AI Agent 的分身术:深度解析 OpenClaw 子代理系统设计
摘要 OpenClaw的子代理系统通过三大核心机制实现高效并行任务处理: Session隔离:采用严格的命名规范和权限控制,确保子代理独立运行且无法嵌套创建 上下文精简:子代理仅加载必要配置文件,禁用高风险工具,配备专用System Prompt保持专注 Lane并发控制:通过通道化管理实现差异化并发策略(子代理并发数8>主代理的4) 该系统让主Agent能安全派发多个"影分身&q
AI Agent 的分身术:深度解析 OpenClaw 子代理系统设计
当主 Agent 分身乏术时,如何优雅地派出"影分身"?OpenClaw 的 Subagent 系统给出了一个工程上极其优雅的答案。
🎯 一句话总结
OpenClaw 的子代理系统通过 Session 隔离、Lane 并发控制、上下文精简三大机制,让主 Agent 能够派生独立的"影分身"执行后台任务,实现真正的并行处理——而且不会互相干扰。
📖 为什么需要子代理?
想象一下这个场景:
你让 AI 助手帮你做一个复杂的代码重构任务。AI 需要先搜索代码库找到所有相关文件,分析依赖关系,理解业务逻辑,然后才能动手改代码。
传统做法是串行的:搜索 → 分析 → 理解 → 动手。每一步都要等上一步完成,效率很低。
更糟糕的是,如果搜索过程中需要探索三个不同的方向(比如找认证模块、找测试文件、找组件结构),AI 只能一个个来,不能同时进行。
OpenClaw 的解决方案是引入子代理系统:主 Agent 可以派出多个"影分身",每个影分身独立执行一个任务,完成后自动汇报结果。
这就像老板派出三个员工同时去调研三个方向,而不是自己一个人跑三趟。
🏗️ Subagent 系统架构总览
先来看一张全景图,理解整个系统的运作方式:
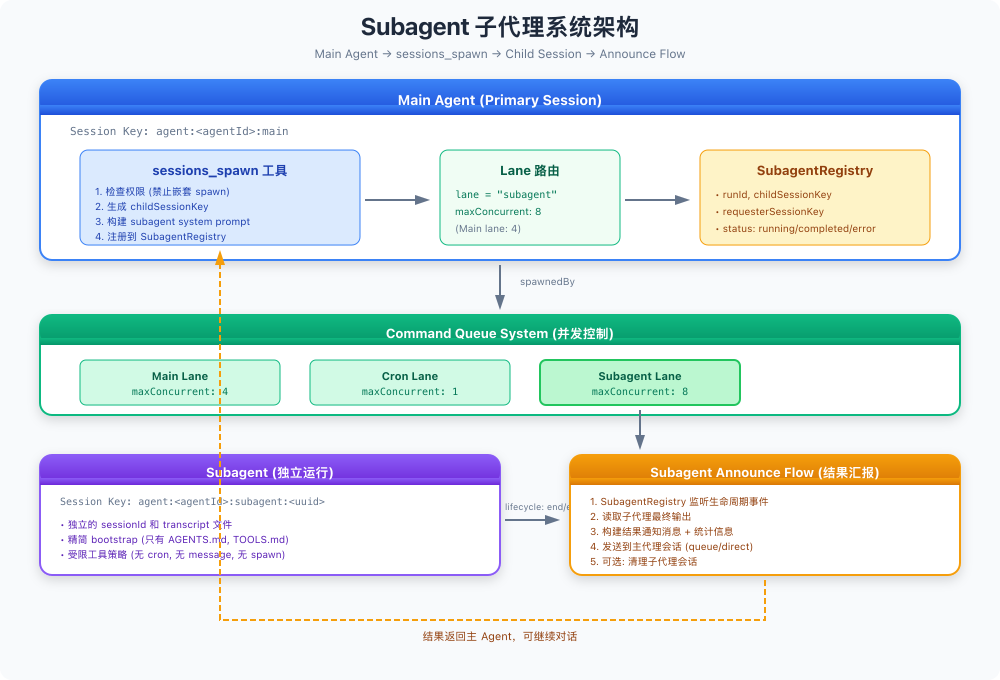
整个流程可以分成四个阶段:
- Spawn 阶段:主 Agent 调用
sessions_spawn工具,创建子代理 - Queue 阶段:子代理进入独立的 Subagent Lane,受并发控制
- Execute 阶段:子代理在隔离的 Session 中独立执行任务
- Announce 阶段:子代理完成后,结果自动汇报给主 Agent
这套系统的精妙之处在于:每个环节都有清晰的边界和职责,不会互相干扰。
🔑 核心机制一:Session Key 隔离
Session Key 命名规范
OpenClaw 用一套命名规范来区分不同类型的会话:
主会话: agent:<agentId>:main
子代理会话: agent:<agentId>:subagent:<uuid>
Cron 会话: agent:<agentId>:cron:<jobId>
这个设计很聪明。通过解析 Session Key,系统可以立即知道当前会话是什么类型,该给它什么权限。
