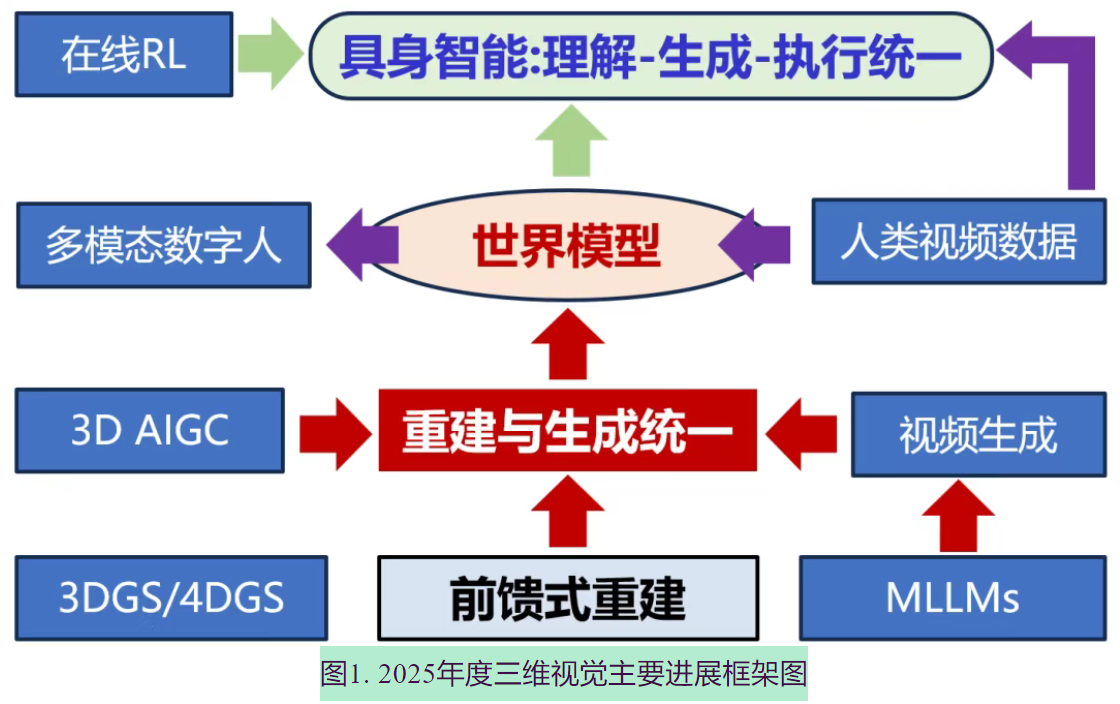
【前沿】2025年度三维视觉前沿趋势与十大进展(Mini3DV)
三维视觉迎来战略发展机遇,AI领域领军人物指出世界模型、空间智能与具身智能是关键方向。2025年三维视觉已深度整合Transformer架构,形成"多模感知-三维建模-四维生成-实时交互"一体化智能架构雏形。五大前沿趋势显现:1)前馈三维重建降低高质量3D内容制作门槛;2)三维生成与重建技术加速融合;3)视频生成推动世界模型与具身智能发展;4)人类行为数据成为具身智能训练核心资

内容来自于2025年10月18北京举办的第二届中国三维视觉前沿研讨会(Mini3DV2025)
文章目录
- 五点前沿趋势:
- 一、前馈式三维重建构筑三维视觉(空间智能)基础模型
- 二、重建技术与生成技术(视频生成/3D生成)路线相汇,从互助到初步融合
- 三、3DGS/4DGS持续提升表达效率,掀起场景建模和体积视频应用热潮
- 四、三维生成:从单体视觉逼真到部件场景结构化、物理可交互能力跃迁
- 五、从视频生成到世界模型:面向时空一致、物理合理与可交互
- 六、理解与生成统一的多模态大模型,服务空间智能感知
- 七、数字人前沿转变:从外观建模到多模态交互
- 八、人类数据成为突破具身智能 Scaling Law 的重要燃料
- 九、具身智能基础模型向理解想象执行一体化统一模型演进
- 十、具身智能的“后训练”时刻:VLA 模型从模仿学习向在线 RL 的范式跃迁
- 总结
随着人工智能发展所依赖的‘Scaling Law’范式边际效益显著递减、遭遇瓶颈,学术界与产业界的焦点正日益明确地转向“世界模型”、“空间智能”和“具身智能”等与三维视觉紧密相关的基础课题,三维视觉因此迎来了前所未有的战略关注与发展机遇。多位AI领域的领军人物也为此提供了理论指引与技术验证: 图灵奖获得者杨立昆,长期倡导构建能够预测和理解物理规律的世界模型 ; AI教母李飞飞则系统论述了空间智能是AI不可或缺的下一个前沿 ,并指出实现它需要具备生成、多模态与交互能力的世界模型;诺贝尔奖获得者谷歌DeepMind的首席执行官德米斯·哈萨比斯认为当前以大型语言模型(LLM)为主导的AI范式存在根本性局限,未来的突破在于让AI理解并交互于物理世界 。
截至2025年,三维视觉方法已深度拥抱Transformer架构,初步确立了前馈式重建与生成的主流技术范式。这一范式实现了对互联网海量视频数据的端到端时空三维重建与生成,其输出结果不仅包含几何结构,更初步展现了多模态语义信息,从而奠定了 多模感知-三维建模-四维生成-实时交互 一体化智能架构的雏形,为空间智能和具身智能的实质性发展提供了关键技术支撑。
五点前沿趋势:
1. 前馈三维重建支持时空多图像输入
随着VGGT等前馈三维重建技术的突破,通过时空多图像前馈式获得场景结构和运动信息变得愈发简易,带来两大深远影响 :它为空间智能提供了坚实的场景三维理解基础,使得许多传统二维视觉问题得以在三维空间中获得更本质的解决;其次,结合3D高斯泼溅(3DGS) 等高效渲染技术,使得高质量三维内容的制作门槛大幅降低,为数字孪生、元宇宙等规模化应用铺平了道路。
2. 三维生成与三维重建逐渐融合
SAM3D等3D AIGC技术,支持单图输入下的组件式和实例级物体生成,生成质量逐渐达到工业级扫描质量,同时结合前馈重建方式逐渐做到符合输入图像的真实三维结构和真实纹理的生成,未来将支持动态复杂场景的前馈式多实例重建,显著提高复杂场景的实时、多模态感知和理解能力。
3. 从视频生成、世界模型到具身智能的贯通
视频生成技术正快速融入显式或隐式的三维表征,向多视角一致、长序列、具备物理合理性的方向进化,直接推动了“感知-生成-交互”一体化的世界模型技术的发展。这类世界模型结合前馈三维重建技术,将形成完整的“多模感知-三维建模-四维生成-实时交互”的4D世界模型。同时,世界模型方法也开始服务于具身智能,理解-生成-执行统一框架初现。世界模型被学界广泛认为是实现可泛化具身智能并最终通向AGI的关键路径。
4. 人类行为和视频数据成为驱动突破的核心燃料
人类的操作空间与交互视频构成了训练具身智能的“数据金矿”。互联网上浩瀚的人类行为视频、以及通过简易设备采集的第一人称视角数据,其中蕴含的物理常识、因果推理与交互偏好,是突破当前具身智能数据瓶颈的天然燃料。通过对这些数据进行显式的三维感知重建或隐空间的动作对齐与学习,可以构建起驱动具身智能 Scaling 的“数据金字塔”基座。
5. 从模仿学习到交互驱动的强化学习具身训练范式演进
具身智能VLA模型的技术演进,正从依赖专家演示的监督微调范式,向融合在线强化学习的复合训练架构跃迁。这一转变有效突破了对稀缺高质量数据的依赖,使策略在稀疏奖励驱动下获得超越模仿学习的泛化与探索能力,解决了连续动作空间探索与稳定更新的难题。同时,高性能训练系统与动作条件世界模型的发展为规模化交互数据生成与高效策略进化提供了基础设施支撑,标志着具身智能正进入以“交互驱动”为核心的“后训练”新阶段。
一、前馈式三维重建构筑三维视觉(空间智能)基础模型
近年来,三维重建正从依赖多阶段、模块化迭代优化的传统范式,逐步演进为以大规模数据和模型为核心的前馈式重建范式,并成为空间智能的重要基础能力之一。相较于依赖反复优化的传统 SfM/MVS 或 NeRF/3DGS几何与纹理贯通的端到端可微优化方法,前馈式重建进一步将相机位姿计算、几何重建融为一体,实现了端到端的一体化流程。该方法在计算效率、可扩展性以及系统集成友好性等方面均展现出显著优势。前馈式三维重建从大量数据中学习到的先验知识使其对歧义性和输入变化具有显著更强的鲁棒性,因而正逐步成为空间智能基础模型的重要组成部分。
过去一年最具代表性的前馈式三维重建VGGT提出了一种统一的前馈Transformer架构,能够从单张、多张甚至数百张图像中,一次性直接预测相机参数、深度图、点云图和3D点轨迹等所有关键3D属性。相比于一次仅能处理两张图像的2024年代表工作Dust3R,VGGT通过引入交替注意力机制,在帧内自注意力和全局自注意力之间切换,实现了对任意数量输入图像的灵活、高效处理,推理速度极快。VGGT开创了三维视觉“大一统”模型。它打破了传统上不同3D任务被孤立模型处理的壁垒。其意义在于证明了通过大规模数据驱动,一个极简架构就能实现通用、高效的3D场景理解,为构建实时、鲁棒的3D视觉系统奠定了新的基础,并显著提升了点跟踪、新视图合成等下游任务的性能。
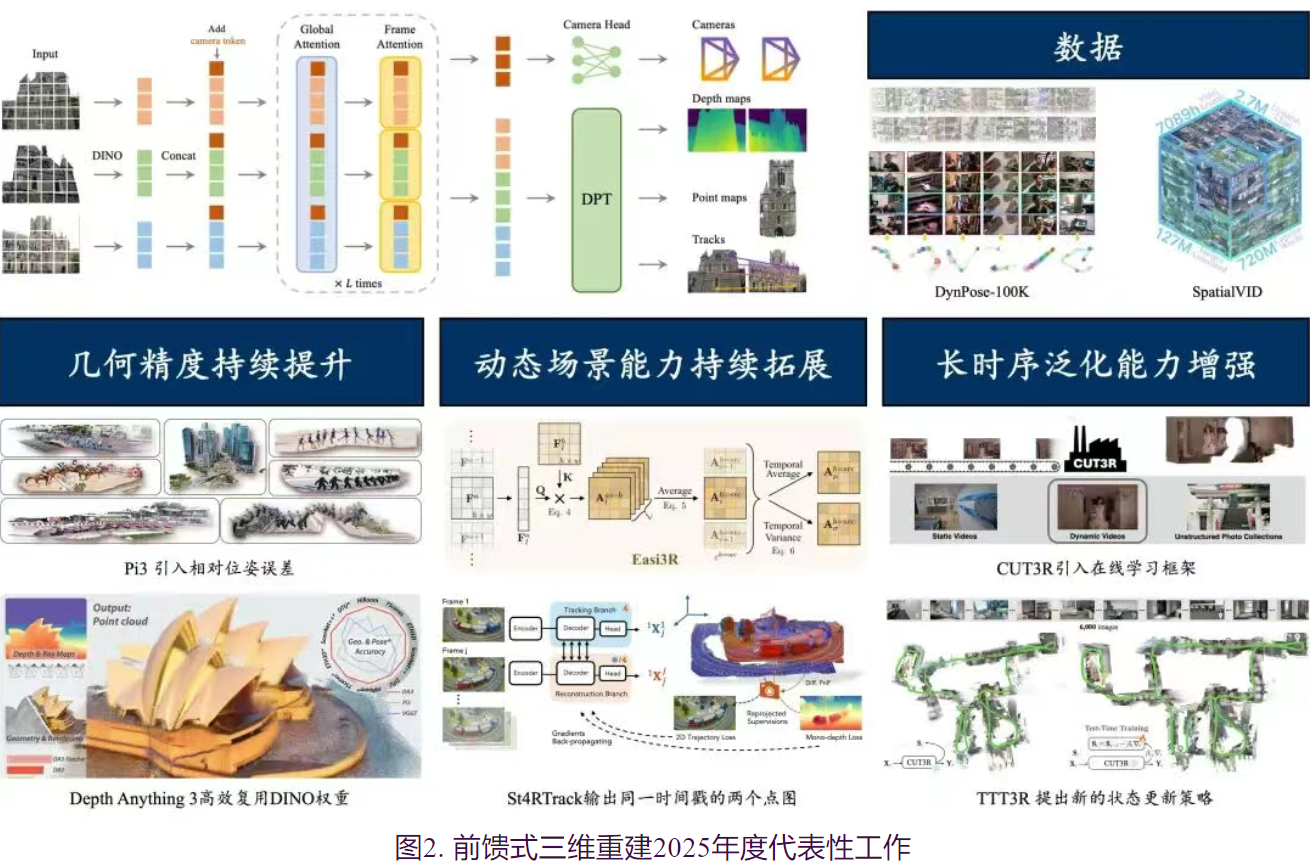
除了VGGT之外,前馈式三维大模型在多个关键维度取得了系统性进展,主要体现在以下三个方面:
1、重建几何精度的持续提升
在训练数据规模不断扩大、模型结构持续演进以及监督策略逐步完善等多重因素的共同推动下,前馈式三维重建的几何精度在过去一年中实现了显著跃升。自 DUSt3R 首次在三维视觉任务中验证 Scaling Law 的有效性以来, VGGT、SLAM3R、CUT3R、Pi3、Depth Anything3 等一系列方法不断刷新相机位姿估计与三维几何重建的性能上限。在数据层面,VGGT与CUT3R几乎整合了当前所有公开可用的、带有深度与相机姿态标注的多视角训练数据,大幅提升了模型的泛化能力。在此基础上,Depth Anything3 进一步将关注点从“数据规模”转向“数据质量”,通过引入单目深度模型,对多视角匹配生成的真值深度图中普遍存在的空洞区域进行有效补全,从而显著增强了监督信号的完整性与一致性。与此同时,面向 动态场景的数据增量也取得了重要进展。例如,DynPose-100K 与 SpatialVID 通过对 Panda-70M 数据集进行系统清洗,并补充相机位姿与深度标注,构建了大规模动态视频数据集,进一步丰富了可用于模型训练与评测的数据资源。
在模型架构方面,VGGT设计了融合 frame-wise 与 global self-attention 的分层注意力结构,并结合 DINO 提取的图像特征,将 DUSt3R 原本仅支持双目输入的框架成功拓展至多视角场景。Depth Anything3 进一步对模型结构进行简化,充分利用 DINO 尾部层完成多视角信息融合,在性能与计算效率之间取得了更优平衡。 SLAM3R 提出层次化架构的端到端稠密重建新范式,通过两个前馈神经网络分别实现局部多视角三维重建与全局增量式点云融合,摆脱了对显式位姿解算和几何优化的依赖。 CUT3R 则提出了流式重建范式,使模型能够以更高效率处理连续视角输入 。在监督策略层面,Pi3 在损失函数中显式引入相对位姿误差,有效避免了以往方法中随机选取参考视角所带来的训练不稳定问题,从而进一步提升了重建结果在多视角间的一致性与鲁棒性。后续工作MapAnything则进一步将多种几何任务统一到多模态网络中,从而实现灵活利用多模态信息,极大提升泛用性与可控性。此外, AnySplat、VolSplat等工作则进一步实现3DGS的重建,其结果可直接用于真实感渲染 。Rayzer 和 E-Rayzer 充分利用了大量无标注数据,实现了重建模型的自监督预训练,从而进一步提升了 VGGT 网络的重建精度。
2、动态场景建模能力的持续拓展
前馈式重建正逐步从静态三维场景扩展至随时间变化的动态场景估计。针对动态数据稀缺这一核心瓶颈,过去一年的研究主要围绕训练范式迁移与精细化运动建模两个方向展开。
在训练范式方面,研究工作形成了“微调适配”与“免训练迁移”两条演进路径。受限于真实动态数据规模有限,
- MonST3R 与 PAGE-4D 采用“静态预训练 + 动态微调”的策略,分别将 DUSt3R 与 VGGT 中学习到的静态几何先验迁移至动态场景。
