RAG技术全解析:解决大模型知识局限,Spring AI+智普AI实战指南
本文详解检索增强生成(RAG)技术,通过将大模型与外部知识库结合,解决知识过期、私有数据不可用等痛点。深入解析RAG与Embedding的协同原理,介绍索引、检索、生成三大核心流程,并通过Spring AI+智普AI实现本地知识库检索的完整案例,帮助开发者掌握无需微调即可扩展大模型能力的方法,为构建生产级RAG应用奠定基础。
本文详解检索增强生成(RAG)技术,通过将大模型与外部知识库结合,解决知识过期、私有数据不可用等痛点。深入解析RAG与Embedding的协同原理,介绍索引、检索、生成三大核心流程,并通过Spring AI+智普AI实现本地知识库检索的完整案例,帮助开发者掌握无需微调即可扩展大模型能力的方法,为构建生产级RAG应用奠定基础。
在 AI 应用开发中,大模型常面临 “知识过期”“不懂私有数据” 的痛点,而检索增强生成(RAG)技术正是解决这一问题的核心方案。RAG 能够将大模型与私有知识库结合,让生成的回答更准确、更具针对性。本文将深入拆解 RAG 的技术原理、核心流程,重点讲解其与 Embedding 技术的协同逻辑,并结合智普 AI 实现本地知识库检索的完整实操,帮助大家掌握 Spring AI 中 RAG 模块的开发精髓。
一、什么是 RAG?核心原理与核心价值
(一)RAG 定义
Retrieval-Augmented Generation(RAG)即检索增强生成,是一种结合 “检索” 与 “生成” 的 AI 技术。它通过在大模型生成回答前,从外部知识库中检索与用户问题相关的信息,并将这些信息作为上下文传递给大模型,从而让大模型基于外部知识生成更准确、更可靠的回答。
(二)RAG 的核心价值
RAG 的核心价值是为大模型 “外接动态知识库”,在不重训 / 微调的前提下,低成本解决知识过期、私有数据不可用、幻觉与高成本四大核心痛点,让回答更准、更新、更合规、更易维护。
- 解决知识局限:无需重新训练大模型,即可让其掌握私有数据(如企业文档、专业知识库)或最新信息,避免 “知识过期” 问题。
- 提升回答准确性:基于具体的外部知识生成回答,减少大模型 “一本正经地胡说八道”(幻觉)现象。
- 降低开发成本:无需投入海量算力进行模型微调,通过简单的知识库配置即可扩展大模型能力。
- 支持灵活更新:外部知识库可独立更新,无需改动大模型或应用代码,适配快速变化的业务需求。
(三)RAG 与 Embedding 的协同逻辑:语义检索的核心支撑
RAG 技术的核心是 “精准检索”,而 Embedding 技术是实现这一目标的关键前提,二者是 “基础支撑” 与 “上层应用” 的紧密协同关系。
简单来说:Embedding 是 RAG 技术的 “语义翻译官”,它将非结构化的文本(知识库片段、用户问题)翻译成机器可理解、可计算的向量语言,没有 Embedding 提供的语义量化能力,RAG 就无法实现高效的 “检索增强”,只能依赖大模型的原生知识库。
二、RAG 的核心流程
RAG 技术的完整流程可分为三个核心阶段,每个阶段都与 Embedding 技术深度协同:
(一)索引阶段:知识库向量化存储
- 将本地知识库(文档、数据库等)解析为文本片段(Chunks),再通过 Embedding 模型将这些片段转换为语义向量保存到向量数据库。
(二)检索阶段:相似文本精准匹配
- 将用户提出的问题通过相同的 Embedding 模型将问题转换为语义向量,然后,在向量数据库中,通过相似度算法(如余弦相似度)计算问题向量与所有文本片段向量的相似度,筛选出 TopK(如 Top2、Top3)个最相似的文本片段。
(三)生成阶段:结合上下文生成回答
将检索到的相关文本片段与用户问题作为上下文传递给大模型,辅助生成准确回答。而这些片段之所以能精准匹配用户问题,本质是 Embedding 技术保证了 “问题语义” 与 “片段语义” 的一致性映射。
下图是 AI 如何处理文档并回答用户问题的完整流程图:
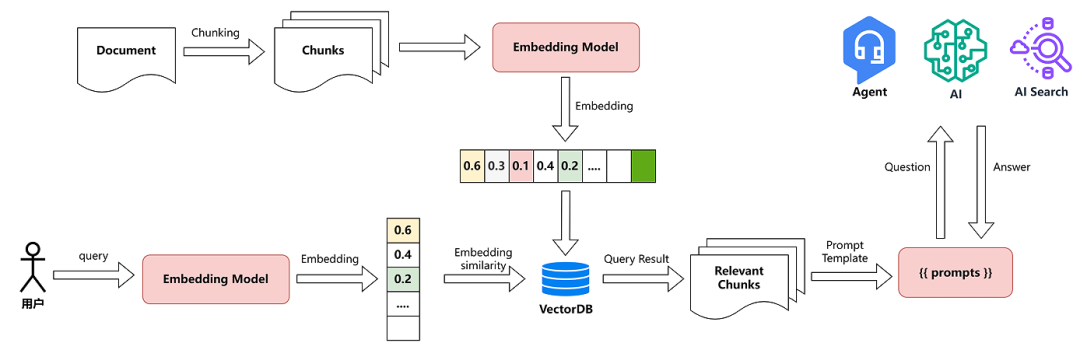
三、实操准备:环境配置(基于 Spring AI + 智普 AI)
(一)准备工作
需提前完成智普 AI 账号注册与 API Key 获取(参考上一篇 Embedding 文章的配置步骤),并创建 Spring Boot 项目。
-
创建 Spring Boot 项目
-
项目名称:Weiz-SpringAI-RAG
-
核心配置:JDK 17、Spring Boot 3.5.0、Maven
-
依赖选择:Spring Web(后续通过 pom.xml 补充 Embedding 相关依赖)
项目结构如下:
Weiz-SpringAI-RAG/
├── src/
│ ├── main/
│ │ ├── java/
│ │ │ └── com/
│ │ │ └── example/
│ │ │ └── weizspringai/
│ │ │ ├── WeizSpringAiRAGApplication.java
│ │ │ ├── controller/
│ │ │ └── service/
│ │ └── resources/
│ │ ├── application.properties
│ └── test/
└── pom.xml
2. 配置 pom.xml 依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>com.example</groupId>
<artifactId>Weiz-SpringAI</artifactId>
<version>0.0.1-SNAPSHOT</version>
</parent>
