AI4S 量子技术揭秘:打破谷歌量子计算的能效壁垒
量子计算是基于量子力学原理发展形成的信息处理的概念和技术体系。量子计算最开始源自物理学家费曼的构想。由于复杂且高度纠缠的量子系统难以用经典计算机高效模拟,费曼提出利用一种可控的量子计算机去研究量子系统的可能性。近年来,随着量子计算硬件与应用算法的不断进步,量子计算被认为有机会在某些特定的应用上提供指数级别的计算加速;另外量子计算作为一种区别于经典计算的体系,因不再受到晶体管极限的限制,而受到人们的
作者:FR、SZL 、ZJC、LH 和 WSH @ Shanghai AI Lab
TL/DR:
所谓“量子霸权”,是指在特定任务上,量子计算机有远超传统计算机的能力。比如谷歌的悬铃木(Sycamore)量子计算机,其声称能在 200 秒内完成百万量子采样(保真度 0.2%),而当时最快的超级计算机需要一万年。尽管有人试图用经典算法弥合谷歌量子霸权,但在生成无关联样本、能源效率等方面仍存在挑战。在亚特兰大举行的全球超级计算大会(SC24)上,我们团队展示了在量子计算领域的最新研究,在量子模拟任务上实现了速度和功耗的数量级飞跃,打破 Sycamore 量子计算能效壁垒,开启量子模拟任务的新篇章。
代码可参考: https://github.com/DeepLink-org/OpenTenNet;
Paper: https://arxiv.org/abs/2407.00769 / SC 2024。
1. 引言
1.1 什么是量子计算
量子计算是基于量子力学原理发展形成的信息处理的概念和技术体系。量子计算最开始源自物理学家费曼的构想。由于复杂且高度纠缠的量子系统难以用经典计算机高效模拟,费曼提出利用一种可控的量子计算机去研究量子系统的可能性。近年来,随着量子计算硬件与应用算法的不断进步,量子计算被认为有机会在某些特定的应用上提供指数级别的计算加速;另外量子计算作为一种区别于经典计算的体系,因不再受到晶体管极限的限制,而受到人们的重视。
在硬件方面,量子计算处理器目前主流路线包括超导、离子阱、光量子、中性原子等。不同的技术路线所利用的量子力学对象不同,因此材料、器件、组件的需求各不相同,并各有优劣。关于量子计算的物理实现可以参考下面这篇文章。
编辑Qtumist量子客:最全量子计算硬件概述(建议收藏)152 赞同 · 8 评论
在算法方面,从90年代开始针对不同应用的量子算法不断涌现。1994年 Shor 提出了质因数分解算法,相比已知最优经典算法性能得到指数增加。1996年 Grover 提出了查找算法,获得了平方级别的加速性能。2009年,Harrow、Hassidim 和 Lloyd 提出了应用于求解线性方程的 HHL 算法。然而上述算法受限于当前量子计算硬件发展,在近期内很难实用。于是近年来,针对当前含噪声中等规模的量子时代(也被称作 NISQ 时代),人们开发了许多更实用的算法。例如2013年提出的变分量子特征值求解算法(VQE),使得 NISQ 时代的量子化学模拟应用成为可能;2016年提出的量子近似优化算法(QAOA),可用于求解组合优化问题等等。要搞明白这些量子算法需要知道量子计算抽象出的数学模型,包括量子计算的基本单位——量子比特、量子计算的操作方式——量子门与量子电路。这里我们不做过多的介绍,推荐文章:
编辑蓉城鲸鱼:快速入门量子计算(量子比特、量子门与量子电路)6 赞同 · 1 评论
1.2 量子霸权的定义
量子霸权,是指量子计算机表现出的超越所有经典计算机的计算能力。其于2019年被谷歌公司的 AI Quantum 等组织首次提出,相关论文“Quantum supremacy using a programmable superconducting processor”发表在 Nature 上。
编辑如何评价 Google 宣称率先实现量子霸权?1.4 万赞同 · 1076 评论
谷歌一直在布局基于超导路线的量子计算。为了展示他们的量子计算机(Sycamore)在某些任务上超越了经典计算机的能力,他们找到了一种对量子计算机很友好的任务:随机电路采样 (Random Circuit Sampling),并宣称使用他们的 Sycamore 量子处理器大约需要 200 秒来进行一百万次随机电路采样,而相同的任务在现代超级经典计算机上需要运行大约一万年。正如论文的摘要中提到:
Our Sycamore processor takes about 200 seconds to sample one instance of a quantum circuit a million times—our benchmarks currently indicate that the equivalent task for a state-of-the-art classical supercomputer would take approximately 10,000 years. This dramatic increase in speed compared to all known classical algorithms is an experimental realization of quantum supremacy for this specific computational task, heralding a muchanticipated computing paradigm.
