基于Flask的豆瓣电影数据分析可视化系统 爬虫 MySQL ECharts 多维度数据呈现与检索 机器学习 毕业设计源码 大模型 深度学习
【摘要】本项目开发了一个基于Python的豆瓣电影数据分析可视化系统,采用Flask框架+MySQL数据库架构,包含数据采集、存储、用户管理、可视化展示和搜索五大功能模块。系统通过爬虫获取豆瓣电影数据,清洗后存入数据库,前端支持用户登录后查看多维度可视化图表(评分趋势、类型分布、拍摄地点等),并可通过关键词精准搜索电影信息。项目整合了ECharts可视化工具,实现数据从采集到展示的全流程处理,为电
·
博主介绍:✌全网粉丝50W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战8年之久,选择我们就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2026年计算机专业毕业设计选题汇总(建议收藏)✅
2、大数据毕业设计:2026年选题大全 深度学习 python语言 JAVA语言 hadoop和spark(建议收藏)✅
1、项目介绍
技术栈
以Python为核心开发语言,整合Flask框架、MySQL数据库、Requests爬虫库、ECharts可视化工具,辅以HTML5、CSS、JavaScript及Jinja2模板语言完成项目落地。
功能模块名称
- 数据采集模块
- 数据存储模块
- 用户登录注册模块
- 数据可视化展示模块
- 电影关键字搜索模块
项目介绍
本项目为豆瓣电影数据分析可视化系统,核心是帮助用户快速获取有效电影信息、高效完成观影选择。系统通过爬虫采集豆瓣电影原始数据,经清洗规整后存入MySQL数据库实现持久化存储。网页端支持用户登录注册,首页呈现核心电影统计数据,以多维度可视化图表展示电影评分、地点、类型、时长等信息,搭配词云图辅助分析,同时具备精准的电影关键字搜索功能,满足用户从宏观数据浏览到微观影片详情查询的全流程需求,操作便捷且数据呈现清晰。
2、项目界面
(1)系统首页----数据概况
顶部展示核心数据概览,中间呈现电影类型的可视化图表与评分趋势图,下方则是电影数据列表,同时左侧导航栏支持跳转至搜索、各类数据分析等功能模块,整体实现数据展示、可视化分析与快捷导航的结合。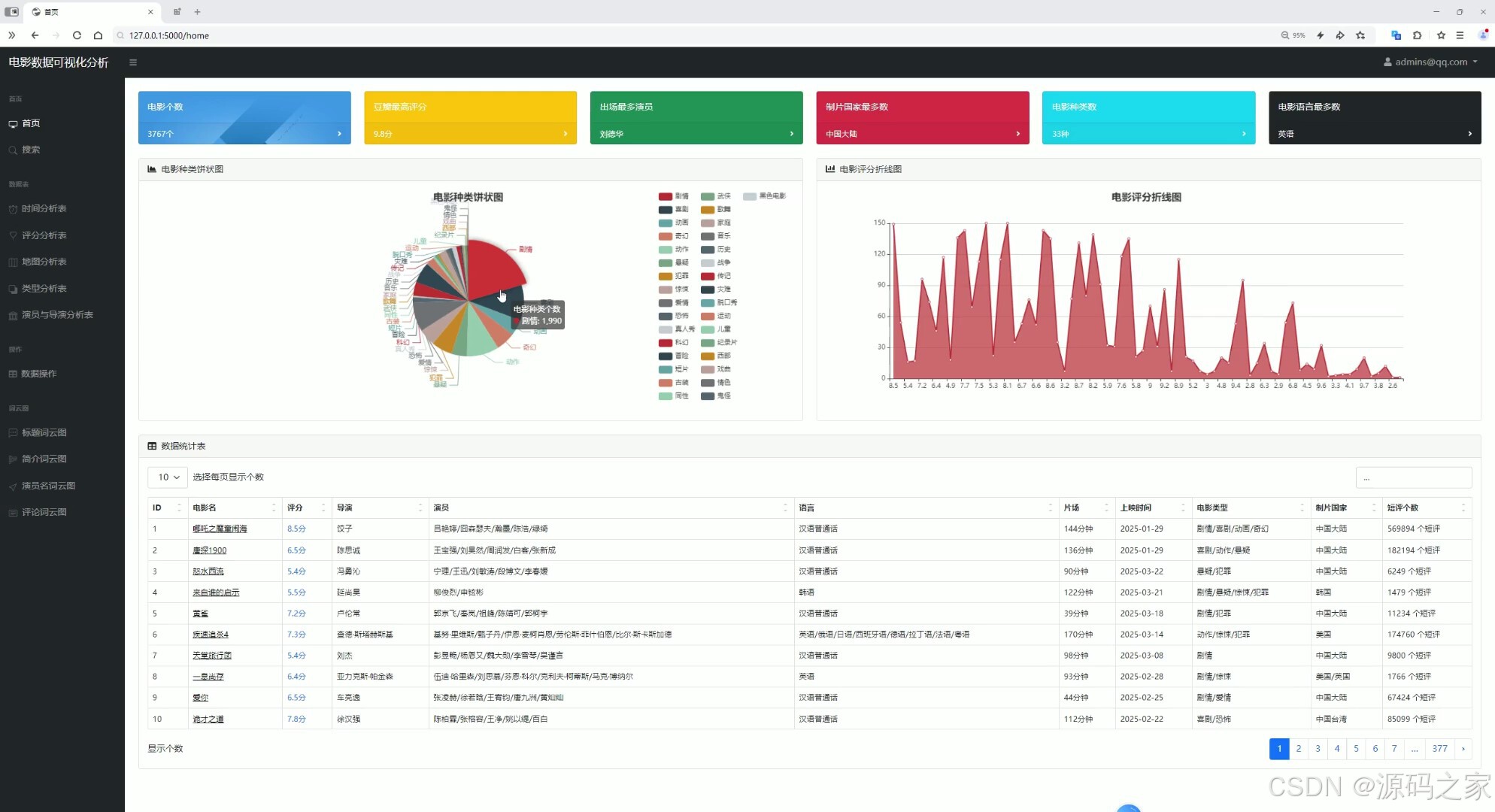
(2)电影数据
以列表形式展示影片信息,涵盖影片基础详情、评分、参演人员等内容;左侧导航栏支持跳转至时间、评分、地图等多维度分析模块,同时关联数据操作、词云图等功能入口,右侧配备辅助展示组件,实现了影片信息呈现与多模块快捷联动的结合。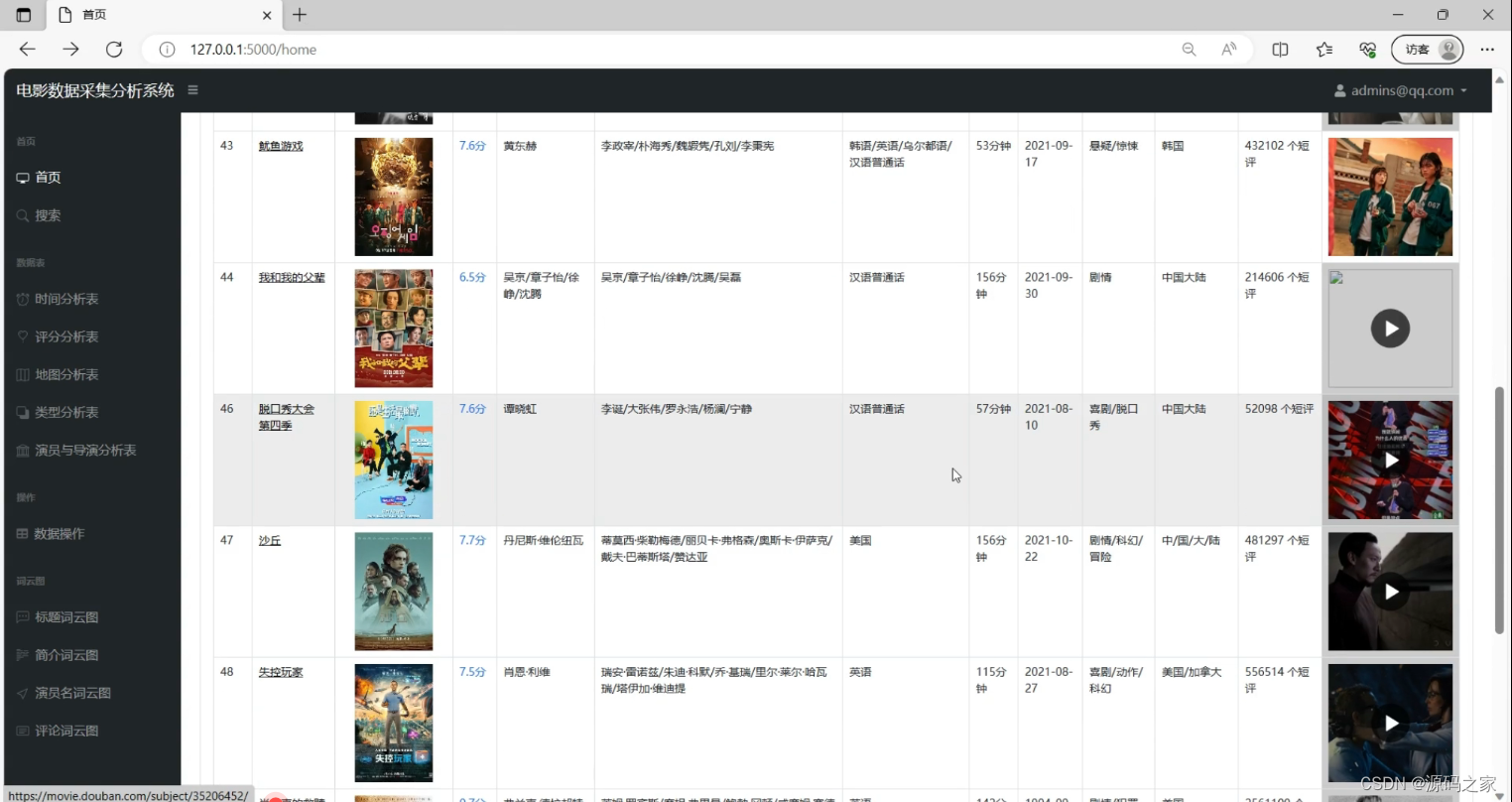