<artifactId>Weiz-SpringAI-RAG</artifactId>
<name>Weiz-SpringAI-RAG</name>
<description>Weiz-SpringAI-RAG</description>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-zhipuai</artifactId>
</dependency>
<!-- spring-ai-client-chat 中包括 TokenTextSplitter、TextReader、Document 等工具 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-client-chat</artifactId>
<version>${spring-ai.version}</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
</project>
- application.properties 配置
# 应用名称
spring.application.name=Weiz-SpringAI-RAG
# 服务端口
server.port=8080
# 智普 AI 基础配置
spring.ai.zhipuai.api-key=你的智普 AI API Key
spring.ai.zhipuai.base-url=https://open.bigmodel.cn/api/paas
# Embedding 模型配置(用于文本向量化)
spring.ai.zhipuai.embedding.options.model=embedding-2
# Chat 模型配置(用于生成回答)
spring.ai.zhipuai.chat.options.model=GLM-4-Flash
注意,需将 “你的智普 AI API Key” 替换为实际获取的密钥。
(二)准备本地知识库文件
在 src/main/resources 目录下创建 户外旅行安全指南.txt,作为本地知识库,内容如下:
户外旅行安全指南
----
1.露营安全
- 选址:避开低洼积水区、陡坡和可能落石的区域,优先选择平坦硬质地面。
- 防火:远离干草、枯枝等易燃物,使用炉具时保持通风,睡前彻底熄灭明火。
- 防虫:携带驱蚊液、防虫网,避免在草丛密集处搭建帐篷,睡前检查帐篷内是否有虫类。
- 应急:随身携带手电筒、急救包和足够的饮用水,提前下载离线地图。
----
2.徒步安全
- 路线规划:提前查询路线难度、天气情况,选择与自身体能匹配的路线,告知亲友行程。
- 装备要求:必须穿防滑登山鞋、戴防晒帽,携带充足食物和水,配备登山杖和护膝。
- 环境应对:遇到暴雨立即寻找高地躲避,避免涉险过河;遭遇野生动物保持冷静,切勿投喂或驱赶。
- 体能管理:保持匀速前进,每小时休息 10-15 分钟,避免过度疲劳。
----
3.城市漫游安全
- 交通:骑行遵守交通规则,不逆行、不闯红灯,佩戴安全头盔;乘坐公共交通保管好个人财物。
- 选址:避开偏僻小巷和治安较差区域,优先选择人流密集的商业街区和景点。
- 应急:保存当地派出所、医院的联系方式,携带少量现金备用,手机保持电量充足。
四、实操案例:RAG 本地知识库检索完整实现
本案例将实现 RAG 的全流程:加载本地知识库并向量化、接收用户问题并检索相似文本、结合上下文生成回答。
1. 核心工具类:复用相似度计算逻辑
可以复用上一篇文章中的SimilarityCalculator.java类,该类封装了余弦相似度、欧氏距离等多种主流算法,支持 RAG 检索阶段的相似度计算。
2. 编写 RagService
创建 com.example.weizspringai.service.RagService 类,整合索引、检索、生成三个RAG 核心逻辑:
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.embedding.EmbeddingModel;
import org.springframework.core.io.ClassPathResource;
import org.springframework.core.io.Resource;
import org.springframework.stereotype.Service;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
import java.util.ArrayList;
import java.util.List;
@Service
public class RagService {
// Embedding 模型(文本向量化)
private final EmbeddingModel embeddingModel;
// Chat 模型(生成回答)
private final ChatClient chatClient;
// 本地知识库文本片段
private final List<String> docChunks = new ArrayList<>();
// 文本片段对应的向量
private final List<float[]> docVectors = new ArrayList<>();
// 相似度算法(默认余弦相似度,可根据需求修改)
private final EmbeddingService.SimilarityAlgorithm similarityAlgorithm = EmbeddingService.SimilarityAlgorithm.COSINE;
// 构造方法注入依赖,初始化知识库(索引阶段)
