从 0 到企业落地:Coze(扣子)工作流
本文针对企业用户,介绍如何有效使用低代码工作流。工作流通过结构化框架组织数据流动与任务处理,将大模型能力与业务逻辑结合,形成可审计、可复现的AI应用开发方式。相比普通智能体,工作流更适合固定流程、多步协作场景(如留资、报表、工单处理)。文章详细讲解工作流创建、编排、调试和发布的完整流程,并比较显式调用(推荐)与隐式调用两种使用方式。通过可视化画布拖拽节点和连线,企业可以构建稳定运行的业务流水线,实
本文面向“要把工作流真正用起来”的读者:不仅讲怎么搭,还讲怎么选、怎么控成本、怎么在企业里跑得稳。主要参考官方文档:
- 低代码工作流介绍
- 使用低代码工作流
- 工作流与对话流
- 低代码工作流使用限制
- 低代码工作流常见问题
- 节点文档:开始/结束、输出、LLM、插件、代码、选择器、循环、批处理、知识库检索、变量等(见文末“参考链接”)
一、工作流是什么?为什么企业更需要它?
官方定义很清楚:工作流是一组可执行指令,用结构化框架组织数据流动与任务处理,把大模型能力与业务逻辑结合,形成可扩展的 AI 应用开发方式(见:低代码工作流介绍)。
附:官方《低代码工作流介绍》要点摘录
- 低代码工作流是一系列可执行指令的集合,为应用/智能体的数据流动和任务处理提供结构化框架;核心是将大模型能力与业务逻辑结合,实现高效、可扩展的 AI 应用开发。扣子提供可视化画布,可拖拽节点搭建并在画布实时调试,清晰看到数据流转与执行顺序。
- 工作流(Workflow):处理功能类请求,顺序执行节点完成某功能,适合数据自动化(如调研报告、海报、绘本)。
- 对话流(Chatflow):基于对话场景,通过对话与用户交互并完成复杂业务逻辑,适合 Chatbot、智能客服、虚拟伴侣等。
- 节点:每个节点具备输入与输出;默认含开始节点(定义输入参数)与结束节点(返回结果);通过引用节点输出将节点连成操作链;多种节点支持
String、Integer、Number、Boolean、Object、File、Array等变量类型。 - 费用:付费节点按计费规则收费(模型节点产生 token 费用,功能节点与插件按各自规则);整体失败时已成功运行的付费节点仍计费。
- 权限:所有者拥有编辑、发布、复制、删除、导出等全部权限;协作者可编辑、导出、发布;空间成员可创建、查看、复制、导入,不可编辑、发布、导出。
把它翻译成企业语言:
- 模型擅长理解与生成,但不擅长“接系统、做动作、跑规则”
- 工作流把“接系统/跑规则/回写数据/可视化输出”做成可审计的流水线
1.1 工作流 vs 普通智能体:什么时候需要工作流?
在扣子里,普通智能体指主要靠「人设与回复逻辑」+ 技能(插件、知识库、联网等)与用户对话的 Bot:由模型在每轮对话中自行决定是否调用技能、调用哪个、参数怎么填,没有固定执行顺序。工作流则是在画布上显式编排的节点与连线,执行顺序、分支、数据流都由你设计,可复现、可审计。
| 维度 | 普通智能体 | 工作流 |
|---|---|---|
| 执行方式 | 模型每轮自由决定:要不要用技能、用哪个、怎么填参 | 按画布固定顺序执行节点,步骤确定 |
| 可控性 | 依赖模型意图识别,同一句话可能走不同路径 | 流程确定,同一输入走同一路径(除分支条件) |
| 适用场景 | 开放对话、多轮闲聊、简单问答、模型“自己选工具”即可 | 固定流程、多步协作、必须“先 A 再 B 再 C”、需进度/中间输出 |
| 典型例子 | “帮我查天气”“介绍一下产品”(模型选插件/知识库) | 留资(问答→写库→回执)、报表(拉数→清洗→LLM 总结→输出)、工单(查单→分支→子流程) |
| 成本与可观测 | 调用链不固定,难精确复现单次路径 | 每步可看输入输出,试运行可复现,便于排错与控成本 |
何时用工作流、何时只用普通智能体?
- 只用普通智能体即可:对话开放、没有强顺序要求、模型“选工具”就能满足(如查天气、简单知识库问答)。
- 建议上工作流:流程有明确步骤(如先查订单再分支处理)、需要中间进度/安抚语、要写库/调多个系统/严格顺序、或需要可审计可复现的流水线。
二、工作流怎么用(从创建到上线)
2.1 创建与编排(最短路径)
官方步骤是三段式:创建 → 编排节点 → 试运行与发布(见:使用低代码工作流)。
| 阶段 | 你要做什么 | 产出 | 关键点 |
|---|---|---|---|
| 创建 | 在资源库新建工作流 | 初始画布(开始+结束) | 命名与描述要清晰,有助于模型理解(官方强调) |
| 编排 | 拖拽节点并按顺序连线 | 可执行流程 | 让数据在节点间通过变量流动 |
| 调试 | 试运行、看每个节点输入输出 | 可复现的测试集 | 运行成功的节点边框变绿,可查看输入输出 |
| 发布 | 发布版本 | 可被智能体/应用引用 | 发布后才可在智能体内稳定使用 |
官方搭建路径(摘自《使用低代码工作流》):步骤一:登录扣子编程 → 资源库 → +资源 > 工作流 → 设置名称与描述 → 确认,即进入编辑页(初始含开始、结束节点)。步骤二:在底部面板选择节点、将节点相连、配置各节点输入与输出;插件商店收藏的插件会在「添加节点」中展示。步骤三:试运行(可上传文件或输入文件 URL;运行成功的节点边框变绿,可查看输入输出)→ 发布(可选已保存测试集作为默认测试集,供空间内其他用户试运行)。在智能体中:工作流区域点加号 → 选择自建工作流 → 在「人设与回复逻辑」中引用工作流名称调用。查看引用资源:编排页右上角点引用关系图标,可查看工作流引用的子工作流、插件、数据库、知识库及版本。复制:编辑页右上角「创建副本」可复制工作流;支持跨画布复制节点粘贴到目标画布(跨空间复制时暂不支持同时复制火山知识库绑定)。
2.2 在智能体里使用工作流(两种方式)
| 使用方式 | 适合 | 关键点 |
|---|---|---|
| 显式调用(推荐可控) | 明确场景必须走工作流 | 在“人设与回复逻辑”里明确指令,引用工作流名称(见:使用低代码工作流) |
| 隐式调用(更自动) | 让模型自己判断何时用 | 依赖模型意图识别,命名/描述更重要(见:低代码工作流常见问题) |
2.3 异步运行(解决“长流程超时”)
当流程复杂或耗时节点多,默认同步可能触发整体 10 分钟超时。官方提供异步运行:超时延长到 24 小时,并先返回一段预设回复,待工作流完成后再给最终回复(见:使用低代码工作流 + 使用限制)。
**注意:**异步运行并不是所有渠道都支持(官方说明“飞书、豆包等渠道暂不支持异步运行”)(见:使用低代码工作流)。官方补充:设置异步后需在工作流右侧点「设置」→ 开启「异步运行」并设置「回复内容」(即先返回给用户的默认文案);异步仅在调试或与商店智能体对话时生效;工作流开启异步运行后,模型节点无法查看对话历史。
2.4 发布到各渠道:具体操作与注意事项
完成工作流编排并发布版本后,需在应用/Bot 中配置发布渠道,用户才能从飞书、微信、掘金等入口使用。以下为各渠道的典型操作与注意点。
发布到飞书
具体操作:
- 在 Coze 控制台进入对应应用,打开「发布」→「飞书」。
- 选择「飞书企业自建」或「飞书应用商店」,按引导完成飞书开发者配置(创建应用、拿到 App ID / App Secret、配置权限与事件订阅)。
- 在飞书后台配置机器人能力、消息与事件订阅(如
im.message.receive_v1),并将请求 URL 指向 Coze 提供的飞书回调地址(若需)。 - 在 Coze 中填写飞书应用的 App ID、App Secret、Encrypt Key 等,保存并启用「飞书」渠道。
- 在飞书工作台或群聊中添加该应用,进行发消息/指令测试。
注意事项:
- 飞书暂不支持异步运行:长耗时工作流可能超时,需用输出节点做进度提示或缩短单次流程(见 2.3)。
- 权限与订阅必须与 Coze 文档一致(如「获取与发送单聊消息」「获取群信息」等),否则收不到用户消息或无法回复。
- 企业自建与应用商店的审核、可见范围不同,上线前确认目标用户能否看到该应用。
示例: 内部「周报助手」Bot 发布到飞书:在 Coze 创建应用并编排「汇总本周 Jira/邮件 → LLM 生成周报」工作流,发布后选「飞书企业自建」,填写公司飞书应用的 App ID/Secret,员工在飞书群 @Bot 说「帮我生成本周周报」即可触发,回复在群内展示。
发布到微信客服
具体操作:
- 在应用「发布」中选择「微信客服」渠道。
- 在微信公众平台(mp.weixin.qq.com)的「功能」→「微信客服」中开通客服能力,并创建客服链接/客服账号。
- 按 Coze 指引将客服链接或客服会话与 Coze 应用关联(通常需在 Coze 中填写客服 ID 或接入配置)。
- 若使用「微信客服 API」方式,需在公众平台获取 AppID、AppSecret,并在 Coze 中配置回调或 API 对接。
- 在客服会话中发送消息,验证 Bot 是否正常回复。
注意事项:
- 微信客服有会话窗口限制与消息格式要求(文本/图片等),工作流返回内容需符合客服消息规范,避免超长或复杂卡片在客服端展示异常。
- 客服接入方式分「网页/小程序内嵌客服」与「API 对接」,选型后按对应文档配置,不要混用两套流程。
发布到微信服务号
具体操作:
- 在应用「发布」中选择「微信(服务号)」或「微信公众号」渠道。
- 在微信公众平台使用已认证服务号,在「开发」→「基本配置」中获取 AppID、AppSecret,并配置 IP 白名单、服务器地址(若 Coze 要求填回调 URL)。
- 在 Coze 中填写服务号 AppID、AppSecret;若需菜单/事件回调,按 Coze 文档填写 Token、EncodingAESKey 及回调 URL。
- 在公众平台「自定义菜单」或「自动回复」中配置关键词/菜单,将用户请求指向已对接的 Coze 应用(具体以 Coze 当前接入方式为准)。
- 用微信扫码关注服务号,发送配置的关键词或点击菜单,验证回复与工作流是否一致。
注意事项:
- 服务号需已认证,未认证账号能力受限,可能无法使用 Coze 的完整能力。
