2.3 大模型推理参数的介绍
大模型推理常用的几个参数,工作原理
一、概述
1. 什么是推理(Inference)?
- 在模型权重固定的前提下,根据输入(即 prompt)生成输出。
- 与训练/微调不同:推理不改变模型参数。
- 可通过两种方式优化输出效果:
- 优化提示词(Prompt Engineering)
- 调整推理参数(本节重点)
2. 大模型本质是概率分布
- 大语言模型(LLM)每次推理时,会基于当前上下文预测下一个 token 的概率分布。
- 从该分布中按一定策略采样出下一个 token,不断循环,直到触发结束条件。
- 数学表示:(其中 ∣V∣是词表大小。)
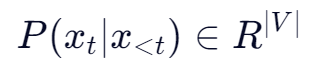
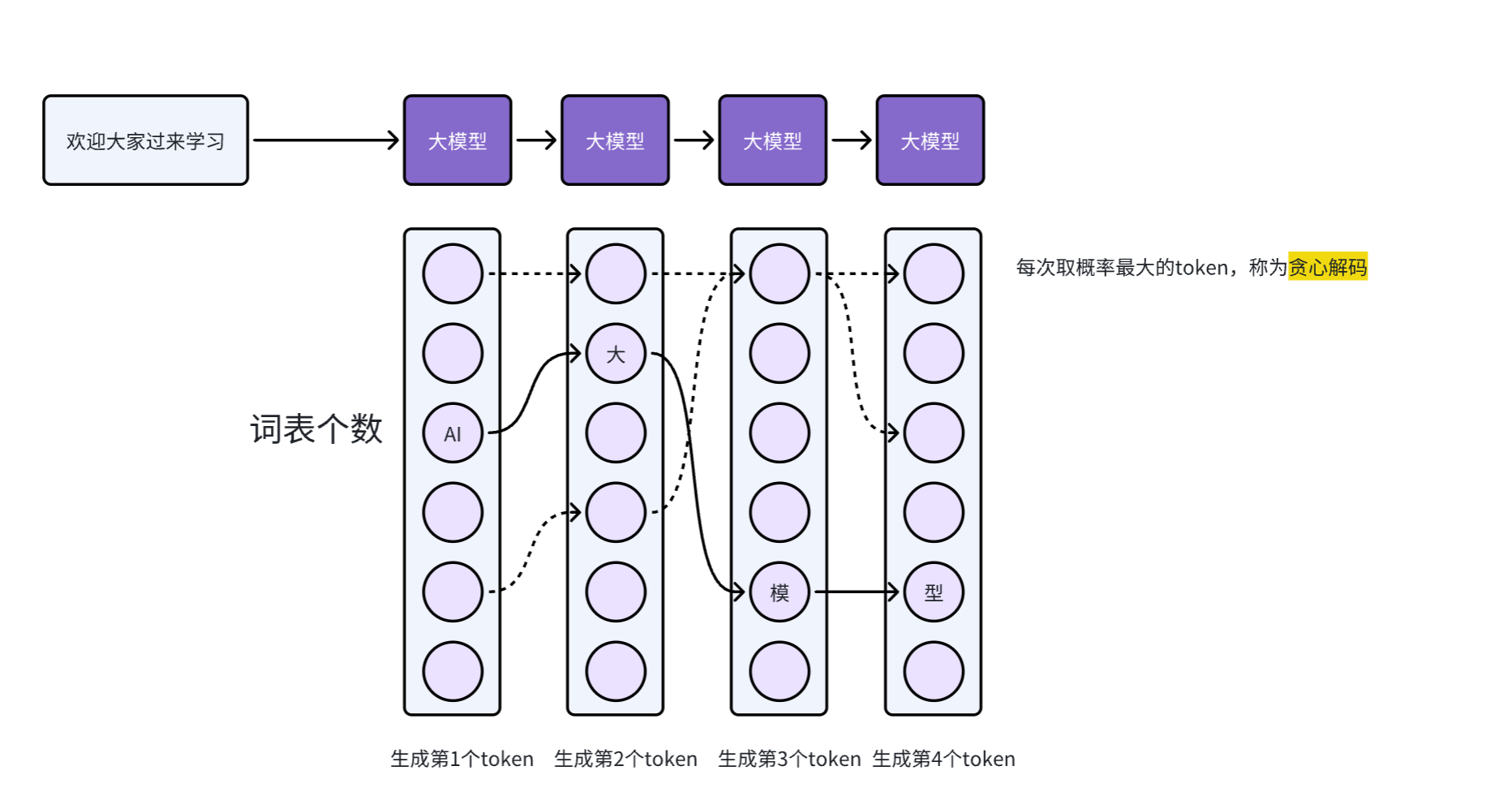
二、推理过程(解码过程)
整体流程:Prompt → 模型 → 概率分布 → 采样策略 → 下一个 token → 拼接 → 循环 → 结束
OpenAI API 中常用推理参数包括:
| 参数 | 说明 |
|---|---|
temperature |
控制输出随机性 |
top_p |
核采样(Nucleus Sampling)阈值 |
max_tokens |
最大生成长度 |
frequency_penalty |
词频惩罚 |
presence_penalty |
出现惩罚 |
n |
生成多个候选回答 |
stream |
是否流式输出 |


三、核心推理参数详解
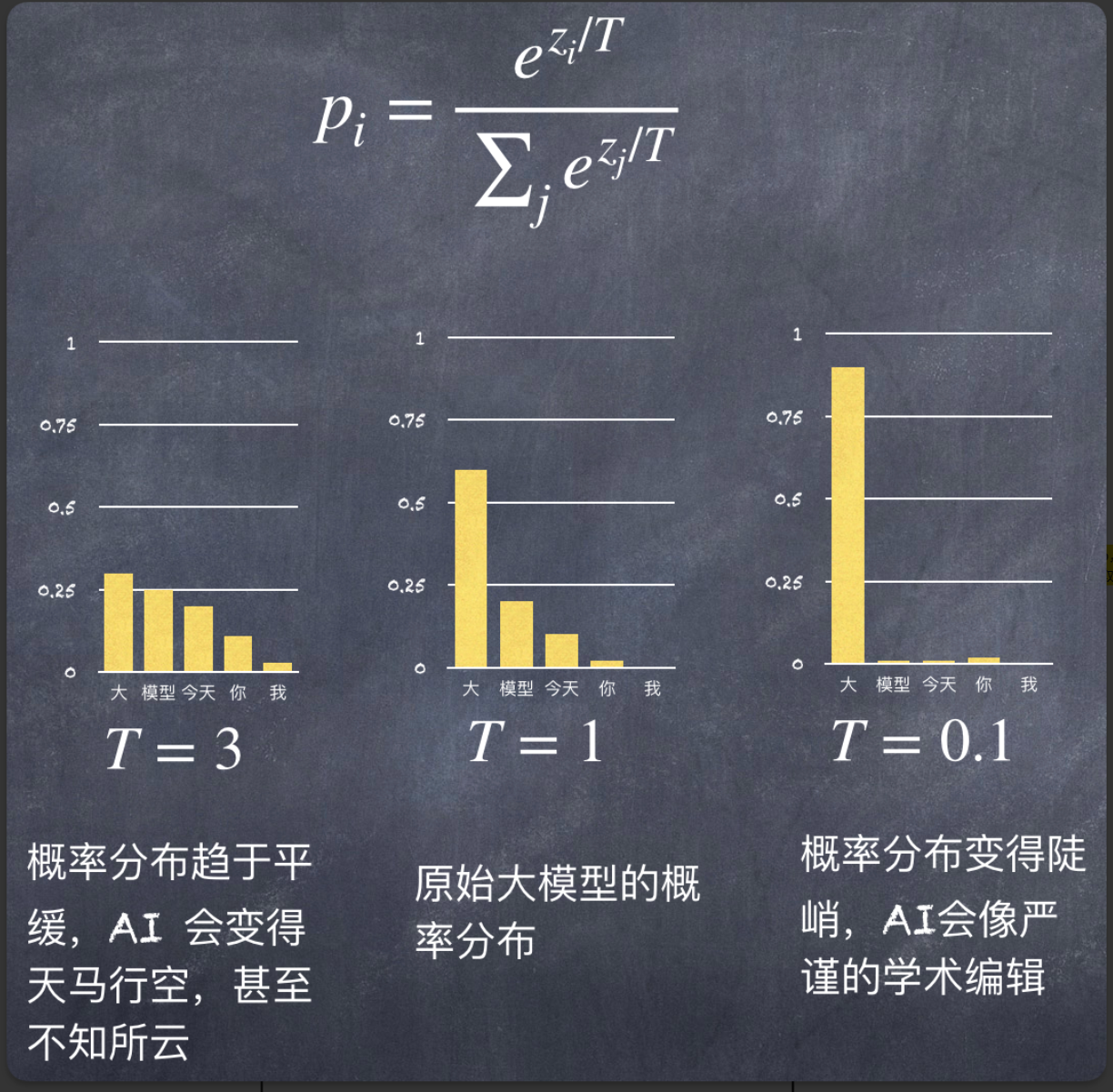
1. Temperature(温度)
- 作用:调节 logits 后再做 softmax,影响概率分布的“陡峭”程度。
- 效果:
- T < 1:分布更集中 → 输出更确定、保守
- T > 1:分布更平缓 → 输出更多样、可能“胡言乱语”
- 典型值:0.7 ~ 1.2
2. Top-p(核采样)
- 原理:对概率降序排序,取最小集合使得累计概率 ≥ p,从中随机采样。
- 优点:动态调整候选集大小,比固定 top-k 更灵活。
- 典型值:0.85 ~ 0.95(常与 temperature 配合使用)
3. Max Tokens
- 限制生成内容的最大 token 数。
- 注意:受模型最大上下文长度限制(如 32K、128K)。
- 实际可用长度 =