public RagService(EmbeddingModel embeddingModel, ChatClient.Builder chatClientBuilder) throws IOException {
this.embeddingModel = embeddingModel;
this.chatClient = chatClientBuilder.build();
// 加载本地知识库文件并切分片段
loadAndSplitDocument();
}
/**
* 加载本地知识库文件,切分为文本片段(索引阶段第一步)
*/
private void loadAndSplitDocument() throws IOException {
// 读取 resources 目录下的知识库文件
Resource resource = new ClassPathResource("户外旅行安全指南.txt");
String content = new String(resource.getInputStream().readAllBytes(), StandardCharsets.UTF_8);
// 按 "----" 切分文本(根据文件格式自定义切分规则)
String[] chunks = content.split("----");
for (String chunk : chunks) {
String cleanChunk = chunk.strip();
if (!cleanChunk.isBlank()) {
docChunks.add(cleanChunk);
// 文本片段向量化并缓存(索引阶段第二步、第三步)
docVectors.add(embeddingModel.embed(cleanChunk));
}
}
}
/**
* 处理用户提问,返回 RAG 增强后的回答(检索+生成阶段)
* @param question 用户问题
* @return 大模型生成的回答
*/
public String answer(String question) {
// 1. 用户问题向量化(检索阶段第一步)
float[] questionVector = embeddingModel.embed(question);
// 2. 检索 Top2 最相似的文本片段(检索阶段第二步、第三步)
List<String> topRelevantChunks = retrieveTopRelevantChunks(questionVector, 2);
// 3. 构建上下文(生成阶段第一步)
String context = String.join("\n---\n", topRelevantChunks);
// 4. 构建提示词(生成阶段第二步)
String prompt = String.format(
"以下是户外旅行安全指南的知识:\n%s\n请基于上述知识,简洁明了地回答问题:%s",
context, question
);
// 5. 调用 Chat 模型生成回答(生成阶段第三步)
return chatClient.prompt()
.system("你是户外旅行安全助手,仅基于提供的上下文回答问题,不添加额外信息。")
.user(prompt)
.call()
.content();
}
/**
* 检索 TopK 最相似的文本片段(检索阶段核心逻辑)
* @param questionVector 用户问题向量
* @param topK 返回前 K 个相似片段
* @return TopK 相似文本片段
*/
private List<String> retrieveTopRelevantChunks(float[] questionVector, int topK) {
List<ChunkSimilarity> similarityList = new ArrayList<>();
// 计算问题向量与所有文本片段向量的相似度(使用指定算法)
for (int i = 0; i < docVectors.size(); i++) {
double sim = calculateSimilarity(questionVector, docVectors.get(i));
similarityList.add(new ChunkSimilarity(i, sim));
}
// 按相似度降序排序,取前 topK 个
similarityList.sort((a, b) -> Double.compare(b.similarity, a.similarity));
return similarityList.stream()
.limit(topK)
.map(item -> docChunks.get(item.index))
.toList();
}
/**
* 相似度计算(调用工具类,支持算法切换)
*/
private double calculateSimilarity(float[] a, float[] b) {
return switch (similarityAlgorithm) {
case COSINE -> SimilarityCalculator.cosineSimilarity(a, b);
case EUCLIDEAN -> SimilarityCalculator.euclideanSimilarity(a, b);
case PEARSON -> SimilarityCalculator.pearsonCorrelation(a, b);
case MANHATTAN -> SimilarityCalculator.manhattanSimilarity(a, b);
