2026年AI应用大模型选型终极指南:最值得关注的权威大模型排行榜与Benchmark榜单
2026年AI大模型选型指南:权威榜单与实战建议 本文整理了2026年最值得关注的AI大模型评测榜单,为技术团队提供选型参考。核心推荐包括:LiveBench(抗污染能力)、Aider(代码能力)、HLE(专家推理)、LMSYS Arena(对话体验)和EQ-Bench(情绪智能)等权威榜单。针对不同场景给出选型建议:代码开发关注Aider,科研推理参考HLE,对话产品优先LMSYS,情感交互侧重
2026年AI应用大模型选型终极指南:最值得关注的权威大模型排行榜与Benchmark榜单
大家好,我是猫头虎。在2026年AI大模型井喷的时代,面对层出不穷的GPT-5、Claude 5、Gemini 3、DeepSeek-V4等前沿模型,如何选择最适合业务场景的LLM(大语言模型)成为技术团队的核心痛点。今天为大家精心整理了一份AI模型选型必备的大模型榜单导航,涵盖代码能力、推理能力、多模态、中文合规等各个维度,助力企业级AI应用落地。
关键词:大模型选型、AI模型排行榜、LLM Benchmark、LiveBench、LMSYS Arena、Humanity’s Last Exam、代码能力评测、国产大模型备案、GPT-5、Claude 5、Gemini 3
文章目录
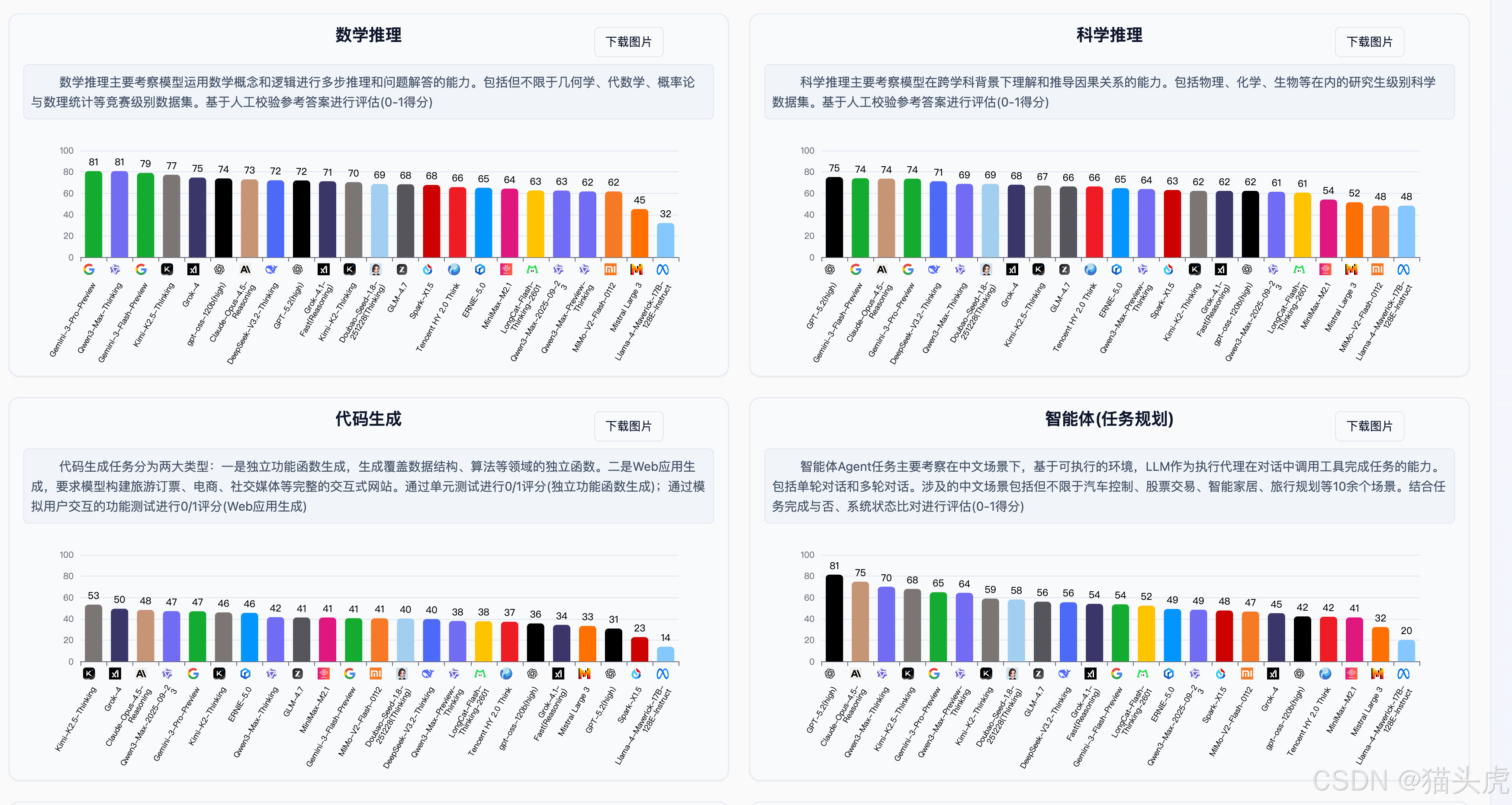
一、国际权威大模型排行榜(个人强烈推荐)