max_context_length(最大上下文长度) - prompt_tokens(提示词数)
4. Frequency Penalty(词频惩罚)
- 对已出现 token 的频率进行线性惩罚。
- 公式(简化):
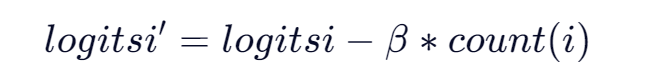
Token i 出现的次数为count(i),词频的惩罚系数为β
- 作用:减少重复词,提升多样性。
- 范围:通常 0.0 ~ 2.0
5. Presence Penalty(出现惩罚)
- 只要 token 出现过一次,就施加固定惩罚。(第二次就惩罚)
- 公式(简化):
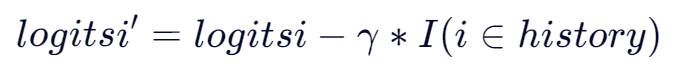
Token i 在已生成的文本中是否出现过,如果出现过记为1,否则为0,用i来表示,
- 作用:鼓励引入新词,避免话题重复。
- 与 frequency penalty 区别:不看次数,只看是否出现。
6. Beam Search(集束搜索)
- 思想:保留 n 条当前最优路径(而非只选 1 个 token)。
- 优点:生成质量更高(更连贯、准确)
- 缺点:计算开销大,缺乏创造性
- 注意:OpenAI 的
n参数 ≠ beam search(实际是并行独立采样)
四、代码示例
import os
from openai import OpenAI
from dotenv import load_dotenv
load_dotenv()
client = OpenAI(
base_url=os.getenv("base_url"),
api_key=os.getenv("API_KEY"))
chunks = client.chat.completions.create(
model="qwen-flash",
messages=[{"role": "user", "content": "如何学习大模型?"}],
stream=False,
n=3, # 生成 3 个独立回答
temperature=1.9, # 高温 → 更随机
top_p=0.5, # 限制采样范围
max_tokens=100,
frequency_penalty=1.2, # 惩罚高频词
presence_penalty=0.9 # 惩罚已出现词
)
answers = []