default -> SimilarityCalculator.cosineSimilarity(a, b); // 默认 fallback 到余弦相似度
};
}
/**
* 辅助类:存储文本片段索引与相似度
*/
private static class ChunkSimilarity {
int index;
double similarity;
ChunkSimilarity(int index, double similarity) {
this.index = index;
this.similarity = similarity;
}
}
}
3. 编写 RagController
创建 com.example.weizspringai.controller.RagController 类,提供 RAG 检索接口:
import com.example.springaiembedding.service.RagService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import java.util.Map;
@RestController
@RequestMapping("/rag")
public class RagController {
@Autowired
private RagService ragService;
/**
* RAG 本地知识库检索接口
* @param question 用户问题
* @return 包含问题与回答的响应
*/
@GetMapping("/ask")
public Map<String, String> ask(@RequestParam("question") String question) {
String answer = ragService.answer(question);
return Map.of(
"question", question,
"answer", answer
);
}
}
4. 测试 RAG 本地知识库检索
- 启动 Weiz-SpringAI-Rag 项目,浏览器访问:http://localhost:8080/rag/ask?question=露营选址有什么安全要求?。
- 响应结果如下:
{
"question": "露营选址有什么安全要求?",
"answer": "露营选址需避开低洼积水区、陡坡和可能落石的区域,优先选择平坦硬质地面,同时要远离干草、枯枝等易燃物,避免在草丛密集处搭建帐篷。"
}
再测试其他问题,如http://localhost:8080/rag/ask?question=徒步时遇到暴雨该怎么办?,响应:
{
"question": "徒步时遇到暴雨该怎么办?",
"answer": "徒步遇到暴雨时,应立即寻找高地躲避,避免涉险过河,同时注意远离陡坡和可能落石的区域,确保自身安全。"
}
测试结果表明,大模型能够基于本地知识库文件的内容生成准确回答,验证了 RAG 技术的核心价值。
五、RAG 优化思路(为后续进阶铺垫)
当前 RAG 实现存在一些可优化点,后续文章将深入讲解:
-
文本切分策略
当前按固定符号切分,可优化为按 Token 数量切分(如每段 400-800 字符),避免语义断裂。
-
向量数据库集成
当前使用内存缓存向量,生产环境需替换为 Milvus、Redis 等向量数据库,支持海量数据存储与高效检索。
-
相似度阈值过滤
仅保留相似度高于阈值(如 0.05)的文本片段,避免引入无关噪声。
-
上下文扩展
检索到相关片段后,同时获取其前后相邻片段,提升语义连贯性。
-
引入 Spring AI 开箱即用 RAG 组件
Spring AI 提供了 QuestionAnswerAdvisor、RetrievalAugmentationAdvisor 等开箱即用的 RAG 组件,可简化开发流程,支持自动索引、检索优化、提示词工程等功能,适配生产级场景。
-
算法动态选择
根据知识库类型(如短文本、专业文档、稀疏向量)自动匹配最优相似度算法,例如专 业文档优先使用皮尔逊相关系数,稀疏向量优先使用杰卡德相似度。
总结
本文深入解析了 RAG 技术的核心原理、核心流程,重点厘清了其与 Embedding 技术的协同逻辑,并通过 Spring AI + 智普 AI 实现了 RAG 本地知识库检索的完整案例。RAG 技术通过 “检索外部知识 + 增强生成能力” 的模式,完美解决了大模型的知识局限问题,而 Embedding 技术提供的语义向量能力,是 RAG 实现精准检索的核心支撑。
核心结论如下:
- RAG 的核心价值在于 “无需微调,快速扩展大模型能力”,适配私有数据、最新知识等场景。
- Embedding 是 RAG 的 “语义基础”,其生成的语义向量决定了检索阶段的精准度,进而影响最终回答质量。
- 基础版 RAG 实现简单,但生产环境需关注文本切分、向量数据库集成、算法选择等优化点,提升系统的稳定性、高效性和准确性。
最后
我在一线科技企业深耕十二载,见证过太多因技术更迭而跃迁的案例。那些率先拥抱 AI 的同事,早已在效率与薪资上形成代际优势,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在大模型的学习中的很多困惑。
我整理出这套 AI 大模型突围资料包:
- ✅AI大模型学习路线图
- ✅Agent行业报告
- ✅100集大模型视频教程
- ✅大模型书籍PDF
- ✅DeepSeek教程
- ✅AI产品经理入门资料
完整的大模型学习和面试资料已经上传带到CSDN的官方了,有需要的朋友可以扫描下方二维码免费领取【保证100%免费】👇👇