由于量子计算机在这种特定的任务上比现有最强大的经典计算机快得多的能力,量子霸权(Quantum Supremacy),这个充满噱头的名字应运而生。
量子霸权的实验不仅仅是一个技术展示,它还推动了量子计算硬件和算法的发展,同时也激发了对量子计算潜在应用的探索。谷歌的这个发现无疑成为量子计算最重要的里程碑,因为之后学术界与工业界蜂拥而至,在量子计算的各个子领域聚集起来,关于算法、硬件的研究论文近几年呈指数级别增长,仿佛展示着量子时代即将来临。
而与此同时,也有另一群人则对谷歌提出的量子霸权持批判的态度,希望利用高性能计算将经典的算力利用到极致,从而表现出紧追甚至超越量子计算的强大性能。于是,很多研究者针对随机电路采样这个任务,使用经典的方式去模拟量子系统,期望使用比 Sycamore 量子处理器更少的时间与更低的功耗。
1.3 随机电路采样
在介绍经典的模拟量子系统算法之前,我们先简单了解这个特殊的任务——随机电路采样,它的量子电路结构展示如下:
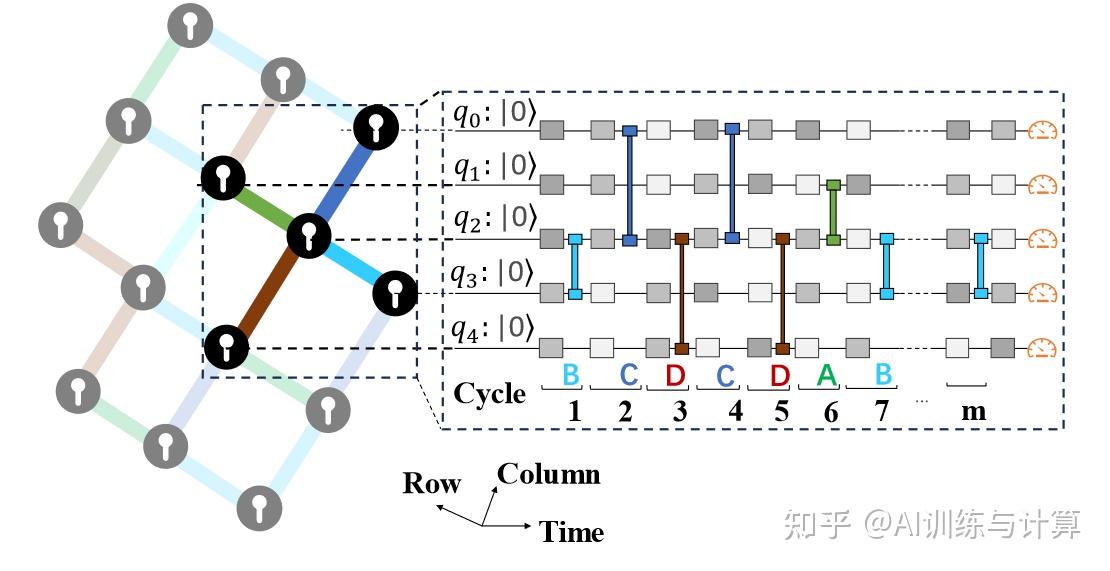
随机电路采样的量子电路
从图中可以观察到,随机电路采样的量子电路具有许多周期 (cycle),每个周期中由一个单量子比特门和一个双量子比特门构成。单量子比特门从下面几个门中进行选择:
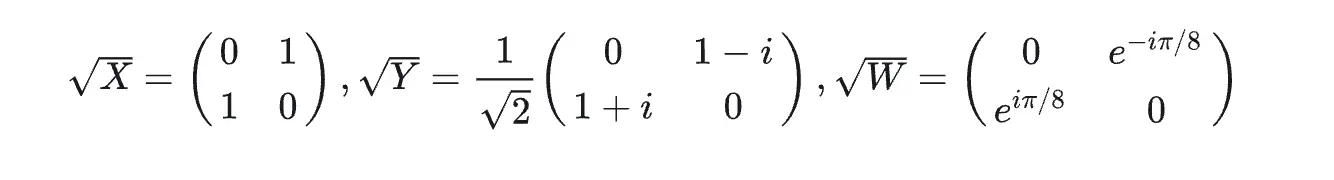 在电路图中,不同的门选择用不同灰度的矩形表示。另外,单量子比特门不能按顺序重复;双量子比特门的顺序按照量子比特的排列模式选择,将每个量子比特依次与其四个最近邻量子比特耦合。通过不断的耦合,电路结构将产生一种高度纠缠的量子系统,这使得用经典计算机仿真模拟十分困难。
在电路图中,不同的门选择用不同灰度的矩形表示。另外,单量子比特门不能按顺序重复;双量子比特门的顺序按照量子比特的排列模式选择,将每个量子比特依次与其四个最近邻量子比特耦合。通过不断的耦合,电路结构将产生一种高度纠缠的量子系统,这使得用经典计算机仿真模拟十分困难。
在上述模型的基础上,对量子电路输出进行采样(测量)产生一组比特串,例如 {0000101, 1011100, ...}。由于其中量子门的操作,最终比特串测量的概率是不均匀的。我们可通过一种称为交叉熵基准测试(XEB)的方法验证量子处理器是否正常工作,该方法比较每个比特串在实验中观察到的频率与在经典计算机上模拟计算的理想概率,交叉熵基准定义: 。
