数眼智能大模型API实战:从接入到落地的全流程指南
本文介绍了数眼智能API的实战应用指南,包括其核心价值、能力优势及开发流程。主要内容涵盖:1)API定位为数据预处理枢纽,支持网页内容提取、实时搜索等功能;2)详细的环境配置与接入步骤;3)核心接口调用示例,包括网页内容提取和实时搜索;4)进阶实战演示如何搭建实时资讯分析Agent,整合数眼API与大模型;5)常见问题解决方案与性能优化建议;6)扩展应用场景如RAG知识库构建、舆情监控等。该API
一、实战前置:数眼智能 API 核心认知
在动手开发前,需明确数眼智能 API 的核心定位与技术优势,避免开发走弯路:
- 核心价值:作为大模型的「数据预处理枢纽」,解决实时数据获取、中文网页精准解析、合规数据输入三大痛点,为 RAG、智能 Agent 等场景提供 99%+ 准确率的结构化数据;
- 核心能力:支持网页内容提取(过滤冗余)、实时搜索(突破知识时效)、多格式输出(JSON/Markdown)、高并发支撑(QPS 1000+),兼容 Python/Java 等主流语言;
- 实战优势:3 步接入、沙箱环境免费测试、按次计费,个人与企业均能低成本落地。
二、环境准备:3 分钟完成接入前置配置
1. 账号与密钥获取(必做)
- 访问数眼智能开放平台,完成个人 / 企业注册;
- 控制台完成实名认证,创建应用后获取 AppID 与 AppSecret;
- 可选操作:账户充值(免费版提供 500 次调用)。
2. 开发环境搭建(以 Python 为例)
数眼 API 无额外环境依赖,仅需安装基础请求库:
# 安装核心依赖
pip install requests python-dotenv # requests用于接口调用,dotenv管理密钥创建 .env 文件存储密钥(避免硬编码泄露):
SHUYAN_APPID=你的AppID
SHUYAN_APPSECRET=你的AppSecret三、核心接口实战:从基础调用到数据解析
1. 接口调用通用规范
- 基础地址:https://api.shuyanai.com
- 认证方式:请求头携带 Authorization: Bearer {token}(token 通过 AppID+AppSecret 生成)
- 响应格式:统一 JSON 结构,包含 code(状态码)、data(核心数据)、message(状态描述)
2. 实战 1:网页内容提取(最常用场景)
需求:提取某新闻网页的标题、正文、发布时间,过滤广告与评论区冗余内容。
import requests
import os
from dotenv import load_dotenv
# 加载密钥与基础配置
load_dotenv()
APPID = os.getenv("SHUYAN_APPID")
APPSECRET = os.getenv("SHUYAN_APPSECRET")
BASE_URL = "https://api.shuyanai.com/v1/web-reading/extract"
# 生成认证Token(简化版,实际需处理过期逻辑)
TOKEN = f"{APPID}_{APPSECRET}"
def extract_web_content(url):
headers = {
"Authorization": f"Bearer {TOKEN}",
"Content-Type": "application/json"
}
# 请求参数:支持结构化输出、关键词提取、来源过滤
data = {
"url": url,
"need_struct": True, # 开启结构化输出
"extract_keywords": True, # 自动提取关键词
"source_filter": "authoritative" # 仅保留权威来源
}
try:
response = requests.post(BASE_URL, headers=headers, json=data, timeout=5)
response.raise_for_status() # 捕获HTTP错误
result = response.json()
if result["code"] == 200:
return result["data"]
else:
return f"提取失败:{result['message']}"
except Exception as e:
return f"接口调用异常:{str(e)}"
# 测试调用(以某新闻网页为例)
if __name__ == "__main__":
web_url = "https://example.com/news/2025-02-04/xxx.html"
content = extract_web_content(web_url)
print("标题:", content["title"])
print("发布时间:", content["publish_time"])
print("关键词:", content["keywords"])
print("结构化正文(前500字):", content["content"][0][:500])输出示例(自动过滤冗余后的结构化数据):
{
"title": "2025年新能源汽车补贴政策落地",
"publish_time": "2025-02-04 09:30:00",
"author": "工信部官网",
"content": ["为推动新能源汽车产业高质量发展...", "..."],
"keywords": ["新能源汽车", "补贴政策", "2025"],
"credibility": 0.99 # 可信度评分
}3. 实战 2:实时搜索(突破大模型知识时效)
需求:获取近一周内「2025 年 Q1 中国 GDP 增速」的权威数据,用于 AI 分析报告。
def real_time_search(query, date_range="past_week"):
search_url = "https://api.shuyanai.com/v1/search"
headers = {
"Authorization": f"Bearer {TOKEN}",
"Content-Type": "application/json"
}
data = {
"query": query,
"date_range": date_range, # 支持past_hour/past_day/past_month
"output_format": "markdown", # 可选json/markdown
"domain_whitelist": ["gov.cn", "stats.gov.cn"] # 仅爬取政务网站
}
response = requests.post(search_url, headers=headers, json=data)
if response.json()["code"] == 200:
return response.json()["data"]["results"]
else:
return "搜索失败"
# 调用示例
gdp_data = real_time_search("2025年Q1中国GDP增速")
