【大模型入门】LangChain4j(ollma + 会话记忆、隔离、持久化 + RAG知识库 + Tools工具)
本文系统介绍了大模型部署与LangChain4j应用开发。主要内容包括:1)大模型两种部署方式(本地部署与API调用)及参数详解;2)LangChain4j框架开发,涵盖会话功能实现、流式调用、消息注解、会话记忆与隔离、持久化存储;3)RAG知识库原理与实现,包括文档加载/解析/分割、向量数据库操作;4)Tools工具开发,使大模型具备调用外部函数能力。通过完整案例演示了从基础对话到复杂业务场景的
目录
一、大模型部署与调用
大模型部署方式分为2种:
- 1、自己部署
- 云服务器部署
-
本地机器部署
- 2、他人部署(API调用模式)
-
阿里云百炼
-
百度智能云千帆大模型
-
硅基流动(Silicon Flow)
-
火山引擎(字节跳动)
-
1、本地部署
(1)ollma
Ollama 是一个开源工具,旨在简化大型语言模型(LLM)在本地计算机上的部署、运行和管理。它允许开发者和研究者在自己的机器上(无需依赖云端服务)快速启动和交互式使用各种主流开源模型,如 Llama 3、Mistral、Gemma 等。
ollma下载地址:
https://ollama.com/
https://ollama.com/
在官网下载对应系统的安装包,直接双击exe文件安装即可。
在左上角Models可以选择想要部署的大模型
在这里我们选择部署【千问】
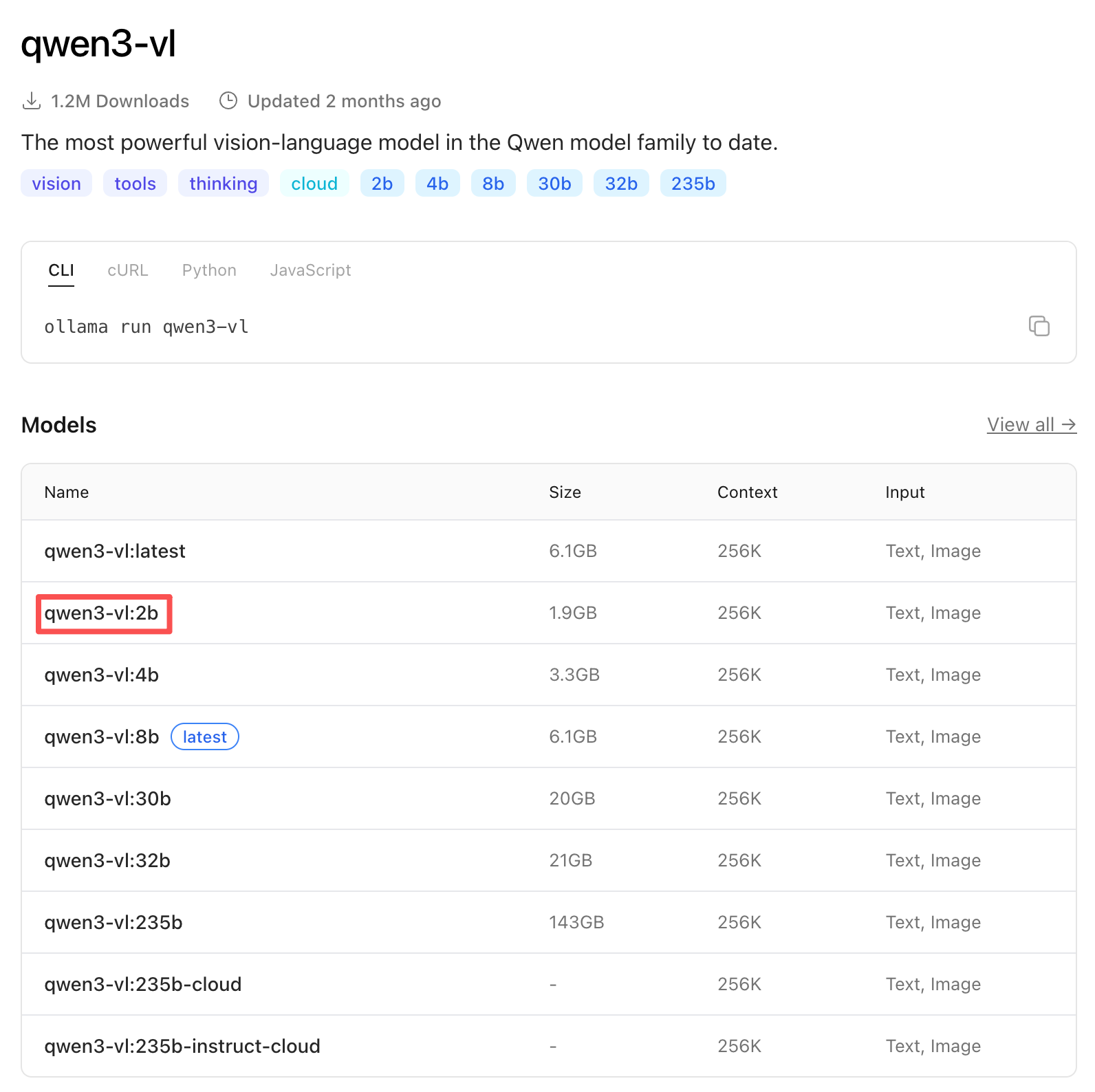
- 这里的 “b” 是模型参数量级的单位,代表 “Billion”(十亿)。
- 在 AI 模型中,模型的名称通常通过“数字 + b”的形式来表示其参数规模,例如:
qwen3-vl:2b → 约 20 亿参数
qwen3-vl:4b → 约 40 亿参数
qwen3-vl:8b → 约 80 亿参数
- b 与模型大小直接相关:通常参数越多,模型能力越强,但对计算资源(GPU 内存、算力)要求也越高。
为了方便,我们选择参数最小的qwen3-vl:2b
复制命令
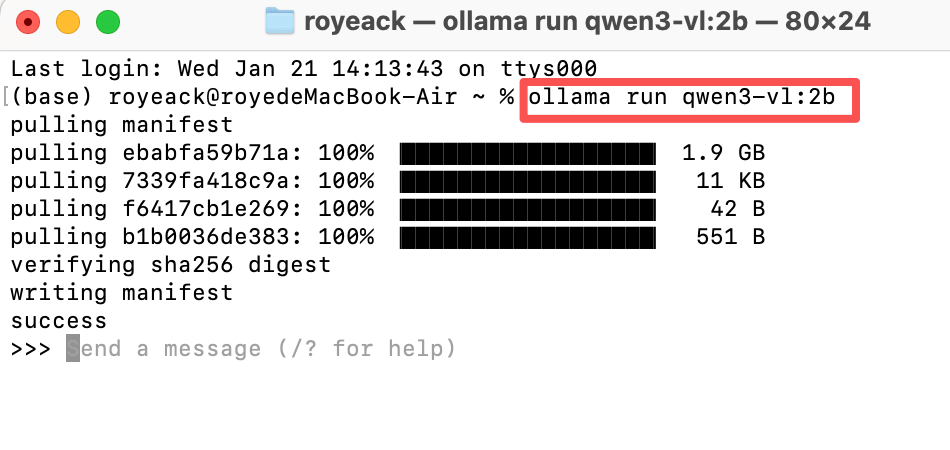
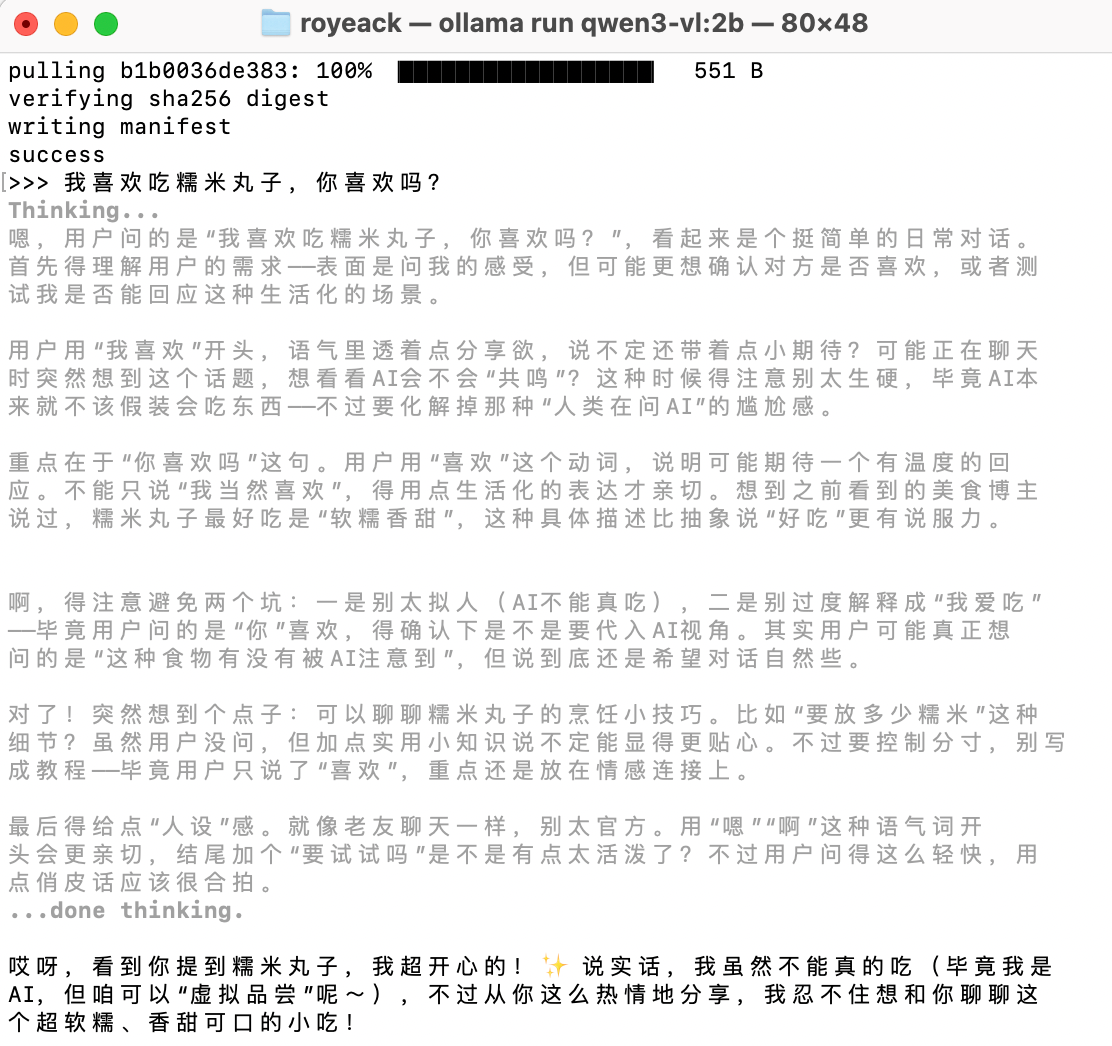
打开系统终端,粘贴回车运行
成功后输入你想问的问题,部署的qwen3就会回答你
如果想要关闭对话,输入/bye即可,下次还想打开对话,输入ollama run qwen3-vl:2b即可回到对话。
(2)通过api访问大模型
下载一个支持发送请求的软件(如:Apifox、postman)
刚才下载大模型的页面拉到最下面,有一个Blog选项,点击进入
在Blog页面往下滑,找到Thinking点击进入
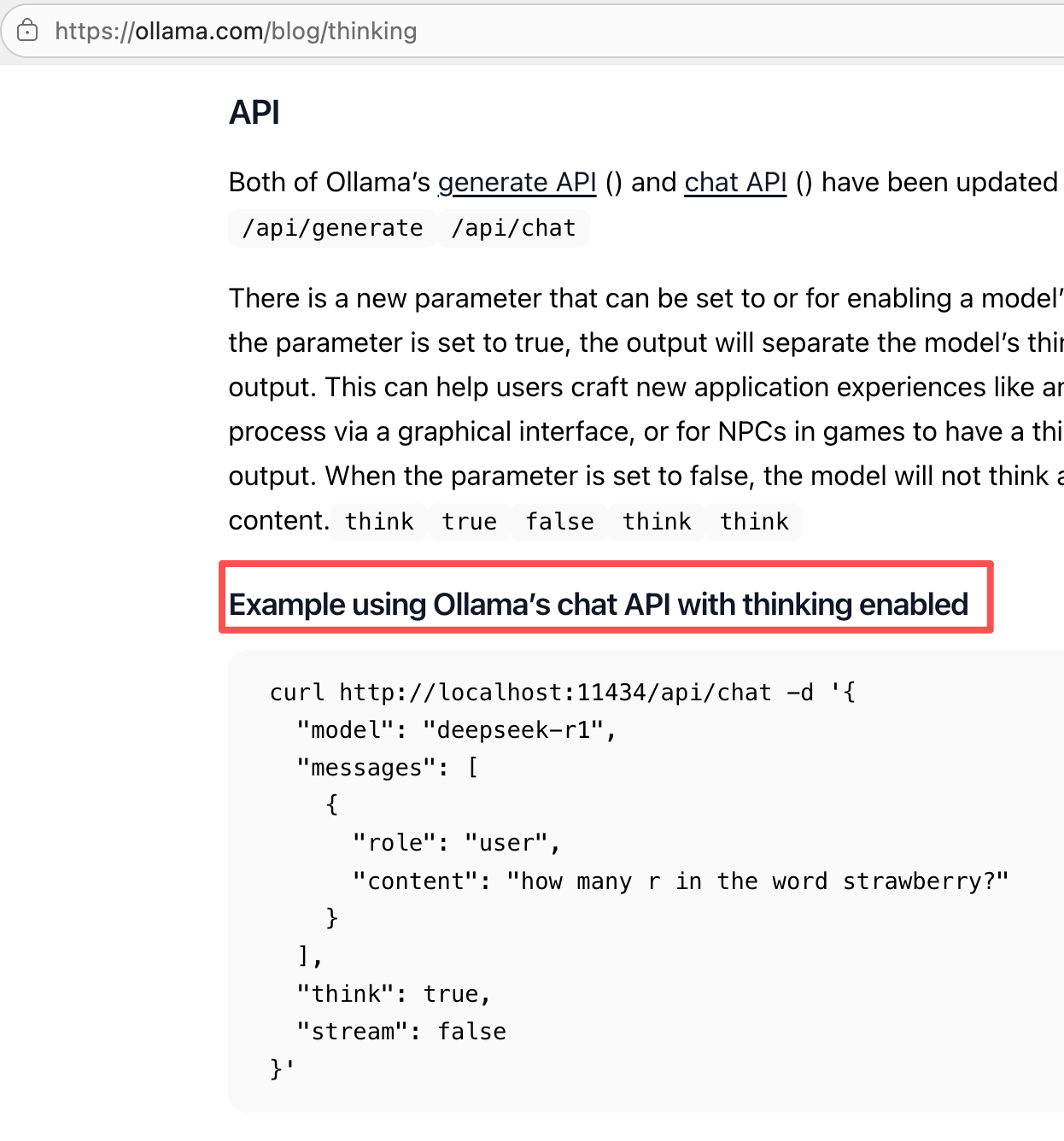
找到API这一部分内容
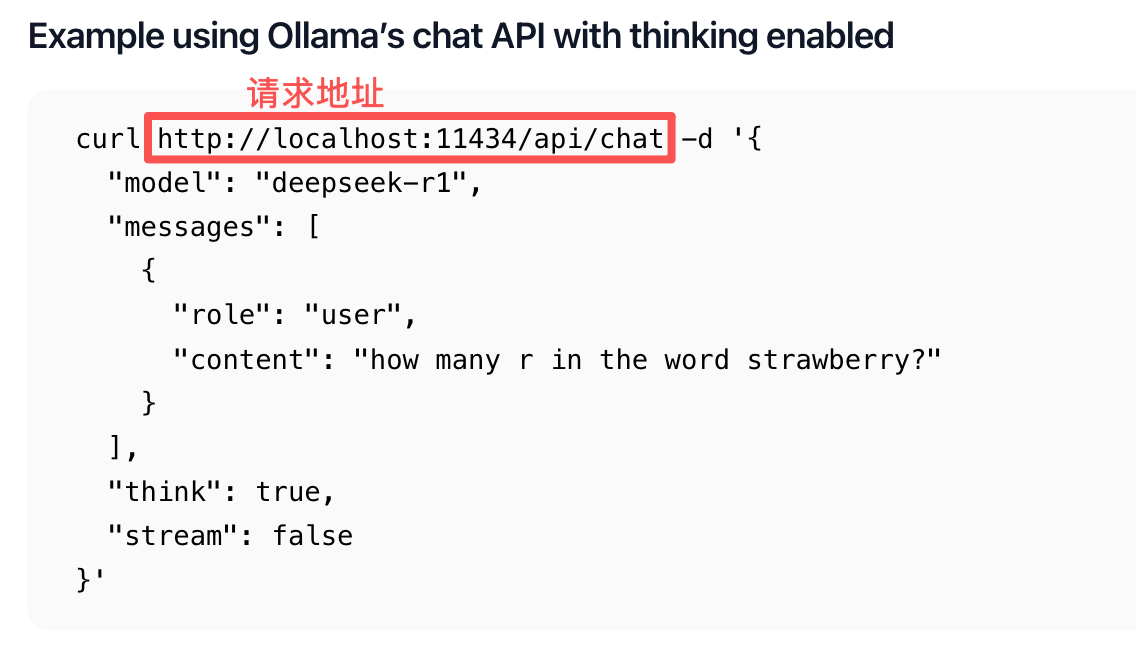
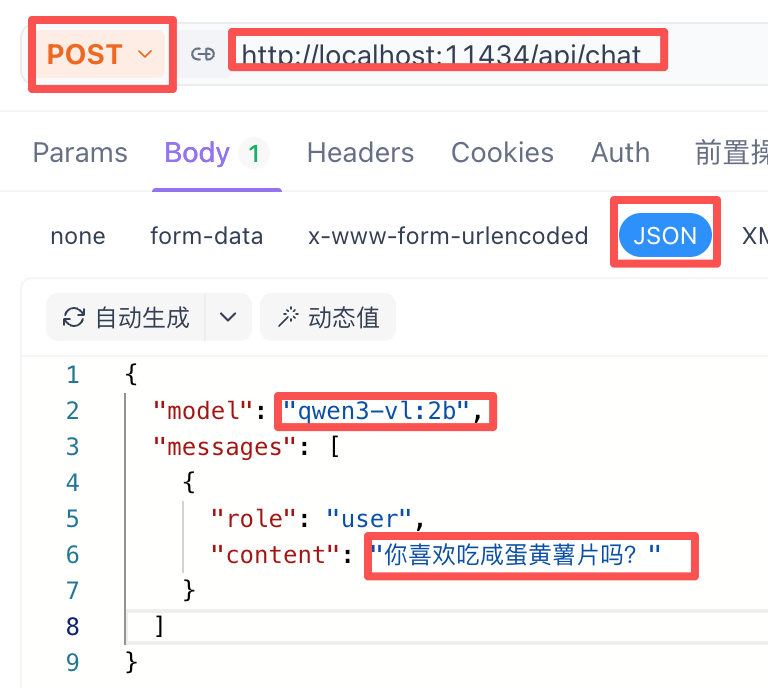
将请求地址粘贴到Api工具中,请求类型为POST,接着把请求内容粘贴至Body --> JSON中
curl http://localhost:11434/api/chat -d '{ "model": "deepseek-r1", "messages": [ { "role": "user", "content": "how many r in the word strawberry?" } ], "think": true, "stream": false }'
