Constrained Dynamic Gaussian Splatting
则利用其属性在时间维度上的连续性,将量化后的数据重塑为2D图像序列(类似视频帧),然后利用成熟的视频编码器(H.264)进行高效压缩。,其最终高斯数量与预设目标的误差稳定在2%以内(如图7的收敛曲线所示),并能智能分配静态与动态部分的比例。:直接量化移除该高斯会导致的渲染图像质量下降(光度残差)、该高斯在屏幕上的覆盖面积,以及其在各训练视角下贡献的一致性。,将更多的高斯“配额”分配给复杂的动态区域
核心问题与动机:
传统动态3D高斯泼溅方法(Dynamic Gaussian Splatting)在重建动态场景时,为追求高保真度会无约束地增加高斯基元的数量,常常生成数百万个高斯。这导致模型体积庞大、内存消耗惊人,完全无法在手机、VR头显等计算与存储资源严格的边缘设备上部署。现有的压缩或剪枝方法多为训练后处理,粗暴移除高斯会破坏已优化的表示,导致渲染质量显著下降。因此,如何在训练伊始就将硬件资源限制作为核心约束,并在此限制下获得最优的重建质量,成为一个关键挑战。
核心思想:预算约束优化范式
本文提出了一个根本性的范式转变:将动态场景重建重新定义为一个预算约束优化问题。不再追求无限制的最高质量,而是追求在用户预设的、严格的高斯数量预算(N_target)内的最优质量。这就像在工程项目中,在固定的预算内完成最优的设计,迫使系统必须智能地分配资源。
整体框架(对应论文图2):
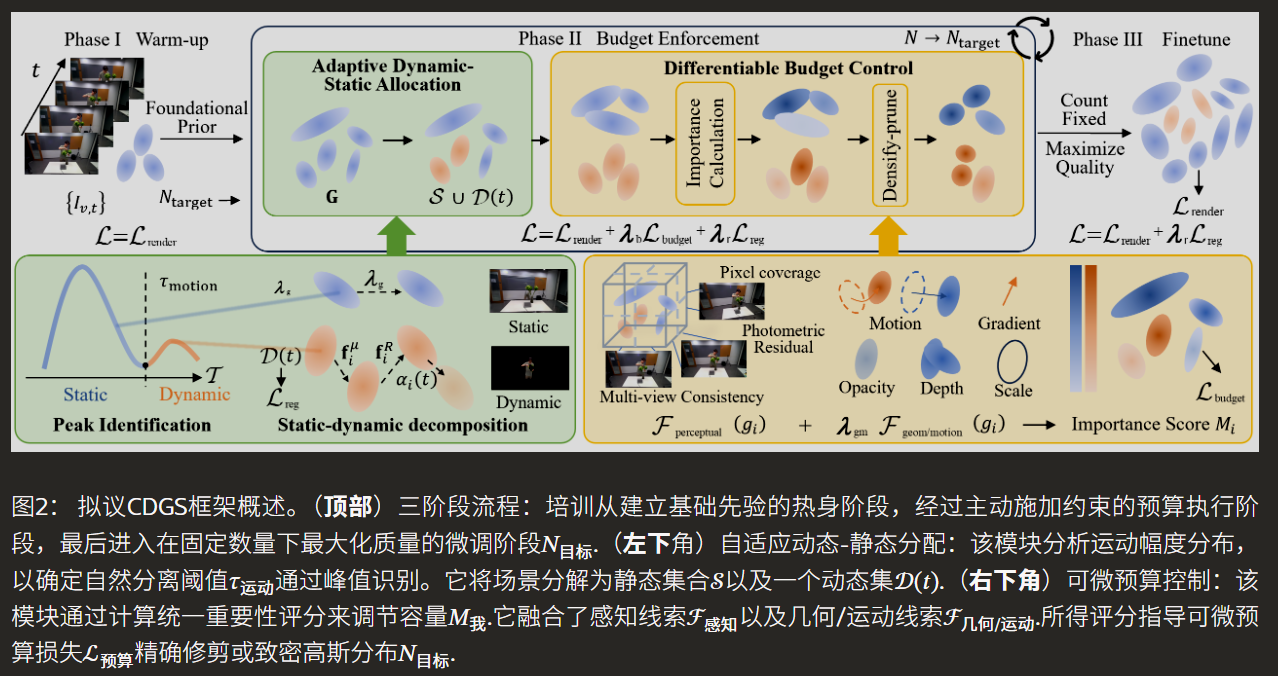
CDGS的整体流程是一个精心设计的三阶段训练管道。第一阶段(Warm-up),模型在不设限的情况下进行短暂初始化,快速捕捉场景的几何与运动先验。第二阶段(Budget Enforcement) 是核心,在此阶段引入了可微分预算控制器和自适应动静分配机制,主动将高斯总数导向目标值。第三阶段(Fine-tuning),在高斯数量稳定后,进行微调以恢复因控制过程可能损失的细节。框架底部展示了两个核心子模块:自适应动静分配模块通过分析运动幅度的分布直方图,自动寻找区分静态与动态元素的自然阈值 τ_motion,从而将场景分解为静态集 S 和动态集 D(t)。可微分预算控制模块则负责融合几何、运动与感知线索,计算每个高斯的统一重要性分数 M_i,并据此通过预算损失函数 L_budget 来精确地增加或删除高斯。
关键技术一:可微分预算控制器(对应论文图3)
