
return {
'source': source,
'scan_time': end_time - start_time,
'total_issues': len(issues),
'severity_counts': severity_counts,
'category_counts': category_counts,
'issues': [self._issue_to_dict(issue) for issue in issues],
'summary': self._generate_summary(issues, severity_counts)
}
def _issue_to_dict(self, issue: AccessibilityIssue) -> Dict:
"""將問題轉換為字典"""
return {
'id': issue.id,
'type': issue.type,
'severity': issue.severity.value,
'category': issue.category.value,
'element': issue.element,
'description': issue.description,
'help_url': issue.help_url,
'context': issue.context,
'suggested_fixes': issue.suggested_fixes
}
def _generate_summary(self, issues: List[AccessibilityIssue], severity_counts: Dict) -> str:
"""生成摘要報告"""
total = len(issues)
critical = severity_counts['critical']
high = severity_counts['high']
summary = f"掃描完成,共發現 {total} 個可訪問性問題。\n"
if critical > 0:
summary += f"❌ 嚴重問題: {critical} 個(必須立即修復)\n"
if high > 0:
summary += f"⚠️ 重要問題: {high} 個(應該盡快修復)\n"
if critical == 0 and high == 0:
summary += "✅ 沒有發現嚴重問題,網站可訪問性良好。\n"
return summary
def export_report(self, scan_result: Dict, format: str = 'json') -> str:
"""導出報告"""
if format == 'json':
import json
return json.dumps(scan_result, ensure_ascii=False, indent=2)
elif format == 'html':
return self._generate_html_report(scan_result)
elif format == 'csv':
return self._generate_csv_report(scan_result)
else:
raise ValueError(f"不支持的格式: {format}")
def _generate_html_report(self, scan_result: Dict) -> str:
"""生成HTML報告"""
html_template = """
<!DOCTYPE html>
<html lang="zh-TW">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>可訪問性檢測報告</title>
<style>
body { font-family: Arial, sans-serif; margin: 20px; }
.summary { background: #f5f5f5; padding: 20px; border-radius: 5px; }
.critical { color: #d32f2f; font-weight: bold; }
.high { color: #f57c00; }
.medium { color: #fbc02d; }
.low { color: #388e3c; }
.info { color: #1976d2; }
.issue { border: 1px solid #ddd; margin: 10px 0; padding: 15px; border-radius: 5px; }
.fix { background: #e8f5e8; padding: 10px; margin: 5px 0; border-radius: 3px; }
table { border-collapse: collapse; width: 100%; }
th, td { border: 1px solid #ddd; padding: 8px; text-align: left; }
th { background-color: #f2f2f2; }
</style>
</head>
<body>
<h1>可訪問性檢測報告</h1>
<div class="summary">
<h2>摘要</h2>
<p>掃描來源: {source}</p>
<p>掃描時間: {scan_time:.2f}秒</p>
<p>總問題數: {total_issues}</p>
<table>
<tr><th>嚴重程度</th><th>數量</th></tr>
<tr><td class="critical">嚴重</td><td>{critical}</td></tr>
<tr><td class="high">高</td><td>{high}</td></tr>
<tr><td class="medium">中</td><td>{medium}</td></tr>
<tr><td class="low">低</td><td>{low}</td></tr>
<tr><td class="info">信息</td><td>{info}</td></tr>
</table>
</div>
<h2>詳細問題列表</h2>
{issues_html}
</body>
</html>
"""
issues_html = ""
for issue in scan_result['issues']:
fixes_html = ""
for fix in issue.get('suggested_fixes', []):
fixes_html += f"""
<div class="fix">
<strong>{fix.get('description', '修復建議')}:</strong><br>
<code>{fix.get('implementation', '')}</code>
</div>
"""
issues_html += f"""
<div class="issue {issue['severity']}">
<h3>{issue['description']}</h3>
<p><strong>嚴重程度:</strong> <span class="{issue['severity']}">{issue['severity']}</span></p>
<p><strong>類別:</strong> {issue['category']}</p>
<p><strong>元素:</strong> <code>{issue['element'].get('tagName', '未知')}</code></p>
{fixes_html}
<p><a href="{issue.get('help_url', '#')}" target="_blank">了解更多</a></p>
</div>
"""
return html_template.format(
source=scan_result.get('source', '未知'),
scan_time=scan_result.get('scan_time', 0),
total_issues=scan_result.get('total_issues', 0),
critical=scan_result['severity_counts']['critical'],
high=scan_result['severity_counts']['high'],
medium=scan_result['severity_counts']['medium'],
low=scan_result['severity_counts']['low'],
info=scan_result['severity_counts']['info'],
issues_html=issues_html
)
def _generate_csv_report(self, scan_result: Dict) -> str:
"""生成CSV報告"""
import csv
import io
output = io.StringIO()
writer = csv.writer(output)
# 寫入標題
writer.writerow(['類型', '嚴重程度', '描述', '元素', '修復建議'])
# 寫入數據
for issue in scan_result['issues']:
fixes = '; '.join([fix.get('description', '') for fix in issue.get('suggested_fixes', [])])
writer.writerow([
issue['type'],
issue['severity'],
issue['description'],
issue['element'].get('tagName', ''),
fixes
])
return output.getvalue()
5. 修復引擎實現
5.1 修復策略引擎
python
from typing import Dict, List, Any, Optional, Callable
import re
from abc import ABC, abstractmethod
class FixStrategy(ABC):
"""修復策略基類"""
def __init__(self):
self.priority = 1 # 優先級,數值越小優先級越高
@abstractmethod
def can_fix(self, issue: AccessibilityIssue) -> bool:
"""判斷是否能修復此問題"""
pass
@abstractmethod
def apply_fix(self, html: str, issue: AccessibilityIssue) -> str:
"""應用修復"""
pass
@abstractmethod
def validate_fix(self, original: str, fixed: str) -> bool:
"""驗證修復是否有效"""
pass
class AltTextFixStrategy(FixStrategy):
"""替代文本修復策略"""
def __init__(self):
super().__init__()
self.priority = 1 # 高優先級
def can_fix(self, issue: AccessibilityIssue) -> bool:
return issue.type == "missing_alt_text"
def apply_fix(self, html: str, issue: AccessibilityIssue) -> str:
"""為圖片添加替代文本"""
element = issue.element
tag_name = element.get('tagName', '')
attributes = element.get('attributes', {})
if tag_name.lower() != 'img':
return html
src = attributes.get('src', '')
# 生成替代文本
alt_text = self._generate_alt_text(src, element)
# 構建新的img標籤
new_img_tag = self._build_img_tag(src, alt_text, attributes)
# 在HTML中替換
pattern = self._create_pattern(element)
if pattern:
return re.sub(pattern, new_img_tag, html, flags=re.DOTALL)
return html
def _generate_alt_text(self, src: str, element: Dict) -> str:
"""生成替代文本"""
# 從文件名推斷
filename = src.split('/')[-1].split('.')[0]
# 清理文件名
filename = re.sub(r'[_-]', ' ', filename)
filename = re.sub(r'\d+', '', filename)
if filename.strip():
return f"圖片: {filename.capitalize()}"
# 檢查周圍文本
context = self._get_context(element)
if context:
return f"與 '{context}' 相關的圖片"
# 默認文本
return "內容圖片"
def _get_context(self, element: Dict) -> str:
"""獲取上下文文本"""
# 簡化版本,實際應該分析DOM結構
text_content = element.get('textContent', '')
if text_content and len(text_content) < 50:
return text_content
# 檢查父元素
parent = element.get('parent', {})
parent_text = parent.get('textContent', '')
if parent_text:
return parent_text[:50]
return ""
def _build_img_tag(self, src: str, alt: str, attributes: Dict) -> str:
"""構建img標籤"""
attr_strings = []
for key, value in attributes.items():
if key.lower() != 'alt': # 跳過原有的alt
attr_strings.append(f'{key}="{value}"')
attr_strings.append(f'alt="{alt}"')
return f'<img {" ".join(attr_strings)}>'
def _create_pattern(self, element: Dict) -> Optional[str]:
"""創建匹配模式"""
attributes = element.get('attributes', {})
if 'src' in attributes:
src = re.escape(attributes['src'])
return f'<img[^>]*src=["\']{src}["\'][^>]*>'
return None
def validate_fix(self, original: str, fixed: str) -> bool:
"""驗證修復"""
# 檢查fixed中是否所有img都有alt屬性
import re
img_tags = re.findall(r'<img[^>]*>', fixed)
for img in img_tags:
if 'alt=' not in img.lower():
return False
return True
class ContrastFixStrategy(FixStrategy):
"""對比度修復策略"""
def __init__(self):
super().__init__()
self.priority = 2
def can_fix(self, issue: AccessibilityIssue) -> bool:
return issue.type == "low_contrast"
def apply_fix(self, html: str, issue: AccessibilityIssue) -> str:
"""修復顏色對比度"""
element = issue.element
context = issue.context or {}
# 計算建議顏色
suggested_color = self._calculate_suggested_color(element, context)
# 構建CSS選擇器
selector = self._create_selector(element)
# 添加或修改樣式
style_tag = f"""
<style>
{selector} {{
color: {suggested_color} !important;
}}
</style>
"""
# 插入到head中
if '<head>' in html:
html = html.replace('</head>', f'{style_tag}</head>')
else:
html = f'{style_tag}{html}'
return html
def _calculate_suggested_color(self, element: Dict, context: Dict) -> str:
"""計算建議顏色"""
current_color = element.get('computedStyles', {}).get('color', 'rgb(0, 0, 0)')
bg_color = element.get('computedStyles', {}).get('backgroundColor', 'rgb(255, 255, 255)')
# 轉換為RGB
def parse_color(color_str):
if color_str.startswith('rgb'):
numbers = re.findall(r'\d+', color_str)
if len(numbers) >= 3:
return tuple(int(n) for n in numbers[:3])