判断是否为子代理
export function isSubagentSessionKey(sessionKey: string | undefined | null): boolean {
const raw = (sessionKey ?? "").trim();
// 快速路径:直接以 "subagent:" 开头
if (raw.toLowerCase().startsWith("subagent:")) {
return true;
}
// 解析 agent:xxx:subagent:yyy 格式
const parsed = parseAgentSessionKey(raw);
return Boolean((parsed?.rest ?? "").toLowerCase().startsWith("subagent:"));
}
这个函数在系统的多个地方被调用:权限检查、Bootstrap 文件过滤、工具策略选择……都依赖它来判断当前是"主人"还是"影分身"。
禁止嵌套 spawn:防止套娃
子代理系统有一条铁律:子代理不能再创建子代理。
// 在 sessions_spawn 工具中
if (isSubagentSessionKey(requesterSessionKey)) {
return jsonResult({
status: "forbidden",
error: "sessions_spawn is not allowed from sub-agent sessions",
});
}
为什么要这么设计?
- 防止无限递归:如果允许套娃,一个失控的子代理可能创建无数个子子代理
- 资源控制:每个子代理都占用资源,嵌套会导致资源爆炸
- 简化追踪:父子关系只有一层,便于管理和调试
这就像公司规定:实习生可以帮正式员工干活,但实习生不能再雇实习生。
🔑 核心机制二:上下文隔离
子代理和主 Agent 最大的区别是:子代理的上下文被大幅精简。
对比图:Main Agent vs Subagent
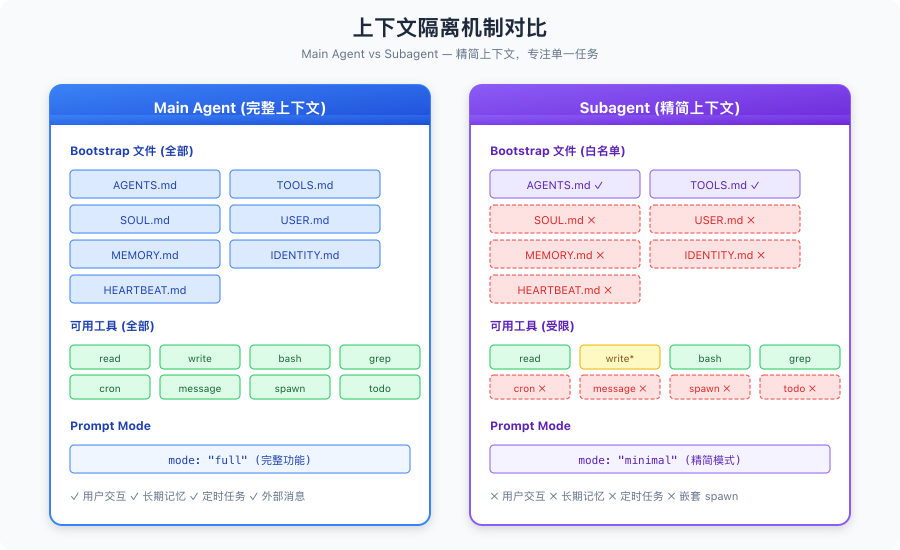
Bootstrap 文件过滤
主 Agent 启动时会读取一堆"启动文件"来建立上下文:
AGENTS.md— 行为规范TOOLS.md— 工具配置SOUL.md— 人格定义USER.md— 用户信息MEMORY.md— 长期记忆IDENTITY.md— 身份档案HEARTBEAT.md— 心跳任务配置
但子代理只能读取其中两个:
const SUBAGENT_BOOTSTRAP_ALLOWLIST = new Set([
"AGENTS.md", // 基础行为规范
"TOOLS.md", // 工具配置
// 不包含: SOUL.md, USER.md, MEMORY.md, IDENTITY.md, HEARTBEAT.md
]);
为什么要过滤掉其他文件?