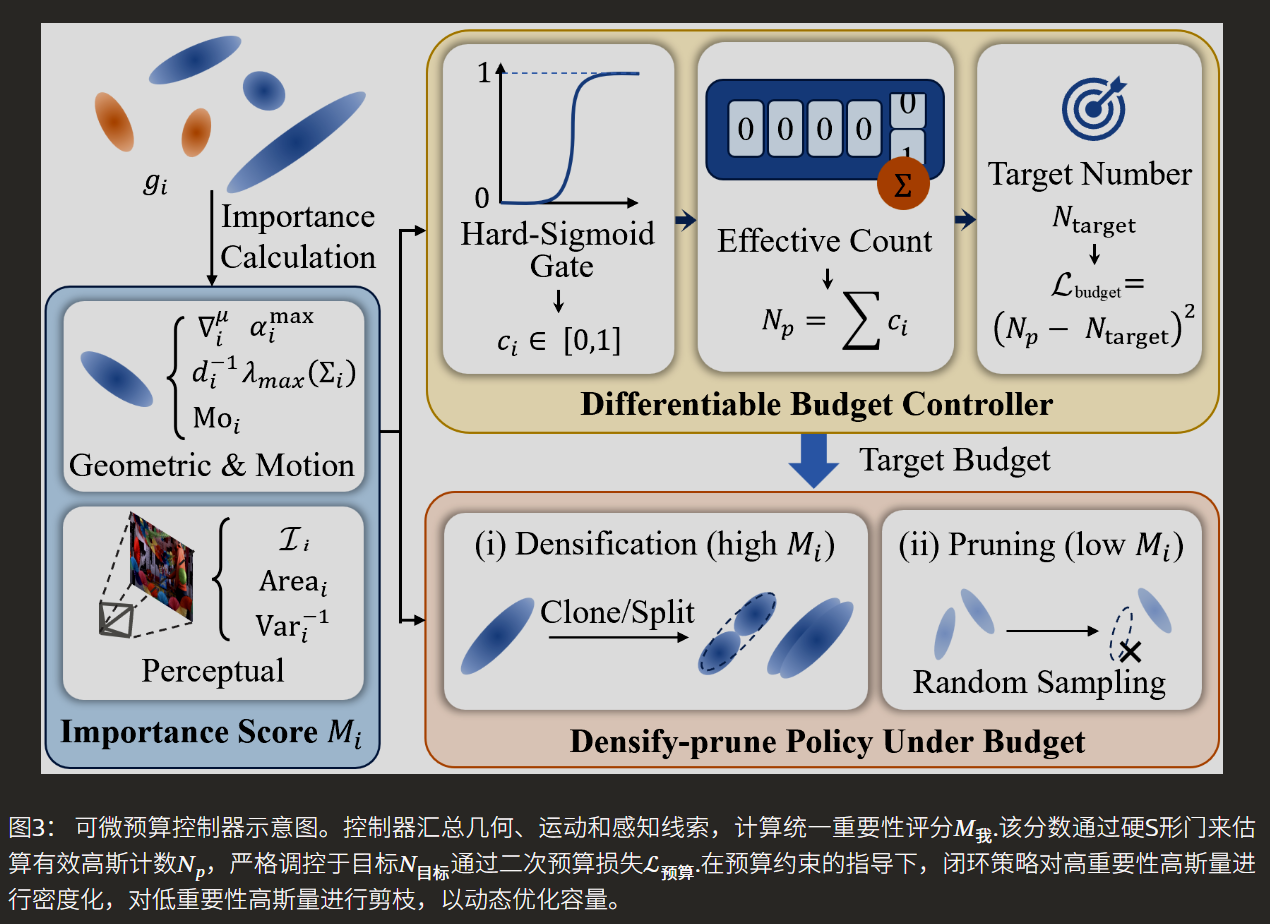
这是实现精确数量控制的核心。其核心挑战在于高斯数量是一个离散、不可微的量。CDGS的解决方案非常巧妙:为每个高斯 g_i 引入一个连续的激活变量 c_i,它通过一个温度可控的硬Sigmoid函数,由该高斯的统一重要性分数 M_i 计算得出。这个 c_i 值介于0到1之间,在渲染时用来调制高斯的不透明度。当 c_i 趋近于0时,该高斯变得透明,相当于被“软删除”。所有高斯的 c_i 之和 N_p 就形成了一个可微分的“有效高斯数量”代理变量。通过一个简单的二次损失函数 L_budget = (N_p - N_target)^2,即可在训练中用梯度下降驱动 N_p 精确逼近 N_target。训练后期,通过“退火”降低温度参数,c_i 会趋于二值(0或1),最终通过阈值化得到一个恰好包含约 N_target 个高斯的显式集合。
统一重要性分数 M_i 的构成是控制器智能与否的关键。它超越了仅考虑几何密度(如静态场景方法Taming 3DGS)的局限,创新性地融合了多模态线索:1) 几何与运动线索:包括位置梯度(识别对重建损失敏感的关键结构)、时序峰值不透明度(保护短暂可见的物体)、逆平均深度(优先处理前景)、空间协方差最大特征值(防止背景出现空洞)以及运动幅度(区分动静并保护高频运动)。