GLM-OCR发布:性能SOTA,超越PaddleOCR-VL-1.5?
智谱AI发布轻量级OCR模型GLM-OCR,参数仅0.9B却实现SOTA性能。该模型在OmniDocBench V1.5评测中获94.6分,擅长处理手写体、复杂表格等场景,PDF处理速度达1.86页/秒,API成本低至0.2元/百万Tokens。采用"编码器-解码器"架构,支持图片/PDF输入,输出结构化文本/JSON/HTML。相比大模型更轻量专业,比传统OCR功能更全面。已
前有通过视觉压缩,实现高效、结构化的文档理解的DeepSeek-OCR2,后有高精度、鲁棒的多任务文档解析PaddleOCR-VL-1.5,而最近智谱AI发布最新GLM-OCR一款轻量级专业光学字符识别模型。它凭借“小尺寸、高精度”的特点,在复杂文档解析领域达到了当前最佳性能,并大幅降低了部署和使用成本。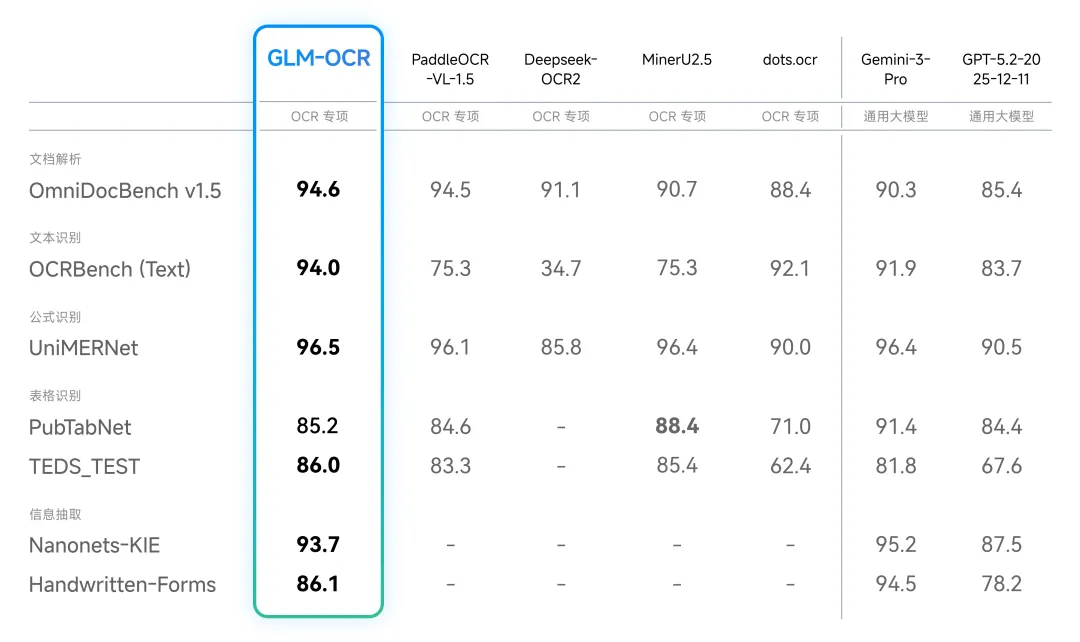
开源地址
Github:https://github.com/zai-org/GLM-OCR
Hugging Face:https://huggingface.co/zai-org/GLM-OCR
在线体验Z.ai:https://ocr.z.ai
模型概述与核心优势
GLM-OCR是一个参数规模仅0.9B(约9亿)的轻量级模型。它在设计上追求极致的效率,具有以下核心优势:
- 性能顶尖:在权威的文档解析综合评测榜单 OmniDocBench V1.5 上取得了 94.6分,达到最优水平。
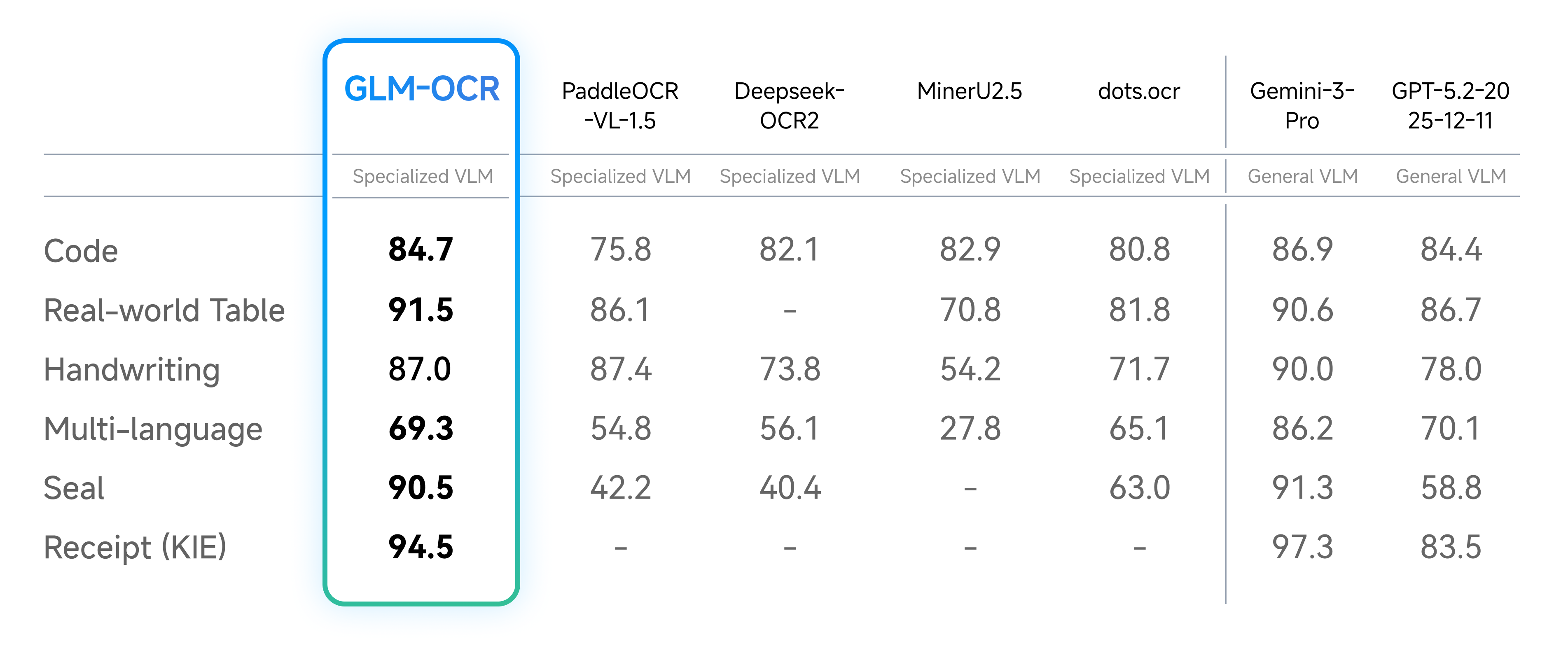
- 场景针对性强:专门针对传统OCR难以处理的手写体、复杂表格、编程代码、印章图像及多语言混合排版等场景进行了深度优化。
- 效率与成本优势显著:PDF文档处理吞吐量高达1.86页/秒。通过API调用,价格仅为0.2元/百万Tokens,成本据称约为传统OCR方案的十分之一。
技术架构解析
GLM-OCR的技术实现围绕高效、精准的目标展开:
- 核心架构:采用经典的**“编码器-解码器”** 架构。视觉部分集成了自研的 CogViT视觉编码器,该编码器在数十亿级图文数据上经过预训练,具备强大的图文语义理解能力。
- 关键技术:
- 两阶段流程:采用“版面分析→并行识别”的流程。首先分析文档结构,然后对不同区域并行识别,兼顾精度与速度。
- 高效训练:引入多Tokens预测损失策略,增强训练信号,提升模型学习效率。
- 模型规格:以下是其关键参数概览:
| 项目 | 规格说明 |
|---|---|
| 参数量 | 0.9B(视觉编码器约400M,语言解码器约0.5B) |
| 支持框架 | vLLM, SGLang, Ollama 等主流推理框架 |
| 输入格式 | 图片、扫描件、PDF文档等 |
