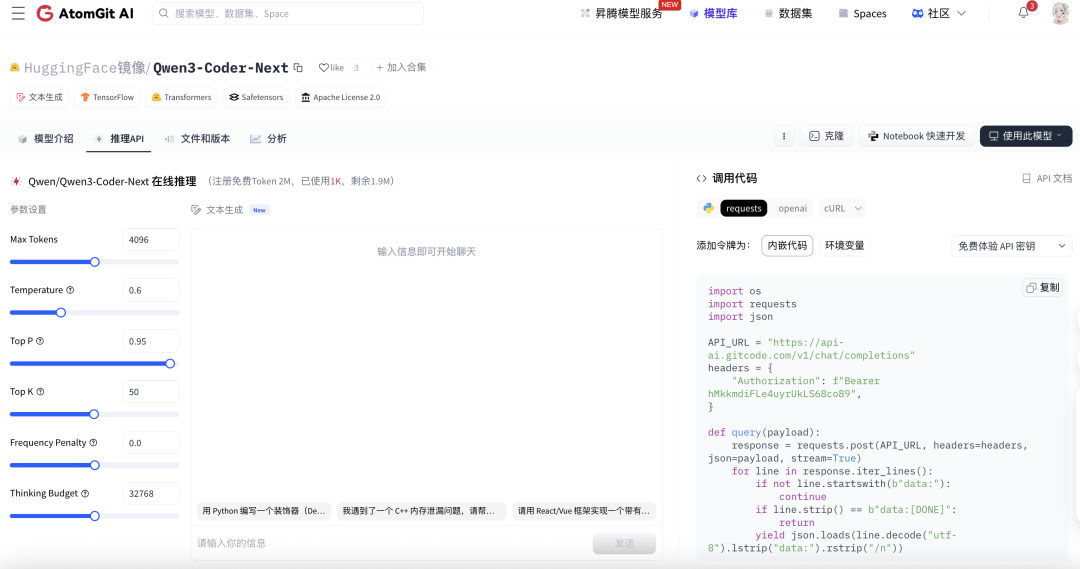
Qwen3-Coder-Next 昇腾适配:开发者在线体验一站式通关指南
2 月 4 日,Qwen3-Coder-Next 正式对外开源发布。该模型面向编程智能体与本地开发场景打造,提供完整开源权重,适合开发者进行二次开发与工程集成。昇腾已适配支持该模型。
2 月 4 日,Qwen3-Coder-Next 正式对外开源发布。该模型面向编程智能体与本地开发场景打造,提供完整开源权重,适合开发者进行二次开发与工程集成。昇腾已适配支持该模型,相关模型与权重已同步上线 AtomGit AI。
👉 立即体验:https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-Coder-Next/model-inference
01|模型介绍
Qwen3-Coder-Next 本质上是一款专门为编程和智能体场景打造的超大模型。它采用了混合专家(MoE)架构,也可以理解为:模型里有很多“专家模块”,每次只调动最合适的一小部分来工作,而不是把全部参数都跑一遍。这样做的好处是,在保持模型能力很强的同时,大幅降低了实际推理开销,更适合真实部署和长期跑服务。
同时,它基于 Qwen3-Next-80B-A3B-Base 构建,并结合新的注意力结构,让模型在写代码、理解工程上下文和处理复杂任务流程时更稳定、更聪明。
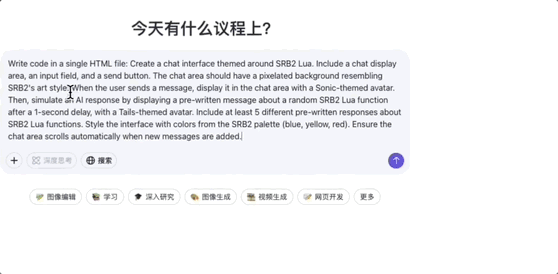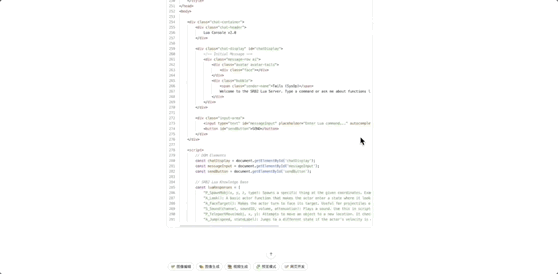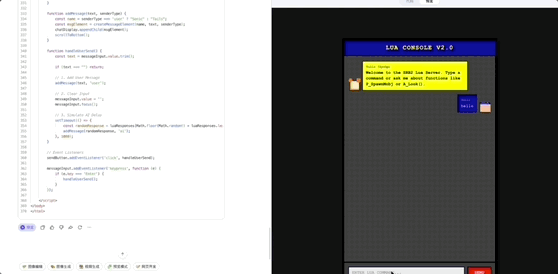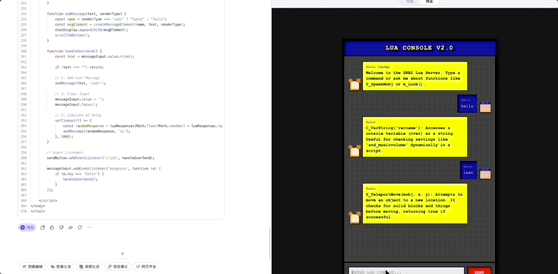
效果演示
我们展示其在 OpenClaw、Web 开发的示例:
使用OpenClaw与其进行聊天:

使用 Web 开发 实现一个聊天界面:
02|硬件建议

03|MindSpeed LLM 全流程部署实战
MindSpeed LLM 已完成对 Qwen3-Coder-Next 的首发适配,支持在昇腾 NPU 上进行预训练、指令微调与推理部署,适合构建长期运行的编程智能体与企业级研发平台。
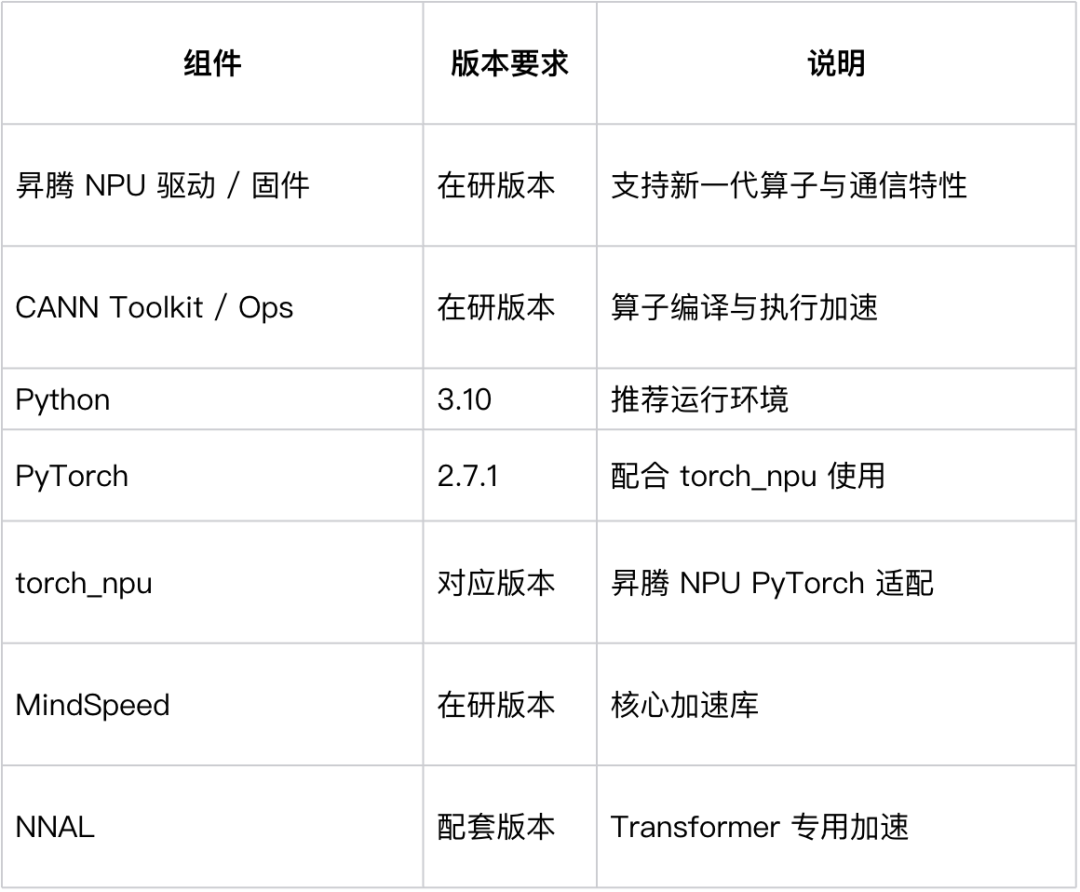
3.1 软件栈与环境依赖
在使用 MindSpeed LLM 部署 Qwen3-Coder-Next 前,需要准备如下基础环境:
3.2 环境准备与仓库部署
拉取核心代码仓库
# MindSpeed-LLM 主仓库
git clone https://gitcode.com/ascend/MindSpeed-LLM.git
# Megatron-LM(MindSpeed-LLM 依赖)
git clone https://github.com/NVIDIA/Megatron-LM.git
cd Megatron-LM
git checkout core_v0.12.1
# 拷贝 Megatron 到 MindSpeed-LLM
cp -r megatron ../MindSpeed-LLM/
cd ../MindSpeed-LLM
git checkout master创建 Python 运行环境
conda create -n qwen3-coder python=3.10
conda activate qwen3-coder安装 PyTorch 与昇腾 NPU 依赖