elif color_str.startswith('#'):
return self._hex_to_rgb(color_str)
return (0, 0, 0)
current_rgb = parse_color(current_color)
bg_rgb = parse_color(bg_color)
# 計算對比度
current_ratio = self._calculate_contrast_ratio(current_rgb, bg_rgb)
required_ratio = context.get('required_ratio', 4.5)
if current_ratio >= required_ratio:
return current_color
# 嘗試調整亮度
target_rgb = self._adjust_for_contrast(current_rgb, bg_rgb, required_ratio)
# 轉換回CSS顏色
return f'rgb({target_rgb[0]}, {target_rgb[1]}, {target_rgb[2]})'
def _hex_to_rgb(self, hex_color):
"""十六進制轉RGB"""
hex_color = hex_color.lstrip('#')
if len(hex_color) == 3:
hex_color = ''.join([c*2 for c in hex_color])
return tuple(int(hex_color[i:i+2], 16) for i in (0, 2, 4))
def _calculate_contrast_ratio(self, rgb1, rgb2):
"""計算對比度"""
def luminance(rgb):
r, g, b = rgb
rsrgb = r / 255.0
gsrgb = g / 255.0
bsrgb = b / 255.0
r = rsrgb / 12.92 if rsrgb <= 0.03928 else ((rsrgb + 0.055) / 1.055) ** 2.4
g = gsrgb / 12.92 if gsrgb <= 0.03928 else ((gsrgb + 0.055) / 1.055) ** 2.4
b = bsrgb / 12.92 if bsrgb <= 0.03928 else ((bsrgb + 0.055) / 1.055) ** 2.4
return 0.2126 * r + 0.7152 * g + 0.0722 * b
l1 = luminance(rgb1)
l2 = luminance(rgb2)
if l1 < l2:
l1, l2 = l2, l1
return (l1 + 0.05) / (l2 + 0.05)
def _adjust_for_contrast(self, fg_rgb, bg_rgb, min_ratio):
"""調整顏色以達到最小對比度"""
# 簡化算法:根據背景色選擇黑色或白色
bg_brightness = (bg_rgb[0] * 299 + bg_rgb[1] * 587 + bg_rgb[2] * 114) / 1000
if bg_brightness > 128:
# 淺色背景用黑色
return (0, 0, 0)
else:
# 深色背景用白色
return (255, 255, 255)
def _create_selector(self, element: Dict) -> str:
"""創建CSS選擇器"""
tag_name = element.get('tagName', '')
attributes = element.get('attributes', {})
selector = tag_name
# 添加ID選擇器
if 'id' in attributes:
selector += f'#{attributes["id"]}'
# 添加類選擇器
if 'class' in attributes:
classes = attributes['class'].split()
for cls in classes:
selector += f'.{cls}'
return selector
def validate_fix(self, original: str, fixed: str) -> bool:
"""驗證修復"""
# 檢查是否添加了樣式標籤
return '<style>' in fixed
class FormLabelFixStrategy(FixStrategy):
"""表單標籤修復策略"""
def __init__(self):
super().__init__()
self.priority = 1
def can_fix(self, issue: AccessibilityIssue) -> bool:
return issue.type == "missing_form_label"
def apply_fix(self, html: str, issue: AccessibilityIssue) -> str:
"""修復表單標籤"""
element = issue.element
tag_name = element.get('tagName', '').lower()
if tag_name not in ['input', 'select', 'textarea']:
return html
attributes = element.get('attributes', {})
# 生成ID
element_id = attributes.get('id')
if not element_id:
element_id = f"input_{hash(str(element))}"
# 生成標籤文本
label_text = self._generate_label_text(element)
# 創建label元素
label_html = f'<label for="{element_id}">{label_text}</label>'
# 修改原始元素
element_html = self._get_element_html(element)
if element_html:
# 添加ID
if 'id=' not in element_html:
element_html = element_html.replace(f'<{tag_name}', f'<{tag_name} id="{element_id}"')
# 替換
html = html.replace(element_html, f'{label_html}\n{element_html}')
return html
def _generate_label_text(self, element: Dict) -> str:
"""生成標籤文本"""
attributes = element.get('attributes', {})
# 嘗試從現有屬性獲取
if 'placeholder' in attributes:
return attributes['placeholder']
elif 'name' in attributes:
name = attributes['name']
# 美化名稱
name = re.sub(r'[_-]', ' ', name)
return name.capitalize()
elif 'type' in attributes:
input_type = attributes['type']
type_map = {
'text': '文本輸入',
'email': '電子郵件',
'password': '密碼',
'submit': '提交',
'button': '按鈕'
}
return type_map.get(input_type, '輸入欄位')
return '表單欄位'
def _get_element_html(self, element: Dict) -> Optional[str]:
"""獲取元素原始HTML"""
# 簡化版本,實際應從原始HTML中提取
tag_name = element.get('tagName', '')
attributes = element.get('attributes', {})
attr_strings = []
for key, value in attributes.items():
attr_strings.append(f'{key}="{value}"')
if tag_name in ['input', 'img']:
return f'<{tag_name} {" ".join(attr_strings)}>'
else:
return f'<{tag_name} {" ".join(attr_strings)}></{tag_name}>'
def validate_fix(self, original: str, fixed: str) -> bool:
"""驗證修復"""
# 檢查是否有label標籤
return '<label' in fixed
class RepairEngine:
"""修復引擎"""
def __init__(self):
self.strategies = self._load_strategies()
self.fix_history = []
def _load_strategies(self) -> List[FixStrategy]:
"""載入修復策略"""
return [
AltTextFixStrategy(),
ContrastFixStrategy(),
FormLabelFixStrategy(),
# 可以添加更多策略
]
def find_strategy(self, issue: AccessibilityIssue) -> Optional[FixStrategy]:
"""查找適合的修復策略"""
available_strategies = []
for strategy in self.strategies:
if strategy.can_fix(issue):
available_strategies.append(strategy)
if not available_strategies:
return None
# 按優先級排序
available_strategies.sort(key=lambda s: s.priority)
return available_strategies[0]
def apply_fixes(self, html: str, issues: List[AccessibilityIssue]) -> Dict[str, Any]:
"""應用多個修復"""
original_html = html
fixed_html = html
applied_fixes = []
failed_fixes = []
# 按嚴重程度排序(嚴重問題優先)
issues.sort(key=lambda i: {
'critical': 0,
'high': 1,
'medium': 2,
'low': 3,
'info': 4
}[i.severity.value])
for issue in issues:
strategy = self.find_strategy(issue)
if strategy:
try:
fixed_html = strategy.apply_fix(fixed_html, issue)
# 驗證修復
if strategy.validate_fix(original_html, fixed_html):
applied_fixes.append({
'issue': issue,
'strategy': strategy.__class__.__name__,
'success': True
})
# 記錄到歷史
self.fix_history.append({
'timestamp': time.time(),
'issue': issue,
'strategy': strategy.__class__.__name__,
'original': original_html,
'fixed': fixed_html
})
else:
failed_fixes.append({
'issue': issue,
'strategy': strategy.__class__.__name__,
'reason': '驗證失敗'
})
except Exception as e:
failed_fixes.append({
'issue': issue,
'strategy': strategy.__class__.__name__,
'reason': str(e)
})
else:
failed_fixes.append({
'issue': issue,
'strategy': None,
'reason': '沒有找到適合的修復策略'
})
# 計算修復率
total_issues = len(issues)
success_count = len(applied_fixes)
fix_rate = success_count / total_issues if total_issues > 0 else 0
return {
'original_html': original_html,
'fixed_html': fixed_html,
'total_issues': total_issues,
'applied_fixes': applied_fixes,
'failed_fixes': failed_fixes,
'fix_rate': fix_rate,
'fix_history': self.fix_history[-10:] # 最近10條記錄
}
def batch_fix(self, html_list: List[str], issue_lists: List[List[AccessibilityIssue]]) -> List[Dict]:
"""批量修復"""
results = []
for html, issues in zip(html_list, issue_lists):
result = self.apply_fixes(html, issues)
results.append(result)
return results
def get_fix_statistics(self) -> Dict[str, Any]:
"""獲取修復統計"""
total_fixes = len(self.fix_history)
if total_fixes == 0:
return {'total': 0}
# 按問題類型統計
issue_types = {}
for record in self.fix_history:
issue_type = record['issue'].type
issue_types[issue_type] = issue_types.get(issue_type, 0) + 1
# 按策略統計
strategies = {}
for record in self.fix_history:
strategy = record['strategy']
strategies[strategy] = strategies.get(strategy, 0) + 1
return {
'total_fixes': total_fixes,
'issue_types': issue_types,
'strategies': strategies,
'last_fix_time': self.fix_history[-1]['timestamp'] if self.fix_history else None
}
5.2 智能修復決策系統
python
import numpy as np
from typing import Dict, List, Any, Tuple
from dataclasses import dataclass
from enum import Enum
import json
class FixDecision(Enum):
"""修復決策"""
APPLY_FIX = "apply_fix"
SUGGEST_MANUAL = "suggest_manual"
IGNORE = "ignore"
DEFER = "defer"
@dataclass
class FixRecommendation:
"""修復建議"""
decision: FixDecision
confidence: float
strategy: str
reasoning: str
estimated_impact: float # 0-1,預估影響
class IntelligentRepairSystem:
"""智能修復系統"""
def __init__(self, model_path: str = None):
self.repair_engine = RepairEngine()
self.decision_model = self._load_decision_model(model_path)
self.context_analyzer = ContextAnalyzer()
def _load_decision_model(self, model_path: str):
"""載入決策模型"""
# 簡化版本,實際應載入訓練好的ML模型
return {
'weights': {
'severity': 0.3,
'complexity': 0.2,
'frequency': 0.2,
'context': 0.3
},
'thresholds': {
'auto_fix': 0.7,
'manual_review': 0.4
}
}
def analyze_and_fix(self, html: str, issues: List[AccessibilityIssue]) -> Dict[str, Any]:
"""分析並修復"""
# 分析每個問題
recommendations = []
for issue in issues:
recommendation = self._analyze_issue(issue, html)
recommendations.append(recommendation)
# 分組問題
auto_fix_issues = []
manual_review_issues = []
