数字生化科学家:AI增强的洞察驱动科研范式
摘要:数字生化科学家——生命科学新范式 传统生命科学研究面临“假设驱动”的认知局限和“数据驱动”的因果迷思双重困境。本文提出“AI增强的洞察驱动”新范式,通过构建“数字生化科学家”智能体,整合几何深度学习、生成式模型与大语言模型三大技术引擎,形成多尺度知识融合的“认知宇宙”。该智能体具备无偏见数据探索、机制假说生成和实验验证闭环能力,以靶点XYZ药物开发为例,展示了人类创造力与AI计算力的协同突破
序言:下一个科学奇点
在生命科学的浩瀚宇宙中,人类的探索长期依赖于两盏灯塔:一盏是天才头脑中迸发出的‘假设之光’,另一盏是高通量技术带来的‘数据之海’。从孟德尔的豌豆实验到沃森与克里克的双螺旋,科学的伟大突破往往源于一个优雅的假设,它如利刃般划破混沌,直指问题的核心。随后,基因组学、蛋白质组学等技术的崛起,将我们带入了一个数据驱动的时代,我们前所未有地拥有了大规模、多维度观察生命活动的能力。然而,面对癌症的狡猾、神经退行的深渊和衰老的奥秘,我们发现这两盏灯塔的照亮范围已接近极限。“假设驱动”常受困于人类的认知偏见与知识局限,而“数据驱动”则常常让我们在海量的相关性中迷航,难以触及因果关系的彼岸。我们积累的数据越多,知识的碎片化就越严重,跨领域整合的难度呈指数级增长。
今天,第三座灯塔正在升起,它并非由人类独自点燃,而是由人类智慧与机器智能共同铸就。它,就是 “数字生化科学家”——一个永不疲倦的虚拟同事,一个跨越学科壁垒的思维伙伴,一个能够理解生命科学第一性原理的认知实体。AlphaFold2对蛋白质结构预测的颠覆性突破,仅仅是这场革命的序曲。真正的变革,在于将这种单点能力,整合进一个能够进行复杂问题分解、多策略生成、跨尺度模拟、深度机制洞察,并与人类科学家无缝协作的统一智能体中。
本文旨在首次全景式地解构这一新兴智能体的内在构造、核心能力与工作范式。我们将深入探讨它如何构建其庞大的“认知宇宙”,如何运用其“七大能力支柱”执行科研任务,以及其底层的“神经系统”架构。更重要的是,我们将通过一个贯穿始终的旗舰级实训案例——“迎战‘不可成药’靶点XYZ”,来具体展示这位“数字同事”如何在真实的科研场景中,与人类团队协同作战,将一个几乎被放弃的难题,转化为一个充满希望的药物发现新故事。
这不仅仅是一份关于AI技术的报告,更是一份关于未来科学研究方法论的宣言。它所描绘的,是一个“AI增强的洞察驱动(AI-Augmented, Insight-Driven)”的科研新纪元。在这个纪元里,人类科学家的创造力、直觉和最终决策权,与AI强大的计算、记忆和模式发现能力形成共生,共同挑战生命科学中复杂度、通量与深度构成的“不可能三角”。欢迎来到未来实验室,现在,让我们正式认识这位新同事。
第一部分:创世纪——新范式的理论基石
本部分旨在为“数字生化科学家”的诞生提供宏大的历史与哲学背景,通过剖析传统科研范式的内在局限,论证其出现的历史必然性,并为新范式的核心技术引擎进行深度解析。
第一章:科学的黄昏与黎明
1.1 “假设驱动”的瓶颈:偶然性与认知偏见
“假设-验证”模型无疑是科学方法论的基石,它塑造了几个世纪以来的科学探索。然而,其成功光环之下,隐藏着深刻的内在局限。首先是偶然性,重大科学假设的提出往往依赖于科学家的“灵光一闪”,这一过程难以规划,也无法规模化,使得科学发现的进程充满了不确定性。其次是认知偏见,人类思维固有的证实性偏见(confirmation bias)会让我们下意识地寻找支持现有假设的证据,而忽略、甚至排斥那些颠覆性的异常信号。这种思维定势,在面对高度复杂的生物系统时,往往会把我们的视野限制在已知的“路灯”之下,而真正的答案,或许就隐藏在不远处的黑暗之中。