- 服务号有频率与条数限制(如 48 小时客服窗口、模板消息条数等),长流程或批量回复需考虑分条或引导用户再次触发。
- 若工作流返回「卡片/富媒体」,需确认服务号接口是否支持(部分仅支持文本/图文),否则要做文本兜底。
发布到微信订阅号
具体操作:
- 在应用「发布」中选择「微信(订阅号)」渠道(若 Coze 提供该选项)。
- 在微信公众平台使用订阅号,在「开发」→「基本配置」中获取 AppID、AppSecret。
- 在 Coze 中填写订阅号 AppID、AppSecret 及所需回调参数;订阅号通常无客服会话接口,多为「关键词自动回复」或「收到消息后 API 回调」。
- 在公众平台「自动回复」或「开发」中配置:用户发消息 → 请求 Coze 回调/API → 将返回内容作为自动回复展示。
- 关注订阅号并发送消息,验证是否走通工作流并得到回复。
注意事项:
- 订阅号没有客服消息接口,只能通过「自动回复」或「开发模式」回调拿到用户消息并回写一条回复,交互能力弱于服务号。
- 每日可推送条数、接口调用频率都有限制,适合轻量通知或简单问答,不适合高频、长对话场景。
- 若 Coze 当前仅支持服务号接入,订阅号需以「复制链接/二维码到菜单」等方式跳转到 H5 或小程序,再在 H5/小程序内使用 Coze 能力。
发布到掘金
具体操作:
- 在应用「发布」中选择「掘金」或「内容平台 - 掘金」类渠道(名称以 Coze 控制台为准)。
- 按 Coze 指引完成掘金侧授权:通常需在掘金创作者/开放平台创建应用或绑定账号,获取 Client ID、Client Secret 等。
- 在 Coze 中填写掘金应用 ID、Secret 及回调地址(若有 OAuth 或 Webhook),保存并启用渠道。
- 若为「文章/内容同步」场景:在 Coze 中配置触发条件(如定时、手动),将工作流产出的正文/摘要同步到掘金草稿或已发文章。
- 若为「互动 Bot」:确认掘金是否提供私信/评论回复 API,并按文档在 Coze 中配置事件与回复逻辑,再在掘金端做互动测试。
注意事项:
- 掘金侧能力以内容发布、数据查询为主,实时对话/客服类能力取决于掘金开放接口,需以掘金与 Coze 最新文档为准。
- 同步到掘金的内容需符合社区规范(原创、无违规等),工作流生成的文案建议有人工审核或敏感词过滤。
- 若 Coze 与掘金的对接方式为「API + 定时任务」,需在工作流中做好失败重试与日志,避免同步失败却无感知。
三、Workflow vs Chatflow:到底选哪个?
官方给出了清晰对比(见:工作流与对话流):
| 维度 | 工作流(Workflow) | 对话流(Chatflow) |
|---|---|---|
| 核心场景 | 功能/任务流水线、批处理 | 对话交互与复杂对话逻辑 |
| 上下文 | 模型类节点不读对话历史 | 模型/意图识别可读会话历史 |
| UI | 支持多种布局/展示组件 | 目前仅 AI 对话组件 |
| 发布渠道 | 应用内可发布 API;部分渠道受限 | 应用内支持 API&SDK/小程序/社交渠道等(官方写“全部渠道”) |
官方补充(摘自《工作流与对话流》):对话流绑定会话,可读取历史消息并写入本次运行产生的消息,相当于“带记忆的工作流”。搭建对话式 AI 应用(助手、客服等)推荐用对话流;工具类、批量处理、任务自动化选工作流。互转:对话流→工作流后,模型类节点不再读对话历史,开始节点预置参数变为普通参数;工作流→对话流后,开始节点会新增必选参数 USER_INPUT、CONVERSATION_NAME 且不可删。节点差异:对话流开始节点须指定会话;对话流中的大模型、意图识别节点支持读取对话历史。发布与 API:工作流支持发布到 API,绑定 UI 后可发布到模板、商店,暂不支持社交渠道、Chat SDK、小程序;对话流支持 API&SDK、小程序、社交渠道、商店、模板等全部渠道。工作流通过「执行工作流」API 调用,对话流通过「执行对话流」API 调用。
一句话决策:
- 你要“跑任务、出结果” → 选 工作流
- 你要“多轮对话、带记忆、带对话 UI” → 选 对话流
四、节点体系:用“对比”理解每个节点的定位
工作流的核心是节点(见:低代码工作流介绍)。下面按“你在企业里会怎么用”来分组。
4.1 起点/终点:开始与结束节点
官方说明:开始节点定义输入参数,结束节点返回结果,支持返回变量(JSON)或返回文本(可流式)(见:开始和结束节点)。
| 节点 | 你用它做什么 | 企业常用技巧 |
|---|---|---|
| 开始 | 定义输入(必填/可选) | 导入 JSON 批量建参;描述写清楚让模型更会填参 |
| 结束 | 输出最终结果 | 返回变量适合卡片/子工作流;返回文本适合直接对话 |
4.2 过程可视化:输出节点(Message Node)
输出节点用于中间过程输出(Loading/安抚语/阶段性结果),支持流式与绑定卡片(见:输出节点)。
| 什么时候必须加输出节点 | 原因 |
|---|---|
| 流程耗时长(外部系统慢、模型长文) | 防止用户等待放弃;也能避免“连续两次回复间隔>10分钟”触发超时(见:工作流 FAQ) |
输出节点在长流程中相当于“进度条”,避免用户空等并规避 10 分钟回复间隔限制。
4.3 “大脑”与“手脚”:LLM 节点 vs 插件节点 vs 代码节点
快速对比表
| 节点 | 最擅长 | 最怕什么 | 适用场景 |
|---|---|---|---|
| LLM 节点 | 理解/生成/总结/改写 | 不确定性(幻觉/漂移) | 文案、总结、分类、生成结构化输出(见:大模型节点) |
| 插件节点 | 调用确定性工具/API | 限流/鉴权/外部不稳定 | 查天气、查订单、写飞书表格(见:插件节点) |
| 代码节点 | 结构化处理/转换/校验 | 超时 60s;依赖库受限 | 把文本切数组、拼 records、计算字段(见:代码节点) |
一个非常实用的编排套路
插件取数据 → 代码清洗/结构化 → LLM 生成表达 → 输出/卡片展示
4.4 逻辑控制:选择器(if-else)与循环
| 需求 | 用哪个 | 依据 |
|---|---|---|
| 需要分支(A/B/C 路径) | 选择器节点 | 标准 if-else(见:选择器节点) |
| 需要逐个处理(严格串行) | 循环节点 | 多轮串行;支持数组循环/次数/无限循环(见:循环节点) |
4.5 批量并行:批处理节点(Batch)
批处理用来对数组元素并行处理,提高吞吐(见:批处理节点)。
| 对比项 | 循环 | 批处理 |
|---|---|---|
| 核心特征 | 串行、强调顺序 | 并行、强调吞吐 |
| 适合 | 需要上下文衔接、每步依赖上一步 | 图片批量分析、批量调用插件 |
| 限制要点 | 不支持嵌套循环 | 批处理体不支持再套批处理/循环;并行不要超过插件限流;同一时刻只允许一个流式插件/消息节点(见:批处理节点) |
4.6 企业级“知识底座”:知识库检索节点
知识库检索节点负责 RAG 召回,支持扣子知识库与火山知识库,并提供检索策略、最小匹配度、查询改写、结果重排等(见:知识库检索节点)。
| 企业典型用法 | 为什么好用 |
|---|---|
| SOP/FAQ/产品手册问答 | 控制答案来源,减少幻觉 |
| 结合标签过滤与重排 | 更高精度,适合客服/技术答疑 |
4.7 变量:别再用“变量节点”
官方明确:变量节点已停用;赋值用“变量赋值节点”,读取则多数节点都可直接读变量(见:变量节点)。
变量在整个工作流内共享;下游节点通过
{{变量名}}或选择器引用,无需单独“变量节点”。
五、节点实战手册(每个节点怎么用|示例|注意事项)
这一节把“对比”升级成“可直接照着搭”。示例以常见企业场景为主:客服、报表、内容生产、留资、批量处理。
本节按节点类型分小节:每小节含「你会用它做什么」「示例」「注意事项」「具体例子可照抄」。
5.1 开始节点(Start):把输入参数设计成“可被模型正确填参”
你会用它做什么
- 定义工作流入参(哪些必填、哪些可选、类型是什么)
- 让智能体在触发工作流时,能把用户 Query 自动拆到对应参数里
示例:工单创建(结构化入参)
- 开始节点参数建议
issue_title(String,必填):问题标题issue_desc(String,可选):问题描述priority(String,可选):P0/P1/P2attachments(File 或 Array,可选):附件
注意事项(容易踩坑)
- 参数描述要写清楚:描述信息会影响模型是否能“自动填参”(见:开始和结束节点)。
- Object 参数嵌套层级:Object 类型参数最多支持 3 层嵌套(见:开始和结束节点)。
- 必填参数与触发:缺少必填参数时可能无法开始执行;对话里用户没说清楚就会触发失败或走不到预期流程。
- 导入 JSON 批量建参:复杂入参建议用“导入 JSON → 同步到节点”来建参,避免手工漏字段(见:开始和结束节点)。
官方补充(摘自《开始和结束节点》):开始节点仅含输入参数,默认有 input(用户本轮输入),可按需添加;支持多种数据类型,Object 最多 3 层嵌套;支持导入 JSON 批量添加参数;参数描述会帮助模型理解并自动填参;必选参数未指定时无法开始执行。结束节点两种返回方式:返回变量(JSON 输出,适合绑定卡片或作子工作流;直接绑智能体时模型会总结 JSON 以自然语言回复);返回文本(模型直接使用指定内容回复,支持 {{变量名}} 引用与流式输出;当大模型输出为 JSON 且含多字段时不支持流式,系统会先处理再一起输出)。
具体例子(可照抄)
- 开始节点导入 JSON(示例):
{
"issue_title": "打印机无法连接",
"issue_desc": "办公室 3F 打印机提示离线,已重启无效",
"priority": "P1"
}
- 对话里触发时用户可能这样说:
“帮我建个工单:打印机连不上了,地点 3F,比较急(P1)。”
你希望模型能把这句话拆进issue_title/issue_desc/priority(靠参数名+描述来引导)。
5.2 结束节点(End):选“返回变量”还是“返回文本”?
