深度学习生成任务 (Seq2seq & Transformer) 核心考点全解析
目录
二、 核心架构:Encoder-Decoder 与 Transformer
考点 1:Positional Encoding (位置编码)
三、 灵魂机制:Masked Attention 与 Cross Attention
前言
在考研复试中,生成任务(Generation Tasks) 和 Transformer 架构 是绝对的重头戏。无论是机器翻译、文本摘要,还是现在的 ChatGPT 等大模型,其核心逻辑都源于此。
很多同学对 Encoder-Decoder 的交互、Mask 机制、以及训练与推理的区别(Teacher Forcing vs Autoregressive)容易混淆。本文将结合课堂讲义,用最通俗的语言带你打通任督二脉!
一、 什么是生成任务 (Seq2seq)?
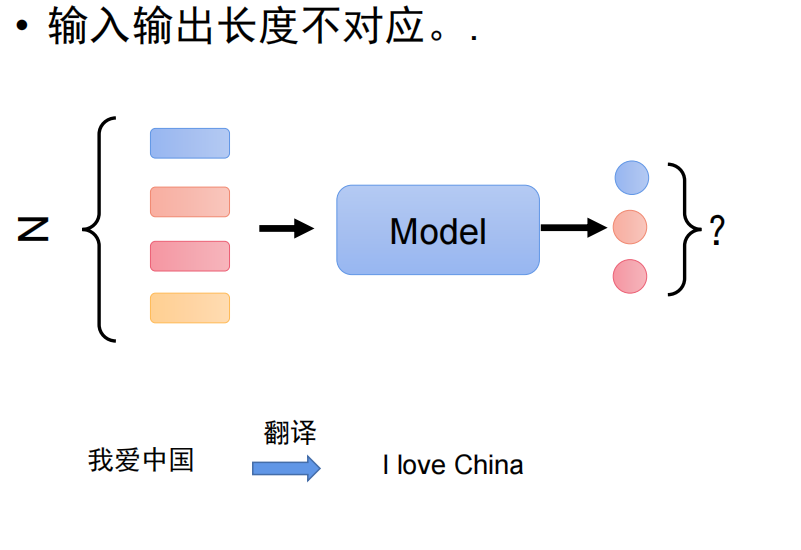
生成任务的核心是 Sequence-to-Sequence (序列到序列)。它的特点是输入和输出都是序列,且长度不固定,由模型自己决定输出多长。