以下榜单从评测方法、数据更新频率、社区认可度来看,是目前全球AI开发者最值得信赖的大模型能力评估基准: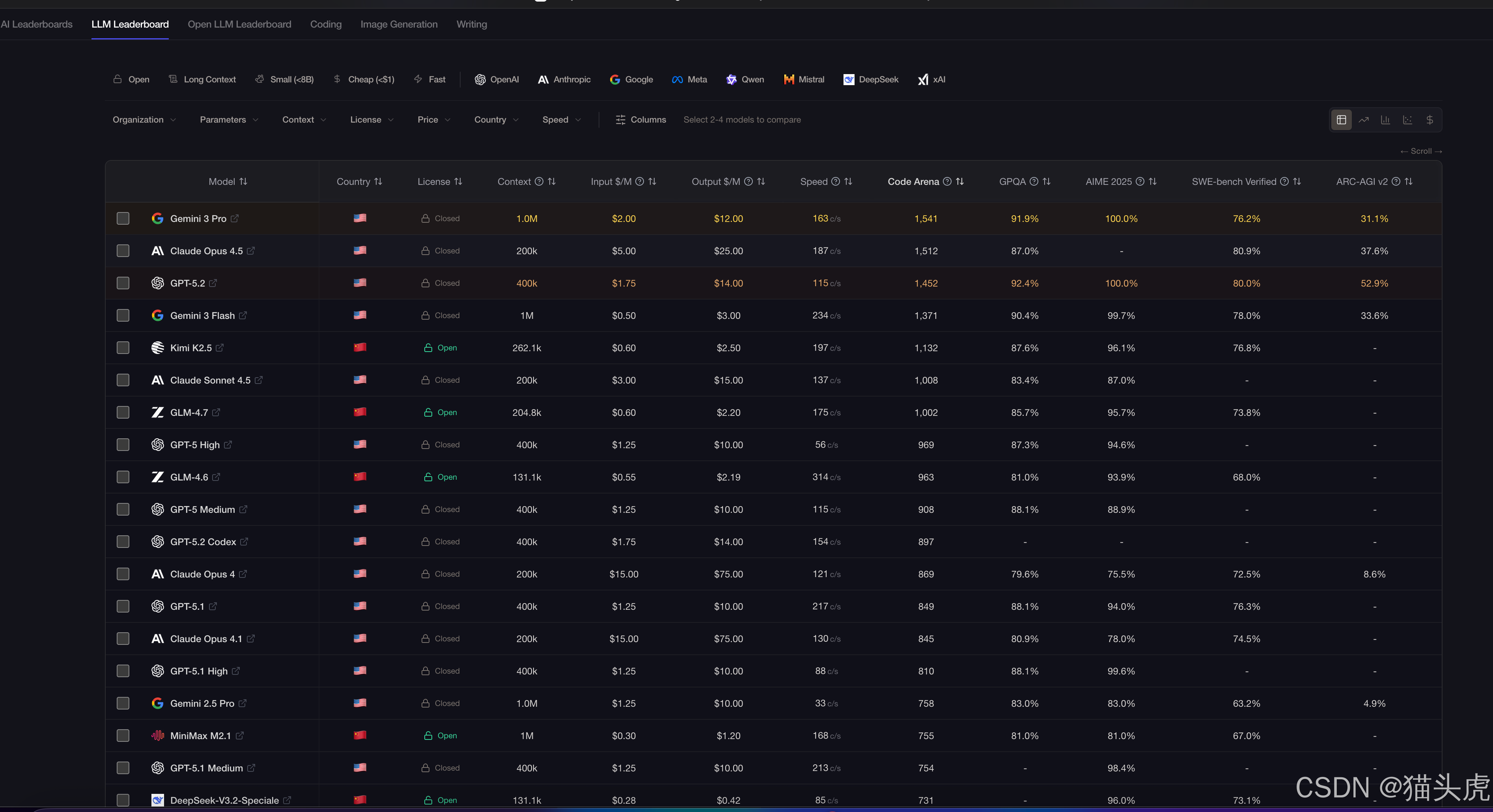
| 榜单名称 | 官方网址 | 核心评测维度 | 更新频率 | 适用场景 |
|---|---|---|---|---|
| LiveBench | https://livebench.ai/#/ | 抗污染能力、持续更新的实时评测 | 定期更新 | 避免数据泄露污染的纯净能力评估 |
| Aider Polyglot Coding Leaderboard | https://aider.chat/docs/leaderboards/ | 代码编辑与重构能力、多语言编程(Python/Go/Rust/Java/C++/JavaScript) | 实时更新 | AI编程助手选型、软件开发场景 |
| LLM Stats | https://llm-stats.com/ | 综合可视化、多维度数据对比 | 每日更新 | 快速对比模型性能与成本 |
| Humanity’s Last Exam (HLE) | https://scale.com/leaderboard/humanitys_last_exam | 专家级知识推理(数学41%、物理9%、生物/医学11%)、2,500道高难度题目 | 2025年4月已最终版 | 检验模型极限推理能力、科研场景 |
| ARC Prize Leaderboard | https://arcprize.org/leaderboard | ARC-AGI-2流体智能、自适应与效率平衡、成本效益分析 | 持续更新 | 通用人工智能(AGI)能力评估 |