你会用它做什么
- 定义最终输出:给用户看(文本)、给下游系统用(JSON)
示例:既要给用户看,也要给系统用
- 结束节点返回变量(JSON):输出
ticket_id、status、raw_result - 智能体侧可再用自然语言解释 JSON(官方说明:工作流绑定智能体时,模型会总结 JSON 并回复)
注意事项
- 返回变量更适合:绑定卡片/作为子工作流/被 API 调用复用(见:开始和结束节点)。
- 返回文本更适合:对话里直接“最后一句话”。
- 流式输出限制:当大模型输出为 JSON 且包含多个字段时,不支持流式输出(见:开始和结束节点)。
具体例子(可照抄)
- 返回变量(JSON)示例(适合给卡片/系统消费):
{
"ticket_id": "INC-20260202-00018",
"status": "created",
"raw_result": {
"provider": "jira",
"key": "IT-3187"
}
}
- 返回文本示例(适合直接对话):
- 回答内容:
工单已创建:{{ticket_id}}(优先级:{{priority}})。我会在 10 分钟内更新处理进度。
- 回答内容:
5.3 输出节点(Message):长流程的“进度条”和“安抚语”
你会用它做什么
- 在工作流执行过程中插入一条中间消息:例如“正在查询中…”
- 支持流式(打字机效果)与绑定卡片(见:输出节点)
示例:报表生成(先出进度,再出结果)
注意事项
- 流式输出只有在大模型节点之后才能开(见:输出节点)。
- 绑定卡片时不流式:即使开启流式,卡片也会等内容完整再一次性展示(见:输出节点)。
- 多输出节点 + 流式:遵循执行顺序,先执行先输出(见:输出节点)。
- 10 分钟消息间隔:FAQ 提醒“一次对话中智能体连续两次回复间隔限制 10 分钟”,长流程要用输出节点缩短间隔(见:低代码工作流常见问题)。
具体例子(可照抄)
- 输出变量:
stage:固定值"数据拉取"eta:固定值"约 20 秒"
- 输出内容:
正在{{stage}}中,请稍等({{eta}})…
用户看到的中间消息示例:
正在数据拉取中,请稍等(约 20 秒)…
5.4 大模型节点(LLM):把“输出格式”当成接口契约
你会用它做什么
- 文案生成/总结/分类/改写 Query
- 生成结构化 JSON,给后续节点做稳定消费(见:大模型节点)
示例:把用户自然语言改写成标准 Query(JSON 输出)
- 输出字段建议:
new_query(String)、reason(String) - 提示词建议:要求“只输出 JSON,字段必须齐全”
注意事项
- 字段名 + 描述非常关键:字段命名和描述能显著提升模型按结构输出的稳定性(见:大模型节点)。
- 技能(插件/工作流/知识库) vs 显式节点:
- LLM 配技能:模型自动决定何时调用、怎么填参(更灵活)
- 显式节点:你固定流程,稳定可控(见:大模型节点)
- 续写会增加耗时与 token:长文可用续写,但要注意超时与成本(见:大模型节点)。
- 流式输出开启后无法重试/跳异常分支(见:大模型节点)。
具体例子(可照抄)
- 输入变量:
query:引用开始节点的input
- 系统提示词(示例):
你是企业客服助手。请将用户问题改写为“可检索”的标准问题句,并输出严格 JSON。
- 用户提示词(示例):
原始问题:{{query}}只输出 JSON,字段为 new_query、reason,禁止输出多余文本。
- JSON 输出示例:
{
"new_query": "打印机离线无法连接应该如何排查?",
"reason": "去掉场景闲聊信息,保留可检索的故障现象与排查意图"
}
5.5 插件节点(Plugin):确定性“动手能力”,但要管住鉴权与限流
你会用它做什么
- 调用插件工具(本质是 API),完成“查/写/调用外部系统”(见:插件节点)
示例:批量查询天气(插件 + 批处理)
注意事项
- 输入/输出结构不可自定义:由插件工具定义决定(见:插件节点)。
- 用模拟集加速调试:试运行可不真实调用插件,直接喂“模拟输出”(见:插件节点)。
- OAuth 授权模式:
- 默认“单独授权”:每个用户都要授权,数据隔离
- “共享授权”:使用开发者账号授权,用户无需授权但风险更高(见:插件节点)
- 企业插件商店限制:企业可能禁用扣子商店插件,需要管理员放行(见:插件节点)。
具体例子(可照抄)
以“天气查询类插件”为例(字段以你选的插件工具定义为准):
- 开始节点输入:
cities = ["杭州","上海"] - 批处理体内插件节点入参:
city:引用批处理的item
- 结束节点输出(建议你自己统一成稳定结构,方便下游使用):
{
"results": [
{"city": "杭州", "ok": true, "data": {"weather": "晴", "temperature": 12}},
{"city": "上海", "ok": true, "data": {"weather": "多云", "temperature": 10}}
]
}
如果插件返回结构很复杂,推荐在插件后加一个“代码节点”把字段抽平/重命名,避免后续节点到处写深层路径。
5.6 代码节点(Code):最强“胶水”,但有 60 秒天花板
你会用它做什么
示例 1:把文本按换行拆成数组(用于循环/批处理)
async def main(args: Args) -> Output:
params = args.params
return {"lines": (params["input"] or "").split("\n")}
示例 2:拼装飞书多维表 add_records 需要的 Array
(官方 FAQ 示例同类:把 input 和 output 拼进 records 数组)(见:低代码工作流常见问题)
注意事项
- 函数限制:不支持写多个函数;必须
return一个对象(见:代码节点)。 - 超时:单请求 60s,上游大对象处理要“早过滤、少拷贝”(见:代码节点)。
- 依赖库受限:
- JS 仅内置
dayjs/lodash - Python 仅内置
requests_async/numpy(见:代码节点)
- JS 仅内置
- 入参大小:代码/插件节点入参上限 2MB(见:低代码工作流使用限制)。
具体例子(可照抄)
- 示例 1 输入:
input = "第一段\n第二段\n第三段" - 示例 1 输出:
{"lines": ["第一段", "第二段", "第三段"]}
- 示例 2(records 拼装)输入:
{"input": "怎么重置密码?", "output": "你可以在设置-账号安全里重置密码。"}
- 示例 2 输出(给数据库/表格节点用):
{
"records": [
{"fields": {"问题": "怎么重置密码?", "Bot回答": "你可以在设置-账号安全里重置密码。"}}
]
}
5.7 选择器节点(If/Else):分支要配“兜底”和“统一出口”
你会用它做什么
- if-else 分流:根据条件走不同分支(见:选择器节点)
示例:按 priority 分流
注意事项
- else 分支一定要有:用户输入不符合任何条件时,需要兜底路径。
- 分支输出要统一:不同分支下游要使用同一套字段时,推荐用“变量聚合节点”做统一出口(见:变量聚合节点)。
具体例子(可照抄)
- 输入:
priority = "P0"(来自开始节点或上游节点) - 选择器条件:
- 如果:
priority == "P0" - 否则:走常规分支
- 如果:
- 分支输出建议(让两条分支都产出同名字段):
- P0 分支:
action = "立即电话通知值班工程师" - 常规分支:
action = "进入排队处理,预计 2 小时内响应"
- P0 分支:
- 下游用法:变量聚合把两条分支的
action聚合成一个,再给结束节点输出。
5.8 意图识别节点(Intent):比“LLM+选择器”更高效的分类分流
官方定位:把用户意图分类后流转到不同分支(见:意图识别节点)。
示例:客服分流(售前/售后/其他)
注意事项
- 极速模式 vs 完整模式:
- 极速:最多 10 个意图,不支持系统提示词
- 完整:最多 50 个意图,可写系统提示词与示例,准确性更高(见:意图识别节点)
- 分类命中要连线:每个意图都必须接后续节点,否则命中后无路可走(官方提示)。
- 兜底策略必须配:未命中分类时走“其他”分支。
具体例子(可照抄)
- 意图配置(示例):
- 售前咨询
- 售后问题
- 转人工
- 用户输入示例:
"我买的会员怎么开发票?" - 节点输出示例(格式为节点固定输出,见官方说明):
{"classificationId": 2, "reason": "用户询问购买后开票,属于售后问题"}
5.9 问答节点(Question):主动补齐信息(但渠道支持要注意)
问答节点用于主动向用户提问,收集关键信息(见:问答节点)。
示例:留资(收集企业名/联系人/电话)
注意事项(非常关键)
- 渠道限制:
- 豆包渠道暂不支持问答节点
- Chat SDK 暂不支持问答节点的“卡片选项效果”(用户需复制选项文本)(见:问答节点)
- 等待时长:最多等待 24 小时,用户不回复则失败(见:问答节点)。
- 直接回答模式:如果设置“从回复中提取字段”为必填,用户答非所问会触发追问;注意设置最多回答次数(1~5)避免无限纠缠(见:问答节点)。
- 选项回答模式:一定要配兜底策略(用户不按选项回答时怎么走)。
具体例子(可照抄)
- 问答节点(直接回答)提问内容:
为了方便联系你,请回复:企业名称、联系人、手机号(缺一不可)。 - 开启“从回复中提取字段”:
company(String,必填)contact(String,必填)phone(String,必填)
- 用户回复示例:
北京XX科技,张三,13800000000 - 节点输出示例:
{
"USER_RESPONSE": "北京XX科技,张三,13800000000",
"company": "北京XX科技",
"contact": "张三",
"phone": "13800000000"
}
5.10 循环节点(Loop):严格串行的“for/while”,适合长文/问卷/轮询
循环节点支持数组循环/固定次数/无限循环(见:循环节点)。
示例:长文分段总结(数组循环 + 中间变量衔接上下文)
注意事项
- 不支持嵌套循环;循环体内不能再放循环节点(可通过“循环里调用子工作流”绕开)(见:循环节点)。
- 循环体内不允许批处理节点(见:循环节点)。
- 内置变量:
item/index仅循环体内可用(见:循环节点)。 - 无限循环必须能退出:要配合条件判断与“终止循环”节点,否则会一直跑到超时/上限(见:循环节点)。
具体例子(可照抄)
- 开始节点输入:
{
"paragraphs": ["第一段原文...", "第二段原文...", "第三段原文..."]