最典型的例子就是机器翻译:
-
输入:
Z(向量序列,如“我爱中国”) -
输出:
Model决定生成几个词,最终输出I love China。
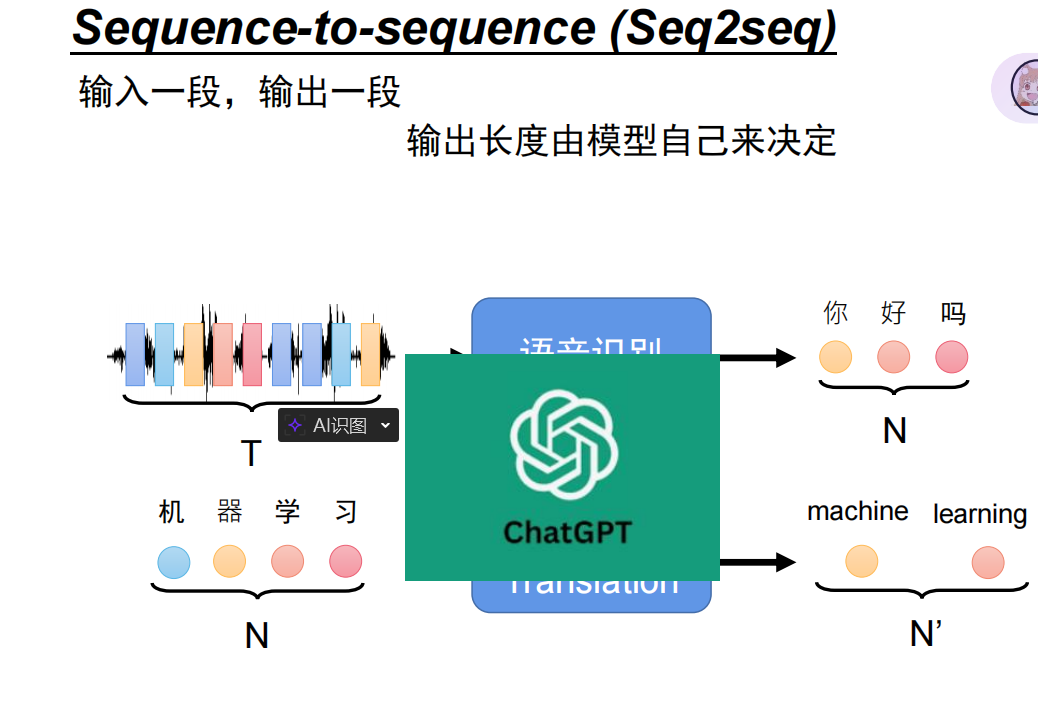
二、 核心架构:Encoder-Decoder 与 Transformer
为了完成这个任务,模型通常分为两部分:
-
Encoder (编码器):负责“读”。把输入的中文压缩成特征向量。
-
特点:拥有双向注意力,可以“上帝视角”看完整句话。
-
-
Decoder (解码器):负责“写”。根据特征向量,一个词一个词地生成英文。
-
特点:拥有Masked Attention,只能看历史,不能看未来。
-
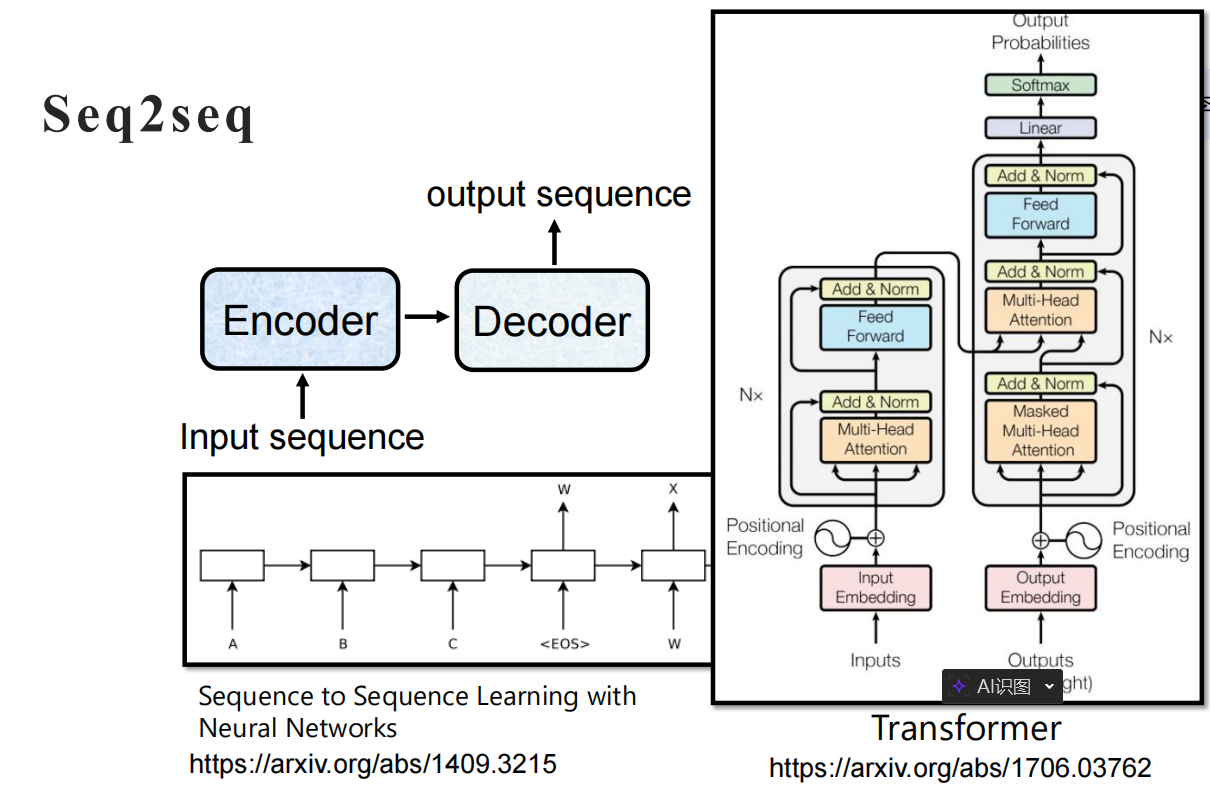
考点 1:Positional Encoding (位置编码)
Q:为什么需要位置编码? A:Transformer 内部的 Self-Attention 机制本质上是“词袋模型”,无法识别词序(“我打你”和“你打我”对它来说没区别)。