在量子电路没有受到噪声干扰的情况下,比特串的概率分布是呈指数分布的,XEB 等于 1;而当干扰较大,抽样的比特串是均匀分布的情况下,XEB 等于 0。
谷歌论文中,对一个由 53 个量子比特组成的量子系统进行实验,量子电路由总共 20 个周期构成,Sycamore 量子处理器可以在 200s 的时间获取百万个随机电路采样(相同的任务他们认为,超级计算机需要计算 10000 年),能达到的 XEB 指标为 。
2. 经典算法弥合量子霸权
随着近年来 NISQ 时代量子设备的快速发展,各类经典计算机上的量子电路模拟器应运而生。模拟量子电路的难度体现在两个层面:
- 一个是组成量子系统的量子比特数量(对应量子算法的空间复杂度),
- 一个是量子系统的深度(对应量子算法的时间复杂度)。
目前,量子电路的模拟器可以分为以下两大类。相关背景知识可以参考:
编辑蓉城鲸鱼:快速入门量子计算(量子比特、量子门与量子电路)6 赞同 · 1 评论 文章
- 状态矢量(state vector)方法,即直接模拟量子态的直接演化。由于这种方法需要存储量子系统所经历的所有叠加态,所需内存空间随量子比特数量呈指数级增长,这成为限制这种方法的挑战。例如对于随机电路采样的任务,Cori2 需要使用 0.5 PB 内存模拟含 45 个量子比特、电路深度为 25 的量子系统,该算法占用的空间容量严格满足 的增长幅度。尽管这种方法较为直接,但它的使用场景规模仍会受到量子比特数量较大限制,很难对抗 Sycamore 量子处理器的性能。
- 通过张量网络(Tensor Network)缩并来进行模拟。关于张量网络的介绍,推荐下面这篇文章:
编辑Xinyu Chen:机器学习 | 张量网络的图结构176 赞同 · 0 评论 文章
实际上,量子电路本身就是一种特殊的张量网络,其中一个单量子比特门被描述为一个维度为 2 的张量,一个双量子比特门被描述为一个维度为 4 的张量,而一个 量子比特门则被描述为一个维度为 的张量。于是量子电路的模拟可以被转化为一个“缩并”相应张量网络的问题,即对张量进行卷积,直到只剩一个顶点。张量方法的直接实现通常涉及的复杂度也随着量子比特的数量和电路的深度呈指数级增长,使得在合理时间内模拟大规模电路变得困难。