}
- 循环输出(汇总结果)示例:
{
"summaries": [
"第一段总结...",
"第二段总结...",
"第三段总结..."
]
}
5.11 批处理节点(Batch):并行吞吐,但别和“流式消息/流式插件”混用
批处理节点用于对数组元素并行处理(见:批处理节点)。
示例:批量视觉理解图片(官方示例同类)
注意事项
- 并行数量上限默认 10;总次数上限最大 200(见:批处理节点)。
- 不要并行跑流式插件/消息节点:同一时刻只允许一个流式插件或消息节点,否则输出会乱或不按预期(见:批处理节点)。
- 批处理体不能再套批处理/循环(见:批处理节点)。
具体例子(可照抄)
- 开始节点输入:
{
"images": [
"https://example.com/a.png",
"https://example.com/b.png"
],
"query": "识别图片里的主要内容"
}
- 结束节点输出示例(每张图一条结果):
{
"results": [
{"image": "https://example.com/a.png", "desc": "…"},
{"image": "https://example.com/b.png", "desc": "…"}
]
}
5.12 知识库检索节点(Knowledge Retrieve):RAG 的“可控入口”
官方输出为 outputList 数组(每条含 output 与 documentId),支持混合/语义/全文检索、查询改写、结果重排等(见:知识库检索节点)。
示例:SOP 问答(检索 + LLM 生成最终话术)
注意事项
- 策略选择:
- 混合:通用推荐
- 语义:跨语言/语义关联强
- 全文:专有名词/缩写/ID(见:知识库检索节点)
- 查询改写会增加一轮模型调用:更准但更耗 token、更慢(见:知识库检索节点)。
- 结果重排适合高精度场景:客服/技术答疑,但会额外成本与耗时(见:知识库检索节点)。
- 知识库检索节点 vs LLM 节点“添加知识库技能”:
具体例子(可照抄)
- Query(来自开始节点 input):
"怎么重置密码?" - 知识库检索节点输出(示例结构):
{
"outputList": [
{"output": "在【设置-账号安全】中点击【重置密码】…", "documentId": "doc_001"},
{"output": "如果无法收到验证码,请检查…", "documentId": "doc_014"}
]
}
下游 LLM 节点提示词可以写:请基于以下知识库切片回答:{{outputList}}
5.13 知识库写入节点(Knowledge Write):用户上传知识的唯一入口(异步)
用于向扣子/火山知识库写入内容,且是异步节点,无需等待上传完成(见:知识库写入节点)。
示例:让用户上传文档后,自动写入知识库
注意事项
- 单次只能上传 1 个文件:批量上传要配合循环/批处理多次执行(见:知识库写入节点)。
- 异步特性:写入后不代表“立刻可检索”;尤其精准解析更慢(见:知识库写入节点)。
- 火山知识库 QPS:写入/上传/检索各自有配额(例如写入文本 QPS 10)(见:知识库写入节点)。
具体例子(可照抄)
- 开始节点输入:
file(用户上传的pdf/docx/md等文件) - 知识库写入节点输出(示例结构):
{
"documentId": "doc_xxx",
"fileName": "员工手册.pdf",
"fileUrl": "https://.../employee_handbook.pdf"
}
因为是异步写入,你可以紧跟一个“输出节点”:
已收到文件《{{fileName}}》,正在解析并入库…
5.14 工作流节点(Workflow Node):把流程模块化(但版本要你手动控)
用于在一个工作流中调用另一个工作流,形成“主流程 + 子流程”的模块化结构(见:工作流节点)。
示例:主流程分流后调用不同子工作流
注意事项
- 子工作流升级不自动同步:父工作流不会自动更新到最新版本,需手动更新并回归后再发布(见:工作流节点)。
- 工作流节点也支持批处理模式:适合批量执行“一个子流程”(见:工作流节点)。
- 忽略异常:可让节点失败时不中断流程,但下游引用输出时会用“预设默认输出”,务必确保默认输出结构正确(见:工作流节点)。
具体例子(可照抄)
- 子工作流(normalize_contact):输入
raw_contact,输出 JSON:{name, phone} - 父工作流:先问答收集
raw_contact,再用工作流节点调用normalize_contact,最后把结构化结果写入数据库。
5.15 变量聚合节点(Variable Merge):把多分支输出收敛成“一个变量”
用于把多路分支的输出聚合成一个,返回“第一个非空值”,避免未执行分支输出为空导致下游报错(见:变量聚合节点)。
示例:选择器/意图识别分支后统一出口
注意事项
具体例子(可照抄)
- 分支A 输出:
answer="可以在设置里重置密码" - 分支B 输出:
answer=""(没执行或为空) - 变量聚合(Group1 聚合两个 answer)输出:
Group1="可以在设置里重置密码"
5.16 数据库(Database):轻量就用扣子库,企业规模上火山库(多用户模式)
数据库能力适合管理结构化数据(客户、订单、产品等),支持扣子数据库与火山 MySQL(见:数据库概述)。
示例:留资写库(问答 → SQL/数据库节点)
注意事项
- 单用户 vs 多用户模式:多用户模式读写更开放,更适合企业业务(见:数据库概述)。
- 扣子数据库免费,适合轻量;火山 MySQL 有成本但更适合企业规模(见:数据库概述)。
- 表/字段/行数限制:例如扣子表字段最多 20、建议最多 10 万行、表最大 500MB(见:数据库概述)。
具体例子(可照抄)
以“线索表 lead” 为例(字段:company、contact、phone、source、created_at):
- 上游问答节点提取出
company/contact/phone - SQL/数据库节点插入一行:
{
"company": "北京XX科技",
"contact": "张三",
"phone": "13800000000",
"source": "官网咨询"
}