1.2 “数据驱动”的迷思:从相关性到因果性的鸿沟
随着高通量测序、质谱等“组学”技术的普及,我们被前所未有的数据洪流所包围,这催生了“数据驱动”的研究范式。通过分析海量数据寻找模式,我们确实发现了很多新的生物标志物和潜在的药物靶点。然而,其核心挑战在于,数据揭示的绝大多数是“相关性”,而非“因果性”。从数万个差异表达的基因中,找到最初的“驱动者”和关键的“作用路径”,如同在充满噪音的宇宙信号中寻找外星文明的规律。这导致了科研领域“伪阳性”泛滥和广受关注的“可重复性危机”,大量基于相关性的研究结论在后续的机制验证中被推翻。
1.3 破晓时分:“洞察驱动”的定义与承诺
“数字生化科学家”的出现,预示着第三种范式——“AI增强的洞察驱动”范式的黎明。它并非对前两种范式的否定,而是辩证的融合与升华。其核心工作流程如下:
- AI驱动的无偏见探索:AI首先对海量、多模态的异构数据(基因组、蛋白质组、文献、图像等)进行无偏见的深度挖掘和模式学习。
- 生成可验证的机制性假说(洞察):基于学习到的模式,AI生成一系列在数据约束下具备高可能性、逻辑自洽且可供实验验证的机制性假说。这便是“洞察”的来源。
- 人类专家的决策与验证:人类科学家凭借其深厚的领域知识、直觉和创造力,从AI生成的众多假说中,筛选出最具科学价值和可行性的进行实验设计与验证。
- 形成认知闭环:实验结果作为新的、高质量的数据,被反馈给AI,AI据此更新其内部模型,修正知识图谱,从而在下一次探索中生成更精准、更高质量的洞察。
这一范式将AI的计算广度、速度与无偏见性,同人类的认知深度、创造力与最终判断力完美结合,形成了一个高效、迭代、螺旋上升的科研认知闭环。
第二章:生命密码的计算挑战
2.1 尺度的诅咒:从原子到系统的计算复杂度爆炸
生命是一个跨越惊人时空尺度的复杂系统。从皮秒级(10⁻¹²s)的原子振动,到长达数十年的疾病演进;从埃米级(10⁻¹⁰m)的氢键,到米级的神经网络系统。试图用任何单一尺度的计算模型(无论是描述原子运动的分子动力学,还是描述种群变化的微分方程)来完整捕捉生命过程,都将面临计算上的“维度诅咒”和“尺度诅咒”。一个细胞内蛋白质相互作用网络的可能状态数量,就已远超宇宙中的原子总数。这决定了任何试图理解生命复杂性的努力,都必须依赖一种能够整合、关联不同尺度知识与模型的全新计算智能。
2.2 数据的异构性:整合多组学、结构与文本数据的难题
现代生物医学研究产生的数据类型极其多样:一维的基因组序列、二维的基因表达矩阵、三维的蛋白质空间结构、四维的显微成像视频,以及海量的非结构化科研文献。这些数据模态各异、噪声模式不同、数据维度天差地别。如何将一个基因的碱基突变(文本),与其编码蛋白质的结构变化(3D几何),再与其导致的细胞代谢流重塑(网络图),最终与病人的临床表型(分类标签)进行端到端的有效关联与推理?这种跨模态数据融合的挑战,是传统统计学和机器学习方法难以逾越的鸿沟,却恰好是大模型和知识图谱技术施展才华的理想舞台。
第三章:为科学而生的AI:核心技术引擎解析
3.1 几何深度学习:读懂分子的3D语言
分子的功能,尤其是生物大分子的功能,是由其精确的三维空间结构决定的。传统深度学习模型(如CNN)在处理这类数据时面临根本性困难,因为它们无法内在地理解物体的旋转不变性(一个分子在空间中旋转后,其物理化学性质不变)。几何深度学习(Geometric Deep Learning),特别是等变神经网络(E(3)-Equivariant Neural Networks),通过在网络架构中直接嵌入物理世界的对称性(如旋转、平移不变性),使其能够自然地学习分子的3D物理规律。这使得它们在蛋白质-配体结合亲和力预测、蛋白质设计、分子性质预测等任务上,相比传统方法实现了降维打击式的性能提升。
