手把手搭建第一个 RAG 实战:实现本地文档智能问答
本文详细介绍了如何从零搭建基于RAG技术的本地文档智能问答系统。系统支持PDF、DOCX、TXT、MD等格式文档上传,通过向量数据库存储文档向量,结合大语言模型实现精准问答。文章首先概述了项目功能和工作流程,包括文档处理和用户查询两大阶段;然后讲解了系统架构设计,分为前端层、服务层和基础服务层;接着提供了技术选型建议,推荐使用Streamlit、LangChain、Chroma等工具;最后给出代码
4 手把手搭建第一个 RAG 实战:实现本地文档智能问答
4.1 项目概述
本文将带领你从零开始搭建基于 RAG(检索增强生成)的知识问答系统,实现文档上传、内容解析与并基于检索文档内容进行智能问答。系统支持 PDF、DOCX、TXT、MD 等多格式文档,通过向量数据库存储文档向量,结合大语言模型(LLM)生成准确回答,并具有流式输出功能提升用户体验,有效解决 LLM 的静态知识局限与 “幻觉” 问题。
核心功能如下:
- 支持上传 PDF/DOCX/TXT/MD 格式文档。
- 自动解析文档内容、进行向量化并存储在向量数据库中。
- 基于用户问题检索相关文档片段,结合检索的文档片段、上下文生成准确回答。
- 支持多轮对话、理解上下文语境和流式输出。
- 提供简洁的 Web 交互界面。
4.2 工作流程
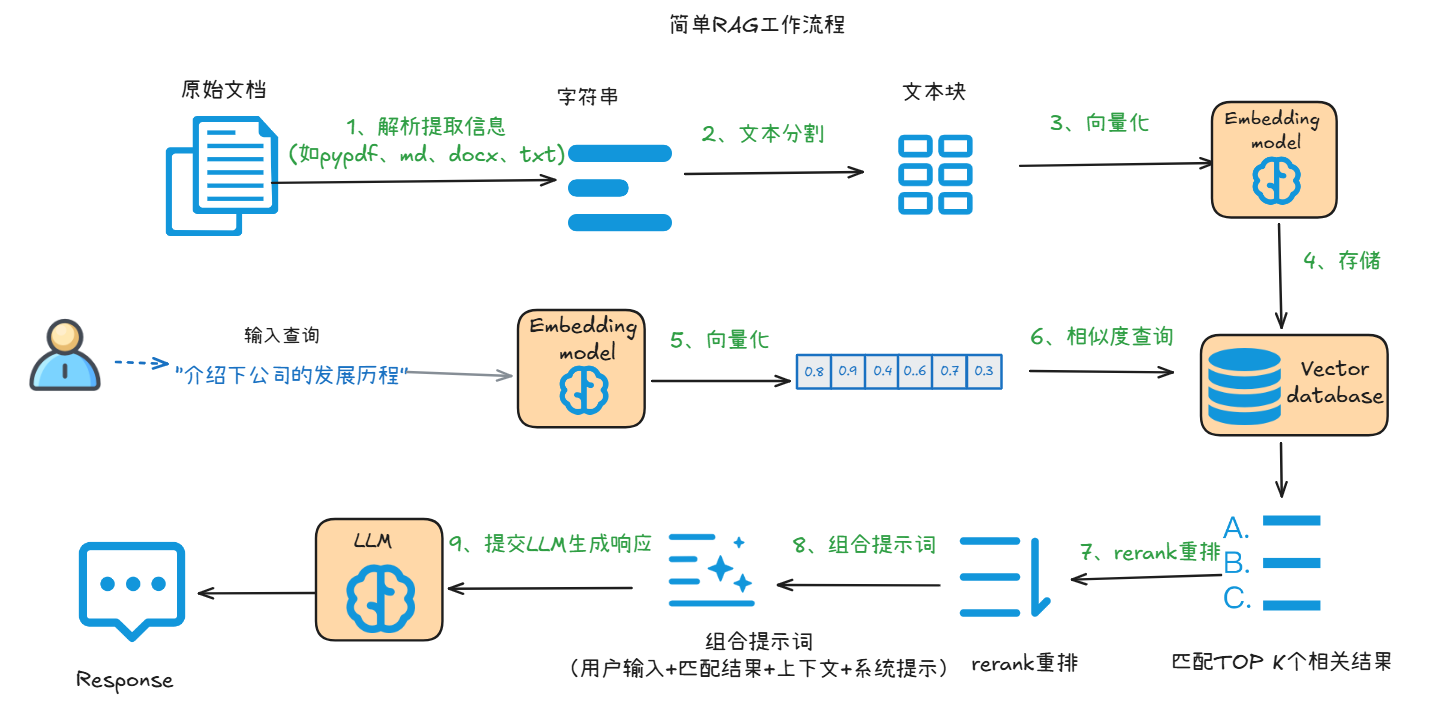
上图展示了基于RAG的知识库问答系统的工作流程,整体可分为文档处理(知识入库)和用户查询(知识检索与回答) 两大阶段,以下分步骤解析:
一、文档处理阶段(知识入库)
- 1. 解析提取信息:对原始文档(如 PDF、Markdown、Word、txt 格式),通过工具(如
pypdf库、文档解析工具)提取文本内容,转化为字符串形式。 - 2. 文本分割:将提取的长字符串切割为若干 “文本块”(Chunk),确保每个文本块语义相对完整(比如按段落、固定字数分割),便于后续向量化和检索。
- 3. 向量化:利用Embedding 模型(一种将文本转化为数值向量的模型),把每个文本块转化为高维向量。向量的数值能够表征文本的语义信息,语义越相似的文本,向量距离越近。
- 4. 存储:将这些文本向量存入向量数据库(Vector Database),支持后续快速的相似度查询。
二、用户查询阶段(知识检索与回答)
- 5. 用户查询向量化:用户输入查询(如 “介绍下公司的发展历程”)后,同样通过上述Embedding 模型,将查询文本转化为向量。
- 6. 相似度查询:查询向量数据库中,计算 “用户查询向量” 与 “已存储的文本块向量” 的相似度,筛选出TOP K 个最相关的文本块(即与用户问题语义最匹配的知识片段)。
- 7. 结果重排(Rerank):对 TOP K相关的结果进一步做重排,确保最相关的内容优先被选用。
- 8. 组合提示词:将 “用户输入、重排后的知识片段 、上下文补充(可选)、系统提示(如 “基于提供的信息生成简洁回答”)” 整合为结构化提示词(Prompt)。
- 9. 提交 LLM 生成响应:将组合好的提示词输入大语言模型(LLM),LLM 基于这些信息理解用户需求,生成最终的自然语言回答(Response)。
4.3 架构设计
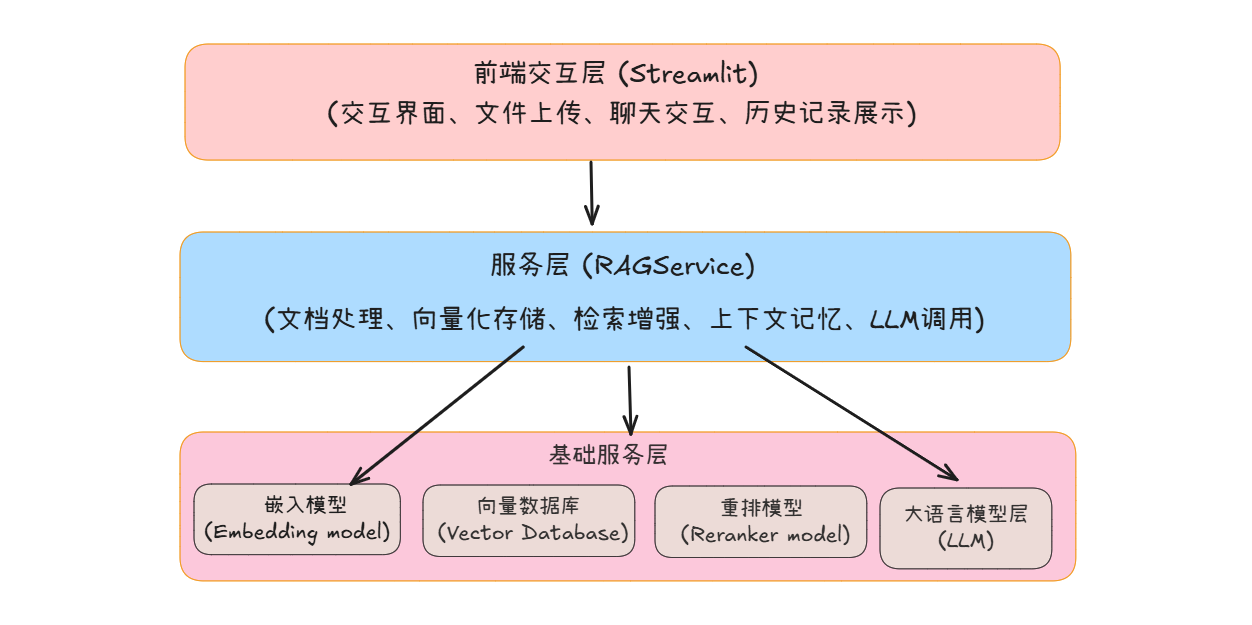
系统采用模块化设计,主要包含以下组件:
-
前端层:基于 Streamlit 构建,负责与用户直接交互,包括提供交互界面、支持文件上传、实现聊天交互、支持连续多轮对话、流式输出。
-
服务层:核心业务逻辑,封装了 RAG 技术的核心流程:
- 文档处理:对用户上传的文档进行解析、分块(将长文档拆分为短文本片段,便于后续处理)。
- 向量化存储:调用嵌入模型,将分块后的文本片段转换为语义向量,再批量写入向量数据库,完成知识入库。
- 检索增强:用户发起查询时,先通过向量数据库检索出Top K 候选文本片段,再调用重排模型对候选结果做精细化排序,筛选出最相关的内容,为 LLM 提供精准知识支撑。
- 上下文记忆:记录对话的上下文信息,使大语言模型能理解多轮对话的逻辑(如连续追问时,模型能基于历史对话回答)。
- LLM 调用:封装对 “大语言模型(LLM)” 的调用逻辑,将 “
系统提示词 + 用户当前问题 + 检索到的相关文本 + 对话上下文” 整合为提示词,调用大语言模型生成准确回答,并将结果回传至前端。
-
基础服务层:
为上层业务提供核心技术能力支撑,包含三大核心组件:
- 嵌入模型(Embedding model):将自然语言文本转换为高维语义向量,是实现文本相似度检索的基础。
- 向量数据库(Vector Database):专用于存储和快速检索向量数据的数据库,支持高效的相似性检索(如余弦相似度计算),是 RAG 流程的核心存储载体。
- 重排模型(Reranker Model):对向量检索得到的 Top K 候选结果做二次精准排序,提升 “相关文本片段” 的匹配精度;
- 大语言模型层(LLM):即大语言模型(如 GPT5、Qwen、 DeepSeek等),负责基于用户问题和检索到的文本,生成自然语言回答。
4.4 技术选型
- 前端框架:Streamlit(快速构建交互式 Web 应用)。
- 文档处理:LangChain(文档加载、文本分块、记忆上下文管理)。
- 嵌入模型:支持 Qwen、OpenAI等第三方提供的嵌入模型,以及支持本地部署模型
bge-small-zh-v1.5。 - 向量数据库:Chroma(轻量级嵌入式向量数据库)。
- 大语言模型:支持 Qwen、OpenAI、DeepSeek 等模型。
- 文档处理:pypdf(PDF 解析)、docx2txt(DOCX 解析)
- 环境管理:python-dotenv(环境变量管理)。
- 开发语言:Python 3.8+。
4.5 代码实现
4.5.1 项目结构搭建
项目完成后,目录结构如下:
simple_rag_assistant/
├── .env # 环境变量配置
├── requirements.txt # 依赖列表
├── main.py # 主程序入口(Streamlit界面)
├── models/
│ ├── models_data/ # 本地嵌入模型文件
│ ├── custom_dashscope_embedding.py # 自定义千问嵌入模型适配(解决批量处理大小限制问题)
│ ├── langchain_embedding.py # 嵌入模型调用
│ └── langchain_llm.py # 大语言模型调用
│ └── reranker_model.py # 重排模型调用
└── services/
└── rag_service_stream.py # RAG核心服务
4.5.2 环境准备
一、配置Conda 虚拟环境(安装 Conda,若未安装)
- 下载地址:https://docs.conda.io/en/latest/miniconda.html(conda 轻量化,推荐)
- 安装流程:
- Windows:双击安装包,勾选 “Add Miniconda3 to PATH”(方便命令行调用)
- Mac/Linux:执行安装脚本,按提示完成(默认会添加环境变量)
- 验证安装:打开终端 / 命令提示符,输入
conda --version,显示版本号则成功
二、创建并激活 Conda 虚拟环境
-
打开终端 / 命令提示符,执行以下命令创建虚拟环境(Python 版本指定 3.11):
# 创建名为rag-env的虚拟环境(名称可随意),指定Python 3.11 conda create -n rag-env python=3.11过程中会提示安装依赖,输入
y确认。 -
激活虚拟环境:
-
Windows(命令提示符):
conda activate rag-env # 若执行不了,尝试:conda.bat activate rag-env -
Mac/Linux:
conda activate rag-env
激活成功后,终端前缀会显示
(rag-env) -
-
(可选)配置 Conda 镜像源(加速依赖安装,国内用户推荐):
# 添加清华镜像源 conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/ conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/ config --set show_channel_urls yes
三、安装项目依赖
-
创建项目文件夹并进入:
# 创建文件夹 mkdir simple_rag_assistant && cd simple_rag_assistant -
创建
requirements.txt文件,添加依赖包如下:streamlit==1.46.0 langchain==0.3.26 langchain-chroma==0.2.4 langchain-community==0.3.27 langchain-core==0.3.66 langchain-deepseek==0.1.3 langchain-openai==0.3.19 python-dotenv==1.1.0 pypdf==5.6.1 dashscope==1.23.5 tenacity==9.1.2 sentence-transformers==5.1.2 # HuggingFace嵌入模型依赖 -
用 pip 安装依赖(Conda 环境中已自带 pip,无需额外配置):
pip install -r requirements.txt若安装缓慢,也可临时使用中科大镜像或清华 pip 镜像安装(要检查下,不确定是否可用):