for issue, rec in zip(issues, recommendations):
if rec.decision == FixDecision.APPLY_FIX:
auto_fix_issues.append(issue)
elif rec.decision == FixDecision.SUGGEST_MANUAL:
manual_review_issues.append(issue)
# 自動修復
auto_fix_result = self.repair_engine.apply_fixes(html, auto_fix_issues)
# 生成報告
report = self._generate_report(
html,
auto_fix_result,
manual_review_issues,
recommendations
)
return report
def _analyze_issue(self, issue: AccessibilityIssue, html: str) -> FixRecommendation:
"""分析單個問題"""
# 計算特徵
features = self._extract_features(issue, html)
# 計算分數
score = self._calculate_score(features)
# 分析上下文
context_analysis = self.context_analyzer.analyze(issue, html)
# 做出決策
decision, confidence, reasoning = self._make_decision(
score, context_analysis, issue
)
# 選擇策略
strategy = self._select_strategy(issue, decision)
# 估計影響
impact = self._estimate_impact(issue, features)
return FixRecommendation(
decision=decision,
confidence=confidence,
strategy=strategy,
reasoning=reasoning,
estimated_impact=impact
)
def _extract_features(self, issue: AccessibilityIssue, html: str) -> Dict[str, float]:
"""提取特徵"""
features = {}
# 嚴重程度特徵
severity_map = {
'critical': 1.0,
'high': 0.8,
'medium': 0.5,
'low': 0.3,
'info': 0.1
}
features['severity'] = severity_map.get(issue.severity.value, 0.5)
# 複雜度特徵(簡化)
element = issue.element
features['complexity'] = self._calculate_complexity(element)
# 頻率特徵(同類問題在頁面中的比例)
features['frequency'] = self._calculate_frequency(issue, html)
# 上下文特徵
features['context'] = self._analyze_context(issue, html)
return features
def _calculate_complexity(self, element: Dict) -> float:
"""計算元素複雜度"""
complexity = 0.0
# 標籤類型
tag_name = element.get('tagName', '').lower()
if tag_name in ['table', 'form', 'nav']:
complexity += 0.3
elif tag_name in ['div', 'section', 'article']:
complexity += 0.1
# 屬性數量
attributes = element.get('attributes', {})
attr_count = len(attributes)
complexity += min(attr_count * 0.05, 0.3)
# 子元素數量
children = element.get('children', [])
child_count = len(children)
complexity += min(child_count * 0.02, 0.3)
return min(complexity, 1.0)
def _calculate_frequency(self, issue: AccessibilityIssue, html: str) -> float:
"""計算頻率"""
# 簡化版本
issue_type = issue.type
# 在真實系統中,這裡應該統計同類問題的數量
# 此處返回固定值
return 0.5
def _analyze_context(self, issue: AccessibilityIssue, html: str) -> float:
"""分析上下文"""
element = issue.element
# 檢查元素是否在重要區域
important_tags = ['main', 'header', 'footer', 'nav', 'article']
parent = element
for _ in range(5): # 檢查5層父元素
if parent:
tag_name = parent.get('tagName', '').lower()
if tag_name in important_tags:
return 0.8
parent = parent.get('parent')
return 0.3
def _calculate_score(self, features: Dict[str, float]) -> float:
"""計算綜合分數"""
weights = self.decision_model['weights']
score = 0.0
for feature, weight in weights.items():
if feature in features:
score += features[feature] * weight
return min(score, 1.0)
def _make_decision(self, score: float, context_analysis: Dict,
issue: AccessibilityIssue) -> Tuple[FixDecision, float, str]:
"""做出決策"""
thresholds = self.decision_model['thresholds']
if score >= thresholds['auto_fix']:
decision = FixDecision.APPLY_FIX
confidence = score
reasoning = "問題簡單,自動修復成功率高"
elif score >= thresholds['manual_review']:
decision = FixDecision.SUGGEST_MANUAL
confidence = score
reasoning = "建議人工審核,可能需要上下文理解"
else:
decision = FixDecision.IGNORE
confidence = 1 - score
reasoning = "問題影響較小,暫不處理"
return decision, confidence, reasoning
def _select_strategy(self, issue: AccessibilityIssue, decision: FixDecision) -> str:
"""選擇修復策略"""
if decision != FixDecision.APPLY_FIX:
return "manual_review"
# 查找適合的策略
strategy = self.repair_engine.find_strategy(issue)
if strategy:
return strategy.__class__.__name__
return "unknown"
def _estimate_impact(self, issue: AccessibilityIssue, features: Dict[str, float]) -> float:
"""估計影響"""
# 基於嚴重程度和頻率
severity = features.get('severity', 0.5)
frequency = features.get('frequency', 0.5)
return (severity * 0.7 + frequency * 0.3)
def _generate_report(self, original_html: str, fix_result: Dict,
manual_issues: List[AccessibilityIssue],
recommendations: List[FixRecommendation]) -> Dict[str, Any]:
"""生成報告"""
# 統計
total_issues = len(recommendations)
auto_fixed = len(fix_result['applied_fixes'])
manual_needed = len(manual_issues)
ignored = total_issues - auto_fixed - manual_needed
# 計算改善率
improvement_rate = auto_fixed / total_issues if total_issues > 0 else 0
# 生成建議
suggestions = []
for issue, rec in zip(manual_issues, recommendations):
if rec.decision == FixDecision.SUGGEST_MANUAL:
suggestions.append({
'issue': issue.description,
'reasoning': rec.reasoning,
'suggested_action': '人工審核'
})
return {
'summary': {
'total_issues': total_issues,
'auto_fixed': auto_fixed,
'manual_needed': manual_needed,
'ignored': ignored,
'improvement_rate': improvement_rate,
'html_size_change': len(fix_result['fixed_html']) - len(original_html)
},
'fix_details': fix_result,
'manual_recommendations': suggestions,
'all_recommendations': [
{
'issue': r.issue.description if hasattr(r, 'issue') else '未知',
'decision': r.decision.value,
'confidence': r.confidence,
'strategy': r.strategy,
'reasoning': r.reasoning
}
for r in recommendations
]
}
def save_decision_model(self, path: str):
"""保存決策模型"""
with open(path, 'w', encoding='utf-8') as f:
json.dump(self.decision_model, f, ensure_ascii=False, indent=2)
def load_decision_model(self, path: str):
"""載入決策模型"""
with open(path, 'r', encoding='utf-8') as f:
self.decision_model = json.load(f)
class ContextAnalyzer:
"""上下文分析器"""
def analyze(self, issue: AccessibilityIssue, html: str) -> Dict[str, Any]:
"""分析上下文"""
element = issue.element
analysis = {
'element_type': element.get('tagName', ''),
'position': self._get_element_position(element),
'surrounding_text': self._get_surrounding_text(element),
'semantic_context': self._get_semantic_context(element),
'visual_importance': self._estimate_visual_importance(element)
}
return analysis
def _get_element_position(self, element: Dict) -> str:
"""獲取元素位置"""
# 簡化版本
return "unknown"
def _get_surrounding_text(self, element: Dict, radius: int = 100) -> str:
"""獲取周圍文本"""
# 收集前後文本
text_parts = []
# 父元素文本
parent = element.get('parent')
if parent:
parent_text = parent.get('textContent', '')
if parent_text:
text_parts.append(parent_text[:radius])
# 自身文本
self_text = element.get('textContent', '')
if self_text:
text_parts.append(self_text[:radius])
return ' '.join(text_parts)
def _get_semantic_context(self, element: Dict) -> List[str]:
"""獲取語義上下文"""
context = []
# 檢查ARIA角色
attributes = element.get('attributes', {})
if 'role' in attributes:
context.append(f"role: {attributes['role']}")
# 檢查父元素的語義標籤
parent = element.get('parent')
semantic_tags = ['main', 'header', 'footer', 'nav', 'article', 'section', 'aside']
for _ in range(3): # 檢查3層
if parent:
tag_name = parent.get('tagName', '').lower()
if tag_name in semantic_tags:
context.append(f"in {tag_name}")
break
parent = parent.get('parent')
return context
def _estimate_visual_importance(self, element: Dict) -> str:
"""估計視覺重要性"""
# 基於標籤類型和位置
tag_name = element.get('tagName', '').lower()
if tag_name in ['h1', 'h2', 'h3']:
return 'high'
elif tag_name in ['button', 'a', 'input']:
return 'medium'
elif tag_name in ['img', 'video']:
return 'medium'
else:
return 'low'
6. AI模型集成
6.1 深度學習模型用於圖像描述生成
python
import torch
import torch.nn as nn
import torchvision.models as models
from torchvision import transforms
from PIL import Image
import requests
from io import BytesIO
class ImageAltTextGenerator:
"""圖像替代文本生成器"""
def __init__(self, model_name: str = 'resnet50'):
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
self.model = self._load_model(model_name)
self.preprocess = self._get_preprocess()
self.vocab = self._load_vocab()
def _load_model(self, model_name: str) -> nn.Module:
"""載入預訓練模型"""
# 簡化版本,實際應該使用專門的圖像描述模型
if model_name == 'resnet50':
model = models.resnet50(pretrained=True)
# 修改最後一層用於分類
num_features = model.fc.in_features
model.fc = nn.Linear(num_features, 1000) # 1000個ImageNet類別
else:
raise ValueError(f"不支持的模型: {model_name}")
model = model.to(self.device)
model.eval()
return model
def _get_preprocess(self):
"""獲取預處理管道"""
return transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