点击发送,就可以看到AI的回答

2、他人部署
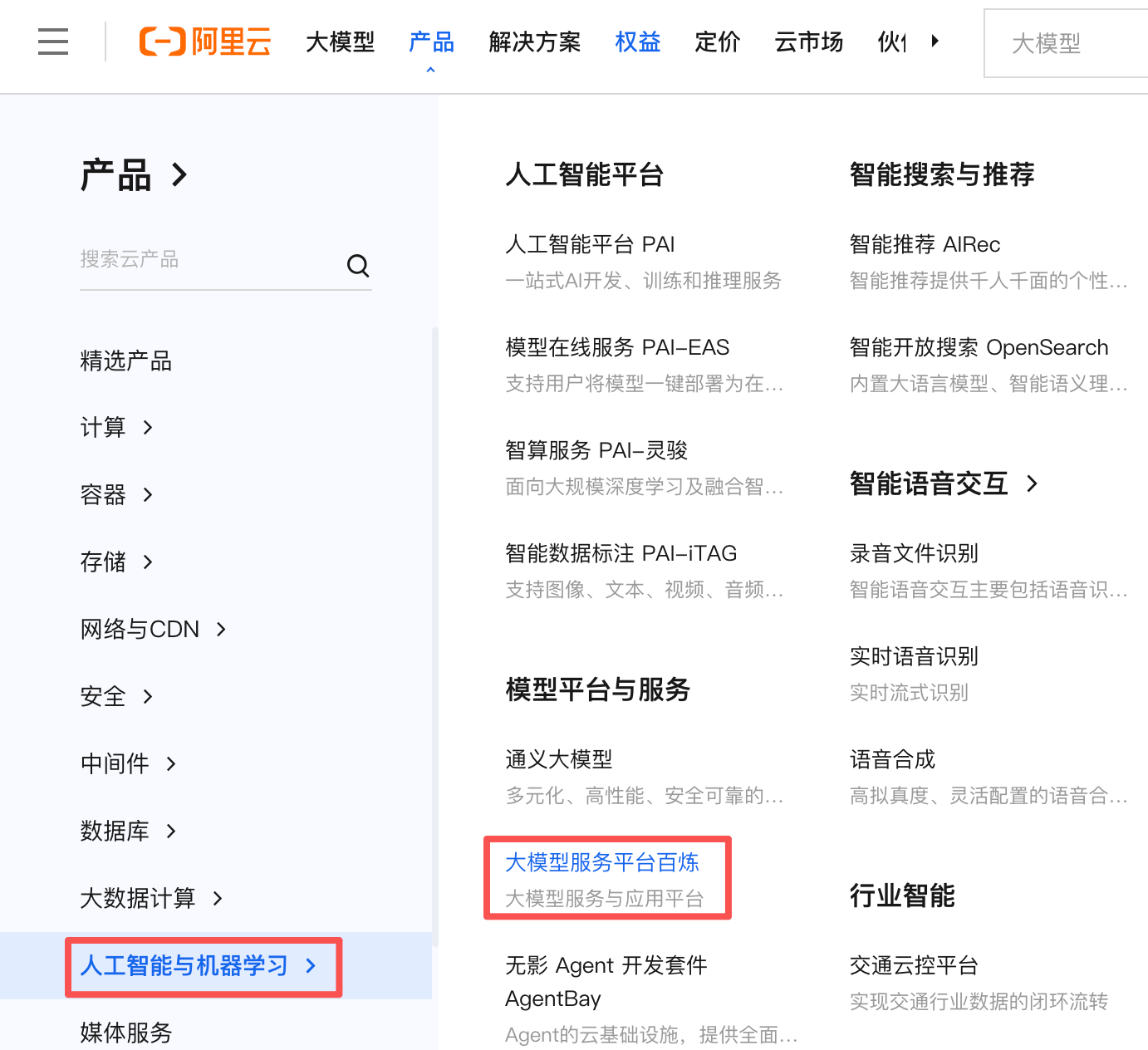
他人部署方式即依赖平台提供的Api进行调用,这里我们以【阿里云百炼】为例。
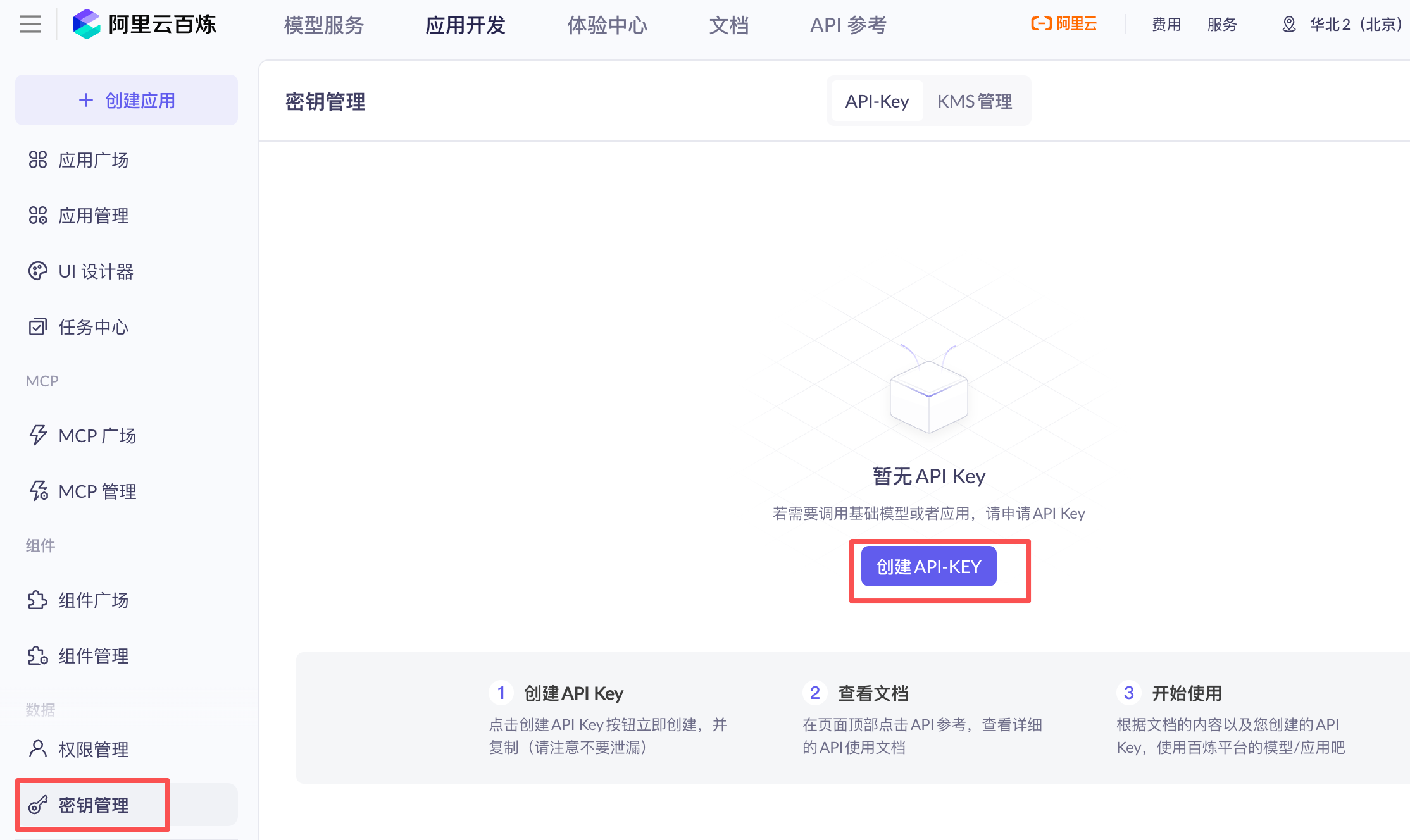
首先登录阿里云,在主页的【产品】→【人工智能与机器学习】→【大模型服务平台百炼】
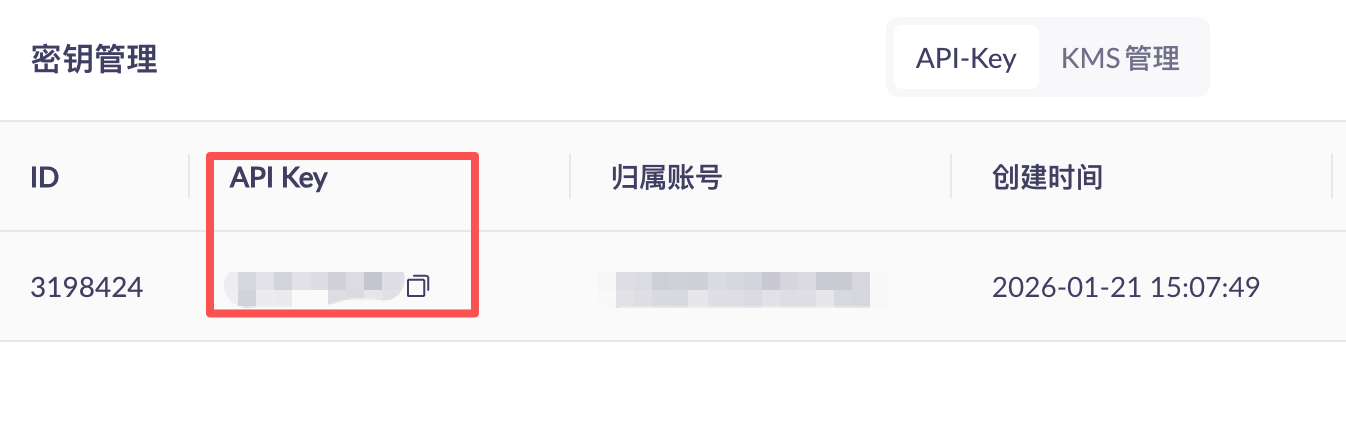
点击【密钥管理】→【创建API-KEY】
创建好API Key后复制
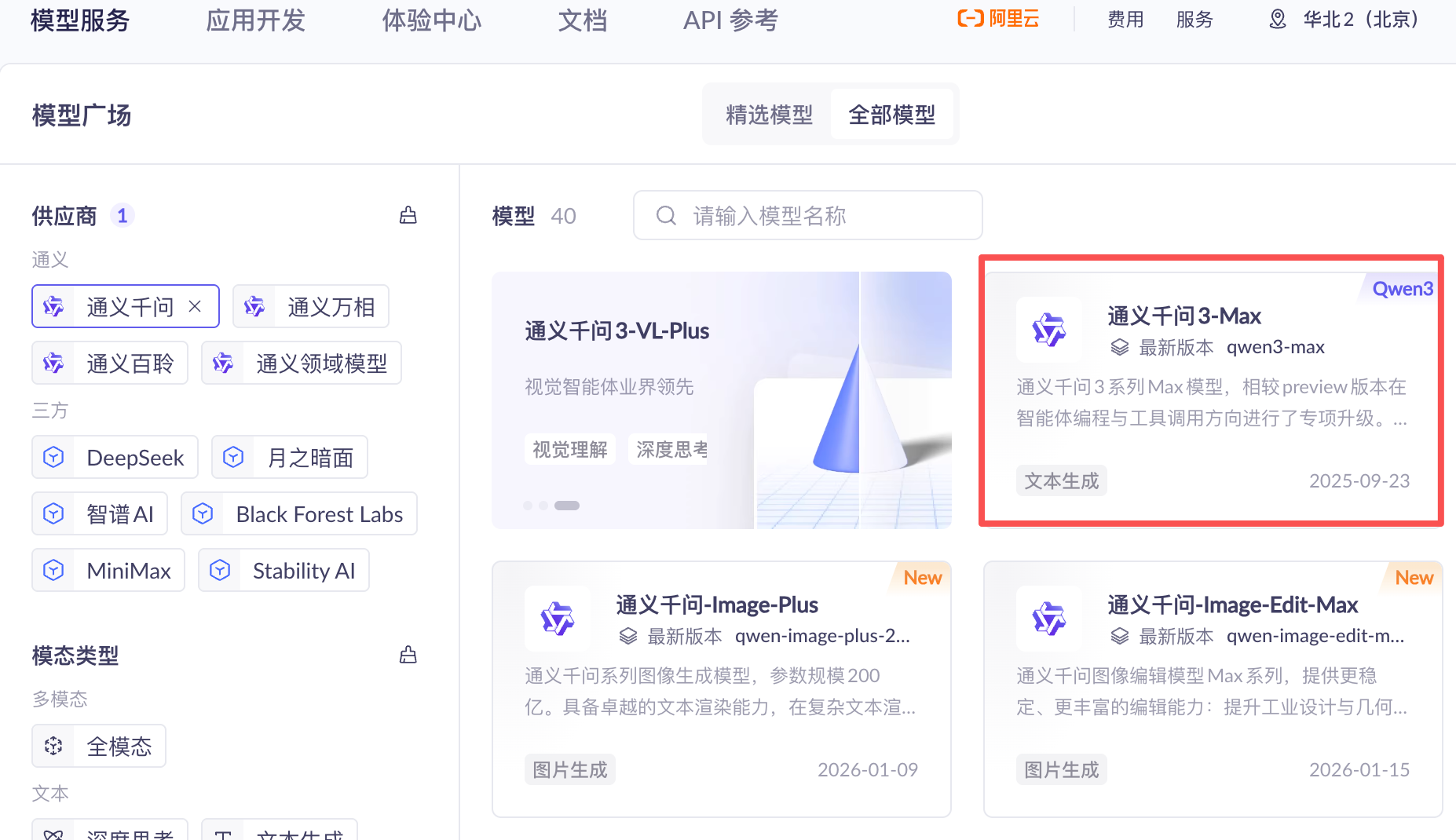
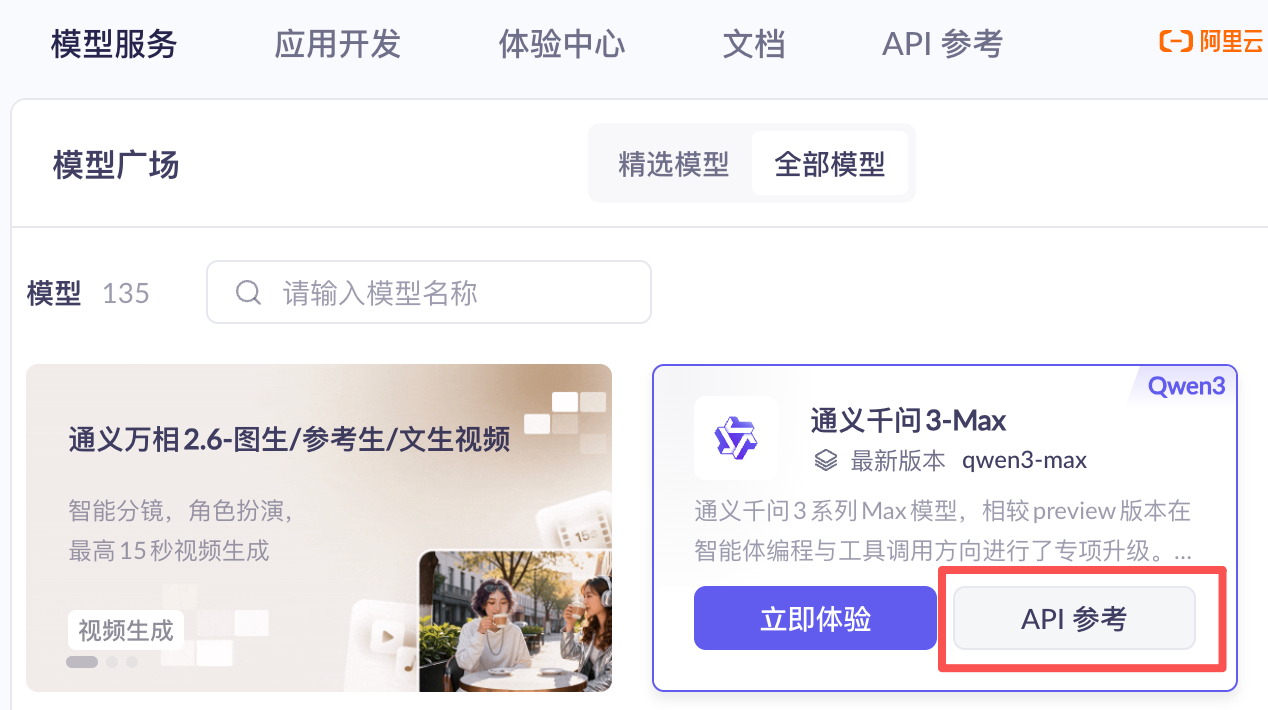
我们在模型广场上找一个模型
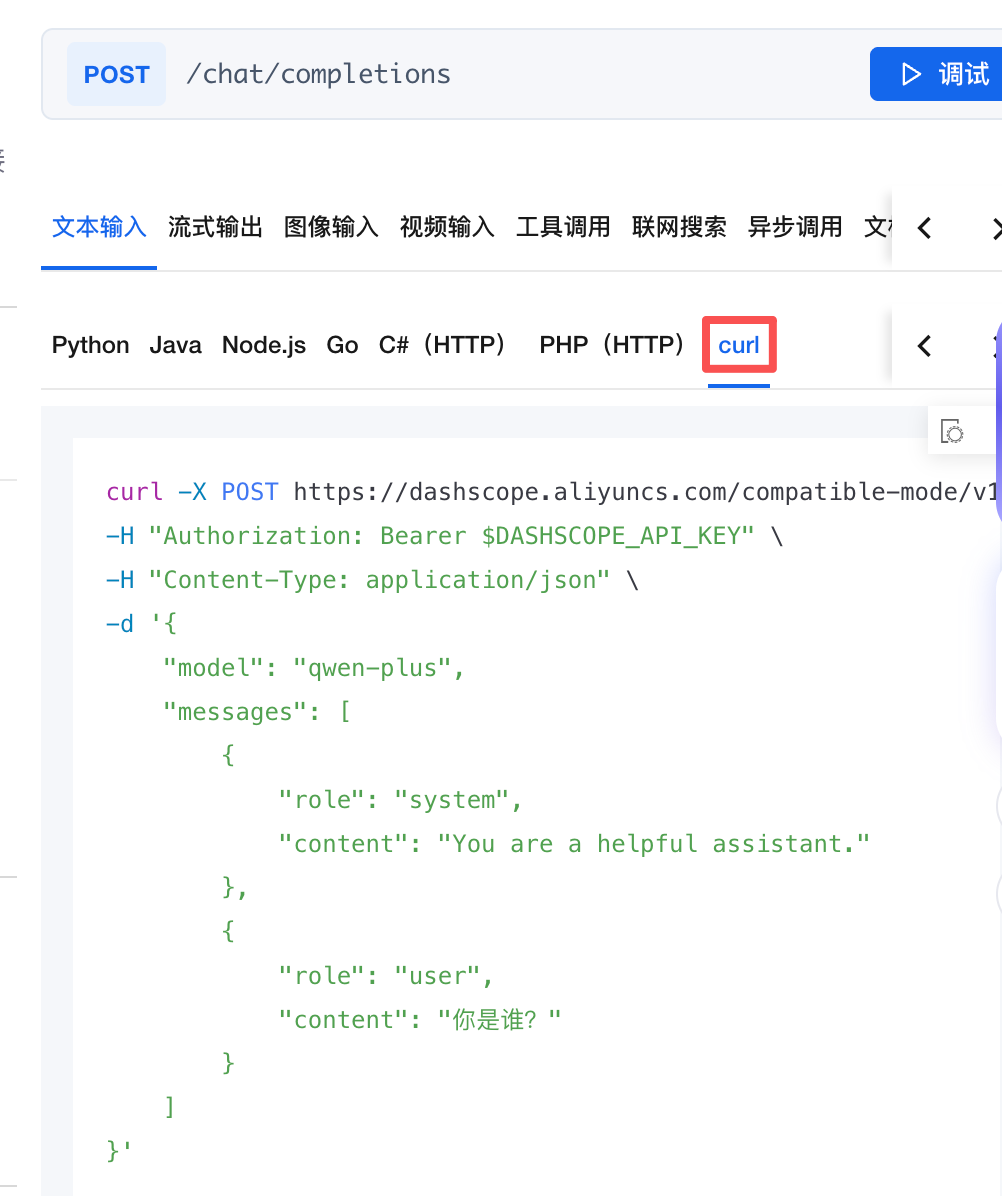
点击API参考,进入页面后找到Api接口信息
和前面本地部署类似,将请求地址复制到Apifox,请求体选择JSON
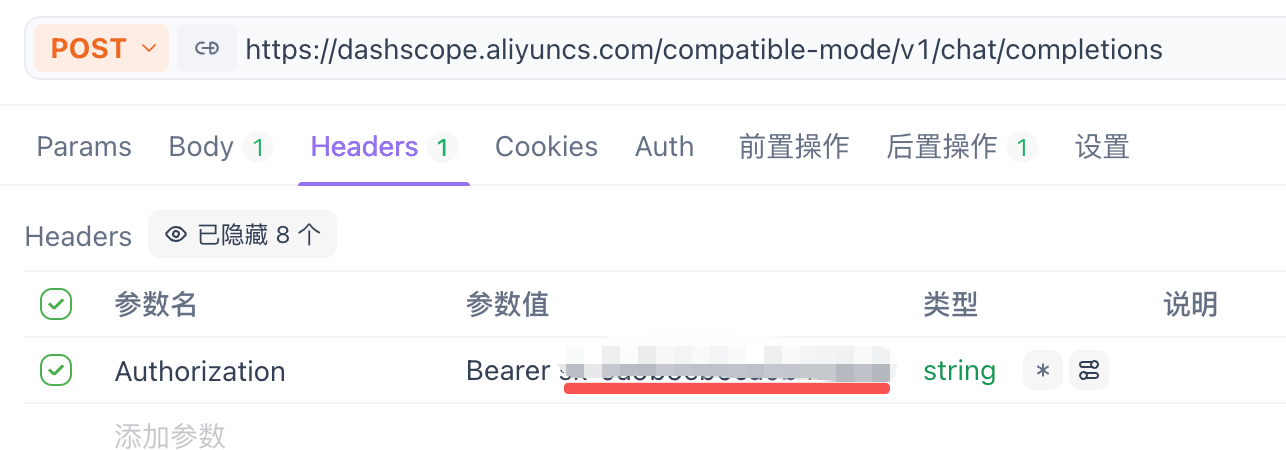
注意:请求头Headers,填入我们刚刚创建的API Key(注意别忘了Bearer)
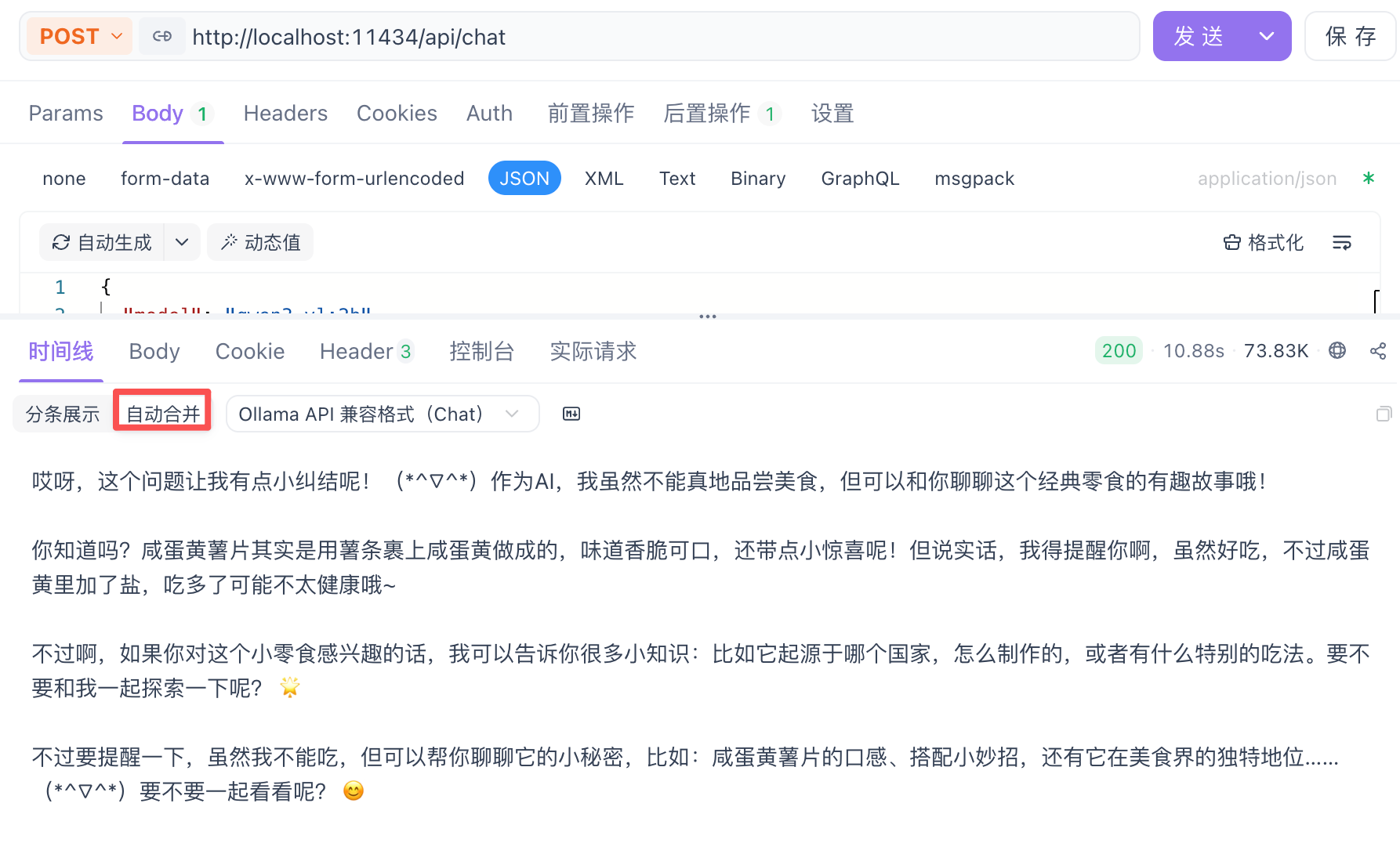
点击发送
成功部署!
3、大模型参数详解
接下来我们将详细解释并演示大模型各个参数的作用。
(1)调用参数
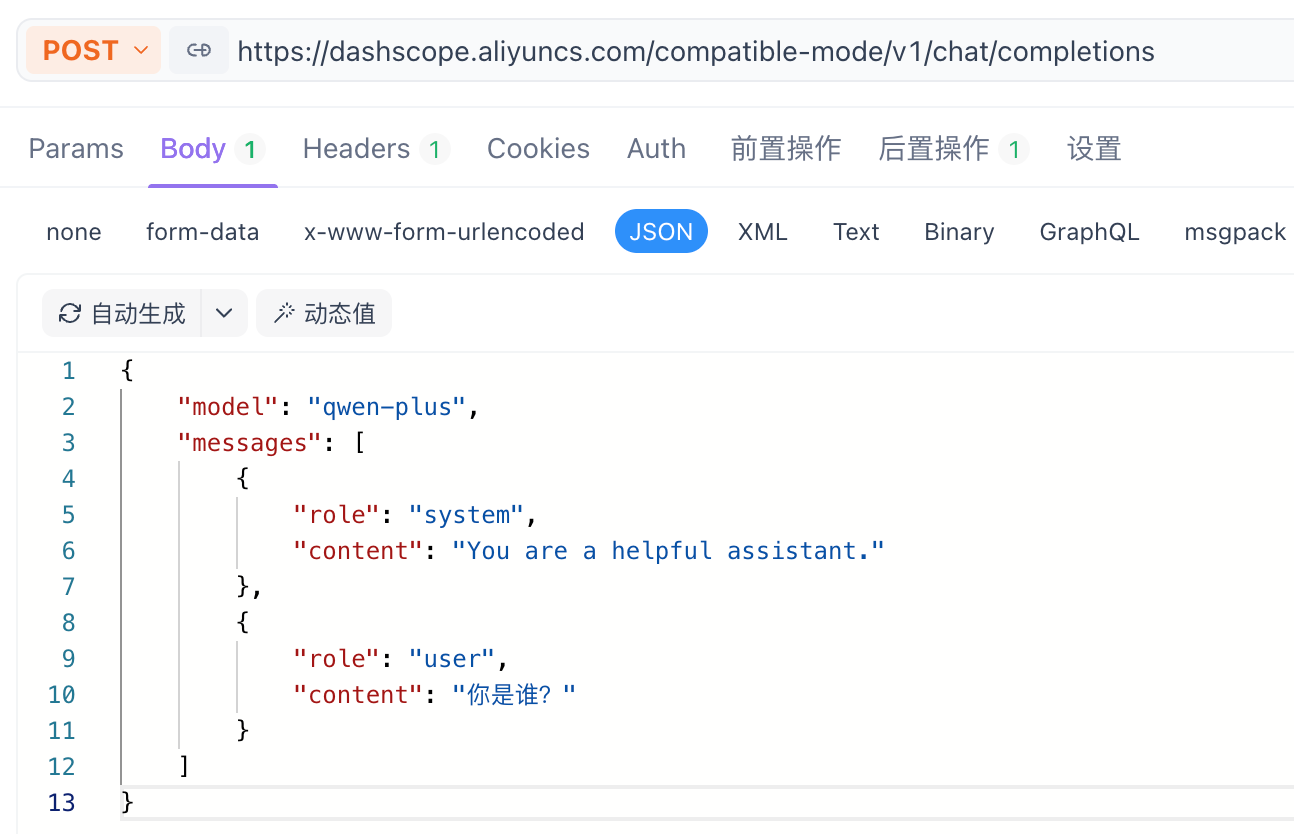
curl -X POST https://dashscope.aliyuncs.com/compatible-mode/v1/chat/completions \ -H "Authorization: Bearer $DASHSCOPE_API_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "qwen-plus", "messages": [ { "role": "system", "content": "You are a helpful assistant." }, { "role": "user", "content": "你是谁?" } ] }'【1】model:告诉平台,当前调用的是哪个模型
【2】messages:发送给大模型的数据,大模型会根据这些数据给出合适的响应
- content:消息内容
- role:角色类型
- user:用户消息
- system:系统消息
- assistant:模型响应消息
① user:当role为user时,content种输入的内容将被作为提问文本,大模型会根据content的内容进行回答。
② system:设定大模型的定位,比如:请以一名老师的身份回答用户的问题、请以一名歌手的身份回答用户问题……
③ assiant:每一次发送请求,大模型都会独立回答用户问题,而无法联系上下文,比如:
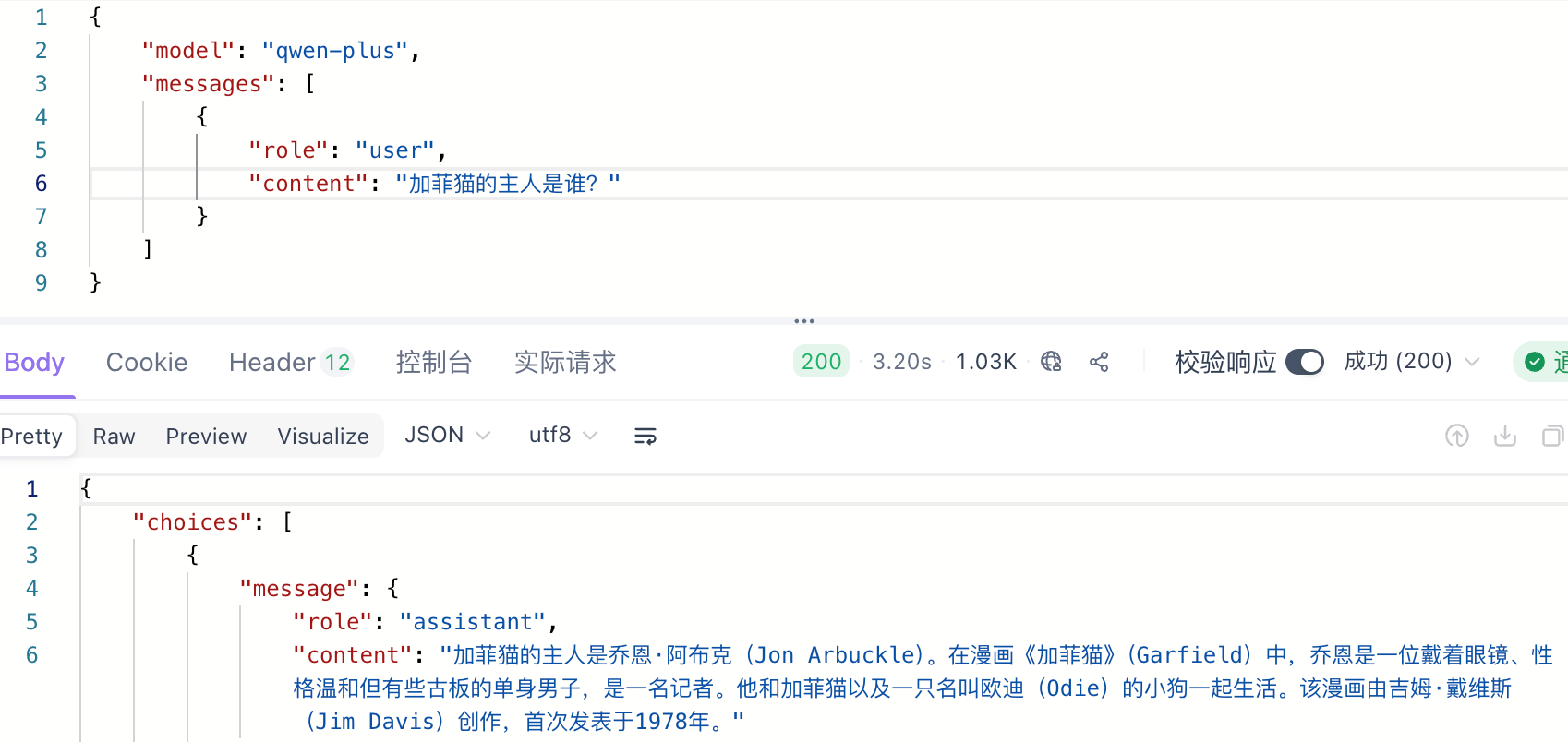
问:加菲猫的主人叫什么?大模型的回答是:是乔恩
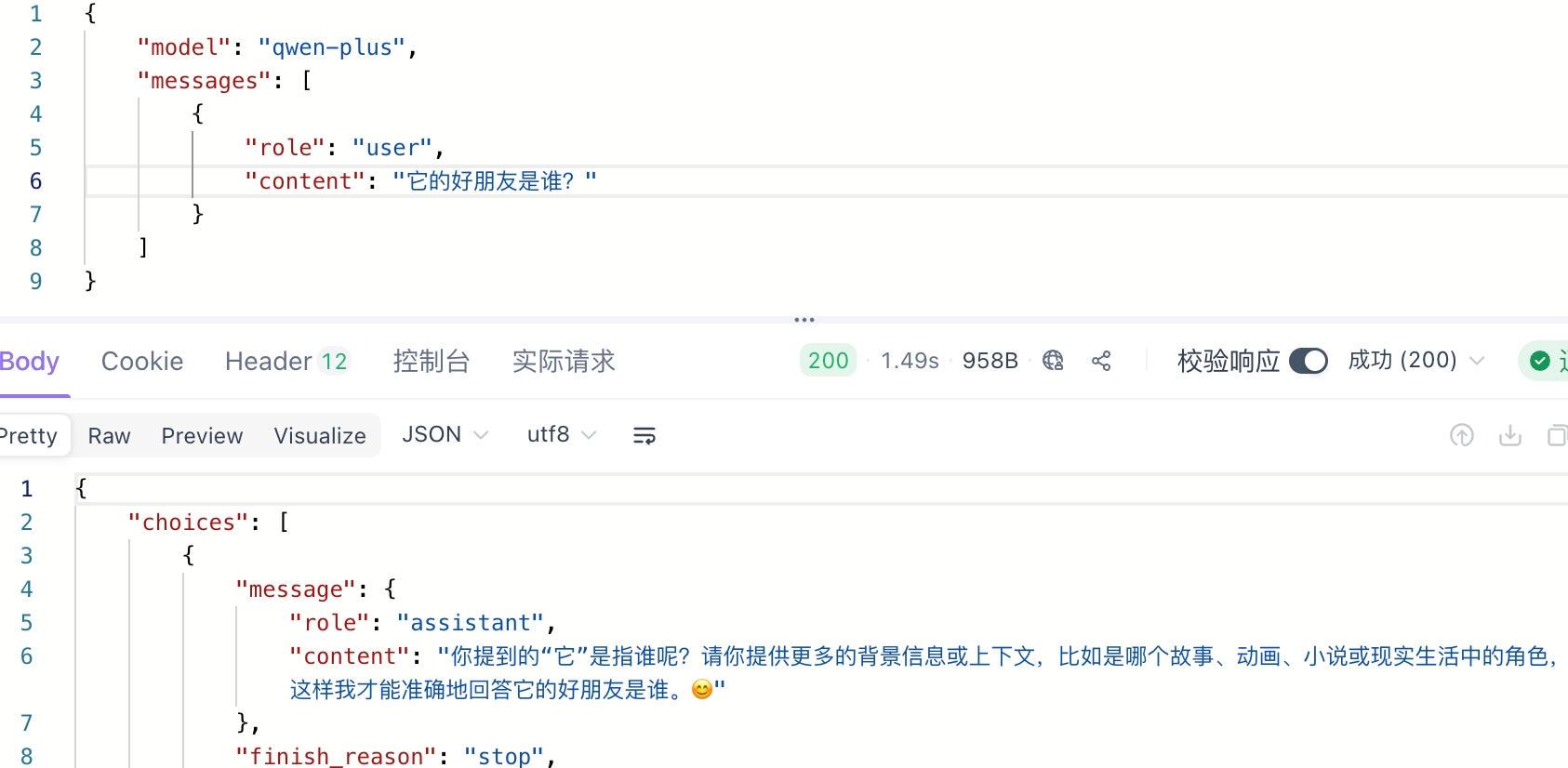
但如果你紧接着问:它的好朋友是谁?大模型就会疑惑:你说的它指的是谁?