然而,如果我们只在电路的末端计算一个或少量的状态幅度,那么张量网络的复杂度将只受到收缩过程中最大张量的影响,而最大张量的大小随着缩并树宽指数增长。这种方法不再受到量子比特数量的限制,对于模拟具有大量量子比特但电路深度较浅的电路来说非常高效,因此近年来基于张量网络缩并的方法成为弥合 Sycamore 量子霸权的主流。
对于随机电路采样的任务,在张量网络缩并方法方面,一个具有代表性意义的工作是2021年度戈登贝尔奖“Closing the “Quantum Supremacy” Gap: Achieving Real-Time Simulation of a Random Quantum Circuit Using a New Sunway Supercomputer”——通过张量网络切分与缩并方法在 304 秒以内得到百万高保真度的关联样本。
编辑之江实验室:重磅!!!神威量子模拟器获“戈登·贝尔奖”2 赞同 · 0 评论 文章
然而,这个工作仍然存在漏洞,算出来的样本之间关联强,容易引发质疑。因为我们先从算法上进行了完善,同时采用后处理算法 [3] 和分布式并行缩并等方法加速量子线路模拟的过程,在时间和功耗两个方面显著超越 Sycamore 的性能。下图总结了量子芯片与经典算法之间的性能对比。
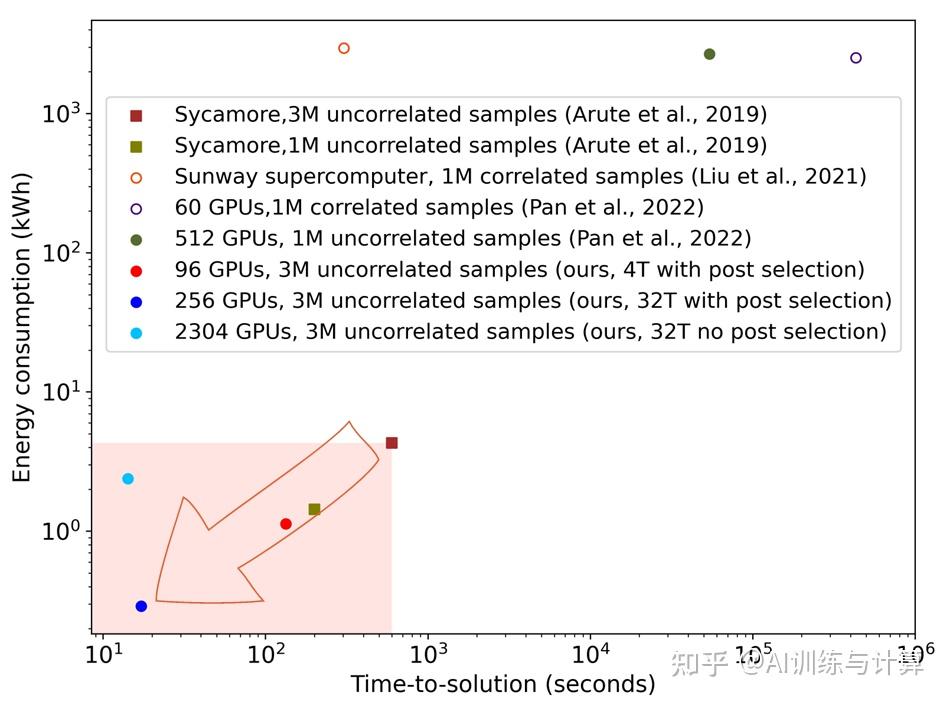
随机电路采样任务中经典模拟算法与Sycamore量子处理器性能比较
其中矩形散点代表量子处理器,圆圈代表经典处理器(空心代表产生相关样本,实心代表产生不相关样本)。横坐标表示 1 或 3 百万次采样所需的时间,纵坐标表示算法所需的能量。作为对比,我们以 Sycamore 产生三百万个不相关的采样实验作为对照,比 Sycamore 量子计算性能更好的经典计算方法,性能会落在粉红色范围之中。
可以发现过去经典算法的许多尝试,包括2021年戈登贝儿奖的工作,都没有在耗时和功耗两方面明显超越量子处理器。而在本文中,我们通过设计优化高性能计算架构(如左下角蓝色实心点所示),进一步提升经典计算性能。经典计算与量子计算最后的 Gap 被合拢了,因为经典计算在耗时和功耗两方面均超越了量子处理器。
3. 量子模拟器 技术揭秘
算法层面上,我们将量子模拟任务转化为大规模张量网络的缩并问题,在内存受限的条件下(例如 4TB 和 32TB 张量网络)使用“模拟退火”搜索出一条计算复杂度近似最优的缩并路径,并使用最新提出的后选择处理算法 [3] 提高任务的保真度,相同 fidelity 下我们的计算量更低。