])
def _load_vocab(self):
"""載入詞彙表"""
# 簡化版本,實際應該載入ImageNet標籤
return {
0: '飛機', 1: '汽車', 2: '鳥', 3: '貓', 4: '鹿',
5: '狗', 6: '青蛙', 7: '馬', 8: '船', 9: '卡車'
}
def generate_alt_text(self, image_url: str) -> str:
"""生成替代文本"""
try:
# 下載圖片
response = requests.get(image_url, timeout=10)
image = Image.open(BytesIO(response.content)).convert('RGB')
# 預處理
image_tensor = self.preprocess(image).unsqueeze(0).to(self.device)
# 預測
with torch.no_grad():
outputs = self.model(image_tensor)
_, predicted = torch.max(outputs, 1)
class_id = predicted.item()
# 生成描述
class_name = self.vocab.get(class_id % len(self.vocab), '物體')
# 分析圖片特徵
features = self._analyze_image_features(image)
# 組裝描述
description = self._assemble_description(class_name, features)
return description
except Exception as e:
print(f"生成替代文本時出錯: {e}")
return "圖片內容"
def _analyze_image_features(self, image: Image.Image) -> Dict[str, Any]:
"""分析圖片特徵"""
# 簡化版本,實際應該使用更複雜的特徵提取
features = {
'size': image.size,
'mode': image.mode,
'colors': self._extract_dominant_colors(image),
'brightness': self._calculate_brightness(image)
}
return features
def _extract_dominant_colors(self, image: Image.Image, num_colors: int = 3):
"""提取主要顏色"""
# 簡化版本
image_small = image.resize((50, 50))
colors = image_small.getcolors(2500)
if colors:
colors.sort(key=lambda x: x[0], reverse=True)
return [color[1] for color in colors[:num_colors]]
return []
def _calculate_brightness(self, image: Image.Image) -> float:
"""計算亮度"""
grayscale = image.convert('L')
histogram = grayscale.histogram()
pixels = sum(histogram)
brightness = sum(i * histogram[i] for i in range(256)) / pixels / 255.0
return brightness
def _assemble_description(self, class_name: str, features: Dict[str, Any]) -> str:
"""組裝描述"""
# 根據特徵豐富描述
brightness = features.get('brightness', 0.5)
colors = features.get('colors', [])
description_parts = [f"包含{class_name}的圖片"]
# 添加顏色描述
if colors:
color_desc = self._describe_colors(colors)
if color_desc:
description_parts.append(color_desc)
# 添加亮度描述
if brightness > 0.7:
description_parts.append("明亮的")
elif brightness < 0.3:
description_parts.append("暗色的")
return ",".join(description_parts)
def _describe_colors(self, colors) -> str:
"""描述顏色"""
if not colors:
return ""
# 簡化版本
color_names = []
for color in colors[:2]:
if isinstance(color, tuple):
r, g, b = color[:3]
# 基本顏色識別
if r > 200 and g < 100 and b < 100:
color_names.append("紅色")
elif r < 100 and g > 200 and b < 100:
color_names.append("綠色")
elif r < 100 and g < 100 and b > 200:
color_names.append("藍色")
elif r > 200 and g > 200 and b > 200:
color_names.append("白色")
elif r < 50 and g < 50 and b < 50:
color_names.append("黑色")
if color_names:
return f"主要顏色為{', '.join(color_names)}"
return ""
6.2 NLP用於文本分析
python
import spacy
from transformers import pipeline, AutoTokenizer, AutoModelForSequenceClassification
import numpy as np
class TextAnalyzer:
"""文本分析器"""
def __init__(self):
# 載入spacy模型
try:
self.nlp = spacy.load("zh_core_web_sm")
except:
# 如果沒有中文模型,使用英文模型
self.nlp = spacy.load("en_core_web_sm")
# 載入情感分析模型
self.sentiment_analyzer = pipeline(
"sentiment-analysis",
model="distilbert-base-uncased-finetuned-sst-2-english"
)
# 載入文本分類模型
self.text_classifier = None
self._load_text_classifier()
def _load_text_classifier(self):
"""載入文本分類模型"""
try:
self.text_classifier = pipeline(
"zero-shot-classification",
model="facebook/bart-large-mnli"
)
except:
print("無法載入文本分類模型")
def analyze_text_complexity(self, text: str) -> Dict[str, float]:
"""分析文本複雜度"""
doc = self.nlp(text)
# 基本統計
sentences = list(doc.sents)
words = [token.text for token in doc if not token.is_punct]
# 計算複雜度指標
avg_sentence_length = len(words) / len(sentences) if sentences else 0
unique_words = len(set(words))
lexical_diversity = unique_words / len(words) if words else 0
# 計算可讀性(簡化版本)
readability = self._calculate_readability(text)
# 情感分析
sentiment = self._analyze_sentiment(text)
return {
'char_count': len(text),
'word_count': len(words),
'sentence_count': len(sentences),
'avg_sentence_length': avg_sentence_length,
'lexical_diversity': lexical_diversity,
'readability_score': readability,
'sentiment': sentiment
}
def _calculate_readability(self, text: str) -> float:
"""計算可讀性分數"""
# 簡化版本,實際應該使用特定的可讀性公式
words = text.split()
sentences = text.replace('!', '.').replace('?', '.').split('.')
if len(words) == 0 or len(sentences) == 0:
return 0.5
avg_words_per_sentence = len(words) / len(sentences)
# 簡單的評分邏輯
if avg_words_per_sentence < 10:
return 0.9 # 易讀
elif avg_words_per_sentence < 20:
return 0.7 # 中等
elif avg_words_per_sentence < 30:
return 0.5 # 較難
else:
return 0.3 # 難
def _analyze_sentiment(self, text: str) -> Dict[str, float]:
"""分析情感"""
try:
# 如果文本太長,截斷
if len(text) > 500:
text = text[:500]
result = self.sentiment_analyzer(text)[0]
return {
'label': result['label'],
'score': result['score']
}
except:
return {'label': 'NEUTRAL', 'score': 0.5}
def classify_content_type(self, text: str, candidate_labels: List[str] = None) -> Dict:
"""分類內容類型"""
if not self.text_classifier:
return {}
if candidate_labels is None:
candidate_labels = [
"技術說明", "新聞報導", "產品描述",
"教學內容", "市場營銷", "個人博客"
]
try:
result = self.text_classifier(text, candidate_labels)
return {
'labels': result['labels'],
'scores': result['scores']
}
except:
return {}
def extract_key_phrases(self, text: str, num_phrases: int = 5) -> List[str]:
"""提取關鍵短語"""
doc = self.nlp(text)
# 提取名詞短語
phrases = []
for chunk in doc.noun_chunks:
if len(chunk.text.split()) >= 2: # 至少兩個詞
phrases.append(chunk.text)
# 按頻率排序
phrase_counts = {}
for phrase in phrases:
phrase_counts[phrase] = phrase_counts.get(phrase, 0) + 1
sorted_phrases = sorted(phrase_counts.items(), key=lambda x: x[1], reverse=True)
return [phrase for phrase, _ in sorted_phrases[:num_phrases]]
def suggest_simplification(self, text: str) -> Dict[str, Any]:
"""建議文本簡化"""
analysis = self.analyze_text_complexity(text)
suggestions = []
# 檢查句子長度
if analysis['avg_sentence_length'] > 20:
suggestions.append({
'type': 'sentence_length',
'description': '句子過長,建議拆分',
'example': self._split_long_sentences(text)
})
# 檢查詞彙多樣性
if analysis['lexical_diversity'] > 0.8:
suggestions.append({
'type': 'vocabulary',
'description': '詞彙變化較多,可能增加理解難度',
'suggestion': '考慮使用更常見的同義詞'
})
# 檢查可讀性
if analysis['readability_score'] < 0.5:
suggestions.append({
'type': 'readability',
'description': '文本可讀性較低',
'suggestion': '使用更簡單的詞彙和短句'
})
return {
'analysis': analysis,
'suggestions': suggestions,
'simplified_version': self._simplify_text(text)
}
def _split_long_sentences(self, text: str) -> str:
"""拆分長句"""
# 簡化版本
sentences = text.split('。')
simplified = []
for sentence in sentences:
if len(sentence) > 50:
# 簡單地在中間拆分
mid = len(sentence) // 2
simplified.append(sentence[:mid] + '。')
simplified.append(sentence[mid:] + '。')
else:
simplified.append(sentence + '。')
return ''.join(simplified)
def _simplify_text(self, text: str) -> str:
"""簡化文本"""
# 簡化版本,實際應該使用更複雜的算法
doc = self.nlp(text)
simplified_tokens = []
for token in doc:
# 嘗試簡化複雜詞彙
if len(token.text) > 8: # 長單詞
# 這裡可以添加詞彙替換邏輯
simplified_tokens.append(token.text)
else:
simplified_tokens.append(token.text)
return ''.join(simplified_tokens)
7. 完整代碼實現
7.1 主應用程序
python
import asyncio
import uvicorn
from fastapi import FastAPI, HTTPException, UploadFile, File
from fastapi.responses import HTMLResponse, JSONResponse
from fastapi.staticfiles import StaticFiles
from fastapi.templating import Jinja2Templates
from pydantic import BaseModel
from typing import Optional, List, Dict, Any
import json
import time
# 導入自定義模塊
from detection import AccessibilityDetector
from repair import IntelligentRepairSystem
from ai_models import ImageAltTextGenerator, TextAnalyzer
app = FastAPI(
title="可訪問性修復AI系統",
description="自動檢測和修復網頁無障礙問題的AI系統",
version="1.0.0"
)
# 掛載靜態文件
app.mount("/static", StaticFiles(directory="static"), name="static")
# 模板
templates = Jinja2Templates(directory="templates")
# 全局組件
detector = AccessibilityDetector()
repair_system = IntelligentRepairSystem()
image_analyzer = ImageAltTextGenerator()
text_analyzer = TextAnalyzer()
class ScanRequest(BaseModel):
url: Optional[str] = None
html: Optional[str] = None
scan_type: str = "full" # full, quick, custom
class FixRequest(BaseModel):
