基础学习(13): 变分自编码器 VAE 的 loss
随着大模型以及大head 的广泛使用, 很多特征需要压缩到 latent space, 然后在通过解码器解码到自己需要的维度.本文就vae 和 rae 进行学习论文链接: https://arxiv.org/pdf/2510.11690提示:以下是本篇文章正文内容,下面案例可供参考本文就是对VAE 用的 loss 原理进行了剖析:1 MSE 的原理和局限2 其他的 loss3 为什么要用 LPIP
文章目录
前言
随着大模型以及大head 的广泛使用, 很多特征需要压缩到 latent space, 然后在通过解码器解码到自己需要的维度.
本文就vae 和 rae 进行学习
rae: DIFFUSION TRANSFORMERS WITH REPRESENTATION AUTOENCODERS
论文链接: https://arxiv.org/pdf/2510.11690
提示:以下是本篇文章正文内容,下面案例可供参考
1 vae 基础知识复习
在开始说vae 之前我们还是提下想滚概念:
1.1 KL散度(KL Divergence)
对于同一支持集上的两个分布P, Q:
KL散度: D K L ( P ∣ ∣ Q ) = − ∑ i = 1 N P ( x i ) l o g P ( x i ) Q ( x i ) D_{KL}(P||Q) = - \sum_{i=1}^{N} { P(x_i) log \frac {P(x_i) }{Q(x_i)} } DKL(P∣∣Q)=−∑i=1NP(xi)logQ(xi)P(xi)
我们将求和变形:
D K L ( p ∣ ∣ q ) = − ∑ i = 1 N P ( x i ) ( l o g P ( x i ) − l o g Q ( x i ) ) D_{KL}(p||q) = - \sum_{i=1}^{N} { P(x_i) ( log{P(x_i)} - log{Q(x_i)} )} DKL(p∣∣q)=−∑i=1NP(xi)(logP(xi)−logQ(xi))
也就是:把随机变量X p(x) 分布采样,然后对随机量 l o g p ( X ) − l o g q ( X ) logp(X)−logq(X) logp(X)−logq(X) 取期望。
所以即:
E x p [ l o g p ( x ) − l o g q ( x ) ] = x ∑ p ( x ) ( l o g p ( x ) − l o g q ( x ) ) E_{x~p} [logp(x)−logq(x)]=x∑p(x)(logp(x)−logq(x)) Ex p[logp(x)−logq(x)]=x∑p(x)(logp(x)−logq(x))
1.2 MSE
L M S E = ∥ x − x ^ ∥ 2 2 = ∑ i ( x i − x i ^ ) 2 L_{MSE}=∥x−\hat x∥^2_2 =∑_i { (x_i−\hat{x_i})^2 } LMSE=∥x−x^∥22=∑i(xi−xi^)2MSE 描述的是像素满足独立同方差高斯 那么什么是独立同方差高斯
(1) 高斯:随机变量符合正态分布: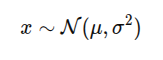
(2) 独立: 各个唯独之间不相关, 也就是协方差阵是对角的: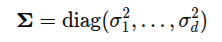
(3) 同方差:,即每一维的方差都一样: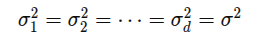
所以其实 对自然图像来说,这个假设不太合理,但它在很多 VAE/AE 里仍被用作一个方便的训练近似(因为它直接对应像素 MSE,简单稳定)。
首先:像素不是独立的,是空间有关联的,
第二:噪声也不是同方差,有高频和低频
第三:像素分布也不是高斯
这些不匹配会导致一个经典现象:MSE 重建容易“糊”——因为在 L2 意义下多种可能的细节会被“平均掉”。
那么问题来了,为什么很多都会用MSE?
因为它带来几个非常实用的好处:(1) 训练简单稳定:MSE 梯度干净,数值稳定,调参成本低。
(2) 有概率学解释:把 MSE 当作高斯 NLL 的一种形式,推导 ELBO 方便。
(3) 多数是“辅助”:在 latent diffusion/flow 的体系里,AE/VAE 的目标往往更偏向“给主干提供好用的 latent”,并不追求严格的像素生成似然。
所以它更像是:“可优化的工程近似”,不是对真实图像的严格统计建模。
1.3 NLL(Negative Log-Likelihood 负对数似然 )
1) 似然(Likelihood)是什么
你有一个概率模型 𝑝𝜃(𝑥)参数是 𝜃,观测到数据 𝑥。
模型给这个数据的概率越大,说明模型“越相信/越能解释”这个数据。
2) 为什么取 log直接用概率会非常小(很多项相乘会下溢),所以常取对数: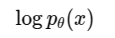
而且 log 把乘法变加法,优化更方便。
3) 为什么加负号(Negative)
最大化 l o g 𝑝 𝜃 ( 𝑥 ) log𝑝_𝜃(𝑥) logp𝜃(x)等价于最小化它的相反数: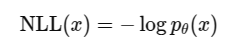
那么问题又来了,NLL 怎么用,在我感觉就像个loss
可以这么说: loss = NLL(data | model params) + regularization
监督学习里 regularization 可能是 weight decay;VAE 里则是 KL最小化 NLL 可以(拟合数据)weight decay(限制模型复杂度,减过拟合)
我们通常的监督学习里常见: m i n θ ( N N L ( θ ) + λ ∣ ∣ θ ∣ ∣ 2 2 ) min_\theta(NNL(\theta) + \lambda || \theta ||^2_2) minθ(NNL(θ)+λ∣∣θ∣∣22)
NLL:比如交叉熵(分类)、BCE、多项式 NLL 等
λ ∣ ∣ θ ∣ ∣ 2 2 \lambda || \theta ||^2_2 λ∣∣θ∣∣22 惩罚参数过大,让模型更“平滑”、减少过拟合
这里再说下weight decay