# 1. 阿里云(稳定,国内首选) pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/ # 2. 清华大学(学术镜像,包全更新快) # pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple/ # 3. 腾讯云(企业级镜像,速度稳定) # pip install -r requirements.txt -i https://mirrors.cloud.tencent.com/pypi/simple/
四、配置环境变量
-
在项目根目录创建
.env文件(注意文件名前有小数点):# Qwen(千问)模型配置(必填,默认使用) QWEN_API_KEY=你的千问API密钥 QWEN_BASE_URL=你的千问API基础地址(如https://dashscope.aliyuncs.com/compatible-mode/v1) # OpenAI模型配置(可选,如需切换使用) OPENAI_API_KEY=你的OpenAI API密钥 OPENAI_BASE_URL=你的OpenAI API基础地址 # DeepSeek模型配置(可选,如需切换使用) DEEPSEEK_API_KEY=你的DeepSeek API密钥 DEEPSEEK_BASE_URL=你的DeepSeek API基础地址说明:
- 默认使用通义千问的大语言模型
qwen-plus以及向量模型text-embedding-v4。千问 API 密钥获取:登录阿里云百炼大模型平台(https://dashscope.console.aliyun.com/)申请,新用户默认有100W token的免费额度。 - 其它 API 密钥根据实际使用需求配置,无需使用则可留空。
- 默认使用通义千问的大语言模型
4.5.3 核心模块实现
1 自定义嵌入模型适配(models/custom_dashscope_embedding.py)
该类实现千问嵌入模型与 LangChain 的适配,负责将文本转换为向量。
由于在使用官方提供的类from langchain_community.embeddings import DashScopeEmbeddings进行向量化时,报错:batch size is invalid,it should not be larger than 10.: input.contents。该错误原因是langchain_community 包中的的DashScopeEmbeddings类在处理文档时,默认的批量大小超过了 DashScope API 的限制。故重写了该类,调整了默认BATCH_SIZE的大小,以解决批量请求超限问题。
在项目目录下创建models 文件夹,并在该文件夹下创建custom_dashscope_embedding.py文件,代码如下:
from __future__ import annotations
import logging
from typing import (
Any,
Callable,
Dict,
List,
Optional,
)
from langchain_core.embeddings import Embeddings
from langchain_core.utils import get_from_dict_or_env
from pydantic import BaseModel, ConfigDict, model_validator
from requests.exceptions import HTTPError
from tenacity import (
before_sleep_log,
retry,
retry_if_exception_type,
stop_after_attempt,
wait_exponential,
)
logger = logging.getLogger(__name__)
# 不同模型的批量处理大小
BATCH_SIZE = {"text-embedding-v1": 25, "text-embedding-v2": 25, "text-embedding-v3": 6, "text-embedding-v4": 6}
def _create_retry_decorator(embeddings: DashScopeEmbeddings) -> Callable[[Any], Any]:
"""创建重试装饰器,处理API调用失败的情况"""
multiplier = 1
min_seconds = 1 # 初始重试间隔1秒
max_seconds = 4 # 最大重试间隔4秒
# Wait 2^x * 1 second between each retry starting with
# 1 seconds, then up to 4 seconds, then 4 seconds afterwards
return retry(
reraise=True,
stop=stop_after_attempt(embeddings.max_retries),
wait=wait_exponential(multiplier, min=min_seconds, max=max_seconds),
retry=(retry_if_exception_type(HTTPError)),
before_sleep=before_sleep_log(logger, logging.WARNING),
)
def embed_with_retry(embeddings: DashScopeEmbeddings, **kwargs: Any) -> Any:
"""带重试机制的嵌入生成函数,支持批量处理"""
retry_decorator = _create_retry_decorator(embeddings)
@retry_decorator
def _embed_with_retry(**kwargs: Any) -> Any:
result = []
i = 0
input_data = kwargs["input"]
input_len = len(input_data) if isinstance(input_data, list) else 1
batch_size = BATCH_SIZE.get(kwargs["model"], 6) # 按模型获取批量大小
# 批量处理输入,避免单次请求超出API限制
while i < input_len:
kwargs["input"] = (
input_data[i: i + batch_size]
if isinstance(input_data, list)
else input_data
)
resp = embeddings.client.call(**kwargs) # 调用嵌入API
if resp.status_code == 200:
result += resp.output["embeddings"] # 提取嵌入结果
elif resp.status_code in [400, 401]:
raise ValueError(
f"status_code: {resp.status_code} \n "
f"code: {resp.code} \n message: {resp.message}"
)
else:
raise HTTPError(
f"HTTP error occurred: status_code: {resp.status_code} \n "
f"code: {resp.code} \n message: {resp.message}",
response=resp,
)
i += batch_size
return result
return _embed_with_retry(**kwargs)
class DashScopeEmbeddings(BaseModel, Embeddings):
"""
DashScope嵌入模型封装类,适配LangChain接口。使用该模型前,您需要先安装 dashscope Python 包,并且:
1.将您的 API 密钥配置到环境变量 DASHSCOPE_API_KEY 中;
2.或者,在构造函数中以命名参数的形式传入 API 密钥。
"""
client: Any = None # 千问嵌入API客户端
"""The DashScope client."""
model: str = "text-embedding-v1" # 默认使用的千问嵌入模型
dashscope_api_key: Optional[str] = None
max_retries: int = 5 # API调用最大重试次数
"""Maximum number of retries to make when generating."""
model_config = ConfigDict(
extra="forbid",
)
@model_validator(mode="before")
@classmethod
def validate_environment(cls, values: Dict) -> Any:
"""验证环境配置,初始化千问客户端"""
import dashscope
# 从环境变量或参数中获取API密钥
values["dashscope_api_key"] = get_from_dict_or_env(
values, "dashscope_api_key", "DASHSCOPE_API_KEY"
)
dashscope.api_key = values["dashscope_api_key"]
try:
import dashscope
# 初始化千问文本嵌入客户端
values["client"] = dashscope.TextEmbedding
except ImportError:
raise ImportError(
"Could not import dashscope python package. "
"Please install it with `pip install dashscope`."