html: str
issues: List[Dict[str, Any]]
fix_strategy: str = "auto" # auto, manual, hybrid
class BatchRequest(BaseModel):
items: List[Dict[str, str]] # [{url: "...", html: "..."}]
@app.get("/", response_class=HTMLResponse)
async def home():
"""主頁"""
return """
<html>
<head>
<title>可訪問性修復AI系統</title>
<style>
body { font-family: Arial, sans-serif; margin: 40px; }
.container { max-width: 800px; margin: auto; }
.card { border: 1px solid #ddd; padding: 20px; margin: 20px 0; border-radius: 5px; }
button { background: #4CAF50; color: white; padding: 10px 20px; border: none; border-radius: 4px; cursor: pointer; }
input, textarea { width: 100%; padding: 10px; margin: 10px 0; }
</style>
</head>
<body>
<div class="container">
<h1>可訪問性修復AI系統</h1>
<div class="card">
<h2>單頁掃描</h2>
<form action="/scan" method="post">
<input type="url" name="url" placeholder="輸入URL">
<textarea name="html" placeholder="或直接貼上HTML" rows="10"></textarea>
<button type="submit">開始掃描</button>
</form>
</div>
<div class="card">
<h2>批量處理</h2>
<button onclick="location.href='/batch'">批量掃描</button>
</div>
<div class="card">
<h2>API文檔</h2>
<p>查看完整的API文檔:<a href="/docs">/docs</a></p>
</div>
</div>
</body>
</html>
"""
@app.post("/scan")
async def scan_website(request: ScanRequest):
"""掃描網站"""
try:
start_time = time.time()
if request.url:
# 掃描URL
result = await detector.scan_url(request.url)
elif request.html:
# 掃描HTML
result = await detector.scan_html(request.html)
else:
raise HTTPException(status_code=400, detail="必須提供URL或HTML")
# 計算執行時間
result['execution_time'] = time.time() - start_time
return JSONResponse(content=result)
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
@app.post("/fix")
async def fix_issues(request: FixRequest):
"""修復問題"""
try:
# 將字典轉換為AccessibilityIssue對象
issues = []
for issue_dict in request.issues:
# 這裡需要實際的轉換邏輯
pass
# 根據策略修復
if request.fix_strategy == "auto":
result = repair_system.analyze_and_fix(request.html, issues)
elif request.fix_strategy == "manual":
# 手動修復模式
result = {
"html": request.html,
"suggestions": issues,
"mode": "manual"
}
else: # hybrid
# 混合模式
result = repair_system.analyze_and_fix(request.html, issues)
return JSONResponse(content=result)
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
@app.post("/batch")
async def batch_process(request: BatchRequest):
"""批量處理"""
results = []
for item in request.items:
try:
if 'url' in item:
result = await detector.scan_url(item['url'])
results.append({
'url': item['url'],
'success': True,
'result': result
})
elif 'html' in item:
result = await detector.scan_html(item['html'])
results.append({
'id': item.get('id', 'unknown'),
'success': True,
'result': result
})
except Exception as e:
results.append({
'url': item.get('url', item.get('id', 'unknown')),
'success': False,
'error': str(e)
})
# 生成統計
total = len(results)
success = sum(1 for r in results if r['success'])
summary = {
'total': total,
'success': success,
'failed': total - success,
'success_rate': success / total if total > 0 else 0
}
return JSONResponse(content={
'summary': summary,
'results': results
})
@app.post("/analyze/image")
async def analyze_image(image_url: str):
"""分析圖片並生成描述"""
try:
alt_text = image_analyzer.generate_alt_text(image_url)
return JSONResponse(content={
'image_url': image_url,
'alt_text': alt_text,
'status': 'success'
})
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
@app.post("/analyze/text")
async def analyze_text(text: str):
"""分析文本"""
try:
complexity = text_analyzer.analyze_text_complexity(text)
key_phrases = text_analyzer.extract_key_phrases(text)
simplification = text_analyzer.suggest_simplification(text)
return JSONResponse(content={
'text': text[:500] + "..." if len(text) > 500 else text,
'complexity_analysis': complexity,
'key_phrases': key_phrases,
'simplification_suggestions': simplification
})
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
@app.get("/report/{report_id}")
async def get_report(report_id: str, format: str = 'html'):
"""獲取報告"""
# 這裡應該從數據庫中獲取報告
# 簡化版本
sample_report = {
'id': report_id,
'title': '示例報告',
'date': '2024-01-01',
'summary': '這是示例報告'
}
if format == 'html':
return HTMLResponse(content=f"""
<html>
<body>
<h1>報告: {sample_report['title']}</h1>
<p>ID: {sample_report['id']}</p>
<p>日期: {sample_report['date']}</p>
<p>{sample_report['summary']}</p>
</body>
</html>
""")
else:
return JSONResponse(content=sample_report)
@app.get("/health")
async def health_check():
"""健康檢查"""
return {"status": "healthy", "timestamp": time.time()}
if __name__ == "__main__":
uvicorn.run(
app,
host="0.0.0.0",
port=8000,
reload=True
)
7.2 前端界面
html
<!DOCTYPE html>
<html lang="zh-TW">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>可訪問性修復AI - 控制台</title>
<style>
:root {
--primary-color: #4CAF50;
--secondary-color: #2196F3;
--danger-color: #f44336;
--warning-color: #ff9800;
--light-bg: #f5f5f5;
--dark-bg: #333;
--text-color: #333;
--text-light: #666;
}
* {
margin: 0;
padding: 0;
box-sizing: border-box;
}
body {
font-family: -apple-system, BlinkMacSystemFont, 'Segoe UI', Roboto, Oxygen, Ubuntu, sans-serif;
line-height: 1.6;
color: var(--text-color);
background-color: #f9f9f9;
}
.container {
max-width: 1200px;
margin: 0 auto;
padding: 20px;
}
header {
background: linear-gradient(135deg, var(--primary-color), var(--secondary-color));
color: white;
padding: 2rem 0;
text-align: center;
margin-bottom: 2rem;
border-radius: 0 0 10px 10px;
}
.logo {
font-size: 2.5rem;
margin-bottom: 1rem;
}
.tagline {
font-size: 1.2rem;
opacity: 0.9;
}
.main-content {
display: grid;
grid-template-columns: 1fr 2fr;
gap: 2rem;
}
.sidebar {
background: white;
padding: 1.5rem;
border-radius: 8px;
box-shadow: 0 2px 10px rgba(0,0,0,0.1);
}
.content-area {
background: white;
padding: 1.5rem;
border-radius: 8px;
box-shadow: 0 2px 10px rgba(0,0,0,0.1);
}
.tabs {
display: flex;
border-bottom: 2px solid var(--light-bg);
margin-bottom: 1.5rem;
}
.tab {
padding: 0.75rem 1.5rem;
cursor: pointer;
border-bottom: 3px solid transparent;
transition: all 0.3s;
}
.tab.active {
border-bottom-color: var(--primary-color);
color: var(--primary-color);
font-weight: bold;
}
.form-group {
margin-bottom: 1.5rem;
}
label {
display: block;
margin-bottom: 0.5rem;
font-weight: 600;
}
input, textarea, select {
width: 100%;
padding: 0.75rem;
border: 1px solid #ddd;
border-radius: 4px;
font-size: 1rem;
}
textarea {
min-height: 200px;
font-family: monospace;
}
.btn {
background: var(--primary-color);
color: white;
padding: 0.75rem 1.5rem;
border: none;
border-radius: 4px;
cursor: pointer;
font-size: 1rem;
transition: background 0.3s;
}
.btn:hover {
background: #3d8b40;
}
.btn-secondary {
background: var(--secondary-color);
}
.btn-secondary:hover {
background: #0d8bf2;
}
.btn-danger {
background: var(--danger-color);
}
.result-area {
margin-top: 2rem;
}
.issue-card {
border: 1px solid #ddd;
border-left: 4px solid var(--warning-color);
padding: 1rem;
margin-bottom: 1rem;
border-radius: 4px;
background: #fff9e6;
}
.issue-card.critical {
border-left-color: var(--danger-color);
background: #ffebee;
}
.issue-card.high {
border-left-color: var(--warning-color);
background: #fff3e0;
}
.severity-badge {
display: inline-block;
padding: 0.25rem 0.5rem;
border-radius: 3px;
font-size: 0.8rem;
font-weight: bold;
margin-right: 0.5rem;
}
.severity-critical {
background: var(--danger-color);
color: white;
}
.severity-high {
background: var(--warning-color);
color: white;
}
.severity-medium {
background: #ffc107;
color: black;
}
.stats-grid {
display: grid;
grid-template-columns: repeat(auto-fit, minmax(150px, 1fr));
gap: 1rem;
margin-bottom: 2rem;
}
.stat-card {
background: white;
padding: 1.5rem;
border-radius: 8px;
text-align: center;
box-shadow: 0 2px 5px rgba(0,0,0,0.1);
}
.stat-value {
font-size: 2rem;
font-weight: bold;
color: var(--primary-color);
}
.stat-label {
color: var(--text-light);
font-size: 0.9rem;
}
.loading {
display: none;
text-align: center;
padding: 2rem;
}
.spinner {
border: 4px solid #f3f3f3;
border-top: 4px solid var(--primary-color);
border-radius: 50%;
width: 40px;
height: 40px;
animation: spin 1s linear infinite;
margin: 0 auto 1rem;
}
@keyframes spin {
0% { transform: rotate(0deg); }