- Align3R同样通过微调适配,利用DUSt3R框架对齐不同帧之间的单目深度,进一步优化全局相机位姿,得到世界坐标系下的动态重建。
- Stereo4D 则通过双目视频构建了大规模、带有三维运动标注的数据集,并在此基础上训练 DUSt3R,取得了具有标志性的精度突破。
- Easi3R 另辟蹊径,通过对 DUSt3R 注意力机制的深入剖析,揭示其交叉注意力在隐式建模刚性视图变换中的关键作用,并据此提出了一种基于注意力调制的免训练动态场景拓展方法。
- VGGT4D与MUT3R沿着类似思路,分别在VGGT与CUT3R框架下,实现了静态模型向动态场景的免训练自适应。
在结构建模层面,研究重心正从“逐帧点云估计”向“全要素点级时序追踪”深化。动态场景重建不仅要求逐像素对齐的几何与相机位姿恢复,还需显式建模时间维度上的几何对应关系。
- Uni4D、DELTA和TrackingWorld基于2D tracking与单目深度估计,进行3D的跟踪;
- St4RTrack、SpatialTrackerV2、Trace Anything 与 Any4D 等方法,分别基于 DUSt3R、VGGT、Fast3R 和 MapAnything 等静态前馈模型,引入点跟踪分支,实现了对动态物体逐点运动轨迹的精细刻画。
- 最新的 D4RT 则进一步革新了解码范式,提出按需查询机制,通过统一的解码接口避免了密集逐帧解码带来的计算冗余,使模型能够灵活查询时空中任意点的三维位置,为高效的时空建模提供了新的技术路径。
3.长时序泛化能力的显著增强
受限于 GPU 显存容量,早期前馈式重建方法对输入视角数量和序列长度高度敏感。尽管这类模型通常拥有数百至上千兆参数规模,即便在 A100-80G 等高端显卡上,也往往只能在较短序列(如 32 张图像)上进行训练,并在有限长度(如 200 张图像)内测试。如何在“短训长测”条件下实现稳定泛化,一直是前馈式重建面临的核心挑战。过去一年中,研究者通过重构模型架构与优化推理策略,在长时序泛化能力方面取得了显著进展。目前,长序列泛化推理主要围绕两类工作展开:一类是基于流式处理与测试时学习的模型架构,另一类则是将基础重建模型嵌入到现有SFM/SLAM框架中。
在模型架构层面,流式处理与测试时学习逐渐成为主流趋势。CUT3R 提出基于循环神经网络的重建范式,将空间记忆编码至压缩状态空间,使模型能够以近似恒定的内存与时间开销处理连续视角输入,从根本上缓解了全局注意力模型随序列长度平方增长的显存瓶颈。在此基础上,TTT3R 进一步将 CUT3R 的流式模型重构为测试时学习框架,将三维重建表述为空间记忆状态的在线学习过程,并引入置信度引导的自适应状态更新机制,有效缓解了短序列训练、长序列测试所带来的分布外泛化问题。StreamVGGT 与 Stream3R 通过将 VGGT 的全局注意力机制改造为因果注意力机制,实现了对长序列的流式处理。然而,当前模型在处理长序列重建任务时仍面临状态遗忘等挑战,导致重建质量随序列增长而显著下降。为缓解这一问题,此类方法需借助更多训练数据来充分训练模型
在系统部署层面,分块处理并融入重建框架则成为目前解决长序列漂移问题最有效的方法。在显式融入重建框架层面,滑动窗口与全局对齐策略为大规模场景重建提供了可行路径。VGGT-Long 与 Depth Anything3-Long 等方法采用跨窗口分块处理策略,在局部上下文内维持恒定内存开销,并通过后处理实现不同窗口预测结果的全局对齐,已在公里级自动驾驶场景的重建上得到成功应用。SLAM3R 在利用滑动窗口机制的基础上,引入历史帧检索机制与基于大模型的增量窗口对齐技术,使其在前馈推理中具备隐式重定位能力,有效抑制长程漂移,并在消费级单卡(4090D)上实现了 20+ FPS 的实时性能。这些工作的共同进展,标志着前馈式重建模型已具备处理超大规模连续数据的实际能力。
总体来看,过去一年中,前馈式三维重建在几何精度、长时序泛化能力以及动态场景建模等方面均取得了系统性进展。前馈式重建思路正逐步在三维视觉相关任务中得到应用与拓展。 Mast3R-SLAM,VGGT-SLAM将最先进的前馈模型(Mast3R,VGGT),结合BA局部/全局优化,和回环检测,构建了一套完整的SLAM系统 (VGGT-Long)。在 场景与人体运动协同重建方面,Human3R 基于CUT3R模型,Josh3R基于 DUST3R,UniSH基于 Pi3进行局部参数适配,实现动态场景与多人体运动的统一前馈重建 。同时,三维重建本身也逐步演化为一种预训练任务,其输出的图像与几何特征正成为支撑空间理解、空间生成与具身智能的重要基础能力(见本文第6项进展)。随着更大规模数据、更强模型结构以及重建与生成范式的深度融合,前馈式三维重建有望在未来空间智能体系中扮演核心感知与建模模块的角色。
二、重建技术与生成技术(视频生成/3D生成)路线相汇,从互助到初步融合
随着生成式人工智能的发展,将欠定信息输入条件下的三维重建,理解为一种特殊的三维生成,已成三维视觉领域学者的基本共识。然而,从具体技术实现来看,三维重建方法和三维生成方法仍是独立发展的两条技术路线。三维生成方面,尽管大部分三维生成大模型(如Clay或TRELLIS等)都能实现单图输入下的三维生成,但输入图像仅作为生成空间的条件,并无法确保获得重建结果与真实三维之间是仿射不变,甚至无法确保重建结果是像素对齐的。因此,大部分单图或稀疏图像输入下的三维生成并不是严格的三维重建。三维重建方面,自2024年来,前馈式方法如DUst3R、VGGT等得到了广泛的关注,但本质上仍局限在还原输入图像中的每个像素的三维位置以及相机信息,并不涉及对不可见区域的猜想和重建,前馈式三维重建极少引入生成技术。
进入 2025 年,三维重建与三维生成的技术边界日益模糊,正经历从独立发展迈向深度融合的阶段。面对稀疏视点输入下的欠定重建难题,视点缺失导致对缺失区域的推断的需求,而纯粹的生成模型缺乏对目标还原的忠实度。为此,学术界致力于探索二者的深层互补机制,构建了多条以提升鲁棒性与一致性为核心的技术演进路径。总体而言,这一 融合趋势主要体现为生成先验与几何约束的双向耦合,表现为两方面:一方面,“生成辅助重建”:旨在解决稀疏观测下的信息缺失问题。通过引入图像或视频扩散模型的时空一致性和强泛化能力,将传统的重建任务转化为“先验引导下的推断与补全问题”;或者通过引入对象三维生成模型,通过局部对象的理解和生成,完成场景的重建。另一方面,“重建规范生成”:旨在解决重建与生成过程中引入生成机制带来的随机性、不可控性及不忠实度度问题。
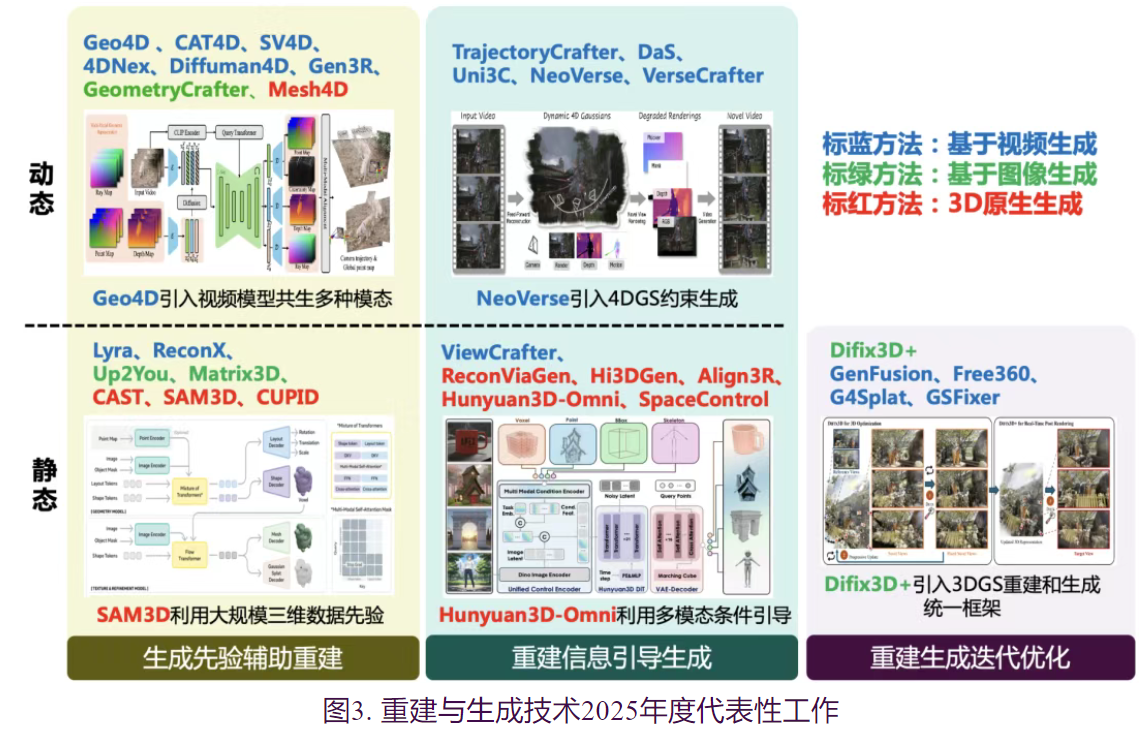
1、重建信息引导生成
a.静态对象的3D原生生成研究
静态对象采用3D原生生成的研究****使用重建得到的几何线索作为条件,以约束生成网络的输出,使其符合真实几何结构。
- ReconViaGen 通过将预训练的VGGT网络特征注入到3D生成模型中,有效提升了生成细节与整体形态和真实物体的一致性。
- Hi3DGen 则利用法向估计来引导生成使网络对法向层面的细节特征更加敏感,并与输入更加一致。
- 此外,在一些特定场景下用户希望通过自己给定的条件控制生成结果。针对这类需求,Hunyuan3D-Omni集成了包含体素、点云、包围盒、骨架的多模态条件引导,使用户可以自由调整生成结果的外观、尺寸、形态。
- SpaceControl 则通过在测试时注入额外几何编码实现几何可控,使得用户无需重新训练新的特有模型也能实现可控生成。
b.动态场景采用视频生成的研究
对基于视频生成的动态场景研究方面,则侧重于利用重建获得的显式3D表示作为一致性约束,以实现高质量的新视角视频生成。例如,
- ViewCrafter、TrajectoryCrafter及Uni3C等工作首先通过深度估计构建点云,并将其投影至目标视角的相机平面,利用这种变形的点云视频序列作为条件输入注入到视频生成模型中。
- DaS将三维点追踪数据转化为“追踪视频(Tracking Video)”,并以此作为视频生成模型的控制条件。
- VerseCrafter提出4D几何控制表示,通过在同一世界坐标系下统一描述动态场景几何信息,从而提升相机与多目标运动控制的精度与一致性,实现4D几何控制动态视频生成的端到端框架。
- NeoVerse 通过重建 4D 高斯,利用其在新视角下的渲染结果作为条件约束驱动生成过程。
- 值得关注的是,NeoVerse 提出了一种全新的训练范式,支持直接利用单目视频数据进行训练,极大地拓展了数据的来源。这些方法通过结合视频生成基座模型的强大建模能力与显式 3D 表示的几何约束,显著增强了新视角下的生成结果在空间维度上的几何一致性。
2.生成先验辅助重建
这类工作关注如何借助生成模型的先验,来提升欠定信息下的重建完整性和重建质量。根据采用的生成方法,可以再细分为三类。
其一是通过图像生成算法,提高静态场景的重建质量。
- Matrix3D 通过对深度、相机位姿、RGB图像共同进行多模态生成式建模,实现了稀疏视点输入下的任意新视点图像与深度同时生成,并用以辅助3DGS的重建;
- UP2You通过图像生成模型构建了一个“数据整流器”,将不规则的图片集合整流为规整视角下的标准图像,间接地实现三维重建。
其二是通过借助原生3D生成算法,实现场景类的组件对象三维重建。
- CAST通过将场景级重建分解为先估计物体位姿再生成3D模型两步实现,并通过物理优化实现更真实的到场景的对齐;
- SAM3D 则通过Mixture-of-Transformers架构将位姿估计和三维生成联合建模为共生生成任务,实现单图像场景的示例级对象重建。