如果你采用“多用户模式”,可以在业务逻辑里决定:用户是否只能读写自己的线索,还是允许团队成员查询全部线索(见:数据库概述)。
5.17 创建会话节点(Create Conversation,仅应用可用)
用于在应用中创建一个空会话,并输出 conversationId(见:创建会话节点)。
注意事项
具体例子(可照抄)
- 输入:
conversationName = "order_3187_followup" - 输出示例(节点固定输出字段):
{
"isSuccess": true,
"isExisted": false,
"conversationId": "7444890359211262037"
}
六、特性与约束(决定能不能上线)
6.1 超时:不是“偶发”,是“设计约束”
官方给了节点级与整体级超时表(见:使用限制)。关键结论:
- 同步整体默认 10 分钟;异步整体可到 24 小时
- 模型/插件类默认 3 分钟(可到 10 分钟),代码节点 60 秒
官方超时表(摘自《低代码工作流使用限制》):
| 场景 | 模型节点、插件节点、语音播客 | HTTP 节点 | 视频生成 | 图像生成 | 数据库/意图识别/代码/画板/视频抽帧 | 其他节点 | 工作流整体 |
|---|---|---|---|---|---|---|---|
| 默认 | 3 分钟 | 2 分钟 | 6 分钟 | 10 分钟 | 1 分钟 | 无单节点限制 | 同步 10 分钟 / 异步 24 小时 |
| 最大值 | 10 分钟 | 10 分钟 | 10 分钟 | 10 分钟 | 1 分钟 | 无单节点限制 | - |
说明:2025 年 4 月 24 日前创建的大模型节点默认 10 分钟;可通过节点「异常处理配置」调整部分节点超时;端插件类型插件无超时限制。未开异步时建议单次执行控制在 5 分钟内;一次对话中智能体连续两次回复间隔限制 10 分钟。
6.2 QPS:企业必须做容量规划
官方限制(见:使用限制):
- 单节点 QPS:数据库相关 400,其它节点 3000
- 单工作流 QPS:按套餐(例如个人免费 200,多个付费/企业版为 500)
结论:不要把“外部系统限流”当成 Coze 的限流。企业落地必须做:缓存、降级、重试与熔断。
6.3 规模上限:节点数/请求体/入参大小
同样来自官方限制(见:使用限制):
| 项 | 上限(要记住的) |
|---|---|
| 单工作流节点数 | 最多 1000;单次运行最多执行 1000 次(含循环/子工作流展开) |
| 代码节点数量 | 每个工作流最多 50 |
| 请求大小 | 20MB(含输入与消息历史等) |
| 节点输入/输出 | 10MB;代码/插件入参 2MB(超出会 Invalid Request: input size exceeded 或截断) |
| 试运行 | 按每次试运行消耗的模型 token 扣减积分 |
| 图像节点并发 | 主账号及子账号共享图像插件并发限制(见插件费用文档) |
| 用户变量长度 | 最大约 6 万字符,出于性能不建议存过长内容 |
七、企业应用:怎么把“工作流”变成“流程资产”
7.1 企业常见落地场景(可复制)
| 场景 | 典型工作流骨架 | 业务价值 |
|---|---|---|
| 智能客服(售前/售后) | 知识库检索 → LLM 生成 → 插件查订单 → 输出节点安抚/卡片 | 提升首响、降低人工工单 |
| 运营内容生产 | 素材输入 → LLM 生成多版本 → 批处理出图/审图 → 输出卡片列表 | 提升产能、减少重复劳动 |
| 报表/周报自动化 | 数据源插件/DB → 代码清洗 → LLM 总结 → Markdown 输出 | 缩短分析链路、标准化口径 |
| 业务流程自动化 | 触发器/输入 → 选择器分支 → 插件写表/发消息 → 结束节点回执 | 降低流程摩擦、可审计 |
7.2 企业治理:工作流要“像服务一样管理”
官方已经提供“资源引用”视图(用来查看工作流引用了哪些子工作流/插件/数据库/知识库,并可查看版本)(见:使用低代码工作流)。
你可以把它升级为企业治理标准:
| 维度 | 建议做法 | 对应风险 |
|---|---|---|
| 命名规范 | 业务域-能力-版本 |
模型难以正确调用 |
| 版本策略 | 关键流程必须锁版本;升级要回归 | “版本冲突/线上漂移” |
| 观测 | 消息日志看 token/节点用量(FAQ 有入口说明) | 成本失控、难定位 |
| 异常策略 | 关键节点开启重试/异常分支 | 外部系统不稳定 |
八、节点对比:企业最常问的 6 个“怎么选”
8.1 LLM 节点“配置技能” vs 直接编排插件节点
官方差异点(见:大模型节点):
- LLM 配技能:模型自动判断何时调用、怎么填参(更灵活,但不确定性更高)
- 显式插件节点:你人工固定流程(更稳定、可控)
**建议:**企业关键流程优先“显式插件节点 + 代码校验”,非关键可用“LLM 配技能”提升开发效率。
8.2 循环 vs 批处理
结论一句话:要顺序与上下文 → 循环;要吞吐与并行 → 批处理(见:循环节点、批处理节点)。
8.3 输出节点什么时候要加?
当用户等待超过体感阈值,或流程存在“长耗时节点”时,加输出节点(见:输出节点 + FAQ:回复间隔 10 分钟限制)。
8.4 “找不到变量可引用”怎么办?
官方给了排查:没连线/上游没定义/类型不匹配(见:工作流 FAQ)。
8.5 节点选型矩阵(逐个节点对比:使用场景 & 如何选择)
这张表按“企业落地”来写:你拿到需求时先看目标,再选节点。
推荐原则:能确定性就确定性(插件/数据库/代码)→ 需要语言理解才用 LLM → 需要交互才用问答/对话流能力。
| 节点 | 典型使用场景(你在企业里会遇到的) | 优先选择它的信号 | 不适合/慎用点 | 常见替代/组合 |
|---|---|---|---|---|
| 开始节点 | 定义入参(工单、报表参数、查询条件) | 需要“结构化输入契约” | 参数名/描述写不好会导致模型填参不准 | 开始 + 问答(缺参再追问) |
| 结束节点 | 最终输出(对话/接口返回/子工作流返回) | 需要稳定的最终结果出口 | JSON 多字段不支持流式;返回文本要防“空输出” | 结束(变量) + 上游输出节点(进度) |
