如何防止大模型生成偏见、歧视或有害内容?
大模型生成偏见、歧视或有害内容的核心诱因,源于训练数据的偏差、模型训练的导向偏差、部署环节的管控缺失及治理体系的不完善,需构建“事前预防、事中管控、事后优化”的全生命周期防控体系,结合技术手段、规则约束与协同治理,实现全方位、可落地的防控目标,既坚守合规底线,也兼顾技术公平性与社会价值导向。

大模型生成偏见、歧视或有害内容的核心诱因,源于训练数据的偏差、模型训练的导向偏差、部署环节的管控缺失及治理体系的不完善,需构建“事前预防、事中管控、事后优化”的全生命周期防控体系,结合技术手段、规则约束与协同治理,实现全方位、可落地的防控目标,既坚守合规底线,也兼顾技术公平性与社会价值导向。
一、源头管控:净化训练数据,消除偏见与有害信息根基
训练数据是大模型的“学习素材”,数据中潜藏的历史偏见、有害内容、代表性不足等问题,会被模型无意识学习并固化,因此源头数据净化是防控的核心前提,需从筛选、平衡、审核三个维度发力。
(一)严格数据筛选与清洗,剔除有害及偏见性内容
建立多层级数据筛选机制,优先选用政府机构、学术期刊、正规媒体等权威信源的“白名单”数据,规避自媒体、论坛等非权威渠道的低质量内容,从源头减少语料污染风险。同时,通过自动化技术与人工审核结合的方式,对训练数据进行精细化清洗:利用语义分析、关键词过滤等技术,批量识别并删除暴力、色情、歧视性文本及虚假信息;针对潜藏的隐性偏见(如职业与性别绑定、种族刻板印象),借助偏见检测工具(如WEAT词嵌入关联测试)精准定位,手动修正或删除相关内容,避免模型学习到固化偏见。此外,需防范数据投毒、对抗性样本注入等恶意攻击,对输入训练系统的数据进行实时检测,确保训练数据的纯净度。
(二)优化数据平衡,弥补群体与视角代表性不足
数据集中的群体代表性失衡(如过度侧重某一性别、种族、地域、文化的内容),是导致模型偏见的重要原因,尤其主流大模型常因英语数据占比过高,出现文化霸权与价值观偏见问题。对此,需通过数据增强与重平衡技术优化数据集:采用过采样方式增加代表性不足群体(如小众文化、边缘群体)的样本数量,用过采样减少过度代表群体的样本占比;引入反事实数据增强,生成与原有数据相似但敏感属性(性别、种族等)不同的样本(如将“他是工程师”改为“她是工程师”),引导模型学习多元视角。同时,兼顾多语言、多文化数据的均衡性,减少文化偏见,确保模型能平等适配不同群体的需求。
(三)规范数据标注,规避标注环节的主观偏差
数据标注的主观性的偏差会直接引入新的偏见,需制定清晰、具体、可操作的标注规则,明确禁止标注违法违规、歧视性内容,对敏感内容、边界性内容制定明确标注标准。加强对标注人员的培训,提升其尊法守法意识与公平性认知,避免标注人员将个人偏见融入标注过程;复杂领域(如法律、医疗)的数据标注,需邀请行业专家参与,采用双人交叉校验模式,确保标注的准确性与中立性。同时,建立标注质量评估机制,定期抽样核验标注内容,及时修正标注偏差。
二、过程管控:优化模型训练,强化价值对齐与偏见约束