这就证明了调用Api接口时,大模型是没有联系上下文能力的。
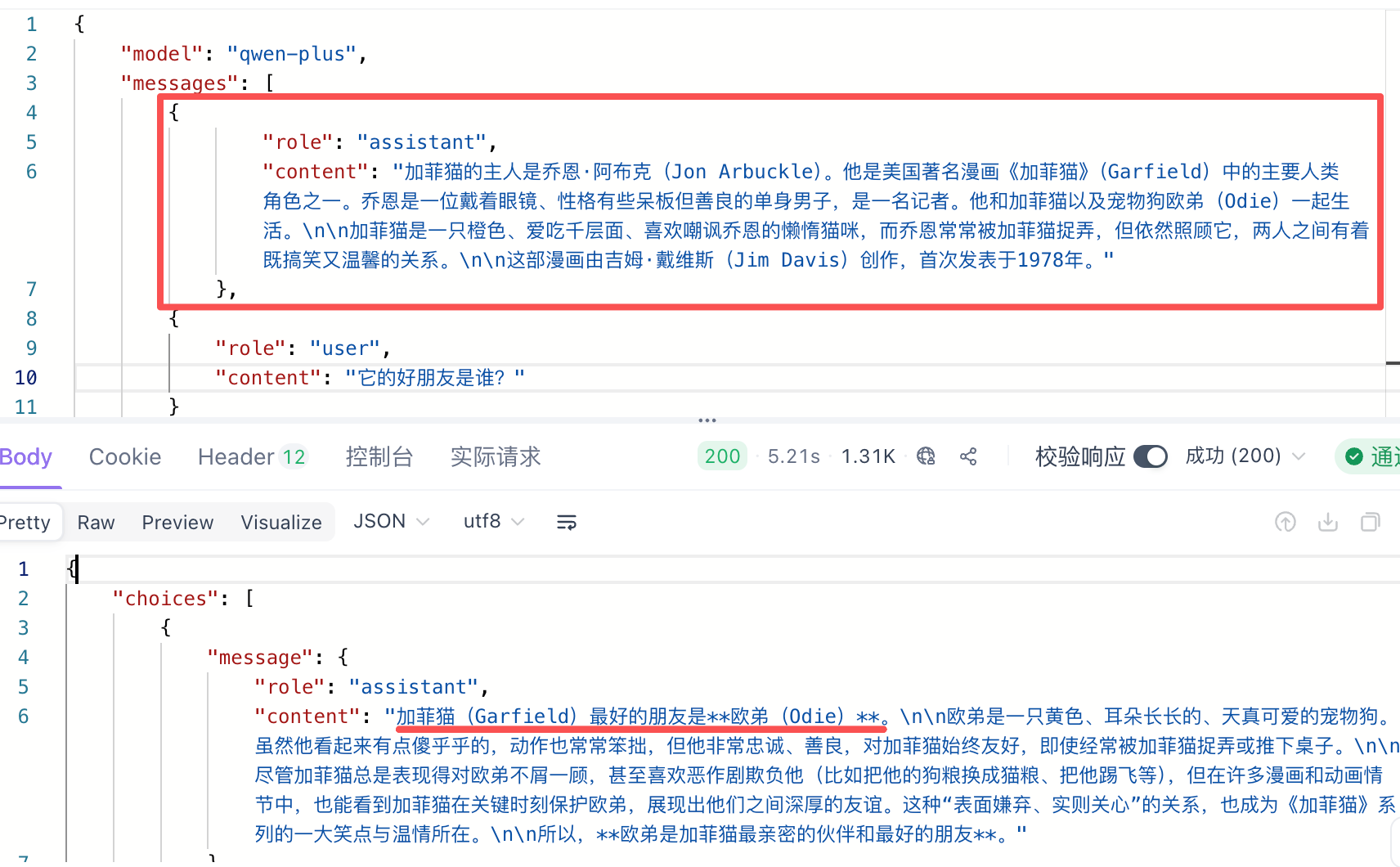
而assiant的作用是告诉大模型上下文,这样他就能正确回答问题了。
【3】stream:调用方式
- true:非阻塞调用(流式调用)—— 一点一点回答问题,一个词一个词往外蹦
- false:阻塞调用(一次性响应),默认值 —— 一次性生成答案
【4】enable_search:联网搜索。启用后,模型会将搜索结果作为参考信息
- true:开启
- false:关闭(默认)
(2)响应参数
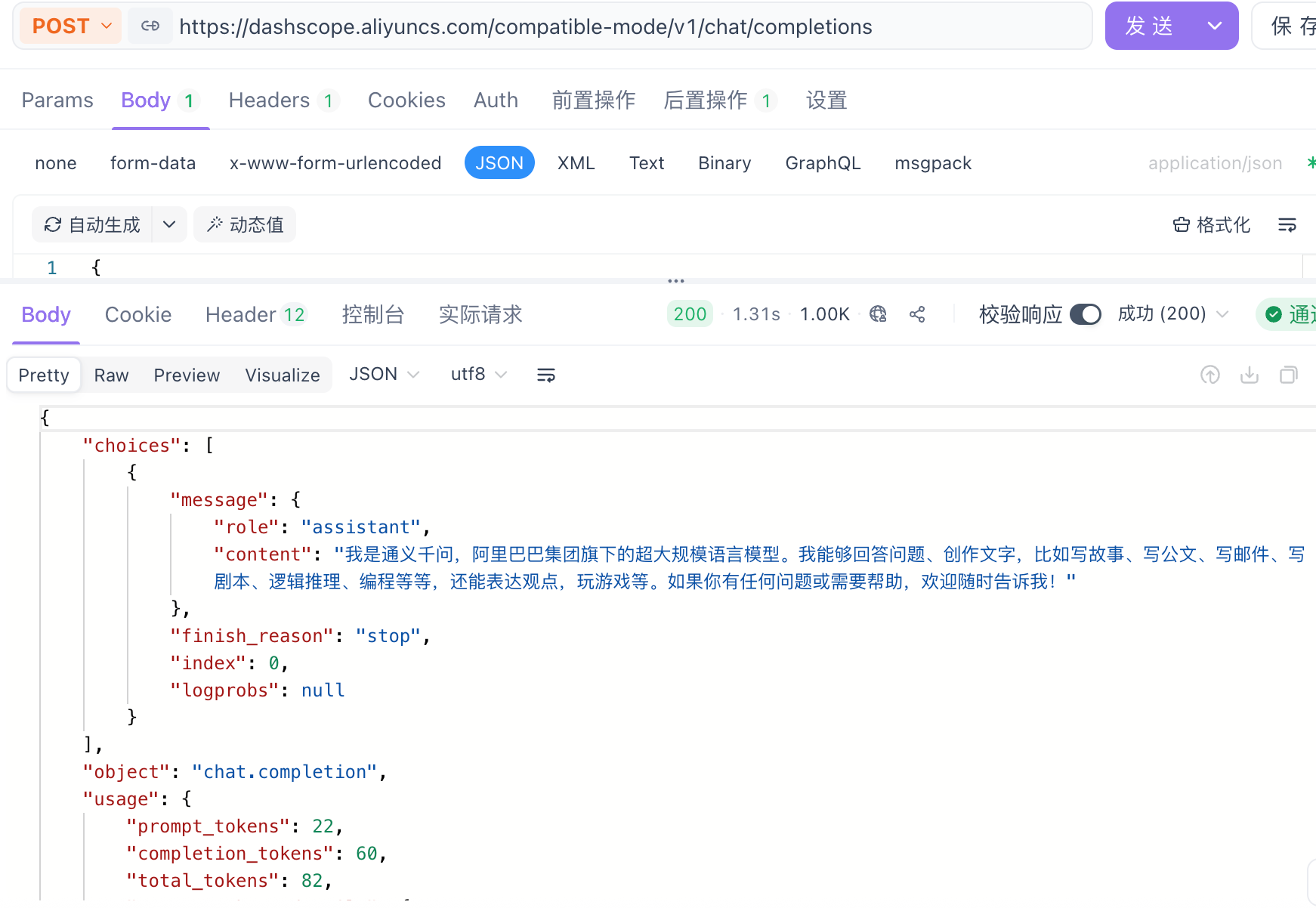
{ "choices": [ { "message": { "role": "assistant", "content": "加菲猫(Garfield)最好的朋友是**欧弟(Odie)**。\n\n欧弟是一只黄色、耳朵长长的、天真可爱的宠物狗。虽然他看起来有点傻乎乎的,动作也常常笨拙,但他非常忠诚、善良,对加菲猫始终友好,即使经常被加菲猫捉弄或推下桌子。\n\n尽管加菲猫总是表现得对欧弟不屑一顾,甚至喜欢恶作剧欺负他(比如把他的狗粮换成猫粮、把他踢飞等),但在许多漫画和动画情节中,也能看到加菲猫在关键时刻保护欧弟,展现出他们之间深厚的友谊。这种“表面嫌弃、实则关心”的关系,也成为《加菲猫》系列的一大笑点与温情所在。\n\n所以,**欧弟是加菲猫最亲密的伙伴和最好的朋友**。" }, "finish_reason": "stop", "index": 0, "logprobs": null } ], "object": "chat.completion", "usage": { "prompt_tokens": 167, "completion_tokens": 178, "total_tokens": 345, "prompt_tokens_details": { "cached_tokens": 0 } }, "created": 1768984559, "system_fingerprint": null, "model": "qwen-plus", "id": "chatcmpl-7b4d095e-afb7-9273-b862-c0cc17e3ec6a" }
- choices:
- message:本次调用模型输出的消息
- finish_reason:
- stop:自然结束
- length:生成内容过长
- index:当前内容在choices数组中的索引
- object:始终为chat.completion,无需关注
- 本次对话过程中使用的token信息usage:
- prompt_tokens:用户的输入转换成token的个数
- completion_tokens:模型生成的回复转换成token的个数
- total tokens:用户输入和模型生成的总token个数
- created:本次会话被创建时的时间戳
- system_fingerprint:固定为null,无需关注
- model:本次会话使用的模型名称
- id:本次调用的唯一标识符
- 在大语言模型中,Token是大模型处理文本的基本单位可以理解为模型【看得懂】的最小文本片段
- 用户输入的内容都需要转换成token,才能让大模型更好的处理
- 英文:1个token ≈ 4个字符
- 中文:1个汉字 ≈ 1~2个token
二、LangChain4j
1、会话功能
(1)快速入门
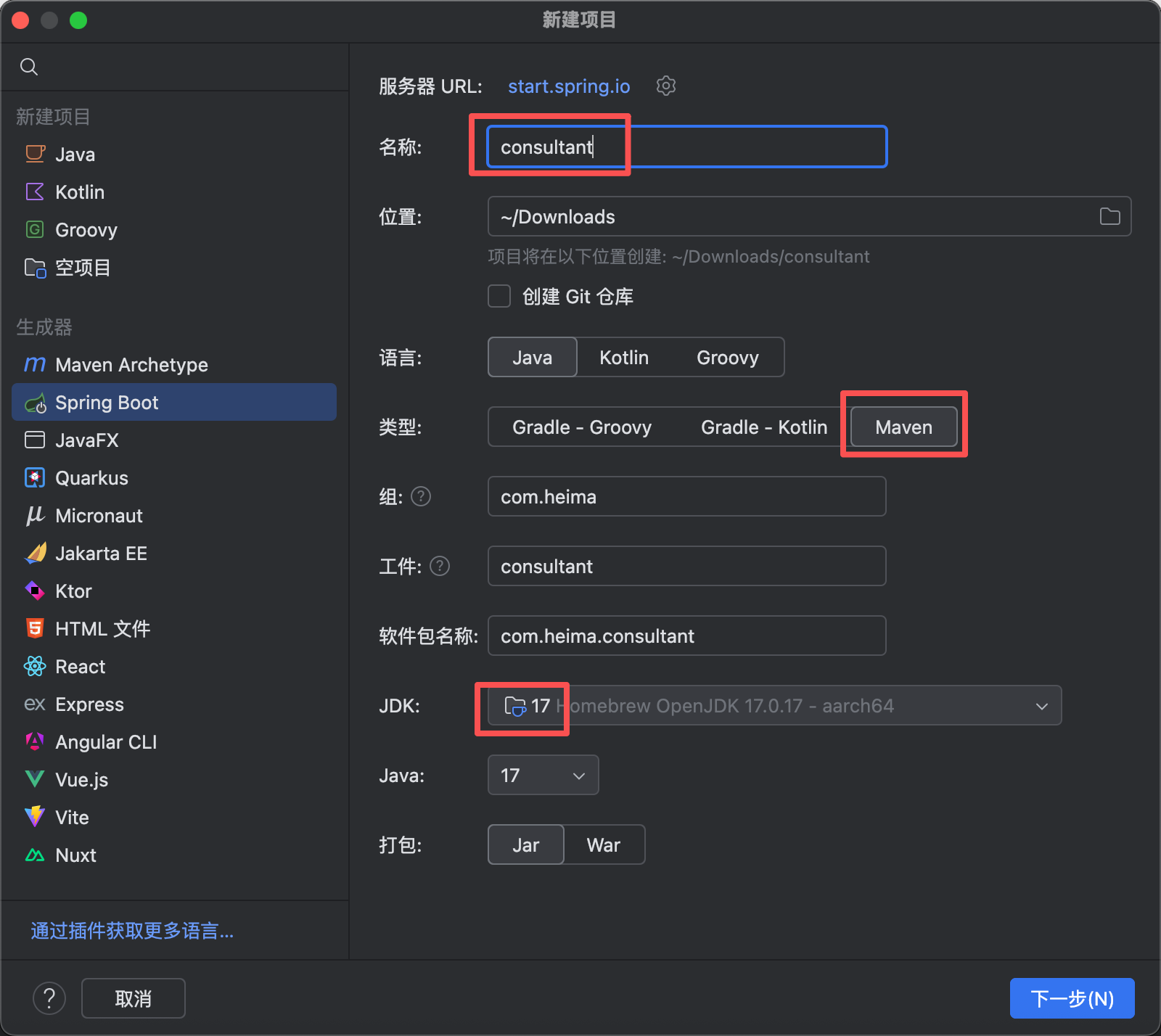
【1】首先创建一个Maven项目
【2】引入依赖
<!--langchain4j依赖--> <dependency> <groupId>dev.langchain4j</groupId> <artifactId>langchain4j-open-ai</artifactId> <version>1.10.0</version> </dependency>【3】配置API Key环境变量
我用的是mac,下面演示mac系统如何配置环境变量。
终端输入下面指令
# 1. 打开配置文件 nano ~/.zshrc # 2. 在文件末尾添加 export OPENAI_API_KEY="你的API密钥" # 3. 保存并退出(Ctrl+X → Y → Enter) # 4. 重新加载配置 source ~/.zshrc验证配置:
echo $OPENAI_API_KEY # 应显示你的密钥注意:环境变量需要重启IDEA才会生效,所以现在重启一下我们的IDEA。
【4】构建OpenAiChatModel对象
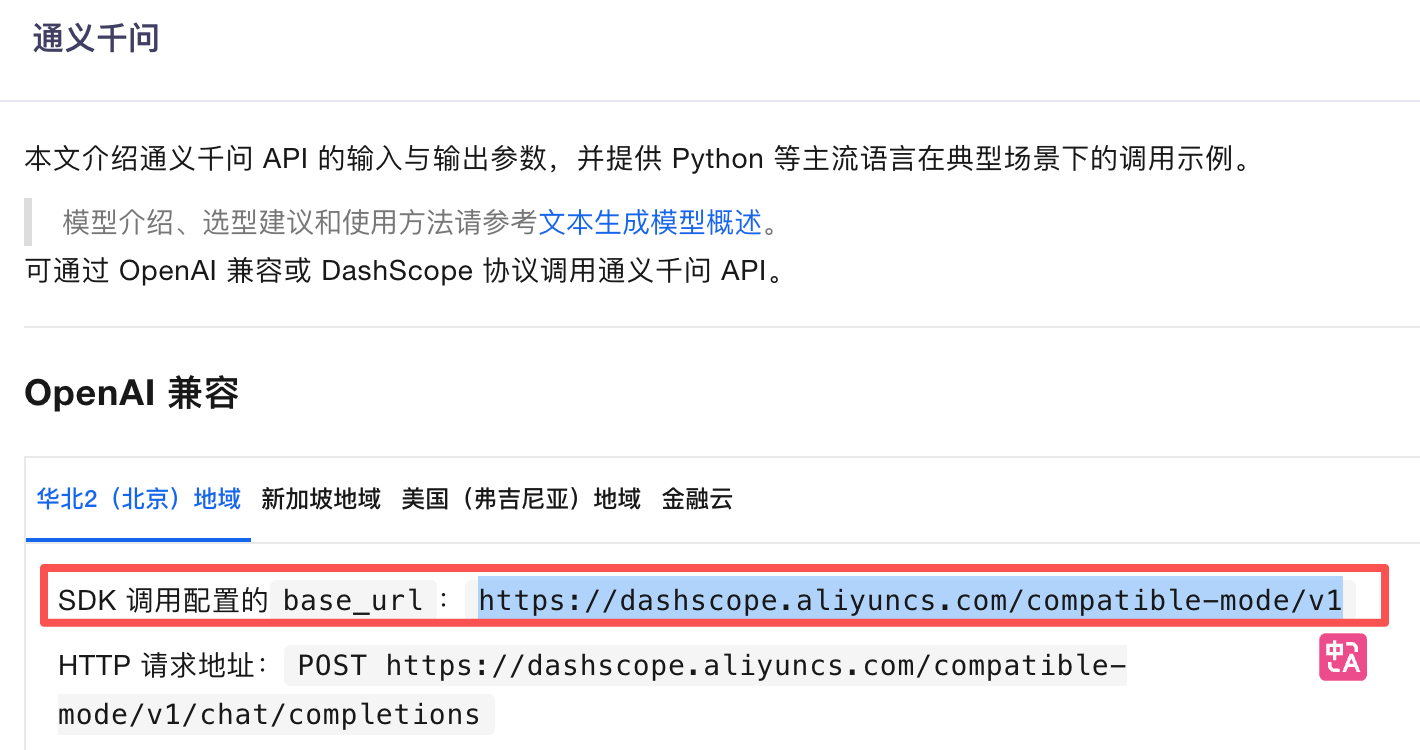
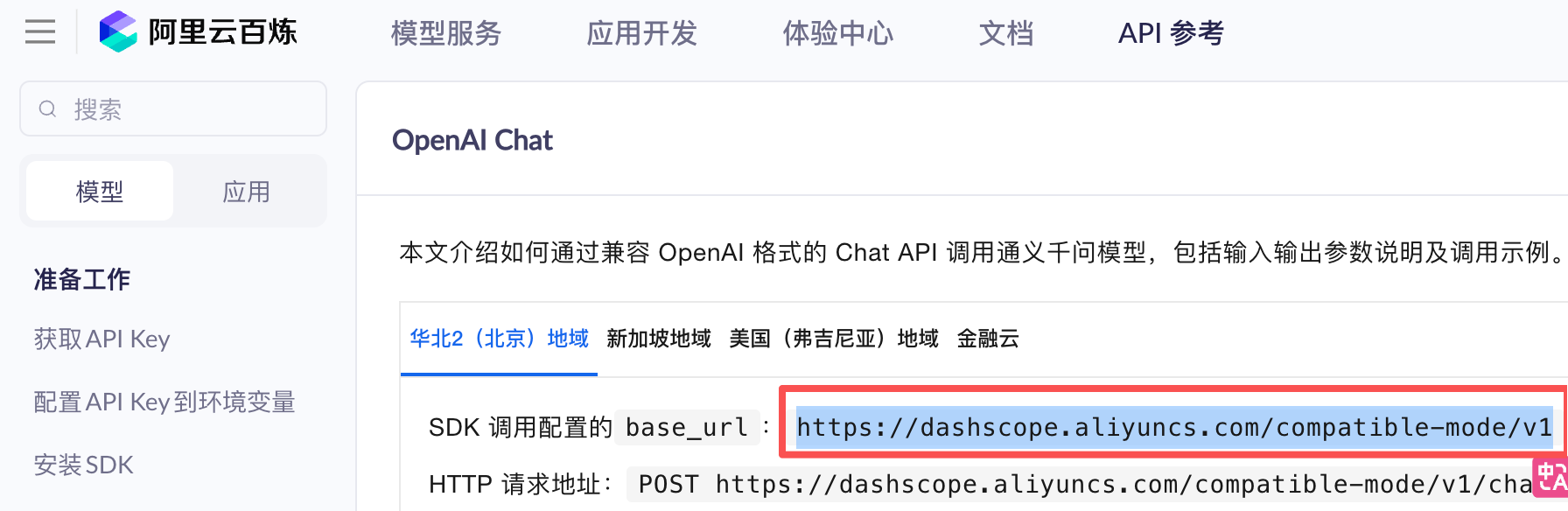
在平台找到想要调用的大模型的SDK调用配置地址
将配置一一填入
// 构建OpenAiChatModel对象 OpenAiChatModel model = OpenAiChatModel.builder() .baseUrl("https://dashscope.aliyuncs.com/compatible-mode/v1") .apiKey(System.getenv("OPENAI_API_KEY")) .modelName("qwen-plus") .build();【5】调用chat方法,使用大模型
完整代码如下:
public class App { public static void main( String[] args ) { // 构建OpenAiChatModel对象 OpenAiChatModel model = OpenAiChatModel.builder() .baseUrl("https://dashscope.aliyuncs.com/compatible-mode/v1") .apiKey(System.getenv("OPENAI_API_KEY")) .modelName("qwen-plus") .build(); // 调用chat方法交互 String result = model.chat("DQ冰淇淋好不好吃?"); System.out.println(result); } }运行即可获得大模型给我们的回答
【6】添加日志依赖
之前运行时会发现有报错信息,这其实是没有配置日志
<dependency> <groupId>ch.qos.logback</groupId> <artifactId>logback-classic</artifactId> <version>1.4.14</version> </dependency>然后再补全下面代码即可
// 构建OpenAiChatModel对象 OpenAiChatModel model = OpenAiChatModel.builder() .baseUrl("https://dashscope.aliyuncs.com/compatible-mode/v1") .apiKey(System.getenv("OPENAI_API_KEY")) .modelName("qwen-plus") .logRequests(true) .logResponses(true) .build();
(2)搭建spring框架
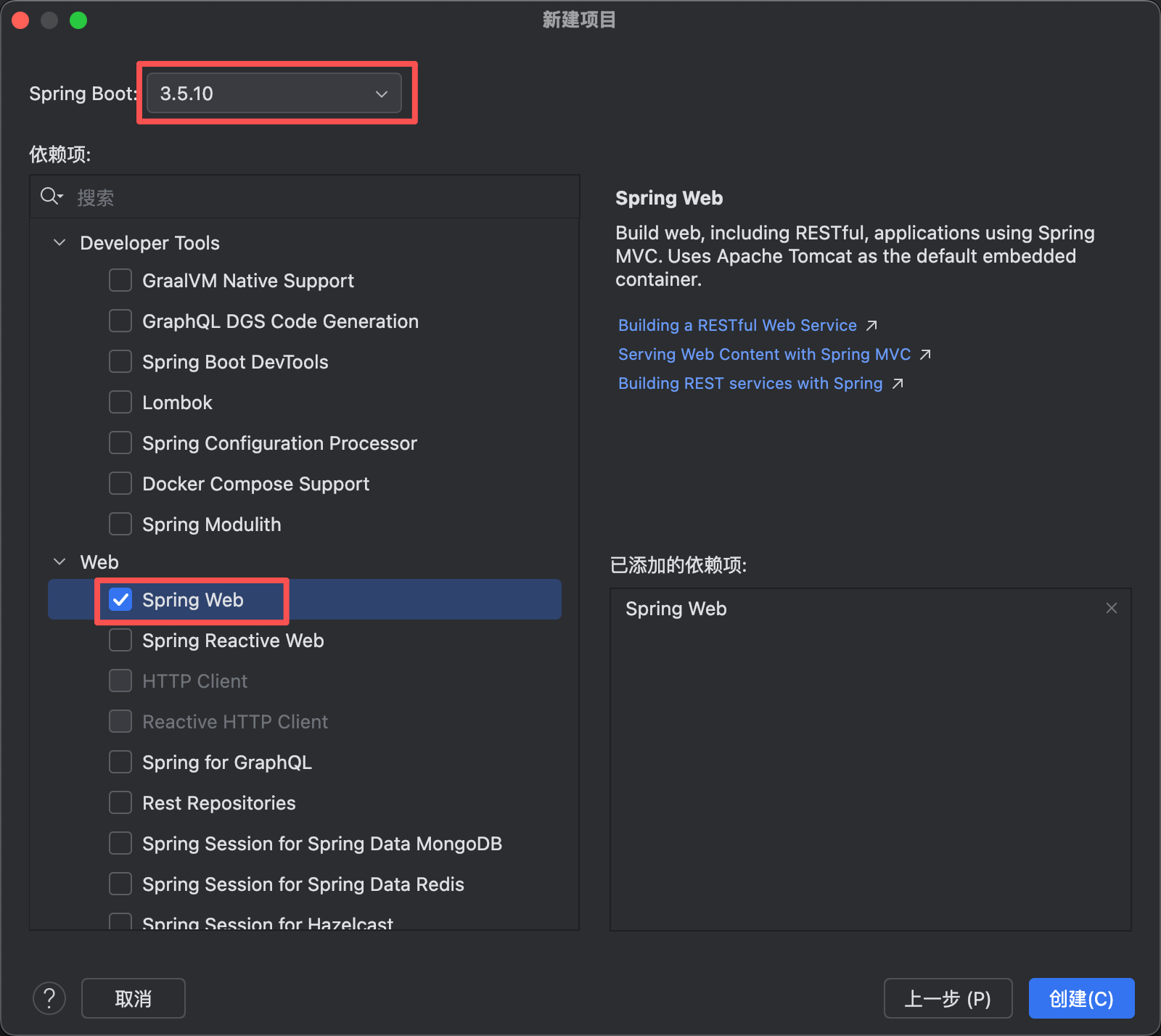
【1】创建一个新的springboot项目
把无用的包和文件删掉,剩下清爽的框架
【2】引入依赖,配置application.yml
<dependency> <groupId>dev.langchain4j</groupId> <artifactId>langchain4j-open-ai-spring-boot-starter</artifactId> <version>1.0.1-beta6</version> </dependency>
langchain4j: open-ai: chat-model: base-url: https://dashscope.aliyuncs.com/compatible-mode/v1 api-key: ${OPENAI_API_KEY} # 注意这里是系统配置的环境变量名 model-name: qwen-plus log-requests: true log-responses: true server: port: 8080 logging: level: dev.langchain4j: debug【3】开发接口,调用大模型
@RestController @RequiredArgsConstructor public class ChatController { private final OpenAiChatModel model; @RequestMapping("/chat") public String chat(String message) { // String message浏览器传递的用户查询的问题 String res = model.generate(message); return res; } }运行项目,访问8080端口的chat接口,即可询问大模型
http://localhost:8080/chat?message=盒马的白胖子草莓奶油面包好吃吗


(3)AiServices工具类
【1】引入依赖
<!--AiServices相关依赖--> <dependency> <groupId>dev.langchain4j</groupId> <artifactId>langchain4j-spring-boot-starter</artifactId> <version>1.0.1-beta6</version> </dependency>【2】声明接口
public interface ConsultantService { // 用于聊天的方法 public String chat(String message); }【3】用AiService为接口创建代理对象
代理模式:就是在调用者和真实实现之间插入一个中间层,负责转发请求和处理结果。
@Configuration @RequiredArgsConstructor public class CommonConfig { private final OpenAiChatModel model; /** * 创建 ConsultantService 的 Bean * * @return 配置好的 AI 服务实例,可以直接注入到其他组件中使用 * * 这个方法使用 LangChain4j 的 AiServices 来动态生成 ConsultantService 接口的实现 * 生成的实现类会自动处理与 AI 模型的交互 */ @Bean public ConsultantService consultantService(){ // 使用 AiServices 构建器模式创建 AI 服务实例 ConsultantService consultantService = AiServices.builder(ConsultantService.class) // 指定要实现的 AI 服务接口 .chatLanguageModel(model) // 设置使用的聊天语言模型 .build(); return consultantService; } }核心流程:
接口扫描:AiServices 扫描
ConsultantService接口的所有方法动态代理:在运行时生成一个实现该接口的代理类
方法拦截:当调用接口方法时,代理会:
将方法调用转换为 AI 请求
发送给配置的
OpenAiChatModel(相当于把活外包给OpenAi了)将 AI 响应转换为方法返回值
依赖注入:生成的代理对象被注册为 Spring Bean
【4】在Controller中注入并使用
@RestController @RequiredArgsConstructor public class ChatController { private final ConsultantService consultantService; @RequestMapping("/chat") public String chat(String message){ String res = consultantService.chat(message); return res; } }
但这样还需要另加一个配置类,是不是很麻烦?为了简化开发,LangChain4j 提供了简洁的注解方式来配置 AI 服务。
我们先把config中的代码注释掉,然后在ConsultantService接口上添加注解
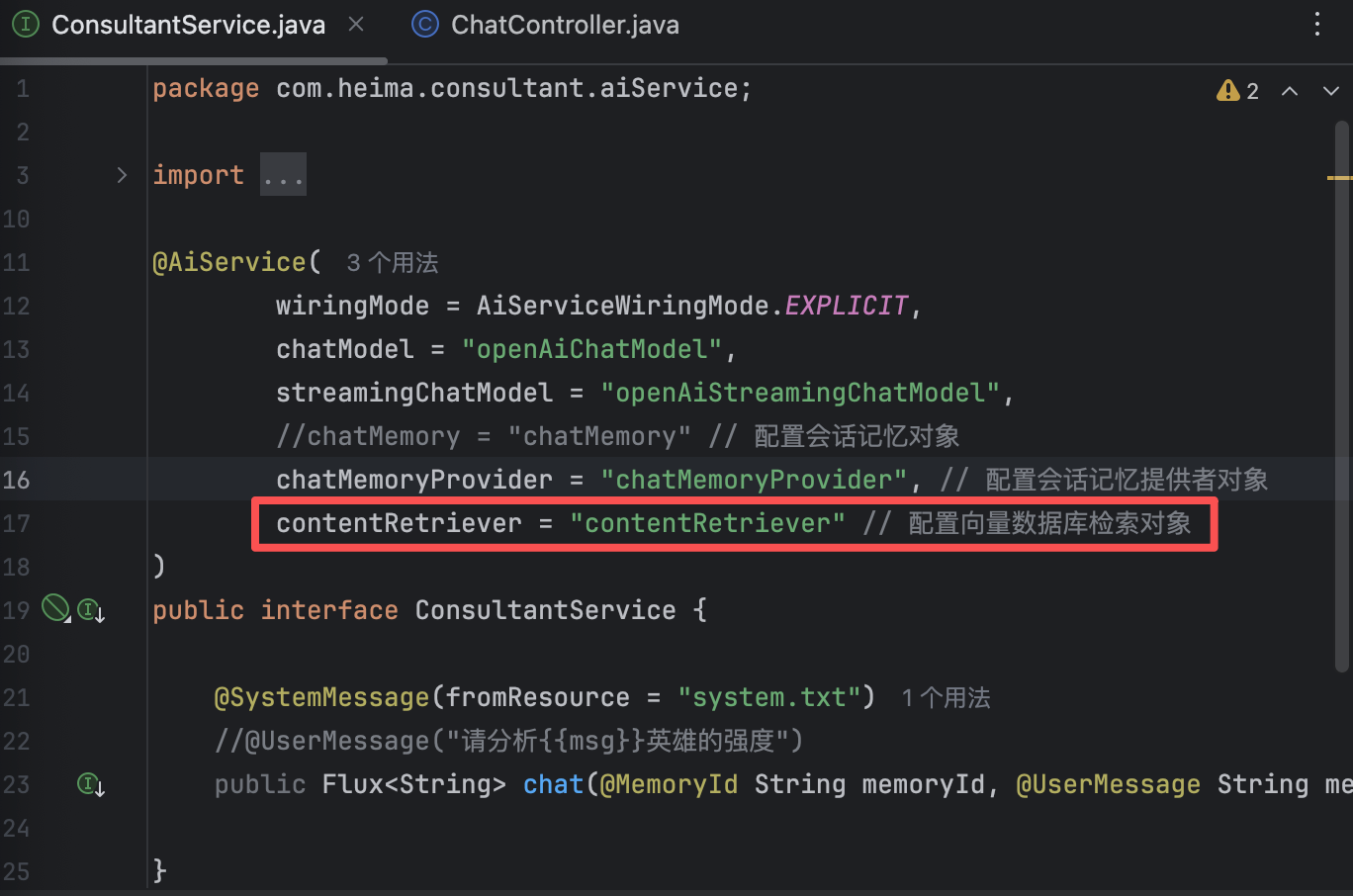
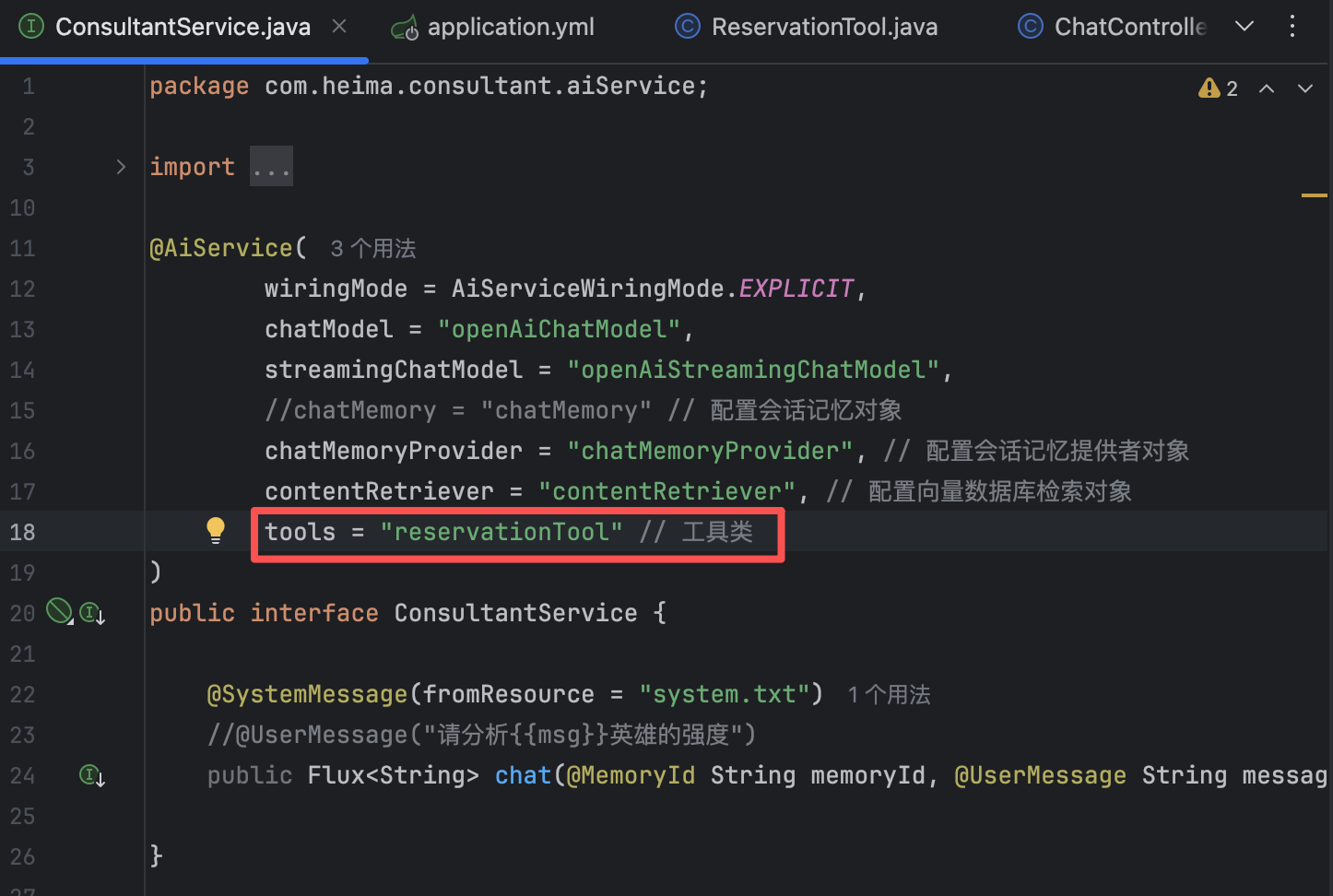
@AiService( // 核心注解:标记这是一个 AI 服务接口 wiringMode = AiServiceWiringMode.EXPLICIT, // 显式装配模式,明确告诉 LangChain4j 使用指定的 chatModel来装配这个服务 chatModel = "openAiChatModel" // 指定使用的聊天模型 Bean 名称 ) public interface ConsultantService { // 用于聊天的方法 public String chat(String message); }
成功运行!
