大语言模型LLM推理硬件的挑战以及研究方向,建议收藏!
本文探讨了大型语言模型(LLM)推理面临的内存带宽和互连延迟等关键挑战。作者指出,随着模型规模扩大和多模态应用增多,内存容量和带宽成为主要瓶颈,而非计算能力。论文提出了四个研究方向:高带宽闪存(HBF)提供大容量存储、近存计算(PNM)提升内存带宽、3D堆叠技术优化集成密度,以及低延迟互连加速芯片间通信。这些方案旨在解决当前GPU/TPU架构在推理效率上的不足,为下一代AI硬件设计提供新思路。文章
TL;DR
Xiaoyu Ma 和David Patterson有一篇论文《Challenges and Research Directions for Large Language Model Inference Hardware》正好CES上老黄有一个演讲也涉及到一些KVCache和内存层次结构的内容, 在这里一并进行一些分析. 而对于Rubin的一些分析后续留在3月GTC后有更详细的信息再说. 首先我们来解析一下这篇论文.
作者首先阐述了LLM推理的难题, 其底层Transformer模型的自回归解码(Decode)阶段, 使得LLM的推理与训练有着本质上的不同.在最近AI趋势的加剧下, 其主要挑战在于内存和互联, 而非计算. 因此这篇文章主要讨论四个体系结构的研究机遇:
- HBF: 用于以类HBM的带宽提供10倍内存容量的高带宽闪存
- PNM: 用于实现高内存带宽的近存计算, 将计算单元置于内存附近以获得高内存带宽.
- 3D内存-逻辑堆叠, 通过垂直集成实现高带宽和低功耗.
- 用于加速通信的低延迟互联, 针对推理中频繁的小消息通信进行网络优化
其实核心问题就是内存带宽和互连上, Patterson讲了这么多, 其实有一个很显然的答案: 对于3D-Stacking, Groq这样的Cycle级的确定性控制在对散热和功耗的抑制上是有好处的, 它也是一个PNM的架构. 而对于其它问题, 将SRAM直接Attach在网络上并构建PNM, 然后外挂一些HBF做大容量大带宽的池化不就行了么? 这不就是很多年前我折腾NetDAM早就分析清楚的一条路么? 本文的最后一章将详细阐述.

本文目录如下:
1. 引言: LLM推理是一场危机
2. 当前LLM推理硬件及其低效性
2.1 Decode挑战1: 内存
2.2 Decode挑战2: 端到端延迟
3. 四大研究机遇
3.1 高带宽闪存 (High Bandwidth Flash, HBF)
3.2 近存计算 (Processing-Near-Memory, PNM)
3.3 3D内存-逻辑堆叠 (3D memory-logic stacking)
3.4 低延迟互联 (Low-Latency interconnect)
4. Nvidia的解决方案
4.1 BlueField 4
4.2 Nvidia KVCache方案
5. 一些潜在的方案
5.1 3D-Stacking
5.2 HBF+PNM+Interconnect
5.3 NetDAM
- 引言: LLM推理是一场危机
=================
作者首先指出, 当前学术界的体系结构研究与工业界的实际需求存在脱节. Patterson职业生涯开始的1976年, 大概有40%的体系结构的论文来自工业界, 而到了ISCA 2025, 这一比例已降至4%以下, 这表明学术研究与工业实践之间几乎脱节.
这一段黑的真漂亮, 其实我也一直想说在网络互连领域也有同样的问题, 审稿人大多数是在学术界的, 其taste决定了无法了解到工业界的实际问题, 对于一些工业界非常简单又巧妙的解决方案以及一些生产环境下的约束了解甚少.
作者开篇的这段话不仅仅是一个引子, 更是作者写作本文的深层动机. 他希望通过这篇文章, 像一座桥梁, 重新连接学术界和工业界. 他在呼吁学术界的研究者们, 将目光投向工业界真正"卡脖子"的难题上, 而不是在一些与现实脱节的"象牙塔"问题上打转. 这为本文提出的研究方向赋予了更强的现实意义和紧迫感.
LLM推理的成本和难度正在成为其经济可行性的决定性因素. 据预测, 推理芯片的年销售额在未来5-8年内将增长4到6倍. 尽管训练阶段展示了非凡的AI突破, 但推理成本却决定了其经济可行性. 随着这些顶尖模型使用量的急剧增加, 公司们发现为其提供服务的成本非常高昂.
同时, 以下几个AI新趋势使得推理变得更加困难:
| 趋势 | 核心机制 | 对推理的影响 | 主要瓶颈 |
|---|---|---|---|
| MoE | 用大量稀疏激活的专家网络替代密集网络 | 模型参数量暴增, 需要在众多专家中路由. | 内存容量 (存下所有专家), 互联 (在专家间通信) |
| Reasoning | 生成大量中间"思考"步骤 | 输出序列长度急剧增加, 延迟变长. | 内存带宽 (频繁读写KV Cache), 延迟 |
| Multimodal | 处理图像/音频/视频等大数据类型 | 输入/输出的数据量更大. | 内存容量 & 带宽 |
| Long context | 增加模型能参考的输入信息量 | KV Cache体积线性增长. | 内存容量 & 带宽 |
| RAG | 从外部数据库检索信息作为上下文 | 增加了输入处理步骤和上下文长度. | 内存容量 & 带宽 |
| Diffusion | 并行生成, 迭代优化 | 计算步骤增多, 但非自回归. | 计算 |
这是一个非常好的总结, 对于体系结构而言, 前五个趋势的瓶颈归结为内存和通信, 最后一个瓶颈为计算.