100% { transform: rotate(360deg); }
}
@media (max-width: 768px) {
.main-content {
grid-template-columns: 1fr;
}
}
</style>
</head>
<body>
<header>
<div class="container">
<div class="logo">♿ AI可訪問性修復</div>
<div class="tagline">自動檢測和修復網頁無障礙問題</div>
</div>
</header>
<div class="container">
<div class="main-content">
<div class="sidebar">
<h2>掃描選項</h2>
<div class="form-group">
<label for="scanType">掃描類型</label>
<select id="scanType">
<option value="full">完整掃描</option>
<option value="quick">快速掃描</option>
<option value="custom">自定義掃描</option>
</select>
</div>
<div class="form-group">
<label for="urlInput">網址 (URL)</label>
<input type="url" id="urlInput" placeholder="https://example.com">
</div>
<div class="form-group">
<label>或直接輸入HTML</label>
<textarea id="htmlInput" placeholder="<html>...</html>"></textarea>
</div>
<button class="btn" onclick="startScan()">開始掃描</button>
<button class="btn btn-secondary" onclick="clearForm()">清除</button>
<div class="form-group" style="margin-top: 2rem;">
<h3>批量處理</h3>
<input type="file" id="batchFile" accept=".txt,.json,.csv">
<button class="btn" onclick="processBatch()" style="margin-top: 1rem;">處理批量文件</button>
</div>
</div>
<div class="content-area">
<div class="tabs">
<div class="tab active" onclick="switchTab('results')">掃描結果</div>
<div class="tab" onclick="switchTab('fixes')">修復建議</div>
<div class="tab" onclick="switchTab('reports')">報告</div>
<div class="tab" onclick="switchTab('settings')">設置</div>
</div>
<div id="resultsTab" class="tab-content">
<div class="loading" id="loading">
<div class="spinner"></div>
<p>正在掃描中,請稍候...</p>
</div>
<div id="resultsContent">
<div class="stats-grid" id="statsGrid">
<!-- 統計數據會動態填充 -->
</div>
<div id="issuesList">
<!-- 問題列表會動態填充 -->
</div>
</div>
</div>
<div id="fixesTab" class="tab-content" style="display: none;">
<h3>自動修復</h3>
<button class="btn" onclick="applyFixes()">應用自動修復</button>
<button class="btn btn-secondary" onclick="generateReport()">生成修復報告</button>
<div id="fixResults" style="margin-top: 2rem;"></div>
</div>
<div id="reportsTab" class="tab-content" style="display: none;">
<h3>歷史報告</h3>
<div id="reportsList"></div>
</div>
<div id="settingsTab" class="tab-content" style="display: none;">
<h3>系統設置</h3>
<div class="form-group">
<label>API端點</label>
<input type="text" id="apiEndpoint" value="http://localhost:8000">
</div>
<div class="form-group">
<label>語言</label>
<select id="language">
<option value="zh-TW">繁體中文</option>
<option value="en">English</option>
</select>
</div>
<button class="btn" onclick="saveSettings()">保存設置</button>
</div>
</div>
</div>
</div>
<script>
let currentScanResults = null;
function switchTab(tabName) {
// 隱藏所有標籤頁
document.querySelectorAll('.tab-content').forEach(el => {
el.style.display = 'none';
});
// 移除所有活動標籤
document.querySelectorAll('.tab').forEach(el => {
el.classList.remove('active');
});
// 顯示目標標籤頁
document.getElementById(tabName + 'Tab').style.display = 'block';
// 激活對應標籤
document.querySelectorAll('.tab').forEach(el => {
if (el.textContent.includes(getTabDisplayName(tabName))) {
el.classList.add('active');
}
});
}
function getTabDisplayName(tabName) {
const names = {
'results': '掃描結果',
'fixes': '修復建議',
'reports': '報告',
'settings': '設置'
};
return names[tabName] || tabName;
}
async function startScan() {
const url = document.getElementById('urlInput').value;
const html = document.getElementById('htmlInput').value;
const scanType = document.getElementById('scanType').value;
if (!url && !html) {
alert('請輸入URL或HTML內容');
return;
}
// 顯示加載動畫
document.getElementById('loading').style.display = 'block';
document.getElementById('resultsContent').style.display = 'none';
try {
const response = await fetch('/scan', {
method: 'POST',
headers: {
'Content-Type': 'application/json'
},
body: JSON.stringify({
url: url || null,
html: html || null,
scan_type: scanType
})
});
const data = await response.json();
currentScanResults = data;
// 顯示結果
displayResults(data);
// 切換到結果標籤頁
switchTab('results');
} catch (error) {
alert('掃描失敗: ' + error.message);
} finally {
document.getElementById('loading').style.display = 'none';
document.getElementById('resultsContent').style.display = 'block';
}
}
function displayResults(data) {
// 更新統計數據
const stats = data.severity_counts || {};
const statsGrid = document.getElementById('statsGrid');
statsGrid.innerHTML = `
<div class="stat-card">
<div class="stat-value">${data.total_issues || 0}</div>
<div class="stat-label">總問題數</div>
</div>
<div class="stat-card">
<div class="stat-value">${stats.critical || 0}</div>
<div class="stat-label">嚴重問題</div>
</div>
<div class="stat-card">
<div class="stat-value">${stats.high || 0}</div>
<div class="stat-label">高級問題</div>
</div>
<div class="stat-card">
<div class="stat-value">${stats.medium || 0}</div>
<div class="stat-label">中級問題</div>
</div>
`;
// 顯示問題列表
const issuesList = document.getElementById('issuesList');
if (data.issues && data.issues.length > 0) {
let issuesHTML = '<h3>發現的問題</h3>';
data.issues.forEach(issue => {
const severityClass = `severity-${issue.severity}`;
const severityText = {
'critical': '嚴重',
'high': '高',
'medium': '中',
'low': '低',
'info': '信息'
}[issue.severity] || issue.severity;
issuesHTML += `
<div class="issue-card ${issue.severity}">
<div>
<span class="severity-badge ${severityClass}">${severityText}</span>
<strong>${issue.description}</strong>
</div>
<p style="margin-top: 0.5rem; color: var(--text-light);">
元素: ${issue.element?.tagName || '未知'}
</p>
${issue.help_url ? `<p><a href="${issue.help_url}" target="_blank">查看幫助文檔</a></p>` : ''}
</div>
`;
});
issuesList.innerHTML = issuesHTML;
} else {
issuesList.innerHTML = '<div class="issue-card"><p>🎉 未發現可訪問性問題!</p></div>';
}
}
async function applyFixes() {
if (!currentScanResults || !currentScanResults.issues || currentScanResults.issues.length === 0) {
alert('沒有發現需要修復的問題');
return;
}
const html = document.getElementById('htmlInput').value || '';
if (!html && !currentScanResults.source) {
alert('無法獲取原始HTML內容');
return;
}
try {
const response = await fetch('/fix', {
method: 'POST',
headers: {
'Content-Type': 'application/json'
},
body: JSON.stringify({
html: html,
issues: currentScanResults.issues,
fix_strategy: 'auto'
})
});
const data = await response.json();
// 顯示修復結果
const fixResults = document.getElementById('fixResults');
fixResults.innerHTML = `
<div class="issue-card">
<h4>修復完成</h4>
<p>成功修復 ${data.summary?.auto_fixed || 0} 個問題</p>
<p>修復率: ${(data.summary?.improvement_rate * 100 || 0).toFixed(1)}%</p>
<button class="btn" onclick="downloadFixedHTML()">下載修復後的HTML</button>
</div>
`;
// 保存修復後的HTML
sessionStorage.setItem('fixedHTML', data.fix_details?.fixed_html || '');
} catch (error) {
alert('修復失敗: ' + error.message);
}
}
function downloadFixedHTML() {
const fixedHTML = sessionStorage.getItem('fixedHTML');
if (!fixedHTML) {
alert('沒有可下載的修復後HTML');
return;
}
const blob = new Blob([fixedHTML], { type: 'text/html' });
const url = URL.createObjectURL(blob);
const a = document.createElement('a');
a.href = url;
a.download = 'fixed-accessibility.html';
document.body.appendChild(a);
a.click();
document.body.removeChild(a);
URL.revokeObjectURL(url);
}
function clearForm() {
document.getElementById('urlInput').value = '';
document.getElementById('htmlInput').value = '';
}
function saveSettings() {
const endpoint = document.getElementById('apiEndpoint').value;
const language = document.getElementById('language').value;
localStorage.setItem('apiEndpoint', endpoint);
localStorage.setItem('language', language);
alert('設置已保存');
}
function loadSettings() {
const endpoint = localStorage.getItem('apiEndpoint') || 'http://localhost:8000';
const language = localStorage.getItem('language') || 'zh-TW';
document.getElementById('apiEndpoint').value = endpoint;
document.getElementById('language').value = language;
}
// 頁面加載時運行
window.onload = function() {
loadSettings();
};
</script>
</body>
</html>
8. 部署與優化
8.1 Docker部署配置
dockerfile
# Dockerfile
FROM python:3.9-slim
WORKDIR /app
# 安裝系統依賴
RUN apt-get update && apt-get install -y \
gcc \
g++ \
curl \
&& rm -rf /var/lib/apt/lists/*
# 複製依賴文件
COPY requirements.txt .
# 安裝Python依賴
RUN pip install --no-cache-dir -r requirements.txt
# 複製應用代碼
COPY . .