pip install torch-2.7.1-cp310-cp310m-manylinux2014_aarch64.whl
pip install torch_npu-2.7.1*-cp310-cp310m-linux_aarch64.whl安装 MindSpeed 加速库
git clone https://gitcode.com/ascend/MindSpeed.git
cd MindSpeed
git checkout master
pip install -r requirements.txt
pip install -e .安装完成后,MindSpeed 将自动接管 Transformer、Attention 与 MoE 等核心模块的加速执行路径。
3.3 权重转换:打通 HuggingFace 生态
Qwen3-Coder-Next 官方以 HuggingFace 格式发布权重。
MindSpeed LLM 提供一键式转换脚本,可将权重转换为 Megatron / MindSpeed 可直接使用的格式。
cd MindSpeed-LLM
bash examples/mcore/qwen3_coder_next/ckpt_convert_qwen3_coder_next_80b_hf2mcore.sh该过程会自动完成:
-
权重切分与并行映射
-
MoE 专家参数重排
-
与昇腾并行策略对齐
3.4 数据预处理流程
预训练数据处理
bash examples/mcore/qwen3_coder_next/data_convert_qwen3_coder_next_pretrain.sh \
--input /path/to/raw_data \
--tokenizer-name-or-path /path/to/tokenizer \
--output-prefix /path/to/processed_data指令微调数据处理
bash examples/mcore/qwen3_coder_next/data_convert_qwen3_coder_next_instruction.sh \
--input /path/to/instruction_data.json \
--tokenizer-name-or-path /path/to/tokenizer \
--output-prefix /path/to/processed_sft_data3.5 预训练、微调与推理部署
预训练示例
我们这里以 4 机 64 卡 Atlas A3 为例
bash examples/mcore/qwen3_coder_next/pretrain_qwen3_coder_next_80b_4K_A3_ptd.sh全参数微调
bash examples/mcore/qwen3_coder_next/tune_qwen3_coder_next_80b_4K_full_ptd.sh推理生成
bash examples/mcore/qwen3_coder_next/genarate_qwen3_coder_next_80b_ptd.sh04|vLLM Ascend 推理上手指导
4.1 获取模型权重
可在 AtomGit AI 快速下载模型权重:
# 从 AtomGit 镜像站下载
git clone https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-Coder-Next或访问页面手动下载:https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-Coder-Next