- 当前LLM推理硬件及其低效性
=================
LLM推理主要包含两个阶段: Prefill 和 Decode, 前者是一个计算密集型(Compute Bound), 而后者是一个内存密集型(Memory Bound). 当前主流的GPU/TPU在为训练设计时, 其架构并未专门为LLM的Decode阶段优化, 导致在推理时效率低下. 作者总结了Decode阶段面临的两大挑战.
2.1 Decode挑战1: 内存
自回归模型的Decode阶段是一个Memory Bound的应用, 而新的软件趋势更是加剧了这一挑战. 与此相反, 硬件的发展趋势却走向了一个完全不同的方向:
- AI处理器面临内存墙问题: 当前的数据中心GPU/TPU依赖于高带宽内存(HBM), 并将多个HBM堆栈连接到单个巨大的加速器ASIC上. 然而, 内存带宽的提升速度比计算浮点性能(FLOPS)要慢得多. 例如, 从2012年到2022年, NVIDIA GPU的64位FLOPS增长了80倍, 但带宽仅增长了17倍. 这个差距将继续扩大.
| HBM | HBM2 | HBM2E | HBM3 | HBM3E | HBM4 |
|---|---|---|---|---|---|
| 推出年份 | 2013 | 2016 | 2019 | 2022 | 2023 |
| 最大引脚带宽 (Gbit/sec) | 1.0 | 2.4 | 3.6 | 6.4 | 9.8 |
| 引脚数 | 1024 | 1024 | 1024 | 1024 | 1024 |
| 堆栈带宽 (GB/s) | 128 | 307 | 461 | 819 | 1254 |
| 最大Die数/堆栈 | 4 | 8 | 12 | 12 | 16 |
| 最大Die容量 (GiB) | 1 | 1 | 2 | 2 | 3 |
| 最大堆栈容量 (GiB) | 4 | 8 | 24 | 24 | 48 |
| NVIDIA GPU | Volta V100 | Ampere A100 | Hopper H100 | Blackwell B100 | Rubin R100 |
| HBM堆栈数/GPU | 4 | 5 | 6 | 8 | 8 |
论文原始的表格有一个Typo, 在Hopper这一代有6颗HBM3e
- HBM成本日益高昂: HBM的制造和封装难度越来越大, 导致其单位容量和单位带宽的价格不降反升. 另一方面虽然原文说DDR的价格在下降, 但是最近DDR5也在疯狂的涨价中.
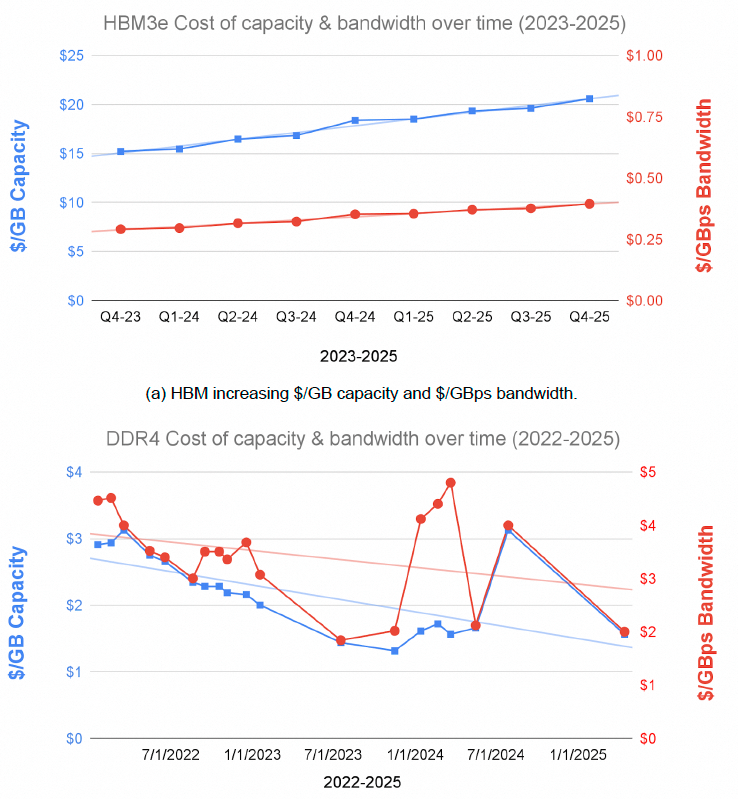
- DRAM密度增长放缓:单个DRAM芯片的容量增长速度也在变慢.
- 纯SRAM方案的局限性: 类似Cerebras和Groq采用片上SRAM的方案, 随着LLM模型参数的爆炸式增长, 其SRAM容量已无法满足需求, 最终仍需依赖外部DRAM.