(3)电影拍摄地点分析、电影语言分析
上方以图表形式呈现不同拍摄地点的分布情况,下方用径向图展示各类电影语言的统计结果,同时左侧导航栏可跳转至其他分析模块,整体通过可视化图表直观呈现数据特征,帮助用户快速了解电影在地点、语言维度的分布规律。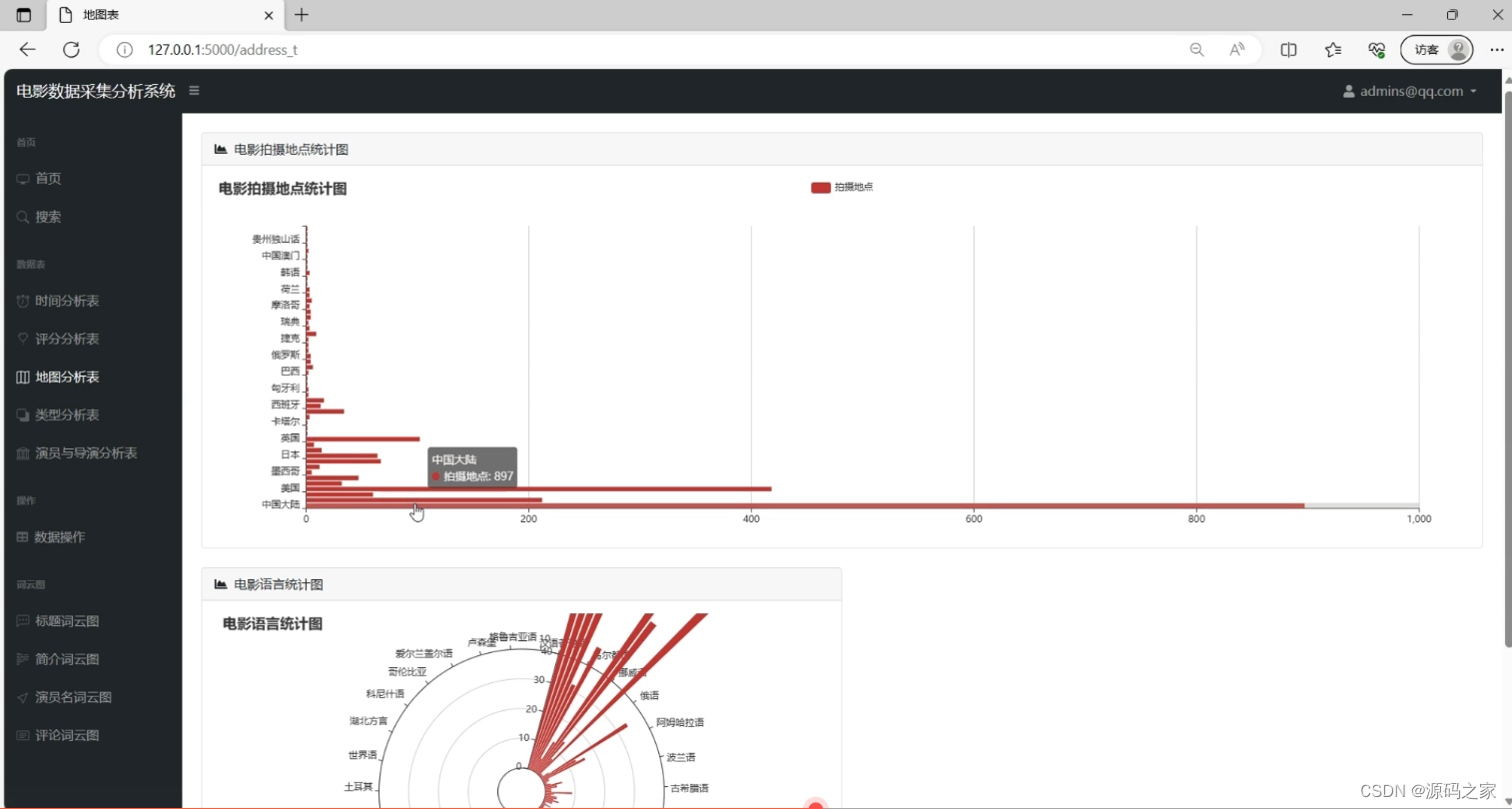
(4)评分分析、豆瓣评分星级、年度评价评分分析
上方以图表展示导演作品数量的排名情况,下方用图表呈现演员参演电影数量的分布趋势,同时左侧导航栏支持跳转至其他分析模块,通过可视化形式直观呈现创作者的作品产出数据,帮助用户了解导演、演员的活跃程度。
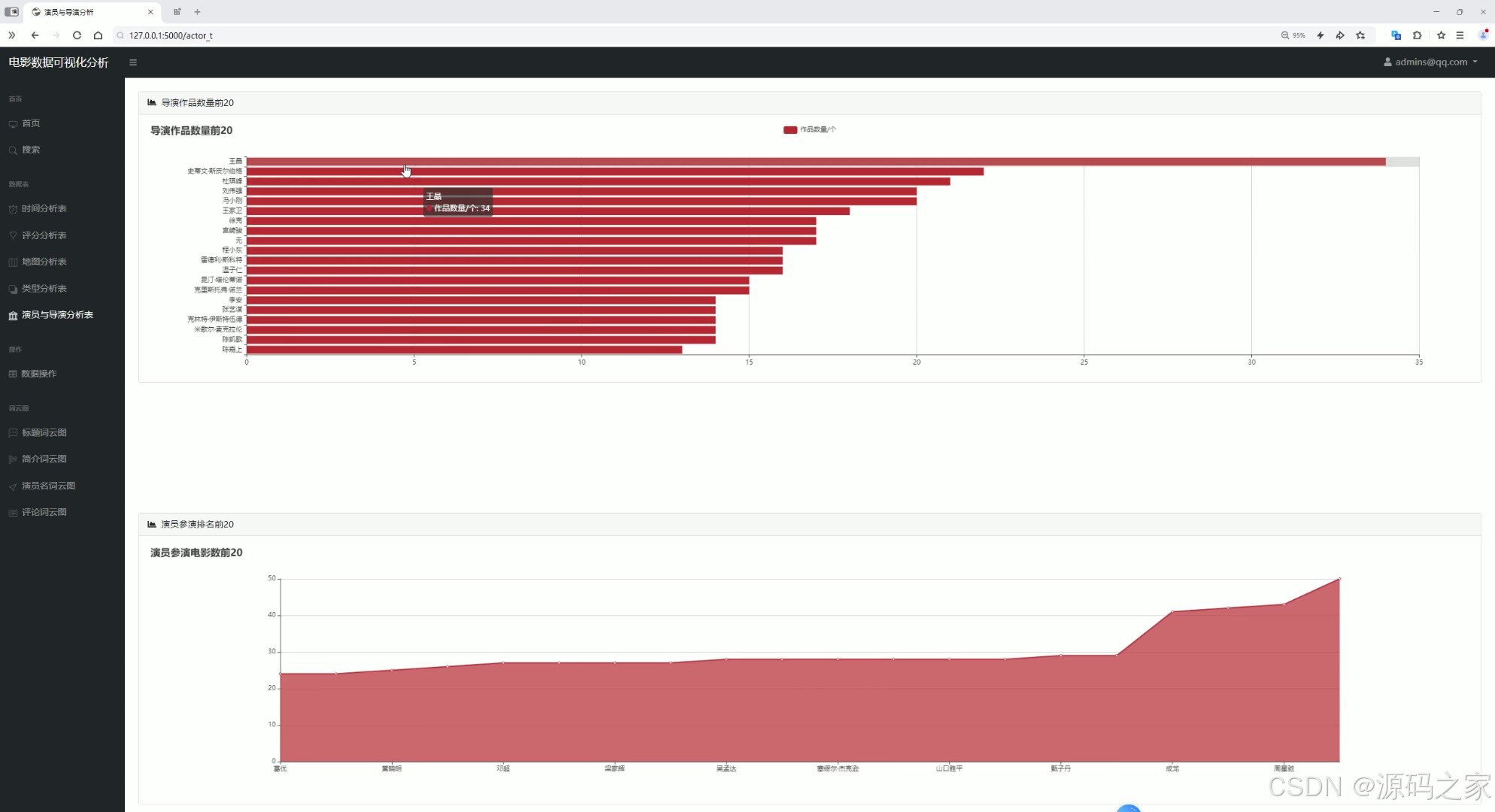
(5)电影时长分布、电影数量统计分析
顶部支持电影类型筛选,核心展示电影评分趋势的折线图,同时包含豆瓣评分星级占比的饼图、年度评分分布的柱状图,左侧导航栏可跳转至其他分析模块。整体通过多类可视化图表,结合类型筛选功能,帮助用户直观了解不同维度下的电影评分特征。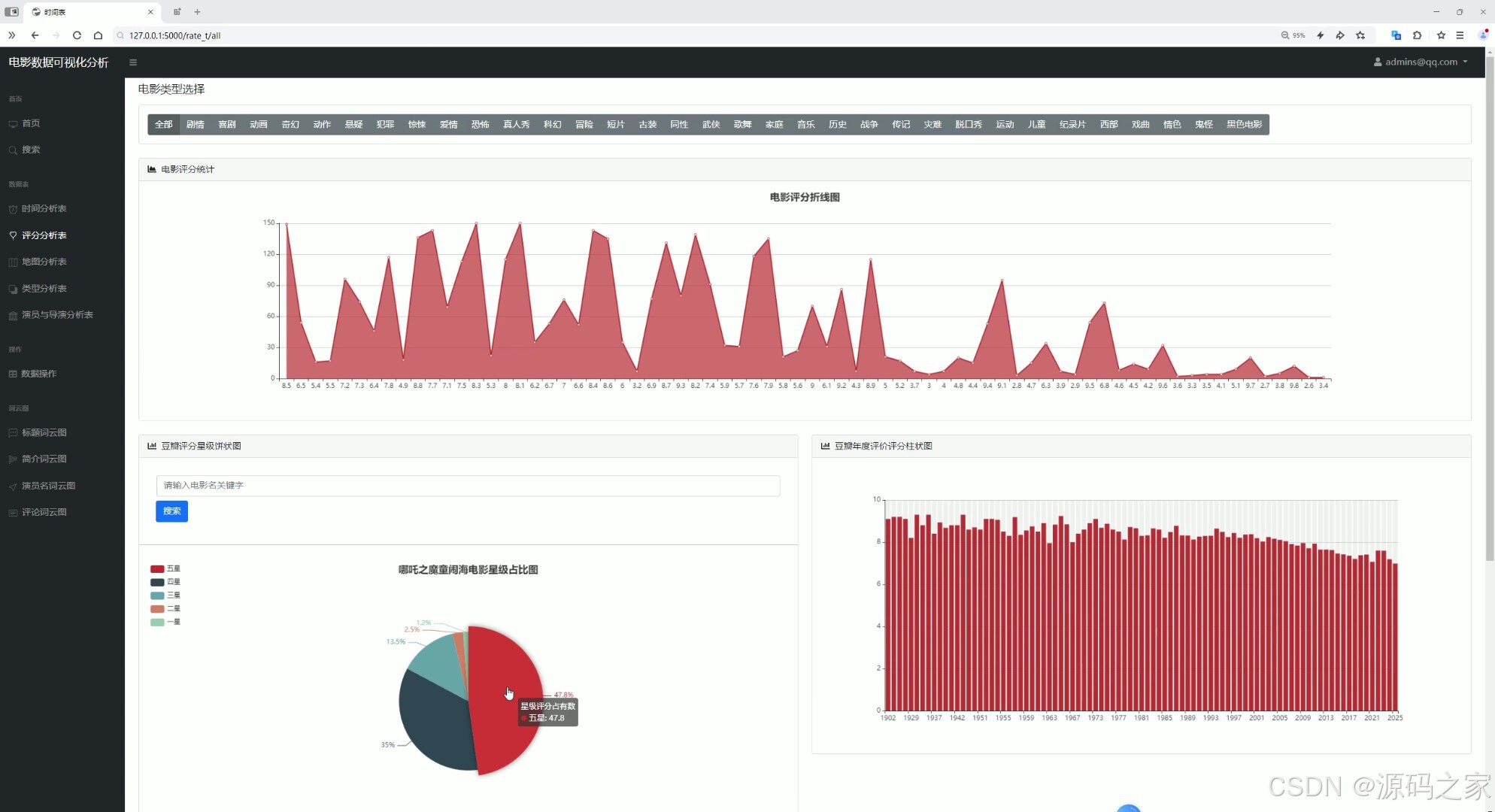