# for chunk in chunks:
# print(chunk)
# print(chunk.choices[0].delta.content, end="")
# # print(chunk.choices[0].index) # index 与n的对应关系
print(chunks.choices[0].message.content)
print("-------------------" * 5)
print(chunks.choices[1].message.content)
print("-------------------" * 5)
print(chunks.choices[2].message.content)
"""
学习大模型(Large Language Models, LLMs)是一个系统性、多阶段的过程,
-----------------------------------------------------------------------------------------------
学习大模型(Large Language Models, LLMs)是一个系统性、多阶段的过程,
-----------------------------------------------------------------------------------------------
学习大模型(Large Language Models, LLMs)是一个系统性、多阶段的过程,
"""
注意:当
n > 1且stream=False时,可获取多个完整回答;若stream=True,需通过index字段区分流中的不同回答。
| 参数 | 控制方向 | 推荐场景 |
|---|---|---|
temperature |
创造性 vs 确定性 | 创意写作(高),事实问答(低) |
top_p |
采样范围 | 一般设为 0.85~0.95 |
max_tokens |
输出长度 | 根据任务需求设定 |
frequency_penalty |
减少重复词 | 长文本生成 |
presence_penalty |
鼓励新话题 | 多轮对话、发散思考 |
最佳实践:
- 默认可设
temperature=0.7,top_p=0.9 - 若回答重复,适当提高
frequency_penalty或presence_penalty - 需要多个答案对比?用
n=3+<font style="color:rgb(6, 10, 38);">stream=False</font>
本小节面可能会问到的问题(仅供参考)