- CUPID通过3D形状与UV的共生生成间接实现了同时生成3D物体与相机位姿估计,此外CUPID还利用估计的相机位姿作为更精细化的纹理生成控制。这些通过生成模型的先验进行重建的方式极大地提高了重建的质量和适用范围。
- Mesh4D进一步将原生3D的重建式生成拓展到动态形变物体上,通过VAE将动态形变场编码为一个生成式隐空间,并使用扩散模型通过单视频直接生成物体的网格曲面及其动态形变。最后一类是借助视频生成算法,实现动态场景三维重建。
- Geo4D通过对单视频动态场景共生生成点云图、深度图和光线图等多种互补的几何视频形态,在推理时对齐并融合这些形态,实现对长视频鲁棒且精确的4D重建;
- 4DNex则仅从单图直接共生生成动态场景的RGB与点云图像以得到场景动态点云表达;Lyra则进一步在视频生成模型的基础上进行针对3D高斯的自蒸馏,从而在推理时可以直接生成场景级别的3D高斯表达。
- SV4D设计了统一的潜在视频扩散模型,通过视角注意力和帧注意力机制的联合推理,从单目视频生成时序一致的多视角输出,进而实现优化式动态3D高斯重建。
- ReconX则使用重建的稀疏点云作为引导以生成3D一致的新视点视频,并在此基础上通过优化得到3D高斯的场景重建。
- CAT4D、Diffuman4D分别针对一般场景和虚拟数字人提出基于时间与视角采样的多路视频生成模型,实现了将单视频或稀疏视点视频拓展为时间、空间一致的多路视频的功能,并最终将其重建为高精度的动态高斯表达。
3.重建生成迭代优化
另一个重要的趋势是重建与生成相互迭代优化的框架出现,通过反馈重建和生成的迭代反馈增强整体系统能力。
- Difix3D+ 通过在新采样轨迹上生成含伪影的渲染图像,并利用单步扩散模型对其进行优化,从而提升 3D 重建质量与新视角合成效果。
- GenFusion和Free360 则在新采样轨迹上渲染包含伪影的视频序列,并将其输入视频扩散模型以生成无伪影结果,进而通过迭代反馈逐步优化 3D 表示。这些工作重建提供粗几何结构作为生成的起点,而生成结果又被反馈用于重建优化,使两者协同提升整体输出质量。
总体来看,2025 年以来的这些工作不仅在技术表现上各自推进了重建或生成的边界,更为重要的是,它们的设计理念都在逐步模糊重建与生成的界限,使得两者在方法架构、条件输入与任务目标上趋于统一。然而,虽然重建与生成的融合已经产生了许多有效的尝试,目前的大多数方法从宏观而言仍然局限于“先重建再生成”、“先生成再重建”、“边生成边重建”,距离一个统一任务的通用综合模型尚有距离。最近VIST3A、Gen3R等工作开始探索将DUSt3R、VGGT等前馈式重建模型与视频生成模型相结合,如 Gen3R 通过结合这二者的隐空间,同时实现了场景级生成与重建,为构建通用的重建与生成模型提供了新的思路。展望未来,如何结合重建与生成领域各自前沿发展以设计一个可支持稀疏输入、复杂动态场景的前馈式多模态信息统一重建方法将是下一阶段的主要探索目标。
三、3DGS/4DGS持续提升表达效率,掀起场景建模和体积视频应用热潮
随着计算机视觉与图形学技术的快速发展,复杂场景的数字化记录已成为连接物理世界与虚拟空间的关键技术。2023年3D高斯泼溅技术凭借显式点云表示和可微分渲染在静态场景重建领域取得突破,其兼顾质量与效率的特性为复杂场景建模提供了新的三维表征、优化和渲染技术。2025年,3DGS/4DGS的表达效率持续提升,掀起场景建模和体积视频应用热潮。以下围绕静态场景的3DGS技术和动态场景的4DGS技术分别总结2025年度进展。
2025年,静态3D高斯重建技术在多视图重建质量、训练收敛速度及实时渲染效率等关键维度持续演进,各类新型三维表达范式竞相涌现,显著推动了高斯重建技术从学术研究迈向实际落地应用。在重建质量上,研究者主要聚焦于优化基元核函数与外观表征。Student Splatting and Scooping 创新性地引入 Student-t 分布替代传统的高斯分布,并允许负不透明度的存在,有效增强了模型对细节的捕捉能力;DBS则提出了 Beta 核函数,并将传统的球谐函数(SH)外观替换为球形 Beta 外观函数,改善了边缘与高光的重建细节。此外,Billboard Splatting 将高斯基元的单一颜色属性替换为低分辨率纹理图,提升了场景纹理的保真度。
在 重建效率优化层面 ,
- 3DGS^2充分利用了高斯优化过程中海森矩阵的稀疏特性,引入二阶牛顿法进行求解,将高保真场景的重建时间压缩至 3-4 分钟量级。
- SpeedySplat则通过设计高效的剪枝策略,剔除了超过 90% 的冗余高斯基元,在极大幅度降低显存占用的同时,显著加速了训练收敛过程。
在 实时渲染效率上 ,学术界呈现出从体积辐射场向更高效显式表面表达转型的趋势。
- Gaussian-Enhanced Surfel提出了一种混合表达机制,使用一组完全不透明的二维椭圆 面片粗略构建场景几何与外观,并辅以高斯基元补充细节。该方法在训练阶段采用渐进式引导策略,实现了半透明面片向完全不透明状态的平滑过渡;在渲染阶段,利用 Z-buffer 技术直接通过传统图形管线渲染面片,而高斯则以排序无关的方式混合叠加,并利用渲染面片得到的深度图进行剔除实现精确遮挡关系。这种无需排序的传统管线机制,在确保高质量渲染的同时实现了三倍于原始高斯重建的加速,并彻底消除了排序抖动引发的闪烁伪影,已成功在 WebGL 端实现轻量化部署。
- MeshSplatting直接采用三角形作为基元,结合德布劳内三角化生成网格,通过类似的渐进式不透明度优化策略完成重建,以少量质量损失实现了与现代渲染引擎的完美兼容。
在 实时重建方面 ,
- GPS-SLAM延续Gaussian-Enhanced Surfel的混合表达思路,提出了一种名为“Gaussian-Plus-SDF”的双尺度混合场景表达。该方法采用符号距离场(Signed distance filed,SDF)表示粗尺度的几何与颜色信息,并引入稀疏可优化的3D高斯修复SDF中的色彩失真并补充高频细节。这种表达将传统几何驱动SLAM方法的高实时性与辐射场重建方法的高真实感相结合,得益于SDF提供的粗尺度几何与颜色信息,所需优化的高斯数量得以大幅减少,从而加速了高斯优化收敛过程。GPS-SLAM的扫描重建速度相比当前最优方法提升一个数量级以上,实现了超高速(每秒150帧以上)且高保真的实时三维场景重建。

尽管静态高斯技术已臻成熟,但在大规模场景重建与数据采集高效性方面仍存瓶颈,特别是如何彻底消除各类伪影以确保任意视角观察的鲁棒性,依然是当前亟待攻克的难题,静态高斯重建技术有望突破“最后一公里”,真正成为高质量的复杂场景建模工具,落地漫游、VR/AR等应用服务。
2024年至2025年间,4DGS技术也是围绕“高效表达”与“高质重建”两大目标快速演进:从原生4D高斯的理论探索,到高质量重建、渲染效率提升、存储压缩、长序列处理的工程优化,显著缩小了研究原型与实用系统之间的差距,4DGS重建基本达到to B级别应用。
动态场景建模 面临的核心挑战源于时间维度的引入,传统的逐帧重建策略会带来存储需求的线性增长和时间连续性的缺失。
- 4D Gaussian Splatting和4D-Rotor Gaussian Splatting分别独立提出的4DGS,将动态场景建模为连续的4D时空体积,使用原生4D高斯直接表示时空结构,自然支持任意时空点的采样和渲染,同时利用4D几何的内在属性,用紧凑的参数直接编码运动,避免了冗余的中间表示。通过全局优化和时空密度控制,智能地分配计算资源,用最少的高斯图元覆盖最复杂的动态变化。为后续工作奠定了表示层面的理论基础。
随着研究的深入,工作重点逐渐转向提升方法的实用性。在渲染效率方面,
- 4DGS-1K通过时空变异评分剪枝和活跃高斯掩码机制,实现了1000+ FPS的渲染速度,同时将存储需求降低了41倍;
- Temporal Gaussian Hierarchy针对长视频建模,观察到动态场景中不同区域具有不同程度的时序冗余,据此构建多层级4D高斯表示,每层只需加载对应片段4D高斯进显存,仅用17.2GB显存即可处理18000帧的长序列。
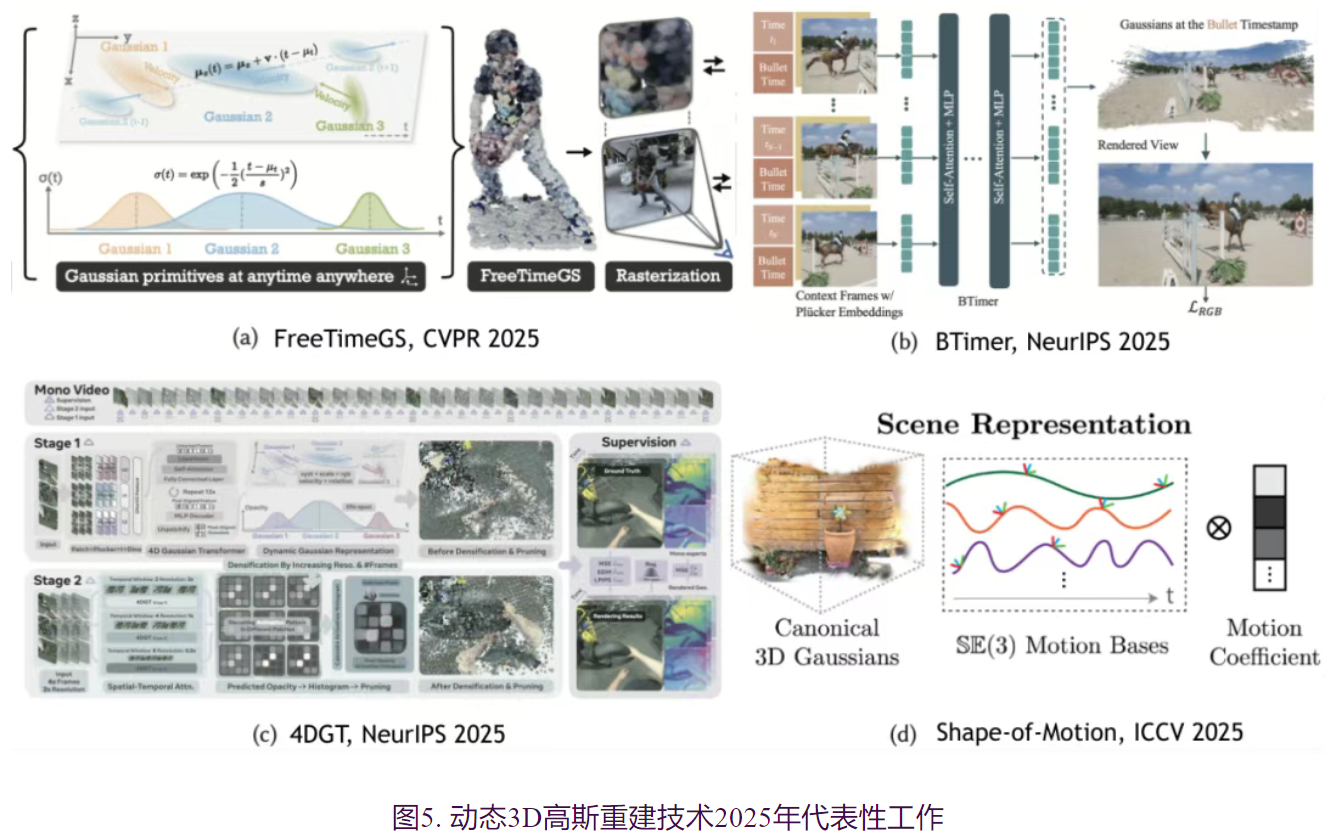
- 在功能拓展方面,FreeTimeGS允许高斯在任意时间和位置出现的4D表示,通过为每个高斯赋予运动函数来模拟物体的物理移动,有助于在时间维度上重用高斯图元,降低表示冗余并提升时序一致性;
- SharpTimeGS通过生命周期调制运动与平顶时间可见性函数增强高斯图元表征能力,进一步在时间维度上重用高斯图元,同时保持动静态建模能力并提升时序一致性;
- 4DSloMo引入多相机的时空间插采集,借助4DGS建模所具备的时空联合建模能力,实现对非同步相机进行4D重建,提升了对高速人体对象运动的高效高质重建;
- Split4D基于流式特征学习策略,实现无需视频分割的场景解耦重建,为动态场景的编辑和交互提供了新的可能性。
- STGS通过将运动建模为非线性复杂运动的同时渲染特征解码图像,实现了高质量重建。
- 4DGV通过运动分层表示实现动静态分离,提高了具有大幅度运动的物体的渲染质量。
总体而言,相比于逐帧的3DGS重建,4DGS联合考虑时空信息,重建结果得以更加时空连续,重建和渲染质量达到可用水平,同时表达效率更高效,初步满足互联网数据传输带宽要求(2MB/s)。
重建速度和采集便捷性方便,仍距离大规模商业落地应用存在差距。目前,重建1分钟的数据仍需要小时级以上时间,并且需要规模化相机阵列。首先,为降低相机数量需求,利用视频生成技术辅助新视点生成,实现动态场景的高斯泼溅重建是当前的主流思路。同时,还有一类方法通过引入运动信息,进行单视频重建:
- MoSca利用从基础视觉模型提取的先验知识,得到新的运动支架表示,对底层运动和变形进行紧凑平滑的编码,从而实现场景几何形状和外观与变形场解纠缠,完成了对单目视频的动态重建;
- Shape-of-Motion通过具有时变平移和旋转的全局3D高斯表示动态元素,使用低维刚性运动基对运动轨迹进行正则化并将噪声观测整合到全局一致的场景估计中,依靠单目视频实现了2D、3D追踪和动态场景重建;
- SplineGS利用创新的运动自适应样条进行动态运动建模,有效地从复杂的单目视频建模动态场景。目前,这类型的重建质量目前仍远低于密集相机阵列的4DGS重建方法。
针对快速4D重建能力研究,前馈重建 的兴起将逐场景优化范式转变为数据驱动的直接推理范式,为快速重建和可泛化性提供基础。其中:
- BTimer采用子弹时间公式化,聚合所有上下文帧的信息预测目标时刻的完整场景,仅需150毫秒即可从单目视频完成动态场景的3D高斯重建;
- MoVieS使用像素对齐的可变形高斯并显式监督其时变运动,在单一框架内统一了外观、几何与运动的建模,一秒内完成4D重建的同时支持场景流估计和运动物体分割等零样本任务;
- 4DGT完全使用真实世界单目视频训练,以滑动窗口方式处理64帧输入并通过密度控制策略有效扩展至长序列,在跨域泛化能力上取得显著突破。这一范式转变使动态场景重建的时间成本从小时级降至秒级。然而,需看到这类研究目前仅能处理单视点输入,且仅能生成极小视点范围内的自由视点视频内容。
展望2026年动态场景高斯建模技术,通过融合生成技术和前馈技术,有望实现少量视点甚至单视点下的高质量内容重建;4DGS的数据表达效率和压缩效率有望进一步提升,适配当前网络带宽下的实时传输应用;最后,在有先验类别场景,如人体为主的动态场景,实现纯RGB相机的实时动态高质量重建能力是应用趋势。随着场景解耦、运动理解和零样本泛化等能力的持续提升,4DGS有望成为增强现实、影视制作、自动驾驶仿真乃至具身智能等领域的基础设施级技术,推动动态三维内容从“昂贵的专业制作”走向“普惠的即时重建与生成”。
四、三维生成:从单体视觉逼真到部件场景结构化、物理可交互能力跃迁
2025年,三维生成进入从视觉优先向结构与物理优先转变的关键期。技术进展呈现五个互联主线:更精细的几何表征与大规模潜空间推动微观细节恢复;三维原生纹理实现高保真PBR输出并解决投影伪影;部件级生成在vecset与sparse-voxel路径上实现可控与高精度拆装;场景生成从语义解耦走向全局协同并借助通用基础模型扩展开放世界能力;与CAD、装配及绑定流程融合,推动工业与游戏级可装配、物理一致的生成。整体上,表征创新、结构化潜空间与跨模态大模型成为贯穿全链条的核心动力,研究重心由单体视觉逼真向结构一致、物理可交互的系统能力迁移。
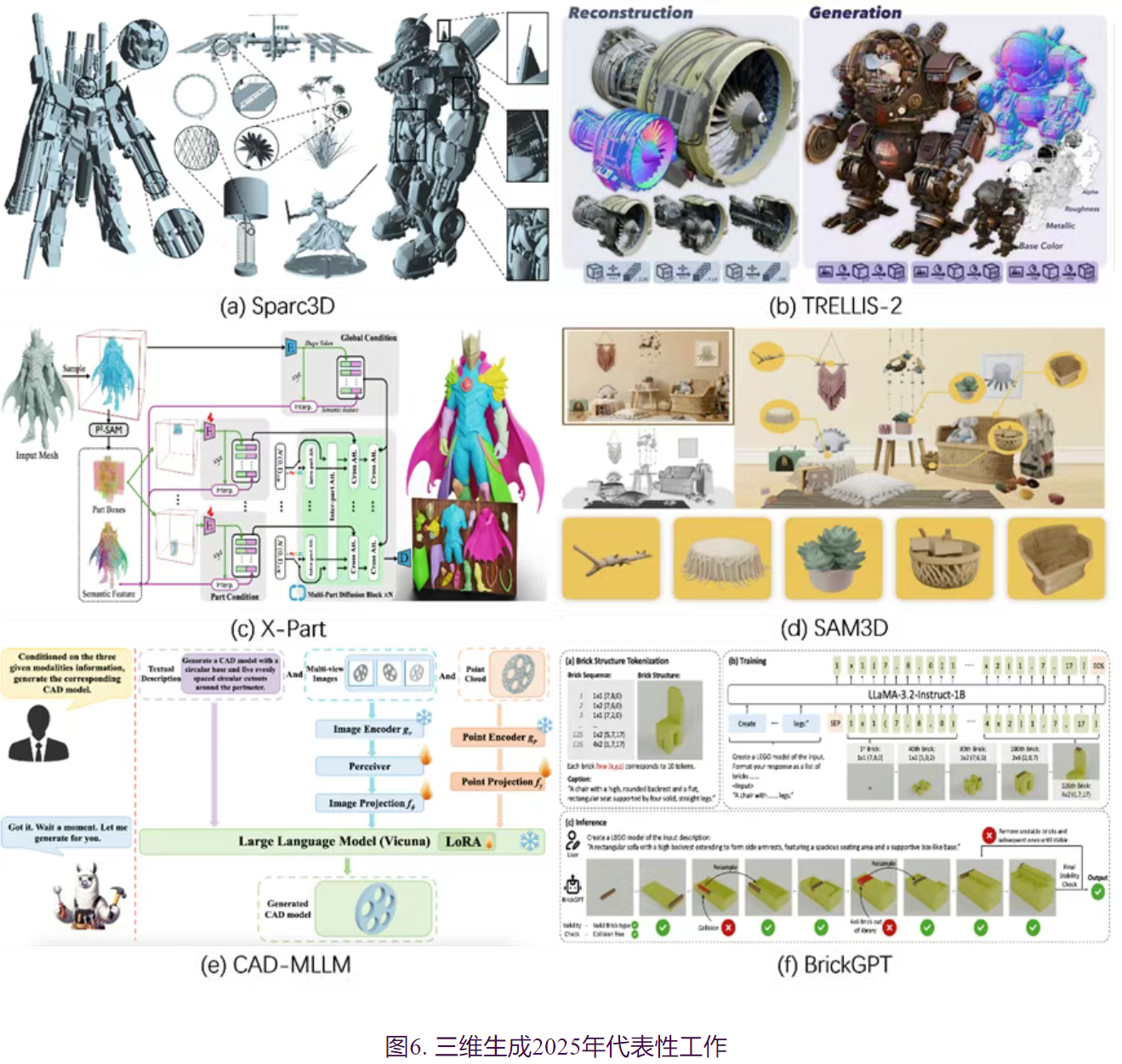
1.更精细的三维生成(几何细节、表征与大规模潜空间)
2025年,三维几何生成的研究重心实现了从描述宏观结构向恢复微观细节的跨越。
- Hi3DGen率先探索了相关方向,该方法通过利用从图像中得到的Normal Map作为中间桥梁,实现了精细化的三维生成,为相关研究提供了新的方向。然而,这种依赖中间表示的方法框架并未直接在三维结构上进行优化
- 针对这一问题,Sparc3D从几何表征的角度进行了创新,提出将Mesh转为新的几何表征方式,实现了在同一框架下的精细化三维生成,但其较高的训练成本和复杂的数据预处理都限制了该方法的使用。
- Lattice进一步在几何表征上了进行创新,通过设计动态调节的几何表征方式VoxSet,在精度和效率上实现了兼顾。
- Trellis.2提出了同时编码形状和外观的几何表征结构O-Voxel,并且减少了对数据预处理的要求,进一步实现了更友好的精细化三维生成。未来研究将更专注于几何表征方面的创新和更简单的方法框架。
2.高保真与三维原生纹理合成
三维纹理生成领域正在经历从“多视图投影拼接”向“3D原生材质建模”的范式跃迁。
- TexVerse 通过发布超大规模数据集,为高泛化纹理模型的训练奠定了数据基础,促使研究视角从局部纹理扩展至全局特征。
- 为了解决传统投影技术引发的接缝与伪影问题,UniTex 率先提出在 3D 连续表面坐标系中直接生成材质,实现了几何感知的精准对齐。
- 在此基础上,针对表征精度的提升出现了两条互补路径:NaTex 利用点集向量(VecSet)建模材质,以突破网格分辨率限制,而 LaFiTe 则通过结构化潜空间,确保了建模的稳定性。近期,
- TRELLIS.2 进一步引入O-Voxel潜空间,在原生 3D 框架下实现了高分辨率的 PBR 输出,标志着生成纹理在视觉细节上已能媲美 2D 扩散模型。当前的研究重心已从单体建模转向场景级材质统合,旨在整合不同表征的泛化力与工业级解耦技术,产出具备物理一致性、可跨场景通用的材质参数集,从而为数字孪生与具身智能提供高保真的视觉与物理交互支持。
3.三维部件生成
部件生成在基于sparse voxel 以及vecset两种原生表征上进行了分别的探索,PartCrafter,PartPacker,BANG基于vecset 的表征,实现了端到端的自适应的精细部件结构的生成,其中PartPacker 引入Dual Volume 的拓扑先验,一定程度上缓解了网络自适应拆件时的几何奇异性。而X-Part采用‘先分割后补全’多阶段策略,旨在可控以及高精度的部件生成。OmniPart作为sparse voxel 表征的尝试,引入了分割图条件下的自回归预测部件bbox,也实现了可控,高效的部件生成。
4.三维场景生成
在场景生成任务中,现有工作均致力于解决多物体间的空间布局与几何一致性难题,但在解决路径上各有侧重。
- 针对复杂场景中物体布局混乱、易穿模的痛点,CAST提出了“语义先验解耦”方案,利用大语言模型构建关系图来约束独立生成的物体位姿,通过明确的语义逻辑显著改善了物理合理性。然而,这种分治策略难以捕捉物体间微妙的紧密耦合关系(如相互遮挡与光照影响),
- MIDI进而转向“全局协同生成”,通过在扩散模型中引入多实例注意力机制,实现在同一生成流中同步优化多个物体,强化了整体场景的视觉连贯性与几何协调性。
- 为了进一步突破上述方法对特定类别的依赖并解决泛化难题,SAM3D引入了“通用基础模型”驱动的思路,利用大规模分割先验实现了“万物三维化”的几何初始化,弥补了场景生成在开放世界(Open-World)场景下通用性不足的问题,为构建多样化场景提供了高泛化的几何底座。
5.三维生成方向的其他多元化发展(结构化、CAD、绑定与装配)
三维生成技术已不再局限于单纯的形状建模,而是与工业计算机辅助设计(CAD)流程、游戏建模及物理可装配性需求深度融合,呈现多方向并行发展的态势。在工业CAD制造领域,多种CAD表征方法均取得了阶段性进展:
- CAD-MLLM以CAD命令序列作为核心表征形式,基于多模态大模型实现CAD命令序列的生成,支持多种输入模态到参数化CAD模型的统一生成任务;
- AutoBrep则采用边界表示(Boundary Representation, BRep)方法,将BRep中的面、边及拓扑关系转化为离散标记序列,可支持复杂实体的长序列建模及单阶段训练过程。
- 在游戏建模的下游应用场景,如布线、多边形网格生成等任务中,RigAnything模型能够实现无模板约束的关节与骨骼拓扑生成及蒙皮权重分配,有效推动了通用化绑定技术的发展;
- BPT通过块级索引与补丁聚合策略对网格序列进行压缩,为高效处理更高面数的网格数据提供了可行方案;
- BrickGPT基于自回归语言模型生成物理稳定的互锁式积木结构,融合物理约束检测与有效性回滚机制,保障了生成结构的可装配性与力学稳定性。
展望未来,三维生成将由模块化研究走向系统化工程。短期内,几何与材质表征的统一、结构化潜空间与多尺度解耦将成为提升精度与泛化的主攻方向;中期将见证跨模态基础模型(融合视觉、语言与物理模拟)带来的普适生成能力,支持开放世界的即插即用三维化;长期看,物理可交互的数字孪生、与CAD/制造流程的无缝对接以及实时可控的高分辨率生成将成为产业化落地的关键。同时,低成本标注、可解释性的评估框架与标准化基准数据集是推动学术向工业转化的必要条件。
五、从视频生成到世界模型:面向时空一致、物理合理与可交互
2025年,世界模型成为三维视觉和计算机图形学等领域最受关注的焦点之一。随着大语言推理模型、多模态大模型、视频生成和三维重建等技术快速发展,研究者能够以更高层次建构和预测复杂世界状态,使“可理解、可预测、可交互” 的数字世界逐渐成为可能。2025年在世界模型的研究工作方面取得了一系列进展,主要聚焦于物理感知、空间一致、长序记忆等核心问题。该领域正处于蓬勃兴起的快速发展期,新技术迭代迅速,新范式层出不穷,在具身智能、空间智能和智能驾驶等应用场景将产生实用价值。美国工程院院士、斯坦福教授李飞飞指出,世界模型在机器人、教育、医疗保健、制造业、农业、VR和AR等多个方面都有广阔应用前景。图灵奖得主LeCun也指出,仅仅文本和语言是不够的,AI系统需要理解现实世界,具备一定的常识,以及推理和规划的能力,拥有持久记忆。
世界模型被定义为编码环境知识并模拟其动态变化的数字引擎,能够在语义、物理、几何与动态等多重复杂世界(无论虚拟或现实)中进行理解、推理、生成和交互的模型。当下,以Sora为代表的视频生成模型已经在视觉质量上得到优异的结果,实现“表面忠实”,世界模型技术则进一步推进至“一致性忠实”和“物理内在忠实”,保证时空一致性,支持复杂物理的交互和控制。通过世界模型,可以实现对物理世界未来状态的精确预测和演化模拟,由“视觉合理”迈向“物理真实”。针对使用视频生成模型构建世界模型所面临的挑战,包括物理合理性不足、空间一致性较弱、难以交互式生成、缺乏长序列和记忆四个方面,2025年出现许多优秀的工作解决上述问题。