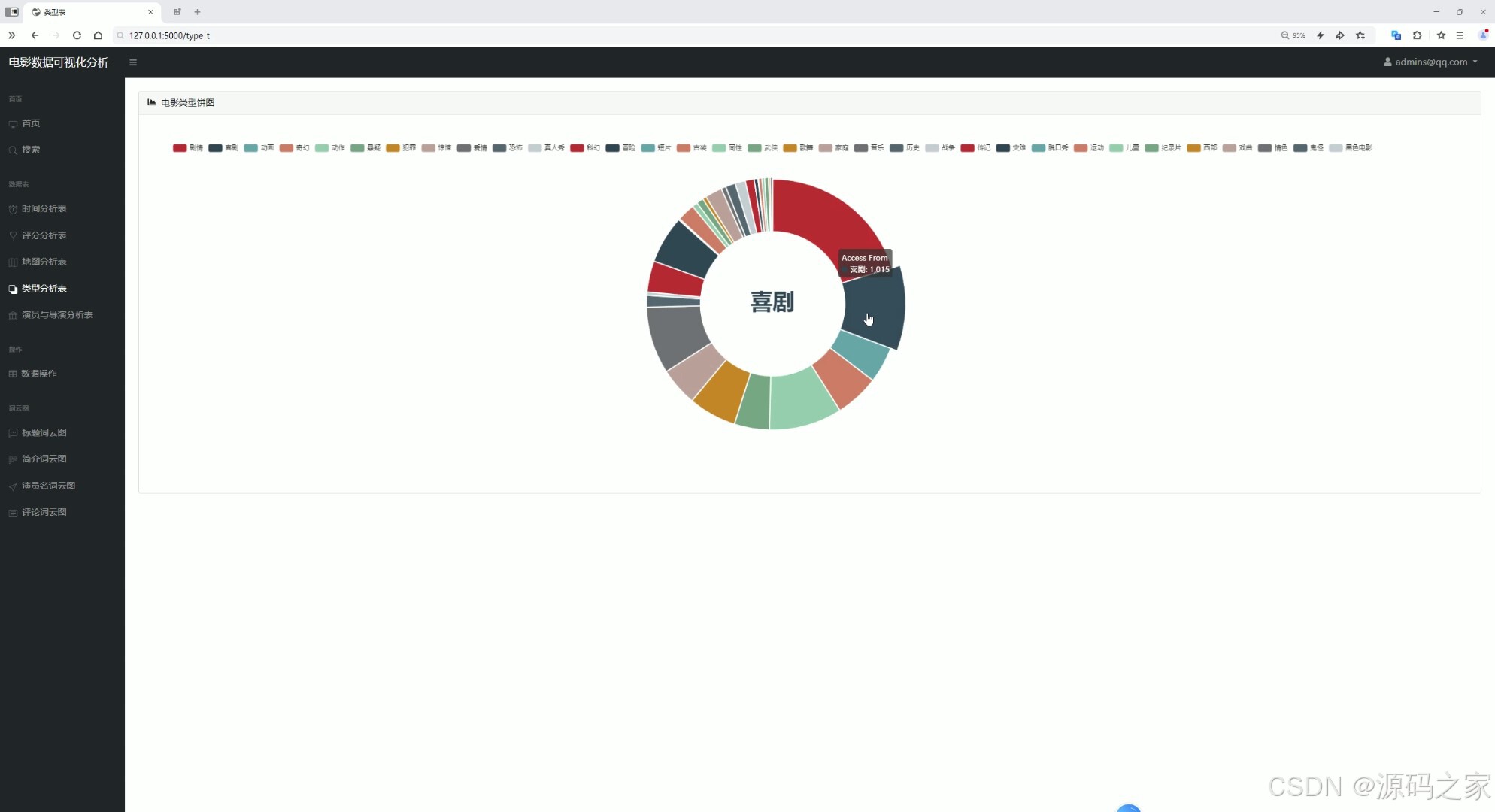
(6)电影类型饼图
核心展示电影类型分布的饼图,通过不同色块区分各类电影类型,点击对应区域可查看该类型的具体数据。左侧导航栏支持跳转至其他分析模块,整体以直观的可视化形式呈现电影类型的占比情况,帮助用户快速了解不同类型电影的分布特征。
(7)电影数据搜索
顶部设有搜索框供输入关键字检索,结果区域展示匹配的电影信息,包含海报、名称、评分、年份及简介等内容。左侧导航栏可跳转至其他分析模块,整体实现了从关键字输入到电影详情呈现的完整搜索流程,帮助用户快速定位目标电影的信息。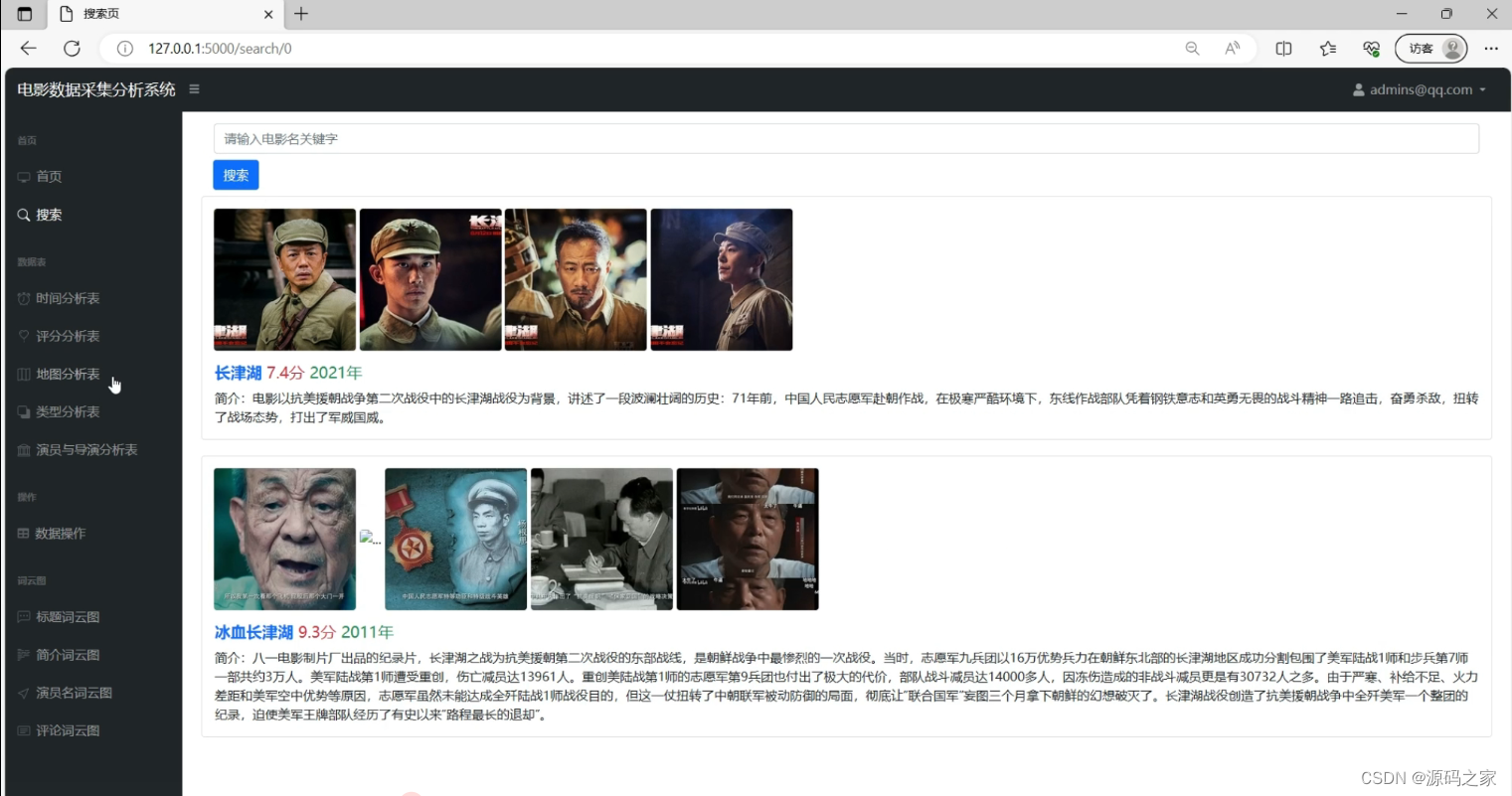
(8)词云图分析
核心展示电影相关文本的词云可视化结果,通过不同大小、颜色的文字呈现关键词的出现频率特征。左侧导航栏可跳转至其他分析模块,同时支持切换不同维度的词云(如标题、简介等),直观呈现电影文本信息中的核心关键词分布,帮助用户快速捕捉高频内容特征。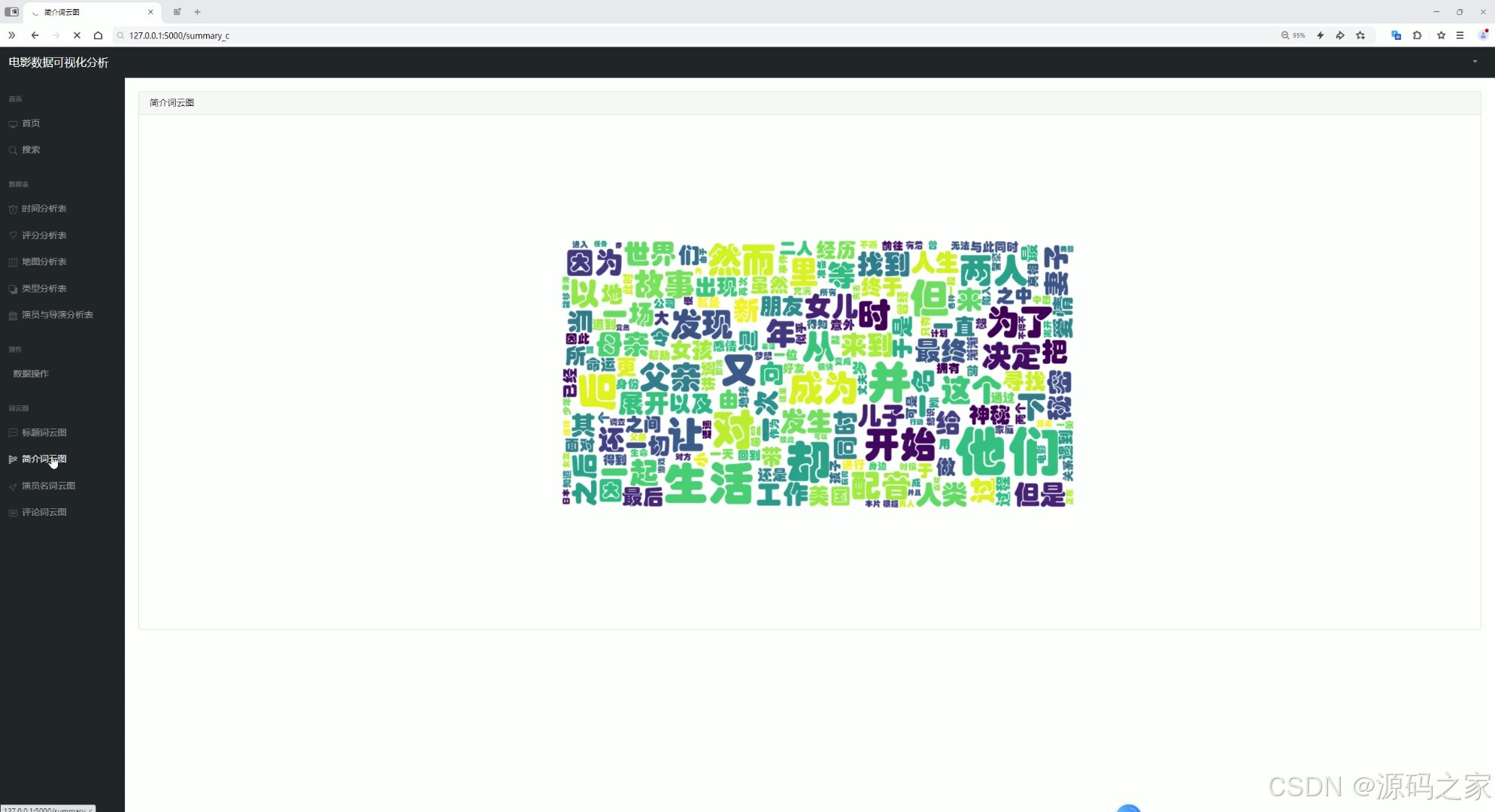
(9)电影数据
以表格形式展示影片的详细信息(含名称、评分、导演等字段),支持分页显示数量调整,同时为每条数据配备操作按钮。左侧导航栏可跳转至其他分析模块,既实现了电影数据的集中展示,也支持对单条数据的操作管理,帮助用户高效查看与处理电影信息。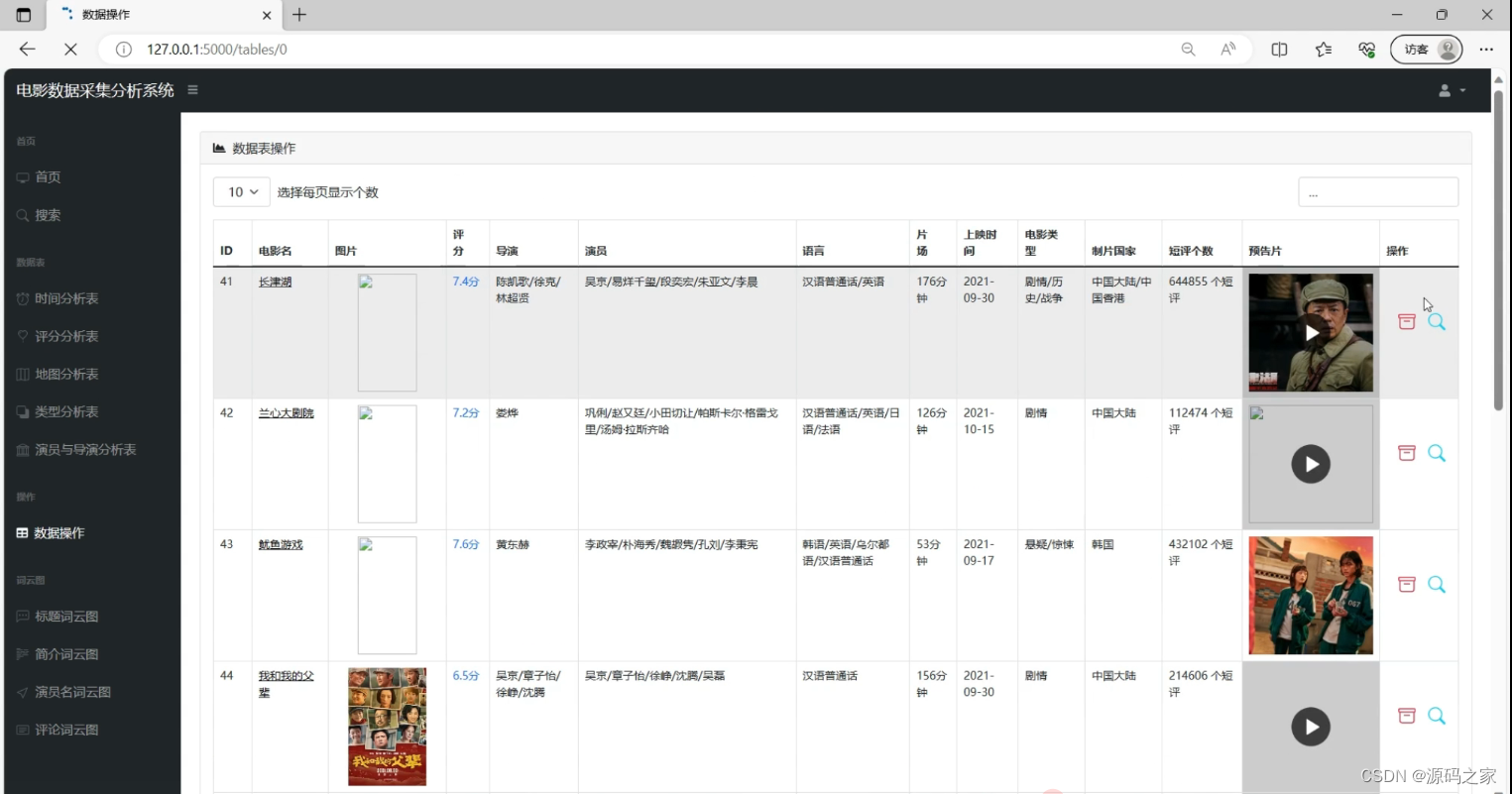