2.2 Decode挑战2: 端到端延迟
面向用户意味着低延迟. 与需要数周时间的训练不同, 推理与实时请求绑定, 需要在几秒或更短时间内响应. 低延迟对于面向用户的推理至关重要 (批处理或离线推理没有低延迟要求). 根据应用的不同, 延迟的衡量标准是所有输出token的完成时间, 或是首个token的生成时间(TTFT). 两者都面临挑战:
- 完成时间挑战: Decode阶段一次只生成一个token, 因此输出越长, 延迟就越高. 长的输出序列会拉长延迟, 但长的输入序列也会使速度变慢, 因为在Decode和Prefill阶段访问KV Cache需要更多时间. 由于是内存密集型, 每个Decode迭代都有很高的内存访问延迟.
- TTFT挑战: 长的输入序列和RAG增加了生成开始前的工作量, 因此也增加了首个token的生成时间. 推理模型(Reasoning models)同样会增加这个延迟, 因为它们在生成第一个用户可见的token之前, 会先生成许多"想法"token.
LM推理因模型巨大通常需要多芯片系统, 这意味着频繁的跨芯片通信. 与训练不同, Decode阶段的批量大小(batch size)通常很小, 导致网络消息的尺寸也很小. 对于频繁的小消息通信, 网络延迟的影响远大于带宽.下表总结了LLM Decode的硬件瓶颈以及论文提出的研究方向如何应对这些瓶颈.
| LLM Decode 特点与趋势 + 潜在研究机遇 | 内存 容量 | 内存 带宽 | 互联 延迟 | 计算 |
|---|---|---|---|---|
| 硬件改进的驱动因素 | ||||
| 常规Transformer Decode | ✅ | ✅ | ||
| MoE | ✅ | ✅ | ✅ | |
| Reasoning 模型 | ✅ | ✅ | ❓ | |
| 多模态 | ✅ | ✅ | ❓ | |
| 长上下文 | ✅ | ✅ | ❓ | |
| RAG | ✅ | ✅ | ❓ | |
| Diffusion | ✅ | |||
| 潜在研究方向 | ||||
| ① 高带宽闪存 (High Bandwidth Flash) | ✅ | ⬆️ | ||
| ② 近存计算 (Near Memory Compute) | ✅ | ⬆️ | ||
| ③ 3D 计算-逻辑堆叠 (3D Compute-Logic Stacking) | ✅ | ⬆️ | ||
| ④ 低延迟互联 (Low-Latency Interconnect) | ✅ |
注: “✅” 表示主要瓶颈. “⬆️” 表示该方向通过缩小系统规模间接帮助降低了互联延迟.*
- 四大研究机遇
=========
作者提出了四个可以重塑LLM推理硬件的研究方向, 旨在优化新的性能/成本指标, 如TCO(总拥有成本), 功耗和碳排放.
3.1 高带宽闪存 (High Bandwidth Flash, HBF)
采用类似HBM的堆叠技术来堆叠闪存(Flash) die, 从而获得闪存的容量和HBM级的带宽.
优势
- 10倍权重内存: HBF可提供比HBM大一个数量级的容量, 用于存储推理时固定的模型权重, 使单节点能够承载远超当前规模的模型(如巨型MoE).
- 10倍上下文内存: 可用于存储变化缓慢的上下文数据, 如网络语料库, 代码库等.
- 更小的推理系统: 由于单节点内存容量大增, 运行同一个模型所需的节点数减少, 从而降低通信开销, 提高可靠性.
挑战
- 有限的写寿命: 闪存的擦写次数有限, 因此HBF只适用于存储不经常更新的数据.
- 基于页的高延迟读取: 闪存以页(Page)为单位读取(通常几十KB), 延迟远高于DRAM(几十微秒 vs 几十纳秒).
下表是HBF与其他存储设备的粗略比较:
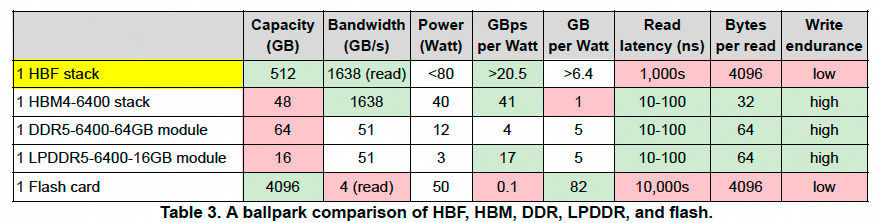
研究方向
- 如何设计软件来适配HBF的特性?
- 系统中HBF与传统内存的比例应该是多少?
- 能否从技术上改进HBF的限制?
3.2 近存计算 (Processing-Near-Memory, PNM)
首先作者严格区分了PIM和PNM:
- PIM (Processing-in-Memory, 存内计算): 计算逻辑和存储单元在同一个die上.
- PNM (Processing-Near-Memory, 近存计算): 计算逻辑和存储单元在不同但邻近的die上.