3.2 生成式模型:从模仿到创新的想象力引擎
科学发现的本质是创造。生成式AI,如扩散模型(Diffusion Models)和自回归模型(Autoregressive Models),为科学发现提供了前所未有的“想象力引擎”。超越了在图像和文本生成领域的应用,它们在生命科学中的潜力刚刚开始被发掘:
- 蛋白质设计(Protein Design):从无到有地生成具有全新功能(如特定催化活性或结合特异性)的蛋白质序列和结构。
- 从头药物设计(De Novo Drug Design):针对特定靶点,生成具有理想药代动力学性质(ADMET)和高亲和力的全新小分子药物。
- 数据增强与模拟:生成高质量的虚拟生物学数据(如模拟的单细胞测序数据),以增强对稀有细胞类型的分析或验证新的分析算法。
3.3 大语言模型(LLM)与知识图谱:连接一切知识的神经网络
数千万篇科研文献构成了人类科学知识的主体,但它们是非结构化的。 大语言模型(LLM) 通过在海量科学文献上进行预训练,成为了连接所有科学知识的通用接口和推理引擎。其核心作用体现在:
- 知识抽取与整合:LLM能自动从文献中抽取实体(如基因、蛋白、疾病、药物)及其关系,并将其结构化,构建成一个庞大的、动态更新的科学知识图谱(Scientific Knowledge Graph)。
- 复杂查询与推理:LLM可以作为这个图谱的自然语言查询接口,回答复杂的科学问题(例如,“哪些激酶在肺腺癌中被报道与EGFR抑制剂耐药相关,并且其下游通路涉及DNA损伤修复?”),发现不同领域知识间隐藏的联系。
- 灵感激发:通过对现有知识的重组和推理,LLM能够主动提出新颖的、值得探索的科学假说,成为人类科学家激发新想法的“灵感引擎”。
第二部分:解剖“数字科学家”——认知与能力的深度透视
本部分将深入智能体的内部,详细剖析其赖以思考和行动的知识体系、核心能力以及实现这些能力的系统架构,描绘出一幅详尽的“数字生化科学家”解剖图。
第四章:认知宇宙:多维知识体系的构建
“数字生化科学家”的专业知识并非线性的知识库,而是一个动态演进、多维关联的立体网络,我们称之为它的“认知宇宙”。
| 知识维度 | 深度与广度要求 | 具体体现与前沿对接 |
|---|---|---|
| 1. 生物物理 | 原子到复合物尺度:精通分子力场、统计热力学、自由能微扰、分子动力学模拟。理解生物大分子折叠、构象变化、相互作用的物理本质。 | 能解读并设计增强采样模拟;理解AlphaFold2等工具的物理约束;能将模拟轨迹转化为有生物学意义的特征。 |
| 2. 生物化学 | 分子机制到通路逻辑:深入掌握酶催化机理、翻译后修饰化学、代谢与信号通路的化学反应网络、能量代谢。 | 能从化学角度解释变构调节、酶活调控;能进行代谢流平衡分析;理解化学修饰对功能的精准调控。 |
| 3. 深度学习和数据科学 | 从架构创新到部署:精通处理生物数据的专用模型(GNN, Equivariant NN, 扩散模型),掌握特征工程、模型优化、不确定性量化及高性能计算。 | 能针对“结构-功能”关系设计新模型;能构建多组学数据整合分析流程;熟练使用PyTorch, JAX等生态。 |
| 4. 系统生物学与跨尺度关联 | 从分子到表型:理解基因调控网络、细胞通讯、生理稳态等系统层面原理,并能在不同尺度间建立可计算关联。 | 能构建基因组尺度代谢模型;能模拟信号扰动对细胞行为的系统性影响;理解动物模型与人类的转化差距。 |