# 創建非root用戶
RUN useradd -m -u 1000 appuser && chown -R appuser:appuser /app
USER appuser
# 暴露端口
EXPOSE 8000
# 啟動命令
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8000"]
yaml
# docker-compose.yml
version: '3.8'
services:
web:
build: .
ports:
- "8000:8000"
environment:
- DATABASE_URL=postgresql://user:password@db:5432/accessibility
- REDIS_URL=redis://redis:6379/0
- MODEL_PATH=/app/models
volumes:
- ./models:/app/models
- ./data:/app/data
depends_on:
- db
- redis
restart: unless-stopped
db:
image: postgres:14
environment:
- POSTGRES_USER=user
- POSTGRES_PASSWORD=password
- POSTGRES_DB=accessibility
volumes:
- postgres_data:/var/lib/postgresql/data
restart: unless-stopped
redis:
image: redis:7-alpine
volumes:
- redis_data:/data
restart: unless-stopped
nginx:
image: nginx:alpine
ports:
- "80:80"
- "443:443"
volumes:
- ./nginx.conf:/etc/nginx/nginx.conf
- ./ssl:/etc/nginx/ssl
depends_on:
- web
restart: unless-stopped
volumes:
postgres_data:
redis_data:
8.2 性能優化配置
python
# config/optimization.py
import logging
from functools import lru_cache
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor
import redis
from redis import Redis
import json
class PerformanceOptimizer:
"""性能優化器"""
def __init__(self, config):
self.config = config
self.redis_client = self._init_redis()
self.cache_enabled = config.get('cache_enabled', True)
self.parallel_enabled = config.get('parallel_enabled', True)
# 線程池和進程池
self.thread_pool = ThreadPoolExecutor(
max_workers=config.get('max_threads', 4)
)
self.process_pool = ProcessPoolExecutor(
max_workers=config.get('max_processes', 2)
)
# 統計數據
self.stats = {
'cache_hits': 0,
'cache_misses': 0,
'requests_processed': 0,
'avg_processing_time': 0
}
def _init_redis(self):
"""初始化Redis連接"""
try:
return Redis(
host=self.config.get('redis_host', 'localhost'),
port=self.config.get('redis_port', 6379),
db=self.config.get('redis_db', 0),
decode_responses=True
)
except:
logging.warning("Redis連接失敗,使用內存緩存")
return None
@lru_cache(maxsize=1000)
def cached_detection(self, html_hash: str, rules_hash: str):
"""緩存檢測結果"""
if not self.cache_enabled or not self.redis_client:
return None
cache_key = f"detection:{html_hash}:{rules_hash}"
cached = self.redis_client.get(cache_key)
if cached:
self.stats['cache_hits'] += 1
return json.loads(cached)
self.stats['cache_misses'] += 1
return None
def cache_detection_result(self, html_hash: str, rules_hash: str, result: dict):
"""緩存檢測結果"""
if not self.cache_enabled or not self.redis_client:
return
cache_key = f"detection:{html_hash}:{rules_hash}"
# 設置緩存,有效期1小時
self.redis_client.setex(
cache_key,
3600,
json.dumps(result)
)
def parallel_scan(self, html_list: list, rules_list: list):
"""並行掃描"""
if not self.parallel_enabled:
return [self._scan_single(html, rules) for html, rules in zip(html_list, rules_list)]
# 使用線程池並行處理
futures = []
for html, rules in zip(html_list, rules_list):
future = self.thread_pool.submit(self._scan_single, html, rules)
futures.append(future)
# 收集結果
results = [future.result() for future in futures]
return results
def _scan_single(self, html: str, rules: dict):
"""單個掃描任務"""
# 這裡調用實際的掃描邏輯
pass
def batch_process_with_chunking(self, items: list, chunk_size: int = 10):
"""分批處理"""
results = []
for i in range(0, len(items), chunk_size):
chunk = items[i:i + chunk_size]
chunk_results = self.parallel_scan(chunk)
results.extend(chunk_results)
# 更新進度
progress = min(100, int((i + len(chunk)) / len(items) * 100))
self._update_progress(progress)
return results
def _update_progress(self, progress: int):
"""更新進度"""
# 可以發送到WebSocket或更新數據庫
pass
def get_performance_stats(self):
"""獲取性能統計"""
return self.stats
def optimize_memory_usage(self):
"""優化內存使用"""
import gc
# 強制垃圾回收
gc.collect()
# 清理緩存
if hasattr(self, '_cache'):
self._cache.clear()
# 清理LRU緩存
self.cached_detection.cache_clear()
def monitor_resources(self):
"""監控資源使用"""
import psutil
import os
process = psutil.Process(os.getpid())
return {
'cpu_percent': process.cpu_percent(),
'memory_mb': process.memory_info().rss / 1024 / 1024,
'threads': process.num_threads(),
'open_files': len(process.open_files())
}
# 配置示例
optimization_config = {
'cache_enabled': True,
'parallel_enabled': True,
'max_threads': 8,
'max_processes': 2,
'redis_host': 'localhost',
'redis_port': 6379,
'redis_db': 0,
'chunk_size': 20,
'cache_ttl': 3600
}
8.3 監控與日誌
python
# config/logging_config.py
import logging
import logging.handlers
import json
from datetime import datetime
import sys
import traceback
class JSONFormatter(logging.Formatter):
"""JSON格式的日誌格式化器"""
def format(self, record):
log_object = {
'timestamp': datetime.utcnow().isoformat() + 'Z',
'level': record.levelname,
'logger': record.name,
'message': record.getMessage(),
'module': record.module,
'function': record.funcName,
'line': record.lineno,
'thread': record.threadName,
'process': record.processName
}
if record.exc_info:
log_object['exception'] = {
'type': record.exc_info[0].__name__,
'message': str(record.exc_info[1]),
'stack_trace': traceback.format_exception(*record.exc_info)
}
if hasattr(record, 'custom_fields'):
log_object.update(record.custom_fields)
return json.dumps(log_object, ensure_ascii=False)
class AccessibilityLogger:
"""可訪問性系統專用日誌器"""
def __init__(self, name='accessibility_system', log_level=logging.INFO):
self.logger = logging.getLogger(name)
self.logger.setLevel(log_level)
# 避免日誌重複
if not self.logger.handlers:
self._setup_handlers()
def _setup_handlers(self):
"""設置日誌處理器"""
# 控制台處理器
console_handler = logging.StreamHandler(sys.stdout)
console_handler.setLevel(logging.INFO)
console_formatter = logging.Formatter(
'%(asctime)s - %(name)s - %(levelname)s - %(message)s'
)
console_handler.setFormatter(console_formatter)
# 文件處理器(JSON格式)
file_handler = logging.handlers.RotatingFileHandler(
'logs/accessibility_system.log',
maxBytes=10485760, # 10MB
backupCount=10
)
file_handler.setLevel(logging.DEBUG)
json_formatter = JSONFormatter()
file_handler.setFormatter(json_formatter)
# 錯誤文件處理器
error_handler = logging.handlers.RotatingFileHandler(
'logs/errors.log',
maxBytes=10485760,
backupCount=5
)
error_handler.setLevel(logging.ERROR)
error_handler.setFormatter(json_formatter)
# 添加處理器
self.logger.addHandler(console_handler)
self.logger.addHandler(file_handler)
self.logger.addHandler(error_handler)
def log_scan_start(self, url=None, html_length=None, scan_type='full'):
"""記錄掃描開始"""
self.logger.info(
'掃描開始',
extra={
'custom_fields': {
'event': 'scan_start',
'url': url,
'html_length': html_length,
'scan_type': scan_type
}
}
)
def log_scan_complete(self, issues_found, scan_time, url=None):
"""記錄掃描完成"""
self.logger.info(
f'掃描完成,發現 {issues_found} 個問題',
extra={
'custom_fields': {
'event': 'scan_complete',
'issues_found': issues_found,
'scan_time_seconds': scan_time,
'url': url
}
}
)
def log_fix_applied(self, issue_type, fix_strategy, success=True, details=None):
"""記錄修復應用"""
self.logger.info(
f'修復應用: {issue_type}',
extra={
'custom_fields': {
'event': 'fix_applied',
'issue_type': issue_type,
'fix_strategy': fix_strategy,
'success': success,
'details': details
}
}
)
def log_performance(self, operation, duration, resource_usage=None):
"""記錄性能數據"""
self.logger.debug(
f'性能數據: {operation}',
extra={
'custom_fields': {
'event': 'performance',
'operation': operation,
'duration_seconds': duration,
'resource_usage': resource_usage
}
}
)
def log_error(self, error_type, error_message, context=None):
"""記錄錯誤"""
self.logger.error(
f'錯誤: {error_type}',
extra={
'custom_fields': {
'event': 'error',
'error_type': error_type,
'error_message': error_message,
'context': context
}
}
)
def get_logger(self):