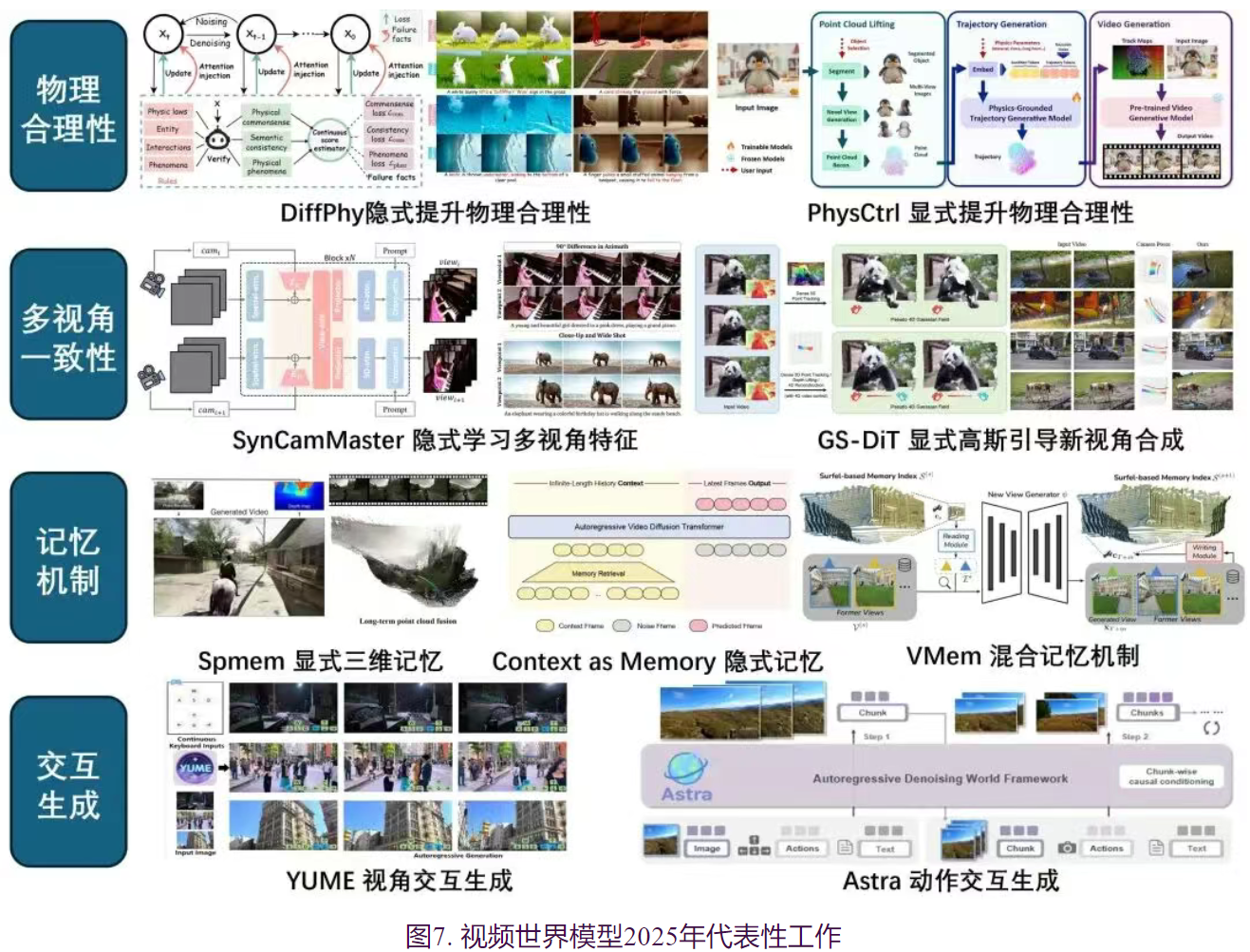
在提升视频生成结果的物理合理性方面,现有方法主要分为两类:隐式先验注入与显式先验注入。隐式先验注入的方法将视频理解模型的物理先验知识蒸馏至视频生成模型,在尽可能保持原始视频模型架构的情况下引入新的优化约束项,隐式提升视频结果物理合理性。
- DiffPhy使用大语言模型在物理常识、语义一致性和与预期物理现象等方面添加额外的约束项,并添加新的注意力层关注不合理的物理情境。
- VideoREPA将视频理解模型(VFMs)的物理能力迁移到生成模型,提出词元关系蒸馏损失函数,提升物理合理性。对比隐式方法,显式先验注入方法构建场景或物体的几何代理,显式预测物体的运动状态后以引导视频生成。
- VLIPP 基于多模态模型预测二维包围盒的运动轨迹;
- ReVision 提取粗糙视频中的三维形状与运动信息,结合参数化物理模型(PPPM)优化结果;
- PhysCtrl 则将物体分割并重建为三维点云,再基于扩散模型生成物理轨迹。
- 此外,部分方法在生成视频的时同步生成动作/3D表征,联合视觉表观先验与物理约束,提高世界模型的几何与物理感知能力。例如,VideoJAM引入光流信息,TessertAct同步生成深度和法向信息,4DNeX则约束生成4D点云场景。值得注意的是,商业模型如Sora 2和Veo3在物理合理的视频生成方面也取得了很好的效果。
除了基于数据驱动方式,直接在重建的三维场景上显式地集成物理仿真引擎,并生成物理真实的结果也出现了许多工作。目前方法主要探索基于三维高斯泼溅的场景加入物理方程约束,例如,RainyGS生成视觉和物理真实的降雨仿真效果,FieryGS引入燃烧和炭化方程,模拟符合物理规律的火焰传播和烟雾生成。
多视角一致性是世界模型实现空间连贯感的关键。现有研究也可分为隐式学习与显式学习两类。隐式学习方法采用数据驱动的路径,需要使用渲染引擎或特殊方法采集的多视角数据,并对视频模型结构进行调整,隐式学习多视角特征,实现多视角一致性视频生成。
- ReCamMaster将相机轨迹输入到DiT视频生成模型,实现已有视频的新视角变换。
- SynCamMaster和SV4D 2.0同步预测多个视角的视频结果,并扩展引入多视角注意力,提升多视角一致性。
- 与隐式方法不同,显式学习方法则采用”3D重建-新视角渲染-引导生成”链路,将粗糙投影结果作为条件,引导扩散模型重绘与生成视频细节,实现多视角几何一致且纹理逼真的视频生成。
- ViewCrafter从稀疏图像出发,实现精确相机控制的场景的新视角合成。
- TrajectoryCrafter将上述思路扩展至动态场景,由动态点云引导新视角合成。点云以外的三维表示也被用作控制信号,例如DaS采用3D轨迹视频,而GS-DiT则采用4D高斯表示。
三维高斯的渲染结果真实且本身具备良好的三维一致性,也可用于构建世界模型。例如
- GWM采用了与LDM类似的思路,使用VAE对高斯场景进行压缩,并在隐态空间中构建扩散模型。
- 另一类方法则更加深入的利用3DGS的显示特点,对高斯球进行三维变换,生成未来场景。例如,GaussianWorld根据自车移动进行仿射变换,生成新区域并添加物体运动信息,得到未来状态。ManiGaussian++针对双手机械臂场景进行设计,构建主导变形模型和跟随变形模型对高斯进行变换,模拟物体抓取等操作。
基于视频生成构建世界模型的关键问题之一是确保长视频生成过程中的时空一致性,需要构建记忆机制。当前的工作主要也可以分为显式记忆和隐式记忆两类。显式记忆方法使用三维重建技术作为载体,直接对3D记忆进行渲染作为输入。例如,
- DeepVerse和EvoWorld在预测未来视频结果的同时构建点云场景,引导后续生成。
- Spmem构建了三类记忆模块,包括短期、长期和稀疏情景记忆,实现长时序生成。
隐式记忆方法使用Transformer的Context窗口或KV Cache存储历史信息,避免重建误差。例如,
- Context as Memory根据视野范围对历史帧进行检索并提供上下文信息,
- FramePack根据重要性对历史帧进行压缩,高效生成时序一致的长视频结果。
- 相关工作也提出混合记忆机制,采用隐式记忆和弱三维重建的路径。例如,VMem和RTFM基于重建的点云场景或空间位置和朝向信息检索历史帧,引导预测未来状态,期望融合显式和隐式的优势。
视频世界模型交互式生成也是重要研究问题。
- 一类交互式方法关注于从视频数据中学习视角交互信息,以增强模型的空间理解能力。例如,YUME将相机的相对位置和朝向变化使用文本编码,控制视频生成;NWM将相机参数作为AdaIN参数,并使用交叉注意力融合前序帧特征。
- 另一类交互式方法则以额外的用户动作或机器人动作为输入,实现对视频内容交互生成。例如,Astra提出了ACT-Adapter的模块,编码动作信息并注入至视频模型;DWS提出了运动强化损失,更加关注由动作引起的视频的区域变化。工业界在交互式视频世界模型领域也快速发展,例如腾讯开源了混元世界模型1.1;昆仑万维开源Matrix-Game 2.0。Google发布了Genie3,可以实时生成数分钟长的视频结果,并模拟主体和环境的真实的交互效果,也可以确保长时序的一致性。WorldLabs发布了Marble,可以通过单张图像或文本创建三维世界,并且支持交互式的编辑、扩展和融合,得到多种表示的场景输出结果。
除了基于视频模型的方法,隐空间世界模型,通过在特征空间中建模动态变化,避免直接进行高维像素级预测,从而实现更高的计算效率与建模紧凑性。这类方法通常借助预训练图像编码器或自监督视频表示模型,在隐态特征空间中进行时间序列建模与未来状态预测。典型工作包括Meta FAIR团队提出的 DINO-world(在 DINOv2 的特征空间中训练视频世界模型),V-JEPA 2(采用自监督学习框架,从视频中学习统一的表示空间)。
以上系列研究验证了构建可交互的物理真实的世界模型的可行性,在多个方面已经展现了惊艳的效果,并在智能驾驶、具身智能和影视游戏等多方面有应用价值。然而,尽管世界模型取得了显著进展,仍有许多值得进一步探讨的问题。
- 首先,虽然已有很多方法探索生成物理合理的视频合成结果,但是如何在任意情景下确保物理可靠性,并支持物理参数的精细化控制仍是值得探索的问题。
- 其次,三维一致和交互式的场景生成在长时序生成方面仍面临瓶颈,如何实现真正无限场景的生成并实现完全准确的历史记忆仍值得研究。
- 最后,尽管现有方法实现了虚拟场景的构建和模拟,如何对真实的场景进行虚拟复刻,并且支持一系列探索和交互也是值得探索的方向。
六、理解与生成统一的多模态大模型,服务空间智能感知
空间智能(Spatial Intelligence) 在2025年被学术界公认为VLM从“读图”迈向“世界模型”的关键一步。随着具身智能(Embodied AI)和自动驾驶等领域对物理世界理解需求的爆发,仅具备语义感知的VLM已无法满足实际应用中对三维空间推理、导航和操作的要求。这一年,学术界在空间智能的理论体系、数据构建、架构创新及训练范式上均取得了重要进展,标志着视觉语言模型正式从二维图像的被动观察者向三维环境的主动思考者转变。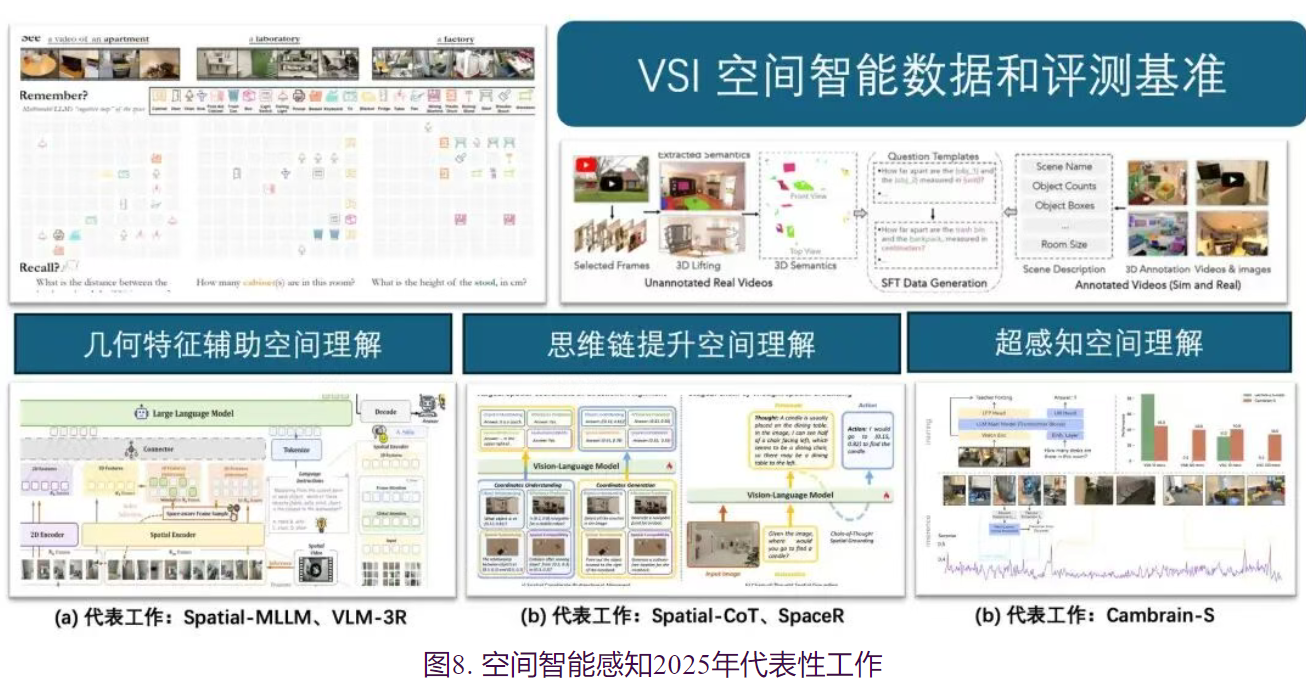
在基础评测基准方面,2025年的综述论文 《Spatial Intelligence in Vision-Language Models》 首次为空间智能建立了清晰的认知层级体系,将其划分为空间感知(Perception,如3D检测)、空间理解(Understanding,如相对位置推理)以及空间外推(Extrapolation,如心理旋转与路径规划)三个递进水平。为了精准评估这些能力,VSI-Bench(Thinking in Space)引入了基于视频的“看、记、忆”(See, Remember, Recall)评估范式,考察模型在观测环境后构建隐式“认知地图”的能力。此外,RealWorldQA 和 OmniSpatial 等综合基准的推出,覆盖了从基础感知到复杂逻辑推理的全方位能力,揭示了当前模型在跨认知层级整合方面的不足。
在 训练数据方面,2025年见证了空间专用数据集的爆发式增长。据统计,仅在2023至2025年间就涌现了21个主要的空间训练语料库,数据量级呈现出明显的加速趋势。研究重心从通用的图文匹配转向了更具针对性的空间指令微调。例如,
- 为了支持长时程空间记忆的训练,Cambrian-S 构建了包含59万条指令的大规模数据集 VSI-590K,涵盖了空间计数、距离估计等细粒度任务。尽管数据规模在扩大,但综述也指出当前数据仍存在“认知不平衡”和“模态单一”的问题,即侧重于静态2D图像的简单关系描述,而缺乏涉及3D几何变换和动态预测的高阶数据。
在 模型架构方面,核心突破在于打破2D视觉与3D物理世界之间的壁垒。针对传统VLM过分依赖CLIP等2D语义特征、导致几何感知缺失的问题,Spatial-MLLM和VLM-3R等方法引入预训练的视觉几何基础模型(VGGT/CUT3R)作为独立的3D空间编码器, 这些专用的空间编码器能够从多视角图像(Multi-view Images)或视频流中提取显式的3D几何特征——包括深度信息、相机位姿变化以及场景的三维结构流——从而 弥补了传统ViT在处理空间深度和透视关系上的先天不足。
在 训练方法方面,研究发现传统的监督微调难以赋予模型复杂的空间逻辑,因此强化学习(RL)和思维链(CoT)成为了新的破局点。