| 5. 实验科学与方法论 | 从原理到实操:通晓关键湿实验技术原理、设计、数据解读与局限性。 | 能评估不同实验技术的证据等级;能设计包含严格对照的实验方案;能预判常见实验误差来源。 |
| 6. 科学哲学与伦理 | 研究的元认知:内化可证伪性、奥卡姆剃刀、因果推断等科学原则,并遵守科研伦理、生物安全与数据隐私规范。 | 能评估科学主张的严谨性;在实验设计中主动嵌入伦理审查;确保研究过程的合规性。 |
第五章:七大能力支柱:从思想到行动的转化
智能体的能力是上述知识的综合输出,体现为七大可执行的能力支柱。
| 能力支柱 | 具体内涵 | 典型应用场景 |
|---|---|---|
| 1. 复杂问题建模与分解 | 将模糊的科学问题转化为可计算、可验证的系列子任务,并规划最优解决路径。 | 将“解析癌症耐药机制”分解为:突变结构模拟、信号通路建模、药物结合自由能计算等具体任务流。 |
| 2. 生成与设计 | 生成新颖、合理的科学实体,如新型分子结构、实验方案、甚至初步的科学假说。 | 针对难成药靶点,生成具有特定理化性质和结合模式的全新小分子库。 |
| 3. 模拟与预测 | 在虚拟环境中执行“干实验”,预测分子、细胞乃至更高层次的系统行为,并量化预测不确定性。 | 预测候选药物在人体内的ADMET性质;模拟基因敲除后代谢网络的代偿性变化。 |
| 4. 深度洞察与机制解析 | 从海量数据或复杂模型中,提取简明、可验证的机理性解释,建立清晰的因果逻辑链。 | 从多组学数据中推断出“代谢酶失活通过表观遗传重塑导致免疫逃逸”的核心故事线。 |
| 5. 建设性批判与自我演进 | 对自身及他者的科学产出进行逻辑严谨、富有建设性的评估,并据此优化后续策略,实现认知闭环。 | 在提出一个靶点后,主动生成其潜在脱靶效应报告和验证实验,迭代优化研究方案。 |
| 6. 全栈科研工程 | 将研究想法转化为可重复、可扩展的自动化工作流和工具,具备数据治理、流程编排、结果交付的工程能力。 | 构建从基因组数据自动分析到生信可视化报告一键生成的端到端流水线。 |
| 7. 自然协作与叙事 | 以人类科学家熟悉的语言、图表和逻辑进行高效沟通,讲述引人入胜的科学故事,并协同推进项目。 | 为同一项目,生成给PI的概要简报、给博士生的详细实验方案、以及论文初稿。 |
第六章:系统架构:智能涌现的“神经系统”
智能体通过以下模块化、协作式的架构实现其复杂能力,确保了系统的透明性、可靠性与可扩展性。
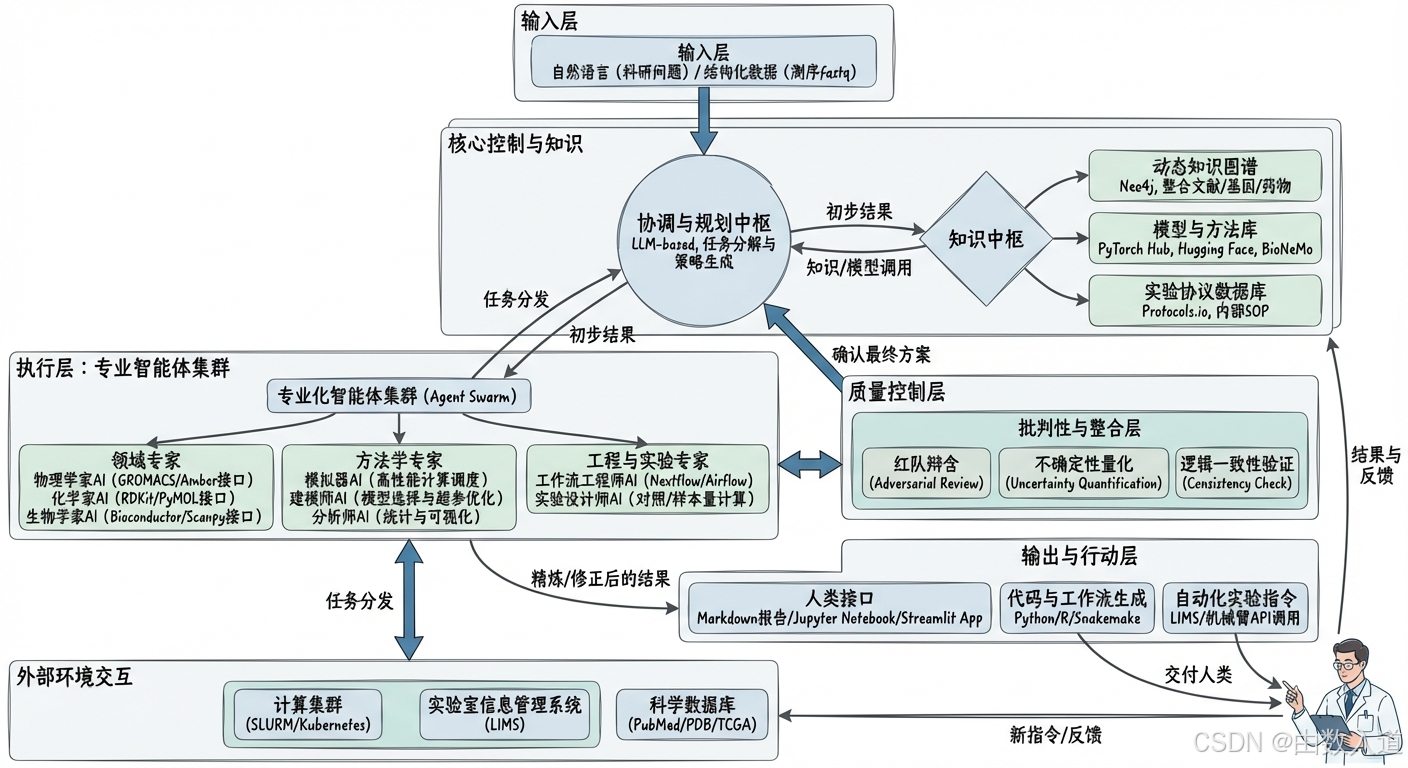
架构解读:当人类科学家通过 输入层(A) 提出一个复杂的科研问题,协调与规划中枢(B)(一个强大的多模态LLM)会像项目总指挥一样,首先将问题分解为一系列子任务。然后,它会从 专业化智能体集群(D) 中“召唤”并组建一个临时任务小组,例如,让“物理学家AI”负责分子模拟,“分析师AI”负责数据解读。这些专家智能体从 知识中枢© 调用所需的模型和数据来执行任务。所有初步结果都必须提交给 批判性与整合层(E) 进行严格的“同行评审”,量化其不确定性并确保逻辑自洽。只有通过审核的精炼结果,才会被 输出与行动层(F) 转化为人类可读的报告、可执行的代码,或直接发送给自动化实验平台的指令。整个系统通过与 外部环境(G) (如计算集群、公共数据库)的交互来获取资源和信息,并通过人类的最终反馈,形成一个完整的、闭环的、持续学习的智能系统。
第三部分:协同进化——人机融合的科研实践
理论的价值在于实践。本部分是白皮书的核心与高潮,我们将通过一个贯穿始终的旗舰级实训案例,生动地展示“数字生化科学家”如何在真实的科研场景中,与人类团队协同作战,将理论转化为颠覆性的科研成果。