| 被过滤的文件 | 原因 |
|---|---|
SOUL.md |
人格定义——子代理不需要"人格",它只是执行任务的工具 |
USER.md |
用户信息——子代理不直接与用户交互 |
MEMORY.md |
长期记忆——子代理是短期任务,不需要历史 |
HEARTBEAT.md |
心跳配置——子代理不应该自己设置定时任务 |
这就像派实习生去办事:你只告诉他公司规章制度和可用资源,不需要告诉他老板的人生故事。
工具策略隔离
子代理的可用工具也被限制:
// 子代理默认禁用的工具:
// - cron: 不能创建定时任务
// - message: 不能直接发消息给用户
// - sessions_spawn: 不能嵌套创建子代理
// - todo: 不需要任务追踪(主 Agent 负责)
这些限制确保子代理:
- 不会越权(不能直接联系用户)
- 不会失控(不能创建更多子代理)
- 不会持久化(不能设置定时任务)
专用 System Prompt
子代理有一套精简的 System Prompt:
# Subagent Context
You are a **subagent** spawned by the main agent for a specific task.
## Your Role
- You were created to handle: {task_text}
- Your output will be reported back to the main agent when done
## Rules
1. **Stay focused** - Do your assigned task, nothing else
2. **Be thorough** - Your final message is your deliverable
3. **Complete the task** - Don't ask for clarification, make reasonable assumptions
## What You DON'T Do
- NO user conversations (that's the main agent's job)
- NO external messages unless explicitly tasked
- NO cron jobs or persistent state (you're ephemeral)
- NO spawning other sub-agents
注意第三条规则:“Don’t ask for clarification, make reasonable assumptions”。
这很重要——子代理不能向用户提问,所以它必须自己做合理假设。这避免了子代理因为一个小疑问而卡住整个流程。
🔑 核心机制三:Lane 并发控制
OpenClaw 引入了"通道"(Lane)的概念来管理并发:
export const enum CommandLane {
Main = "main", // 主代理通道,最大并发 4
Cron = "cron", // 定时任务通道,最大并发 1
Subagent = "subagent", // 子代理通道,最大并发 8
Nested = "nested", // 嵌套调用通道
}
为什么子代理的并发限制更高?
主代理最大并发是 4,子代理却是 8。这不是设计失误,而是有意为之:
- 子代理任务更轻量:通常是搜索、读取文件这类快速操作
- 子代理更短命:执行完就销毁,不会长期占用资源
- 子代理相互独立:不同子代理处理不同问题,不会冲突
- 支持并行探索:允许主 Agent 同时派出多个探索任务
这就像餐厅的后厨规划:主厨(Main)最多 4 个人同时工作,但帮厨(Subagent)可以有 8 个,因为帮厨的活更简单、更独立。
队列实现
当某个通道的并发达到上限时,新任务会进入队列等待:
async function processLane(lane: string) {
const state = lanes.get(lane);
if (!state) return;
// 检查并发限制
while (state.active < state.maxConcurrent && state.queue.length > 0) {
const entry = state.queue.shift()!;
state.active++;
try {
await executeEntry(entry);
} finally {
state.active--;
void processLane(lane); // 继续处理队列
}
}
}
这种设计确保系统不会因为突发的大量请求而过载。
🚀 并行 Subagent:让 AI 同时做多件事
核心发现:不是代码层面实现并行