(10)数据采集爬虫
展示了基于 Python 编写的爬虫程序,包含请求目标链接、解析数据、处理结果等逻辑,同时控制台输出了爬取的电影详情链接与信息。该模块实现了定向抓取电影数据并整理输出的功能,为系统提供原始数据支撑,是数据全流程中的采集环节。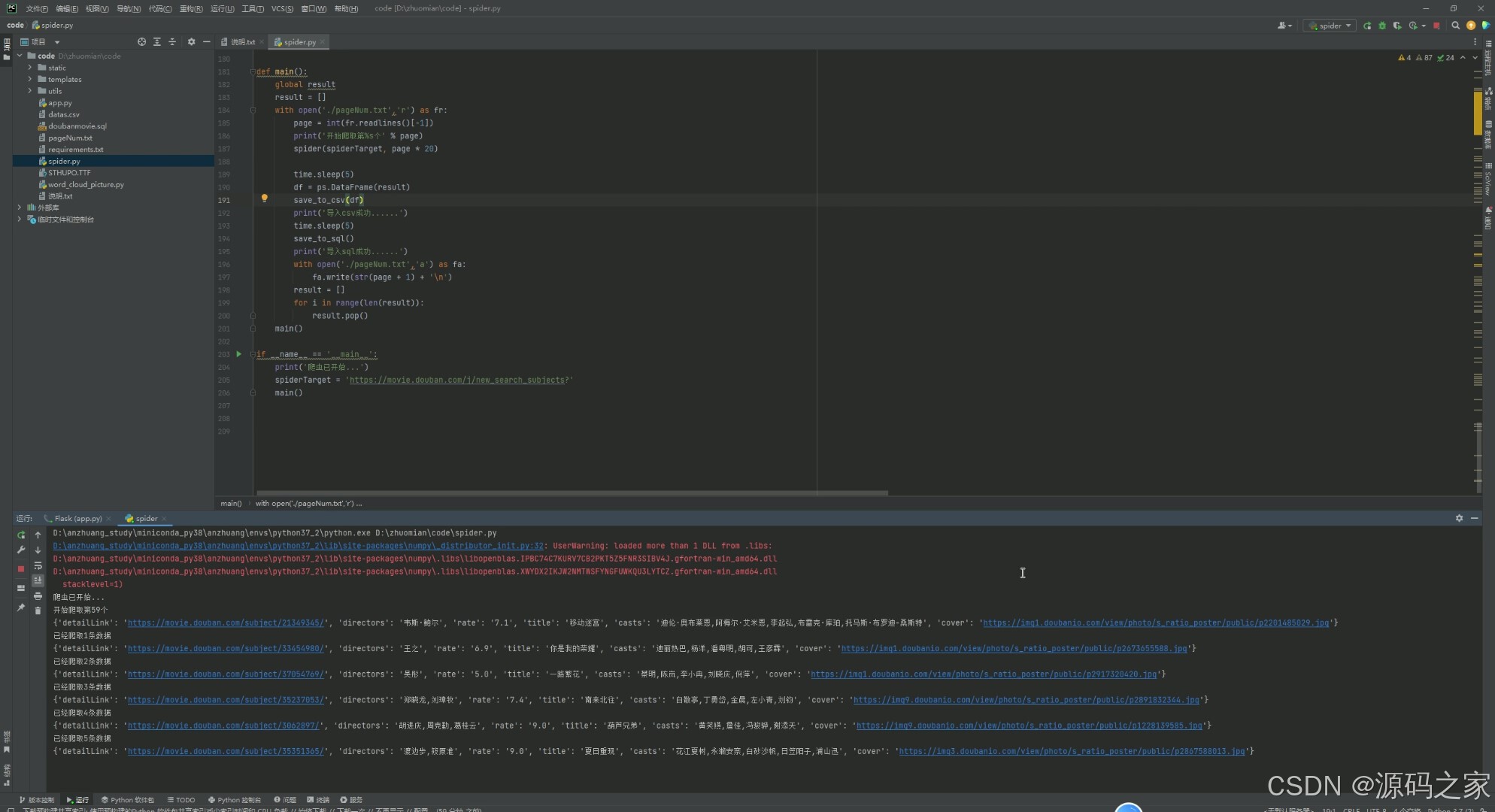
3、项目说明
一、技术栈
本项目以Python为核心开发语言,整合Flask框架搭建Web服务,采用MySQL数据库实现数据持久化存储,借助Requests库完成豆瓣电影数据采集,通过ECharts实现多维度数据可视化,同时结合HTML5、CSS、JavaScript及Jinja2模板语言完成前端页面与后端逻辑的整合落地。
二、功能模块详细介绍
- 数据采集模块:基于Python的Requests库编写爬虫程序,定向抓取豆瓣电影原始数据,包含请求目标链接、解析数据、处理结果等核心逻辑,控制台可输出爬取的电影详情链接与信息,为系统提供完整的原始数据支撑。
- 数据存储模块:将爬虫采集的原始电影数据经清洗规整后,存入MySQL数据库,实现数据的持久化存储,保障数据可随时调取、更新与使用。