- 为了增强推理的逻辑性,Spatial-CoT 训练模型首先生成空间坐标和推理依据,再输出最终答案。
- 更进一步,SpaceR 和 ViLaSR 等工作引入了强化学习框架(如GRPO算法),通过设计空间特定的奖励函数,鼓励模型在复杂的动态场景中生成符合物理规律的推理路径。这种从“模仿学习”到“强化推理”的转变,显著提升了模型在未见场景中的泛化能力。
作为2025年空间智能领域的压轴进展, Cambrian-S 的提出标志着该领域向“空间超感知”(Spatial Supersensing)与世界模型的演进。针对现有模型在长视频中记忆模糊的痛点,Cambrian-S 提出了“预测即感知”(Predictive Sensing)的理念。该模型不再被动处理每一帧,而是像人类大脑一样,利用下一帧的潜在特征预测误差来动态调节注意力,从而在无限视频流中高效地管理记忆。
同时,多模态模型逐渐从单一的理解或生成功能走向统一理解和生成的多模态输入、多模态输出模型。以Bagel为代表的统一多模态模型(Unified Multimodal Models,UMM),将视觉理解、视觉生成和编辑等任务统一,进一步展现出了图文交错生成和多模态推理的能力。这些统一多模态模型领域的新进展,给下一代统一感知、理解、重建、预测的空间智能多模态模型奠定了基础。在具身智能领域,WorldVLA等模型通过统一多模态模型,将视觉和指令理解、图片预测、和动作预测统一在VLA模型中,提升了VLA模型对于视觉环境中的物理理解能力和动作预测能力。
七、数字人前沿转变:从外观建模到多模态交互
2025年数字人技术方面,基于三维表征的,特别是基于高斯泼溅的头部与全身数字化身重建技术继续推进,尤其在基于单张或多张图像输入的高效、高保真重建方面涌现出多种创新方法。在头部重建领域:
- FlexAvatar (Kirschstein et al.) 展现出强大的泛化能力,通过基于Transformer的3D肖像动画模型,可实现在单目和多视角数据集上进行统一训练,确保泛化性的同时得到3D人头的一致性,实现了从单张图像创建高质量且完整3D头部虚拟人的方法。
- RGBAvatar提出了一种简化的高斯混合蒙皮,可从单目视频输入中快速的重建出人头化身,并且可以支持实时交互。
- 对于多图输入场景,Avat3r和FastGHA提出了绑定在四张输入图像像素空间的高斯表达可动画三维头部化身;
- FlexAvatar(Peng et al.)与FastAvatar(Wu et al.)均提出了基于前馈网络的快速重建架构,可从任意数量的输入图像中高效复原三维模型;此外,GUAVA和Bringing Your Portrait to 3D Presence则是提出了一种能够支持头部、半身乃至全身输入的可动画三维化身重建的前馈生成式框架。
- 在全身数字人构建方面,TaoAvatar和mmlpHuman通过构建轻量化的MLP训练范式,能够从多视点单人采集数据中重建出逼真、可驱动且支持实时渲染的高质量全身高斯数字人;在全身人体3D化身建模方面,虽然如 PERSONA、LHM、IDOL、PGHM等融合了二维视频和三维数据进行可泛化重建,但通过单视频或单图重建的数字化身效果仍不尽人意,难以捕捉服装的高逼真飘动。

除了上述3D外观建模技术的扎实推进,2025年数字人生成技术正逐步从纯视觉效果导向的“外观建模”向全方位“基于多模态交互的数字人生成”转型,这一技术变革在产业界表现突出。随着大语言模型、视觉模型与多模态感知体系的协同发展,各大头部厂商已推出具备语音、动作、情感和环境感知能力的多模态数字人系统。以OpenAI Sora-2、字节跳动M3-Agent为代表的工作,通过整合语音识别、自然语言理解、情绪识别及动作合成等多模态技术,推动数字人由静态形象迈向具备智能交互与个性化表达的“数字生命体”。
以音视频为核心的二维生成技术是多模态数字人技术的重要分支,主要强调音视频同步、人物和场景声音视频联合建模等高仿真视听效果的呈现。这一技术路线通常包括音频驱动和音视频联合生成两个主要方向。其中,音频驱动数字人视频生成方面,如InfiniteTalk,专为无限长序列配音设计,采用流式生成架构,充分利用时间上下文帧实现无缝片段过渡,并通过精细参考帧定位提升音乐、语音与视频片段衔接的流畅性和控制精度。其凭借无限长度生成能力及唇形、头部、表情与姿态的精准同步,已迅速成为语音驱动虚拟人领域的主流工具之一。 AnyTalker则将主流的单人说话方法扩展为多人对话视频生成框架,采用灵活的多流结构,仅利用以单人说话为主的数据集即可实现真实一致的多人对话,既能实现identify的大规模扩展,又能确保不同ID间的无缝互动。
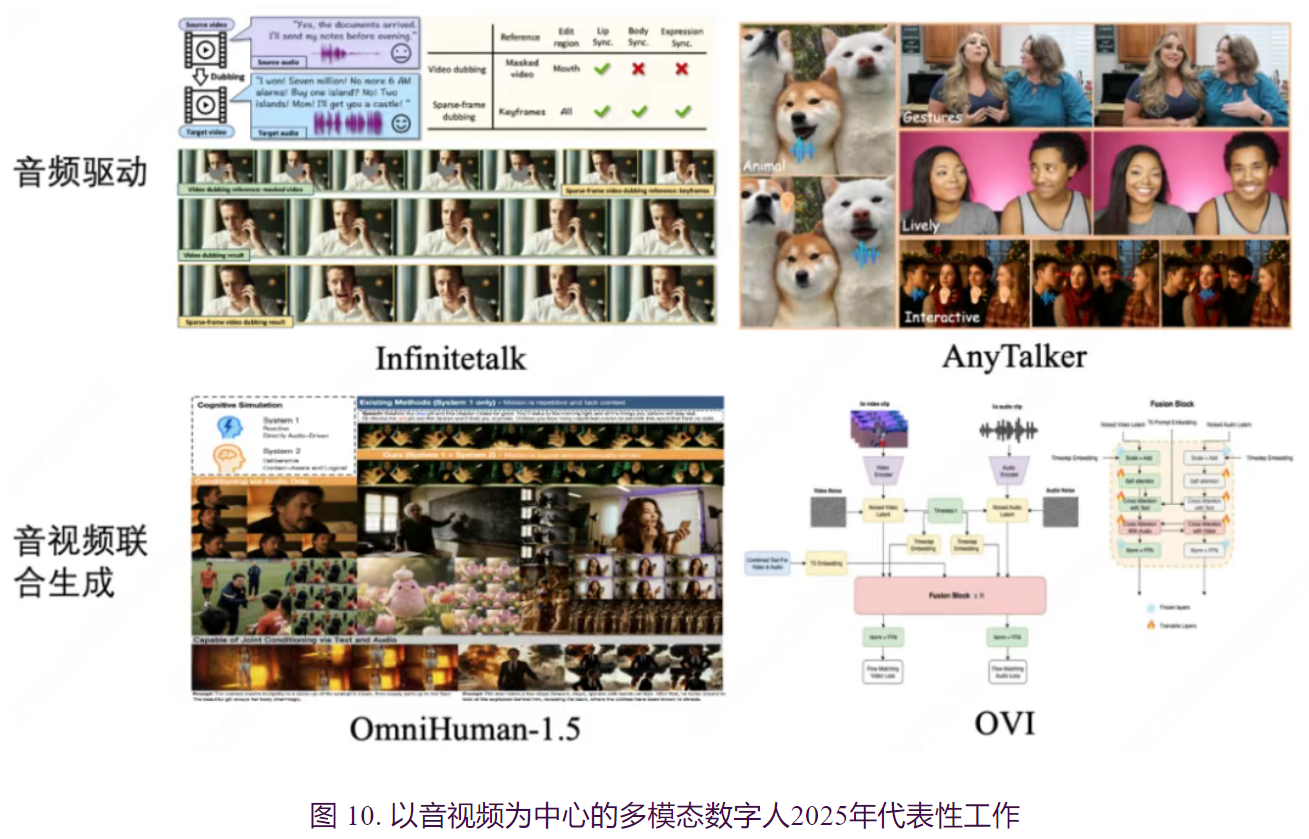
音视频联合生成方面则以OmniHuman-1.5和OVI为代表。
- OmniHuman-1.5通过多模态大型语言模型,合成结构化文本表示并提供更强语义引导,实现动作、语音和视频内容的联合建模。该方法不仅能够生成兼具语境理解与情感共鸣的动作,还能够实现在听觉和视觉两个维度上的多感官用户体验,将传统以单模态生成为核心的任务(例如音频驱动的视频生成)扩展至更高维度。随着相关技术的发展,应用场景也得到了广泛拓展,由此前主要依赖音频输入的生成模式,升级为可通过文本输入实现短视频、电影、虚拟数字人等高定制化内容的生成,提升了生成结果的可控性和多样性以及用户体验。
从交互的角度而言,主流方法可划分为多模态交互和物理交互两个研究方向。其中,多模态交互聚焦于对文本、音频及视频等多维信息的深度融合,这些信息既可作为任务的输入,也可作为输出结果。与以内容生成为核心的音视频联合生成任务不同,交互类方法更加强调系统的智能性,要求能够准确理解用户的意图并做出合理响应,从而实现更高水平的人机交互体验。近期主流数字人交互系统,例如M3-Agent、Qwen2.5-Omni、InteractiveOmni、M.I.O、X-Streamer、ORCA和FlowAct-R1,普遍采用模块化设计,将整个交互过程分为“思考”与“回复”两个核心环节。其中,“大脑”模块聚焦于理解用户询问及相关语境,“渲染”模块则负责将高维交互信号转化为用户可感知的视频或音频内容,显著优化了响应的自然度和流畅性。在此基础上,M3-Agent进一步引入记忆模块,赋予系统持久的长时记忆能力,实现上下文连贯且个性化的智能互动。
- X-Streamer通过创新性的流式结构,有效支持了无限时长的实时交互需求。
- M.I.O则针对人脸与身体动作进行了独立处理,在交互的同时可以实现更加真实拟人的视觉效果。
- ORCA通过闭环的观察-思考-行动-反思循环及分层双系统架构模拟内部世界模型, 使虚拟人能够自主推理、验证结果并实时修正错误。
- FlowAct-R1则通过diffusion forcing训练策略实现了误差更少的长序列交互,并利用蒸馏和系统优化进一步降低了延迟。这些交互方法均以智能为核心,并通过融合长时记忆、实时响应、真实观感等多维功能,进一步增强系统的智能表现。这一技术进步有效推动了数字人从以内容生成为主的模式向以虚拟智能体为核心的模式转变,显著提升了虚拟人系统的交互性与智能水平。
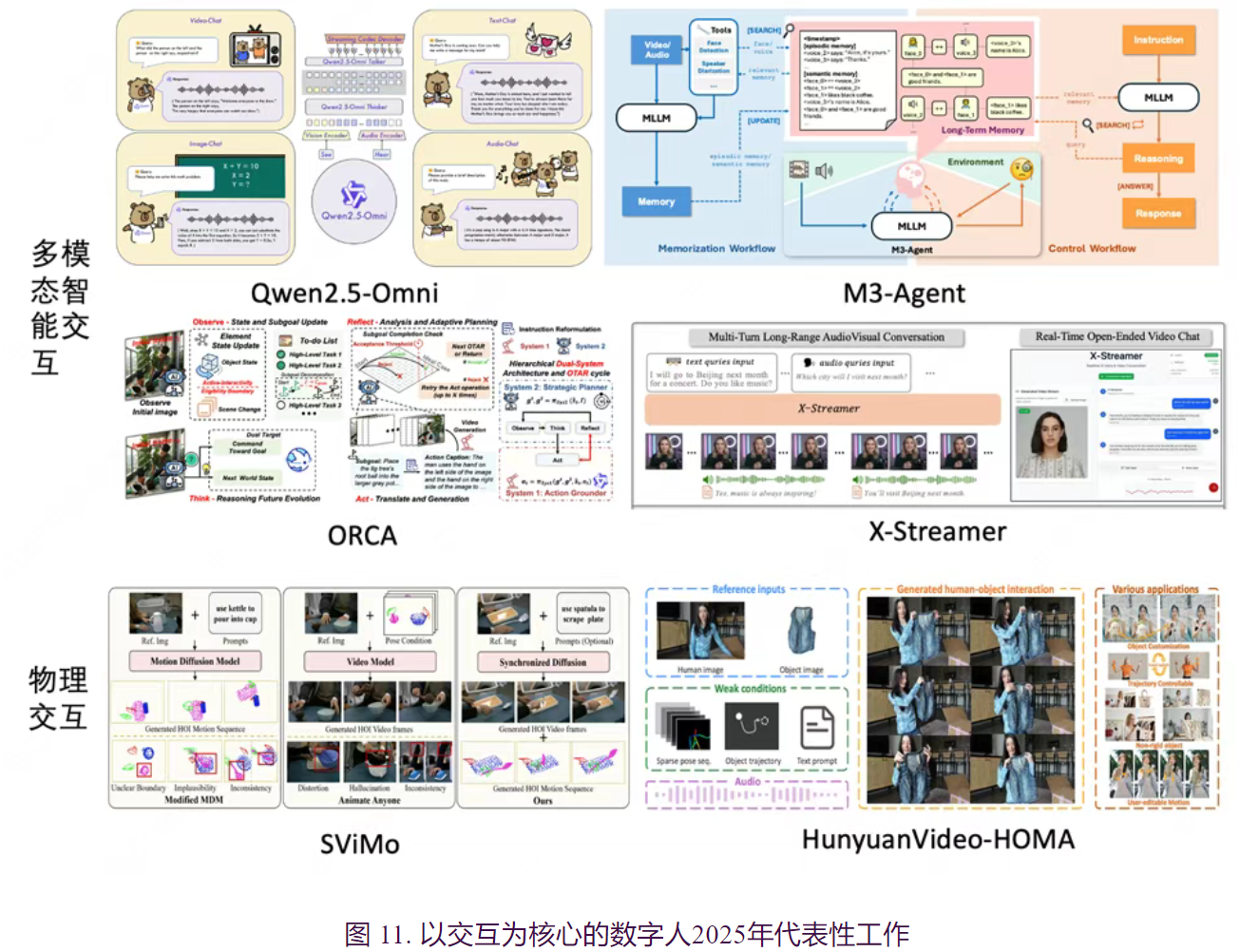
物理交互则侧重于人与周围物体和环境的实际接触与融合。
- SViMo将视觉先验与动态约束相结合,实现了在扩散模型框架下同步生成手-物交互的运动信息与视频内容,有效提升了物理合理性与交互真实感。
- HunyuanVideo-HOMA提出了基于弱条件约束的多模态驱动方法,通过稀疏且解耦的运动引导策略,达到了对手-物交互过程的灵活可控性。
- UniMo通过统一的自回归建模框架,将二维人体视频与三维人体运动信息进行整合,探索了二维与三维数据之间的对齐机制。
- SCAR聚焦于开放环境下手-物交互的泛化能力,通过结构与接触感知的表征增强了生成结果的物理一致性。
总体而言,上述方法扩展了传统以运动生成为主的物理交互研究至视频生成领域,进一步强调了多功能融合与生成视频的物理合理性。
展望未来,数字人技术的发展将以多模态融合与智能交互为核心,不断迈向更高的实用性与便捷性。首先,实时性作为交互过程中的关键性能指标,未来的技术演进将力求在保证生成效果的基础上,实现更为高效的实时交互反馈。其次,长序列生成能力也将成为重要的发展方向,有助于提升数字人在复杂场景中的表现力。与此同时,更高精度的控制机制将成为研究重点,为短视频、电影等内容创作带来更加便捷和自动化的技术支持。最后,具备更强认知和推理能力的智能“中枢”将成为数字人技术不可或缺的组成部分,为构建具备自主决策和更高层次交互能力的智能体奠定坚实基础。
八、人类数据成为突破具身智能 Scaling Law 的重要燃料
高质量机器人本体数据的匮乏已成为制约具身智能 Scaling Law 生效的最大短板,人类数据不再仅仅是模仿学习的参考,而是跃升为训练具身大脑的重要燃料。人类的操作空间天然构成了机器人操作空间的“超集”,人类视频中蕴含的物理常识、因果推理及交互偏好,正是机器人所缺失的“通用物理直觉”。目前,具身智能领域研究中主要三大数据组成为 人类遥操作数据、手持机械末端(Universal Manipulation Interface, 缩写为UMI)操作数据和人类视频操作数据 。这一年,陆续涌现出基于UMI和人类操作数据的操作策略学习方法,标志着具身领域逐步从机器人本体数据向人类视频数据中学习转变的趋势。本节将在UMI数据、人类视频数据、基于人手数据的学习等方面回顾2025年度的代表性研究工作。