下表总结了PIM和PNM在数据中心LLM推理场景的对比:
| Processing-in-Memory (PIM) | Processing-Near-Memory (PNM) | 胜出者 | |
|---|---|---|---|
| 数据移动功耗 | 非常低 (片上) | 低 (片外但邻近) | PIM |
| 带宽(每瓦) | 非常高 (标准的5-10倍) | 高 (标准的2-5倍) | PIM |
| 内存-逻辑耦合 | 内存和逻辑在同一个die上 | 内存和逻辑在分离的die上 | PNM |
| 逻辑PPA | 在DRAM工艺下逻辑更慢, 功耗更高 | 逻辑工艺有助于性能, 功耗和面积 | PNM |
| 内存密度 | 更差, 因为与逻辑共享面积 | 不受影响 | PNM |
| 商品化内存定价 | 否. 量小, 供应商少, 密度低 | 是. 不受影响 | PNM |
| 功耗/散热预算 | 逻辑在内存die上预算紧张 | 逻辑受限较小 | PNM |
| 软件分片 | 需要为内存bank (如32–64 MB) 分片 | 分片限制较小 (如16–32 GB) | PNM |
作者结论
针对数据中心LLMPNM优于PIM: 作者认为, 尽管PIM在理论带宽和功耗上更有优势, 但PNM在实际应用中更胜一筹.
- 软件分片(Sharding): PIM要求将数据切分到极小的内存bank(如32-64MB), 这对于LLM复杂的内存结构来说非常困难. PNM的分片粒度可以大得多(如16-32GB), 易于实现.
- 逻辑PPA (性能, 功耗, 面积): PNM的计算逻辑可以使用先进的逻辑工艺制造, PPA更优. 而PIM的计算逻辑受限于DRAM工艺, 性能较差, 功耗较高.
- 内存密度与成本: PNM不影响标准内存的密度和商品化定价.
- 功耗/散热预算: PIM中计算逻辑的功耗和散热受到DRAM die的严格限制.
另外, 作者也指出, 对于移动设备, 由于模型更小, 功耗预算更紧, PIM的劣势不那么突出, 可能是一个可行的方案.
3.3 3D内存-逻辑堆叠 (3D memory-logic stacking)
利用硅通孔(TSV)技术将内存die和逻辑计算die垂直堆叠在一起, 从而获得极宽, 极密集的内存接口, 实现高带宽和低功耗. 这本身就是PNM的一种实现方式.有两种形式:
- 基于HBM Base-die的计算: 在HBM的Base Die中嵌入计算逻辑. 带宽与HBM相同, 但功耗因路径缩短而降低2-3倍.
- 定制化3D方案: 设计全新的3D堆叠接口, 可以实现比HBM更高的带宽和能效.
主要挑战
- 散热 (Thermal): 3D堆叠表面积减小, 散热更困难. 一种解决方案是限制计算逻辑的频率和电压.
- 内存-逻辑耦合: 需要行业标准来定义3D堆叠的接口.
研究方向
- 软件如何适应新的带宽/容量/算力配比?
- 如何在多种内存类型的系统中高效映射LLM?
- 如何与其他3D堆栈或主处理器通信?
3.4 低延迟互联 (Low-Latency interconnect)
针对推理场景中延迟敏感的特点, 重新思考网络设计的延迟-带宽权衡. 具体技术方案:
- 高连通性拓扑: 采用Tree, Dragonfly, Tori等拓扑结构, 减少网络跳数, 降低延迟.
- 网络内处理 (Processing-in-network): 利用交换机硬件加速集合通信操作(如all-reduce, broadcast), 例如NVIDIA SHARP技术.
- AI芯片优化: 将小数据包直接存入片上SRAM而非DRAM; 将计算引擎靠近网络接口.
- 可靠性协同设计: 使用本地备用节点减少故障迁移延迟; 在对通信质量要求不高的场景下, 允许使用过期或伪造数据来避免等待慢节点, 从而降低尾延迟.
- Nvidia的解决方案
==============
4.1 BlueField 4
BF4实际上是Grace CPU和CX9拼接而成的:

总体来看, Nvidia网络团队在体系结构上还是有很大问题的. 整个芯片实际上算上CX9内部的PSA/DSA, 再加上Grace有三套不同的处理器运行, 还包括了一些Spectrum-X的交换机PortLogic, 整个芯片的PPA来看非常差, 只是一个临时拼凑的方案. 然后基于BF4构建了一个KVCache的Storage Server

由于Grace本身的性能还有一些问题, 加上ARM的一些Memory Order导致的部分生态上的问题. 同时他们对分布式存储的理解还有很多问题, 换我宁愿选择用几颗X86配CX9来实现, 还可以扩展更多的CPU内存作为热Cache避免对SSD的频繁的直接写入和降低延迟.