2) 感知线索:直接量化移除该高斯会导致的渲染图像质量下降(光度残差)、该高斯在屏幕上的覆盖面积,以及其在各训练视角下贡献的一致性。这种综合评估确保了在严格预算下,被保留的高斯都是对最终视觉质量贡献最大的。
关键技术二:自适应动静分配(对应论文图9)
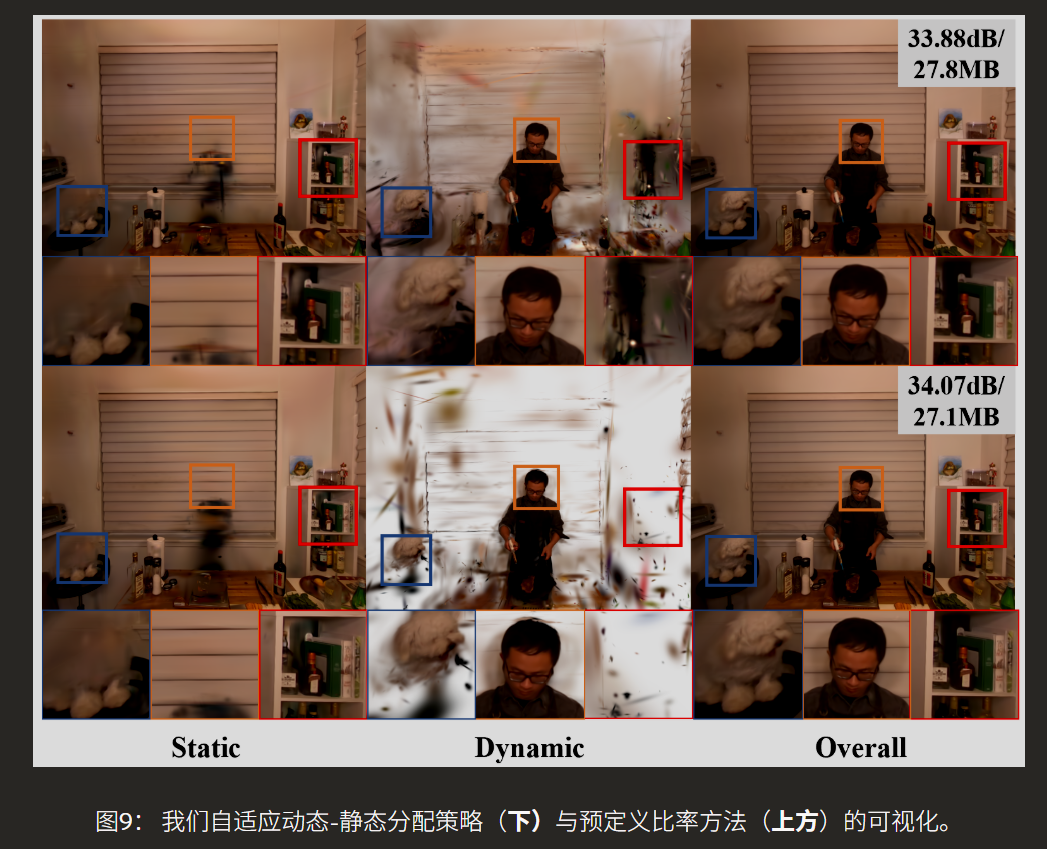
动态场景中资源消耗往往不均衡:大部分背景区域是静态的,而剧烈运动仅发生在局部区域(如人物手势)。均匀分配高斯预算会造成巨大浪费。CDGS提出了一种完全数据驱动的自动分解方法。其核心思想是分析场景中所有高斯平移运动量的分布。这个分布通常呈现双峰形态,分别对应静态和动态高斯群体。系统通过寻找双峰之间的“山谷”位置,自动确定分离阈值 τ_motion,而无需任何手工标注或启发式比例设定。如图9底部所示,这种方法能鲁棒地将墙壁、桌椅等静态元素归入静态模型,同时精准地将运动的手、小狗等区域划为动态部分。基于此分解,系统对静态和动态高斯采用不同的参数化策略,并按需分配预算,将更多的高斯“配额”分配给复杂的动态区域,从而最大化有限资源的使用效率。