做法:通过将位置向量与词向量进行 Element-wise Addition (直接相加),给数据打上位置“水印”。位置向量的生成通常有两种方式:
-
Sinusoidal (固定公式):利用正弦 (Sin) 和余弦 (Cos) 函数生成不同频率的波纹。
-
优点:不需要学习参数,且具有一定的外推性(即推断时可以处理比训练集更长的序列)。
-
代表模型:原始 Transformer。
-
-
Learned (可学习):像学习词向量一样,初始化一个位置矩阵,随着训练过程自动调整更新。
-
优点:更能适应特定任务的数据分布。
-
缺点:难以处理超过预设最大长度的序列(例如训练最长512,遇到513就无法处理)。
-
代表模型:BERT, GPT。
-
三、 灵魂机制:Masked Attention 与 Cross Attention
这是复试中最容易被问到的细节,务必背熟!
1. Decoder 为什么要用 Mask?
在 Encoder 端,我们可以看完整句话。但在 Decoder 端,生成是一个时间序列过程。
-
预测第 2 个词时,绝对不能看到第 3 个词(那是未来的答案)。
-
Mask 矩阵:如下面的下三角矩阵所示,右上角被遮挡(设为0),强制模型只能关注历史。

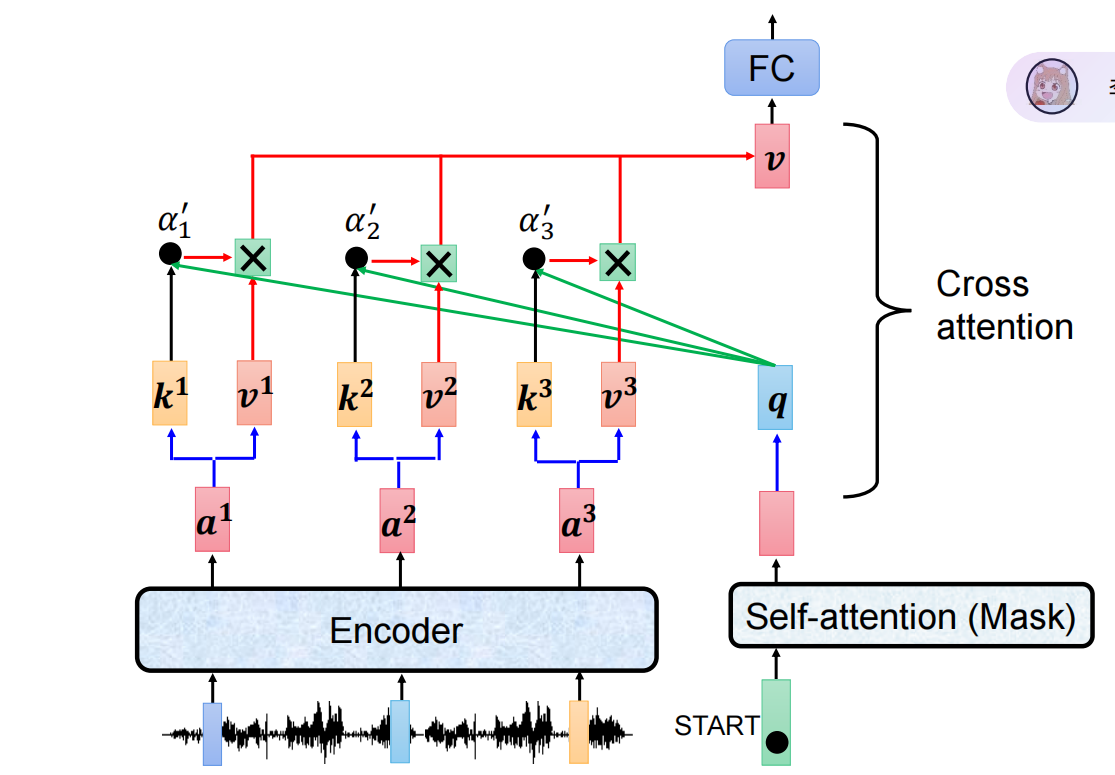
2. Cross Attention (交叉注意力)
这是连接 Encoder 和 Decoder 的桥梁。
-
Query (Q):来自 Decoder(代表“我现在缺什么信息”)。
-
Key (K) / Value (V):来自 Encoder(代表“原文有哪些信息”)。
-
原理:Decoder 拿着 Q 去扫描 Encoder 的 K,计算出注意力分数,然后加权提取 V。这就好比调酒时“按需索取”原料。
四、 训练与推理的巨大差异 (The Gap)
这是理解大模型工作原理的关键,也是区别“背书”和“真懂”的分水岭。
1. 训练时:Teacher Forcing (并行)
我们在训练时手里有标准答案(Ground Truth)。为了加速,我们不等待模型自己生成,而是直接把正确答案喂给 Decoder。
-
优势:配合 Mask 机制,可以一次性并行计算整句话的 Loss,效率极高。
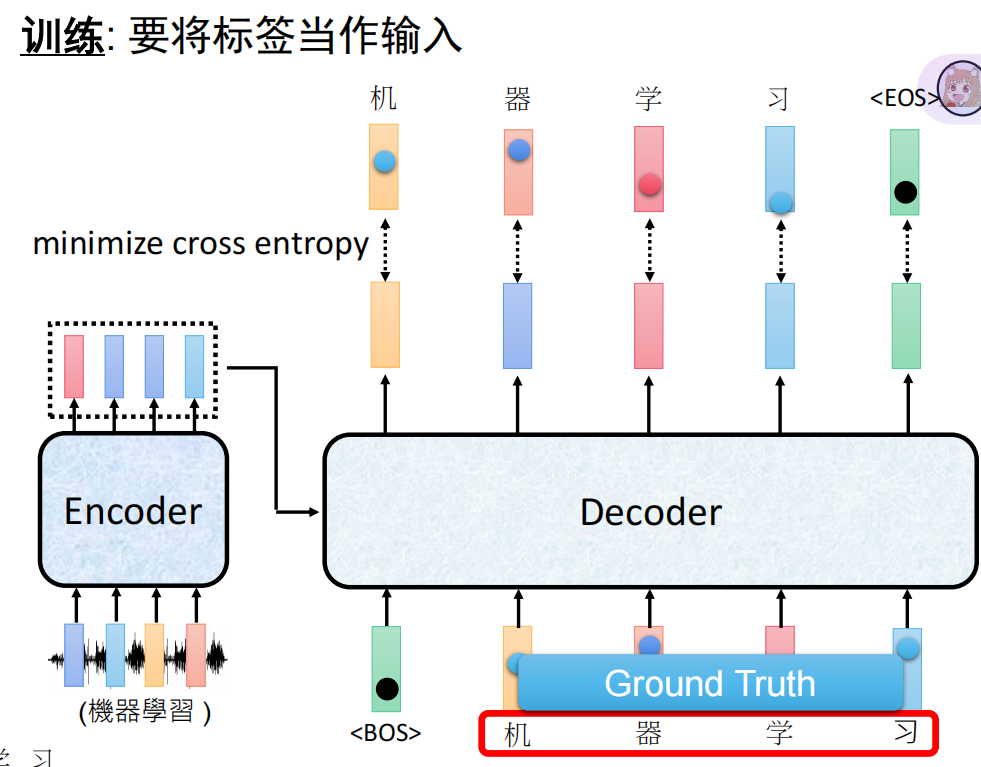
