【大模型 OCR】GLM-OCR 使用教程:从入门到部署
·
概述:
GLM-OCR 是智谱 AI 推出的一款轻量级、高性能的专业 OCR(光学字符识别)模型,参数仅 0.9B,却在多个文档理解基准测试中达到业界领先水平。它支持文本、表格、公式、手写体、多语言等多种复杂场景的识别,并提供灵活的部署方式,适用于从云端快速验证到本地高并发推理、再到边缘设备嵌入式运行的各类需求。
本教程将带你一步步掌握 GLM-OCR 的使用方法,涵盖 云端 API 调用 和 三种主流本地部署方案(Ollama / vLLM / SGLang),帮助你根据实际业务场景选择最适合的方式。
一、准备工作
- 注册账号并获取 API Key(仅云端 API 需要)
访问 智谱 AI 开放平台
登录或注册账号
进入「API Keys」管理页面,创建一个新的 API 密钥
二、方式一:云端 API 部署(最快上手)
适用场景:快速验证效果、小规模调用、无服务器运维能力。
步骤 1:安装 SDK
pip install zai-sdk

步骤 2:编写调用代码
from zai import ZaiClient
# 初始化客户端
client = ZaiClient(api_key="your-api-key-here")
# 支持 URL 或 Base64 编码的图片/PDF
image_url='https://img0.baidu.com/it/u=2804101985,3835295807&fm=253&fmt=auto&app=138&f=JPEG?w=800&h=1119'
# 调用 GLM-OCR 布局解析接口
response = client.layout_parsing.create(
model="glm-ocr",
file=image_url
)
# 打印识别结果(默认为 Markdown 格式)
print(response.md_results)
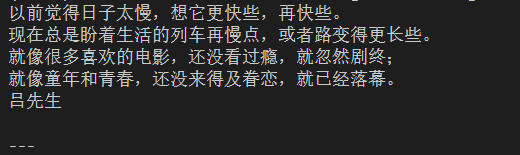
本地图片:
import base64
with open("invoice.jpg", "rb") as f:
b64_data = base64.b64encode(f.read()).decode()
resp = client.layout_parsing.create(
model="glm-ocr",
file=f"data:image/jpeg;base64,{b64_data}"
)
print(response.md_results)
方式二:Ollama 一键部署(本地党福音)
# 直接运行
ollama run glm-ocr
# 识别图片(拖拽图片到终端自动填充路径)
ollama run glm-ocr "Text Recognition: ./image.png"
方式三:vLLM 部署(生产环境推荐)
# 安装 vLLM
pip install -U vllm --extra-index-url https://wheels.vllm.ai/nightly
# 安装 transformers(需要源码版本)
pip install git+https://github.com/huggingface/transformers.git
# 启动服务
vllm serve zai-org/GLM-OCR --allowed-local-media-path / --port 8080
开源与在线体验1.开源地址
Github:https://github.com/zai-org/GLM-OCR
Hugging Face:https://huggingface.co/zai-org/GLM-OCR
2.模型API智谱开放平台:
https://docs.bigmodel.cn/cn/guide/models/vlm/glm-ocr
3.在线体验Z.ai:
https://ocr.z.ai

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 22
22 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)