| 输出格式 | 文本、HTML表格代码、结构化JSON等 |
| 训练策略 | 多Tokens预测损失,全任务强化学习 |
性能表现与基准测试
在多个专业测试中,GLM-OCR展现了全面且领先的能力:
- 综合评分领先:在覆盖文本、公式、表格、信息抽取四大任务的OmniDocBench V1.5榜单中,其综合得分达到SOTA水平。
- 细分任务优异:在文本识别、公式识别、表格结构识别及关键信息抽取等细分任务上,性能优于多款专用OCR模型,并接近谷歌旗舰大模型Gemini-3-Pro的水平。
- 处理速度快:在单副本、单并发的测试条件下,处理PDF文档的速度显著优于同类对比模型。
应用场景与案例分析
GLM-OCR的能力在多个实际场景中得到验证:
- 通用文本识别:可准确识别照片、截图、扫描件中的印刷体、手写体、印章文字甚至编程代码。
- 复杂表格解析:能理解合并单元格、多层表头等复杂结构,并直接输出标准HTML代码,无需人工二次制表。
- 信息结构化提取:可从发票、票据、证件中智能提取关键字段(如金额、日期、编号),并输出结构化JSON,便于直接接入业务系统。
- 为RAG提供支撑:其高精度和规整的输出格式,能为检索增强生成系统提供高质量的数据来源。
部署实践与成本分析
GLM-OCR致力于降低使用门槛:
- 灵活部署:得益于小参数量,它支持多种主流推理框架,非常适合在资源受限的边缘设备或需要高并发处理的服务器端部署。
- 极低成本:通过官方API调用,1元人民币约可处理2000张A4扫描图片或200份10页的简单PDF文档,具有极高的性价比。
- 开源生态:模型、完整的SDK及推理工具链均已开源,开发者可以便捷地集成到现有项目中。
与其他模型的对比
GLM-OCR的定位清晰,与其它类型模型相比特色鲜明:
- 对比大型多模态模型:相比GPT-4V、Gemini等通用大模型,GLM-OCR参数极小、部署成本极低、在专业OCR任务上精度更高,尤其擅长复杂版式和特殊场景。
- 对比传统/专用OCR模型:相比单一功能的传统OCR引擎,GLM-OCR作为一个端到端模型,无需拼接多个子系统就能完成版面分析、文字识别、表格理解和信息提取等全套流程,使用更简单。
总结与展望
总的来说,GLM-OCR通过轻量化设计和针对性的技术优化,在精度、速度、成本和应用范围上取得了优秀的平衡,有望推动OCR技术从专用工具向通用基础设施演进。其开源的属性也将加速技术在金融、政务、教育、物流等行业的规模化应用。
据官方信息,智谱AI未来计划持续迭代GLM-OCR,推出更多尺寸版本,并将其能力拓展至更多语言甚至视频OCR领域。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 13
13 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)