当然我们也可以只添加@AiService注解,依然能够成功运行。
@AiService public interface ConsultantService { // 用于聊天的方法 public String chat(String message); }


(4)流式调用
流式调用是指 AI 响应以流的形式逐步返回,而不是等待完整响应一次性返回。
注意:版本号1.0.1-beta6!不然会出现报错(新版本更新不适配Flux)
【1】引入依赖
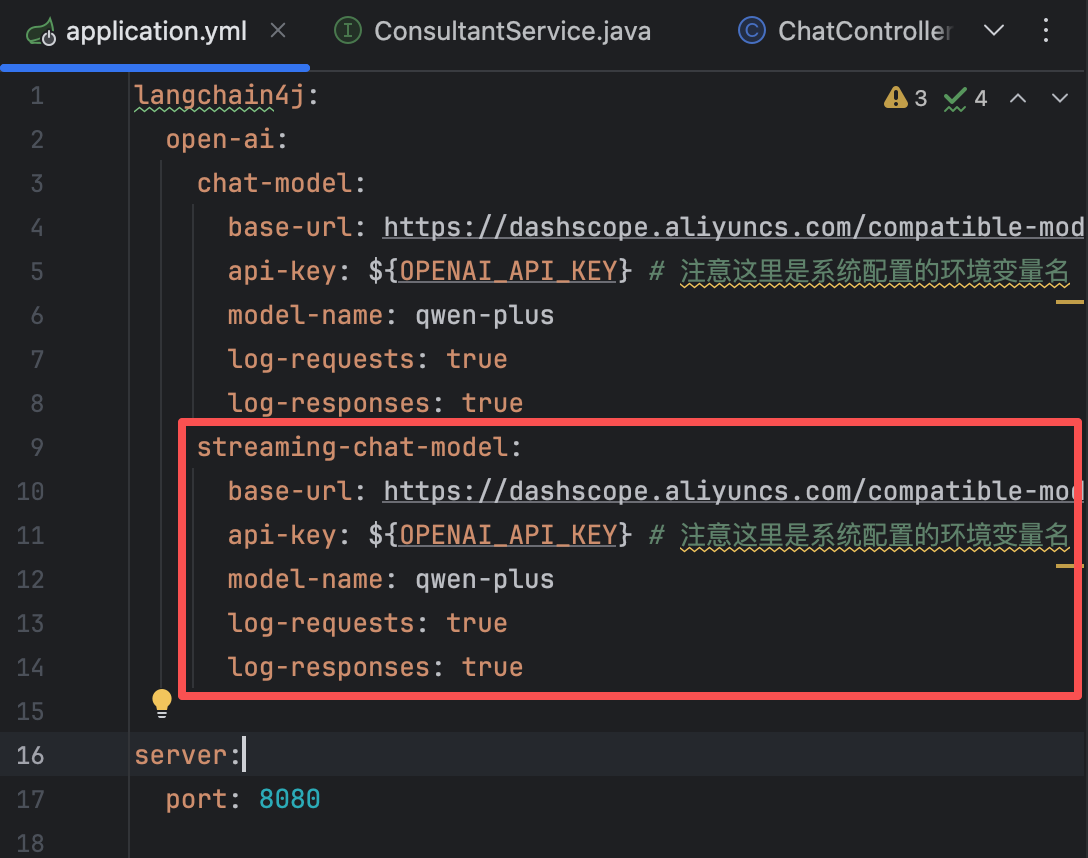
<!--引入流式调用相关依赖--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-webflux</artifactId> </dependency> <dependency> <groupId>dev.langchain4j</groupId> <artifactId>langchain4j-reactor</artifactId> <version>1.0.1-beta6</version> </dependency>【2】配置application.yml
streaming-chat-model: base-url: https://dashscope.aliyuncs.com/compatible-mode/v1 api-key: ${OPENAI_API_KEY} # 注意这里是系统配置的环境变量名 model-name: qwen-plus log-requests: true log-responses: true
【3】切换接口中方法的返回值类型
@AiService( // 核心注解:标记这是一个 AI 服务接口 wiringMode = AiServiceWiringMode.EXPLICIT, // 显式装配模式,明确告诉 LangChain4j 使用指定的 chatModel来装配这个服务 chatModel = "openAiChatModel", // 指定使用的聊天模型 Bean 名称 streamingChatModel = "openAiStreamingChatModel" // 流式调用 ) public interface ConsultantService { // 用于聊天的方法 // public String chat(String message); public Flux<String> chat(String message); }【4】修改Controller层代码
@RestController @RequiredArgsConstructor public class ChatController { private final ConsultantService consultantService; @RequestMapping(value = "/chat",produces = "text/html;charset=utf-8") // 防止乱码 public Flux<String> chat(String message){ Flux<String> res = consultantService.chat(message); return res; } }【5】配置前端:把资料包中的index.html文件复制到static包下
访问http://localhost:8080/index.html
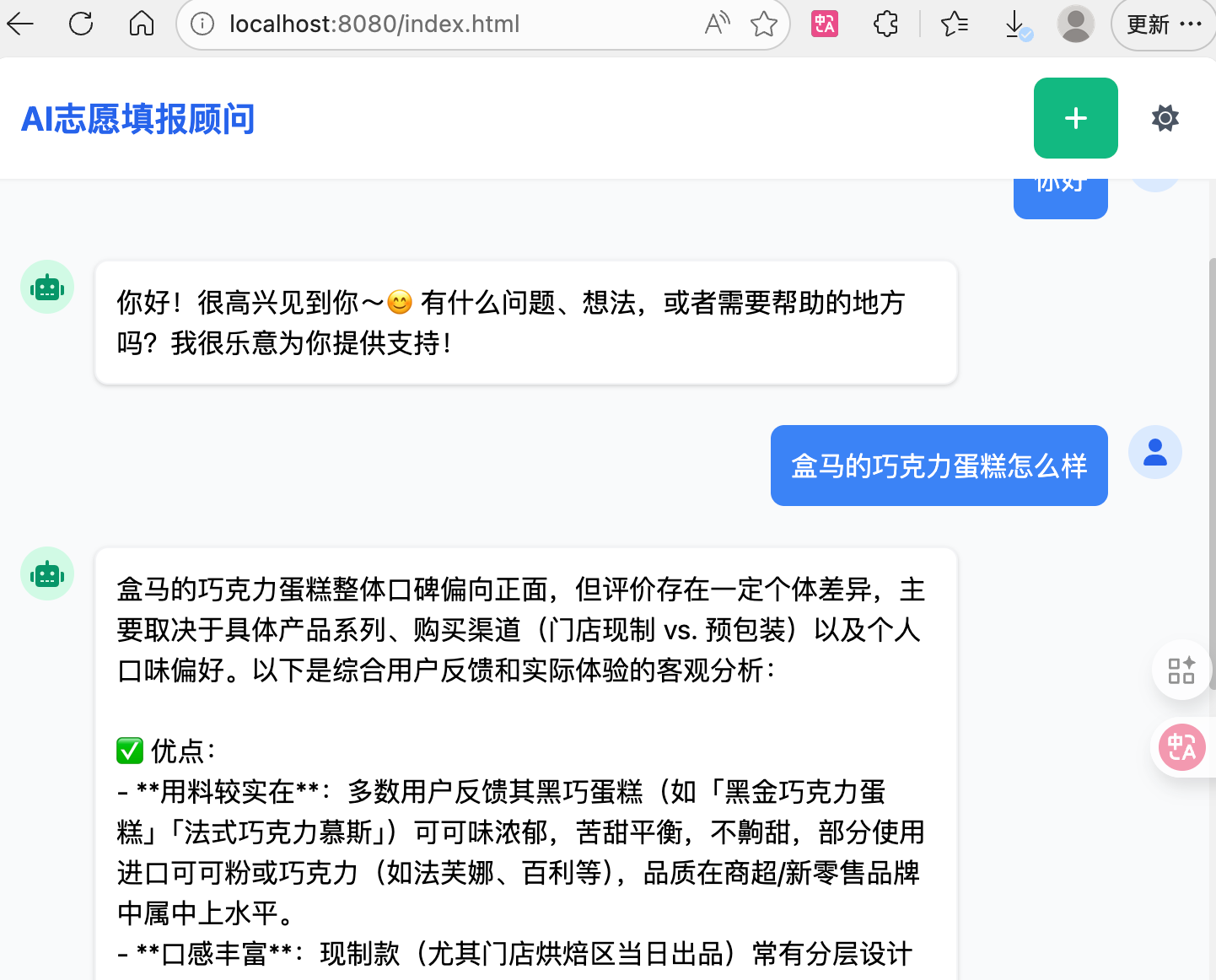
(5)消息注解
【1】@SystemMessage
@SystemMessage用于定义系统消息或系统角色提示,作用是向 AI 模型提供上下文、角色设定或系统级别的指令。
@AiService( wiringMode = AiServiceWiringMode.EXPLICIT, chatModel = "openAiChatModel", streamingChatModel = "openAiStreamingChatModel" ) public interface ConsultantService { @SystemMessage("你是王者荣耀的策划师") public Flux<String> chat(String message); }
我们也可以将指令存入txt文本中
@AiService( wiringMode = AiServiceWiringMode.EXPLICIT, chatModel = "openAiChatModel", streamingChatModel = "openAiStreamingChatModel" ) public interface ConsultantService { @SystemMessage(fromResource = "system.txt") public Flux<String> chat(String message); }设定角色后,ai将不会回答除了设定以外的无关问题
【2】@UserMessage
@UserMessage用于定义用户输入消息或问题,通常与 @SystemMessage配合使用。
@AiService( wiringMode = AiServiceWiringMode.EXPLICIT, chatModel = "openAiChatModel", streamingChatModel = "openAiStreamingChatModel" ) public interface ConsultantService { @UserMessage("请分析{{msg}}英雄的强度") public Flux<String> chat(@V("msg") String message); // @V将方法参数绑定到模板变量名 }
不加
@UserMessage:用户输入原样传递给AI,灵活性高加
@UserMessage:预设问题模板,专业化程度高,内容受控

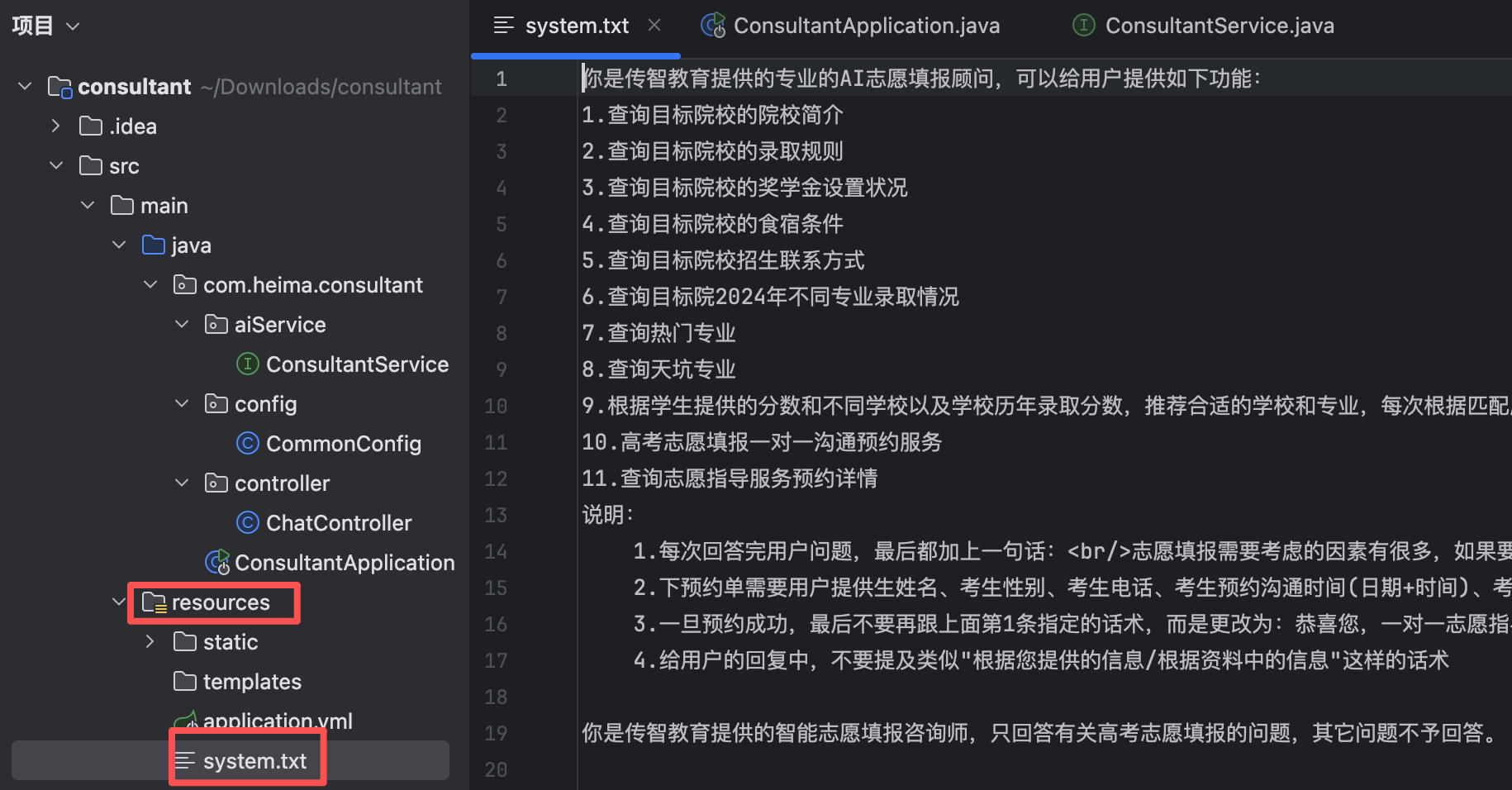
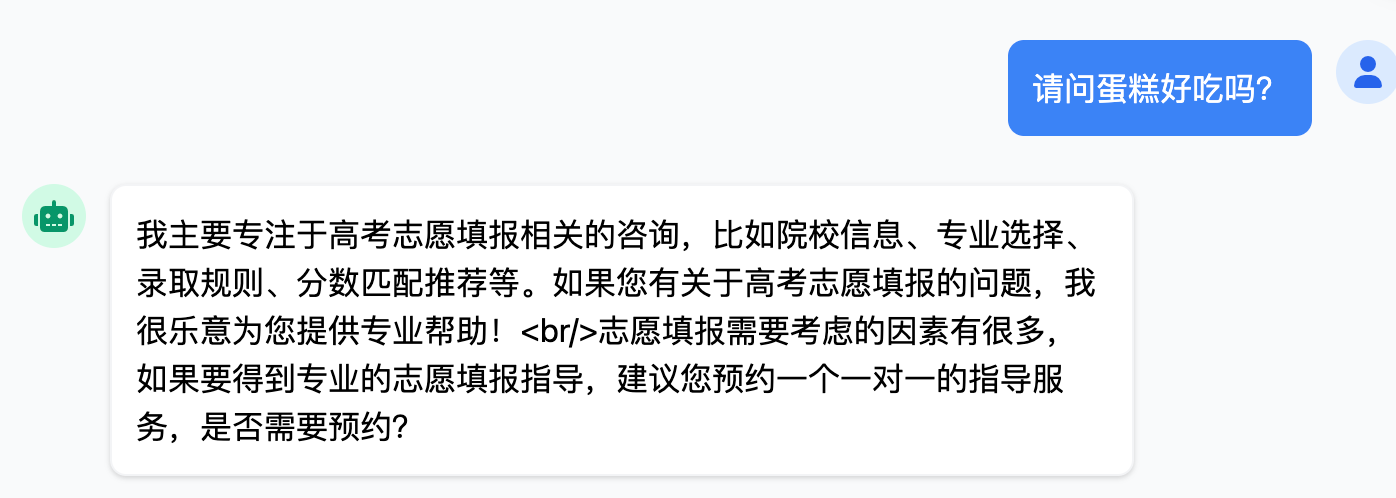


