别再用Dify做Demo了!真正的工业级AI系统,必须掌握LangGraph+LangFuse+RAGFlow!
去年我们接到一个需求:**用AI自动生成建筑施工图设计说明**。听起来很简单?调个GPT API,接入几个PDF文档,写个前端界面就完事了。
一、为什么90%的AI应用都死在了Demo阶段?
去年我们接到一个需求:用AI自动生成建筑施工图设计说明。听起来很简单?调个GPT API,接入几个PDF文档,写个前端界面就完事了。
现实很骨感:
- 第一版Demo用了2周,效果还不错
- 但真正投入使用后,问题接踵而至:
- 生成内容不符合规范,设计师不敢用
- 检索速度慢,用户等不起
- 上下文超限,长对话直接崩溃
- Prompt散落各处,改一次要重新部署
我们花了3个月重构,最终搭建了一套工业级AI系统。本文将完整分享:
- 为什么选择 LangGraph 而不是 Dify
- 如何用 RAGFlow 解决专业文档解析
- ReAct 模式如何提升25%准确率
- 上下文爆炸的解决方案
- 完整的部署架构和踩坑经验
二、系统架构:前后端分离+独立AI服务
先看整体架构图:
为什么这样设计?
| 设计决策 | 理由 |
|---|---|
| Java + Python 分离 | Java处理业务逻辑和数据持久化,Python专注AI能力,各司其职 |
| 独立AI服务 | AI服务可独立扩容,不影响业务系统稳定性 |
| SSE流式传输 | 实时返回生成内容,用户体验更好 |
| RAGFlow独立部署 | 知识库管理与业务解耦,便于维护 |
| Langfuse独立部署 | 可插拔的 AI 应用监控、评测 |
三、核心技术选型:为什么不用Dify?
LangGraph vs Dify:代码控制 vs 低代码
很多人会问:Dify这么火,为什么不用?
Dify的优势:可视化拖拽,快速搭建标准RAG应用,适合非技术人员。
但我们的场景需要更强的控制力:
| 需求 | Dify | LangGraph |
|---|---|---|
| 复杂控制流 | 可视化编排难以表达逻辑循环、ReAct循环、条件重试 | 代码方式天然支持 |
| 状态管理 | 黑盒,难以调试 | TypedDict显式定义,透明可控 |
| 中断与恢复 | 不支持 | interrupt机制支持人工审核 |
| 深度集成 | API调用 | 与Spring Boot、RAGFlow深度集成 |
LangGraph核心优势示例:
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line
# 显式状态定义,每个字段清晰可控
class AgentState(TypedDict):
messages: Annotated[List[BaseMessage], add_messages]
project_info: str
research_loop_count: int # 循环计数器
graph = StateGraph(AgentState)
graph.add_node("researcher", researcher_node)
graph.add_node("generate", generate_node)
# 条件分支:根据状态动态决定下一步
graph.add_conditional_edges("researcher",
lambda state: "tools" if state["messages"][-1].tool_calls else "generate")
我们的选择:技术团队主导,代码可维护性优先于低代码便捷性。
RAGFlow:Context Engine专业文档解析的最佳选择
自建RAG的痛点:
- 建筑规范PDF解析复杂:表格、公式、层级结构
- 需要2-3个月开发文档解析、向量数据库、检索策略
RAGFlow的核心优势:
| 维度 | 自建RAG | RAGFlow |
|---|---|---|
| 文档解析 | 需自研 | DeepDoc开箱即用 |
| 检索策略 | 需调优 | 多种策略可选 |
集成示例:
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line
from ragflow_sdk import RAGFlow
class RAGService:
async def search(self, query: str, kb_ids: List[str]):
results = await self.client.search(
question=query,
datasets=kb_ids,
similarity_threshold=0.7,
top_k=10
)
return results
实际效果:万条规范文档,检索延迟 < 1秒。
Langfuse:LLM应用全生命周期观察、测试
 早期的痛点:
早期的痛点:
- Prompt散落在代码各处,难以统一管理
- 修改Prompt需要重新部署
- 无法追踪哪个版本的Prompt效果更好
- 生产环境问题难以复现和调试
- 缺少成本和性能监控
Langfuse的完整价值:
Langfuse不仅仅是Prompt管理工具,它是LLM应用从开发、测试到生产的全生命周期监控和调试平台。
| 功能模块 | 能力 | 价值 |
|---|---|---|
| Prompt管理 | 集中管理、版本控制、热更新 | 迭代周期从1天→10分钟 |
| 调用追踪 | 完整的调用链路、Token统计 | 快速定位问题根因 |