| WebDev Arena | https://web.lmarena.ai/leaderboard | 网页开发能力、前端代码生成 | 实时更新 | Web开发、前端工程化 |
| LMSYS Chatbot Arena | https://lmarena.ai/?leaderboard | 人类偏好投票(Elo评分)、真实对话体验 | 实时更新 | 对话体验优化、客服场景 |
| LMSYS Arena (新版) | https://beta.lmarena.ai/leaderboard | 升级版的模型对战平台 | 实时更新 | 更精细的模型对比 |
| Wolfram LLM Benchmark | https://www.wolfram.com/llm-benchmarking-project/ | Wolfram语言代码生成能力 | 定期更新 | 科学计算、符号推理场景 |
| EQ-Bench | https://eqbench.com/ | 情绪智能(EQ)、共情能力、社交技巧 | 持续更新 | 心理健康、客服、教育陪伴场景 |
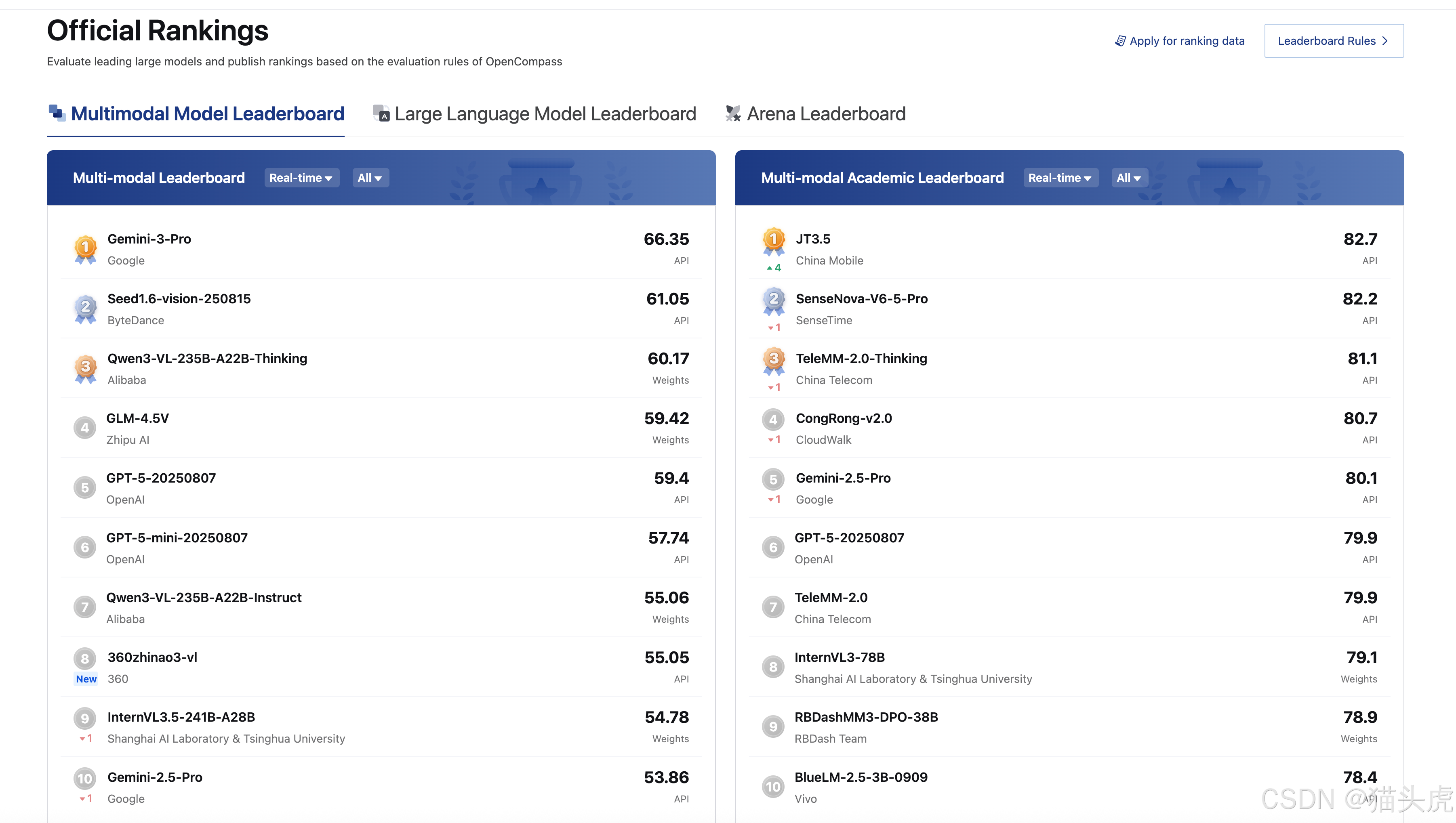
二、补充参考榜单(其他值得关注的AI模型评测)
以下榜单可作为大模型选型的辅助参考,覆盖开源模型、中文能力、特定垂直领域: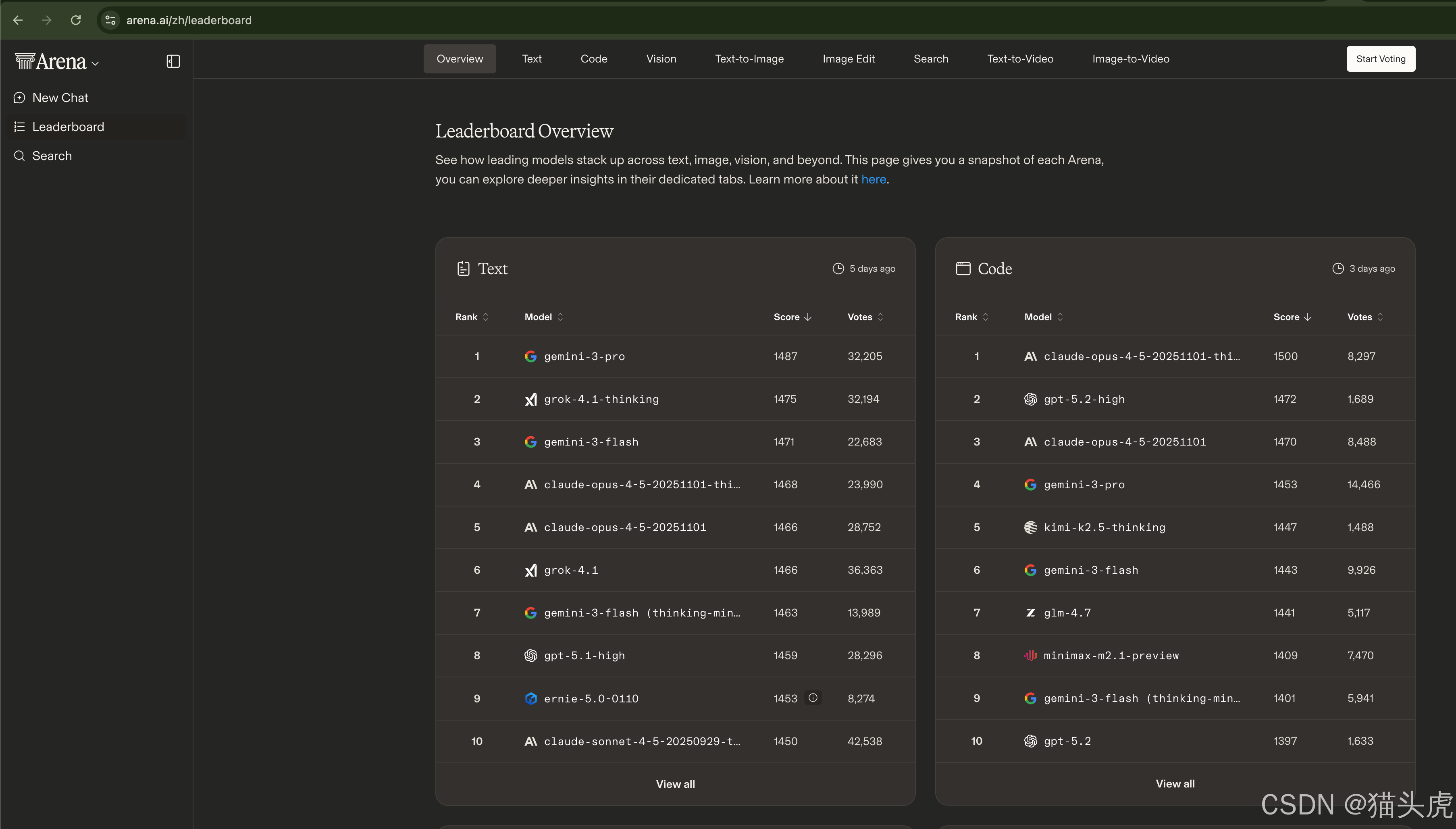