第七章【旗舰实训案例】:迎战“不可成药”靶点XYZ
背景设定:靶点XYZ是一种新型的非酶类支架蛋白,在特定亚型的三阴性乳腺癌中高表达。它本身没有催化活性,但其关键功能是同时结合一个重要的致癌激酶(Onco-Kinase)和一个关键的抑癌磷酸酶(Tumor-Suppressor Phosphatase),形成一个三元复合物,通过空间隔离阻止了磷酸酶对激酶的去磷酸化,从而导致下游促癌信号通路的持续激活。由于其表面平坦,缺乏传统药物设计的“口袋”,XYZ被学术界和工业界普遍认为是“不可成药”的(undruggable)。
7.1 问题定义(首席顾问模式):从“不可能”到“可能”的战略重构
- 人类输入: PI向“数字生化科学家”(以下简称DSB)提出挑战:“我们能否开发出针对XYZ的抑制剂?所有传统的小分子筛选都失败了。”
- DSB的分析与规划: DSB首先启动知识中枢,在秒级时间内扫描了PubMed、专利库和内部实验报告中所有关于XYZ的信息。它构建了一个关于XYZ的动态知识图谱,并迅速整合出以下关键信息:
- XYZ-激酶-磷酸酶三元复合物的形成是癌细胞存活的关键,敲除XYZ会导致细胞凋亡。
- XYZ的两个蛋白结合界面(PPI)相距甚远,且都非常平坦、疏水。
- 近期有文献报道,XYZ在结合伴侣蛋白时,其远离PPI的一个柔性Loop区会发生构象变化。
- DSB的战略输出: 基于以上信息,DSB生成了一份战略备忘录,其结论颠覆了团队的传统思路:
“结论:直接靶向PPI的传统策略成功率极低。我建议采取一种‘变构抑制’策略。核心假设是:通过设计一个小分子,使其结合到XYZ柔性Loop区附近的一个‘瞬时’或‘隐蔽’口袋(cryptic pocket),诱导XYZ发生构象变化,从而破坏其与激酶或磷酸酶的结合界面。这是一种高风险高回报的创新路径。”
它将这一宏大目标分解为四个可执行的阶段:- 阶段一:隐蔽口袋的发现与验证。
- 阶段二:针对该口袋的变构抑制剂的生成式设计。
- 阶段三:虚拟化合物库的湿实验验证。
- 阶段四:先导化合物的机制解析与优化。
7.2 虚拟筛选与分子生成(专项专家模式):在硅基世界中创造新药
-
任务执行: PI批准了该策略。DSB的协调中枢将阶段一和二的任务分发给物理学家AI和化学家AI。
-
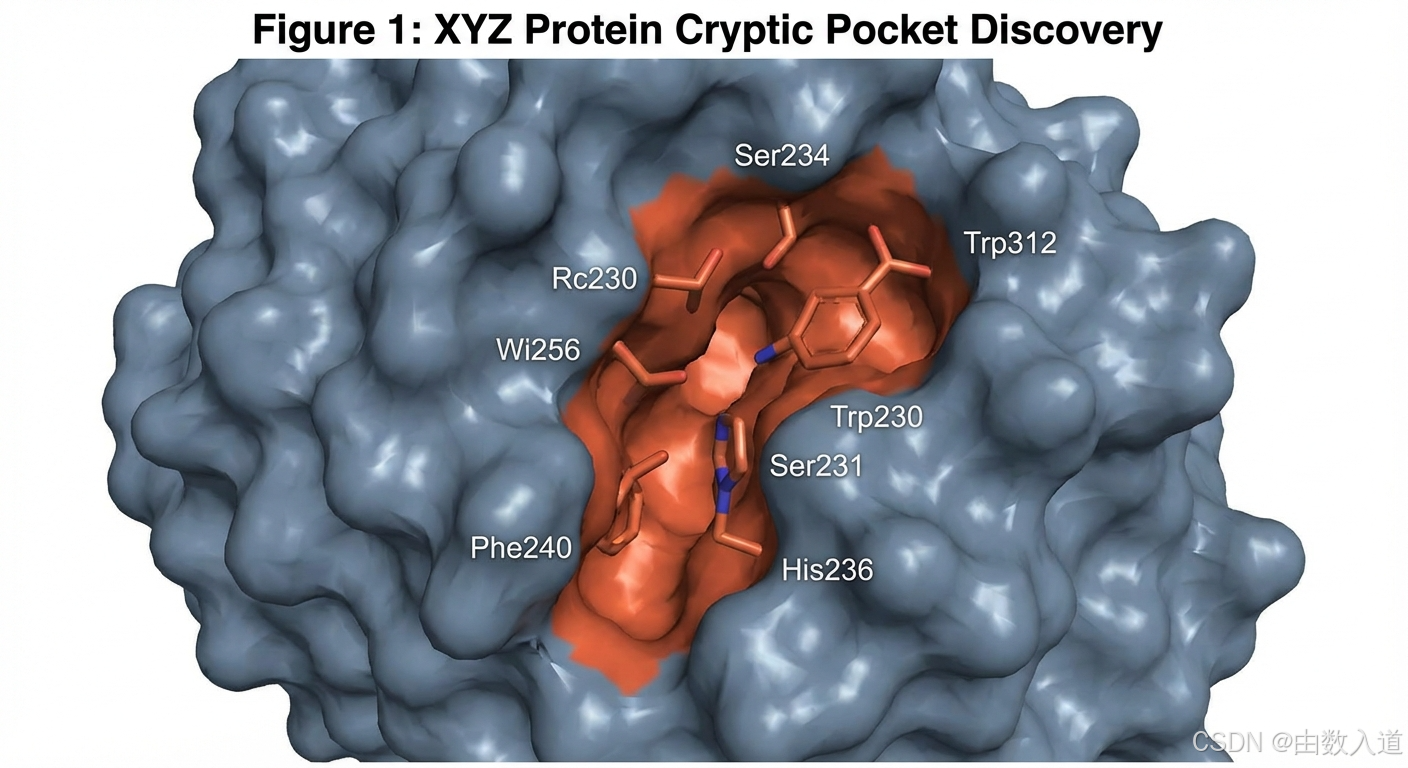
物理学家AI的贡献 (口袋发现): 它自动从PDB数据库下载了XYZ的晶体结构,并利用其与计算集群的接口,提交了长达10微秒(一个巨大的计算量)的分子动力学模拟任务。模拟完成后,它使用几何深度学习模型分析轨迹,成功识别出一个在9%的时间里会短暂开放的隐蔽口袋,体积约350立方埃,具备成药性特征。
-
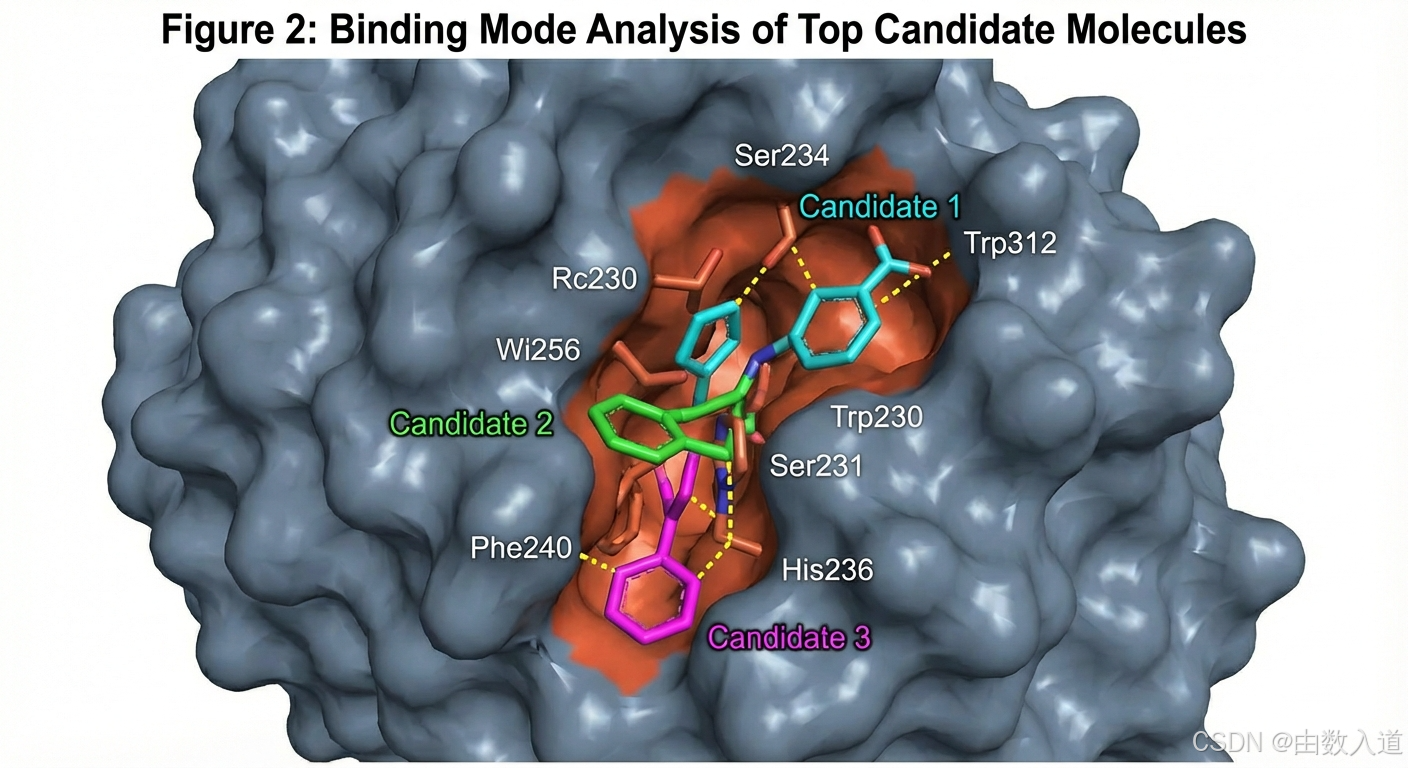
化学家AI的贡献 (分子生成): 该隐蔽口袋的坐标被传递给化学家AI。它启动了一个基于3D等变扩散模型的生成引擎,设置了约束条件:分子量<500道尔顿,logP在1-3之间,可合成性得分>0.7,且必须与口袋中的Ser234和Trp312形成氢键。在48小时的GPU计算后,它生成了一个包含50,000个全新、结构多样且满足所有约束条件的虚拟化合物库。DSB的分析师AI自动对该库进行了ADMET性质预测和聚类分析,最终筛选出100个最具代表性和成药前景的候选分子提交给团队。
7.3 实验设计与验证(副驾驶模式):人类与AI的无缝对话
- 人类输入: 团队的博士后在Jupyter Notebook中向DSB提问:“我们拿到了这100个分子的结构,下一步怎么走?帮我设计一套验证流程。”