| 性能监控 | 延迟、成本、错误率实时监控 | 生产环境可观测 |
| 评测体系 | 自动化评测、人工标注 | 持续优化模型效果 |
| 数据集管理 | 测试用例、回归测试 | 保证版本质量 |
使用示例:
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line
class PromptManager:
def get_prompt(self, name: str, version: str = None):
"""获取指定版本的Prompt模板"""
prompt = self.langfuse.get_prompt(name=name, version=version)
return prompt.compile()
def trace_generation(self, trace_id: str, input: str, output: str):
"""记录完整的生成过程用于追踪和分析"""
return self.langfuse.trace(id=trace_id, input=input, output=output)
实际效果:
- 生产环境问题定位时间大幅降低
- 通过调用追踪发现并优化了多个性能瓶颈
四、核心突破:ReAct模式提升25%准确率
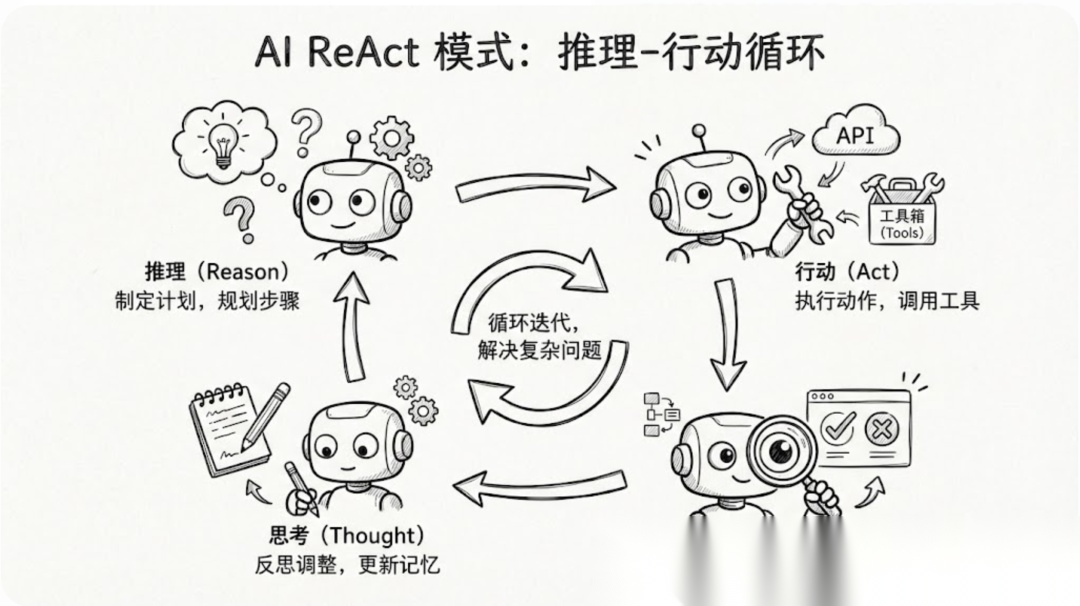
多Agent工作流设计
业务场景:生成完整的施工图设计说明,需要信息收集、文档生成、合规审核的完整流程。
三个核心Agent:
| Agent | 职责 | 工具 |
|---|---|---|
| 数据收集Agent | 查询规范库、案例库中的相关信息 | RAGFlow检索、知识库路由 |
| 文档编写Agent | 根据收集的信息生成设计说明 | 模板渲染、格式转换 |
| 审核Agent | 校验生成内容是否符合规范 | 规范条文比对、合规性检查 |
ReAct模式:从60%到85%的准确率提升
传统方案的问题:
- 一次性检索所有知识库 → 可能漏查关键信息,或查询过多无关内容
- 上下文质量不高 → 文档生成质量差
ReAct模式:Agent在"思考-行动-观察"的循环中逐步完善信息收集。
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line
用户需求: "生成大连某住宅项目的建筑设计说明"
│
▼
┌─────────────────────────────────────────────────┐
│ Reasoning: 大连属于寒冷地区,需要查询寒冷地区 │
│ 住宅建筑的防火和保温规范 │
│ Action: 调用RAGFlow检索防火+保温规范知识库 │
│ Observation: 获取到8条相关规范条文 │
├─────────────────────────────────────────────────┤
│ Reasoning: 大连临海,需要查询沿海地区的 │
│ 防腐蚀和抗风压设计要求 │
│ Action: 调用RAGFlow检索沿海建筑规范知识库 │
│ Observation: 获取到5条沿海地区特殊要求 │
├─────────────────────────────────────────────────┤
│ Reasoning: 还需要查询住宅的节能设计标准 │
│ Action: 调用RAGFlow检索节能规范知识库 │
│ Observation: 获取到4条节能设计标准 │
├─────────────────────────────────────────────────┤
│ Reasoning: 信息已足够,可以开始生成文档 │
│ Action: 将收集的信息传递给文档编写Agent │
└─────────────────────────────────────────────────┘
LangGraph实现示例:
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line
# 工具定义
researcher_tools = [retrieve_case, retrieve_standard, web_search]
# 构建工作流
workflow = StateGraph(AgentState)
workflow.add_node("researcher", researcher_node)
workflow.add_node("generate", generate_node)
workflow.add_node("auditor", auditor_node)
# ReAct循环控制:达到最大次数或无工具调用时退出
def researcher_condition(state):
if state.get("research_loop_count", 0) >= MAX_LOOPS:
return "generate"
return "tools" if state["messages"][-1].tool_calls else "generate"
workflow.add_conditional_edges("researcher", researcher_condition)
workflow.add_edge("researcher_tools", "researcher") # 工具结果返回推理
workflow.add_edge("generate", "auditor")
app = workflow.compile()