)
return values
def embed_documents(self, texts: List[str]) -> List[List[float]]:
"""
为文档文本生成嵌入向量(批量处理)
Args:
texts: The list of texts to embed.
Returns:
List of embeddings, one for each text.
"""
embeddings = embed_with_retry(
self, input=texts, text_type="document", model=self.model
)
embedding_list = [item["embedding"] for item in embeddings]
return embedding_list
def embed_query(self, text: str) -> List[float]:
"""为查询文本生成嵌入向量(单个文本).
Args:
text: The text to embed.
Returns:
Embedding for the text.
"""
embedding = embed_with_retry(
self, input=text, text_type="query", model=self.model
)[0]["embedding"]
return embedding
2 嵌入模型调用(models/langchain_embedding.py)
该文件统一初始化不同来源的文本嵌入模型。支持千问(Qwen)、OpenAI 和本地 BGE 模型,方便开发者根据需求切换,无需修改核心逻辑。
在models文件夹下创建文件langchain_embedding.py,代码如下:
# 导入必要的Python库
import os # 用于处理操作系统相关的功能
from dotenv import load_dotenv
from langchain_openai import OpenAIEmbeddings
from langchain_huggingface import HuggingFaceEmbeddings
from models.custom_dashscope_embedding import DashScopeEmbeddings
# 加载环境变量
load_dotenv()
def initialize_embedding_model(provider: str = "qwen"):
"""
初始化并返回指定提供商的嵌入模型
参数:
provider (str): 嵌入模型提供商,支持"openai"、"qwen"、"local_bge_small“,默认为qwen
返回:
embeddings: 初始化后的嵌入模型实例
"""
# 加载环境变量
if provider.lower() == "openai":
# 使用OpenAI的嵌入模型
api_key = os.getenv("OPENAI_API_KEY")
if not api_key:
raise ValueError("缺少OPENAI_API_KEY环境变量")
base_url = os.getenv("OPENAI_BASE_URL")
if base_url:
return OpenAIEmbeddings(
openai_api_key=api_key,
base_url=base_url,
model="text-embedding-ada-002"
)
else:
return OpenAIEmbeddings(
openai_api_key=api_key,
model="text-embedding-ada-002"
)
elif provider.lower() == "qwen":
# 使用千问的嵌入模型
api_key = os.getenv("QWEN_API_KEY")
if not api_key:
raise ValueError("缺少QWEN_API_KEY环境变量")
base_url = os.getenv("QWEN_BASE_URL")
if not base_url:
raise ValueError("缺少QWEN_BASE_URL环境变量")
return DashScopeEmbeddings(
dashscope_api_key=api_key,
model="text-embedding-v4", # 千问嵌入模型名称,根据实际情况调整
)
elif provider.lower() == "local_bge_small":
# BGE-small-zh-v1.5是北京智源研究院(BAAI)开发的轻量级中文文本嵌入模型,支持将文本转换为高维向量,适用于检索、分类、聚类等任务,且对资源受限场景友好。
# 手动下载向量模型,指定本地文件夹路径,若 SDK 自动下载,直接用模型名。
model_path = "./models_data/bge-small-zh-v1.5" # 手动下载的本地路径
# 或 model_path = "BAAI/bge-small-zh-v1.5"(直接用模型名,首次使用时,SDK 自动下载模型文件)
return HuggingFaceEmbeddings(
model_name=model_path,
model_kwargs={'device': 'cpu'}, # 可指定 'cuda' 启用 GPU 加速
encode_kwargs={'normalize_embeddings': True} # 是否对输出向量归一化(推荐用于相似度计算)
)
else:
raise ValueError(f"不支持的嵌入模型提供商: {provider}。请选择'openai'、'huggingface'或'qwen'")
提供了 3 种嵌入模型,只需选择其中一直即可,每种模型的初始化逻辑如下:
-
**
qwen(千问):**默认,这里使用的是千问向量模型text-embedding-v4。必须配置QWEN_API_KEY和QWEN_BASE_URL两个环境变量。 -
**openai:**需在环境变量中配置
OPENAI_API_KEY,若使用第三方代理还需配置OPENAI_BASE_URL(自定义接口地址)。 -
**local_bge_small:**本地加载向量模型,不访问第三方提供的模型服务。这里使用的是北京智源研究院(BAAI)开发的轻量级中文文本嵌入模型
bge-small-zh-v1.5,对资源要求不高,适合资源受限场景。若使用本地加载向量模型,执行以下步骤:
-
首先安装必要的 Python 库。
pip install transformers sentence-transformers torch --upgrade -
下载向量模型文件,两种方式下载:
-
手动下载:可从HuggingFace 或 魔塔地址下载模型文件,放到当前目录的
./models_data/bge-small-zh-v1.5路径下。下载文件:config.json(模型配置)、model.safetensors(模型权重)、tokenizer.json、tokenizer_config.json、vocab.txt(分词器文件)。设置model_path 为下载的本地路径地址。 -
自动下载:设置
model_path为"BAAI/bge-small-zh-v1.5",首次运行时 SDK 会自动下载(需联网)。下载默认存储路径如下:Windows:``C:\Users\用户名.cache\huggingface\transformers
)Linux/Mac:
~/.cache/huggingface/transformers下载完成后,后续运行代码会直接从缓存加载,无需重复下载。
-
-
加载模型:通过 LangChain 库中
HuggingFaceEmbeddings加载。-
配置为 CPU 运行(可改
cuda用 GPU); -
对输出向量归一化(方便后续相似度计算)。
-
-
测试嵌入模型
def test_embedding_model(provider: str = "openai"):
"""测试嵌入模型的基本功能"""
try:
# 初始化嵌入模型
embeddings = initialize_embedding_model(provider)
# 测试文本
test_text = "这是一个测试文本,用于验证嵌入模型的功能。"
# 生成嵌入向量
vector = embeddings.embed_query(test_text)
# 打印基本信息
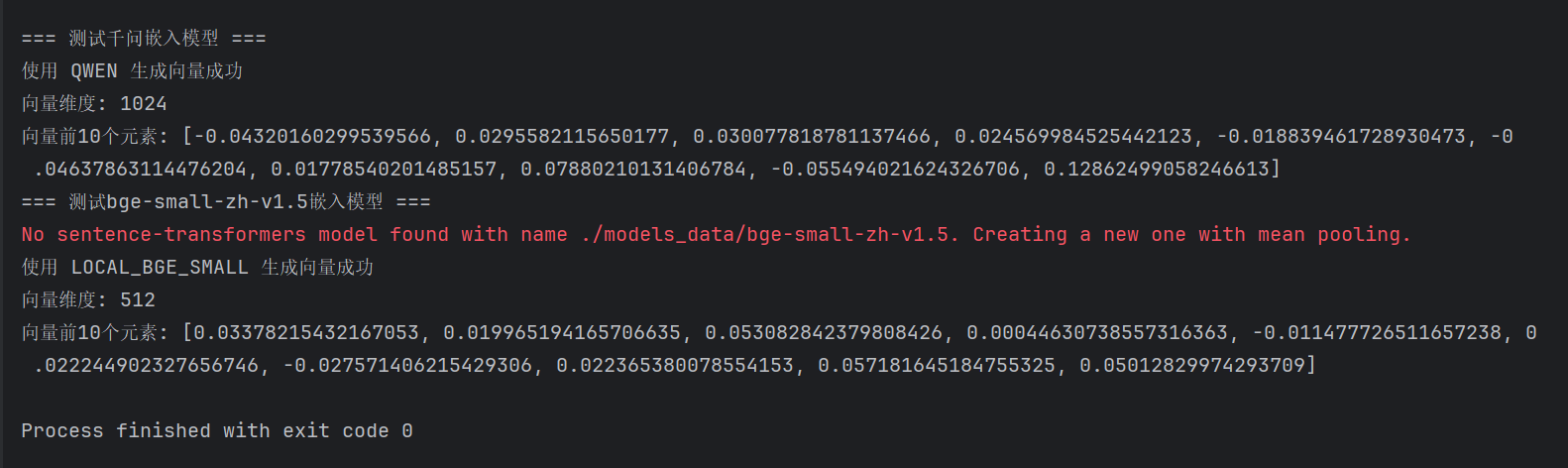
print(f"使用 {provider.upper()} 嵌入模型生成向量成功")
print(f"向量维度: {len(vector)}")
print(f"向量前10个元素: {vector[:10]}")
return vector
except Exception as e:
print(f"测试失败: {str(e)}")
return None
if __name__ == "__main__":
# 测试千问模型
print("\n=== 测试千问嵌入模型 ===")
test_embedding_model("qwen")
# 测试OpenAI模型
print("=== 测试bge-small-zh-v1.5嵌入模型 ===")
test_embedding_model("local_bge_small")
运行结果如下:
4 LLM模型调用(langchain_llm.py)
基于 LangChain 框架,封装LLM的调用,实现从环境变量读取配置、校验参数,返回模型聊天实例ChatOpenAI。可适配兼容openAI 接口规范的模型服务,如千问(Qwen)、DeepSeek、OpenAI、智谱(Zhipu)等,可配置MODEL_CONFIG_MAP灵活扩展,默认使用千问模型。
在models文件夹下创建文件langchain_llm.py,代码如下:
# 导入必要的Python库
import os # 用于处理操作系统相关的功能
from typing import Dict, Optional
from dotenv import load_dotenv
from langchain.chat_models import init_chat_model
from langchain_core.language_models import BaseChatModel
from langchain_openai import ChatOpenAI
# 加载环境变量
load_dotenv()
# 模型配置常量(集中管理,便于维护)
MODEL_CONFIG_MAP: Dict[str, Dict[str, str]] = {
"qwen": {
"api_key_env": "QWEN_API_KEY",
"base_url_env": "QWEN_BASE_URL",
"default_model": "qwen-plus"
},
"deepseek": {
"api_key_env": "DEEPSEEK_API_KEY",
"base_url_env": "DEEPSEEK_BASE_URL",
"default_model": "deepseek-chat"
},
"openai": {
"api_key_env": "OPENAI_API_KEY",
"base_url_env": "OPENAI_BASE_URL",
"default_model": "gpt-4-turbo"
},
"zhipu": {
"api_key_env": "ZHIPU_API_KEY",
"base_url_env": "ZHIPU_BASE_URL",
"default_model": "glm-4"
}
}
def _get_env_var(env_name: str, model_type: str) -> str:
"""
安全获取并校验环境变量,提供错误提示。
Args:
env_name: 待读取的环境变量名称(如QWEN_API_KEY)
model_type: 模型类型标识(如qwen/deepseek),用于错误提示上下文
Returns:
str: 非空的环境变量值
Raises:
ValueError: 当环境变量未设置或值为空时抛出,包含明确的配置指引
"""
value = os.getenv(env_name)
if not value:
raise ValueError(
f"[{model_type.upper()}] 缺少必要的环境变量:{env_name}\n"
f"请在.env文件中配置 {env_name}=你的API密钥/基础地址"
)
return value
def langchain_llm(
model_type: str = "qwen",
model: Optional[str] = None,
temperature: float = 0.0,
**kwargs
) -> BaseChatModel:
"""
统一的LLM模型初始化入口函数,适配所有兼容OpenAI接口规范的模型。
已支持模型:qwen(通义千问)/deepseek(深度求索)/openai(OpenAI官方)/zhipu(智谱GLM模型),可配置MODEL_CONFIG_MAP扩展。
Args:
model_type: 模型类型标识,支持:qwen/deepseek/openai/zhipu
model: 具模型名称,不传则使用默认值
temperature: 生成温度系数,控制输出随机性(0=完全确定,1=高度随机),默认0.0
**kwargs: 透传参数,会传递给底层的init_chat_model/ChatOpenAI初始化方法
支持的参数示例:max_tokens(生成最大长度)、timeout(超时时间)、top_p(采样阈值)等
Returns:
BaseChatModel: 初始化完成的LangChain聊天模型实例,可直接用于对话生成
"""
# 校验模型类型是否支持
if model_type not in MODEL_CONFIG_MAP:
raise ValueError(
f"不支持的模型类型:{model_type}\n"
f"当前支持的类型:{list(MODEL_CONFIG_MAP.keys())}"
)
# 获取模型配置
config = MODEL_CONFIG_MAP[model_type]
model = model or config["default_model"]
# 获取环境变量
api_key = _get_env_var(config["api_key_env"], model_type)
base_url = _get_env_var(config["base_url_env"], model_type)
# 根据模型类型初始化
if model_type == "deepseek":
# DeepSeek使用init_chat_model初始化
llm = init_chat_model(
model=model,
api_key=api_key,
api_base=base_url,
temperature=temperature,
model_provider="deepseek",
**kwargs
)
else:
# 其他模型使用ChatOpenAI(兼容OpenAI接口)
llm = ChatOpenAI(
model=model,
api_key=api_key,
openai_api_base=base_url,
temperature=temperature,
**kwargs
)
return llm
def langchain_qwen_llm(model: str = "qwen-plus", temperature: float = 0.0) -> BaseChatModel:
"""初始化千问聊天模型"""
return langchain_llm("qwen", model=model, temperature=temperature)
def langchain_deepseek_llm(model: str = "deepseek-chat", temperature: float = 0.0) -> BaseChatModel:
"""初始化DeepSeek聊天模型"""
return langchain_llm("deepseek", model=model, temperature=temperature)
def langchain_openai_llm(model: str = "gpt-4-turbo", temperature: float = 0.0) -> BaseChatModel:
"""初始化OpenAI聊天模型"""
return langchain_llm("openai", model=model, temperature=temperature)
# 新增智谱初始化函数(扩展支持)
def langchain_zhipu_llm(model: str = "glm-4", temperature: float = 0.0) -> BaseChatModel:
"""初始化智谱聊天模型"""
return langchain_llm("zhipu", model=model, temperature=temperature)
测试LLM模型
if __name__ == "__main__":
print("=" * 50)
print("开始测试模型初始化与调用")
print("=" * 50 + "\n")
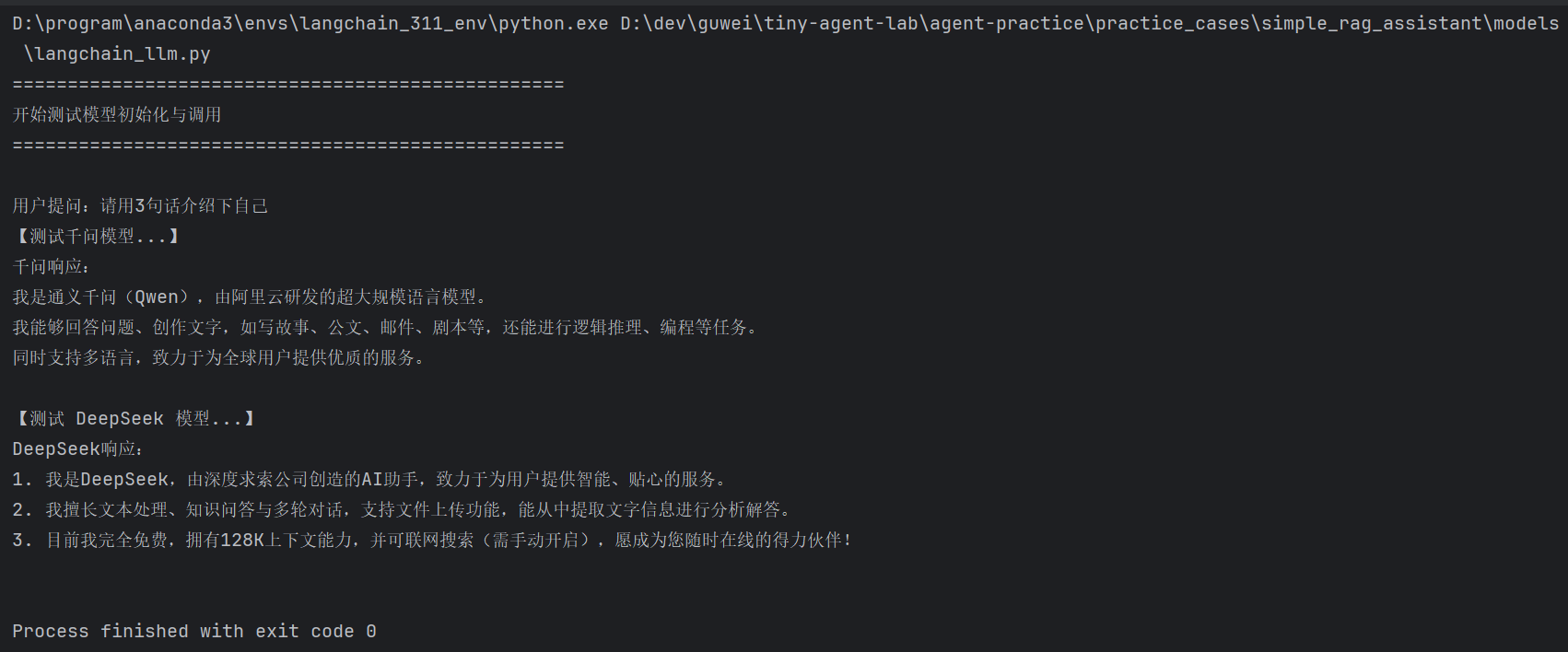
user_query = "请用3句话介绍下自己"
print(f"用户提问:{user_query}")
# 1. 测试千问模型
print("【测试千问模型...】")
qwen_llm = initialize_qwen_llm(model="qwen-plus", temperature=0)
response = qwen_llm.invoke(user_query)
print(f"千问响应:\n{response.content}\n")
# 2. 测试DeepSeek模型
print("【测试 DeepSeek 模型...】")
deepseek_llm = initialize_deepseek_llm("deepseek-chat", temperature=0)
response = deepseek_llm.invoke(user_query)
# 美化输出响应
print(f"DeepSeek响应:\n{response.content}\n")
# 3. 测试OpenAI模型(保留注释,需启用时取消注释即可)
# print("【测试 OpenAI 模型...】")
# 取消下面2行注释即可启用OpenAI测试
# openai_llm = initialize_openai_llm(model="gpt-5", temperature=0.3)
# print("ℹ️ 若需测试OpenAI,取消代码中OpenAI相关的注释即可\n")
运行结果如下:
5 重排模型调用(reranker_model.py)
初始化重排模型,用于对检索阶段召回的候选文档进行语义相关性重排,提升检索精度。
在models文件夹下创建文件reranker_model.py,代码如下:
import logging
from typing import List, Optional
import torch
from langchain_core.documents import Document
from sentence_transformers import CrossEncoder
# 配置日志
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s - %(name)s - %(levelname)s - %(message)s"
)
logger = logging.getLogger(__name__)
class RerankerCrossModel:
def __init__(
self,
model_name_or_path: str = "BAAI/bge-reranker-large",
device: Optional[str] = None,
batch_size: int = 16
):
"""
初始化重排器。用于对检索阶段召回的候选文档进行语义相关性重排,提升检索精度。
适配遵循 sentence-transformers 的 CrossEncoder 规范的模型, 如ms-marco-MiniLM-L-12-v2、bge-reranker-base/large等
Args:
model_name_or_path: str,模型名称(HuggingFace Hub规范名)或本地存储路径:
- 1.模型名称:本地缓存(默认~/.cache/huggingface/)无该模型时,自动从Hub下载权重/配置/分词器;缓存已存在则直接加载,无需重复下载。
- 2.本地路径:需手动下载完整模型文件(包含config.json、model.safetensors/pytorch_model.bin等)到本地路径地址。
device: 模型运行设备,None则自动检测(优先使用CUDA,无则使用CPU)
batch_size: 推理批次大小,建议CPU设8/16,GPU可根据显存适当增大(默认16)
"""
# 设备自动适配
self.device = device if device else ("cuda" if torch.cuda.is_available() else "cpu")
self.batch_size = batch_size
self.model_name_or_path = model_name_or_path
self.reranker_model: Optional[CrossEncoder] = None
# 初始化模型
self._load_model()
def _load_model(self) -> None:
"""加载并重初始化CrossEncoder重排模型"""
try:
self.reranker_model = CrossEncoder(self.model_name_or_path, device=self.device)
logger.info(f"✅重排模型加载完成 | 设备:{self.device} | 批次大小:{self.batch_size}")
except Exception as e:
raise RuntimeError(f"模型加载失败:{e}\n请检查:1. 模型路径是否正确 2. 网络是否正常(首次下载需联网)")
def rerank_documents(
self,
query: str,
documents: List[Document],
top_n: int = 3,
score_threshold: float = 0.0
) -> List[Document]:
"""
对检索到的文档进行重排序
Args:
query: 用户查询问题
documents: 向量检索得到的原始文档列表
top_n: 重排后保留的文档数量
score_threshold: 分数阈值,低于该值的文档会被过滤
Returns:
List[Document]: 重排序后的文档列表(按相关性从高到低)
"""
if not documents:
return []
# 构造模型输入:(query, doc_text) 对
pairs = [(query, doc.page_content) for doc in documents]
# 计算相关性分数
scores = self.reranker_model.predict(pairs)
# 将文档与分数配对并排序
doc_score_pairs = list(zip(documents, scores))
# 按分数降序排序
doc_score_pairs.sort(key=lambda x: x[1], reverse=True)
# 过滤分数阈值并截取top_n
filtered_docs = []
for doc, score in doc_score_pairs:
if score >= score_threshold and len(filtered_docs) < top_n:
# 将分数添加到文档元数据中
doc.metadata["rerank_score"] = float(score)