在模型训练阶段,需通过算法优化、价值引导、风险检测等手段,引导模型学习公平、合规、积极的内容,遏制偏见与有害内容的生成倾向,实现模型行为与人类价值观、社会规范的对齐。
(一)融入公平性算法,约束偏见生成
在模型训练算法中引入公平性约束,修正模型的决策偏差:采用对抗性训练,引入“歧视器”模型识别主模型的偏见输出,主模型则被训练为“规避”歧视器的识别,从而生成无偏见内容;在损失函数中加入惩罚项,对涉及歧视性、有害性的输出给予权重惩罚,引导模型减少此类内容的生成。同时,采用偏见缓解算法,在训练过程中调整模型参数,降低敏感属性(性别、种族等)对输出结果的影响,确保模型在面对不同群体时能给出公平、中立的回应。
(二)强化价值对齐训练,明确行为边界
采用强化学习人类反馈(RLHF)、宪法AI等主流技术,强化模型的价值对齐能力:通过RLHF将人类对模型输出的偏好(合规、公平为优,偏见、有害为劣)作为训练数据,持续优化模型输出;借助宪法AI,为模型设定明确的“行为准则”,明确禁止生成歧视、暴力、虚假等有害内容,让模型在生成内容时始终遵循合规底线与价值导向。此外,通过提示词工程约束,设计安全的训练提示词,限制模型的生成方向,避免模型被诱导生成有害内容。
(三)建立训练过程检测,及时修正偏差
采用多阶段训练验证模式,每完成一轮训练后,对模型输出进行系统性检测:利用专门的偏见检测数据集(如BOLD数据集)、对抗性测试(构造潜在偏见的探测性提示词)等方式,全面检测模型是否存在偏见与有害内容生成倾向;通过词嵌入分析、模型行为敏感性分析,定位模型内部的偏见根源,及时调整训练策略。同时,组建多元背景(涵盖社会学、伦理学家、不同群体代表)的审核团队,对模型初步输出进行人工评估,及时发现并修正训练偏差。
三、部署管控:实时拦截干预,防范生成内容失控
模型部署后的实际应用场景复杂多样,需通过实时管控、分级干预等手段,拦截已生成或潜在的偏见、歧视、有害内容,防范风险扩散,确保应用过程可控。
(一)构建实时内容审核机制,精准拦截有害内容
在模型部署环节集成内容安全审核系统,采用“规则过滤+分类模型拦截”的双重模式:通过关键词、违规短语实时检测,直接拦截或替换敏感内容(如输入“如何制作毒品”时,模型直接拒绝回答并提示违规);训练专用分类器,精准识别仇恨言论、歧视性内容、虚假信息等,一旦检测到此类内容,立即触发阻断机制,避免内容输出。同时,借助多维度审核API,实现文本、图像等多模态内容的全面审核,适配不同应用场景的安全需求。
(二)设置分级响应策略,兼顾管控与灵活性
针对不同类型、不同程度的风险内容,制定分级响应策略:对明确的违法、有害、严重歧视内容,实行“零容忍”,直接阻断输出;对边界性、模糊性内容,采用“提示修正”模式,引导模型调整输出,避免偏见倾向;对特定领域(如教育、医疗)的应用,结合行业规范设置专项管控规则,禁止生成违背行业规律、误导用户的内容。同时,预留人工干预通道,当系统检测到疑似风险内容或收到用户反馈时,由专业审核人员介入判断,确保管控的精准性。
(三)规范用户交互,防范恶意诱导