注意:Qwen3-Coder-Next 已在 vllm-ascend:v0.14.0rc1 版本镜像中支持。
4.2 安装 Triton Ascend
需要确保环境中已安装 Triton Ascend 以运行该模型:
pip install triton-ascend==3.2.0详细安装指南可参考:https://gitcode.com/Ascend/triton-ascend
4.3 启动 Docker 容器
根据您的昇腾硬件版本选择对应镜像:
# 对于 Atlas A3 机器:
exportIMAGE=quay.io/ascend/vllm-ascend:v0.14.0rc1
docker run --rm \
--shm-size=1g \
--name qwen3-coder-next \
--device /dev/davinci0 \
--device /dev/davinci1 \
--device /dev/davinci2 \
--device /dev/davinci3 \
--device /dev/davinci_manager \
--device /dev/devmm_svm \
--device /dev/hisi_hdc \
-v /usr/local/dcmi:/usr/local/dcmi \
-v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi \
-v /usr/local/Ascend/driver/lib64/:/usr/local/Ascend/driver/lib64/ \
-v /usr/local/Ascend/driver/version.info:/usr/local/Ascend/driver/version.info \
-v /etc/ascend_install.info:/etc/ascend_install.info \
-v /root/.cache:/root/.cache \
-p 8000:8000 \
-it $IMAGEbash
4.4 离线推理(Python API)
在容器内执行以下 Python 脚本进行离线推理:
import os
os.environ["VLLM_USE_MODELSCOPE"]="True"
os.environ["VLLM_WORKER_MULTIPROC_METHOD"]="spawn"
from vllm import LLM, SamplingParams
defmain():
prompts =[
"Hello, my name is",
"The president of the United States is",
"The capital of France is",
"The future of AI is",
]
# 采样参数配置
sampling_params = SamplingParams(
max_tokens=100,
temperature=0.0
)
# 初始化 LLM(NPU 环境)
llm = LLM(
model="/path/to/model/Qwen3-Coder-Next/",# 替换为 AtomGit 下载路径
tensor_parallel_size=4,# 4 卡张量并行
trust_remote_code=True,