OpenClaw 实现并行 Subagent 的方式很有意思:不是在代码层面写并发逻辑,而是通过 Prompt 指导 LLM 在单条消息中发起多个工具调用。
看看 Prompt 是怎么写的:
### Phase 1: Initial Understanding
2. **Launch up to 3 Explore agents IN PARALLEL** (single message, multiple tool calls)
to efficiently explore the codebase. Each agent can focus on different aspects:
- Example: One agent searches for existing implementations, another explores
related components, a third investigates testing patterns
- Provide each agent with a specific search focus or area to explore
- Quality over quantity - 3 agents maximum
关键词是 “single message, multiple tool calls”。
LLM 被指导在一条消息里同时发起多个 Task 工具调用,然后 Vercel AI SDK 会自动并行执行这些工具。
并行执行流程图
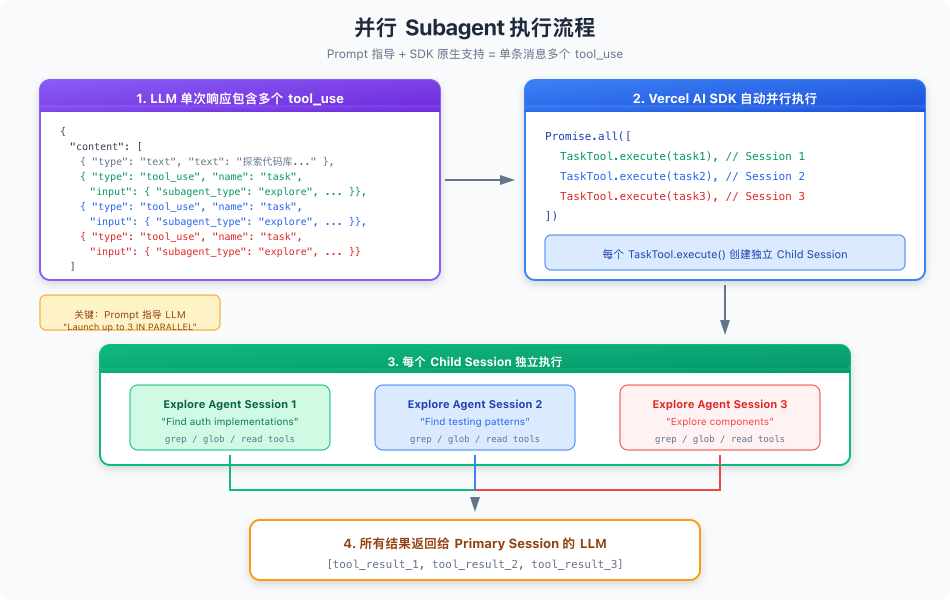
SDK 自动并行的原理
当 LLM 返回的消息包含多个 tool_use 块时:
{
"content": [
{ "type": "text", "text": "Let me explore the codebase..." },
{ "type": "tool_use", "id": "1", "name": "task", "input": {...} },
{ "type": "tool_use", "id": "2", "name": "task", "input": {...} },
{ "type": "tool_use", "id": "3", "name": "task", "input": {...} }
]
}
Vercel AI SDK 会自动用 Promise.all 并行执行这三个工具调用:
Promise.all([
TaskTool.execute(task1), // → 创建 Child Session 1
TaskTool.execute(task2), // → 创建 Child Session 2
TaskTool.execute(task3), // → 创建 Child Session 3
])
每个 TaskTool.execute() 会创建一个独立的 Child Session,在 Subagent Lane 中执行,互不干扰。
为什么这种设计很聪明?
- 复用现有基础设施:不需要额外写并发代码,SDK 自带
- LLM 自主决策:AI 自己判断是否需要并行,不是硬编码
- 灵活度高:可以是 1 个、2 个或 3 个并行,视任务复杂度而定
- 质量优先:“Quality over quantity”——不是越多越好
📢 结果汇报:Announce Flow
子代理完成任务后,结果如何回到主 Agent?这就是 Announce Flow 的职责。
汇报流程
export async function runSubagentAnnounceFlow(params: {
childRunId: string;
childSessionKey: string;
requesterSessionKey: string;
taskLabel: string;
cleanup?: "delete" | "keep";
}) {
// 1. 等待子代理完全结束
const waitResult = await callGateway({
method: "agent.wait",
params: { runId: params.childRunId },
});
// 2. 读取子代理的最终回复
const latestReply = await readLatestAssistantReply({
sessionKey: params.childSessionKey,
});
// 3. 构建触发消息
const triggerMessage = `
📋 Background task "${params.taskLabel}" just ${statusLabel}.
**Findings:**
${latestReply || "(no output)"}
---
Summarize this naturally for the user.