关键技术三:双模式混合压缩(对应论文图4与图10)
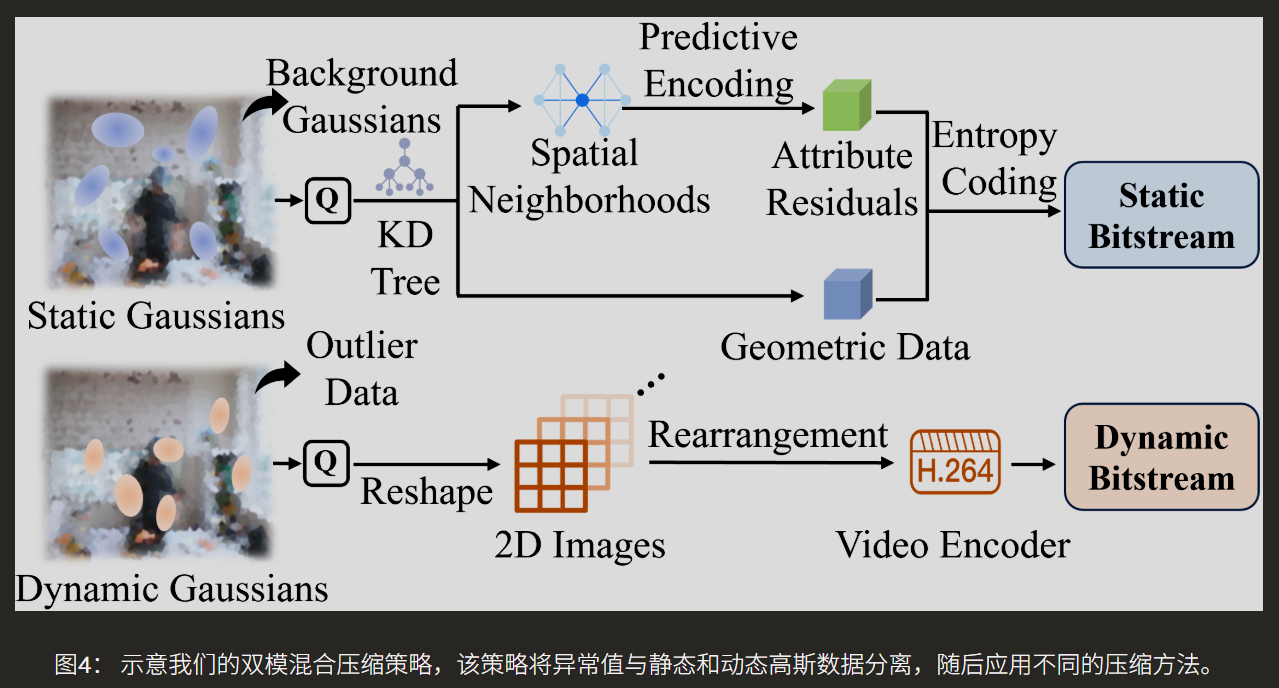
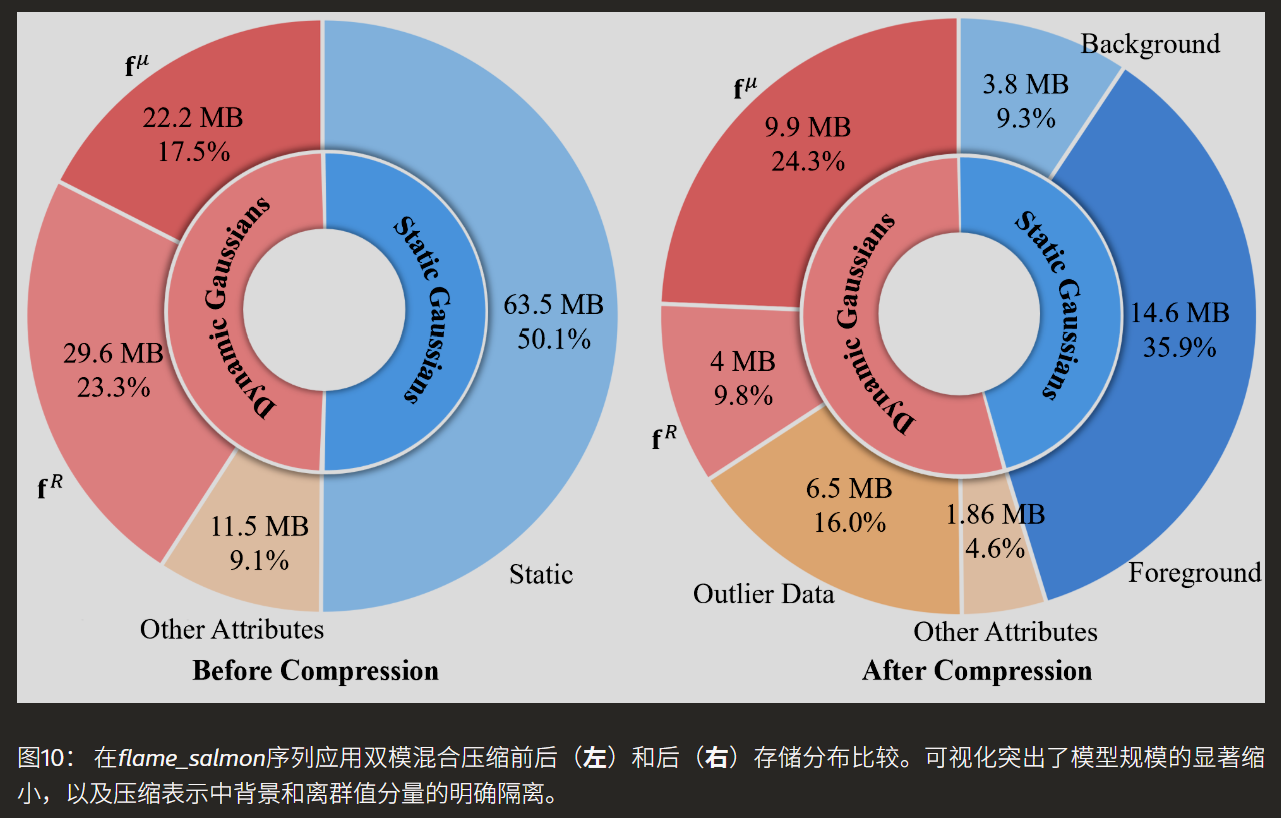
在已经获得紧凑模型的基础上,CDGS进一步设计了针对性的压缩方案以减小存储与传输开销。其策略是“分而治之”,对静态和动态高斯数据采用不同的压缩模式。对于静态高斯,关键洞察是远离场景中心的“背景”异常值会拉大坐标取值范围,导致均匀量化时精度下降。因此,首先基于距离统计分离出这些背景高斯,然后对前景高斯进行量化、空间重排(利用KD树),再对预测残差进行熵编码。对于动态高斯,则利用其属性在时间维度上的连续性,将量化后的数据重塑为2D图像序列(类似视频帧),然后利用成熟的视频编码器(H.264)进行高效压缩。图10的存储分布对比图清晰展示了压缩效果:压缩后,背景和异常值数据被成功隔离,存储空间被集中用于保留关键的前景和运动细节。
实验验证与效果:
论文在多个具有挑战性的真实动态数据集(N3DV, Technicolor, MeetRoom)上进行了全面评估。定量结果显示,在设定相似目标高斯数时,CDGS在PSNR和SSIM指标上达到或超越了当前最优方法(如4DGS、Ex4DGS),而模型大小仅为这些方法的1/3到1/20,实现了显著的压缩。更重要的是,CDGS展现了无与伦比的控制精度,其最终高斯数量与预设目标的误差稳定在2%以内(如图7的收敛曲线所示),并能智能分配静态与动态部分的比例。在渲染速度上,CDGS达到了每秒近200帧的实时性能。率失真曲线表明,CDGS在所有比特率上都推升了帕累托前沿,证明了其预算约束优化框架的整体优越性。
总结与贡献:
总而言之,CDGS通过引入可微分预算控制、自适应动静分配、三阶段训练和双模式压缩这一套组合创新,成功地将动态3D高斯重建从一个“先扩张后压缩”的启发式过程,转变为一个完整的、端到端的资源约束优化系统。它不仅解决了模型体积过大的问题,更提供了一种精确、可预测的硬件-质量权衡机制,为在广泛边缘设备上部署高质量自由视角视频与沉浸式媒体提供了切实可行的解决方案。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 14
14 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)