| 榜单名称 | 官方网址 | 评测特色 |
|---|---|---|
| LLM Stats Leaderboards | https://llm-stats.com/leaderboards/llm-leaderboard | 细分领域的LLM能力排行 |
| Arena AI | https://arena.ai/zh/leaderboard | 友好的模型对战平台 |
| Hugging Face Open LLM Leaderboard | https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard#/ | 开源模型可复现评测、社区驱动 |
| Artificial Analysis | https://artificialanalysis.ai/models/claude-3-7-sonnet | 详细的单一模型深度分析 |
三、2026年大模型选型实战建议
基于上述榜单,我为大家总结几点AI模型选型策略:
1. 代码开发场景
重点关注 Aider Leaderboard,当前GPT-5 (high)以88.0%的准确率领先,Gemini 2.5 Pro、DeepSeek-V3.2-Exp等紧随其后。建议根据预算(成本列)和准确率做权衡。
2. 科研与复杂推理
Humanity’s Last Exam 是目前最难的学术 benchmark,涵盖数学、物理、化学、生物等多学科专家级问题。如果模型在此榜单表现优异,说明具备深度知识推理能力。
3. 对话体验与用户体验
LMSYS Arena 采用真实人类投票机制,Elo评分反映用户主观满意度。对于C端产品、智能客服等场景,建议优先考虑Arena排名靠前的模型(如GPT-5、Claude-4、Gemini-2.5-Pro)。
4. 情绪智能与社交能力
EQ-Bench 专注评测模型的情商、共情能力和社交技巧,适用于心理咨询、教育陪伴、高端客服等需要情感交互的场景。
5. 成本效益平衡
ARC Prize Leaderboard 不仅看准确率,还关注每任务成本,帮助企业找到性能与性价比的最佳平衡点。
总结:收藏这份AI大模型选型导航
以上就是我为大家整理的2026年最权威、最实用的大模型排行榜合集。无论你是需要AI编程助手选型、多模态大模型对比,还是国产大模型合规查询,这份清单都能为你提供数据支撑。
建议收藏本文,定期回访这些榜单获取最新数据。大模型技术迭代飞快,基于实时Benchmark数据做选型决策,才能确保你的AI应用始终保持竞争力。
最后更新:2026年2月
作者:猫头虎
标签:#大模型选型 #LLMBenchmark #AI排行榜 #LiveBench #LMSYS #HumanitysLastExam #代码能力评测 #GPT5 #Claude4 #Gemini2.5

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 0
0 0
0- 0



 已为社区贡献43条内容
已为社区贡献43条内容

所有评论(0)