人类遥操作机器人本体执行的操作轨迹 是最直接具身学习数据,然而该数据采集方式受本体设备的高昂复杂、采集效率等制约。人手手持末端UMI方案在2025 年受到了更多的关注,该方案既保留了人类操作的灵活性,又在物理上天然对齐了机器人本体,极大地降低了全量遥操作的高昂成本与空间消耗。2024年,UMI通过手持式夹爪与精心设计的交互接口,实现了便携、低成本、信息丰富的人类操作数据采集。该工作确立了“手持末端”的采集范式。2025年,FastUMI 通过解耦采用解耦的硬件设计,并融入了广泛的机械改进,消除了对专业机器人组件的依赖突破;DexUMI 设计了和五指灵巧手手同构手持末端,突破了现有UMI的灵巧性瓶颈。这些衍生方案在灵巧度、感知维度与构型适应性上进行了全面升级,而工业界的相关工作演示初步展示了通过大规模UMI数据积累进行scaling的潜力。Generalist AI 提出的 Gen-0 基础模型则通过大规模扩展这一思路,利用高达27万小时的真实世界操作数据进行训练,展现了跨形态、跨场景的强大泛化能力。Sunday Robotics 公司则演示了该类方案对三指夹爪等工业构型的强大适应性。
在人类操作视频方面,采集并解析第一人称视角数据是2025年三维视觉在具身领域突破的重要方向。EgoZero 提出了极具颠覆性的“Smart Glasses Only”方案,证明了仅凭智能眼镜采集的第一人称视频即可训练闭环机器人策略。随着硬件性能的提升,EgoDex 数据集利用 Apple Vision Pro 的空间计算能力,构建了包含全身 3D 姿态及高精度手部追踪的富信息数据。Ego4D、EgoLife、Epic Kitchen、100DoH 以及 Motion-X 等大规模数据集的持续迭代,汇聚了全球各地的海量第一人称生活视频。针对单纯视频数据缺乏具身操作领域最重要的接触信息缺失问题,VTDexManip通过自研低成本压阻传感器触觉手套,构建了大规模人类复杂操作的视频和触觉集,并设计了18种非预训练和预训练方法,并对它们进行了比较,以研究不同模态和相关策略的有效性。
不同于遥操作和UMI数据直接对齐到目标机械手并涵盖了机械手本体的物理和动力学学术,人类视频数据缺乏这些对于具身本体执行最重要的信息。挖掘人类视频对于具身技能学习的先验是2025年 的研究热点。
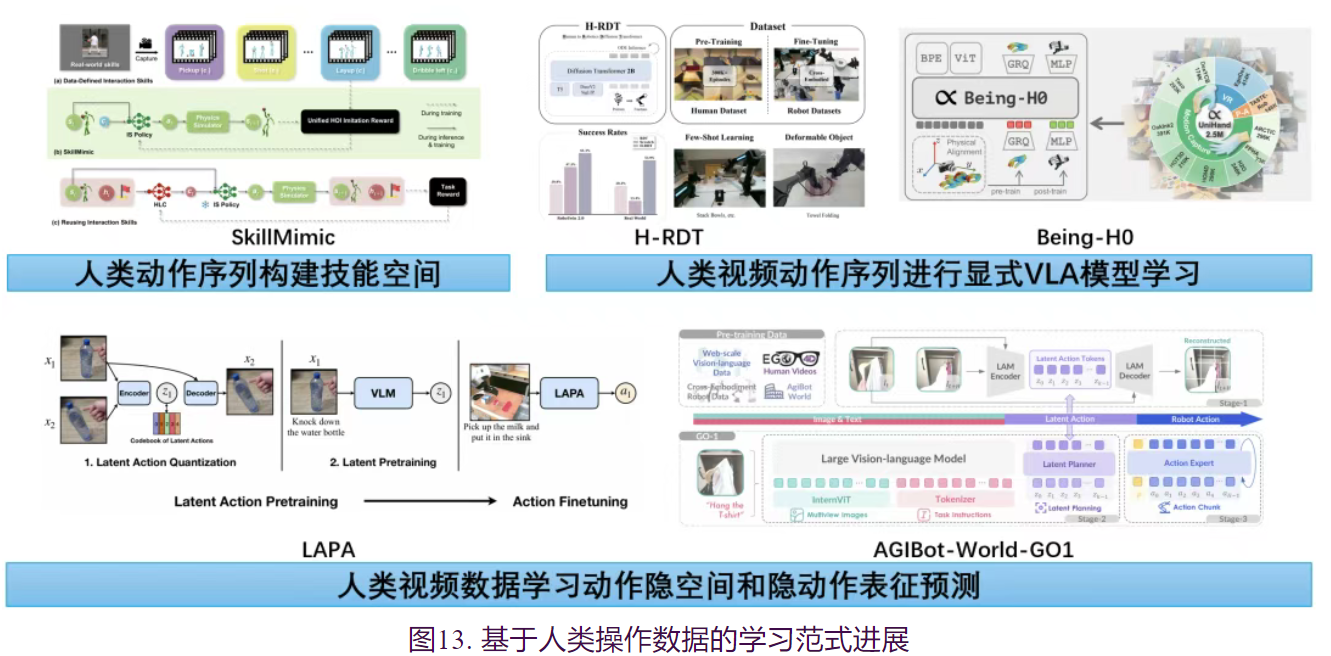
1.人类动作序列构建技能空间
在全身的具身人形智能体研究方面,从早期的DeepMimic到ASE工作,研究重心逐渐从单一动作的物理模仿转向构建通用的隐式技能空间,使人形智能体具备了复用人类基础运动能力的潜能。在此基础上,2025年的研究进一步聚焦于复杂交互技能的迁移,SkillMimic 与 InterMimic 通过在物理仿真中引入大规模人类演示数据,让智能体习得符合动力学约束的通用人-物交互策略,突破了传统模仿学习在物理一致性上的瓶颈。同时,生成式模型正在成为技能数据的扩充器,Sitcom-Crafter与Human-X等工作结合大模型能力,能够生成长序列、情节驱动的复杂交互数据,为具身智能体提供了近乎无限的虚拟演练场景。这种高质量的合成数据结合Token-HSI和MaskedManipulator等多任务联合建模架构,实现了从高层语义理解到全身精细操控的端到端贯通,使得合成人类技能数据同样有潜力能作为关键数据支撑,助力智能体在物理世界中实现更通用的灵巧操作和技能迁移。
2.人类视频动作序列进行显式VLA模型学习
在人类操作研究方面,从人类视频中中直接显式重建人手操作动作并基于该操作动作序列构建VLA模型学习成为2025年从人类视频中学习的主要范式。Being-H0 提出了一种基于显式运动建模的预训练范式,利用部件级动作编码将人类手部作为“基础机械手”,通过物理指令微调实现了从人类视频到机器人灵巧操作的毫米级精度迁移。H-RDT 验证了大规模人类数据预训练的有效性,证明了在海量人类数据上训练 Diffusion Transformer 骨干网络后再进行跨具身微调,能显著优于仅使用机器人数据的基线。相对于基于VLA的预训练后微调的方式,构建统一动作空间使得人类视频数据和机器人数据可以进行混合训练。因此,EgoVLA 提出了“Unified VLA”范式,构建了统一的动作空间,将人类手部姿态与机器人控制指令映射到同一维度,实现了在人类数据集上的预训练与机器人数据上的微调,大幅提升了跨本体泛化能力。VITRA通过将灵巧手和人类数据的状态编码到统一的空间中去做本体上的统一,并在训练过程中将这两种数据进行混合训练Physical Intelligence的论文Emergence of Human to Robot Transfer in VLAs也使用数据分析的方式证明了人类数据在充分预训练后能够和具身本体的数据做对齐。
3.人类视频数据学习动作隐空间和隐动作表征预测
与上述直接进行显式操作动作提取方式完全不同的是,是从视频数据学习图像帧间的离散隐动作空间。LAPA 研究提出一种从无机器人动作标注的网络规模视频中学习的方法:首先通过基于VQ-VAE目标的动作量化模型学习图像帧间的离散隐动作空间,随后预训练VLA模型以根据观测结果和任务描述预测这些隐动作表征,最终在小规模机器人操作数据上对VLA模型进行微调,实现从隐动作空间到机器人实际动作的映射。AGIBot-World-GO1 模型进一步验证了基于 隐动作空间预测的方式可以显著提升 VLA 长程任务的能力和泛化性能。 当前,具身智能领域正从依赖有限机器人本体数据加速转向融合多模态人类数据的新范式。UMI与人类视频数据的规模化应用,以及通过统一动作空间、隐动作表征等方式对数据进行高效对齐与迁移,已初步展现了智能体在复杂长程任务中的泛化与适应能力。展望未来,随着多模态基础模型与物理模拟技术的深度结合,构建从人类经验中提炼“通用物理直觉”的跨本体学习框架将成为关键突破点。这不仅将催生能理解并执行复杂抽象指令的通用机器人,更将推动从“感知-模仿”到类似大语言模型的的具身智能涌现本质跨越,最终赋能机器人在开放世界中自主掌握人类级别的操作技能。
九、具身智能基础模型向理解想象执行一体化统一模型演进
围绕“具身智能体如何建立对世界的内在表征”这一核心问题,具身智能基础模型经历了一个从“直接视觉-语言-动作(VLA)模型”向“内在建模”逐步演进的连续过程。传统的视觉-语言-动作(VLA)模型虽然在指令理解上表现出色,但本质上仍属于“基于当前观测的反应式系统”,缺乏对动作后果的物理预测能力,导致在处理长程任务或强动力学交互时表现出短视与脆弱。为了突破这一瓶颈,2025年的前沿研究呈现出清晰的演进脉络:
- 首先通过“快慢系统”的分层设计,在保留语义泛化的同时引入流匹配(Flow Matching)等生成式策略以提升动作的物理拟合精度;
- 继而引入视频生成模型作为“具身想象器”,利用其内隐的物理规律表征来辅助决策,并解决了从开环想象到闭环控制的实时性难题;
- 最终迈向“理解-想象-执行”的一体化架构,在单一的混合专家(MoT)网络中实现了对过去语义、未来画面与当前动作的联合建模,标志着具身智能体开始具备类似人类的“直觉物理”与“预演规划”能力。
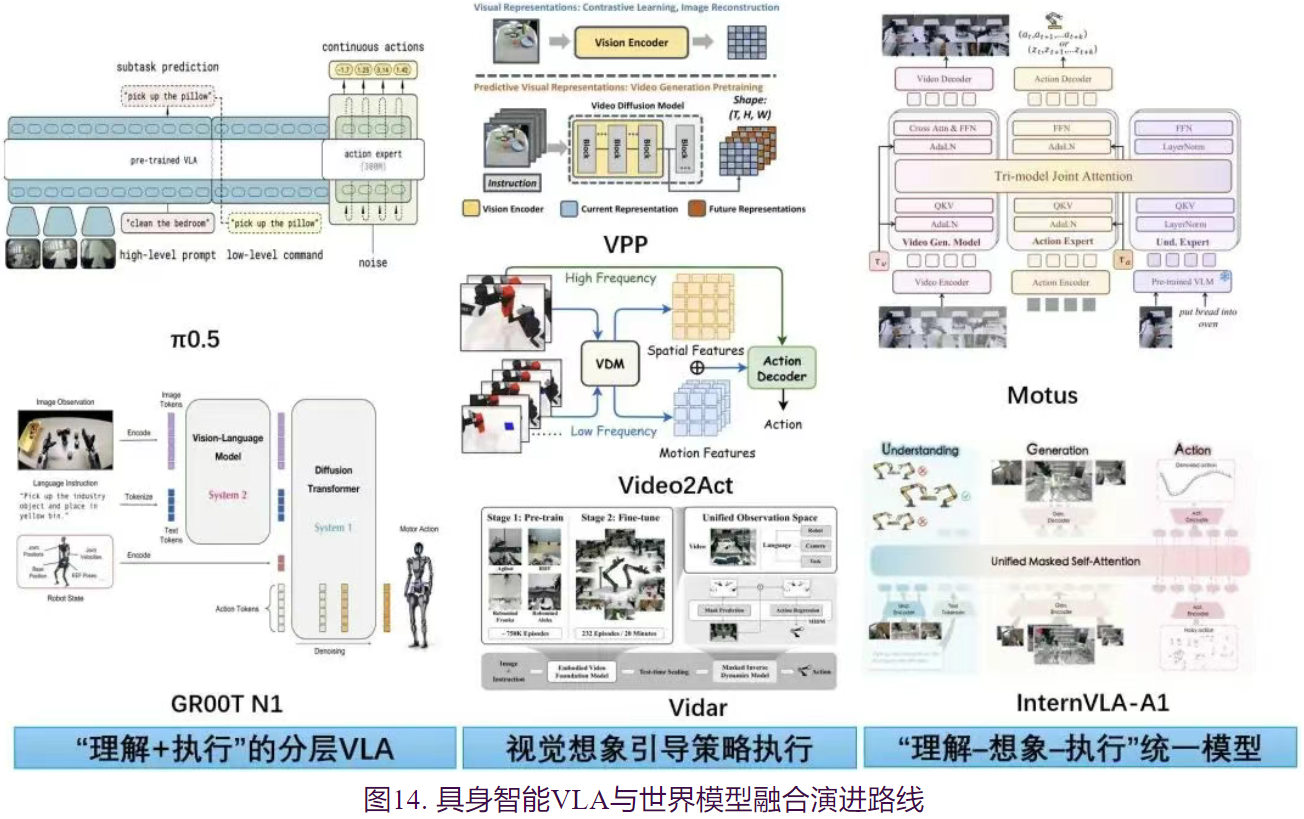
1.“理解+执行”的分层VLA
针对端到端VLA模型在语义广度与动作精度上的权衡难题,新一代模型转向了“系统1(直觉)+系统2(推理)”的异构分层架构。以 π 0.5 \pi_{0.5} π0.5为例,其开创性地采用了两阶段训练范式:预训练阶段利用FAST Tokenizer将视觉、语言和动作统一为离散Token,从而能吞吐包括互联网视频和多机器人数据在内的海量异构数据;后训练阶段则切换至流匹配(Flow Matching)专家模块,专注于将高层语义子任务解码为高频连续动作流,实现了“思维链”式的分层控制。GROOT N1 则进一步将这种解耦推向极致,构建了基于VLM的语义推理模块与基于扩散Transformer(DiT)的动作生成模块,并通过“数据金字塔”策略——底层利用VQ-VAE从人类视频提取潜动作(Latent Actions),顶层使用稀缺真机数据——在保证模型具备通用语义理解的同时,大幅提升了在真实物理环境中的操作鲁棒性。
2.视觉想象引导策略执行
上述“理解+执行”的VLA模型中的VLM基模提供的是静态的语义理解能力,而非对物理过程的动态推理能力。模型虽然知道“该抓哪个物体”,却无法预判“抓取后的物理后果”。为了赋予机器人“三思而后行”的前瞻能力,研究者开始利用视频扩散模型,作为隐式物理引擎。VPP (Video Prediction Policy) 发现视频生成模型的中间层特征隐含了丰富的未来物理动态信息,因此提出直接提取其“预测性视觉表征”来条件化指导动作策略,从而避免了显式生成视频的高昂计算代价。而针对视频预测通常难以用于实时控制的问题,Vidarc 提出了一种基于KV Cache重预填充(Re-prefilling)的自回归推理机制,将实时的环境观测反馈注入视频生成过程,实现了从“离线开环想象”到“在线闭环修正”的突破;同时,该模型引入了掩码逆动力学模型(Masked IDM)与具身感知损失(Embodiment-aware Loss),强制模型在生成未来画面时重点关注机械臂与交互对象的物理一致性,显著降低了幻觉对控制精度的影响。
3.“理解–想象–执行”统一模型