4.2 Nvidia KVCache方案
Nvidia在CES上发布了基于BF4的KVCache方案. 总共分为如下四个层级:
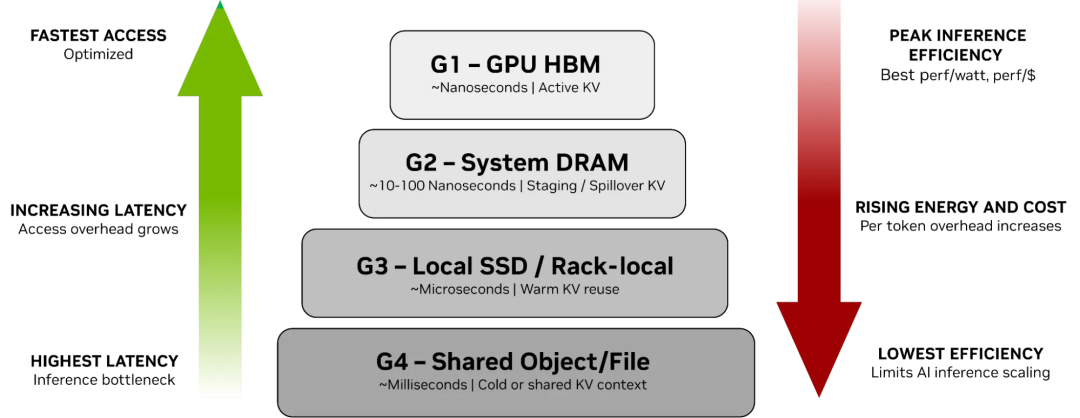
首先在G1这一层,GPU内的HBM直接存储KVCache以及G4通过OSS存储是没问题的. 主要问题出现在G2和G3这两层
- G2的问题: 在G1和G2之间其实有一个强假设, 必须要使用NVLink C2C的Grace-Blackwell和Vera-Rubin的方案. 而针对那些PCIe的卡例如Rubin CPX或者B200/R200这些8卡的平台这一条是不成立的, 因为在CPU和GPU之间的PCIe带宽有明显的Oversubscription, 同时CPU的内存带宽和PCIe RC的性能还是有一定的限制. 并且还要和一些PCIe上的RDMA ScaleOut网络流量有一定的冲突, 而PCIe又没有很好的QoS机制.
- G3的问题: 对于G3这样的Local SSD可能也有一定的问题, 例如一些MaaS平台, T1时间是用来服务 A 模型的, T2时间用来服务 B 模型. KVCache在Local Disk或者Rack Level都会带来很重的数据搬移成本.
对于G2/G3的问题, 实质的解决问题的办法为:
- 在ScaleOut网络或者ScaleUP网络接入池化的分布式存储
- 在RDMA上实现QoS, 即Traffic RateLimit/Shapping的处理方式, 避免KVCache和集合通信的互相干扰.
当然CX9能不能做到, 这是一个未知数, 一方面原来的组网按照多轨道的方式构建的, 那么存储节点的网卡挂在哪个轨道上? 如果不采用多轨道, 而使用FatTree, 如何在一个带有收敛比的网络下做好拥塞控制和避免Hash冲突, 即便是NV宣传的Adaptive Routing也有不少问题, 这是Nvdia CX9网卡的硬伤, 对于第二个问题当前的Nvidia CX9的拥塞控制算法也有不少问题, 就不展开了. 只想说一句我既然能提出这个问题, 其实早就已经在现在CIPU2.0的芯片上解决了这些问题.