max_model_len=10000,# 根据 NPU 显存调整
gpu_memory_utilization=0.8,# GPU 内存利用率
max_num_seqs=4,
max_num_batched_tokens=4096,
compilation_config={
"cudagraph_mode":"FULL_DECODE_ONLY",
},
)
# 生成文本
outputs = llm.generate(prompts, sampling_params)
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
if __name__ =="__main__":
main()
4.5 在线推理
启动兼容 OpenAI API 的推理服务:
vllm serve /path/to/model/Qwen3-Coder-Next/ \
--tensor-parallel-size 4\
--max-model-len 32768\
--gpu-memory-utilization 0.8\
--max-num-batched-tokens 4096\
--compilation-config '{"cudagraph_mode":"FULL_DECODE_ONLY"}'
建议:
--max-model-len 32768:NPU 部署建议先使用 32K 上下文长度,稳定后可尝试 256K
--tensor-parallel-size 4:4 卡并行,充分发挥 NPU 算力
发送测试请求:
curl http://localhost:8000/v1/completions \
-H "Content-Type: application/json"\
-d '{
"prompt": "Write a Python function to implement quick sort",
"max_tokens": 512,
"temperature": 0.0
}'
05|快速体验模型能力
为了帮助用户快速上手并高效评估模型能力,Qwen3-Coder-Next 提供「在线体验」与「API 接入」两种使用方式,分别面向快速验证与工程化应用场景。
方式一:即刻在线体验
无需部署,无需环境配置,打开即可使用。
通过模型在线推理页面直接输入代码或自然语言指令,即可快速体验 Qwen3-Coder-Next 在代码生成、代码理解、复杂任务拆解与智能体能力方面的实际效果,适用于模型能力验证、编程场景测试以及不同代码模型之间的对比评估。
👉 在线体验地址:https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-Coder-Next/model-inference
方式二:调用推理 API
还可通过推理 API 接入 Qwen3-Coder-Next 的模型能力,用于构建代码助手、自动化开发工具和智能体系统,适用于对稳定性、并发能力与工程集成要求较高的开发场景。
👉 推理 API 地址:https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-Coder-Next/model-inference

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 15
15 0
0- 0



 已为社区贡献51条内容
已为社区贡献51条内容

所有评论(0)