filtered_docs.append(doc)
elif len(filtered_docs) >= top_n:
break
logger.info(f"重排完成:原始{len(documents)}个文档 → 筛选后{len(filtered_docs)}个文档")
return filtered_docs
测试重排模型
if __name__ == "__main__":
# 测试数据
sample_documents = [
Document(page_content="文档1内容:人工智能入门", metadata={"id": 1}),
Document(page_content="文档2内容:大语言模型原理", metadata={"id": 2}),
Document(page_content="文档3内容:Python 基础教程", metadata={"id": 3}),
Document(page_content="文档4内容:语义检索算法", metadata={"id": 4}),
Document(page_content="文档5内容:机器学习实战", metadata={"id": 5}),
]
# 使用BAAI/bge-reranker-large模型
reranker = RerankerCrossModel(
# 这里加载本地路径模型(需手动下载模型文件到指定路径)
# a.模型文件获取地址:https://modelscope.cn/models/BAAI/bge-reranker-v2-m3
# b.需下载文件:config.json、model.safetensors、special_tokens_map.json、tokenizer.json、tokenizer_config.json
# model_name_or_path="BAAI/bge-reranker-base", # 模型名称
model_name_or_path="../../../data/models_reranker_data/BAAI/bge-reranker-v2-m3", # 模型名称
device="cuda" if torch.cuda.is_available() else "cpu",
batch_size=8
)
query = "大语言模型的语义检索方法"
result_docs = reranker.rerank_documents(
query=query,
documents=sample_documents,
top_n=3
)
# 打印最终结果(新增:输出重排后的详细信息)
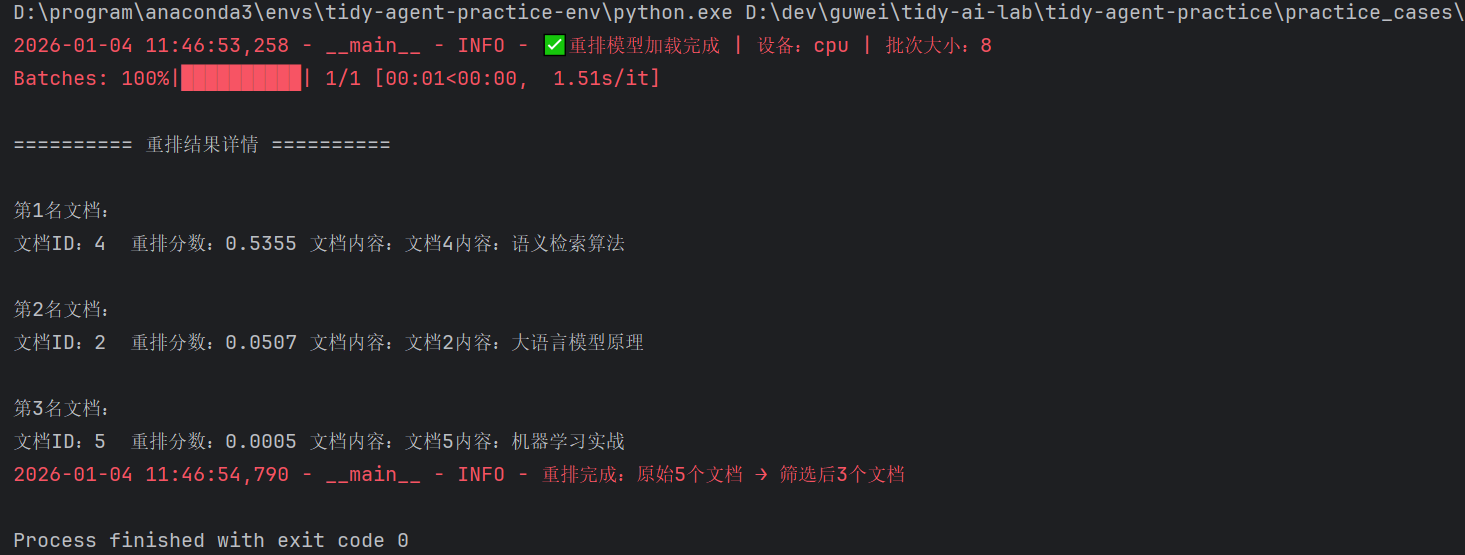
print("\n========== 重排结果详情 ==========")
for i, doc in enumerate(result_docs, 1):
print(f"\n第{i}名文档:")
print(f"文档ID:{doc.metadata['id']} 重排分数:{doc.metadata['rerank_score']:.4f} 文档内容:{doc.page_content}")
执行结果如下:
6 RAG 核心服务(rag_service_stream.py)
该类实现完整检索增强生成(RAG)的核心逻辑:文档处理、向量存储、检索和回答生成。基于 LangChain 构建,核心目标是让大语言模型(LLM)结合上传的文档知识进行问答,解决纯 LLM 可能存在的事实性错误、知识时效性等问题。
在项目目录下创建services文件夹,在该文件夹下创建文件rag_service_stream.py。
一、引入依赖
import logging
import os
import tempfile
from typing import List, Dict, Optional, Any, Generator
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import TextLoader, PyPDFLoader, Docx2txtLoader
from langchain_chroma import Chroma
from langchain.memory import ConversationBufferWindowMemory
from langchain.schema import HumanMessage
from sentence_transformers import CrossEncoder
from models.langchain_embedding import initialize_embedding_model
from models.langchain_llm import langchain_qwen_llm
from models.reranker_model import RerankerCrossModel
二、创建RAGService类并初始化
class RAGService:
"""
RAG(检索增强生成)服务类,实现文档解析、向量化存储及基于检索的知识进行问答,辅助 LLM 生成更准确、有依据的回答。
核心流程:文档上传→解析分块→向量化存储→检索相关片段→LLM生成答案。
支持流式输出。
"""
def __init__(self,
persist_directory: str = "chroma_db",
retrieve_k: int = 8, # 检索 top-k 个相关文本块
enable_reranker: bool = True, # 是否开启重排
model_name_or_path: str = "BAAI/bge-reranker-large", # 重排模型名称(HuggingFace Hub规范名)或本地存储路径
rerank_top_n: int = 4, # 重排后保留数量,必须小于retrieve_k
rerank_score_threshold: float = 0.1 # 重排分数阈值,大于该阈值才被选取
):
"""
初始化RAG服务,加载嵌入模型、LLM模型及已存在的向量数据库。
Args:
persist_directory: 向量数据库持久化存储路径,默认值为"chroma_db"
model_name_or_path: 可选,重排模型名称(HuggingFace Hub规范名)或本地存储路径,默认使用BAAI的bge-reranker-v2-m3(中文性价比较高)
- 1.模型名称:本地缓存(默认~/.cache/huggingface/)无该模型时,自动从Hub下载权重/配置/分词器;缓存已存在则直接加载,无需重复下载。
- 2.本地路径:需手动下载完整模型文件(包含config.json、model.safetensors/pytorch_model.bin等)到本地路径地址。
retrieve_k: 可选,向量检索阶段从数据库中召回的候选文本块数量,默认值10。
rerank_top_n: 可选,从召回的候选文本块中重排筛选后,最终保留的高相关文本块数量,默认值3。约束:必须满足 rerank_top_n < retrieve_k。
rerank_score_threshold:可选,重排结果的分数筛选阈值,默认值0.1。仅得分超过该阈值的文本块会被保留。
"""
# 向量数据库持久化目录
self.persist_directory = persist_directory
# 初始化嵌入模型(用于将文本转换为向量)
self.embeddings = initialize_embedding_model("qwen")
# 检索 top-k 个相关文本块
self.retrieve_k = retrieve_k,
# 初始化向量数据库(若存在)
self.vectordb = self._load_vector_db()
# 初始化大语言模型(用于生成答案)
self.llm = langchain_qwen_llm()
# 是否开启重排
self.enable_reranker = enable_reranker
# 初始化重排模型
self.reranker_model = self._init_rerank_model(model_name_or_path)
# 重排后保留数量,必须小于k
self.rerank_top_n = rerank_top_n
# 重排分数阈值,大于该阈值才被选取
self.rerank_score_threshold = rerank_score_threshold
# 保存当前流式回答,用于完整存储
self.current_stream_answer = ""
# 初始化内存,设置窗口大小 k=50(只保留最近100轮对话)
# ConversationBufferWindowMemory 是 ConversationBufferMemory 的扩展版本,专门用于解决长对话场景下的
# 上下文管理问题。它通过只保留最近的 N 轮对话(滑动窗口机制),在维持对话连贯性的同时,避免历史记录过长导致的 Token 超限问题。
self.memory = ConversationBufferWindowMemory(
k=50, # 窗口大小:仅保留最近50轮对话(1轮=1次用户+1次助手交互)
return_messages=True, # 返回LangChain标准Message对象(而非纯字符串,便于格式统一)
memory_key="chat_history", # 记忆数据的存储键(后续提取历史时使用)
output_key="answer", # 与LLM输出结果的键对齐(适配链式调用规范)
input_key="input" # 与LLM输出结果的键对齐(适配链式调用规范)
)
def _load_vector_db(self) -> Optional[Chroma]:
"""
私有方法:加载已持久化的向量数据库(若目录存在且非空)。
向量数据库用于存储文档片段的向量表示,支持高效的相似性检索。
Returns:
加载成功的Chroma向量数据库实例;若不存在或加载失败,返回None
Raises:
RuntimeError: 数据库加载过程中发生错误时抛出异常
"""
# 路径不存在时自动创建(支持多级目录)
if not os.path.exists(self.persist_directory):
try:
os.makedirs(self.persist_directory, exist_ok=True)
except Exception as e:
error_msg = f"创建Chroma数据库路径失败:{self.persist_directory},错误:{str(e)}"
raise RuntimeError(error_msg) from e
# 检查持久化目录是否存在且非空
try:
return Chroma(
embedding_function=self.embeddings,
persist_directory=self.persist_directory,
)
except Exception as e:
raise RuntimeError(f"向量数据库加载失败(路径:{self.persist_directory}):{str(e)}")
# ===================== 重排模型初始化 =====================
@staticmethod
def _init_rerank_model(model_name_or_path: str = "BAAI/bge-reranker-large") -> RerankerCrossModel | None:
"""
初始化重排模型,用于对检索结果进行语义重排序.默认使用BAAI的bge-reranker-large。
Args:
model_name_or_path: 重排模型名称(HuggingFace Hub规范名)或本地存储路径,
Returns:
CrossEncoder: 初始化后的重排模型实例
"""
try:
# 加载重排模型
rerank_model = RerankerCrossModel(model_name_or_path)
logger.info(f"成功加载重排模型: {model_name_or_path}")
return rerank_model
except Exception as e:
logger.info(f"加载重排模型失败: {str(e)}")
return None
三、文档处理:process_document(file)
处理用户上传的文档,解析、分块、向量化、并存储到向量数据库。
def process_document(self, file: Any) -> Dict[str, bool | str]:
"""
处理用户上传的文档(解析、分块、向量化、存储到向量数据库)。
支持的格式:PDF、DOCX、TXT、MD(可通过扩展loader支持更多格式)。
"""
# -------------------------- (1)文件有效性校验与临时文件创建 ------------------------
# 验证文件对象有效性
if not file or not hasattr(file, 'name') or not hasattr(file, 'getvalue'):
return {"success": False, "message": "无效的文件对象"}
# 提取并标准化文件后缀(转为小写,便于格式判断)
file_name = file.name
file_suffix = file_name.split('.')[-1].lower() if '.' in file_name else ''
tmp_file_path = None # 临时文件路径(用于后续清理)
try:
# 创建临时文件存储上传的文件内容(避免直接操作内存中的二进制数据)
with tempfile.NamedTemporaryFile(
delete=False, # 关闭自动删除,确保加载器能读取
suffix=f".{file_suffix}", # 保留文件后缀,避免加载器解析错误
mode='wb' # 二进制写入模式
) as tmp_file:
tmp_file.write(file.getvalue()) # 写入文件内容
tmp_file_path = tmp_file.name # 记录临时文件路径
# -------------------------- (2)文档加载(按格式适配) -------------------------
# 根据文件后缀选择对应的文档加载器
if file_suffix == 'pdf':
loader = PyPDFLoader(tmp_file_path) # PDF加载器
elif file_suffix == 'docx':
loader = Docx2txtLoader(tmp_file_path) # DOCX加载器
elif file_suffix in ['txt', 'md']:
loader = TextLoader(tmp_file_path, encoding='utf-8') # 文本文件加载器(支持UTF-8编码)
else:
return {
"success": False,
"message": f"不支持的文件类型:{file_suffix},当前支持:pdf/docx/txt/md"
}
# 加载文档内容(返回Document对象列表,每个对象含page_content和metadata)
documents = loader.load()
if not documents: # 处理空文档情况
return {"success": False, "message": "文档加载失败:内容为空或无法解析"}
# -------------------------- (3)文本分块(解决长文本问题) ---------------------
# 初始化文本分块器(解决长文本超出模型上下文窗口的问题)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, # 每个片段的字符数(根据模型上下文调整)
chunk_overlap=200, # 片段间重叠字符数(保持上下文连贯性)
separators=["\n\n", "\n", "。", " ", ""] # 优先按中文标点分割,提升分块合理性
)
# 将文档分割为片段(每个片段作为独立单元存入向量库)
splits = text_splitter.split_documents(documents)
# -------------------------- (4)向量存储 --------------------------
# 将片段添加到向量数据库
if self.vectordb:
# 若数据库已存在,直接添加新片段
self.vectordb.add_documents(splits)
else:
# 若数据库不存在,创建新库并添加片段
self.vectordb = Chroma.from_documents(
documents=splits,
embedding=self.embeddings, # 使用初始化的嵌入模型
persist_directory=self.persist_directory # 指定存储路径
)
return {
"success": True,
"message": f"文档处理成功!共添加 {len(splits)} 个文本片段(文件:{file_name})"
}
except Exception as e: # 捕获所有异常,返回具体错误信息
return {"success": False, "message": f"文档处理失败({file_name}):{str(e)}"}
finally:
# -------------------------- (5)临时文件清理 --------------------------
# 确保临时文件被清理(无论处理成功/失败)
if tmp_file_path and os.path.exists(tmp_file_path):
try:
os.remove(tmp_file_path)
except Exception as e:
print(f"警告:临时文件清理失败(路径:{tmp_file_path}):{str(e)}")
负责将用户上传的文档转换为向量并存储,流程如下:
-
文件有效性校验与临时文件创建:
-
校验文件对象是否包含
name(文件名)和getvalue()(获取二进制内容)方法; -
通过
tempfile.NamedTemporaryFile创建临时文件,写入上传文件的二进制内容(避免直接操作内存数据)。
-
-
文档加载(按格式适配):
根据文件后缀选择对应的 LangChain 加载器,支持 4 种格式:
文件格式 加载器 核心作用 PDF PyPDFLoader解析 PDF 每页内容,生成 Document 对象 DOCX Docx2txtLoader提取 DOCX 文本内容(忽略格式) TXT/MD TextLoader读取纯文本,指定 UTF-8 编码 -
文本分块(解决长文本问题):
使用
RecursiveCharacterTextSplitter进行智能分块,核心配置:chunk_size=1000:每个文本片段最多 1000 字符(适配 LLM 上下文窗口);chunk_overlap=200:片段间重叠 200 字符(避免上下文断裂,比如一个事件描述跨片段);separators=["\n\n", "\n", "。", " ", ""]:优先按大分隔符(如\n\n段落)分割,分割失败再用小分隔符(如。中文句末),最大程度保证语义完整性。
-
向量化存储:
负责将文本(问题、文档片段)转换为高维向量,是「检索」的核心基础,并存入向量数据库中。
- 若向量数据库已存在(
self.vectordb非空),直接添加新分块; - 若不存在,通过
Chroma.from_documents初始化数据库并写入分块向量,同时指定持久化路径。
- 若向量数据库已存在(
-
临时文件清理:
通过
finally块确保无论处理成功 / 失败,临时文件都会被删除,避免磁盘占用。
四、问答生成:get_answer_stream(question, chat_history)
该方法是 RAG(检索增强生成)的核心执行入口,实现检索相关文档→重排→结合历史对话→调用LLM流式生成输出。核心目标是:让 LLM 基于「用户问题 + 历史对话 + 相关文档片段」生成精准、有依据的答案,同时支持上下文连贯对话,流式输出。
def get_answer_stream(self, question: str) -> Generator[str, None, None]:
"""
基于RAG技术生成问题答案,实现流式输出,逐块产生回答内容。
核心流程:检索相关文档片段 →结合对话历史 → 拼接提示词 → 调用LLM生成答案。
Args:
question: 用户当前的问题(字符串类型,非空)
Returns:
生成的答案字符串;若发生错误,返回错误提示;若未上传文档,返回引导提示
"""
# 重置当前流式回答
self.current_stream_answer = ""
# -------------------------- 1. 检查向量数据库是否初始化(是否已上传文档) -------------
if not self.vectordb:
yield "请先上传并处理文档,才能进行问答哦~"
return
if not question or not isinstance(question, str) or question.strip() == "":
yield "请输入有效的问题内容~"
return
# -------------------------- 2. 对话历史记忆加载(适配长对话) -----------------------
# 上下文管理
combine_contexts = []
# 加载对话历史记忆,设置窗口大小 k=50(保留最近100轮对话,滑动窗口机制),在维持对话连贯性的同时,避免历史记录过长导致的 Token 超限问题。
for msg in self.memory.load_memory_variables({})["chat_history"]:
combine_contexts.append(msg)
# ------------------------ 3. 文档检索:获取问题相关的事实依据 ------------------------
# 创建向量数据库检索器,根据问题检索相关文档片段
retriever = self.vectordb.as_retriever(search_kwargs={"k": 5})
relevant_docs = retriever.invoke(question)
# ------------------------ 4. 对检索的相关文档进行重排 ------------------------
if self.reranker_model and self.enable_reranker:
filters_docs = self.reranker_model.rerank_documents(
query=question,
documents=relevant_docs,
top_n=self.rerank_top_n,
score_threshold=self.rerank_score_threshold
)
if filters_docs: # 若未重排未筛选到文档,就自动选取前rerank_top_n个检索的相关文档
relevant_docs = filters_docs
logger.info(f"重排后提取 {len(relevant_docs)} 个相关文本块")
else:
relevant_docs = relevant_docs[:self.rerank_top_n]
logger.info(f"重排后未筛选到文档,提取检索的 {len(relevant_docs)} 个相关文本块")
# -------------------------- 5. 提示词构建:拼接完整提示词 --------------------------
# 提取片段内容,格式化为字符串(便于拼接提示)
context_text = "\n\n".join([doc.page_content for doc in relevant_docs])
# 系统提示词模板:明确LLM角色、回答规则(避免幻觉)和输入结构(Context/History/Question)
system_prompt = """