当前主流的视觉-语言-动作模型通常基于多模态大语言模型构建,在语义理解方面展现出卓越能力,但其本质上缺乏对物理世界动态的推理能力。视频预测构建世界模型往往缺乏语义根基,且在处理预测误差时表现出脆弱性。为融合语义理解与动态预测能力,最新的演进趋势旨在打破模块间的壁垒,构建全链路可微的统一大模型,“理解–想象–执行”高度耦合的统一模型范式在今年逐步涌现。InternVLA-A1 采用了混合专家Transformer(MoT)架构,通过统一掩码自注意力机制严格定义了从“语义理解专家”到“视觉预见专家”再到“动作执行专家”的信息流向,使得动作生成显式地建立在对未来物理后果的预测之上,并在5.33亿帧的合成-真实混合数据上验证了其在强动态任务中的优越性。Motus 则进一步提出了“五位一体”的统一潜动作世界模型,其核心创新在于利用光流(Optical Flow)提取像素级的“Delta Action”作为通用动作表征,从而能无监督地利用海量互联网视频进行预训练;配合三模态联合注意力机制与UniDiffuser调度器,模型不仅能在同一参数空间内灵活切换视频生成、动作预测与语义推理模式,更展现出了对未见物理场景的强大零样本泛化能力。
总体而言,VLA结构的演进呈现出一条清晰的认知层级上移主线:从最初的直接函数逼近(模仿动作),到语义条件控制(理解指令)、显式前瞻预测(预演未来),最终走向统一世界建模。这一过程标志着具身智能正从简单的反应式系统迈向复杂的认知型系统。未来VLA范式的核心竞争点,将不再是单一模块的性能堆砌,而是模型内部世界表征的稳定性、可预测性与可控性。当前的统一模型阶段,正是实现这一关键转折的重要里程碑。
十、具身智能的“后训练”时刻:VLA 模型从模仿学习向在线 RL 的范式跃迁
具身智能领域的视觉-语言-动作(VLA)模型正经历着类似于大语言模型后训练阶段的路径演变,即发展重心正从单纯依赖大规模模仿学习,向以在线强化学习为核心的训练范式迁移。在早期阶段,基于多模态预训练与高质量机器人轨迹微调的两阶段监督微调范式占据主导,但随着模型规模的扩展,该范式逐渐暴露出数据不可持续与泛化能力受限的内生矛盾。由于高质量的人类遥操作数据兼具稀缺性与昂贵性,单纯依赖 SFT 进行规模化面临极高的边际成本,且监督学习本质上是对专家演示分布的拟合,导致策略在面对未见场景或长视距任务时往往表现出鲁棒性不足。本
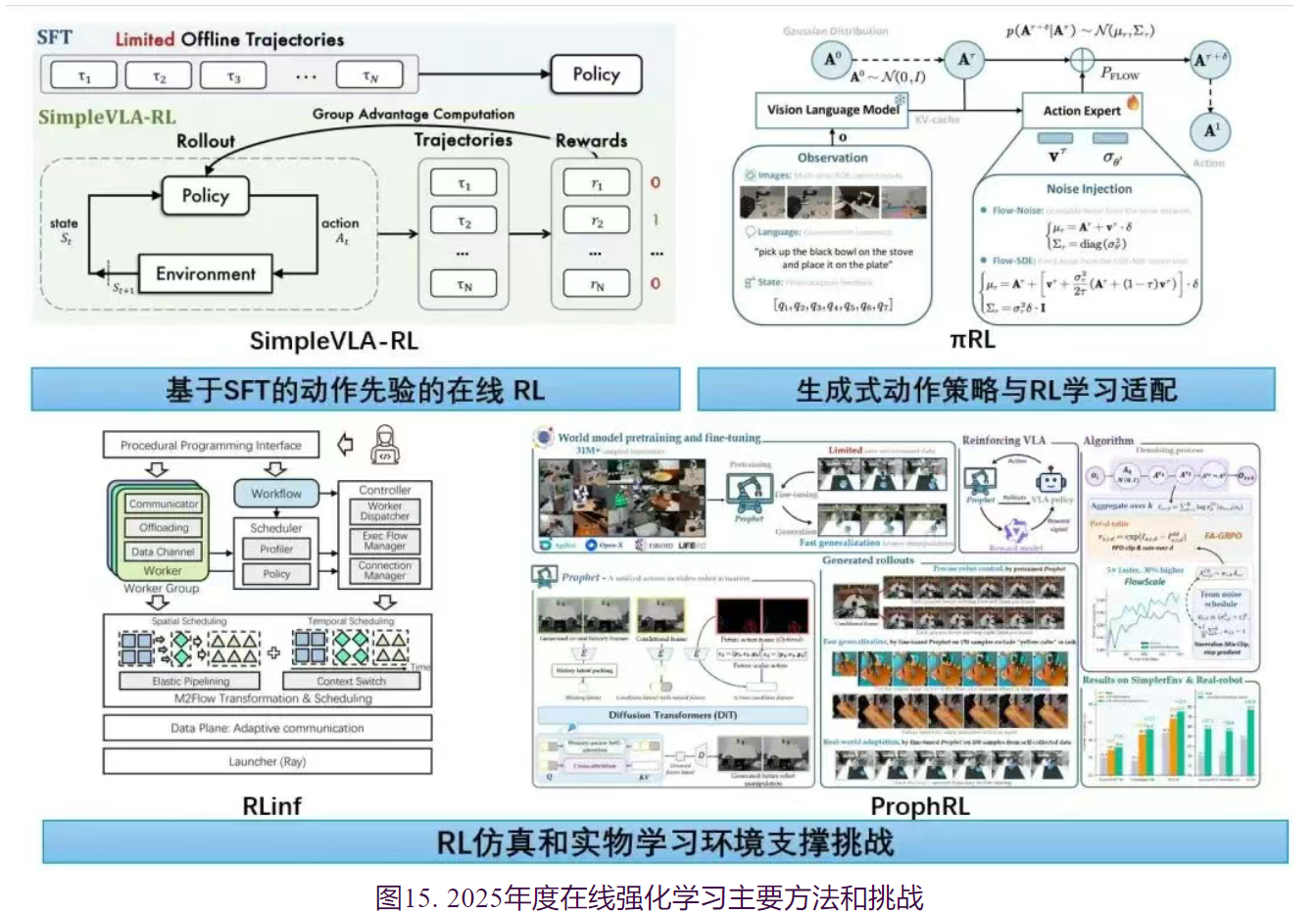
1.基于SFT的动作先验的在线RL
这一范式的核心在于将训练的闭环从“拟合专家轨迹”重构为“采样—评估—更新”的强化学习过程。在SimpleVLA-RL中,SFT 的角色被重新定义为策略的“冷启动”或初始化手段,而非能力增长的主引擎。实验证明即便在极度稀缺的数据设定下(如单条演示轨迹),仅需利用 SFT 提供基础的动作先验,随后的性能提升完全可以交付给在线 RL。通过引入 GRPO 等 On-Policy 算法并结合 Outcome-level 的稀疏奖励,模型能够在缺乏密集标注的情况下,通过与环境的持续交互自我进化。这种机制不仅显著缓解了对昂贵专家数据的依赖,更促使策略从复刻走向探索,允许模型在奖励信号的驱动下搜索更广阔的状态-动作空间,这种机制促使模型产生如“Pushcut”等涌现行为——即发现专家演示中从未出现过的全新操作模式。通过动态采样策略(Dynamic Sampling)和提升采样温度,模型得以在更广阔的状态空间进行探索,显著增强了跨任务、跨物体和跨空间的泛化能力。这种从“复刻演示”到“驱动搜索”的转变,确立了在线强化学习作为具身智能能力持续增长的核心引擎地位。
2.生成式动作策略与RL学习适配
生成式策略架构的演进与 RL 优化接口之间存在显著的适配挑战。随着 VLA 的动作生成头从自回归架构转向连续空间的扩散模型或流匹配。传统RL算法在新架构下面临着确定性 ODE 采样缺乏探索随机性、以及在少量去噪步数下难以计算精确对数似然的困境。针对这一问题, πRL等工作提出了基于随机微分方程(SDE)的改进方案,通过在去噪过程中显式注入噪声并重构概率流,成功将流匹配过程改造为可计算似然且具备探索能力的马尔可夫决策过程。这种架构层面的适配,使得PPO等经典 RL 算法能够有效驱动连续动作空间的VLA模型,在极少监督数据的情况下实现了超越全量 SFT 的性能,验证了在线RL范式在不同骨干架构下的通用性与有效性。ProphRL针对扩散/流匹配式动作头在RL场景中的稳定性问题提出通过将优势比率与更新目标对齐到“环境动作”粒度,并对去噪内部步的梯度贡献进行噪声日程感知的重加权,缓解了连续生成策略在少步采样下易不稳定、更新效率低等难点。此外,π*0.6的RECAP 等方法则另辟蹊径,利用优势调节(Advantage Conditioning)规避了流匹配模型中复杂的策略梯度目标函数,通过在模型输入中注入二值化的优势指示符(Indicator),直接在连续动作空间中提取更优策略。这些适配方案验证了在线 RL 在不同骨干架构下的普适性,使其在极少监督数据下也能超越全量 SFT 的性能。
3.RL仿真和实物学习环境支撑
在线强化学习范式的高效落地,首要依赖于能够处理仿真、采样、奖励计算及策略更新等异构负载的底层系统。以RLinf为代表的高性能训练系统,针对VLA训练中硬件利用率低和训练缓慢的问题,提出了“宏观到微观流转换”(M2Flow)范式。该系统通过将高层逻辑工作流自动分解并重构为优化的执行流,实现了计算资源在空间(跨加速器分配)和时间(上下文切换)维度的灵活调度。例如,在具身智能任务中,RLinf能有效应对模拟器(CPU/显存密集型)与模型生成(显卡核心密集型)之间的资源冲突,通过混合调度模式将端到端训练吞吐量提升高达2.43倍。这种基础设施的进步,使得VLA的“后训练”阶段能够从理论验证走向大规模应用。另一类代表性工作则面向“后训练”交互数据的获取与扩展的关键瓶颈:在真实机器人上进行大规模在线探索往往代价高、风险大且难以并行,而传统物理仿真又难以覆盖复杂视觉与接触动力学。ProphRL通过动作条件世界模型 Prophet在数据驱动的“模型环境”中生成长时序交互 rollouts,为VLA提供可规模化的强化学习训练闭环:策略不再局限于拟合专家演示分布,而是在可控的 rollouts 中进行采样—评估—更新,从而显著降低后训练对昂贵真机交互与高质量遥操作数据的依赖,并强化长视距任务下的鲁棒性与泛化能力。综上所述,VLA 的训练范式正在发生更迭,在线强化学习凭借其对数据的低依赖性、对新策略的探索能力以及优越的泛化性能,正逐步确立为驱动具身智能能力持续增长的核心范式。
总结
本报告系统性梳理与总结了2025年度三维视觉领域的关键趋势与十大前沿进展。在核心技术纵深发展与交叉融合的双重驱动下,三维视觉正从一项专项感知和重建技术,演进为构建空间智能与具身智能的核心基础设施。然而,受限于篇幅与报告聚焦点,一些同样至关重要且活跃发展的方向,如三维导航与路径规划、高精度人体运动捕捉与生成、高斯泼溅数据压缩、2D/3D光影编辑、三维视觉在各领域的应用等,未能在此详尽展开。这些方向作为连接三维感知与最终应用的桥梁,其持续创新对于三维视觉的发展至关重要。由于每个条目的相关工作非常多,许多重要工作也难免遗漏,期待指正。
2025年的突破性进展,无疑为人工智能突破当前以“Scaling Law”为主导的范式瓶颈注入了崭新而强劲的动力。三维视觉所提供的空间结构与物理理解,正在填补大模型所缺失的“世界常识”。与此同时,伴随“世界模型”、“具身智能”、“空间智能”等前沿概念从学术探讨迅速走向产业风口,三维视觉在人工智能宏大叙事中的战略地位已愈发凸显,不再仅是“视觉”的一个分支,而是通向通用人工智能(AGI)不可或缺的物理世界编码与交互界面。
展望未来,三维视觉的发展将不再局限于单项技术的精进,而更在于多重技术栈的深度融合与统一范式的确立。这种融合与统一将主要体现在两个层面:其一,是技术栈的纵向收敛从分立管线到一体化世界模型。 “三维重建(建模)-三维生成(聚合)-三维理解(感知)-视频生成(推演)”的技术链条将加速融合,边界日益模糊。前馈重建将提供实时、鲁棒的环境几何基座;三维生成将聚合场景语义实例对象,视频生成技术将赋予系统对不可见区域的合理想象与对未来状态的物理推演能力。这些技术的深度耦合,正驱动着从静态3D模型到动态4D场景,再到具备物理感知与实时交互能力的“世界模型” 的演进。其二,是应用层的横向贯通从孤立场景到泛在智能基座。 三维视觉的能力将深度嵌入并赋能千行百业。在具身智能领域,机器人的“大脑”(VLA模型)将不再仅仅依赖二维图像特征,而是能够直接基于场景的3D/4D几何与语义表征进行思考与规划。这些丰富的场景表征将通过统一的特征空间,与语言指令、视觉目标、触觉反馈乃至动作原型进行深度对齐与融合,从而极大提升复杂长程操作任务的泛化性、精确性与物理合理性。
展望2026,我们正站在一个范式转变的转折点上:三维视觉不再仅仅是“重建”或“生成”一个数字副本,而是致力于“理解”并“构筑”一个可与智能体交互的、符合物理规律的动态数字世界。这正如杨立昆所倡导的“世界模型”、李飞飞所论述的“空间智能”以及德米斯·哈萨比斯所展望的“物理交互AI”那样,三维视觉将成为实现下一代人工智能,即能真正理解我们所在物理世界的智能,最为关键的基石之一。
#pic_center =60%x80%
d \sqrt{d} d 1 8 \frac {1}{8} 81 x ˉ \bar{x} xˉ D ^ \hat{D} D^ I ~ \tilde{I} I~ ϵ \epsilon ϵ
ϕ \phi ϕ ∏ \prod ∏ a b c \sqrt{abc} abc ∑ a b c \sum{abc} ∑abc
/ $$ E \mathcal{E} E

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 8
8 0
0- 0



 已为社区贡献30条内容
已为社区贡献30条内容

所有评论(0)