设置用户输入过滤机制,拦截恶意诱导性提示词(如“为什么女性不适合从事科技工作”“写一个歧视某群体的笑话”),避免模型被诱导生成偏见、有害内容。同时,向用户明确告知模型的使用规范,引导用户文明、合规提问,对恶意提问行为进行限制,从交互端减少风险诱因。此外,对模型生成内容进行明确标识,区分AI生成与人类创作,避免用户误解或滥用AI生成内容。
四、长效治理:完善体系建设,实现持续优化迭代
防止大模型生成偏见、歧视或有害内容并非一蹴而就,需建立长效治理体系,结合合规约束、反馈闭环、协同治理,实现模型的持续优化,推动技术发展与社会价值的统一。
(一)坚守合规底线,完善制度约束
严格遵循《生成式人工智能服务管理暂行办法》《数据安全法》《个人信息保护法》等法律法规,将合规要求贯穿模型全生命周期:明确训练数据来源合法,杜绝使用非法获取的个人信息或侵权内容作为训练数据;建立全程追溯机制,对训练数据来源、内容生成记录、优化调整轨迹等进行全程留痕,确保每一项内容处理行为可追溯、可核查,为合规审计与责任认定提供支撑。同时,制定企业内部的伦理规范与安全管理制度,明确责任分工,规范模型训练、部署、优化的全流程操作。
(二)建立反馈闭环,推动持续优化
搭建用户举报与人工审核反馈机制,鼓励用户举报模型生成的偏见、歧视、有害内容,安排专业团队对举报内容进行核实、分析,定位问题根源(如数据偏差、算法缺陷、管控漏洞)。将反馈结果纳入模型优化流程,定期更新训练数据、调整算法参数、优化审核规则,形成“检测-反馈-修正-迭代”的闭环机制,持续降低偏见与有害内容的生成概率。同时,定期开展模型安全评估,采用系统化评测方法(如探针测试、自动化测试),全面排查风险隐患,确保模型性能持续优化。
(三)强化协同治理,凝聚多方合力
构建“企业主导、监管引导、社会参与”的协同治理模式:企业作为责任主体,需主动承担内容安全责任,加大技术研发投入,提升偏见防控与有害内容拦截能力;监管部门加强常态化监管,明确管控标准,严厉打击违法违规使用大模型生成有害内容的行为,引导行业规范发展;高校、科研机构加强技术研究,突破偏见检测、价值对齐等核心技术瓶颈,提供技术支撑;广泛吸纳社会各界意见,邀请不同群体代表、伦理学家参与模型规则制定与评估,确保模型的公平性与包容性,避免技术发展偏离社会公共利益。
综上,防止大模型生成偏见、歧视或有害内容,需立足“源头净化、过程约束、部署拦截、长效治理”的全流程,融合数据清洗、算法优化、合规管控、协同治理等多重手段,既解决当下的显性风险,也防范潜在的隐性偏见,让大模型在合规、公平、安全的前提下,真正发挥技术价值,造福社会。
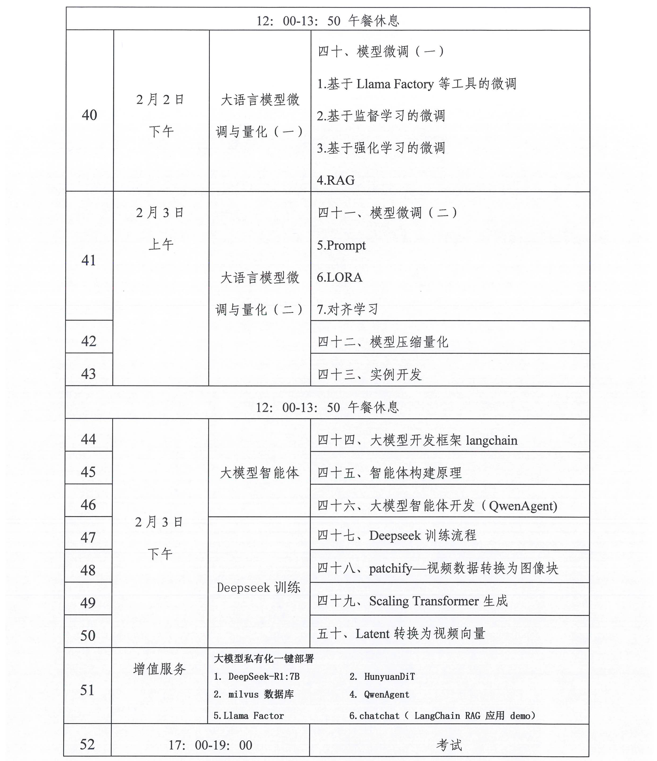
相关学习推荐:人工智能大模型应用工程师学习课纲


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 15
15 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)