超大规模张量网络的缩并问题,会产生更多的通信开销,尤其是 GPU 集群内的节点间通信会成为新的瓶颈。为了解决这一困难,我们提出了三级并行架构、定制化低精度通信、重计算等技术,以缓解节点间的通信瓶颈。
3.1 三级并行架构
首先,将我们的架构分为三个层级:全局级别(global level)、多节点级别(multi-node level)和设备级别(device level),如下图所示:
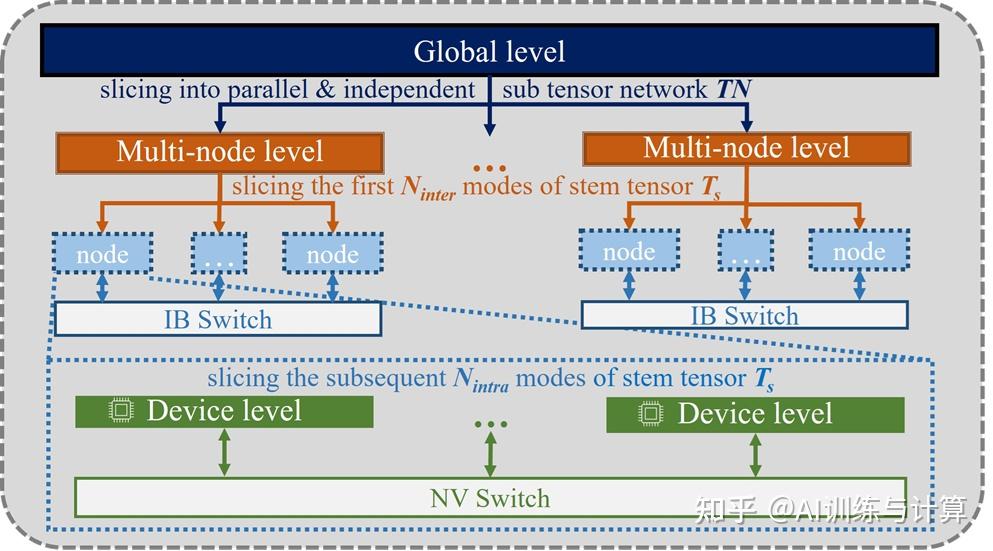
三级并行架构示意图
在找到接近最优的缩并路径后,我们先将整体张量网络的收缩分解为独立的子网络,使其可以独立地在多节点上执行。每个子任务对应于切分后张量子网络的收缩,都分配给多节点级别(对应图中的实心橙色矩形),每个多节点级别任务包含某一个子网络的收缩过程,并通过 InfiniBand (IB) 网络互连。
“主干路径”(stem path) 指的是张量网络中一系列计算量非常大的节点,这些节点成为整体任务计算量和内存开销的主要瓶颈。“主干张量”(stem tensor)是指与主路径相关的张量。图中的虚线绿色矩形表示了不同设备之间的并行划分方式。这里,主干张量被进一步分割成适合于设备级别(device level)的大小。
同时,考虑到节点内和节点间带宽的差异,我们提出了混合通信算法。计算硬件平台中节点内的 GPU 通过 NVLink 连接,带宽为 300 GB/s,而节点间通过 InfiniBand 通信,只有 100 GB/s 的带宽且同时由节点内 8 个 GPU 共享。因此,节点间通信比节点内通信慢一个数量级,如下图所示:
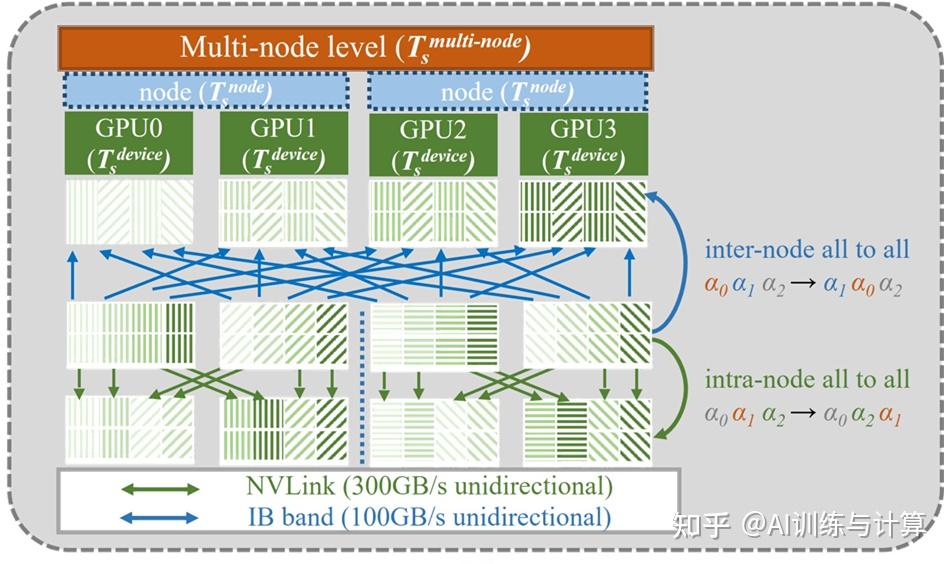
一个2节点-4GPU分布式通信示例
正如上面的 2 节点 -4 设备通信示例图所示,我们展示了一个包含两个节点的子任务,每个节点包含两个 GPU,分别在节点间和节点内两个层面上画出了数据搬运的过程,即张量维度的置换。通过混合通信的方式,合理划分节点内和节点间之间的通信负载,极大地利用了 NVLink 提供的高带宽,从而总体上提高了系统性能。
3.2 混合精度通信计算策略
