LangChain4jRAG知识库:从原理到快速入门
摘要:本文介绍了RAG(检索增强生成)技术,该技术通过检索外部知识库增强大模型生成能力,解决模型无法获取私域和最新知识的问题。文章详细讲解了RAG的核心原理,包括文本向量化、余弦相似度计算等数学基础,并基于LangChain4j框架提供了构建知识库和问答系统的完整代码示例。通过将知识存储与模型推理解耦,RAG实现了低成本、高可控的企业级AI应用开发,是构建智能客服、知识库等系统的有效解决方案。
摘要:在大模型应用开发中,如何让模型掌握私域、最新的专业知识?RAG(检索增强生成)技术提供了完美的解决方案。本文将从零开始,深入浅出地讲解RAG的核心原理、数学基础(向量与余弦相似度),并基于LangChain4j框架,手把手带你完成一个RAG知识库的快速搭建,包含完整的代码示例和架构流程图。
一、 RAG是什么?为什么需要它?
想象一下,你有一个基于GPT-4的客服机器人。它可以流畅地回答通用问题,但一旦涉及你公司内部的、未公开的产品手册、技术文档或最新会议纪要,它就会“胡说八道”或表示不知道。这是因为大模型的“知识”被冻结在其训练数据的时间点上。
RAG (Retrieval-Augmented Generation, 检索增强生成) 正是为了解决这一问题而生。其核心思想是:通过检索外部知识库来增强大模型的生成能力。
RAG核心流程如下图所示:
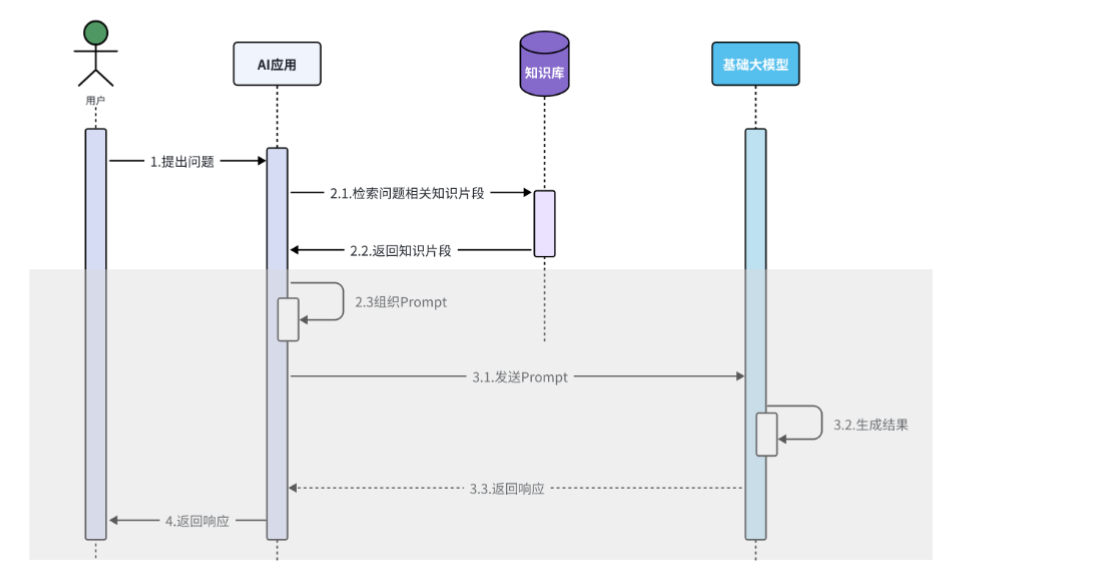
如上图所示,RAG将大模型的记忆能力与推理能力解耦。记忆(知识)存储在可随时更新、扩展的外部知识库中,大模型专注于其最擅长的理解和生成。这种方式成本低、可控性强,是目前构建企业级AI应用的主流范式。
二、 RAG核心原理与数学基石
2.1 向量:知识的数学表示
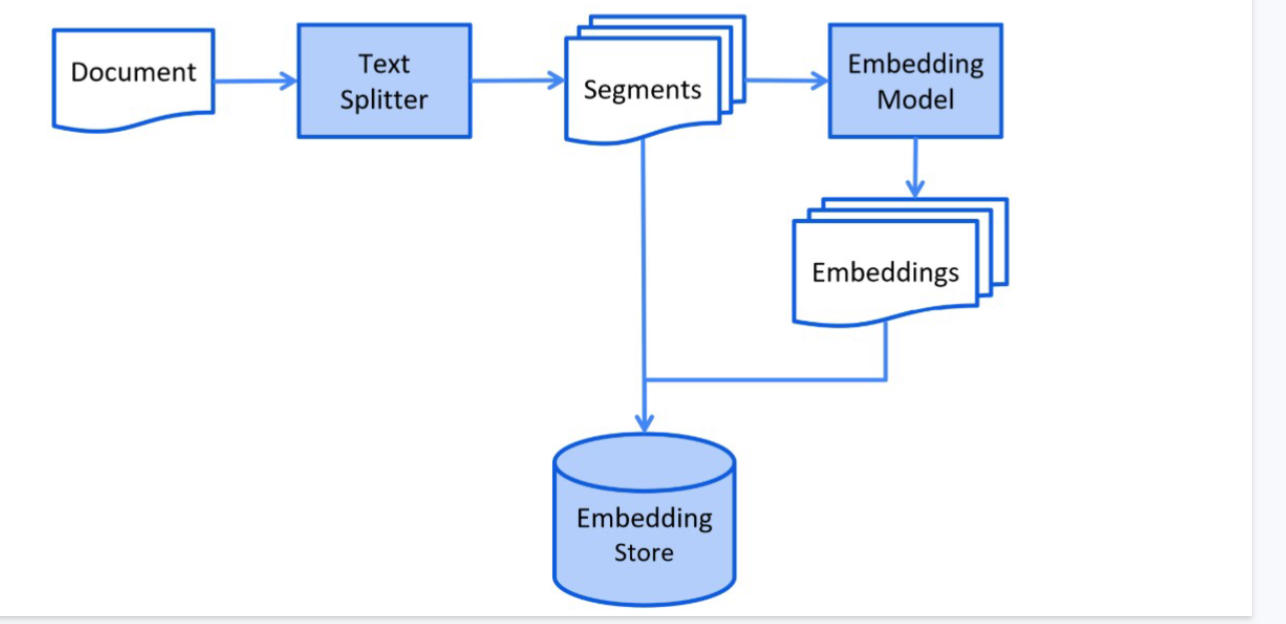
计算机无法直接理解文本。在RAG中,我们将所有文本(无论是知识文档还是用户问题)都通过嵌入模型(Embedding Model) 转换为向量(Vector)。