- 一些潜在的方案
==========
关于Patterson的论文以及提出的一些问题和四个潜在的研究方向, 接下来做一些解答. 首先我们将谈论3D-Stacking的方案, 然后再对于剩余3种(HBF/PNM和Interconnect)结合在一起分析.
5.1 3D-Stacking
Groq的解决方式是很不错的, 由于确定性的处理, 对于功耗的优化有很多优势, 可以Cycle粒度评估整个系统的功耗和散热
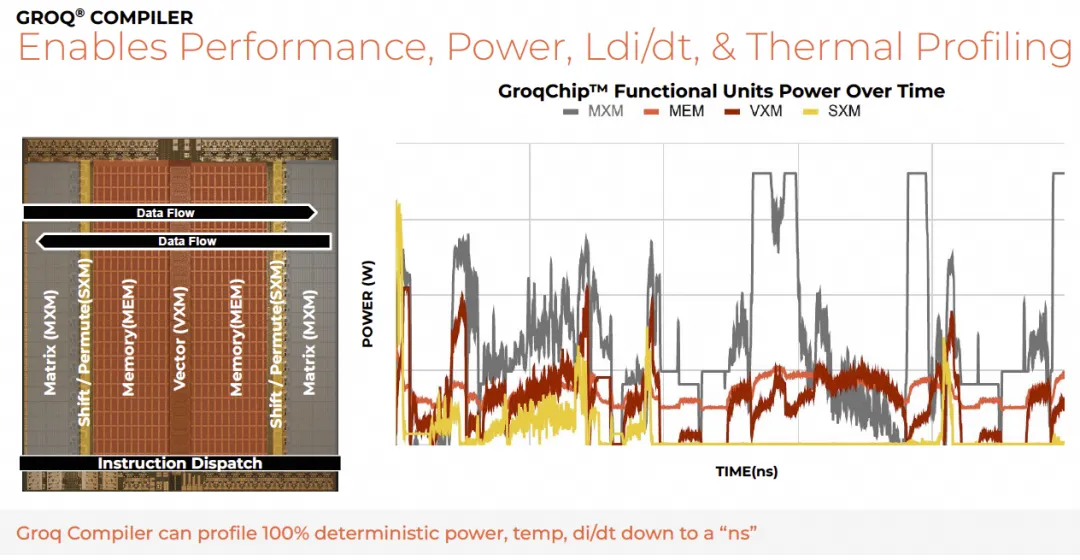
使得Logic-on-Logic的3D Stacking成为可能
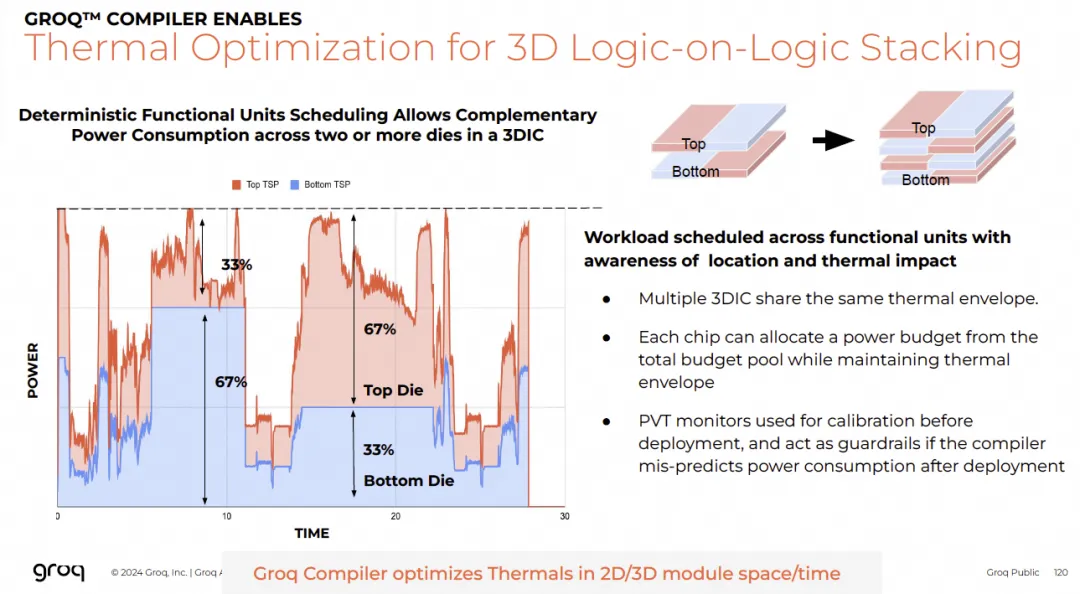
其实功耗控制的问题就可以得以解决了. 对于Feynman如何使用3D-Stacking有一个详细的分析可以参考[《Nvidia如何整合吸收Groq的技术》]. 这种方案也很好的解决了Patterson提出的纯SRAM的Groq方案的不足, 通过整合Feynman GPU Die实现的3D-Stacking有更高的SRAM容量, 对于MoE来说weight加载的代价也会减少, GEMV的执行也会更好的和通信Overlap.
5.2 HBF+PNM+Interconnect
其实这三种路线通过巧妙的结合可以叠加在一起处理.
首先来谈谈HBF, 如果直接挂载在GPU Core上会存在论文提到的HBM和HBF配比的问题

而且KVCache本来就有很繁重的写入压力, 对HBF的持久性还是存在很大的挑战, 同时延迟较大. 从软件的视角来看, 当前最有可能放入HBF的大概也就是一些模型的权重数据.
对于GPU需要扩展内存容量, 可能更多的可以考虑HBM4 Based Die上接入一些LPDDR, 这也是我在前面一章提到的Nvidia G2的一些问题的解答
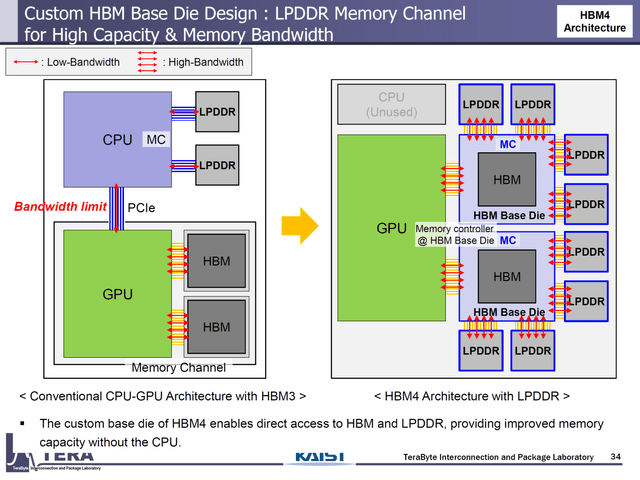
而对于HBF, 我们为什么不将其池化后挂载在ScaleUP总线上呢? HBF自身的延迟已经在数十个微秒的量级, 因此穿越一次ScaleUP总线的代价并不大.