| 输出节点 | 长流程进度、安抚语、阶段性结果、卡片提示 | 用户需要即时反馈;流程可能>几十秒 | 卡片非流式;流式需在 LLM 后;批处理并发流式易乱 | 输出节点 + 结束节点;输出节点 + 卡片 |
| LLM 节点 | 文案/总结/分类/结构化 JSON 生成 | 任务需要语言理解与生成 | 不确定性;长文续写会增耗时与 token | LLM + 知识库检索;LLM + 插件(技能/显式) |
| 插件节点 | 调外部系统(天气/工单/飞书表格/搜索) | 有明确 API/工具可用,追求确定性 | 限流、鉴权、外部不稳定;入参大小限制 | 插件 + 代码清洗;插件 + 批处理/循环 |
| 代码节点 | 格式转换、字段抽取、校验、拼装 records | 需要“确定性数据处理/胶水逻辑” | 60s 超时;依赖库受限;入参 2MB | 代码 + LLM(先结构化再表达) |
| 选择器节点 | if-else 分支(按优先级/状态/字段分流) | 分支条件可用规则表达、确定 | 分支输出不统一会让下游很难用 | 选择器 + 变量聚合;选择器 + 工作流节点 |
| 意图识别节点 | 按“用户意图”分流(售前/售后/投诉) | 需要把自然语言快速归类到分支 | 分类容易混淆需优化;要配兜底分支 | 意图识别 + 知识库检索;意图识别 + 转人工 |
| 问答节点 | 主动收集缺失信息(留资/日期/账号) | 必须用户回答才能继续 | 渠道限制(豆包不支持);等待 24h;要设置追问次数 | 问答 + 数据库写入;问答 + 工作流节点 |
| 循环节点 | 串行遍历(长文分段、问卷逐题、轮询) | 每轮依赖上一轮结果/需要上下文衔接 | 不支持嵌套循环;循环体不能放批处理 | 循环 + 中间变量;循环 + 子工作流 |
| 批处理节点 | 并行批量处理(多图分析、批量插件调用) | 任务之间相互独立、追求吞吐 | 并行上限与总次数上限;不要并行流式插件/消息 | 批处理 + 插件/LLM;批处理 + 结果汇总 |
| 知识库检索节点 | RAG 检索(SOP/FAQ/手册问答) | 需要“可控召回”并减少幻觉 | 查询改写/重排会增加成本与耗时 | 检索 + LLM;检索 + 意图识别分流 |
| 知识库写入节点 | 用户上传文档入库、动态更新知识 | 需要把“用户输入内容”变成知识资产 | 异步写入,非立刻可检索;单次 1 文件 | 写入 + 输出节点提示;写入 + 循环/批处理 |
| 工作流节点(嵌套) | 复用标准子流程(售前/售后子流程) | 需要模块化、复用、分工协作 | 子工作流升级不自动同步;要控版本一致 | 工作流节点 + 版本治理;工作流节点 + 批处理 |
| 变量聚合节点 | 多分支统一出口(选其一输出) | 分支互斥执行,下游需要统一变量名 | 分组内类型必须一致;顺序影响优先级 | 变量聚合 + 结束节点;变量聚合 + LLM |
| 数据库(相关节点/SQL) | 结构化数据存取(线索、订单、配置) | 需要可查询、可统计、可审计的数据 | 表结构/权限模式要设计;规模与字段限制 | 数据库 + 问答留资;数据库 + LLM 解读 |
| 创建会话节点(应用内) | 应用中创建会话,供对话流/消息管理使用 | 需要显式管理会话生命周期 | 仅应用可用;会话名需唯一 | 创建会话 + 对话流;会话 + 查询消息/清理历史 |
8.6 同类节点“怎么选”(最常用的几组对比)
8.6.1 LLM vs 插件 vs 代码(处理同一问题的三种方式)
| 你要解决的问题 | 优先选 | 原因 | 常见组合 |
|---|---|---|---|
| 查数据/写数据/做动作(确定性) | 插件 / 数据库 | 可控、可回放、可审计 | 插件→代码→LLM(解释) |
| 结构化清洗/格式转换 | 代码 | 结果稳定、可测试 | 插件→代码(抽平字段) |
| 文案/总结/推理/生成结构 | LLM | 语言能力与推理能力 | 检索→LLM;代码→LLM |
8.6.2 选择器 vs 意图识别 vs 问答(分流与交互怎么选)
| 需求 | 选哪个 | 关键判断 |
|---|---|---|
| 分支条件是确定规则(字段/阈值) | 选择器 | 条件可表达为 if-else |
| 分支条件来自自然语言意图 | 意图识别 | 需要模型把话归类成意图 |
| 必须补齐用户信息才能继续 | 问答 | 需要等待用户回答(要注意渠道限制) |
8.6.3 循环 vs 批处理(串行 vs 并行)
| 需求 | 选哪个 | 关键判断 |
|---|---|---|
| 每轮依赖上一轮/要上下文衔接 | 循环 | 串行、可用中间变量 |
| 每项任务相互独立/追求吞吐 | 批处理 | 并行、批量执行更快 |
8.6.4 输出节点 vs 结束节点(什么时候用“中间输出”)
| 你要做什么 | 选哪个 | 备注 |
|---|---|---|
| 最终一次性返回结果 | 结束节点 | 可返回变量或文本 |
| 过程里给用户“正在处理” | 输出节点 | 长流程必备;可绑卡片 |
8.6.5 知识库检索节点 vs LLM 节点配置知识库技能(RAG 入口怎么选)
| 方式 | 优点 | 缺点 | 适合场景 |
|---|---|---|---|
| 知识库检索节点(显式) | 100% 召回、可控、可观测 | 需要你设计检索 Query | 客服/合规/高准确率场景 |
| LLM 节点加知识库技能(隐式) | 更灵活,减少节点编排 | 模型可能不调用或检索偏 | 内容创作/探索式问答 |
8.6.6 数据库 vs 知识库(“存数据”还是“存知识”)
| 你要存什么 | 选哪个 | 典型例子 |
|---|---|---|
| 结构化、要统计/筛选/更新 | 数据库 | 线索表、订单表、配置表 |
| 非结构化文档、要语义检索 | 知识库 | SOP、手册、FAQ、制度 |
8.7 一句话决策树(从需求倒推节点)
8.8 核心概念示例一览(各举一例)
以下按「工作流的作用、节点输入输出、大模型节点、代码节点、知识库节点、选择器节点、数据库节点、插件节点、工作流组合」各举一个可落地的例子,便于对照理解。
| 概念 | 示例 |
|---|---|