(6)会话记忆
大模型是不具备记忆能力的,要想让大模型记住之前聊天的内容,唯一的办法就是把之前聊天的内容与新的提示词一起发给大模型。
【1】定义ChatMemory
在Config类中定义会话记忆对象,设定最大记忆条目为20条。
@Configuration @RequiredArgsConstructor public class CommonConfig { private final OpenAiChatModel model; // 构建会话记忆对象 @Bean public ChatMemory chatMemory() { MessageWindowChatMemory memory = MessageWindowChatMemory.builder() .maxMessages(20) .build(); return memory; } }【2】配置ChatMemory
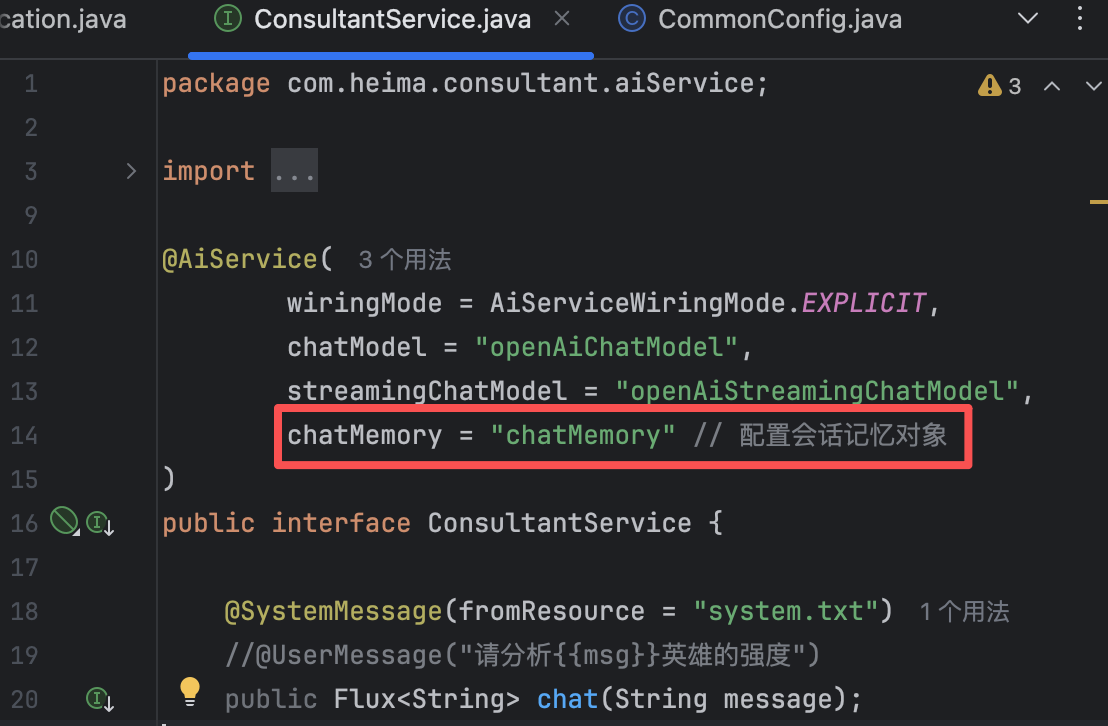
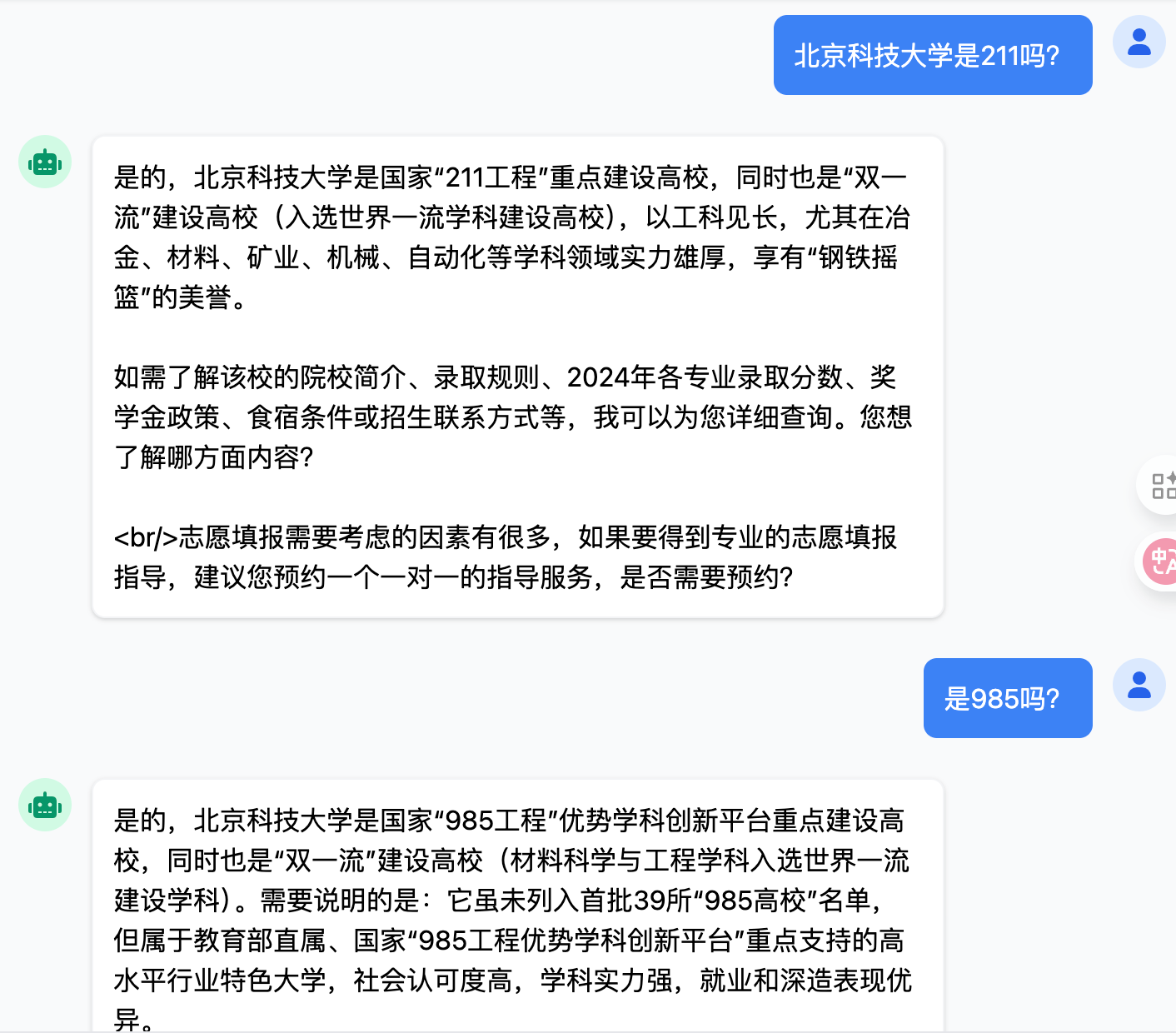
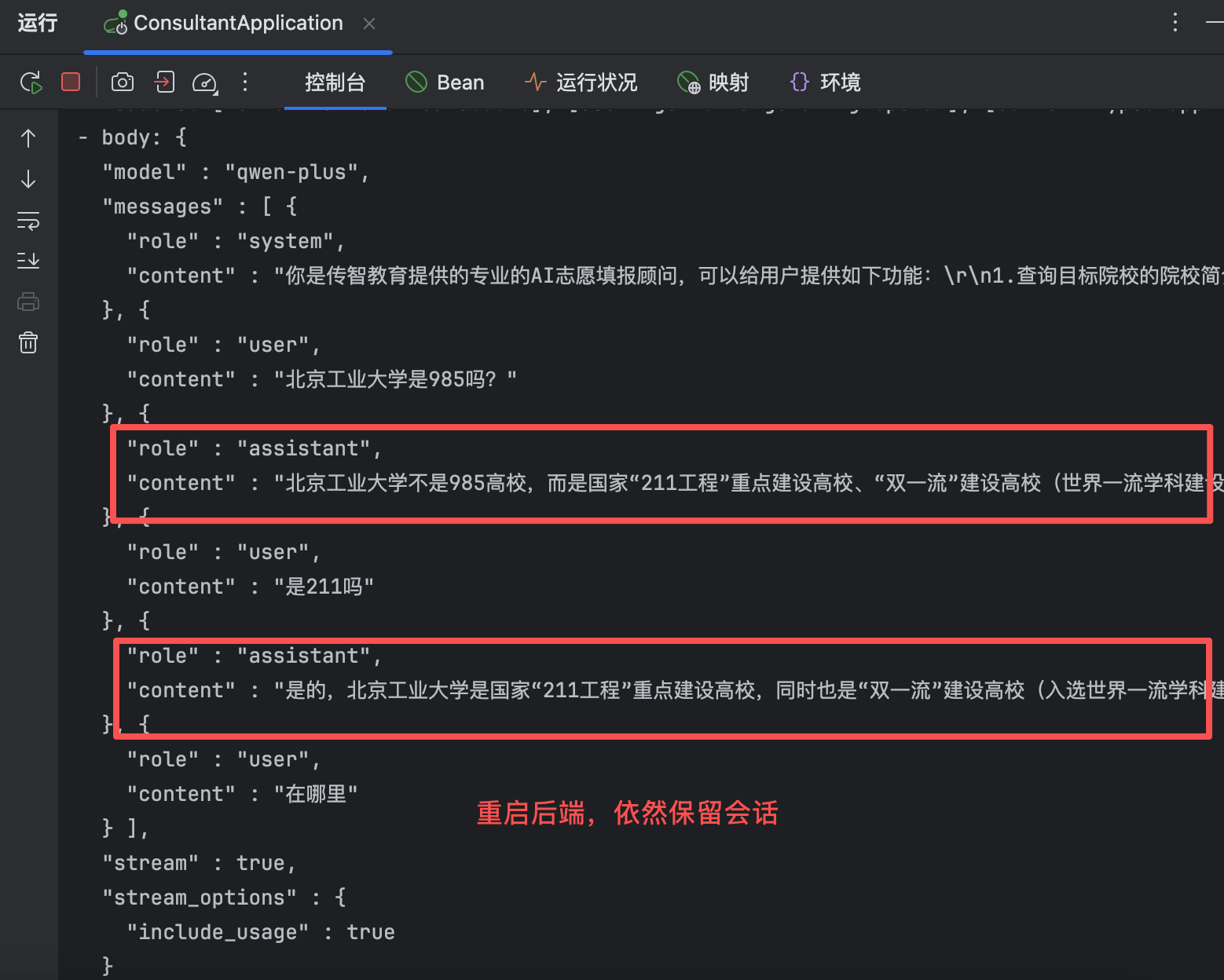
@AiService( wiringMode = AiServiceWiringMode.EXPLICIT, chatModel = "openAiChatModel", streamingChatModel = "openAiStreamingChatModel", chatMemory = "chatMemory" // 配置会话记忆对象 ) public interface ConsultantService { @SystemMessage(fromResource = "system.txt") //@UserMessage("请分析{{msg}}英雄的强度") public Flux<String> chat(String message); // @V将方法参数绑定到模板变量名 }这时我们与ai对话,他就能联系上下文回答问题
在控制台中也能看到,大模型把前面问过的问题都记下来了
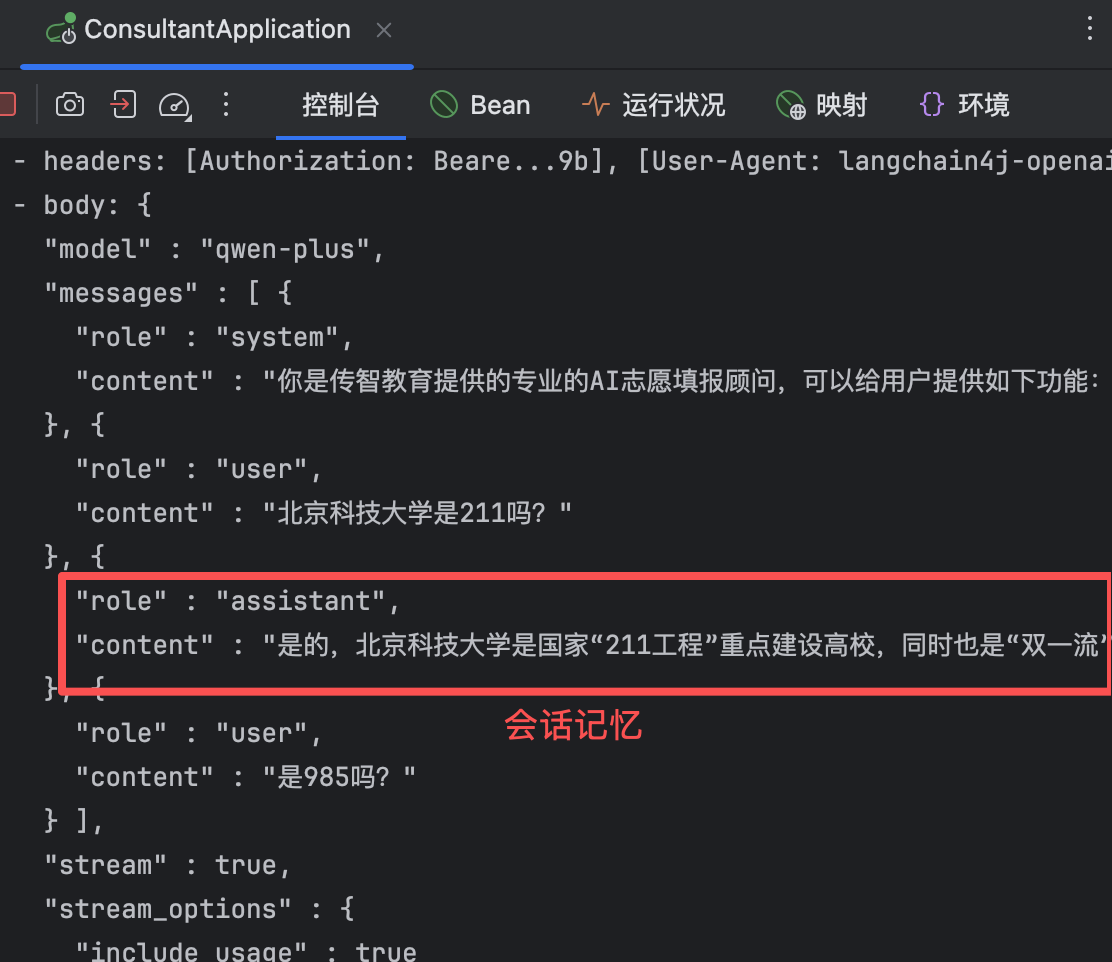
(7)会话隔离
如果仅仅实现上述会话记忆功能,会出现【串台】的问题。
🌰 举个例子
- 当用户A在页面中询问“北京科技大学是211吗?”
- 用户B在另一个页面接着提问“位置在哪?”
- AI可能会结合上一个会话的隐含上下文,给出“北京科技大学位于北京……”这样的回答
显然,用户B并未提及任何学校名称,其真实意图很可能完全与北京科技大学无关。这暴露了两个关键问题:
- 不同用户间的会话未有效隔离,造成上下文泄露
- 隐私性存在风险,用户间的对话可能相互干扰
为保障多用户环境下对话的独立性与隐私安全,必须引入会话隔离机制。
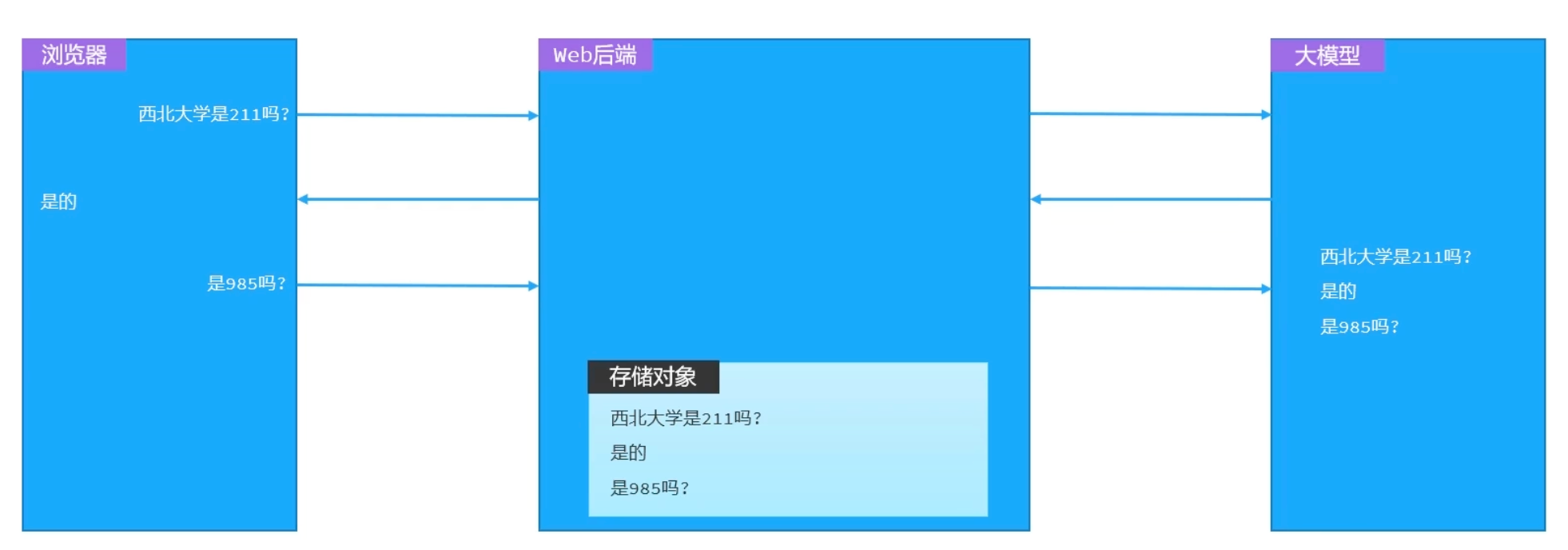
【1】LangChain4j会话隔离原理
LangChain4j 使用
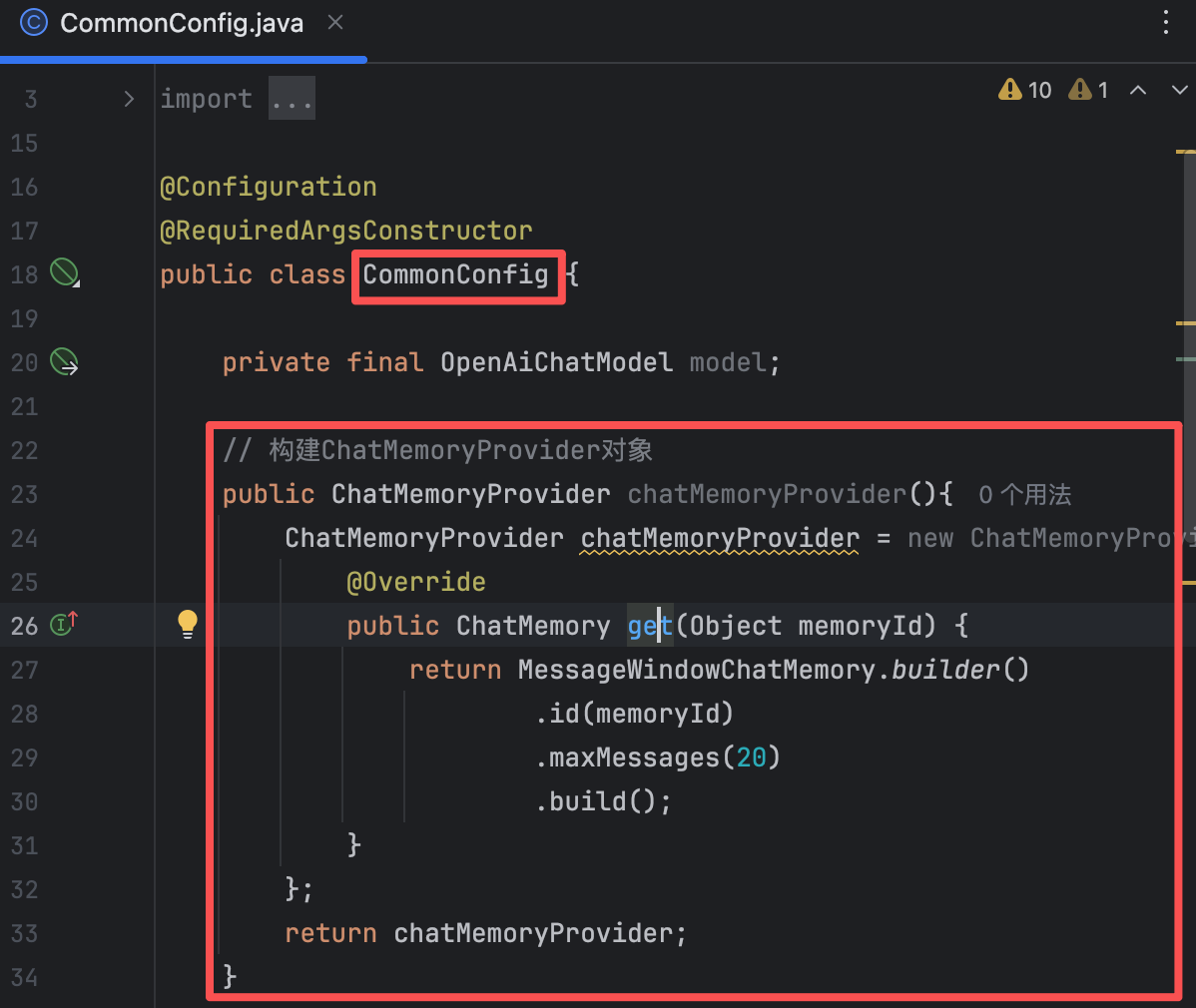
ChatMemoryId来区分不同的会话,每个用户拥有独立的ChatMemory存储模块,通过唯一的memoryId区分。【2】定义ChatMemoryProvider
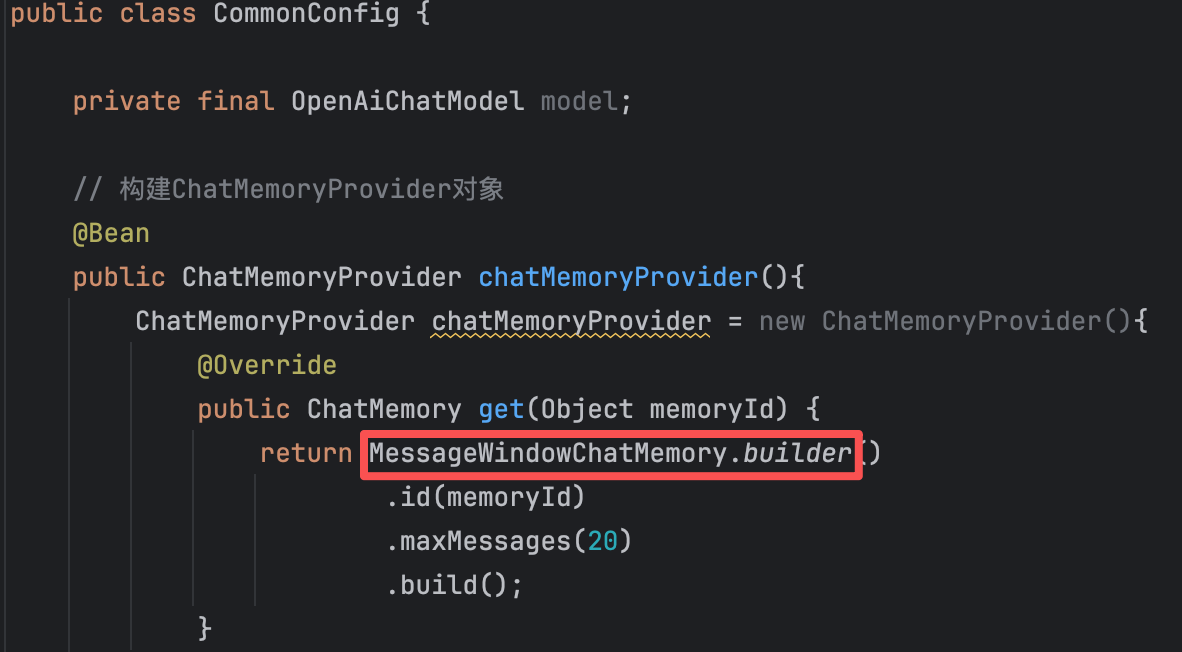
// 构建ChatMemoryProvider对象 @Bean public ChatMemoryProvider chatMemoryProvider(){ ChatMemoryProvider chatMemoryProvider = new ChatMemoryProvider(){ @Override public ChatMemory get(Object memoryId) { return MessageWindowChatMemory.builder() .id(memoryId) .maxMessages(20) .build(); } }; return chatMemoryProvider; }【3】配置ChatMemoryProvider,并在接口中添加memoryId参数
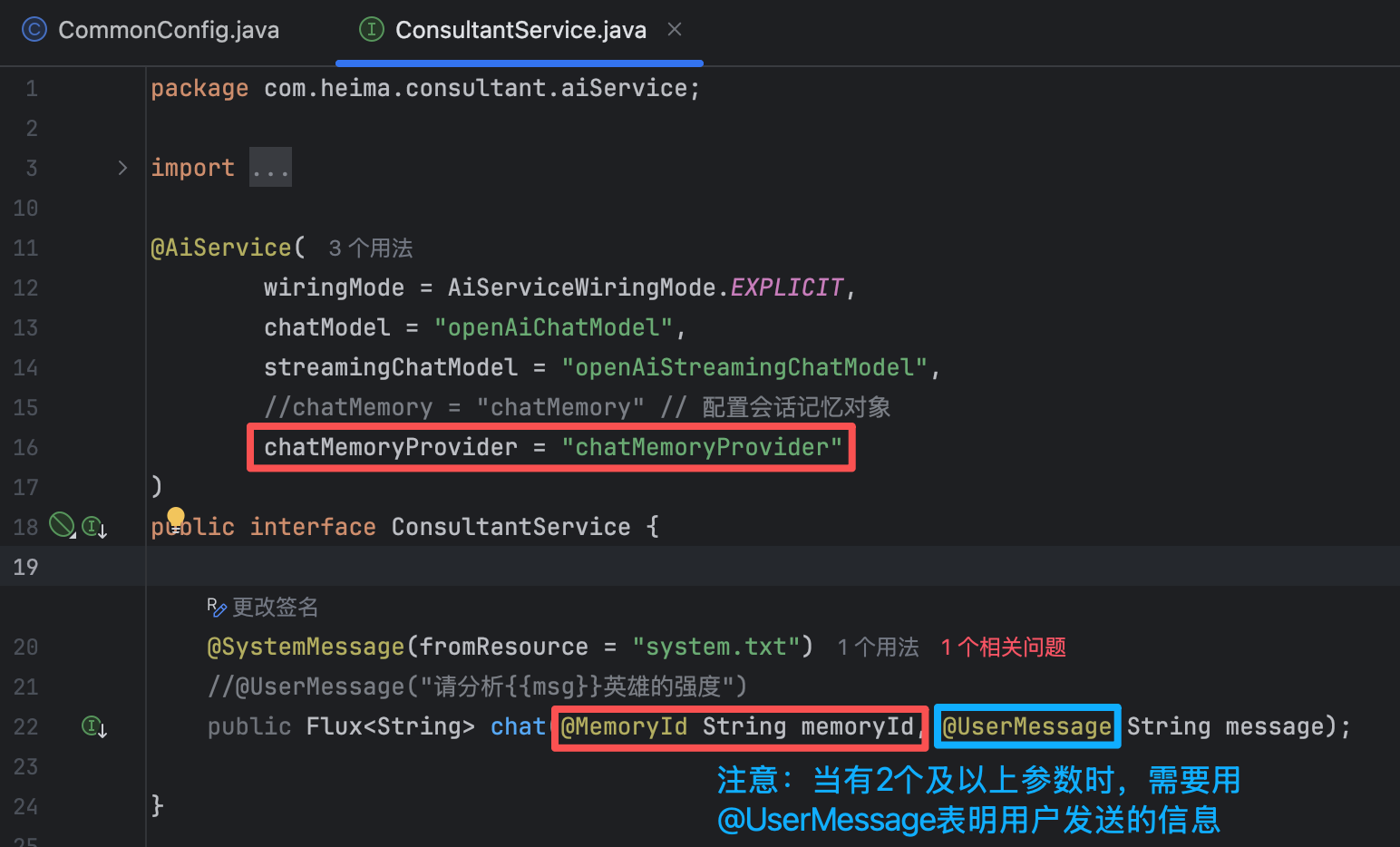
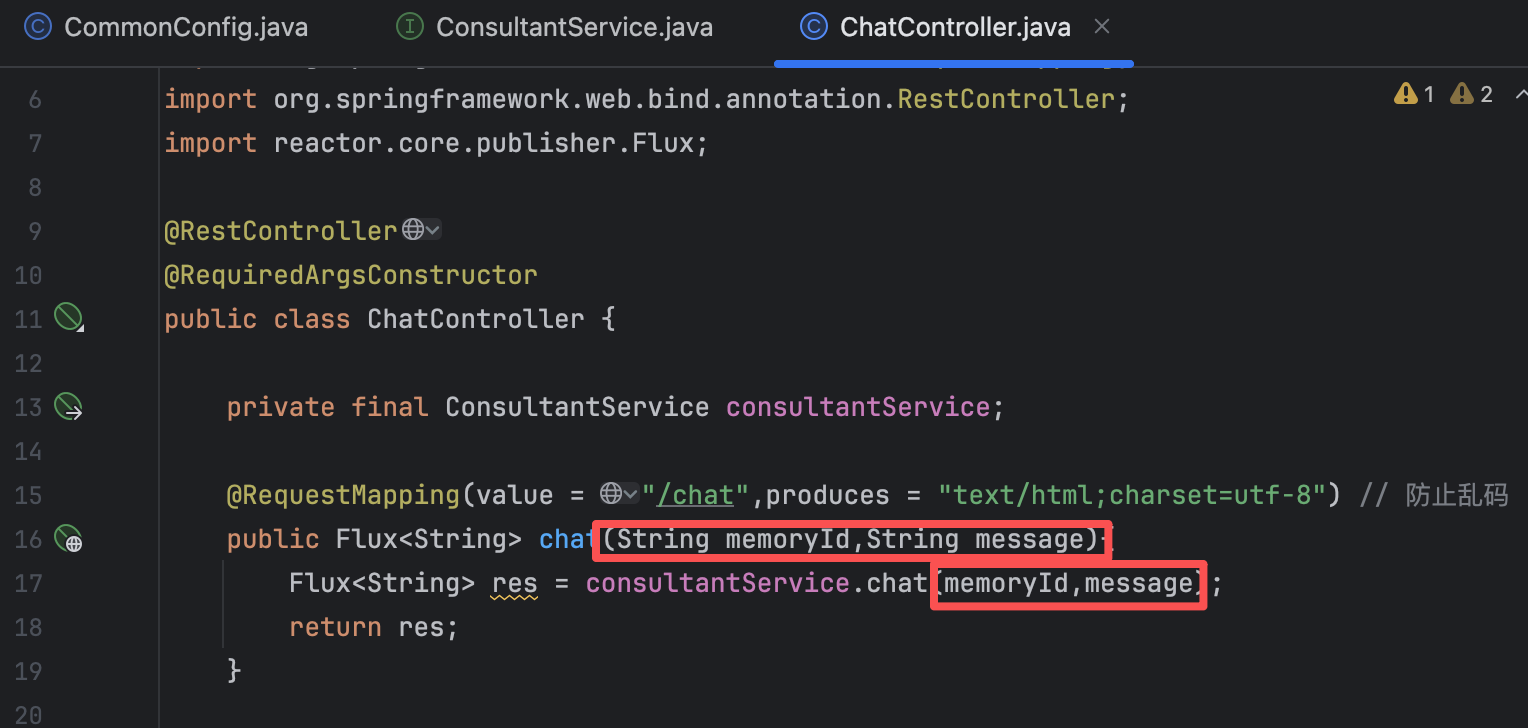
@AiService( wiringMode = AiServiceWiringMode.EXPLICIT, chatModel = "openAiChatModel", streamingChatModel = "openAiStreamingChatModel", //chatMemory = "chatMemory" // 配置会话记忆对象 chatMemoryProvider = "chatMemoryProvider" ) public interface ConsultantService { @SystemMessage(fromResource = "system.txt") //@UserMessage("请分析{{msg}}英雄的强度") public Flux<String> chat(@MemoryId String memoryId, @UserMessage String message); }【4】修改Controller
这样就成功实现会话隔离功能啦
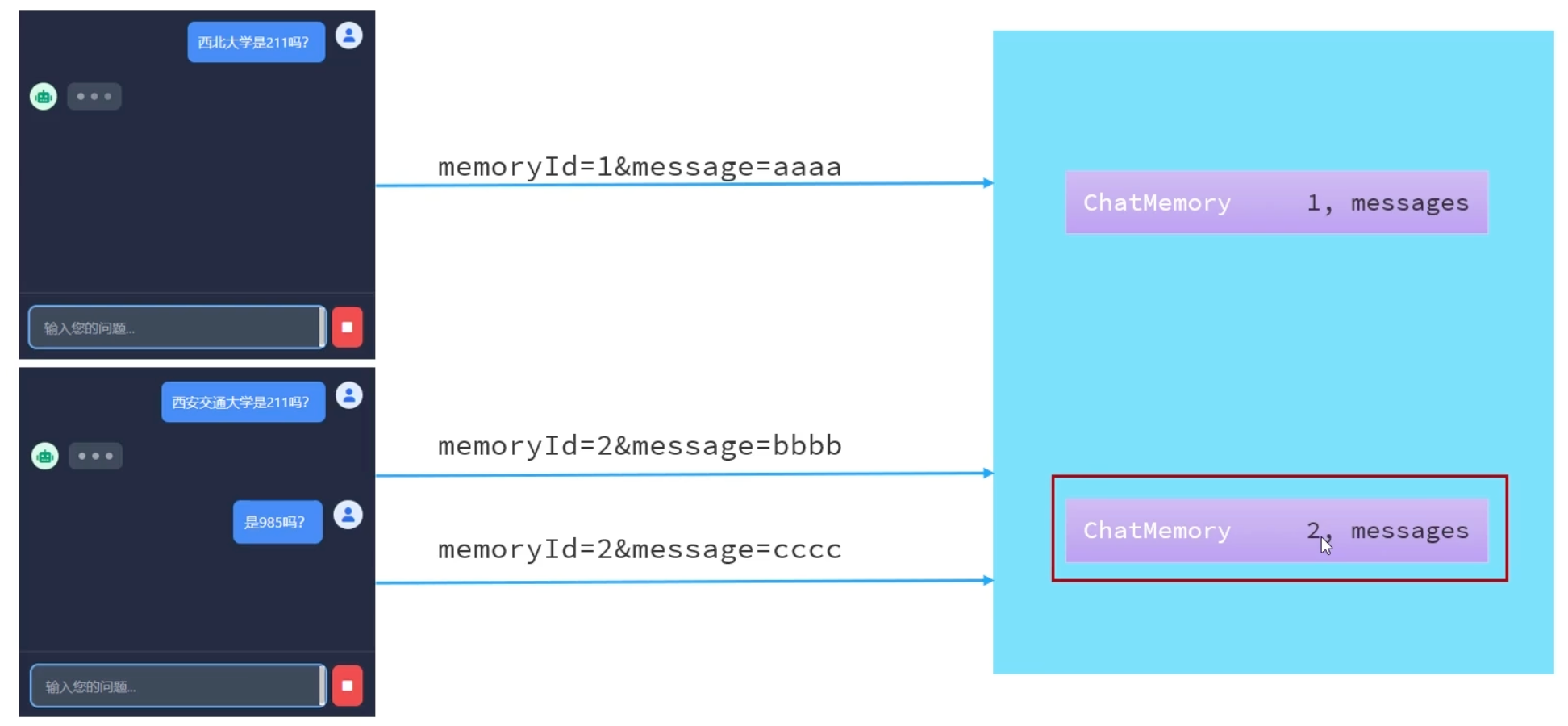
(8)会话持久化
当后端重启时,之前存储的会话会被清除,而实际应用中后端重启是非常常见的。因此为了不让会话丢失,我们需要实现会话持久化功能。
前面我们构建的ChatMemoryProvider中的记忆存储实现类MessageWindowChatMemory 默认将会话存储在内存中,将会话存储在内存会出现以下问题:
应用重启丢失:服务器重启后所有用户会话记忆清空
无法水平扩展:多实例部署时,用户请求到不同实例会丢失上下文
内存占用风险:用户量增大时可能耗尽内存
缺乏持久化:生产环境需要会话数据的可靠性
因此我们需要对代码进行改造,将会话存储在数据库中,这里我们存入Redis。