接下来我们讨论一下PNM如何整合进入互连总线. 如果我是Nvidia的架构师, 我会很快做一个Time-to-Market的方案, 在Rubin Ultra的NVLink I/O Die上增加一些SRAM来作为Groq的MEM FU, 并引入Groq SXM FU即可, 整体方案如下:
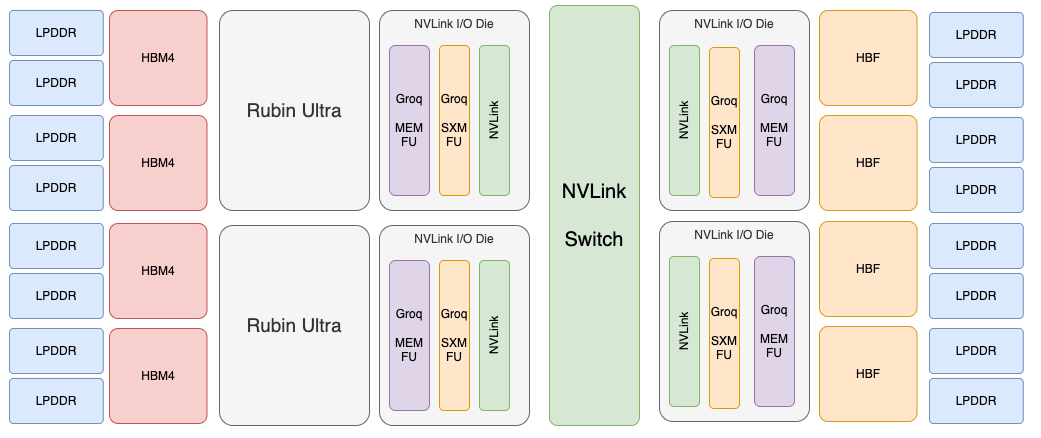
首先对于MoE模型而言, Token Dispatch和Combine所需要的低延迟计算在NVLink SHARP上是无法实现的, 因为大量的token所产生的Dispatch和Combine的组合如果在交换机芯片内处理, 每个Token需要维持 num_topk 个 flow table 进行Combine的运算, 设计上会非常复杂, 同时NVLink Switch又需要很大的带宽和很高的Radix, 并且它也是多颗交换芯片并行连接到多个NVLink上, 如何保证Dispatch和Combine的状态都在同一个NVLink Switch上是困难的.
因此最适合的地方是在NVLink I/O Die上首先增加Groq的MEM FU和SXM FU, GPU产生的Token无需存储到HBM就可以直接通过SMEM写入到Groq MEM FU并触发SXM FU参与Disptach和Combine的运算, 同时还可以进行细粒度的Transpose等操作, 更好的适应Expert FFN中GPU TileBased GEMM的运算.
5.3 NetDAM
对于这种方案, 在5~6年前我还在Cisco构建NetDAM的时候就进行过验证. 整体方案如下, 实质上这算是工业界第一个Ethernet ScaleUP方案了, 详细内容可以参考[《NetDAM: Network Direct Attached Memory with Programmable In-Memory Computing ISA》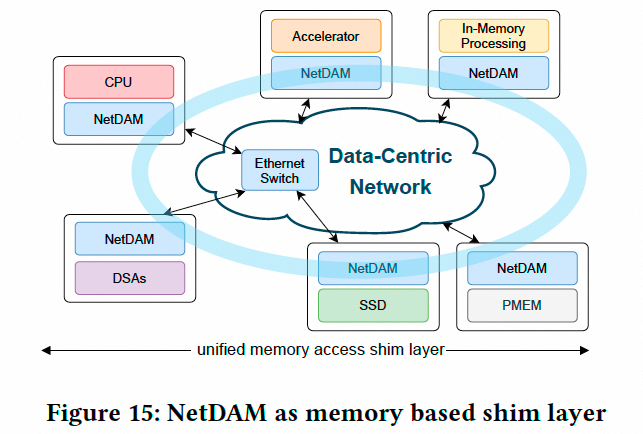
NetDAM即在网络上Direct-Attach-Memory并引入PNM, 它的原型是一颗带有HBM的FPGA, 内部架构如下:
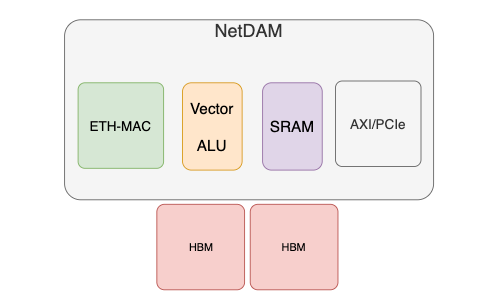
PNM指令通过ScaleUp的协议进行Encoding, 每个数据包头都带有相应的指令, 可以执行Vector based的操作. 对于数据的读写, 由于存在SRAM, 它相对于传统方案具有更好的确定性:
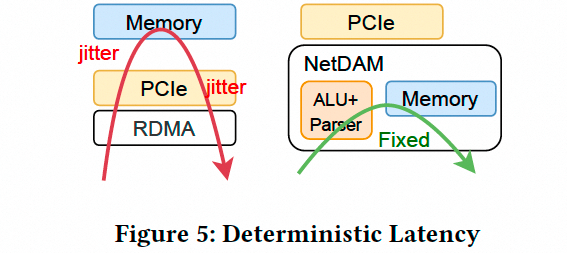
进行Reduce操作时, 它的延迟远小于传统的方案:
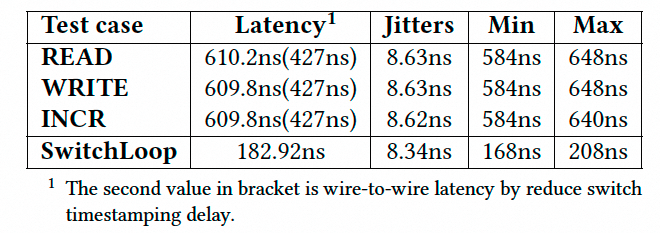
整体处理延迟经过一个交换机为610ns, 直连仅427ns, 抖动仅8ns:
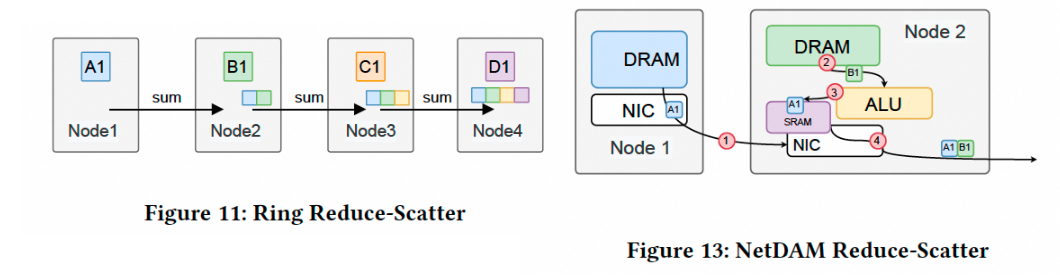
执行集合通信整体的延迟, 经过4跳完成Ring Reduce-Scatter的延迟仅需要3us, 对于大一点的消息延迟上涨是因为6年前还只有100GE的带宽, 现在扩展到1Tbps没什么难度.