| 工作流的作用 | 客服工单路由:用户说「我要退款」,工作流先调插件查订单 → 选择器按订单状态分支(未发货/已发货)→ 分别走「直接退款」或「填退货单」子流程,最后结束节点返回操作结果。把「接系统、跑规则、回写数据」做成一条可审计的流水线。 |
| 节点的输入与输出 | 开始节点输入 user_query(文本)、知识库检索节点输出 outputList(数组),代码节点入参引用 outputList、return 出 summary 字符串,结束节点返回 { "answer": "{{summary}}" }。数据从上游节点通过变量名被下游引用,形成明确的输入输出链。 |
| 大模型节点(将自然语言变成参数) | 用户说「帮我约下周三下午 3 点和王经理开会」。大模型节点配置结构化输出:{ "title": "string", "start_time": "string", "attendee": "string" },模型从自然语言中抽取为 {"title":"与王经理开会","start_time":"下周三15:00","attendee":"王经理"},下游插件节点用该 JSON 调用日历 API 创建日程。 |
| 代码节点 | 插件「查订单列表」返回{ "orders": [ { "id": 1, "amount": 99.5, "created_at": "2024-01-15T10:00:00Z" } ] }。代码节点入参接 orders,写一段 Python:取前 5 条、把 created_at 转成「YYYY-MM-DD」、算出 total_amount,return { "list": [...], "total_amount": 123.4 },供下游 LLM 或结束节点使用。 |
| 知识库节点 | 上传《售后政策.pdf》到扣子知识库。工作流中知识库检索节点:检索策略选「混合」、Query 用开始节点的 user_question、开启查询改写。输出 outputList 传给大模型节点,提示词写「仅根据以下内容回答:{{outputList}}」,实现「先检索、再生成」的 RAG,减少幻觉。 |
| 选择器节点 | 开始节点传入priority(P0/P1/P2)。选择器配置:条件1 priority == "P0" → 走「插件:创建加急工单」;条件2 priority == "P1" → 走「插件:创建普通工单」;默认 → 走「输出节点:请填写优先级」。下游用变量聚合节点收拢各分支的 ticket_id,再统一进结束节点。 |
| 数据库节点 | 留资场景:问答节点收集到name、phone、company。数据库节点选「插入」、表选扣子库的 leads,列映射为 name <- name、phone <- phone、company <- company。执行后该行写入表,结束节点返回「已提交,我们会尽快联系您」。 |
| 插件节点 | 用「飞书多维表格」插件:插件节点选「添加记录」、入参app_token/table_id 来自变量,records 为代码节点拼好的数组(格式满足飞书 API)。执行后数据写入表格;若限流或失败可接选择器走「重试」或「输出节点提示用户稍后再试」。 |
| 工作流组合 | 主工作流:意图识别(售前/售后)→ 分支后各接一个工作流节点,分别调用子工作流「售前话术与报价」「售后工单与换货」。子工作流内再各自用知识库检索 + LLM + 插件。主流程只负责分流与调用,子流程负责具体逻辑,便于分工与复用。 |
综合示例:从网络下载图片(串联上述所有节点)
下面用一个从网络下载图片并落库记录的完整流程,把「工作流的作用、节点输入输出、大模型节点、代码节点、知识库节点、选择器节点、数据库节点、插件节点、工作流组合」串在一起,便于对照理解。
场景:用户说「帮我下载这张图:https://example.com/photo.png」或「搜一张猫的图片并下载」,Bot 解析意图 → 按规范校验 → 拉取图片 → 落库 → 返回结果(或文件)。
| 环节 | 用到的节点 | 在本例中的具体用法 |
|---|---|---|
| 工作流的作用 | 整条流水线 | 把「理解用户话 → 查规范 → 调网络拉图 → 处理二进制 → 写库 → 回复」做成一条可审计、可复用的流程,而不是单点脚本。 |
| 节点输入与输出 | 各节点之间 | 开始节点出user_input → 大模型节点出 parsed → 选择器按 parsed.action 分支 → 插件节点出 http_response → 代码节点入参 http_response、出 image_info → 数据库节点入参 image_info 等,结束节点返回 result。上游输出变量名在下游配置里引用,形成清晰数据链。 |
| 大模型节点(自然语言变参数) | 大模型节点 | 用户输入user_input。大模型节点配置结构化输出,例如:`{ “action”: "url |
| 选择器节点 | 选择器节点 | 根据parsed.action 分支:action == "url" 走「直接下载该 URL」分支(调 HTTP 插件);action == "search" 走「先搜图再下载」分支(可调搜索类插件拿 URL,再调子工作流或同一流程内 HTTP 插件下载)。默认分支可走「输出节点:请提供图片链接或描述」。 |
| 插件节点 | HTTP 请求 / 搜索类插件 | URL 分支:用「HTTP 请求」插件 GET parsed.image_url,得到图片二进制或 base64。搜索分支:若有「图片搜索」类插件,入参 parsed.search_keyword,拿到第一个结果 URL,再交给下载逻辑(同一插件二次请求或子工作流)。插件输出作为代码节点的输入。 |
| 代码节点 | 代码节点 | 入参:插件返回的http_response(如 body、status、headers)。代码里校验 status、Content-Type 是否为图片、大小是否超限;将 body 转为 base64 或生成临时文件 ID,return 例如 { "image_base64": "...", "content_type": "image/png", "size": 12345, "url": "..." }。下游数据库节点存元数据,结束节点或输出节点可返回该 base64/文件链接。 |