你是基于文档的问答助手,仅使用以下提供的文档片段(Context)回答问题。
如果文档中没有相关信息,直接说“根据提供的文档,无法回答该问题”,不要编造内容。
回答需简洁、准确,结合历史对话(History)理解上下文,每一次回答要重新审视当前提供的内容,不要只是简单重复历史回答。
Context:
{context_text}
Current Question: {question}
Answer:
"""
# 使用检索的相关文档片段和用户输入问题格式化提示模板
final_prompt = system_prompt.format(
context_text=context_text,
question=question
)
# 添加最终提示到上下文中
combine_contexts.append(HumanMessage(content=final_prompt))
logger.info(f"combine_contexts:{combine_contexts}")
# -------------------------- 6. 流式调用LLM:逐块生成并返回答案 ----------------------
try:
# 流式调用LLM:llm.stream()返回生成器,逐块获取LLM输出(而非等待完整答案)
for chunk in self.llm.stream(combine_contexts):
# 实时返回输出内容
if chunk.content:
yield chunk.content
self.current_stream_answer += chunk.content
# 完整答案生成后,更新对话记忆:将本次问答(问题+完整答案)存入记忆,供下一轮对话复用
self.memory.save_context(
inputs={"input": question},
outputs={"answer": self.current_stream_answer}
)
logger.info(f"self.memory.save_context:{self.memory.model_dump_json()}")
except Exception as e:
logger.error(f"错误:答案生成失败:{str(e)}")
yield "抱歉,处理问题时发生错误,请稍后再试~"
流程如下:
-
前置校验
-
检查向量数据库是否初始化(即是否已上传文档) 。
-
检查用户问题是否有效(非空字符串)。
-
-
对话历史加载
通过
ConversationBufferWindowMemory(滑动窗口记忆)管理对话历史,配置k=50,仅保留最近 50 轮对话(1 轮 = 1 次用户提问 + 1 次助手回答),既保证对话连贯性,又避免长对话导致的 Token 超限问题。 -
检索相关文档(获取回答的事实依据)
基于向量检索技术,从已上传文档中提取与用户问题语义相似的文本片段:
-
将向量数据库转为检索器(
self.vectordb.as_retriever); -
配置
search_kwargs={"k": 5}:检索与用户问题最相关的 5 个文本片段(k值可调整,平衡相关性与上下文长度); -
提取检索结果的文本内容,拼接为
context_text(供 LLM 参考)。
-
-
检索文档重排(提升文档相关性精度)
对原始检索结果进行精细化筛选,进一步提升文档与问题的匹配度:
- 若配置了重排模型(
self.reranker_model),则调用模型对原始检索的文本片段进行重排; - 重排规则:按「相关性分数」筛选 Top-N 个片段(
top_n可配置),并过滤分数低于阈值(score_threshold)的片段; - 降级处理:若重排后无符合条件的片段,则默认选取原始检索结果的前 N 个片段。
- 若配置了重排模型(
-
组合提示词
- 初始化上下文对话列表:combine_contexts = []。
- 添加历史对话记忆:从记忆中加载最近对话列表(Message对象)到上下文对话中,让 LLM 清晰识别历史交互逻辑。
- 定义提示词模板(
system_prompt):定义 LLM 的角色、回答规则,如:仅使用提供的文档片段回答,无相关信息时明确告知,不编造内容。 - 格式化提示模板:将
context_text(检索到的文档)、question(当前问题) 格式化提示模板,生成结构化的final_prompt,并作为用户输入添加到上下文对话中。
-
流式调用LLM输出结果及记忆更新
实现流式输出回答,并将本次交互存入记忆以支撑后续对话:
- 流式生成回答:调用
self.llm.stream(combine_contexts),将完整上下文提交给 LLM,逐块读取生成器中的响应片段并实时返回给用户,同时将片段拼接为self.current_stream_answer(完整答案); - 对话记忆更新:当完整答案生成后,将本次问答对(用户问题
question+ 完整答案self.current_stream_answer)存入记忆ConversationBufferWindowMemory,供下一轮对话。
流式输出提升用户体验,记忆更新保障下一轮对话可复用本次交互信息,维持上下文连贯。
- 流式生成回答:调用
五、清空数据库clear_database()
支持重新上传文档、清空历史知识。
def clear_database(self) -> bool:
"""清空向量数据库"""
try:
if self.vectordb:
self.vectordb.reset_collection()
# 清除记忆
self.memory.clear()
return True
except Exception as e:
print(f"错误:数据库清空失败:{str(e)}")
return False
清空 Chroma 向量数据库的集合内数据(reset_collection)。
7 前端界面(main.py)
通过 Streamlit 框架搭建 Web 交互界面,通过 “上传文档→提问” 的操作,获得基于文档的精准回答,同时支持流式输出(边生成边展示)和聊天连续性。
import os
import sys
import streamlit as st
from dotenv import load_dotenv
# 将当前脚本所在目录加入Python搜索路径(确保能找到services目录下的RAGService)
current_dir = os.path.dirname(os.path.abspath(__file__))
sys.path.append(current_dir)
from services.rag_service_stream import RAGService
# 加载环境变量
load_dotenv()
# 配置页面标题、图标、布局
st.set_page_config(
page_title="RAG知识问答助手",
page_icon=":robot:",
layout="wide"
)
# 初始化Streamlit会话状态(跨刷新保存数据,避免页面刷新后数据丢失)
def initialize_app():
# 初始化会话状态
if "history" not in st.session_state:
st.session_state.history = []
# 用于重置文件上传框状态的会话变量
if "upload_key" not in st.session_state:
st.session_state.upload_key = 0
# 初始化RAG配置参数
if "retrieve_k" not in st.session_state:
st.session_state.retrieve_k = 6 # 默认检索文档数量
if "enable_reranker" not in st.session_state:
st.session_state.enable_reranker = False # 默认开启重排
if "rerank_top_n" not in st.session_state:
st.session_state.rerank_top_n = 5 # 重排后保留文档数量
# 初始化RAG核心服务(封装了文档处理、向量存储、流式问答的核心逻辑)
if "rag_service" not in st.session_state:
st.session_state.rag_service = RAGService(
retrieve_k=st.session_state.retrieve_k,
enable_reranker=st.session_state.enable_reranker,
rerank_top_n=st.session_state.rerank_top_n,
# 重排模型配置:用于对检索结果进行语义重排序.默认使用BAAI的bge-reranker-v2-m3(中文效果性价比较高)。
# 这里加载本地路径模型(需手动下载模型文件到指定路径)
# a.模型文件获取地址:https://modelscope.cn/models/BAAI/bge-reranker-v2-m3
# b.需下载文件:config.json、model.safetensors、special_tokens_map.json、tokenizer.json、tokenizer_config.json
model_name_or_path="../../data/models_reranker_data/BAAI/bge-reranker-v2-m3" # 指定重排模型本地存储路径
)
initialize_app()
# 定义侧边栏区域
with st.sidebar:
st.subheader("RAG知识问答助手")
# RAG检索配置区域
# 1. 检索数量控制
retrieve_k = st.slider(
"初始检索文档数量 (retrieve_k)",
min_value=1, max_value=10, value=st.session_state.retrieve_k, step=1,
help="从向量库中初始检索的文档数量,数量越多覆盖范围越广,但可能引入噪音"
)
# 2. 重排功能开关
enable_reranker = st.toggle(
"开启检索结果重排",
value=st.session_state.enable_reranker,
help="开启后会对检索到的文档进行语义重排序,提升回答质量,但会增加响应时间"
)
# 3. 重排后保留数量(仅在开启重排时可配置)
rerank_top_n = st.slider(
"重排后保留文档数量 (rerank_top_n)",
min_value=1, max_value=8, value=st.session_state.rerank_top_n, step=1,
help="重排后最终保留的文档数量,需小于等于初始检索数量",
disabled=not enable_reranker # 关闭重排时禁用该参数
)
# 限制rerank_top_n不超过retrieve_k
if rerank_top_n > retrieve_k:
rerank_top_n = retrieve_k
st.warning(f"重排保留数量自动调整为 {retrieve_k}(不超过初始检索数量)")
# 4. 应用配置按钮
if st.button("应用配置", use_container_width=True, type="primary"):
# 更新会话状态
st.session_state.enable_reranker = enable_reranker
st.session_state.retrieve_k = retrieve_k
st.session_state.rerank_top_n = rerank_top_n
# 更新RAGService的配置
st.session_state.rag_service.enable_reranker = enable_reranker
st.session_state.rag_service.retrieve_k = retrieve_k
st.session_state.rag_service.rerank_top_n = rerank_top_n
st.success("配置已更新生效!")