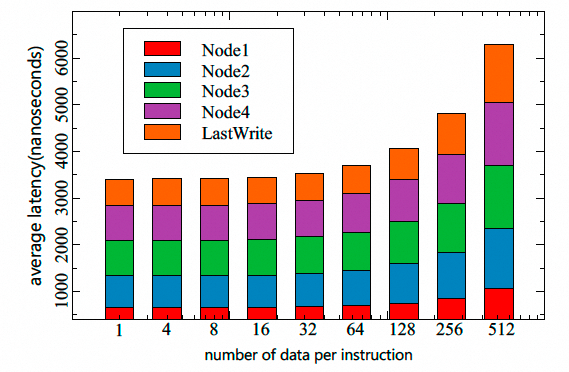
Jitter也可以控制在很小的范围: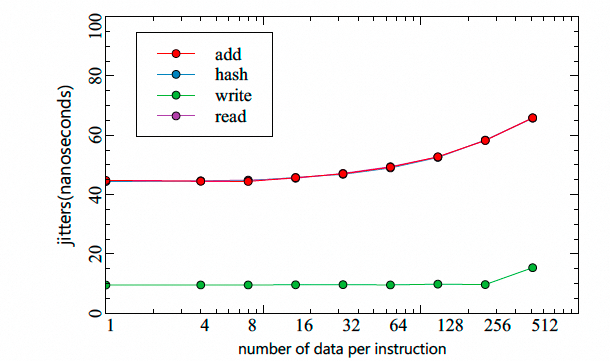
这些6年前的设计都可以很好的匹配现在MoE的通信难题, 但是很遗憾的是工业界在ScaleUP的协议上, 从GenZ/OpenCAPI,到CXL, 再到现在NVLink/UALink/SUE等大量的方案一直没有统一. 并且直到MoE模型大规模推理出现时, 才变成工业界的一个巨大的挑战.
最后
选择AI大模型就是选择未来!最近两年,大家都可以看到AI的发展有多快,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,人才需求急为紧迫!
人工智能时代最缺的是什么?就是能动手解决问题还会动脑创新的技术牛人!智泊AI为了让学员毕业后快速成为抢手的AI人才,直接把课程升级到了V6.0版本。
这个课程就像搭积木一样,既有机器学习、深度学习这些基本功教学,又教大家玩转大模型开发、处理图片语音等多种数据的新潮技能,把AI技术从基础到前沿全部都包圆了!
课堂上不光教理论,还带着学员做了十多个真实项目。学员要亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
课程还教大家怎么和AI搭档一起工作,就像程序员带着智能助手写代码、优化方案,效率直接翻倍!
这么练出来的学员确实吃香,83%的应届生都进了大厂搞研发,平均工资比同行高出四成多。
智泊AI还特别注重培养"人无我有"的能力,比如需求分析、创新设计这些AI暂时替代不了的核心竞争力,让学员在AI时代站稳脚跟。
课程优势一:人才库优秀学员参与真实商业项目实训
课程优势二:与大厂深入合作,共建大模型课程

课程优势三:海外高校学历提升

课程优势四:热门岗位全覆盖,匹配企业岗位需求
如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
·应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
·零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
·业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

智泊AI始终秉持着“让每个人平等享受到优质教育资源”的育人理念,通过动态追踪大模型开发、数据标注伦理等前沿技术趋势,构建起"前沿课程+智能实训+精准就业"的高效培养体系。
重磅消息
人工智能V6.0升级两大班型:AI大模型全栈班、AI大模型算法班,为学生提供更多选择。

由于文章篇幅有限,在这里我就不一一向大家展示了,学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。
【最新最全版】AI大模型全套学习籽料(可无偿送):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!
获取方式:有需要的小伙伴,可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
来智泊AI,高起点就业
培养企业刚需人才
扫码咨询 抢免费试学
⬇⬇⬇

AI大模型学习之路,道阻且长,但只要你坚持下去,就一定会有收获。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 12
12 0
0- 0



 已为社区贡献216条内容
已为社区贡献216条内容

所有评论(0)