| 知识库节点 | 知识库检索节点 | 知识库里放《图片下载规范》(允许的域名、禁止的域名、单张大小上限、格式要求等)。检索 Query 用parsed.image_url 或「下载规范」,得到 outputList。大模型节点或代码节点根据 outputList 判断:若不允许则不走下载、直接结束并提示「该链接不符合下载规范」;允许则继续。实现「先查规范、再动手」的合规控制。 |
| 数据库节点 | 数据库节点 | 扣子库建表如download_log(user_id, image_url, downloaded_at, file_size, content_type)。代码节点输出 image_info 后,数据库节点选「插入」,列映射 image_url、file_size、content_type 等来自 image_info,downloaded_at 用当前时间。便于审计、去重、统计。 |
| 工作流组合 | 工作流节点 | 主工作流:开始 → 大模型解析 → 知识库检索规范 → 选择器(url / search)→ 各分支内调子工作流「单次下载与校验」(入参:url;内部:HTTP 插件 → 代码节点处理 → 返回 image_info)。主流程再接数据库节点写入、结束节点返回「已下载并记录」或文件信息。子工作流可被「批量下载多张图」的循环/批处理重复调用,实现复用。 |
流程简图(Mermaid):
这样,从网络下载图片这一件事,就用到了:工作流整体作用、节点间输入输出、大模型节点(自然语言变参数)、选择器节点、插件节点、代码节点、知识库节点、数据库节点、工作流组合(主流程 + 子工作流)。
九、一套可直接抄的企业模板:RAG + 工具 + 进度输出
关键配置建议:
- 知识库检索:开启查询改写;高精度场景开重排(见:知识库检索节点)
- 插件节点:用模拟集加速调试;必要时设置重试/异常分支(见:插件节点)
- 输出节点:长流程先输出“正在处理”,最终再输出结果(见:输出节点)
十、结语:工作流的“终局价值”
工作流不是“把节点连起来”那么简单,它的终局价值是:
- 把 AI 能力产品化(可复用、可测试、可回滚)
- 把流程资产化(可治理、可审计、可观测)
- 把交付工业化(从 PoC 到生产的路径更短)
当你用工作流把“数据源、规则、模型、输出体验”串成一条链,你做的就不是 AI Demo,而是企业级能力模块。
附:常见问题与排查(摘自《低代码工作流常见问题》)
以下要点来自官方 FAQ,便于快速定位问题。
| 问题 | 要点/处理 |
|---|---|
| 工作流数量限制 | 智能体无数量限制;单应用最多 100 个工作流、100 个对话流;单工作流最多 1000 节点、单次运行最多执行 1000 次。 |
| Array 类型参数 | 飞书多维表格 add_records 等要求 Array:建议引用前置节点输出(代码等节点支持 Array 输出);多参数拼 Array 用代码节点,例如records: [{"fields":{"问题":params["input"],"Bot回答":params["output"]}}]。 |
| Array 固定值 | 固定值会按 String 写入。Array 固定值需在节点前加代码节点转为 Array 再引用,否则易报param[records] should be array。 |
| 引用数组中的对象 | 结束节点、输出节点、大模型节点等支持{{ 联想引用当前导入参数及数组/对象;可引用如 {{xxx[0]}} 取第一个元素。 |
| 未按预期调用插件/工作流 | 在「人设与回复逻辑」里用自然语言明确在何种场景下调用哪个插件/工作流;优化自建插件或工作流的名称与简介,便于模型识别。 |
| 连续两次回复间隔 10 分钟 | 一次对话中间隔超 10 分钟会判超时并停止。建议:耗时环节加输出节点、为输出/结束节点开流式输出,缩短消息间隔。 |
| 节点中有不合法的内容 | 多为某节点配置含敏感词被拦截。通过试运行逐个节点排查。 |
| 运行超 10 分钟 | 设为异步运行,超时延至 24 小时,先返回预设回复,运行完毕后再做最终回复。 |
| 恢复历史版本 | 仅开启多人协作的工作流支持查看与恢复历史版本(见「管理历史版本」文档)。 |
| 设置参数时“暂无数据” | 工作流节点未连上游 → 从左侧连线到其他节点;上游未定义该参数 → 在上游设置或本节点设固定值;类型不匹配 → 上游需有同类型输出(如 Array)。 |
| 版本号冲突 | 报错“工作流的版本号冲突: xxx”:同一子工作流被多处引用时须版本一致。子工作流发新版本后,须在父工作流中把每一处引用都升级到同一最新版本;带版本号与不带版本号节点混用也会冲突,可新增同款节点触发版本更新后删掉新增节点。 |
| 飞书多维表格授权 | 无法规避飞书授权,平台要求用户完成授权才能写入。 |
| 发布报错“插件调用报错” | 多为指定了已存在的版本号,更换版本号后重新发布。 |
| 从数组输出提取字符串 | 插件输出 Array 的 URL 而下游要 String:单元素可用文本处理节点{{String1[0]}};多元素或取最后一个用代码节点,如 params.input[params.input.length - 1]。 |
| 查看 token 与调用记录 | 消息日志(空间配置 > 发布管理 > 消息日志)可看每次调用的 token;单条消息的调用树里点节点可看该节点 usage。试运行在调试区选「积分」可看单次消耗。工作流调用记录:发布管理 > 工作流 > 对应工作流 > 日志。 |
排查思路简图:
工作流测试
新建工作流
添加结点
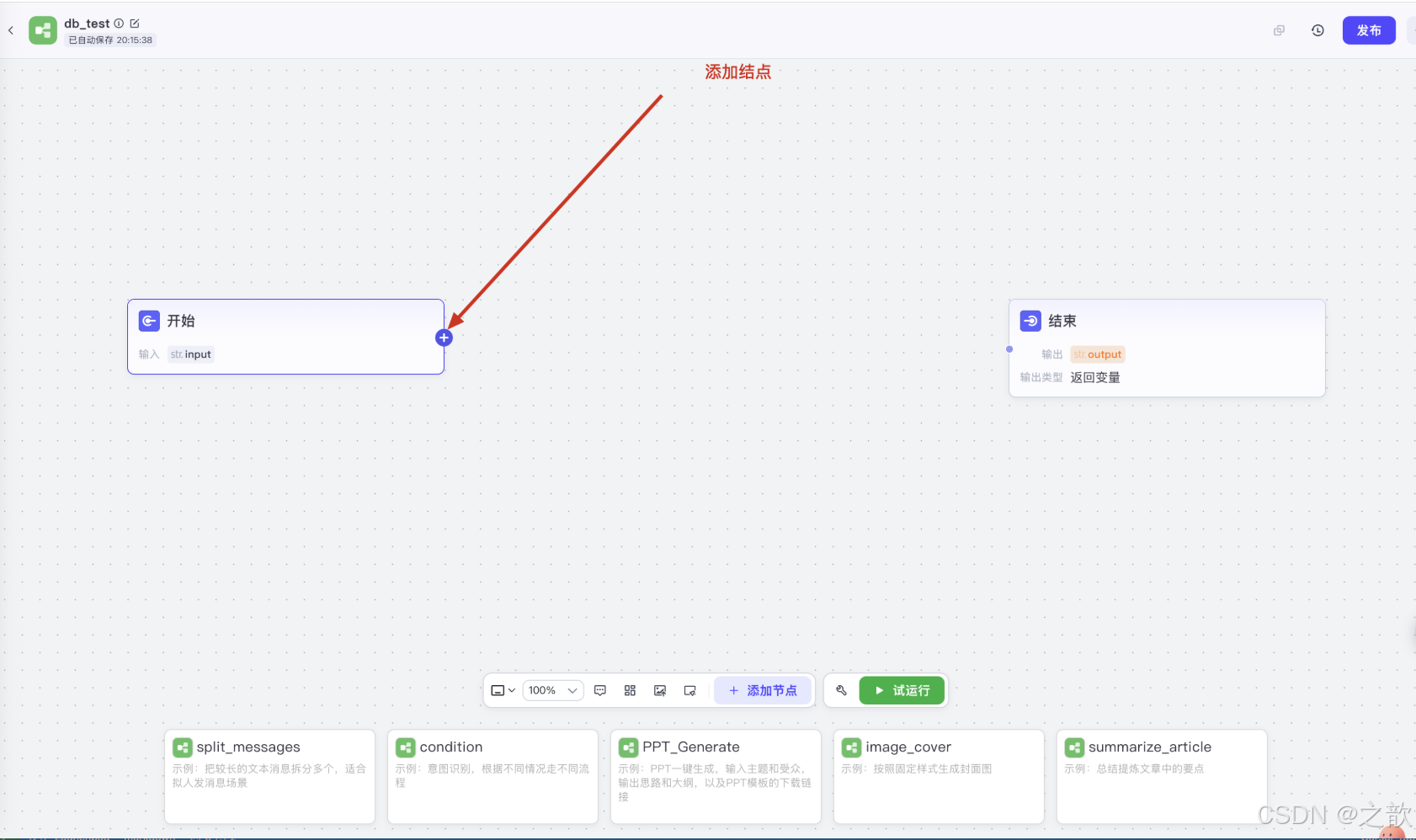
添加图片生成节点
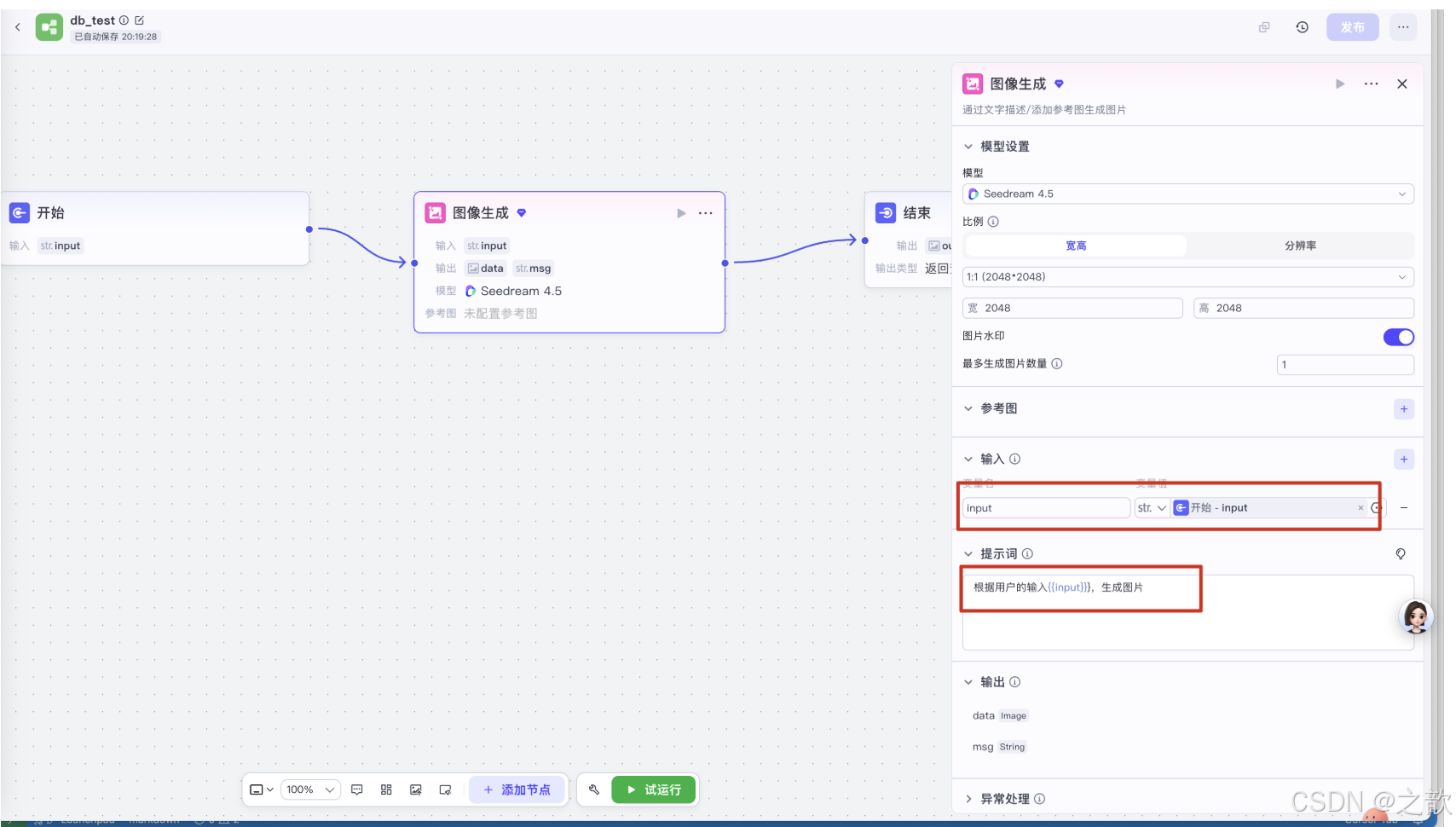
选择输出的内容
测运行
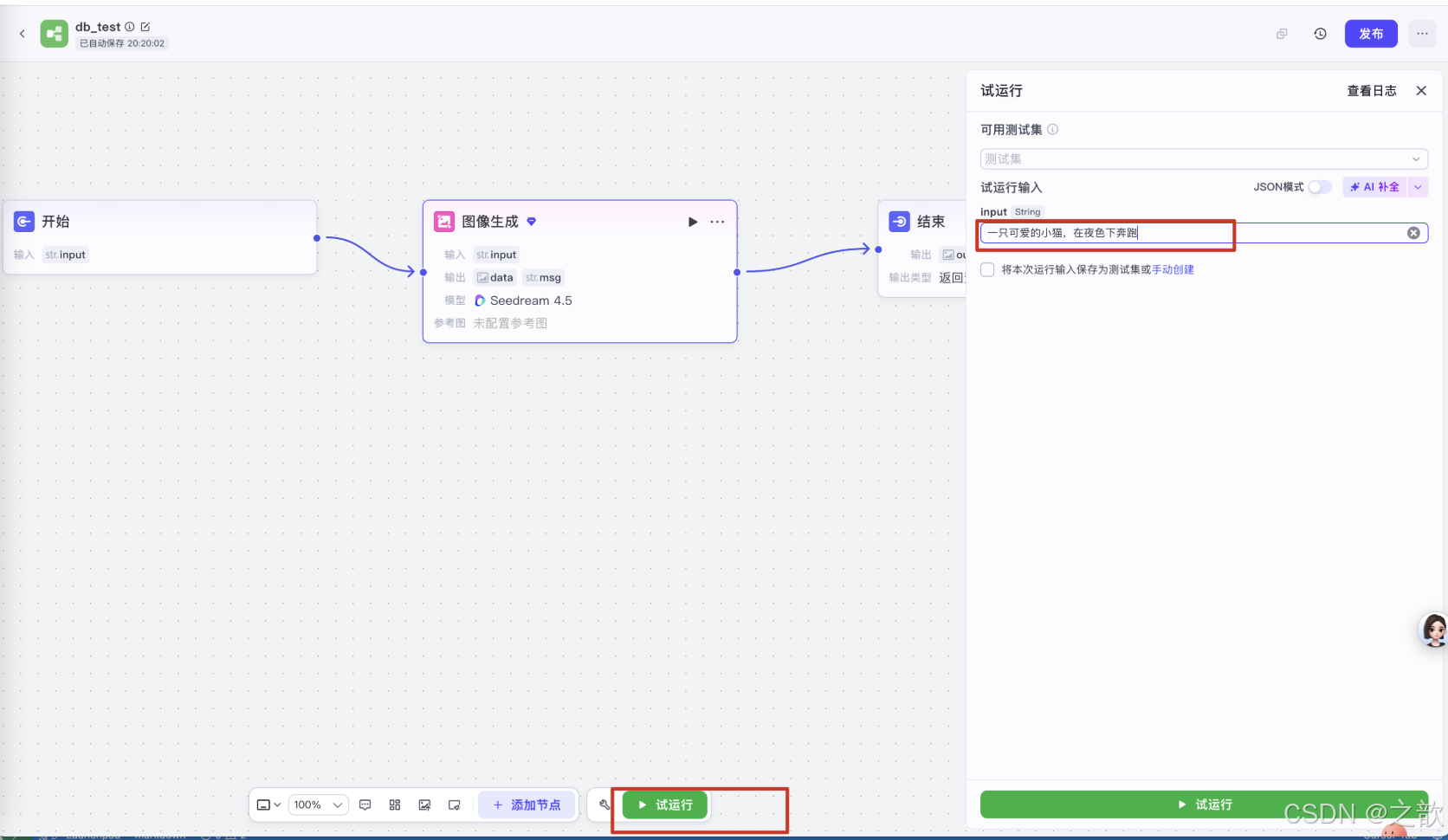
试运行结果
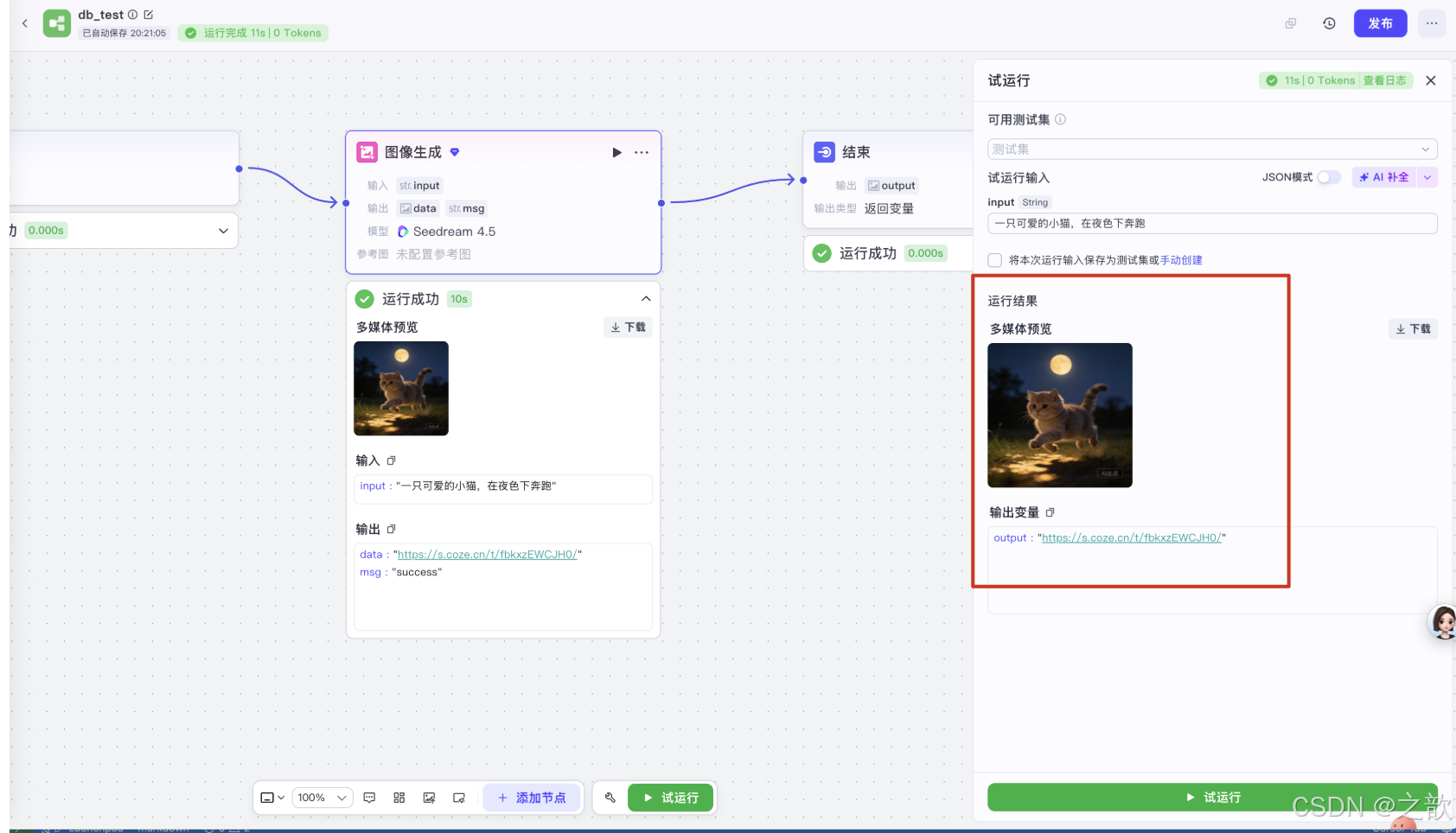
我也只是抛砖引玉 , 工作流的下一个节点有太多的好用的东西 ,自己去探索 。
参考链接(本文引用的官方文档)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 12
12 0
0- 0



 已为社区贡献38条内容
已为社区贡献38条内容

所有评论(0)