1. 什么是大模型推理(Inference)?
答:推理是在模型权重固定的情况下,根据输入 prompt 生成输出的过程,不更新模型参数。
2. 大模型是如何生成文本的?
答:模型基于当前上下文预测下一个 token 的概率分布,并按一定策略采样,逐步生成完整文本。
3. temperature 参数的作用是什么?
答:控制生成文本的随机性。值越低越确定(保守),越高越随机(有创意但可能不连贯)。
4. top_p(核采样)和 top_k 有什么区别?
答:top_k 固定选概率最高的 k 个 token;top_p 动态选择最小集合使其累计概率 ≥ p,更灵活。
5. max_tokens 控制什么?
答:限制模型生成的最大 token 数量,不包括输入 prompt 的 token。
6. frequency_penalty 和 presence_penalty 的区别?
答:
- frequency_penalty:根据 token 出现次数线性惩罚,减少重复词。
- presence_penalty:只要 token 出现过就惩罚,鼓励引入新词。
7. beam search 是什么?优缺点?
答:保留多个候选序列(而非只选一个)进行扩展。
优点:生成质量高、连贯;
缺点:计算开销大、缺乏多样性。
8. OpenAI API 中的 n 参数是 beam search 吗?
答:不是。n 表示并行生成 n 个独立回答,每个都是单独采样,不是共享路径的 beam search。
9. 如何减少模型生成中的重复内容?
答:可适当提高 frequency_penalty 或 presence_penalty。
10. temperature=0 时模型行为如何?
答:等价于贪心解码(greedy decoding),每次都选概率最高的 token,输出完全确定。
11. 为什么通常同时使用 temperature 和 top_p?
答:两者作用互补:temperature 调整整体分布平滑度,top_p 限制采样范围,联合使用可更好平衡质量与多样性。
12. 流式输出(stream)在什么场景下有用?
答:需要实时显示生成结果时(如聊天界面),可提升用户体验,降低等待感。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 9
9 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)