举个SGD:
L ( θ ) = L d a t a ( θ ) + λ ∣ ∣ θ ∣ ∣ 2 L(\theta)=L_{data} (\theta) + \lambda|| \theta ||^2 L(θ)=Ldata(θ)+λ∣∣θ∣∣2
梯度:
δ θ L = δ θ L d a t a + 2 λ θ \delta_{\theta}L= \delta_{\theta}L_{data} + 2\lambda\theta δθL=δθLdata+2λθ
一步 SGD:
θ ← θ − η ( λ L d a t a + 2 λ θ ) = ( 1 − 2 η λ ) θ − η λ L d a t a \theta←\theta - \eta(\lambda L_{data} + 2\lambda \theta) = (1-2\eta\lambda)\theta - \eta\lambda L_{data} θ←θ−η(λLdata+2λθ)=(1−2ηλ)θ−ηλLdata
你看到参数每一步都会被乘上一个 <1 的系数 (1−2ηλ),也就是权重在“衰减”,所以叫 weight decay。
1.4 discretized logistic (离散化logistic 似然)
自然图像像素通常是 8-bit 离散值(0…255)。如果你用高斯(MSE)或伯努利(BCE)去建模,和“离散像素”不匹配。
Discretized logistic 的想法是:
先用一个连续分布(logistic)来描述像素强度的概率密度
但观测是离散值,所以要计算“这个离散bin对应区间的概率质量(probability mass)”
它的 CDF(累积分布函数)很简单: F ( t ; μ , s ) = δ ( t − μ s ) F(t;\mu, s) = \delta(\frac{t-\mu}{s}) F(t;μ,s)=δ(st−μ)很少用, 被 lopips + gan 给替代了, 因此剩下的就不细推
1.5 LPIPS(Learned Perceptual Image Patch Similarity)
learned 是学的每个项的权重
Perceptual Image Patch Similarity 就是固定权重的perceptual loss 比如 VGG16
重点来了:像素级损失(MSE/L1/BCE)不符合人眼感受:(1)图像整体结构对了,但像素对不齐 → MSE 仍很大(2)纹理/边缘稍微偏移 → MSE 惩罚很重,导致模型倾向“保守平均”,看起来糊所以LPIPS 的核心是:用深网络特征空间衡量相似度,更接近人类感知。
1.6 gan loss
GAN loss(对抗损失)在 AE/VAE 里出现时,通常目的不是“做一个纯 GAN”,而是:让重建/生成更锐、更像真实照片的纹理统计,
生成器 𝐺:在 AE/VAE 里就是 decoder(输入 z,输出 x ^ \hat x x^)。
判别器 𝐷:看一张图,输出“像不像真实”。
训练是博弈:
𝐷学会把真实图 𝑥判为真,把生成图 x ^ \hat x x^判为假
G 学会骗过 D,让 x ^ \hat x x^看起来像真实
那么z 是啥?----某个输入
真实图像 𝑥:来自你的训练数据集的一张真图,xp ~ data。也就是“GT 图像”(ground truth),是数据集给你的。
生成图像 𝐺(𝑧):生成器用某个输入 z 生成出来的假图。
判别器 D(⋅):输入一张图,输出“像真的”的分数/概率。
那么某个输入从哪里来?
A) 纯 GAN(无条件生成)
生成器的输入不是图像,而是 随机噪声 z。
判别器的输入是图像(真实或生成)。
这时就不存在“输入图像给生成器”的说法。
B) AE/VAE + GAN(我们博文里面讨论的)
输入图像就是 要重建的那张真图 x,送进 encoder 得到 latent。
decoder 输出重建 x ˆ \^x xˆ。
GAN 判别器拿 x(真)和 x ˆ \^x xˆ(假)来做对抗。
这时你会同时看到:
𝑥:既是 encoder 的输入,也是 判别器的真样本.
x ˆ \^x xˆ:decoder 的输出,也是判别器的假样本.
所以我们经常遇到的“训练阶段的 gt 图像”——在 AE/VAE 训练里是对的:每个 step 都抽一批 x 作为 GT。
1.6.1 一种经典的GAN loss:
判别器最大化:
E x − p d a t a [ l o g ( D ( x ) ) ] + E z l o g ( 1 − D ( G ( z ) ) ) E_{x-p_{data}}[log(D(x) )] + E_z{log( 1- D(G(z)) )} Ex−pdata[log(D(x))]+Ezlog(1−D(G(z)))
生成器最小化(常用“非饱和”版本): L G = − E z [ l o g D ( G ( z ) ) ] L_G = -E_z[log D(G(z))] LG=−Ez[logD(G(z))]
所以G 让 D ( x ˆ ) 越接近 1 越好 D(\^x) 越接近1越好 D(xˆ)越接近1越好
1.6.2 Hinge loss(很常见,稳定)
判别器:
L D = E [ m a x ( 0 , 1 − D ( x ) ) ] + E [ m a x ( 0 , 1 + D ( x ˆ ) ) ] L_D=E[max(0, 1- D(x))] + E[max(0, 1 + D(\^x))] LD=E[max(0,1−D(x))]+E[max(0,1+D(xˆ))]
生成器:
L D = − E ( D ( x ˆ ) ) L_D = -E(D(\^x)) LD=−E(D(xˆ))
VAE loss 如何构建
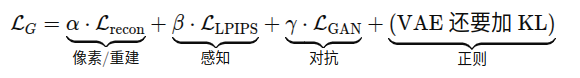
总结
本文就是对VAE 用的 loss 原理进行了剖析:
1 MSE 的原理和局限
2 其他的 loss
3 为什么要用 LPIPS loss
4 为什么要用 gan loss

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 15
15 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)