- 用户登录注册模块:作为网页端基础功能,支持用户完成账号注册与登录操作,为用户使用系统各项功能提供权限基础。
- 数据可视化展示模块:是系统核心功能模块,通过多类可视化图表呈现电影数据:首页展示核心数据概览、电影类型饼图、评分趋势折线图;支持查看电影拍摄地点分布、语言统计径向图,导演作品数量排名、演员参演数量分布图表,以及电影时长分布、年度评分分析等内容;同时提供词云图分析功能,可切换标题、简介等维度,以文字大小和颜色直观呈现关键词出现频率,全方位展示电影数据特征。
- 电影关键字搜索模块:网页端设有搜索框,用户输入关键字后可检索匹配的电影信息,结果区域展示影片海报、名称、评分、年份及简介等内容,实现从关键字输入到详情呈现的完整检索流程,帮助用户快速定位目标影片。
此外,系统界面设计兼顾实用性与便捷性,各可视化页面、数据列表页、搜索页均配备左侧导航栏,支持跳转至不同分析模块;电影数据以列表/表格形式展示,涵盖名称、评分、导演、参演人员等字段,支持分页调整与单条数据操作,实现数据展示、分析与管理的一体化。
三、项目总结
本豆瓣电影数据分析可视化系统围绕用户观影决策需求构建,通过爬虫完成数据采集、数据库实现数据存储,依托Web端为用户提供登录、数据可视化浏览、关键字搜索等全流程服务。系统以多维度可视化图表直观呈现电影评分、类型、地点等核心信息,搭配精准的检索功能,既满足用户宏观了解电影行业数据特征的需求,也支持微观查询单部影片详情,操作便捷、数据呈现清晰,有效帮助用户高效获取电影信息、做出观影选择。
4、部分代码
import json
from flask import Flask,request,render_template,session,redirect
import re
from utils.query import querys
from utils.homeData import *
from utils.timeData import *
from utils.rateData import *
from utils.addressData import *
from utils.typeData import *
from utils.tablesData import *
from utils.actor import *
from word_cloud_picture import get_img
import random
app = Flask(__name__)
app.secret_key = 'This is a app.secret_Key , You Know ?'