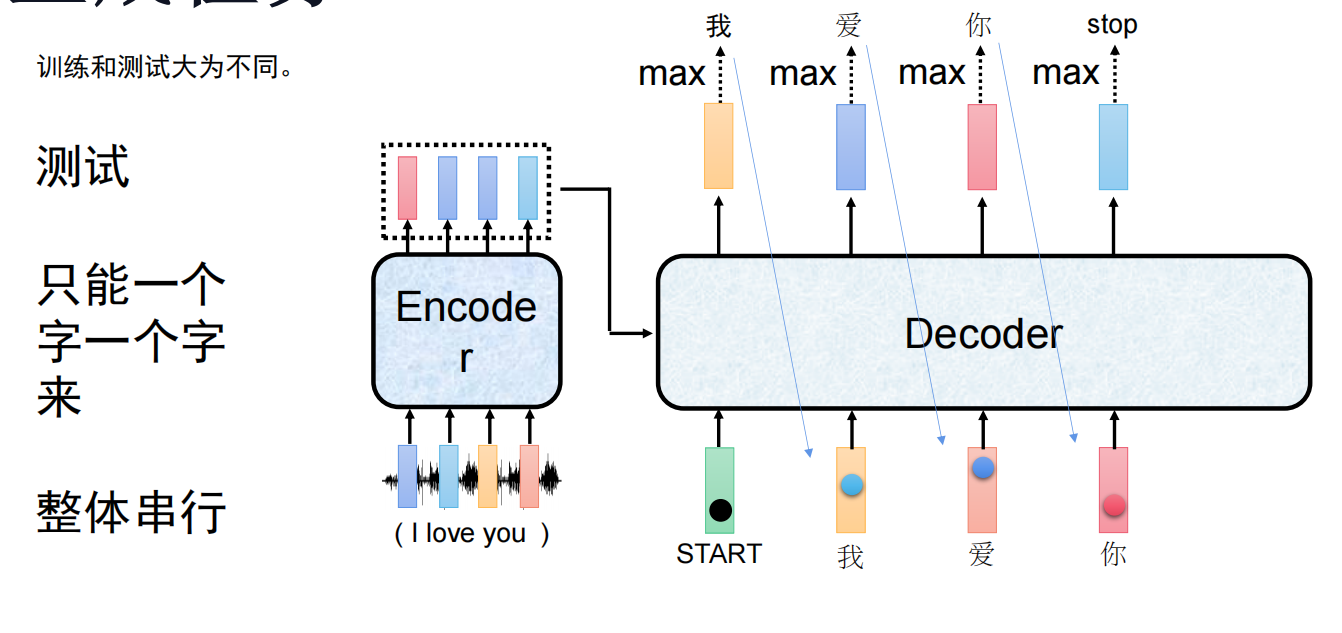
2. 推理时:Autoregressive (串行)
考试(测试/推理)时没有标准答案。模型必须“走一步看一步”。
-
生成
I-> 把I塞回去 -> 生成love-> 把love塞回去... -
劣势:无法并行,速度受限。
五、 大模型时代的优化:KV Cache & GQA
Q:既然推理是串行的,每次都要把历史重新算一遍吗? A:不需要!我们使用 KV Cache 技术。
-
原理:已经生成过的词(如前 99 个词),它们的 Key 和 Value 矩阵是固定的。我们把它存在显存里。
-
第 100 步:只计算第 100 个词的 Q,去和缓存里的 99 个 K 做注意力计算。
-
代价:显存爆炸。因为每一层(Layer)、每一个头(Head)都需要存一份独立的 KV 档案。
-
优化技术:GQA (Grouped Query Attention),让多个 Query 头共用一组 KV(例如 8 个头共用 1 组),大幅降低显存消耗。
-
六、 解码策略:如何不“捡了芝麻丢西瓜”?
模型输出的是概率分布,怎么选词?