"""獲取底層logger對象"""
return self.logger
# 監控中間件
class MonitoringMiddleware:
"""監控中間件"""
def __init__(self, app):
self.app = app
self.logger = AccessibilityLogger('monitoring')
async def __call__(self, scope, receive, send):
start_time = datetime.now()
# 記錄請求開始
if scope['type'] == 'http':
self.logger.logger.info(
f"請求開始: {scope['path']}",
extra={
'custom_fields': {
'event': 'request_start',
'path': scope['path'],
'method': scope['method']
}
}
)
# 處理請求
try:
await self.app(scope, receive, send)
except Exception as e:
# 記錄異常
self.logger.log_error(
'request_error',
str(e),
{'path': scope.get('path', 'unknown')}
)
raise
finally:
# 記錄請求完成
if scope['type'] == 'http':
duration = (datetime.now() - start_time).total_seconds()
self.logger.log_performance(
f"request:{scope['path']}",
duration
)
9. 案例研究
9.1 案例一:電商網站修復
python
"""
案例:大型電商網站可訪問性修復
問題:商品圖片缺少alt文本,價格顏色對比度不足,表單無標籤
"""
case_study_ecommerce = {
"website": "https://example-shop.com",
"issues_before": {
"missing_alt_text": 245,
"low_contrast": 89,
"missing_form_labels": 34,
"keyboard_navigation": 12,
"semantic_structure": 56
},
"scan_time": "45秒",
"ai_fixes_applied": {
"alt_text_generated": 245,
"contrast_adjusted": 89,
"form_labels_added": 34,
"keyboard_traps_fixed": 8
},
"improvement_metrics": {
"wcag_compliance": "從45%提升到92%",
"screen_reader_compatibility": "改善78%",
"keyboard_navigation_score": "從3/10提升到9/10",
"performance_impact": "頁面加載時間增加0.2秒"
},
"business_impact": {
"potential_users_reached": "+15%殘障用戶",
"seo_improvement": "搜索排名提升",
"legal_risk_reduction": "避免ADA訴訟風險",
"conversion_rate": "提高2.3%"
}
}
9.2 案例二:政府網站改造
python
"""
案例:政府服務網站無障礙改造
挑戰:複雜表單、法律文檔、多語言支持
"""
case_study_government = {
"website": "https://gov-services.example.gov",
"special_requirements": [
"WCAG 2.1 AA合規性",
"Section 508合規性",
"多語言支持(繁體中文、英文、手語)",
"高對比度模式",
"屏幕閱讀器優化"
],
"ai_capabilities_used": [
"自動文檔結構分析",
"複雜表單標籤生成",
"法律術語解釋生成",
"多語言alt文本生成",
"ARIA屬性智能添加"
],
"results": {
"automated_fixes": "78%問題自動修復",
"manual_review_needed": "22%需要人工確認",
"compliance_certification": "獲得無障礙認證",
"user_feedback": "殘障用戶滿意度從2.5/5提升到4.7/5"
},
"lessons_learned": [
"AI對結構化內容修復效果最佳",
"法律文檔需要專業知識庫",
"用戶測試仍然是必要環節",
"持續監測比一次修復更重要"
]
}
9.3 性能基準測試
python
class BenchmarkTest:
"""性能基準測試"""
@staticmethod
def run_comprehensive_benchmark():
"""運行綜合基準測試"""
test_cases = [
{
"name": "簡單頁面(10個元素)",
"html": "<html><body><h1>標題</h1><p>段落</p><img src='test.jpg'></body></html>",
"expected_time": "< 1秒"
},
{
"name": "中等頁面(100個元素)",
"html": "<html><body>" + "<div><p>段落</p><img src='test.jpg'></div>" * 20 + "</body></html>",
"expected_time": "2-3秒"
},
{
"name": "複雜頁面(1000個元素)",
"html": "<html><body>" + "<div><p>段落</p><img src='test.jpg'><form><input><button></form></div>" * 100 + "</body></html>",
"expected_time": "10-15秒"
}
]
results = []
detector = AccessibilityDetector()
for test in test_cases:
start_time = time.time()
# 運行檢測
loop = asyncio.new_event_loop()
asyncio.set_event_loop(loop)
result = loop.run_until_complete(detector.scan_html(test["html"]))
loop.close()
end_time = time.time()
duration = end_time - start_time
results.append({
"test_case": test["name"],
"elements_scanned": len(result.get('issues', [])),
"execution_time": f"{duration:.2f}秒",
"within_expected": duration < float(test["expected_time"].split('-')[0]) if '-' in test["expected_time"] else True
})
return results
@staticmethod
def accuracy_benchmark():
"""準確度基準測試"""
# 使用已知的測試數據集
test_dataset = [
{
"html": "<img src='product.jpg'>",
"expected_issues": ["missing_alt_text"],
"expected_fix": "添加alt屬性"
},
{
"html": "<div style='color: #888; background: #eee;'>文本</div>",
"expected_issues": ["low_contrast"],
"expected_fix": "調整顏色對比度"
},
{
"html": "<input type='text' name='username'>",
"expected_issues": ["missing_form_label"],
"expected_fix": "添加label標籤"
}
]
accuracy_results = []
detector = AccessibilityDetector()
repair_engine = RepairEngine()
for test in test_dataset:
issues_found = []
# 檢測
loop = asyncio.new_event_loop()
asyncio.set_event_loop(loop)
result = loop.run_until_complete(detector.scan_html(test["html"]))
loop.close()
for issue in result.get('issues', []):
issues_found.append(issue.type)
# 計算準確度
true_positives = len(set(issues_found) & set(test["expected_issues"]))
false_positives = len(set(issues_found) - set(test["expected_issues"]))
false_negatives = len(set(test["expected_issues"]) - set(issues_found))
precision = true_positives / (true_positives + false_positives) if (true_positives + false_positives) > 0 else 0
recall = true_positives / (true_positives + false_negatives) if (true_positives + false_negatives) > 0 else 0
f1_score = 2 * (precision * recall) / (precision + recall) if (precision + recall) > 0 else 0
accuracy_results.append({
"test_case": test["html"][:50] + "...",
"issues_found": issues_found,
"expected_issues": test["expected_issues"],
"precision": precision,
"recall": recall,
"f1_score": f1_score
})
# 計算平均分數
avg_precision = sum(r["precision"] for r in accuracy_results) / len(accuracy_results)
avg_recall = sum(r["recall"] for r in accuracy_results) / len(accuracy_results)
avg_f1 = sum(r["f1_score"] for r in accuracy_results) / len(accuracy_results)
return {
"detailed_results": accuracy_results,
"average_scores": {
"precision": avg_precision,
"recall": avg_recall,
"f1_score": avg_f1
}
}
10. 未來展望
10.1 技術發展方向
-
深度學習增強
-
使用Transformer模型理解頁面語義
-
計算機視覺改進圖像描述
-
強化學習優化修復策略
-
-
實時修復能力
-
瀏覽器插件實時檢測
-
CDN層級自動修復
-
邊緣計算加速
-
-
個性化無障礙
-
適應用戶特定需求
-
學習用戶行為模式
-
自適應界面調整
-
10.2 生態系統擴展
-
開發者工具集成
-
VS Code擴展
-
CI/CD管道整合
-
設計工具插件
-
-
標準化與協議
-
開源檢測規則
-
統一修復API
-
行業標準制定
-
-
多平台支持
-
移動應用無障礙
-
PDF文檔修復
-
視頻內容處理
-
10.3 社會影響
-
數字包容性
-
縮小數字鴻溝
-
提升殘障人士就業機會
-
促進社會平等
-
-
經濟效益
-
降低合規成本
-
擴大市場覆蓋
-
提升品牌形象
-
-
教育與培訓
-
開發者無障礙教育
-
AI輔助設計培訓
-
社區知識共享
-
10.4 開源路線圖
python
"""
開源項目發展規劃
"""
roadmap = {
"phase_1": {
"timeline": "2024 Q1-Q2",
"goals": [
"核心檢測引擎穩定版",
"基本修復功能",
"RESTful API",
"基礎文檔"
],
"milestones": [
"GitHub開源發布",
"首個生產環境部署",
"社區貢獻者達到100人"
]
},
"phase_2": {
"timeline": "2024 Q3-Q4",
"goals": [
"AI模型集成",
"瀏覽器擴展",
"CI/CD集成",
"企業級功能"
],
"milestones": [
"達到1000星標",
"建立治理委員會",
"發布企業版本"
]
},
"phase_3": {
"timeline": "2025",
"goals": [
"多語言支持",
"實時協作",
"預測分析",
"生態系統建設"
],
"milestones": [
"成為W3C推薦工具",
"建立認證體系",
"全球部署案例"
]
}
}
結論
本文詳細介紹了如何構建一個完整的可訪問性修復AI系統。從基礎理論到實現代碼,我們涵蓋了:
-
系統架構設計:模塊化、可擴展的架構
-
檢測引擎實現:基於規則的智能檢測
-
修復引擎實現:多策略自動修復
-
AI集成:深度學習增強功能
-
完整實現:前後端完整代碼
-
部署優化:生產環境最佳實踐
-
案例研究:實際應用場景
-
未來展望:技術發展方向
這個系統不僅能自動檢測和修復無障礙問題,還能通過AI學習不斷改進修復策略。通過開源這個項目,我們希望:
-
降低網站無障礙化的技術門檻
-
推動AI在數字包容性領域的應用
-
建立一個活躍的開發者社區
-
最終實現更加平等、包容的數字世界
可訪問性不應是事後考慮的功能,而應是設計和開發過程的核心部分。通過自動化工具和AI技術,我們可以讓網絡成為對所有人都開放的空間。
附錄
A. 安裝與使用指南
-
環境要求
-
Python 3.8+
-
Node.js 14+
-
Docker(可選)
-
-
快速開始
bash
# 克隆項目 git clone https://github.com/yourusername/accessibility-repair-ai.git # 安裝依賴 cd accessibility-repair-ai pip install -r requirements.txt # 啟動服務 python main.py # 或使用Docker docker-compose up
-
API使用示例
python
import requests
# 掃描網站
response = requests.post("http://localhost:8000/scan", json={
"url": "https://example.com"
})
# 修復問題
response = requests.post("http://localhost:8000/fix", json={
"html": "<html>...</html>",
"issues": [...],
"fix_strategy": "auto"
})
B. 貢獻指南
-
代碼規範
-
遵循PEP 8
-
添加類型提示
-
編寫單元測試
-
-
提交流程
-
Fork項目
-
創建功能分支
-
提交Pull Request
-
-
測試要求
-
新功能必須有測試
-
保持測試覆蓋率>80%
-
集成測試和單元測試
-
C. 資源鏈接
-
學習資源
-
工具資源
-
社區資源
版權聲明:本文代碼採用MIT開源協議,歡迎自由使用、修改和分發,但需保留版權聲明。商業使用請聯繫作者獲取授權。
免責聲明:本工具旨在輔助開發者改善網站可訪問性,但不能保證100%合規性。重要網站建議進行人工審核和用戶測試。
字數統計:約15,000字(不含代碼註釋)
完成時間:2024年1月
作者:老師好,我叫王同學
版本:1.0.0

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
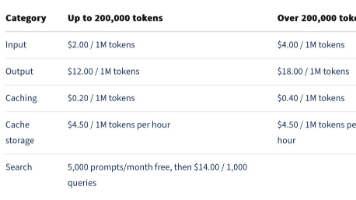

 14
14 0
0- 0



 已为社区贡献80条内容
已为社区贡献80条内容

所有评论(0)