当大规模张量网络的分布式收缩时,需要在多个节点之间多次执行 “all to all” 通信,尽管做了节点内/间优化,依然成为性能瓶颈。例如,在 4T 张量网络中,节点间通信时间占任务总时间 60.0%,能耗约占任务总功耗的 35%。因此,为了减少节点间通信所需的时间和能耗,我们采用低精度量化技术来缓解节点间通信的成本。
我们将张量分成多个组,每个组所对应的张量被称为 group tensor,并提供了三种类型的量化:float2half、float2int8 和 float2int4,如下:
| Type | Range | Exp | Group | Round |
|---|---|---|---|---|
| float | ±3.4×10^38 | – | – | - |
| float2half | ±6.65×10^4 | 1 | entire tensor | FALSE |
| float2int8 | -128∼127 | 0.2 | entire tensor | TRUE |
| float2int4 | 0∼15 | 1 | group tensor | TRUE |
这张表显示了不同量化类型的量化范围和设置。对于半量化和 int8 量化,我们计算整个张量的全局 scale 和 offset。而为了减少保真度损失,int4 量化需要在分组后张量 group tensor 中进行细粒度的量化,不同组具有不同的参数,组大小需要在保真度和通信开销之间做 tradeoff。因此,通过实验我们较好地权衡了计算误差和通信效率提升,最后采用 int4 量化通信,以较小的保真度损失减少了 85%以上的通信时间。
另外,量子模拟可以进一步采用半精度来加速计算,同时内存需求减半。因此我们研究 einsum 等算子并扩展到 complexHalf 类型,从而支持半精度的计算。
3.3 特殊结构的定制化计算
针对张量网络缩并的几个特殊情况,我们提出了定制化的优化方法。它们不像前面的方法一样通用,但在所提张量网络缩并任务下有效。
1)重计算(Recomputation):
在所提 4T 张量网络中,我们观察到以下特征:只有四个步骤中的主干张量的内存占用大于 1T,其中一个是 2T;且在这四个步骤之后,没有数据通信。
基于以上特点,一部分的 GPU 内存可以通过重计算来重复使用,将所需的节点/GPU 卡数量减少到原来的二分之一。值得注意的是,这并不能减少总的时间,但可以节约所需的 GPU 卡数。