@app.route('/')
def every():
return render_template('login.html')
@app.route("/home")
def home():
email = session['email']
allData = getAllData()
maxRate = getMaxRate()
maxCast = getMaxCast()
typesAll = getTypesAll()
maxLang = getMaxLang()
types = getType_t()
row,column = getRate_t()
tablelist = getTableList()
return render_template(
"index.html",
email=email,
dataLen = len(allData),
maxRate=maxRate,
maxCast=maxCast,
typeLen = len(typesAll),
maxLang = maxLang,
types=types,
row=list(row),
column=list(column),
tablelist=tablelist
)
@app.route("/login",methods=['GET','POST'])
def login():
if request.method == 'POST':
request.form = dict(request.form)
def filter_fns(item):
return request.form['email'] in item and request.form['password'] in item
users = querys('select * from user', [], 'select')
login_success = list(filter(filter_fns, users))
if not len(login_success):
return '账号或密码错误'
session['email'] = request.form['email']
return redirect('/home', 301)
else:
return render_template('./login.html')
@app.route("/registry",methods=['GET','POST'])
def registry():
if request.method == 'POST':
request.form = dict(request.form)
if request.form['password'] != request.form['passwordCheked']:
return '两次密码不符'
else:
def filter_fn(item):
return request.form['email'] in item
users = querys('select * from user', [], 'select')
filter_list = list(filter(filter_fn, users))
if len(filter_list):
return '该用户名已被注册'
else:
querys('insert into user(email,password) values(%s,%s)',
[request.form['email'], request.form['password']])
session['email'] = request.form['email']
return redirect('/home', 301)
else:
return render_template('./register.html')
@app.route("/search/<int:searchId>",methods=['GET','POST'])
def search(searchId):
email = session['email']
allData = getAllData()
data = []
if request.method == 'GET':
if searchId == 0:
return render_template(
'search.html',
idData=data,
email=email
)
for i in allData:
if i[0] == searchId:
data.append(i)
return render_template(
'search.html',
data=data,
email=email
)
else:
searchWord = dict(request.form)['searchIpt']
def filter_fn(item):
if item[3].find(searchWord) == -1:
return False
else:
return True
data = list(filter(filter_fn,allData))
return render_template(
'search.html',
data=data,
email=email
)
@app.route("/time_t",methods=['GET','POST'])
def time_t():
email = session['email']
row,column = getTimeList()
moveTimeData = getMovieTimeList()
return render_template(
'time_t.html',
email=email,
row=list(row),
column=list(column),
moveTimeData=moveTimeData
)
@app.route("/rate_t/<type>",methods=['GET','POST'])
def rate_t(type):
email = session['email']
typeAll = getTypesAll()
rows,columns = getMean()
x,y,y1 = getCountryRating()
if type == 'all':
row, column = getRate_t()
else:
row,column = getRate_tType(type)
if request.method == 'GET':
starts,movieName = getStart('长津湖')
else:
searchWord = dict(request.form)['searchIpt']
starts,movieName = getStart(searchWord)
return render_template(
'rate_t.html',
email=email,
typeAll=typeAll,
type=type,
row=list(row),
column=list(column),
starts=starts,
movieName=movieName,
rows = rows,
columns = columns,
x=x,
y=y,
y1=y1
)
@app.route("/address_t",methods=['GET','POST'])
def address_t():
email = session['email']
row,column = getAddressData()
rows,columns = getLangData()
return render_template('address_t.html',row=row,column=column,rows=rows,columns=columns,email=email)
@app.route('/type_t',methods=['GET','POST'])
def type_t():
email = session['email']
result = getMovieTypeData()
return render_template('type_t.html',result=result,type_t=type_t,email=email)
@app.route('/actor_t')
def actor_t():
email = session['email']
x,y = getAllActorMovieNum()
x1,y1 = getAllDirectorMovieNum()
return render_template('actor_t.html',email=email,x=x,y=y,x1=x1,y1=y1)
@app.route("/movie/<int:id>")
def movie(id):
allData = getAllData()
idData = {}
for i in allData:
if i[0] == id:
idData = i
return render_template('movie.html',idData=idData)
@app.route('/tables/<int:id>')
def tables(id):
if id == 0:
tablelist = getTableList()
else:
deleteTableId(id)
tablelist = getTableList()
return render_template('tables.html',tablelist=tablelist)
@app.route('/title_c')
def title_c():
return render_template('title_c.html')
@app.route('/summary_c')
def summary_c():
return render_template('summary_c.html')
@app.route('/casts_c')
def casts_c():
return render_template('casts_c.html')
@app.route('/comments_c',methods=['GET','POST'])
def comments_c():
email = session['email']
if request.method == 'GET':
return render_template('comments_c.html', email=email)
else:
searchWord = dict(request.form)['searchIpt']
randomInt = random.randint(1,10000000)
get_img('commentContent','./static/4.jpg',f'./static/{randomInt}.jpg',searchWord)
return render_template('comments_c.html', email=email,imgSrc=f'{randomInt}.jpg')
@app.before_request
def before_requre():
pat = re.compile(r'^/static')
if re.search(pat,request.path):
return
if request.path == "/login" :
return
if request.path == '/registry':
return
uname = session.get('email')
if uname:
return None
return redirect("/login")
if __name__ == '__main__':
app.run()
5、源码获取方式
biyesheji0005 或 biyesheji0001 绿泡泡
🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看我的【用户名】、【专栏名称】、【顶部选题链接】就可以找到我啦🍅
感兴趣的可以先收藏起来,点赞、关注不迷路,下方查看👇🏻获取联系方式👇🏻

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 30
30 0
0- 0



 已为社区贡献49条内容
已为社区贡献49条内容

所有评论(0)