print("实时搜索结果:", gdp_data)核心优势:自动过滤非权威来源,返回带可信度标注的结构化数据,可直接投喂大模型生成分析报告。
四、进阶实战:搭建「实时资讯分析 Agent」
整合数眼 API 与大模型(以 DeepSeek 为例),实现「用户提问→实时联网→分析回答」的闭环。
1. 环境补充依赖
pip install deepseek-sdk # 集成DeepSeek大模型
2. 完整 Agent 代码实现
from deepseek import DeepSeekClient
import requests
import os
from dotenv import load_dotenv
# 加载配置
load_dotenv()
SHUYAN_TOKEN = f"{os.getenv('SHUYAN_APPID')}_{os.getenv('SHUYAN_APPSECRET')}"
DEEPSEEK_API_KEY = os.getenv("DEEPSEEK_API_KEY")
# 1. 封装数眼搜索工具
class ShuyanSearchTool:
BASE_URL = "https://api.shuyanai.com/v1/search"
@staticmethod
def search(query: str) -> str:
headers = {
"Authorization": f"Bearer {SHUYAN_TOKEN}",
"Content-Type": "application/json"
}
data = {
"query": query,
"date_range": "past_month",
"output_format": "json",
"source_filter": "authoritative"
}
try:
response = requests.post(
ShuyanSearchTool.BASE_URL,
headers=headers,
json=data,
timeout=10
)
return str(response.json()["data"]["results"])
except Exception as e:
return f"搜索工具异常:{str(e)}"
# 2. 初始化Agent核心逻辑
class RealTimeAnalysisAgent:
def __init__(self):
# 初始化大模型(决策大脑)
self.llm = DeepSeekClient(api_key=DEEPSEEK_API_KEY)
# 注册工具
self.tools = {"search": ShuyanSearchTool.search}
# 系统提示词(定义Agent行为)
self.system_prompt = """
你是具备实时联网能力的分析Agent,规则如下:
1. 若用户问题涉及2024年后的实时数据、近期事件,必须调用search工具获取数眼智能的权威数据;
2. 用工具返回的结构化数据进行分析,禁止编造信息;
3. 回答需包含数据来源与可信度,格式清晰(可用列表/表格)。
"""
def run(self, user_query: str) -> str:
# 第一步:让大模型判断是否需要调用工具
tool_check_prompt = f"""
用户问题:{user_query}
请判断是否需要调用search工具获取实时数据?仅返回"需要"或"不需要"。
"""
tool_need = self.llm.chat.completions.create(
model="deepseek-chat",
messages=[{"role": "user", "content": tool_check_prompt}]
).choices[0].message.content
# 第二步:执行工具调用或直接回答
if tool_need == "需要":
# 调用数眼搜索工具
search_result = self.tools["search"](user_query)
# 让大模型基于搜索结果生成回答
final_prompt = f"""
系统提示:{self.system_prompt}
实时数据:{search_result}
用户问题:{user_query}
请生成结构化分析回答,包含核心数据、来源与简要解读。
"""
response = self.llm.chat.completions.create(
model="deepseek-chat",
messages=[{"role": "user", "content": final_prompt}]
)
return response.choices[0].message.content
else:
# 无需联网,直接用大模型回答
response = self.llm.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": self.system_prompt},
{"role": "user", "content": user_query}
]
)
return response.choices[0].message.content
# 3. 测试Agent
if __name__ == "__main__":
agent = RealTimeAnalysisAgent()
user_question = "2025年Q1中国新能源汽车销量TOP3品牌及销量数据?"
result = agent.run(user_question)
print("Agent回答:\n", result)3. 实战效果说明
- 核心价值:Agent 可自动判断是否需要联网,数眼 API 提供的结构化数据直接投喂大模型,避免「信息过期」「数据杂乱」问题;
- 典型输出:包含品牌名称、销量数据、来源(如工信部官网)、可信度评分,且自动过滤非权威信息,符合企业合规要求。
五、避坑指南与优化建议
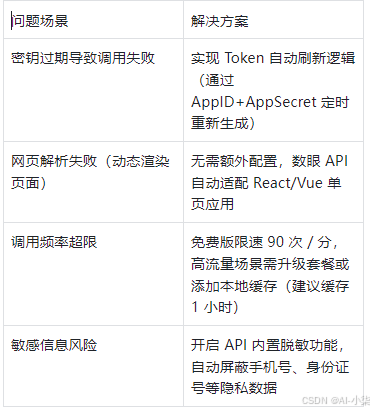
1. 常见问题解决方案
2. 性能优化技巧
- 批量处理:对多个 URL 解析需求,采用异步请求(aiohttp 库)提升效率;
- 缓存策略:对高频访问的固定网页(如政策文件),本地缓存解析结果,减少重复调用;
- 参数优化:无需结构化输出时,设置need_struct=False,响应速度可提升 30%;
- 来源过滤:通过domain_whitelist指定权威域名,减少数据处理量。
六、实战场景扩展
数眼智能 API 的核心落地场景远不止于此,开发者可基于本文思路拓展:
- RAG 知识库构建:批量解析行业文献、产品手册,生成结构化向量数据,提升问答准确率;
- 舆情监控系统:实时抓取指定关键词的新闻 / 社交平台内容,结构化输出舆情趋势;
- 智能办公助手:解析邮件、文档、网页信息,自动整理成会议纪要或任务清单;
- 电商数据分析:提取竞品详情页的价格、参数、评价,生成结构化对比报告。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 42
42 0
0- 0



 已为社区贡献25条内容
已为社区贡献25条内容

所有评论(0)