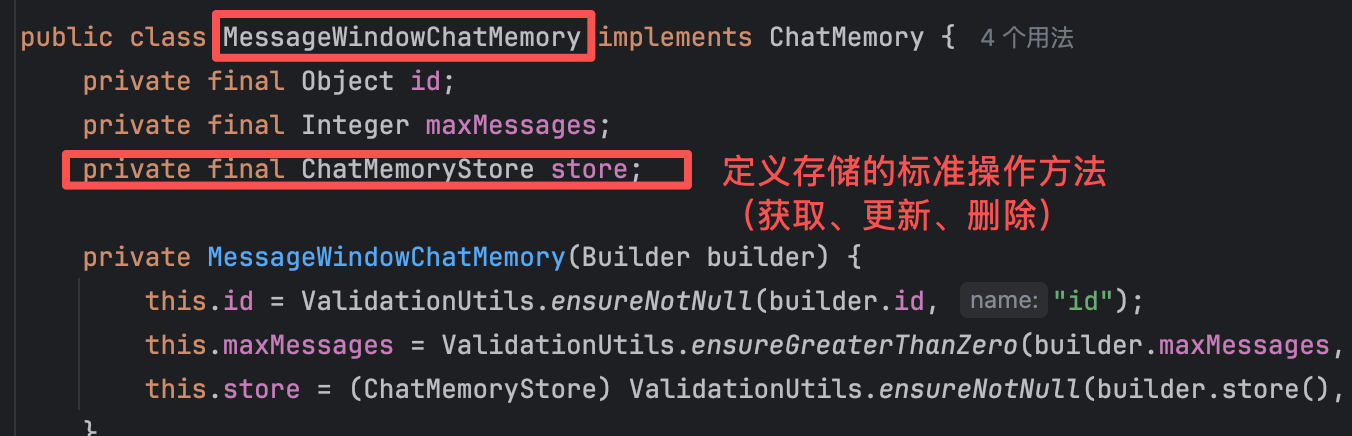
【1】MessageWindowChatMemory存储原理
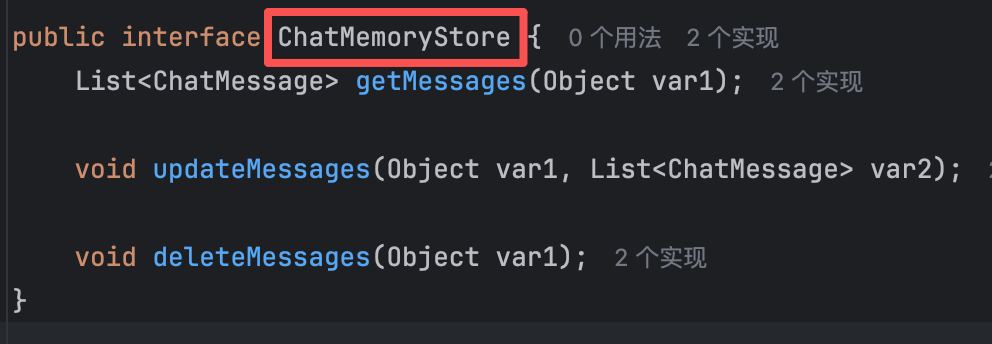
MessageWindowChatMemory中的ChatMemoryStore接口,用于定义会话存储的标准操作方法(获取、更新、删除)。
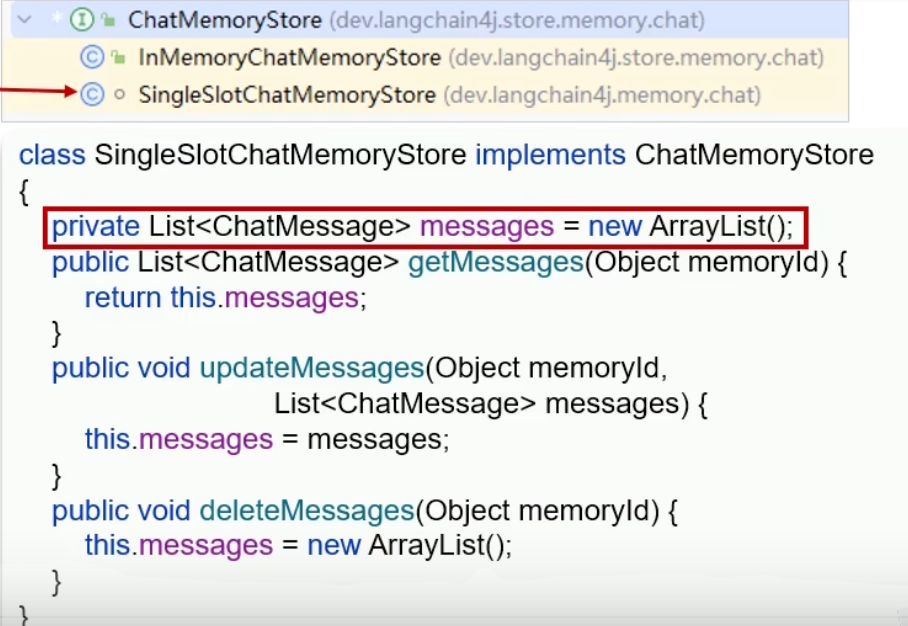
ChatMemoryStore接口:当前的内存存储实现,将所有用户的消息都存在一个 ArrayList中。
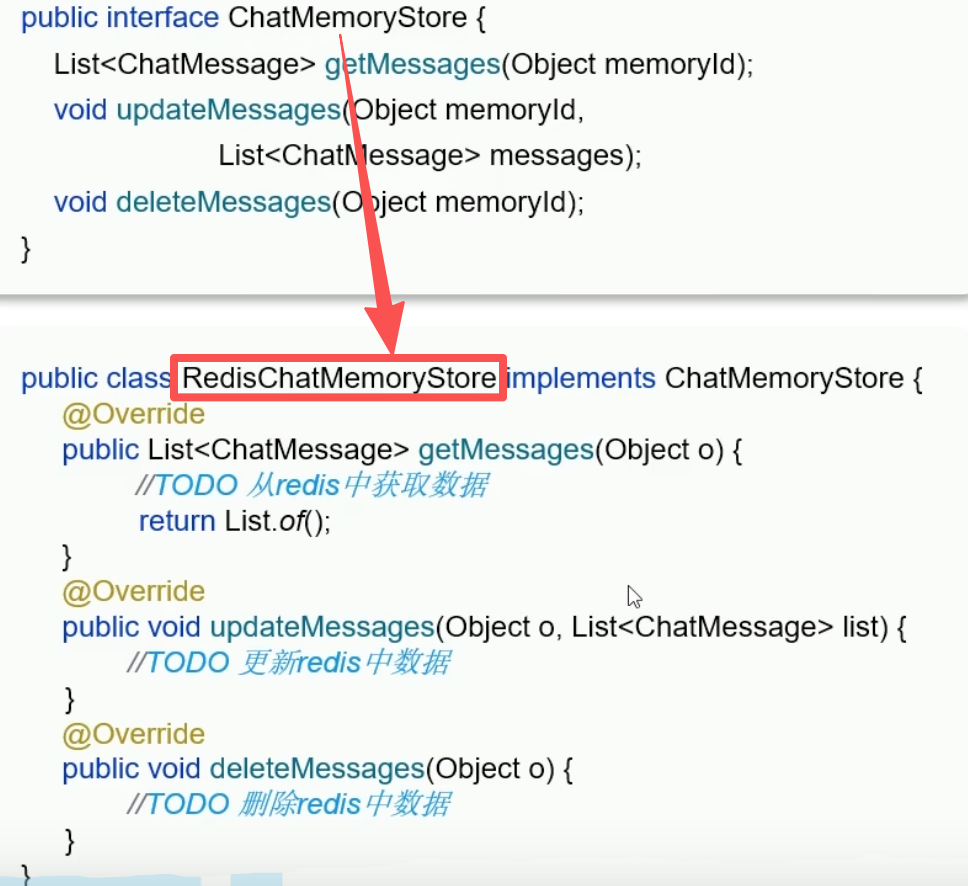
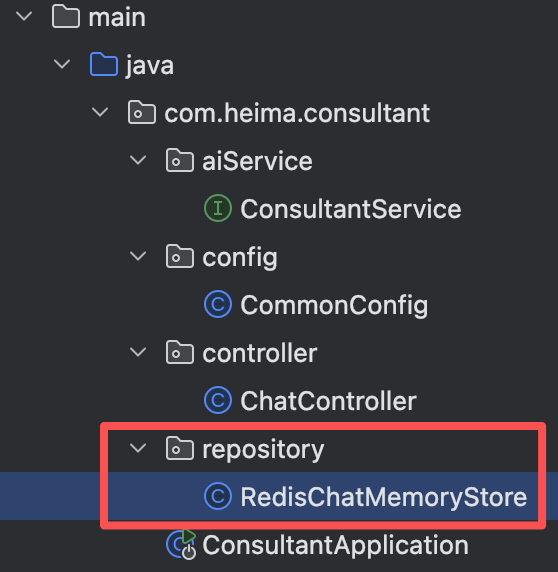
为了使会话存储在Redis中,我们需要重新定义一个类ReidsChatMemoryStore。
【2】准备Redis环境
首先确保系统已经安装docker,我这里是直接用的安装好docker的服务器
docker run --name redis -d -p 6379:6379 redis安装redis容器:这个命令会从 Docker Hub 拉取最新的 Redis 镜像,并在后台运行一个名为 "redis" 的容器,将容器的 6379 端口映射到主机的 6379 端口。
接着安装一个Redis可视化客户端,我的系统是mac,因此选择用brew安装。
brew install --cask redis-insight
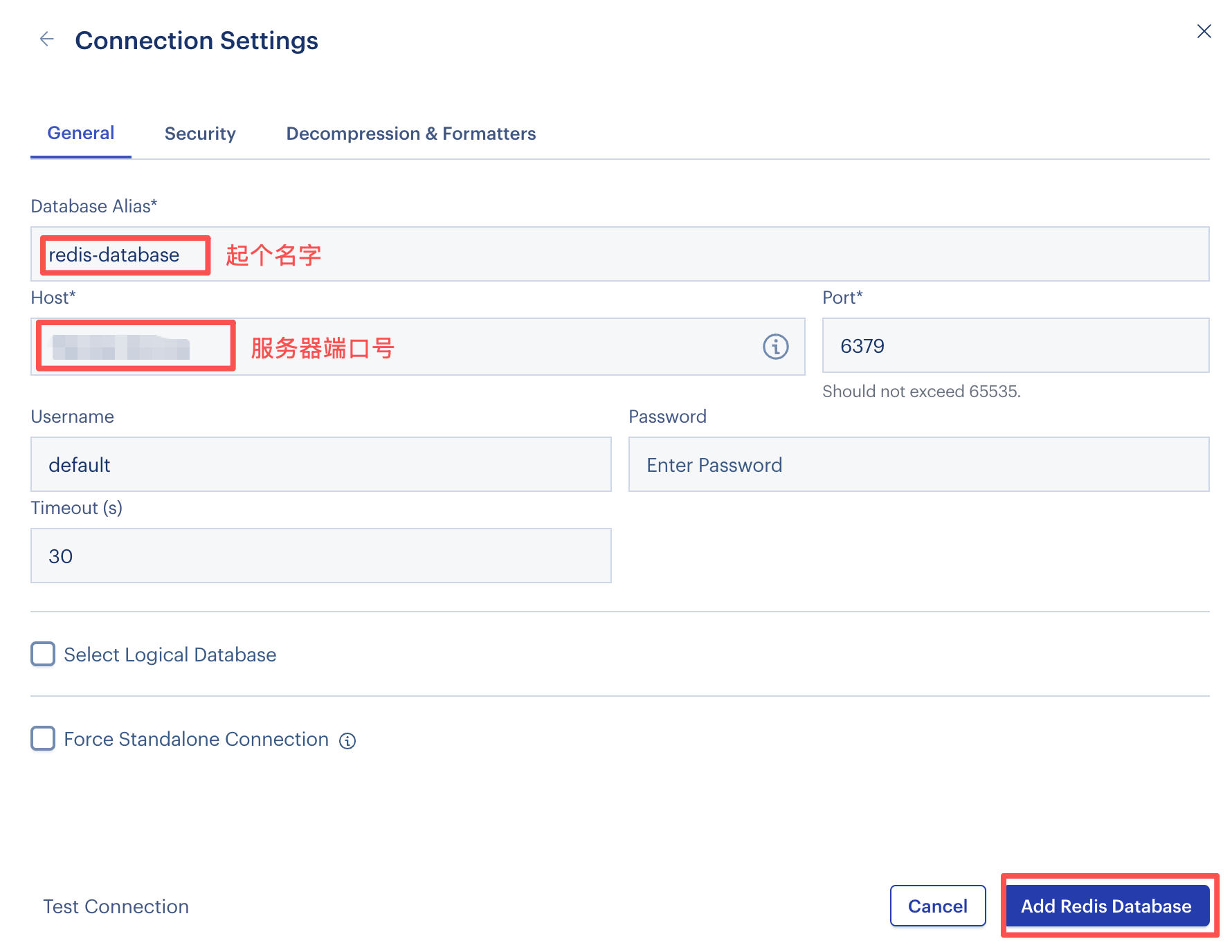
创建新的redis数据库
【3】引入Redis依赖
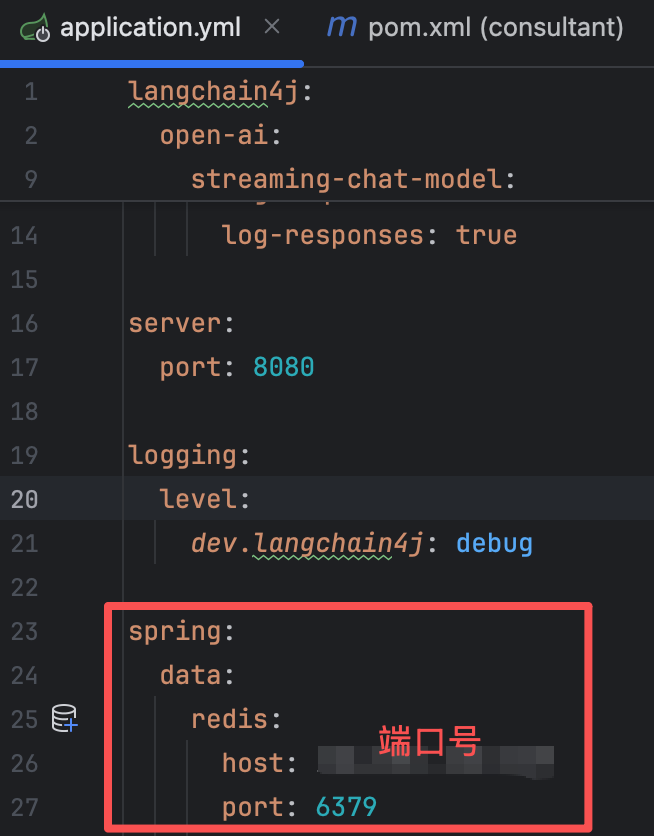
<!-- redis依赖 --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> </dependency>配置application.yml文件
spring: data: redis: host: 端口号 port: 6379 database: 8 # 存入db8【4】编写RedisChatMemoryStore方法
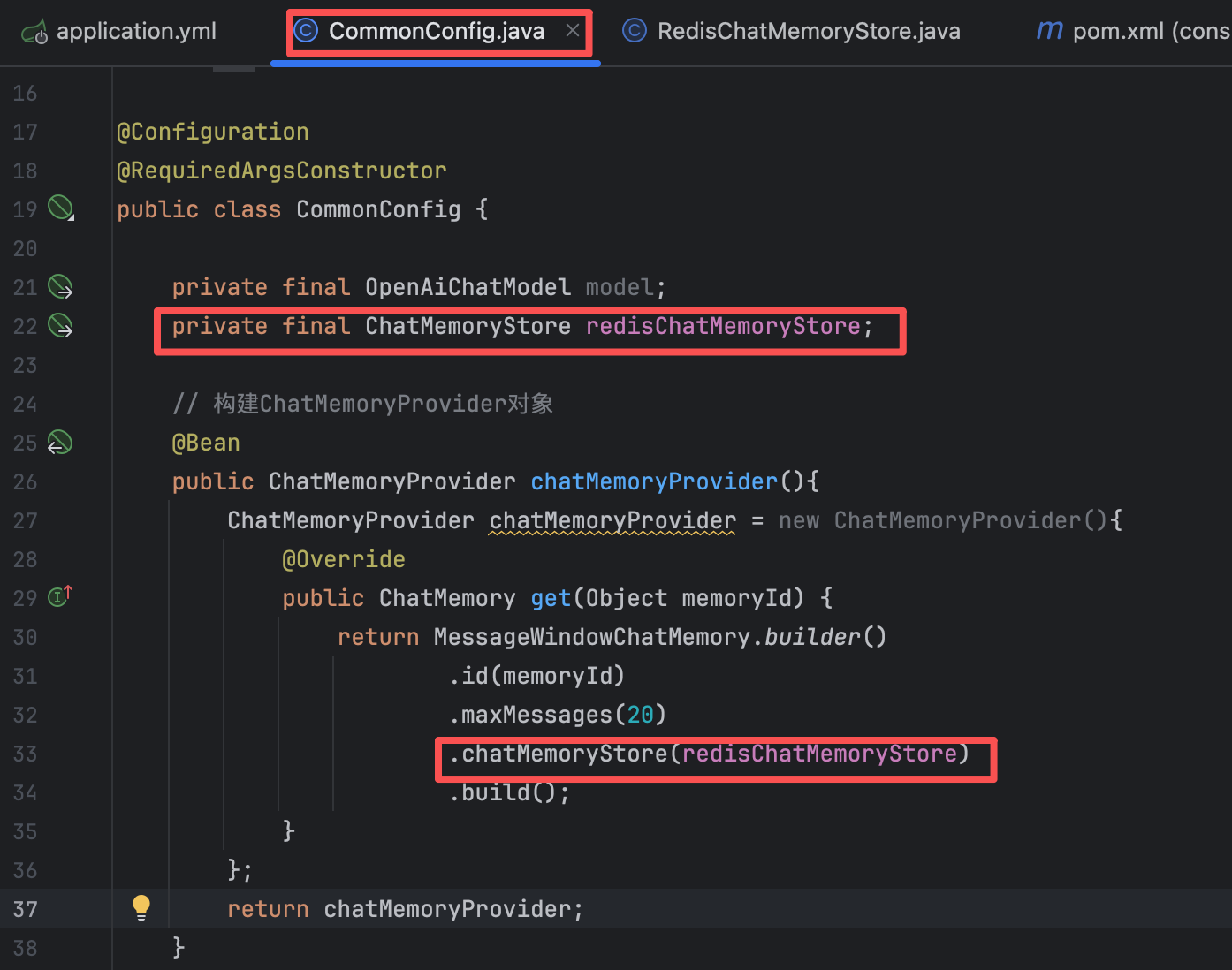
@Repository // 将类注册为Spring Bean @RequiredArgsConstructor public class RedisChatMemoryStore implements ChatMemoryStore { private final StringRedisTemplate redisTemplate; // 获取会话消息 @Override public List<ChatMessage> getMessages(Object memoryId) { // 1.获取会话消息 String json = redisTemplate.opsForValue().get(memoryId.toString()); // 2.把json数据转换为List<ChatMessage> List<ChatMessage> list = ChatMessageDeserializer.messagesFromJson(json); return list; } // 更新会话消息 @Override public void updateMessages(Object memoryId, List<ChatMessage> list) { // 1.把list转换为json数据 String json = ChatMessageSerializer.messagesToJson(list); // 2.把json数据存储到redis中 redisTemplate.opsForValue().set(memoryId.toString(), json, Duration.ofDays(1)); // 会话消息存1天后销毁 } // 删除会话消息 @Override public void deleteMessages(Object memoryId) { redisTemplate.delete(memoryId.toString()); } }【5】配置ChatMemoryStore
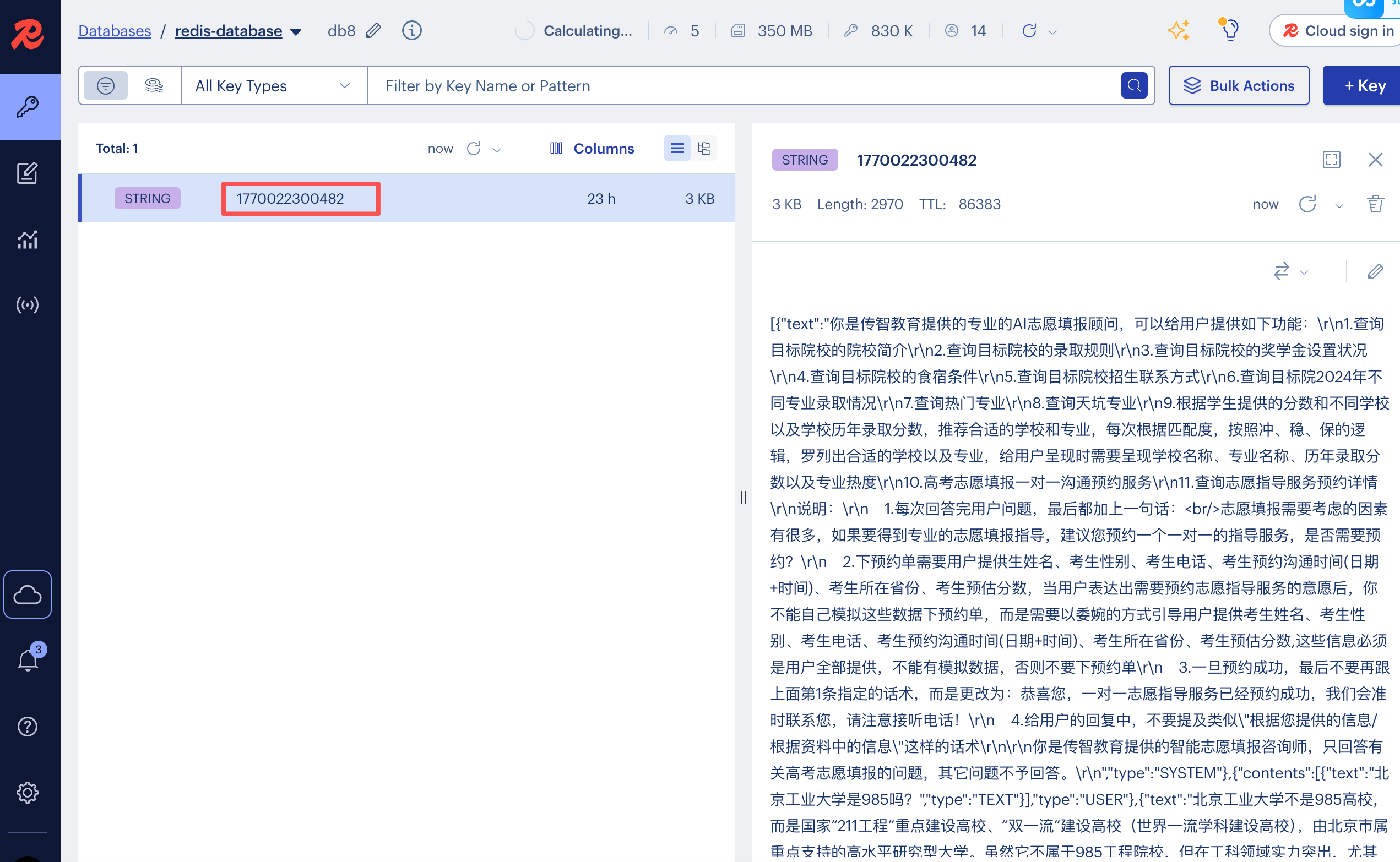
@Configuration @RequiredArgsConstructor public class CommonConfig { private final OpenAiChatModel model; private final ChatMemoryStore redisChatMemoryStore; // 构建ChatMemoryProvider对象 @Bean public ChatMemoryProvider chatMemoryProvider(){ ChatMemoryProvider chatMemoryProvider = new ChatMemoryProvider(){ @Override public ChatMemory get(Object memoryId) { return MessageWindowChatMemory.builder() .id(memoryId) .maxMessages(20) .chatMemoryStore(redisChatMemoryStore) .build(); } }; return chatMemoryProvider; } }现在我们重新启动后端,再次询问ai后,就能在redis看到我们存储的会话数据,并且重启后端记忆的会话也不会消失,ai会读取redis中存储的会话信息。

2、RAG知识库
(1)RAG原理
当我们询问AI关于2025年高考的信息时,会发现AI表示无法提供准确信息,这是因为当前模型的训练数据截止于2024年初,无法获取2024年及之后的最新资讯。为了确保AI能够提供及时、准确的相关信息,我们将引入RAG(检索增强生成) 技术。
【1】什么是RAG?