-
什么是向量? 向量是同时具有大小和方向的量。
-
几何表示:一条有方向的线段。
-
代数表示:一组坐标。例如,在二维平面中,向量
V = (1, 2)。
-
-
文本如何变成向量? 嵌入模型可以将句子、段落映射到一个高维空间(例如1536维)中的一个点。语义相似的文本,在这个高维空间中的向量点距离也会很近。
从文档到向量存储的完整流程如下图所示:
2.2 向量相似度与检索:余弦相似度
知识库中的文档被切分、向量化后存储起来。当用户提问时,系统会在向量空间中,计算查询向量与知识库中所有向量之间的相似度,并返回最相似的文本片段。
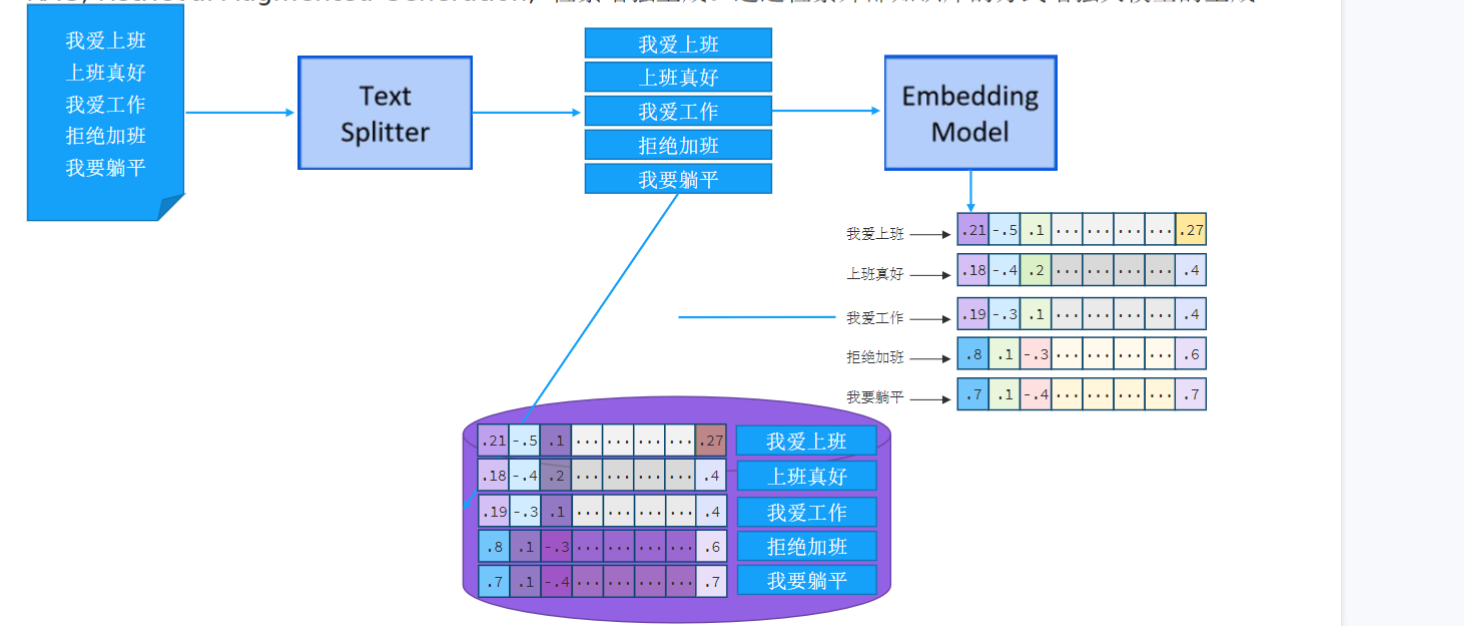
如何计算相似度?最常用的方法是余弦相似度(Cosine Similarity)。
公式:cosθ = (V·U) / (|V| * |U|)
-
V·U是向量的点积。 -
|V|和|U|是向量的模长。 -
cosθ的取值范围在[-1, 1]之间。在文本向量通常所在的第一象限,其范围在(0, 1]。 -
值越接近1,表示两个向量方向越一致,对应文本的语义越相似。
向量与余弦相似度关系图解:
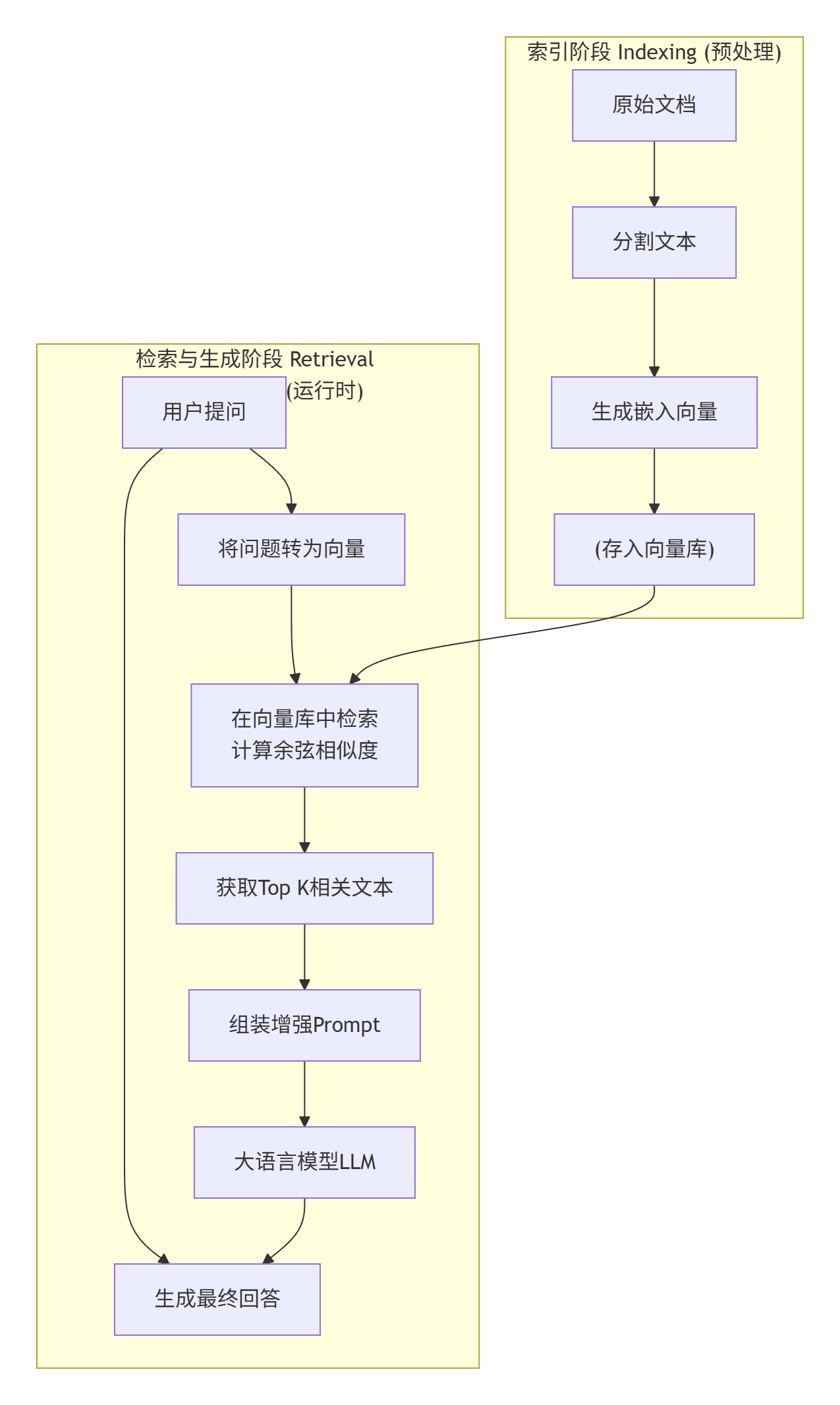
2.3 RAG完整工作架构
结合存储与检索两阶段,RAG的完整技术架构如下:
三、 基于LangChain4j的快速实践
下面我们分两步实现一个RAG系统。
3.1 第一步:存储 - 构建向量数据库
目标:将本地知识文档处理并存入向量数据库。
// 1. 引入Maven依赖 (关键部分)
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
<version>0.31.0</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-embeddings-all-minilm-l6-v2</artifactId>