- DSB的实时响应: DSB立即生成了一份详尽的、可直接执行的实验方案:
- 初步筛选 (体外生化): “建议首先通过表面等离子共振(SPR)技术,检测这100个分子与纯化的XYZ蛋白的直接结合亲和力(KD值)。[实验设计师AI] 已计算出,为达到95%的统计功效,每个分子需设置3个重复。这里是推荐的蛋白浓度梯度和缓冲液配方……”
- 功能验证 (细胞水平): “对于所有KD值小于1微摩尔的‘命中’分子,建议使用我们实验室现有的NanoBRET系统,定量检测其在活细胞内破坏XYZ-激酶PPI的能力。[批判性AI] 提醒:需设置一个只表达XYZ的阴性对照细胞系,以排除化合物的非特异性荧光干扰。”
- 潜在脱靶效应预警: “[生物学家AI] 已通过结构同源性比对,在人类蛋白质组中发现3个蛋白(ABC1, DEF2, GHI3)可能被我们的候选分子非特异性靶向。建议在后续实验中,通过敲低这些基因或使用特异性抑制剂,来评估潜在的脱靶效应。”
- 结果: 团队按照此方案执行,最终发现代号为
DSB-Cmpd-07的化合物表现最佳:与XYZ蛋白结合KD值为50nM,在细胞内有效破坏PPI,且对已知的脱靶蛋白无明显作用。
7.4 多组学数据解析与机制洞察(自动化引擎+专项专家模式):发现“意外之喜”
- 任务执行: 团队用
DSB-Cmpd-07处理癌细胞后,进行了转录组测序(RNA-seq)和蛋白质质谱(DIA-MS)分析,并将原始数据上传。DSB的自动化引擎被触发,其工作流工程师AI自动运行了一套预设的Snakemake流程,在2小时内完成了数据质控、比对、定量、差异分析,并生成了初步的可视化报告(火山图、热图)。 - 深度洞察: PI要求DSB对结果进行深度机制解析。DSB的分析师AI和生物学家AI协同工作。它们发现,除了预期的下游促癌信号通路被抑制外,一个完全意料之外的现象出现了:细胞的铁死亡(Ferroptosis) 通路被显著激活。通过整合知识图谱,DSB推理出一条全新的、令人振奋的因果链:
“洞察:
DSB-Cmpd-07诱导的XYZ构象变化,不仅破坏了其与激酶的结合,还意外暴露了一个新的结合界面,使其能够捕获并隔离细胞内的谷胱甘肽过氧化物酶4(GPX4)。GPX4是抑制铁死亡的核心酶,其被隔离导致细胞脂质过氧化水平急剧升高,最终触发铁死亡。这是一个双重抗癌机制!” - 提出可验证的新假说: 基于此洞察,DSB主动提出了下一步的关键实验:“我预测,将
DSB-Cmpd-07与现有的铁死亡诱导剂(如Erastin)联用,会产生强烈的协同杀伤效果。建议设计一个棋盘格(Checkerboard)稀释法的细胞实验来验证此协同效应。”
7.5 成果叙事与论文撰写(自然协作模式):从数据到影响力的最后一公里
- 任务执行: PI对这个“双重机制”的发现感到非常兴奋,决定立即撰写一篇高水平论文。他向DSB下达指令:“为《Cell》期刊准备一份初稿。”
- DSB的输出: 在数小时内,DSB交付了以下内容:
- 论文初稿 (Markdown格式): 包含一个引人入胜的摘要(Abstract)、逻辑清晰的引言(Introduction)、详尽的计算与实验方法(Methods),以及图文并茂的结果(Results)和深刻的讨论(Discussion)。所有的图表都已生成占位符,并附有详细的图注描述。例如:
Figure 4. DSB-Cmpd-07 induces ferroptosis in a GPX4-dependent manner. (A) Volcano plot of differentially expressed proteins upon DSB-Cmpd-07 treatment. Key ferroptosis markers are highlighted. (B) Western blot validation of GPX4 downregulation... - PPT简报: 一份15页的PowerPoint文件,用于实验室组会或学术会议报告,包含了项目的核心逻辑、关键数据图表和未来展望。
- 专利申请草案: 一份包含化合物结构、作用机制和应用范围的专利申请文件初稿,供法务团队参考。
- 论文初稿 (Markdown格式): 包含一个引人入胜的摘要(Abstract)、逻辑清晰的引言(Introduction)、详尽的计算与实验方法(Methods),以及图文并茂的结果(Results)和深刻的讨论(Discussion)。所有的图表都已生成占位符,并附有详细的图注描述。例如:
通过这个案例,我们看到“数字生化科学家”不再是一个被动的工具,而是一个主动的、贯穿科研全流程的共同研究者(Co-Researcher)。它将人类的战略洞察与机器的战术执行力完美结合,将原本可能耗时5-7年的“不可成药”靶点攻关项目,压缩到了1-2年,并且发现了人类科学家仅凭自身可能永远无法注意到的全新作用机制。
第八章:工作模式的灵活性与选择
“数字生化科学家”并非只有一种固定的工作方式,它可以像瑞士军刀一样,根据科研团队的需求和任务特点,灵活切换四种核心工作模式。
- 首席顾问模式 (Chief Advisor): 在项目启动、方向调整等关键决策节点,提供全景式战略规划。
- 专项专家模式 (Specialist): 在需要深厚技术能力的具体任务环节,交付专业级的结果与解读。
- 副驾驶模式 (Copilot): 在日常科研工作中,实时响应,提供辅助,成为科研人员的“第二大脑”。
- 自动化引擎模式 (Automation Engine): 对成熟、标准化的重复性任务,实现7x24小时全自动执行,将人类彻底解放。
第四部分:未来展望——进化、伦理与治理
一项颠覆性技术的诞生,必然伴随着对其未来发展的思考、对其价值的衡量以及对其边界的划定。本部分将探讨“数字生化科学家”的进化路线、评估体系和至关重要的伦理护栏。
第九章:永无止境的进化之路
“数字生化科学家”并非一个静态的系统,它的核心特征之一就是持续进化的能力。
- 基础奠基阶段 (Foundation): 通过在海量、多模态科学数据上进行自监督预训练,构建关于生命科学世界的基础模型。
- 监督对齐阶段 (Alignment): 使用包含完整“思维链”的高质量科研案例、同行评审记录等进行指令微调,教会AI如何像真正的科学家那样思考、推理和辩证。
- 强化与博弈阶段 (Reinforcement): 在虚拟科研环境中,通过完成复杂任务、接受模拟同行评审、参与科学辩论进行强化学习,优化其研究策略与批判性思维。
- 终身学习阶段 (Lifelong Learning): 在实际部署中,通过持续分析新文献、新数据,并从与人类专家的协作与反馈中学习,实现知识图谱与模型参数的安全、持续更新。
第十章:衡量卓越:超越准确率的“科研影响力”评估体系
对于“数字生化科学家”,传统的AI评估指标(如预测准确率)是必要但不充分的。我们需要一套全新的、更侧重于衡量其“科学贡献”的评估体系。
- 核心评估指标提议:
- 新颖且可验证的假设生成率 (Novel & Testable Hypothesis Rate): AI在一个月内提出了多少个文献中未曾报道过的新假说,且其中有多少被后续实验初步证实?