-
Greedy Search (贪婪搜索):每一步只选概率最高的。
-
缺点:目光短浅,容易陷入局部最优,错过整体更好的句子。
-
-
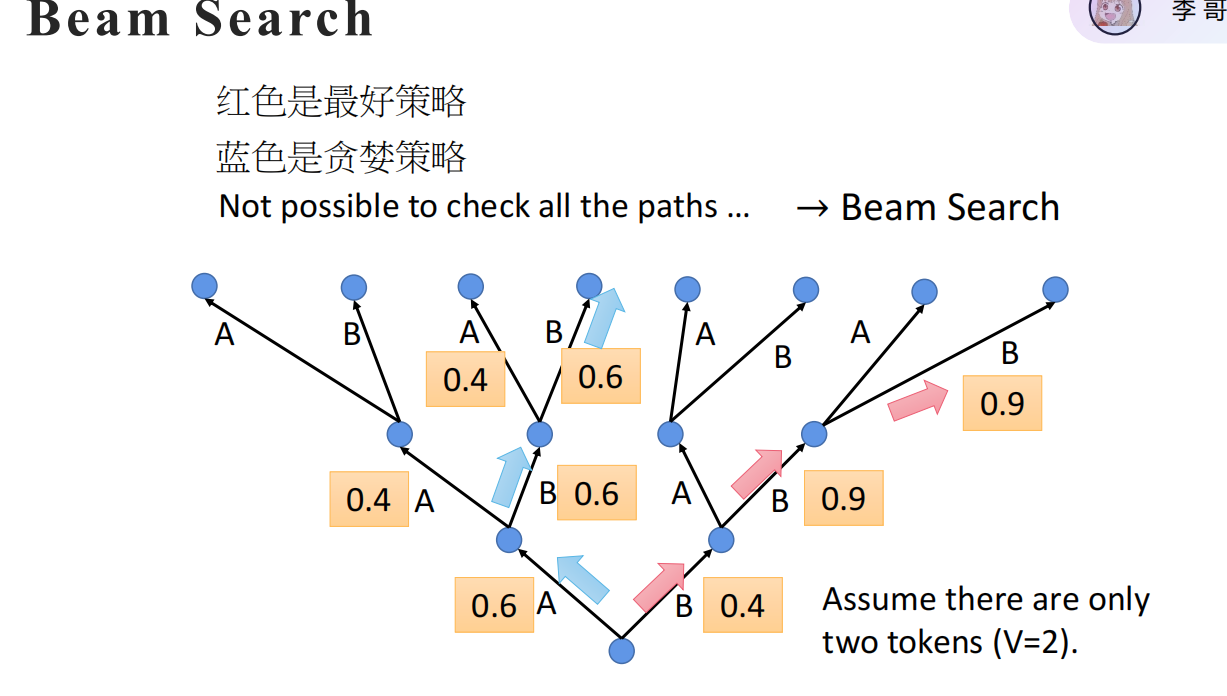
Beam Search (集束搜索):
-
原理:每一步保留 k个最优候选路径(Beam Width)。
-
就像树状结构搜索,虽然不能遍历所有路径,但保留了 k 种可能性,防止一步走错满盘皆输。
-
注:当 k=1时,Beam Search 退化为 Greedy Search。
-
导师总结 (复试高分话术)
如果老师问到 “Transformer 在生成任务中是如何工作的?为什么训练快推理慢?”,你可以这样回答:
“Transformer 通过 Encoder-Decoder 架构处理生成任务。Encoder 利用双向注意力理解全局语义,Decoder 利用 Masked Attention 保证自回归生成不泄露未来信息,并通过 Cross Attention 结合原文特征。值得注意的是,它在训练时利用 Teacher Forcing 实现了并行计算(一次算完所有 Loss);但在推理时是 自回归 (Autoregressive) 的,必须串行生成。为了解决长文本推理时的计算冗余,工业界普遍使用 KV Cache 技术来换取时间,并利用 GQA (分组查询注意力)技术来优化显存占用。”
什么是Cross Attention?
Cross Attention 是连接 Encoder 和 Decoder 的接口。它的 Query 来自 Decoder 的上一层输出,而 Key 和 Value 来自 Encoder 的最终输出。它的作用是让 Decoder 在生成每一个词时,都能根据当前的上下文,动态地关注输入序列中相关的部分(比如翻译“Love”时重点关注“爱”),从而实现信息的准确传递。
祝大家复试顺利,一战成硕!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 33
33 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)