2)稀疏状态下的张量收缩(Tensor contraction during sparse state):
稀疏状态发生在张量网络计算的最后阶段,其本质上是不连续的和重复的,需要复制张量进行计算。然而,由于此时 GPU 内存几乎耗尽,不能支持大张量计算的加载,因此我们将较大的张量划分为较小的块,这些块可以放入当前的 GPU 内存中。然后我们迭代计算每个张量块。
4. 结果与总结
结合算法和系统级优化,我们的量子模拟器在可扩展性、速度、功耗等方面实现了性能的飞跃,为量子计算未来发展提供了可靠的系统支持。
首先,系统可扩展性体现在两个维度上:张量网络的大小(4TB 和 32TB)和使用的 GPU 数量,强可扩展性如下图所示。
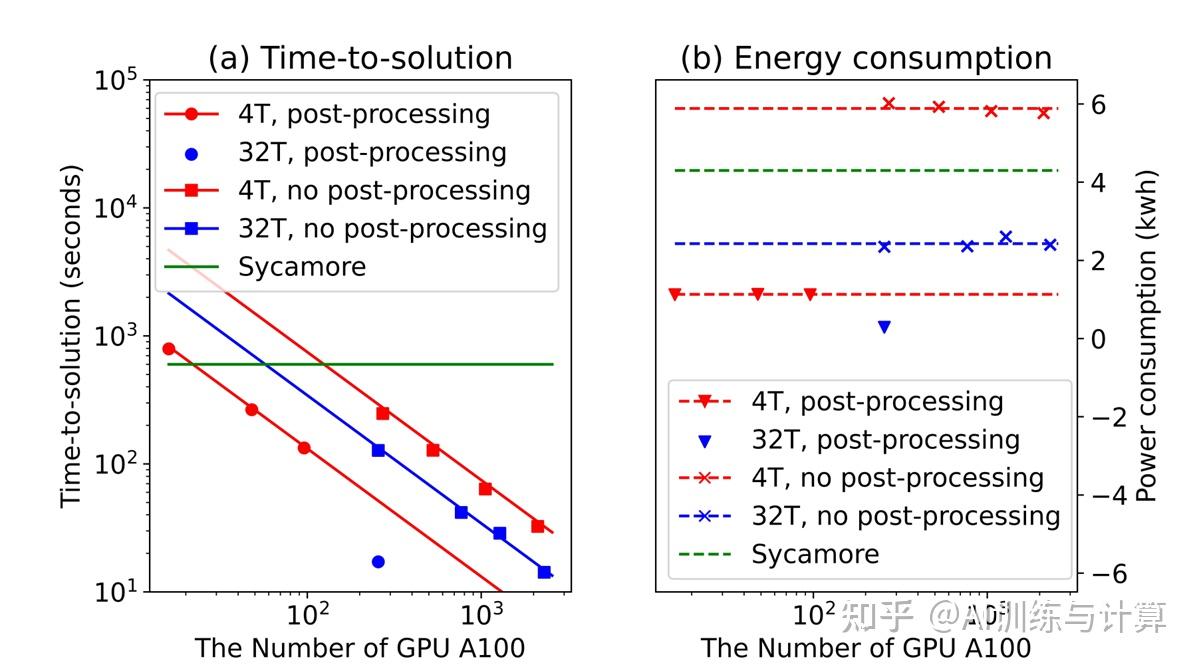
扩展性分析
可以看到,随着 GPU 数量的增加,总任务所需的时间呈线性下降,同时能耗保持在比较稳定的水平。说明我们所使用算法具备良好的并行性,以及三级并行架构设计保持了该缩并任务的高度可扩展性。
最后,对标谷歌 Sycamore 的量子霸权任务,我们进行了多组实验。
| methods | 4T&no-PP | 4T&PP | 32T&no-PP | 32T&PP |
|---|---|---|---|---|
| Complexity(FLOP) | 4.7×10^17 | 7.9×10^16 | 1.3×10^17 | 1.6×10^16 |
| XEB value (%) | 0.2036 | 0.2059 | 0.21194 | 0.2158 |
| Resource(A100) | 2112 | 96 | 2304 | 256 |
| Time(s) | 32.51 | 133.15 | 14.22 | 17.18 |
| Energy(kwh) | 5.77 | 1.12 | 2.39 | 0.29 |
如上表所示,对于 32TB 张量网络,未使用后选择处理算法(简称 no-PP)的情况下,我们用 2304 个 GPU 在 14.22 秒内达到了与 Sycamore 相同的 0.02%保真度,能耗为 2.39 kWh;而使用后选择处理算法(简称 PP)后,我们的方案在时间 17.18 秒内完成了该任务,经过后处理后 XEB 同样达到 0.02%,能耗仅为 0.29 kWh。无论是在速度还是能效效率上,我们的模拟器均超越了谷歌的量子处理器 Sycamore 所需的 600 秒、4.3 kWh,是量子计算研究的一个重要里程碑。