为什么说现在普通人就业/升职加薪的首选是AI大模型?
人工智能技术的爆发式增长,正以不可逆转之势重塑就业市场版图。从DeepSeek等国产大模型引发的科技圈热议,到全国两会关于AI产业发展的政策聚焦,再到招聘会上排起的长队,AI的热度已从技术领域渗透到就业市场的每一个角落。
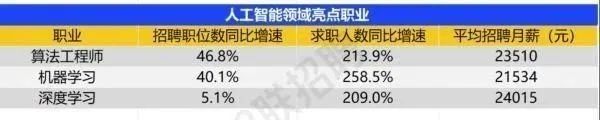
智联招聘的最新数据给出了最直观的印证:2025年2月,AI领域求职人数同比增幅突破200% ,远超其他行业平均水平;整个人工智能行业的求职增速达到33.4%,位居各行业榜首,其中人工智能工程师岗位的求职热度更是飙升69.6%。
AI产业的快速扩张,也让人才供需矛盾愈发突出。麦肯锡报告明确预测,到2030年中国AI专业人才需求将达600万人,人才缺口可能高达400万人,这一缺口不仅存在于核心技术领域,更蔓延至产业应用的各个环节。


资料包有什么?
①从入门到精通的全套视频教程⑤⑥
包含提示词工程、RAG、Agent等技术点
② AI大模型学习路线图(还有视频解说)
全过程AI大模型学习路线

③学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的

④各大厂大模型面试题目详解

⑤ 这些资料真的有用吗?
这份资料由我和鲁为民博士共同整理,鲁为民博士先后获得了北京清华大学学士和美国加州理工学院博士学位,在包括IEEE Transactions等学术期刊和诸多国际会议上发表了超过50篇学术论文、取得了多项美国和中国发明专利,同时还斩获了吴文俊人工智能科学技术奖。目前我正在和鲁博士共同进行人工智能的研究。
所有的视频教程由智泊AI老师录制,且资料与智泊AI共享,相互补充。这份学习大礼包应该算是现在最全面的大模型学习资料了。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。


智泊AI始终秉持着“让每个人平等享受到优质教育资源”的育人理念,通过动态追踪大模型开发、数据标注伦理等前沿技术趋势,构建起"前沿课程+智能实训+精准就业"的高效培养体系。
课堂上不光教理论,还带着学员做了十多个真实项目。学员要亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!


如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓**


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 7
7 0
0- 0



 已为社区贡献648条内容
已为社区贡献648条内容

所有评论(0)