<version>0.31.0</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-chroma</artifactId> <!-- 以Chroma为例 -->
<version>0.31.0</version>
</dependency>
// 2. 加载、分割、向量化并存储文档
import dev.langchain4j.data.document.*;
import dev.langchain4j.data.document.splitter.DocumentSplitters;
import dev.langchain4j.model.embedding.all.minilm.AllMiniLmL6V2EmbeddingModel;
import dev.langchain4j.store.embedding.EmbeddingStoreIngestor;
import dev.langchain4j.store.embedding.chroma.ChromaEmbeddingStore;
public class KnowledgeBaseIndexer {
public static void main(String[] args) {
// 加载文档
Document document = FileSystemDocumentLoader.loadDocument(Paths.get("your_data.txt"));
// 文本分割器
DocumentSplitter splitter = DocumentSplitters.recursive(500, 100);
InMemoryEmbeddingStore embeddingStore = new InMemoryEmbeddingStore();
// 构建摄取器并执行
EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder()
.documentSplitter(splitter)
.embeddingModel(embeddingModel)
.embeddingStore(embeddingStore)
.build();
ingestor.ingest(document);
System.out.println("知识库构建完成!");
}
}3.2 第二步:检索 - 构建问答链
目标:利用已构建的知识库回答用户问题。
//构建向量数据库检索对象
@Bean
public ContentRetriever contentRetriever(EmbeddingStore store){
return EmbeddingStoreContentRetriever.builder()
.embeddingStore(store)
.maxResults(3)
.minScore(0.5)
.embeddingModel(embeddingModel)
.build();
}代码解读:EmbeddingStoreRetriever是核心,它内部将问题向量化,并与知识库中所有向量计算余弦相似度,返回最相似的文本片段。ConversationalRetrievalChain自动将这些片段组织成Prompt发送给大模型生成答案。
四、 总结与展望
通过本文,我们从概念、原理到实践完整走通了RAG知识库的构建流程。RAG通过解耦记忆与推理,让大模型能够安全、可靠地利用外部知识,是构建企业级AI应用的基石。
掌握RAG,你就掌握了构建智能客服、企业知识库、个性化助手等应用的核心能力。希望这篇博客能为你提供清晰的指引。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 14
14 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)