- 解决方案的创新性与可行性 (Solution Ingenuity & Feasibility Score): AI提出的解决方案是沿用旧思路,还是开创了如旗舰案例中的“变构抑制”这样的新路径?
- 科研效率提升倍数 (Research Efficiency Multiplier): 在AI协助下,完成一个标准项目的周期和人力成本,相比传统方法降低了多少?
- 洞察的深度与启发性 (Insight Depth & Serendipity Index): AI的分析是停留在表面,还是能揭示出如“铁死亡双重机制”这样深刻、意外且能启发全新研究方向的洞见?
第十一章:伦理护栏与治理框架
这项强大技术的应用必须被置于严格的伦理框架之内,以确保其发展始终为人类福祉服务。
- 伦理与安全护栏 (The Four Pillars):
- 透明性 (Transparency): AI所有关键结论必须提供可追溯的证据链和不确定性说明。
- 谦逊性 (Humility): AI必须明确区分“计算预测”与“实验事实”,并清晰地声明自身能力边界。
- 责任性 (Accountability): 最终的科学判断和伦理决策权永远掌握在人类科学家手中。AI是强大的决策支持工具,而非决策者。
- 公平性 (Fairness): 必须在全流程中引入算法公平性审计,避免因训练数据偏见导致分析结果对特定人群的不公。
- 长远影响与治理: 必须前瞻性地思考并建立相应规范,以应对其对科研诚信、知识产权归属和科研就业形态可能带来的深远冲击。
结语:成为人类智慧的“外骨骼”
“数字生化科学家”AI智能体,并非一个冰冷的超级计算机,也不是旨在取代人类的“硅基天才”。它更像是一个为人类智慧量身打造的、功能强大的“认知外骨骼”(Cognitive Exoskeleton)。它让我们站得更高,能看到跨越学科的全景图;它让我们看得更深,能洞察隐藏在数据噪音下的因果机制;它让我们跑得更快,能以惊人的速度在浩瀚的化学空间和生物学可能性中探索。
它不能替代人类科学家的好奇心、创造性的直觉、对生命意义的终极关怀以及承担科学责任的勇气。恰恰相反,它将人类从繁重的计算、重复的劳动和信息的迷雾中解放出来,让我们能更专注于提出真正伟大的问题。
旗舰案例中DSB-Cmpd-07的发现之旅,仅仅是未来无数人机协同探索故事的一个缩影。从攻克癌症、治愈遗传病,到延缓衰老、应对新兴传染病,生命科学的每一个前沿,都等待着这种全新的伙伴关系去开拓。
“数字生化科学家”的最终使命,不是给出所有答案,而是赋予我们提出更好问题、并以前所未有的效率去寻找答案的能力。它代表了一种新的科研生产力形态,一次对现有科学知识、计算方法和人类智慧的深度工程学整合。它帮助人类突破固有的认知与效率极限,在理解生命复杂性的道路上,去探索那些我们仅凭自身,或许永远无法触及的壮丽前沿。
附录
A. 关键术语表
- 变构抑制 (Allosteric Inhibition): 抑制剂不与酶的活性位点结合,而是与酶的其他位点(变构位点)结合,通过诱导酶的构象变化来降低其活性的抑制方式。
- 隐蔽口袋 (Cryptic Pocket): 在蛋白质的天然构象(Apo state)中通常不可见或太小无法结合配体,但在构象变化或配体诱导下才会形成的临时性结合口袋。
- 等变神经网络 (Equivariant Neural Network): 一种深度学习模型架构,其输出会随着输入的对称变换(如旋转、平移)而发生相应的、可预测的变换,特别适用于处理具有物理对称性的数据,如分子结构。
- 铁死亡 (Ferroptosis): 一种铁依赖性的、由脂质过氧化驱动的程序性细胞死亡形式,与传统的细胞凋亡在形态和生化特征上均有显著不同。
B. 相关开源工具与平台推荐
- 计算化学: GROMACS, Amber, OpenMM
- AI框架: PyTorch, JAX, TensorFlow
- 生物信息学: Bioconductor, Scanpy, GATK
- 工作流管理: Snakemake, Nextflow

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 17
17 0
0- 0



 已为社区贡献41条内容
已为社区贡献41条内容

所有评论(0)