核心特性:
- 状态管理:
AgentState显式定义所有状态字段,便于调试 - 循环控制:通过
research_loop_count和条件判断控制循环次数 - 条件边:根据消息内容和状态动态决定下一步
效果对比:
| 指标 | 一次性检索 | ReAct模式 + 审核 |
|---|---|---|
| 一次通过率 | 60% | 90% |
| 平均检索次数 | 1次 | 2.3次 |
| 上下文质量 | 中 | 高 |
| 生成时间 | 5min | 10min |
核心价值:用时间换空间,准确率提升25%,大幅减少人工修改成本。
五、生产部署:Docker Compose一键启动
多环境配置:
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line
# docker-compose-dev.yml 核心结构
services:
web:
build: ../../apps/web
ports: ["3000:80"]
backend:
build: ../../apps/backend
ports: ["4999:4999"]
environment:
- MYSQL_HOST=mysql
- AGENT_URL=http://agent:8000
agent:
build: ../../apps/agent
ports: ["8000:8000"]
environment:
- RAGFLOW_BASE_URL=${RAGFLOW_BASE_URL}
- DASHSCOPE_API_KEY=${DASHSCOPE_API_KEY}
- LANGFUSE_PUBLIC_KEY=${LANGFUSE_PUBLIC_KEY}
mysql:
image: mysql:8.0
volumes: [mysql_data:/var/lib/mysql]
环境区分:
docker-compose-dev.yml:开发环境,暴露调试端口docker-compose-pro.yml:生产环境,安全配置.env文件:敏感配置统一管理
六、血泪教训:致命坑及解决方案
坑1:上下文爆炸导致LLM崩溃
问题现象:
- 检索10条规范文档,每条2000字 = 20K tokens
- 加上对话历史、系统Prompt、输出空间 → 轻松超过128K限制
- LLM报错或截断关键信息
4种解决方案:
| 方案 | 做法 | 效果 |
|---|---|---|
| 1. 文档压缩 | 提取关键句子,而非全文 | 减少70% tokens |
| 2. 滑动窗口 | 只保留最近5轮对话 | 控制历史增长 |
| 3. 动态Top-K | 根据剩余空间调整检索数量 | 自适应调整 |
代码示例:
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line
# 文档摘要压缩
def compress_documents(docs, max_length=500):
return [Document(
page_content=extract_key_sentences(doc.page_content, max_length),
metadata=doc.metadata
) for doc in docs]
# 滑动窗口管理对话历史
def get_recent_context(messages, max_history=5):
return messages[-max_history * 2:] # 每轮包含 user + assistant
# 动态调整检索数量
def adaptive_retrieve(query, max_tokens=8000):
available = max_tokens - count_tokens(history) - 2000
return rag_service.search(query, top_k=min(10, available // 500))
效果:上下文控制在32K以内,支持更长的多轮对话。
坑2:Prompt版本爆炸,管理混乱
问题:早期Prompt散落在代码各处,修改需要重新部署。
解决方案:
- 所有Prompt模板迁移到Langfuse
- 代码中只保留Prompt名称引用
- 支持动态参数编译
ounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(lineounter(line
# 重构前:硬编码在代码中
prompt = """你是一个建筑规范助手..."""
# 重构后:从 Langfuse 动态获取 + 参数编译
prompt_manager = PromptManager()
researcher_prompt = prompt_manager.get_prompt("langchain_researcher")
system_msg = researcher_prompt.compile(
project_info=project_info,
loop_count=loop_count,
loop_guidance=loop_guidance
)
效果:
- Prompt动态更新,有序管理。
- LLM 全过程可视化监测。
- 基于评分系统,为数据闭环提供支撑。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 14
14 0
0- 0



 已为社区贡献523条内容
已为社区贡献523条内容

所有评论(0)