总结来说,该模拟器通过三级并行优化实现超大规模张量网络的强扩展性,能够处理达到数十 TB 内存容量的大规模张量网络,大大超越了单个节点的内存空间限制,显著提升了量子电路模拟的效率和准确性,在速度和能效上超越了谷歌的量子处理器。
本文从经典计算视角出发,通过在经典计算机上的一系列高性能优化,为未来设计更加复杂的量子算法与量子计算应用提供了更多模拟方法和解决思路。谷歌最新发表的 Nature 文章中展示了 70 量子比特的量子计算机,在 RCS 任务中速度比全球最强 Frontier 超级计算机快 47 年,再次展现了量子霸权的优势,也给我们带来了新的问题与挑战。尽管量子霸权实验中的随机电路采样任务在实际应用中可能并不直接相关,但它证明了量子计算机在处理某些类型问题上的潜力。随着量子计算技术的不断进步,我们期待量子计算机能够在更多实际问题上展现出其独特的优势。
如果你喜欢我们的内容,欢迎赞同∆、收藏⭐️、关注➕我们!
也欢迎在评论区与我们互动!
你的支持是我们持续创作的动力!
参考文献
- Cerezo, Marco, et al. "Challenges and opportunities in quantum machine learning." Nature Computational Science 2.9 (2022): 567-576.
- Arute, Frank, et al. "Quantum supremacy using a programmable superconducting processor." Nature 574.7779 (2019): 505-510.
- Zhao, Xian-He, et al. "Leapfrogging Sycamore: Harnessing 1432 GPUs for 7× faster quantum random circuit sampling." National Science Review (2024): nwae317.

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 29
29 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)