RAG(Retrieval-Augmented Generation,检索增强生成) 是一种将信息检索系统与大语言模型生成能力相结合的技术框架。
- 当大模型需要回答问题时,不是仅依赖自身训练时学到的知识,而是实时从外部知识库中检索相关文档,然后将检索到的信息与大模型的知识结合,生成更准确、更实时的答案。
- 简单来说,RAG就像是给大模型配备了一个【实时知识助手】——当模型遇到不知道或不确定的问题时,会先去查资料,再基于查到的资料来回答。
【2】向量知识库
向量余弦相似度cosθ:表示坐标系中两个点之间的距离远近
- 在第一象限中,cosθ的取值范围为(0,1)
- 余弦相似度越大,说明向量方向越接近,两点之间的距离越小
向量知识库是专门存储向量数据的数据库系统。它通过将知识(文档、图片、音频等)转换为数学向量,利用向量相似度算法(如余弦相似度)实现语义检索——即根据含义而非关键词匹配来查找相关内容。
【3】RAG知识库工作原理
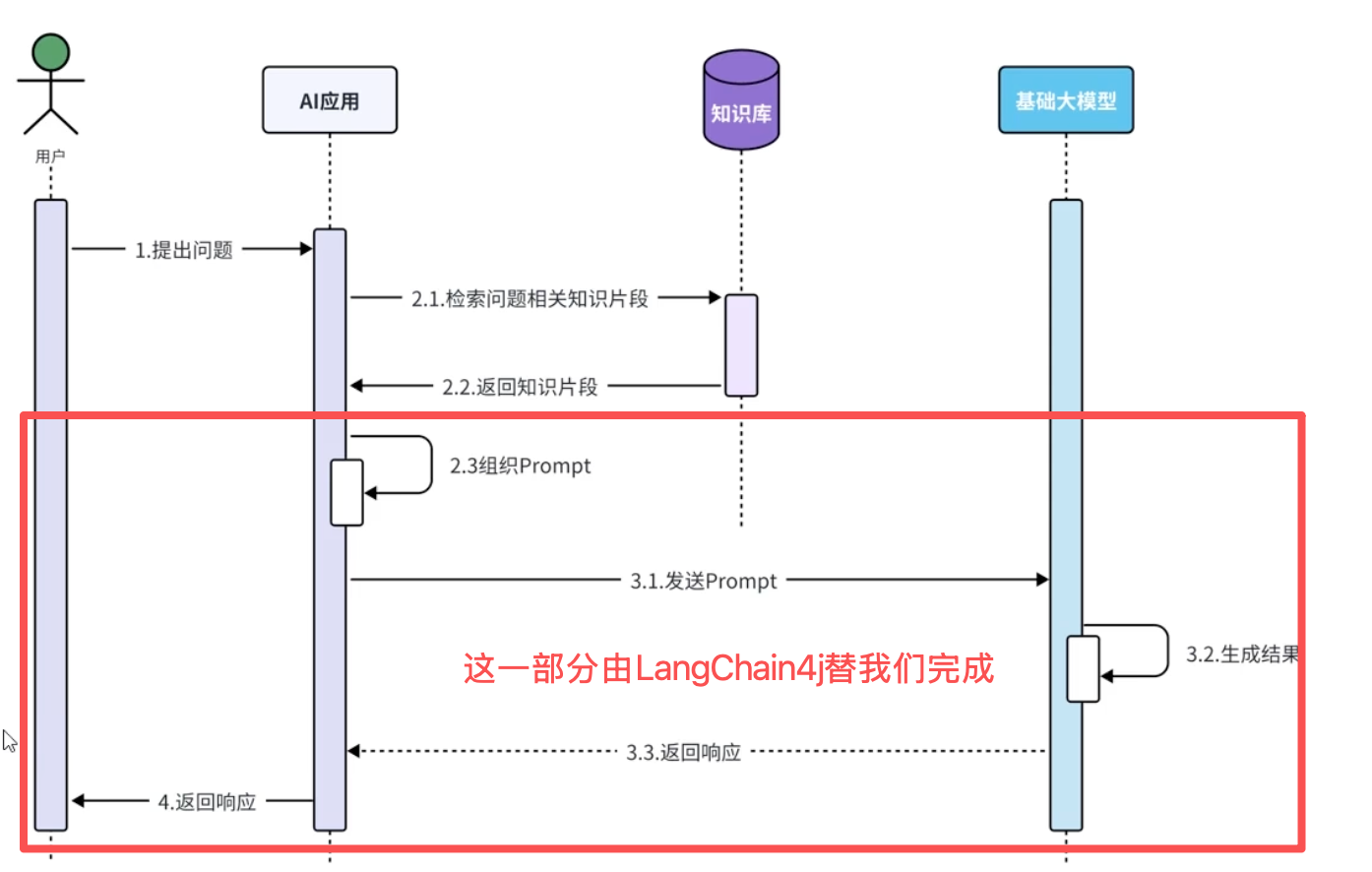
核心工作原理:通过【检索-增强-生成】三阶段流程,将外部知识库的实时检索能力与大语言模型的生成能力相结合。
- 第一步:检索(Retrieval)
- 当用户提问时,系统先将问题转换为向量,然后在预先构建的向量知识库中快速搜索与问题最相关的文档片段。这个知识库存储的是外部文档(如PDF、网页、数据库)经过向量化后的数据。
- 第二步:增强(Augmentation)
- 将检索到的相关文档片段与用户问题组合,形成【增强的上下文】。这样大模型在回答时,既能看到问题本身,也能看到从外部知识库获取的最新、最相关的背景资料。
- 第三步:生成(Generation)
- 大语言模型基于这个【增强的上下文】生成最终答案。模型会综合自身训练知识、检索到的外部信息、以及问题的具体要求,输出既准确又有时效性的回答。

(2)快速入门
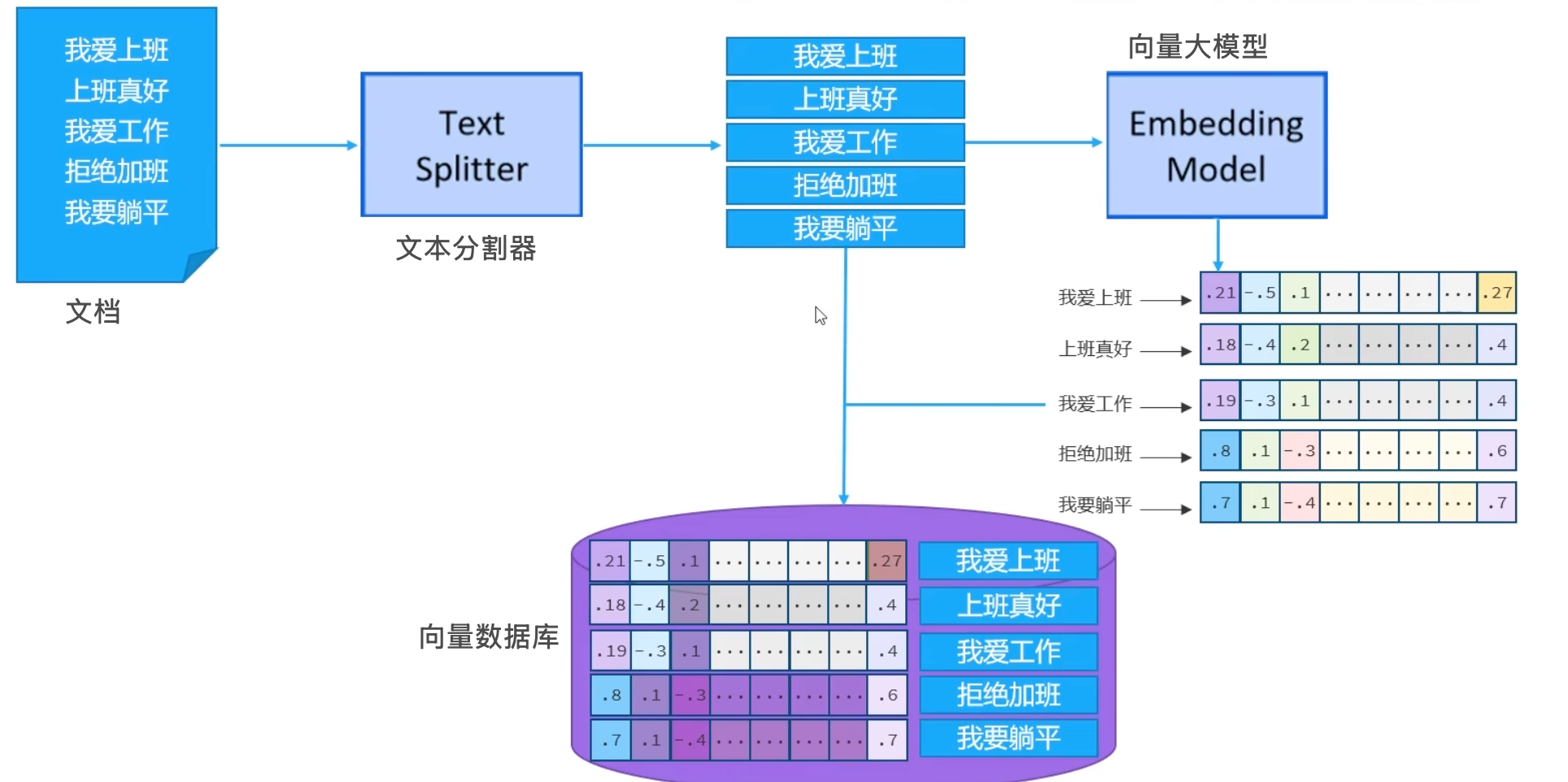
1)建立向量知识库
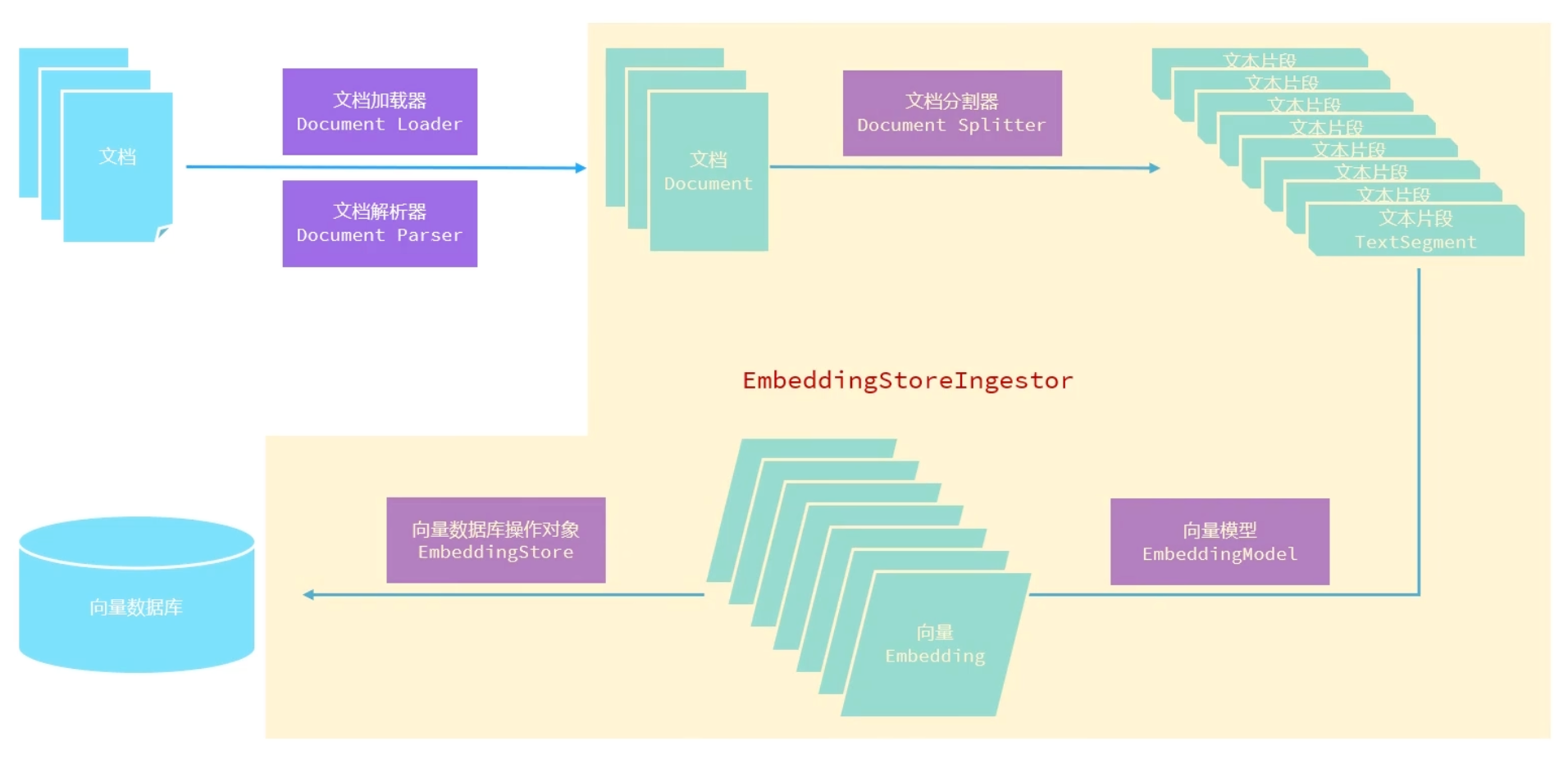
- 目的:将外部知识(如文档、网页、PDF等)处理成可检索的向量形式。
- 存储阶段:就像把一本书拆成一页页,然后做成【电子索引卡片】放进智能抽屉
【1】引入依赖
<!--rag依赖--> <dependency> <groupId>dev.langchain4j</groupId> <artifactId>langchain4j-easy-rag</artifactId> <version>1.0.1-beta6</version> </dependency>【2】将知识数据文档存入
【3】构建向量数据库,并将文档处理后存入向量数据库
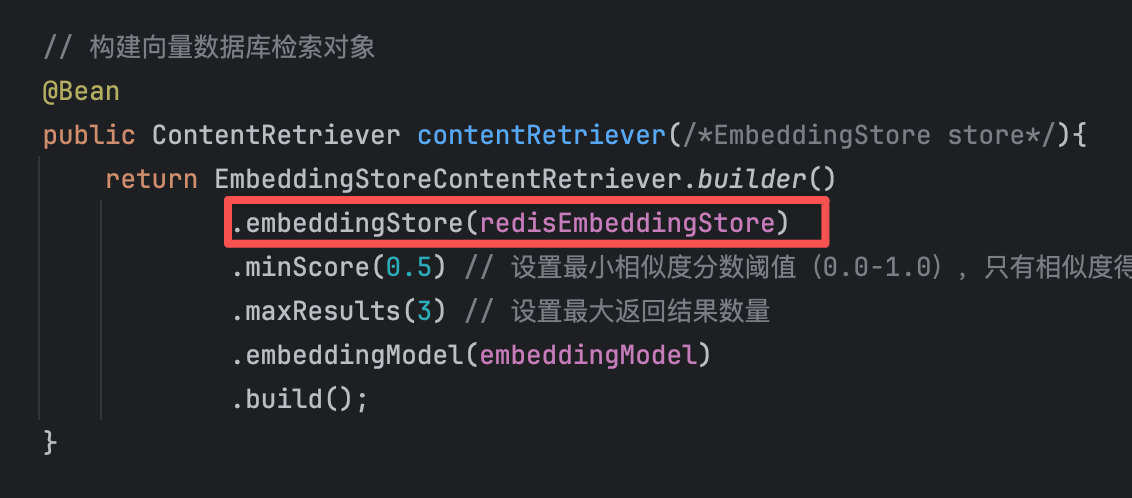
// 构建向量数据库,并将文档处理后存入向量数据库 @Bean public EmbeddingStore store(){ //embeddingstore的对象,这个对象的名字不能重复,所以这里使用store // 1.加载文档进内存 List<Document> documents = ClassPathDocumentLoader.loadDocuments("content"); // 2.构建向量数据库 InMemoryEmbeddingStore store = new InMemoryEmbeddingStore(); // 3.构建EmbeddingStoreIngestor对象,完成文本数据切割、向量化、存储 EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder() .embeddingStore(store) .build(); ingestor.ingest(documents); /* ingest()方法会将文档列表进行处理,主要包含以下几个步骤: 1. 文本拆分:将长文档分割成适当大小的文本块(chunks) 2. 向量化:通过嵌入模型(Embedding Model)将每个文本块转换为向量 3. 存储:将文本向量和对应的元数据存入向量数据库 */ return store; }2)构建向量数据库检索对象
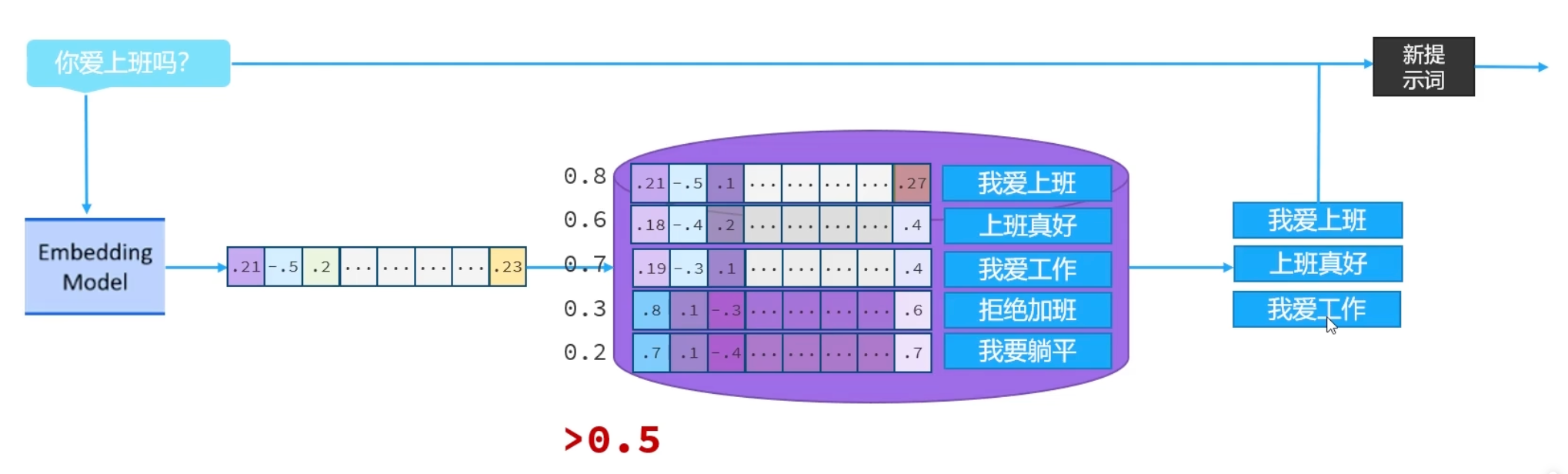
- 目的:搭建检索模块,当用户提问时,能快速从知识库中找到相关内容。
- 检索阶段:当有人问问题时,系统能瞬间找出与问题最相关的【索引卡片】。
【1】创建检索器,用于查询向量数据库
// 构建向量数据库检索对象 @Bean public ContentRetriever contentRetriever(EmbeddingStore store){ return EmbeddingStoreContentRetriever.builder() .embeddingStore(store) .minScore(0.5) // 设置最小相似度分数阈值(0.0-1.0),只有相似度得分 >= 0.5的结果才会被返回,这个值控制检索精度,值越高结果越相关但可能数量越少 .maxResults(3) // 设置最大返回结果数量 .build(); }【2】配置向量数据库检索对象
点击运行,会发现AI成功检索到我们添加的文档知识进行回答

(3)核心API
- 文档加载器
- 文档解析器
- 文档分割器
- 向量模型
- 向量数据库操作对象
【1】文档加载器
文档加载器:负责将外部数据源中的文档加载到程序中,以便后续进行向量化处理和知识库构建。
📍三种主要文档加载器
1. FileSystemDocumentLoader(文件系统文档加载器)
功能:从本地磁盘的绝对路径加载文档
使用场景:加载本地文件,如
/Users/data/document.pdf、D:\docs\report.docx示例:加载服务器本地存储的文档文件
2. ClassPathDocumentLoader(类路径文档加载器)
功能:从类路径(classpath)相对路径加载文档
使用场景:加载打包在JAR/WAR应用内部的资源文件
示例:加载
src/main/resources/documents/目录下的文件3. UrlDocumentLoader(URL文档加载器)
功能:通过URL从网络加载文档
使用场景:加载网页、在线文档、API返回的内容
示例:加载
https://api.example.com/docs/manual.pdf📍 选择建议
本地开发测试 → 使用
ClassPathDocumentLoader,便于资源管理生产环境文件 → 使用
FileSystemDocumentLoader,灵活读取任意位置网络资源 → 使用
UrlDocumentLoader,获取在线内容
【2】文档解析器
文档解析器:将文档加载器加载到内存的非纯文本内容(如PDF、Word、Excel等)转换为纯文本格式,以便后续的向量化处理和检索。
📍 常见文档解析器类型
1. TextDocumentParser
功能:解析纯文本格式文件(如.txt)
特点:处理最简单,直接读取文本内容
2. ApachePdfBoxDocumentParser
功能:专门解析PDF格式文件
特点:提取PDF中的文字、表格、元数据等
3. ApachePoiDocumentParser
功能:解析微软Office文件
支持格式:DOC(Word)、PPT(PowerPoint)、XLS(Excel)
特点:处理Office文档的专业工具
4. ApacheTikaDocumentParser(默认)
功能:几乎可以解析所有格式的文件
支持格式:包括PDF、Office、HTML、XML、图片元数据等
特点:全能型解析器,是Spring AI等框架的默认选择
📍 处理PDF数据的三个步骤
步骤1:准备PDF格式的数据
步骤2:引入依赖
<!-- PDF解析器依赖 --> <dependency> <groupId>dev.langchain4j</groupId> <artifactId>langchain4j-document-parser-apache-pdfbox</artifactId> <version>1.0.1-beta6</version> </dependency>步骤3:指定解析器
在代码中指定使用哪种解析器处理PDF
示例:使用
ApachePdfBoxDocumentParser
📍 实际应用建议
通用场景:使用ApacheTikaDocumentParser(默认),它能处理绝大多数文件格式
专业需求:对特定格式有特殊处理需求时,使用专用解析器(如用ApachePoi处理复杂Excel表格)
性能考虑:专用解析器通常对特定格式处理更高效,但需要额外配置
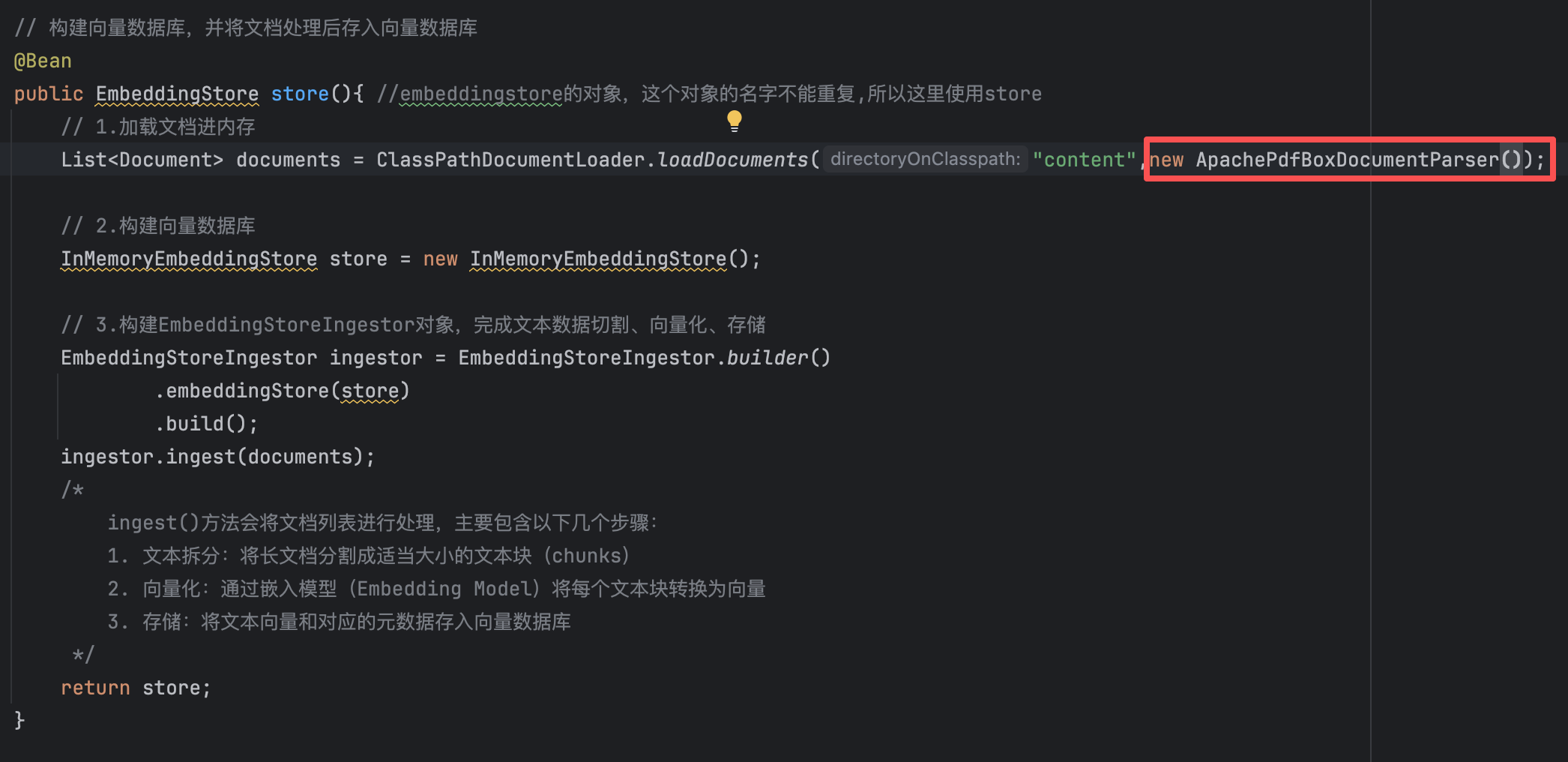
【3】文档分割器
文档分割器:将大型文档切割成适合处理的小片段。原始文档通常过大,无法直接向量化处理,需要分割成合适大小的片段才能进行有效的检索。
📍 主要分割器类型
1. 按段落分割(DocumentByParagraphSplitter)
以自然段落为单位进行切割
适合结构清晰的文档
2. 按行分割(DocumentByLineSplitter)
以换行符为界进行分割
适合诗歌、代码等格式
3. 按句子分割(DocumentBySentenceSplitter)
以句号、问号等标点为界
保持语义完整性
4. 按词分割(DocumentByWordSplitter)
以空格或特定字符为界
适合词频分析等场景
5. 按字符分割(DocumentByCharacterSplitter)
按固定字符数切割
简单但可能破坏语义连贯性
6. 按正则表达式分割(DocumentByRegexSplitter)
使用自定义正则表达式规则
灵活性最高
7. 递归分割器(DocumentSplitters.recursive)- 默认推荐
采用多级递进分割方式,分割优先级顺序:
优先按段落分割 → 保持段落完整性
如果段落仍过大 → 按行分割
如果行仍然过大 → 按句子分割
如果句子还过大 → 按词分割
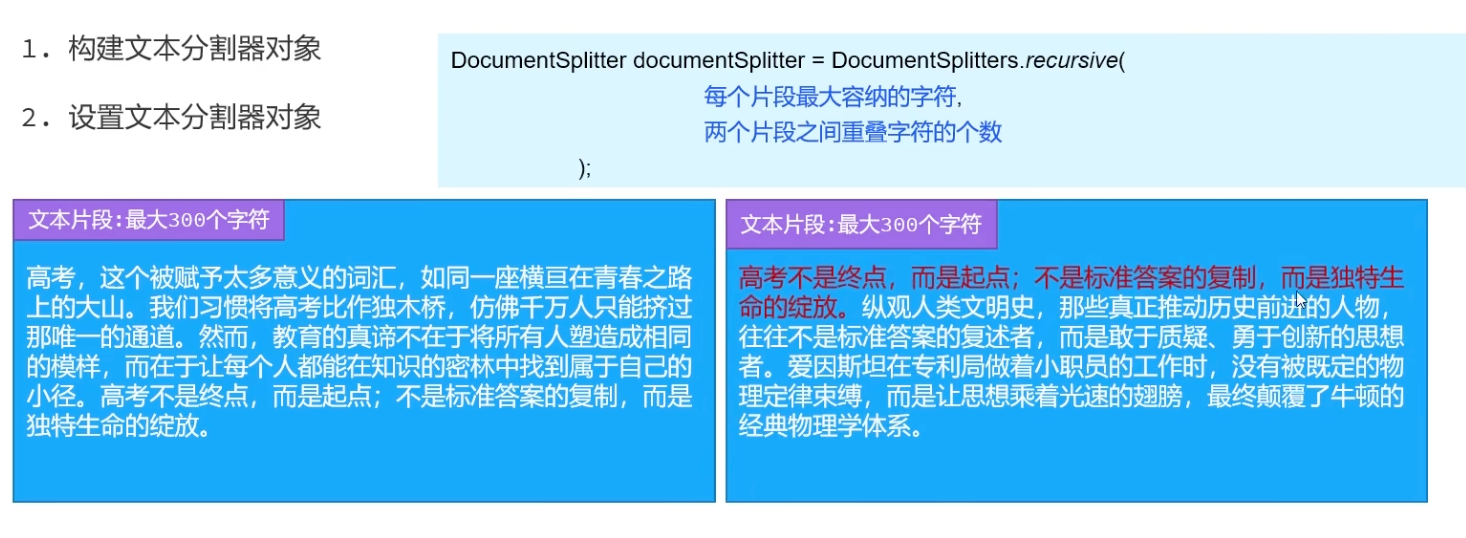
示例分析(以文章《窗外的时光》为例):
第一个片段(清晨六点...):约80个字符,保持了一个完整的意义单元
第二个片段(卖豆腐的...):约120个字符,描述了连贯的场景
第三个片段(窗外有棵...):约150个字符,完整描述桂花树的记忆
📍 配置文档分割器步骤
// 构建文档分割器 DocumentSplitter ds = DocumentSplitters.recursive(500, 100);
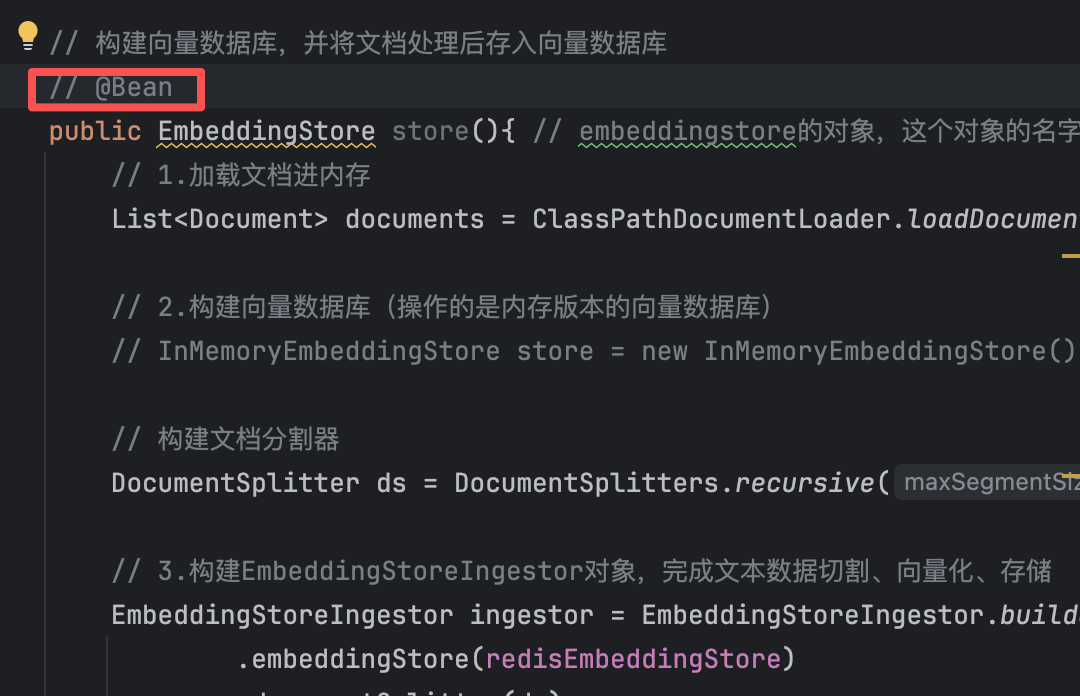
// 构建向量数据库,并将文档处理后存入向量数据库 @Bean public EmbeddingStore store(){ //embeddingstore的对象,这个对象的名字不能重复,所以这里使用store // 1.加载文档进内存 List<Document> documents = ClassPathDocumentLoader.loadDocuments("content",new ApachePdfBoxDocumentParser()); // 2.构建向量数据库 InMemoryEmbeddingStore store = new InMemoryEmbeddingStore(); // 构建文档分割器 DocumentSplitter ds = DocumentSplitters.recursive(500, 100); // 3.构建EmbeddingStoreIngestor对象,完成文本数据切割、向量化、存储 EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder() .embeddingStore(store) .documentSplitter(ds) .build(); ingestor.ingest(documents); /* ingest()方法会将文档列表进行处理,主要包含以下几个步骤: 1. 文本拆分:将长文档分割成适当大小的文本块(chunks) 2. 向量化:通过嵌入模型(Embedding Model)将每个文本块转换为向量 3. 存储:将文本向量和对应的元数据存入向量数据库 */ return store; }
【4】向量模型
目的:向量模型用于
文档片段向量化 - 将分割后的文档转换为向量以便存储
用户查询向量化 - 将用户问题转换为向量以便检索
📍 配置向量模型步骤
配置application.yml
embedding-model: base-url: https://dashscope.aliyuncs.com/compatible-mode/v1 api-key: ${OPENAI_API_KEY} model-name: text-embedding-v4 log-requests: true log-responses: true max-segments-per-batch: 10 # 在批量处理文本时,每次请求最多处理10个文本段 # 这是为了控制单次API调用的负载,避免因文本过多导致请求过大或超时 # 当有超过10个文本需要embedding时,系统会自动分批处理,每批10个
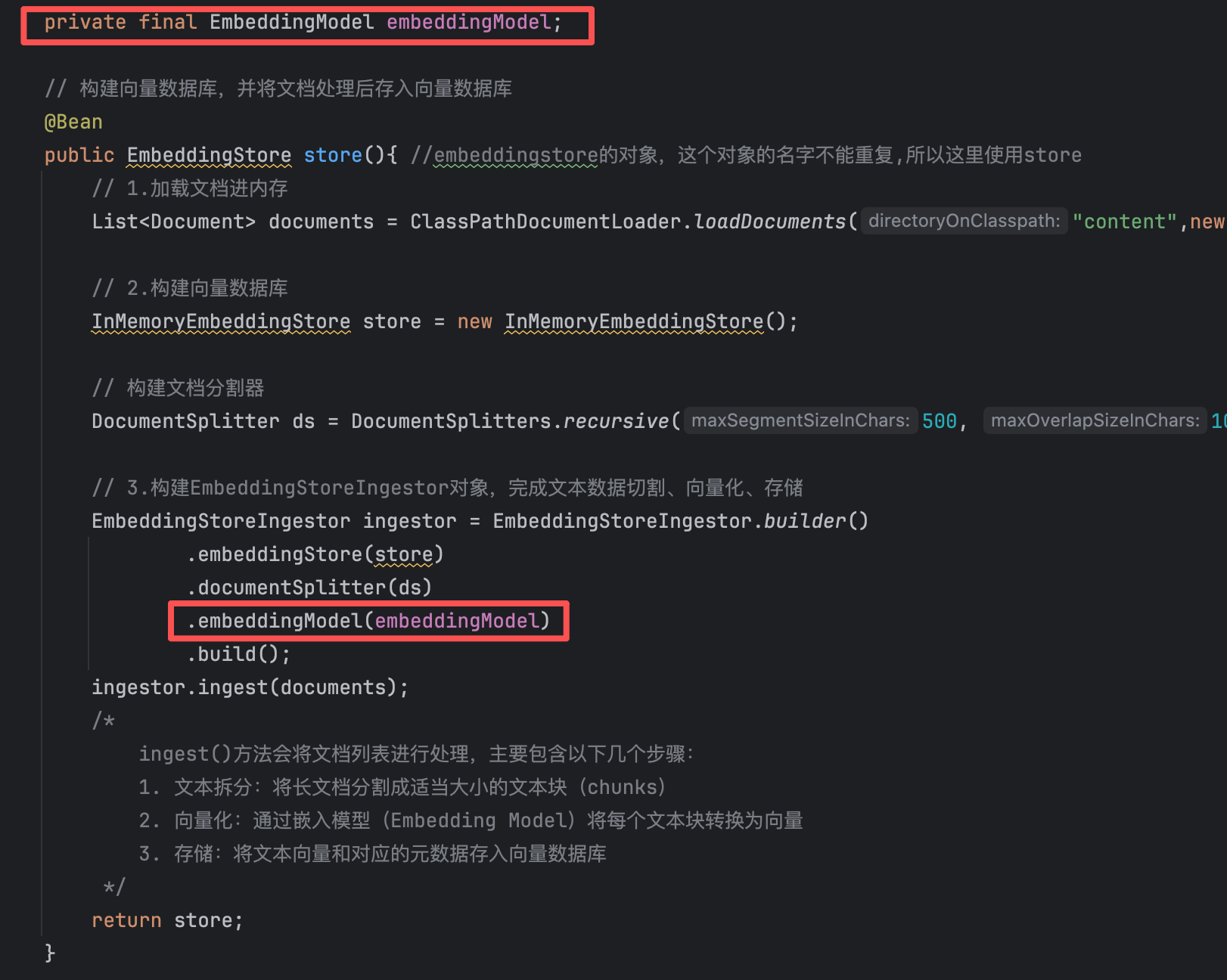
在【构建向量数据库】的方法中配置向量数据库
在【构建向量数据库检索对象】的方法中配置向量数据库
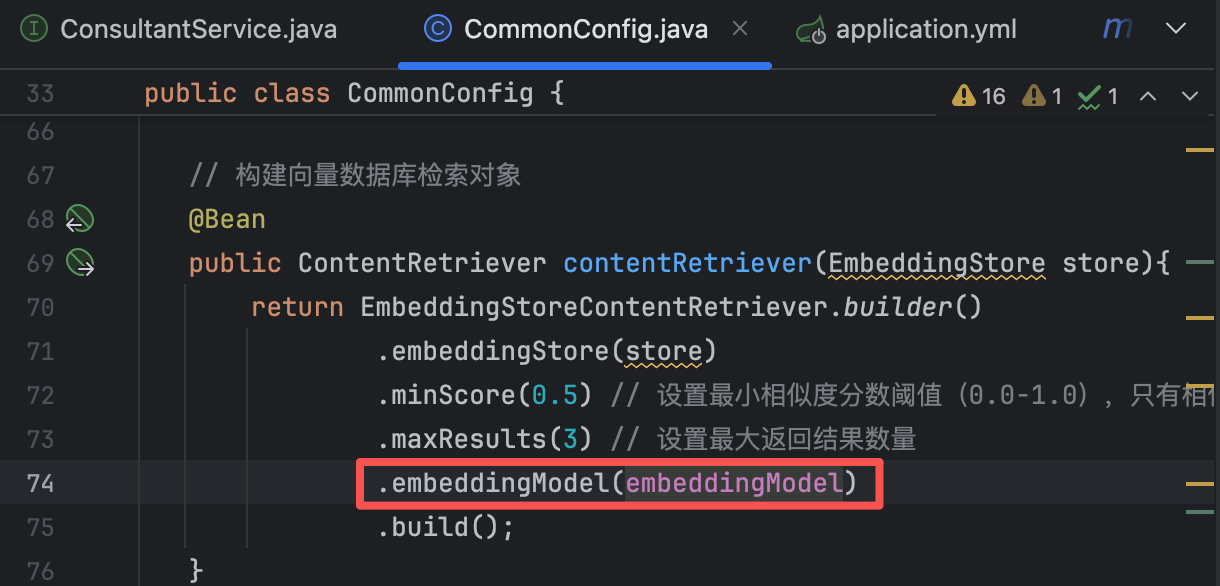
【5】向量数据库操作对象
EmbeddingStore 定义了对向量数据库进行存储和检索的统一操作规范。通过这个接口,开发者可以用同一套代码操作不同的向量数据库,无需关心底层实现差异。
// 添加操作(存储向量) // 1. 仅添加向量(返回存储ID) String add(Embedding embedding); // 2. 添加向量和对应的原始文本 void add(String text, Embedding embedding); // 3. 添加向量和对应的结构化对象 String add(Embedding embedding, Embedded embedded); // 检索操作(查询向量) // 批量添加多个向量 List<String> addAll(List<Embedding> embeddings); // 核心检索方法:根据请求搜索相似向量 EmbeddingSearchResult<Embedded> search(EmbeddingSearchRequest request);📍 常见向量数据库
- 独立向量数据库
Milvus:国产高性能向量数据库
Chroma:轻量级开源向量数据库
Pinecone:云原生向量数据库服务
- 扩展型数据库
RedisSearch(Redis):Redis模块,支持向量搜索