`;
// 4. 发送到主代理会话
await callGateway({
method: "agent",
params: {
sessionKey: params.requesterSessionKey,
message: triggerMessage,
deliver: true,
isSystemEvent: true,
},
});
// 5. 可选:清理子代理会话
if (params.cleanup === "delete") {
await callGateway({
method: "sessions.delete",
params: { key: params.childSessionKey },
});
}
}
公告队列:避免消息冲突
如果主 Agent 正在处理用户消息,子代理的结果不能直接打断。OpenClaw 引入了公告队列:
export async function maybeQueueSubagentAnnounce(params: {...}) {
// 检查主代理是否正忙
const isMainAgentBusy = await checkSessionBusy(params.requesterSessionKey);
if (!isMainAgentBusy) {
return "none"; // 可以直接发送
}
// 主代理正忙,加入队列
queue.push({...});
return "queued";
}
当主 Agent 空闲后,队列中的公告会被批量处理:
// 批量处理:将多个公告合并成一条消息
const combined = queue.map((a) =>
`### ${a.taskLabel}\n${a.triggerMessage}`
).join("\n\n---\n\n");
await callGateway({
method: "agent",
params: {
sessionKey,
message: `Multiple background tasks completed:\n\n${combined}`,
},
});
这避免了主 Agent 被多个子代理的汇报消息"轰炸"。
🎮 用户命令支持
OpenClaw 还提供了命令行接口让用户管理子代理:
/subagents list # 列出当前会话的所有子代理
/subagents stop <id> # 停止指定子代理
/subagents log <id> # 查看子代理对话日志
/subagents send <id> <msg> # 向子代理发送消息
/subagents info <id> # 查看子代理详细信息
输出示例:
- [running] AI Trends Research (abc12345...)
- [completed] Code Analysis (def67890...)
- [error] Database Migration (ghi11213...)
这让用户对后台任务有完全的可见性和控制权。
📊 关键设计要点总结
| 设计点 | 目的 | 实现方式 |
|---|---|---|
| Session Key 隔离 | 区分主/子会话 | agent:xxx:subagent:uuid 格式 |
| 禁止嵌套 spawn | 防止无限递归 | isSubagentSessionKey 检查 |
| Bootstrap 过滤 | 减少子代理上下文 | 白名单机制,只保留 AGENTS.md, TOOLS.md |
| 工具策略隔离 | 限制子代理能力 | 禁用 cron, message, spawn 等 |
| Lane 并发控制 | 资源隔离和限流 | 主代理 4 并发,子代理 8 并发 |
| Registry 追踪 | 生命周期管理 | 注册表 + 事件监听 |
| Announce Queue | 避免消息冲突 | 队列化 + 批量合并 |
| spawnedBy 字段 | 父子关系追踪 | 用于权限和清理 |
💡 我的观点和启发
1. "一次性、专注、受限"的设计哲学
OpenClaw 子代理的核心思想是:子代理是用完即弃的执行单元。
它不需要人格、不需要记忆、不需要与用户交互。它的唯一目标是完成一个具体任务,然后消失。
这种设计让系统保持简洁。如果子代理也要维护状态、管理记忆,复杂度会爆炸。
2. Prompt 驱动 vs 代码驱动
并行子代理的实现方式给我很大启发:与其在代码里硬编码并发逻辑,不如教 AI 自己决定何时并行。
Prompt 里写 “Launch up to 3 agents IN PARALLEL”,AI 就会在合适的时候主动使用这个能力。这比代码里写死"每次创建 3 个子代理"灵活得多。
3. 工程上的"最小权限原则"
子代理系统严格遵循最小权限原则:
- 只给需要的 Bootstrap 文件
- 只给需要的工具
- 只给需要的上下文
这不仅是安全考虑,也是性能优化——更少的上下文意味着更快的响应、更少的 token 消耗。
4. 队列的艺术
Announce Queue 的设计很有意思:当结果无法立即发送时,先排队等候。
这种"延迟发送"的机制在分布式系统中很常见,但用在 AI Agent 上是个巧妙的迁移。它解决了"多个子代理同时完成"和"主 Agent 正忙"这两个实际问题。
🔗 复刻建议
如果你想在自己的 Agent 系统中实现类似的子代理功能,关键点是:
- 设计清晰的 Session Key 命名规范——能一眼看出会话类型
- 实现 Bootstrap 文件过滤——子代理不需要完整上下文
- 配置工具权限白名单——限制子代理的能力边界
- 引入 Lane 并发控制——防止资源耗尽
- 实现 Registry 追踪——知道有哪些子代理在运行
- 设计 Announce 机制——结果能优雅地回到主 Agent
- 禁止嵌套 spawn——这是安全红线
核心思想只有一句话:子代理是"一次性、专注、受限"的执行单元,完成任务后自动汇报并清理。
📚 参考资料
如果觉得有用,欢迎点赞、在看、转发三连~

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 7
7 0
0- 0



 已为社区贡献30条内容
已为社区贡献30条内容

所有评论(0)