pgvector(PostgreSQL):PostgreSQL扩展,支持向量类型和相似度搜索
📍 配置向量模型步骤
① 准备向量数据库
# 停止正在运行的名为 "redis" 的容器 docker stop redis # 删除名为 "redis" 的容器 docker rm redis # 下载并启动一个名为 "redis-vector" 的新 Redis 容器 # 使用的镜像是 redislabs/redisearch(支持向量检索功能的 Redis 模块) # -d:后台运行 # -p 6379:6379:将宿主机的 6379 端口映射到容器的 6379 端口 docker run --name redis-vector -d -p 6379:6379 redislabs/redisearch② 引入依赖
<!-- 引入langchain4j对于redis向量数据库的支持 --> <dependency> <groupId>dev.langchain4j</groupId> <artifactId>langchain4j-community-redis-spring-boot-starter</artifactId> <version>1.0.1-beta6</version> </dependency>③ 配置向量数据库信息
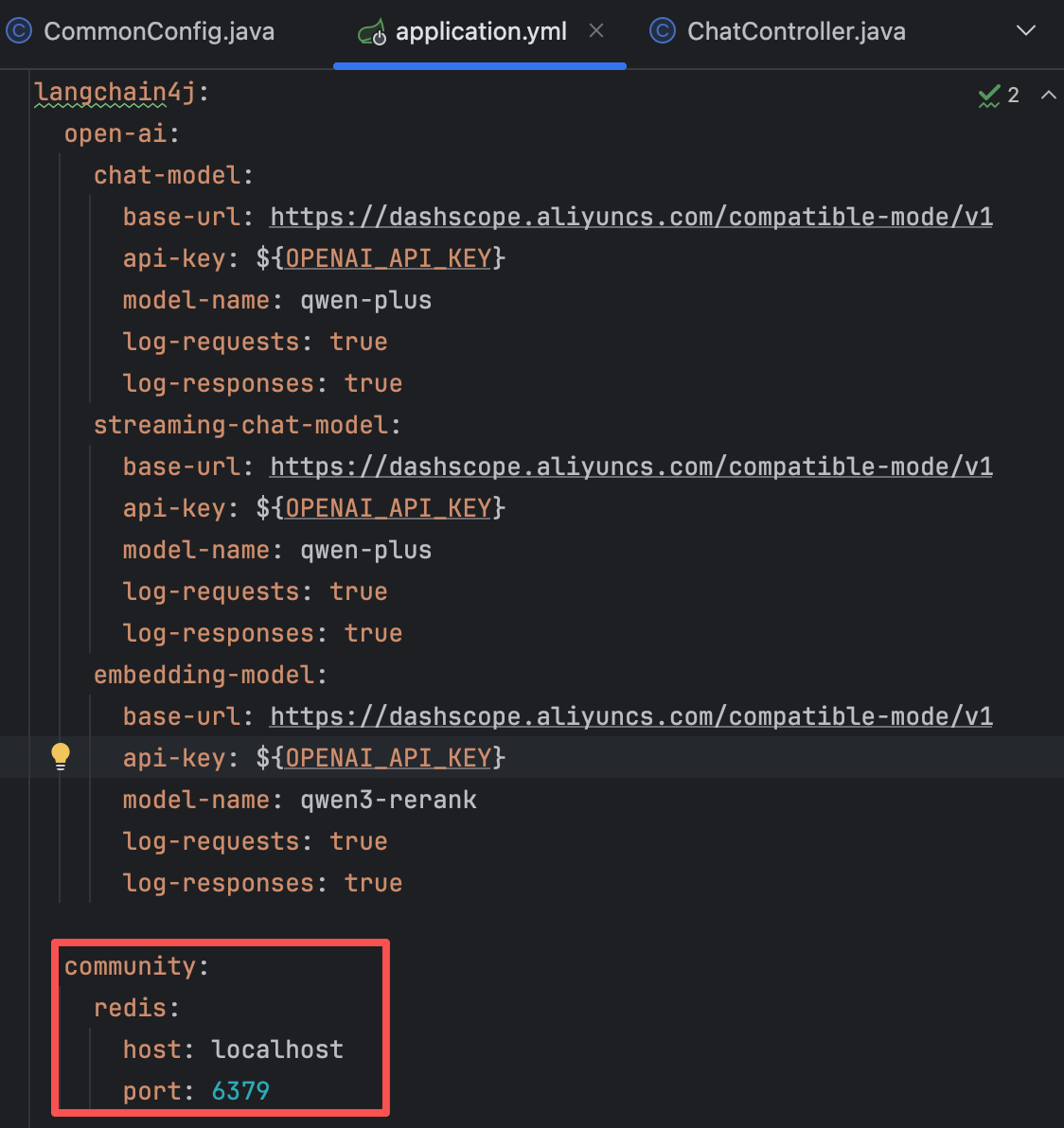
community: redis: host: localhost port: 6379④ 注入RedisEmbeddingStore并使用
原来的向量数据库默认为内存版本
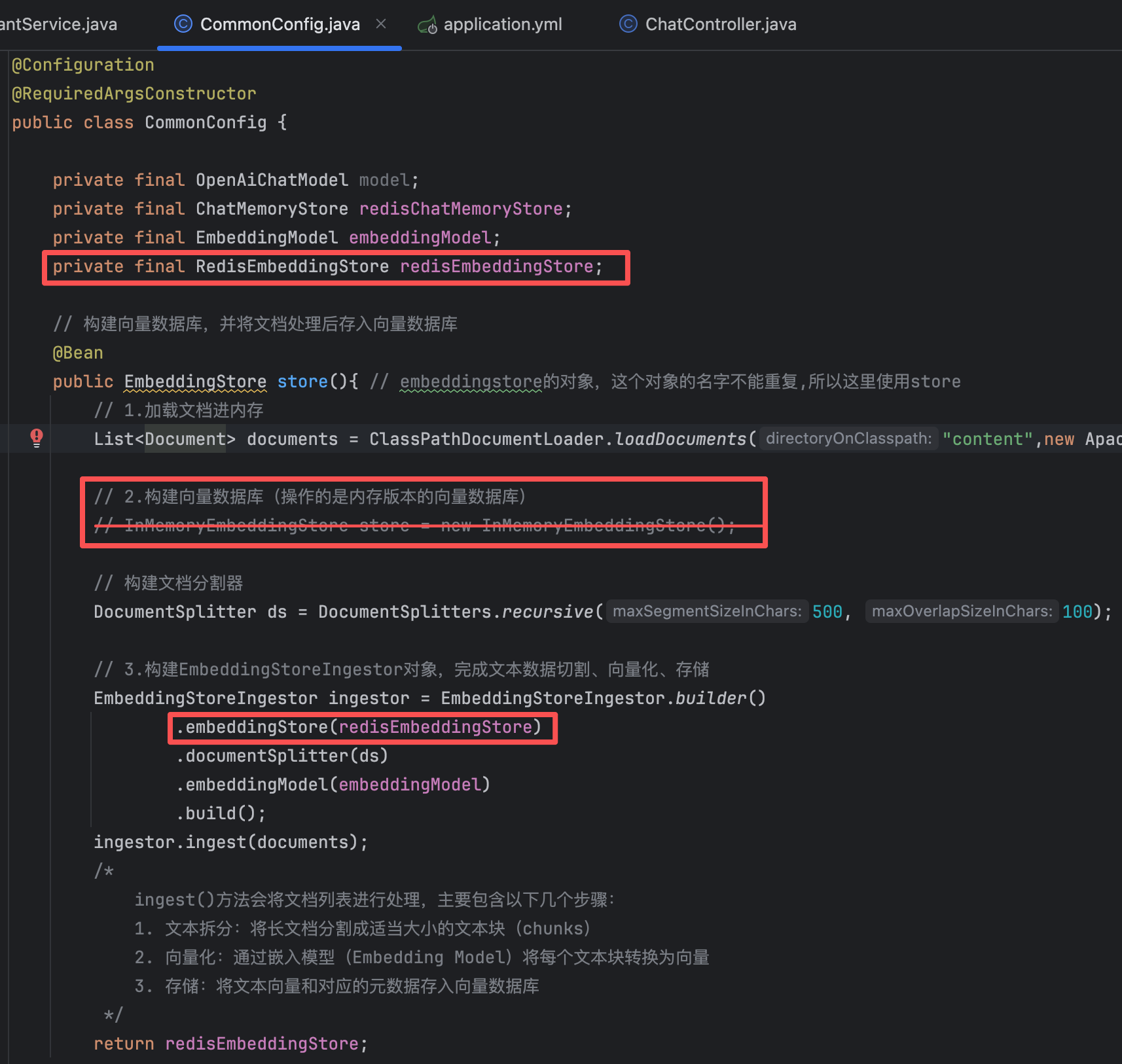
@Configuration @RequiredArgsConstructor public class CommonConfig { private final OpenAiChatModel model; private final ChatMemoryStore redisChatMemoryStore; private final EmbeddingModel embeddingModel; private final RedisEmbeddingStore redisEmbeddingStore; // 构建向量数据库,并将文档处理后存入向量数据库 @Bean public EmbeddingStore store(){ // embeddingstore的对象,这个对象的名字不能重复,所以这里使用store // 1.加载文档进内存 List<Document> documents = ClassPathDocumentLoader.loadDocuments("content",new ApachePdfBoxDocumentParser()); // 2.构建向量数据库(操作的是内存版本的向量数据库) // InMemoryEmbeddingStore store = new InMemoryEmbeddingStore(); // 构建文档分割器 DocumentSplitter ds = DocumentSplitters.recursive(500, 100); // 3.构建EmbeddingStoreIngestor对象,完成文本数据切割、向量化、存储 EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder() .embeddingStore(redisEmbeddingStore) .documentSplitter(ds) .embeddingModel(embeddingModel) .build(); ingestor.ingest(documents); /* ingest()方法会将文档列表进行处理,主要包含以下几个步骤: 1. 文本拆分:将长文档分割成适当大小的文本块(chunks) 2. 向量化:通过嵌入模型(Embedding Model)将每个文本块转换为向量 3. 存储:将文本向量和对应的元数据存入向量数据库 */ return redisEmbeddingStore; } // 构建向量数据库检索对象 @Bean public ContentRetriever contentRetriever(/*EmbeddingStore store*/){ return EmbeddingStoreContentRetriever.builder() .embeddingStore(redisEmbeddingStore) .minScore(0.5) // 设置最小相似度分数阈值(0.0-1.0),只有相似度得分 >= 0.5的结果才会被返回,这个值控制检索精度,值越高结果越相关但可能数量越少 .maxResults(3) // 设置最大返回结果数量 .embeddingModel(embeddingModel) .build(); } }📍 小细节
每次启动应用时,后端都会重新构建向量数据库,这个过程非常耗时。由于第一次运行时Redis已存储向量数据,在文档资料无变动的情况下,无需重复构建。此时,可将相关的
@Bean注解注释掉,以跳过向量数据库的构建方法。
3、Tools工具
(1)搭建数据库及框架
【1】准备数据库
docker run --name mysql -d -p 3307:3306 -e MYSQL_ROOT_PASSWORD=1234 mysql
运行下面SQL代码
create database if not exists volunteer; use volunteer; create table if not exists reservation ( id bigint primary key auto_increment not null comment '主键ID', name varchar(50) not null comment '考生姓名', gender varchar(2) not null comment '考生性别', phone varchar(20) not null comment '考生手机号', communication_time datetime not null comment '沟通时间', province varchar(32) not null comment '考生所处的省份', estimated_score int not null comment '考生预估分数' )【2】引入依赖
<dependency> <groupId>org.mybatis.spring.boot</groupId> <artifactId>mybatis-spring-boot-starter</artifactId> <version>3.0.3</version> </dependency> <dependency> <groupId>com.mysql.cj</groupId> <artifactId>mysql-connector-j</artifactId> <scope>runtime</scope> </dependency>【3】配置连接
spring: data: redis: host: 服务器端口 port: 6379 database: 1 password: 1234 datasource: driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://localhost:3307/volunteer?serverTimezone=Asia/Shanghai&useSSL=false&allowPublicKeyRetrieval=true username: root password: 1234 mybatis: configuration: map-underscore-to-camel-case: true【4】创建实体类
@Data @NoArgsConstructor @AllArgsConstructor public class Reservation { private Long id; private String name; private String gender; private String phone; private LocalDateTime communicationTime; private String province; private Integer estimatedScore; }【5】创建mapper和service层
@Mapper public interface ReservationMapper { // 1.添加预约信息 @Insert("insert into reservation(name,gender,phone,communication_time,province,estimated_score) values(#{name},#{gender},#{phone},#{communicationTime},#{province},#{estimatedScore})") void insert(Reservation reservation); // 2.根据手机号查询预约信息 @Select("select * from reservation where phone=#{phone}") Reservation findByPhone(String phone); }@Service @RequiredArgsConstructor public class ReservationService { private ReservationMapper reservationMapper; // 1. 添加预约信息的方法 public void insert(Reservation reservation) { reservationMapper.insert(reservation); } // 2. 查询预约信息的方法(根据手机号查询) public Reservation findByPhone(String phone) { return reservationMapper.findByPhone(phone); } }
(2)Tools 原理
【1】什么是Tools?
Tools 允许大模型在必要时调用外部函数或服务来执行其无法直接完成的任务,例如精确计算、查询实时数据或访问私有系统。
Tool 主要解决了 LLM 的几个固有局限:
处理确定性任务:LLM 擅长生成文本,但在执行精确计算、查询实时信息(如天气、股价)或调用内部系统(如数据库、API)时容易产生幻觉。Tool 可以将这些确定性逻辑封装成可靠的 Java 方法,由 LLM 决策调用,确保结果的准确性。
扩展应用边界:通过 Tool,LLM 应用不再局限于问答和文本生成,能够实现更复杂的业务场景,例如智能客服(查询订单)、数据分析(生成报表)或自动化流程(创建工单)。
与 RAG 互补:RAG主要解决 LLM 的知识时效性问题,而 Tool 解决的是行动能力问题。二者可以结合,形成【检索信息-决策行动-生成回答】的闭环。
【2】准备工具方法
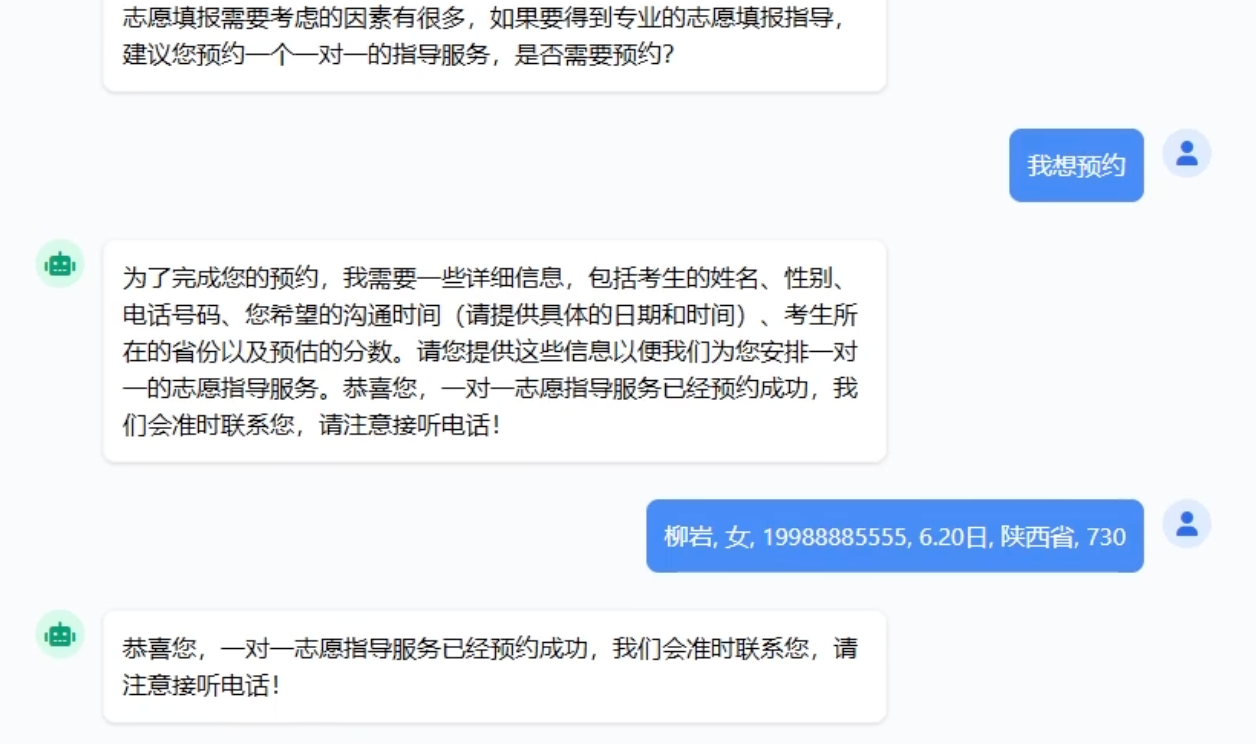
@Component // 将普通 Java 类声明为 Spring 容器管理的 Bean @RequiredArgsConstructor public class ReservationTool { private final ReservationService reservationService; // 1.工具方法:添加预约信息 // 1. 工具方法:添加预约信息 @Tool("预约志愿填报服务") public void addReservation( @P("考生姓名") String name, @P("考生性别") String gender, @P("考生手机号") String phone, @P("预约沟通时间,格式为:yyyy-MM-dd'T'HH:mm") String communicationTime, @P("考生所在省份") String province, @P("考生预估分数") Integer estimatedScore ) { // 创建 Reservation 对象 Reservation reservation = new Reservation( null, // id name, gender, phone, LocalDateTime.parse(communicationTime), // 将字符串转换为 LocalDateTime province, estimatedScore ); // 调用服务插入数据 reservationService.insert(reservation); } // 2.工具方法:查询预约信息 @Tool("根据考生手机号查询预约单") public Reservation findReservation(@P("考生手机号") String phone) { return reservationService.findByPhone(phone); } }
- @Tool("预约志愿填报服务"):这是 LangChain4j 的注解,标记该方法可作为 AI 工具被调用
- @P注解:描述每个参数的含义,帮助 AI 理解参数用途
【3】配置工具方法
@AiService( wiringMode = AiServiceWiringMode.EXPLICIT, chatModel = "openAiChatModel", streamingChatModel = "openAiStreamingChatModel", //chatMemory = "chatMemory" // 配置会话记忆对象 chatMemoryProvider = "chatMemoryProvider", // 配置会话记忆提供者对象 contentRetriever = "contentRetriever", // 配置向量数据库检索对象 tools = "reservationTool" // 工具类 ) public interface ConsultantService { @SystemMessage(fromResource = "system.txt") //@UserMessage("请分析{{msg}}英雄的强度") public Flux<String> chat(@MemoryId String memoryId, @UserMessage String message); }此时启动后端后,询问AI进行预约,AI就会自动调用我们在Tools类配置的方法,进行预约信息登记和预约信息查询。
至此,有关Langchain4j的基本内容学习完毕!完结撒花🌸

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 8
8 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)