# 文档管理区域
st.divider() # 添加分隔线
# 1. 多文件上传(支持PDF/DOCX/TXT/MD,与RAGService支持的格式一致)
uploaded_files = st.file_uploader(
"上传文档 (PDF/DOCX/txt/md)",
accept_multiple_files=True,
key=f"file_uploader_{st.session_state.upload_key}" # 动态生成key
)
# 处理上传的文件:调用RAGService的process_document方法,完成“解析→分块→向量化→入库”
if uploaded_files:
with st.spinner("正在处理文档..."):
for file in uploaded_files:
st.session_state.rag_service.process_document(file)
st.success(f"已成功处理 {len(uploaded_files)} 个文档")
# 处理完成后重置上传框:通过改变key值实现
st.session_state.upload_key += 1
# 2. 清空知识库(删除向量库数据+清空聊天历史,重置整个问答环境)
if st.button("清空知识库", type="secondary", use_container_width=True):
with st.spinner("正在清空知识库..."):
# 清空向量存储
st.session_state.rag_service.clear_database()
# 清空聊天历史
st.session_state.history = []
st.success("知识库已成功清空")
# 主界面 - 聊天区域
st.header("从0开始:用 Streamlit + LangChain搭建一个简单基于RAG问答聊天助手")
# 1. 展示聊天历史(遍历session_state.history,按角色显示消息)
for message in st.session_state.history:
with st.chat_message(message["role"]):
st.markdown(message["content"])
# 2. 处理用户输入
user_input = st.chat_input("请问有什么可以帮助您?")
if user_input:
# 步骤1:将用户消息添加到会话历史
st.session_state.history.append({"role": "user", "content": user_input})
with st.chat_message("user"):
st.markdown(user_input)
# 步骤2:调用RAG服务生成流式回答,并显示
with st.chat_message("assistant"):
with st.spinner("思考中..."):
# RAG回答,非流式:大模型完整输出后才展示出来
# full_answer = rag_service.get_answer(user_input)
# st.markdown(full_answer)
# RAG回答,流式输出
full_answer = "" # 用于存储完整的回复内容
# 调用RAGService的get_answer_stream(流式方法),用st.write_stream实现边生成边显示
for chunk in st.write_stream(st.session_state.rag_service.get_answer_stream(user_input)):
full_answer += chunk
# 步骤3:将完整的助手回答添加到会话历史,供下次刷新时展示
st.session_state.history.append({"role": "assistant", "content": full_answer})
st.rerun()
交互流程如下:
- 准备阶段:用户打开网页,看到侧边栏的 “文档上传” 和主界面的聊天区域;
- 上传文档:用户在侧边栏选择 1 个或多个文档(PDF/DOCX 等),点击上传,系统显示 “正在处理文档…”,完成后提示 “处理成功”;
- 提问交互:用户在底部输入框提问(如 “公司的发展历程?”),点击发送;
- 流式回答:系统显示 “思考中”,并开始逐字 / 逐句显示回答(流式输出),同时将用户问题和助手回答保存到聊天历史;
- 重置操作:若用户想切换文档,可点击侧边栏 “清空知识库”,系统删除所有文档和聊天历史,恢复初始状态。
4.6 运行测试
-
确保
.env文件已正确配置 API 密钥 -
在项目根目录下,打开终端执行命令:
cd simple_rag_assistant streamlit run main.py
系统将启动 Web 服务,默认地址为 http://localhost:8501
-
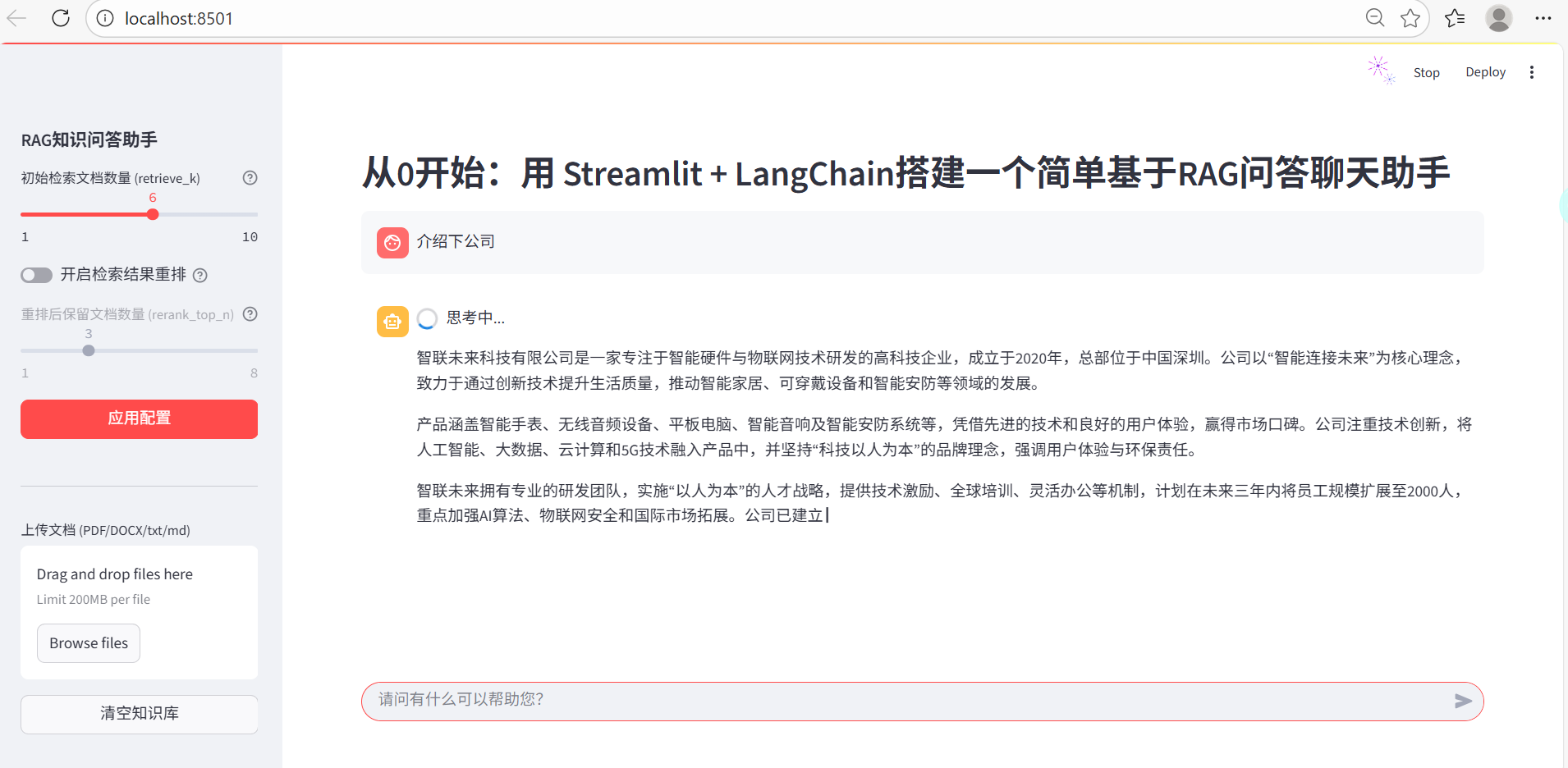
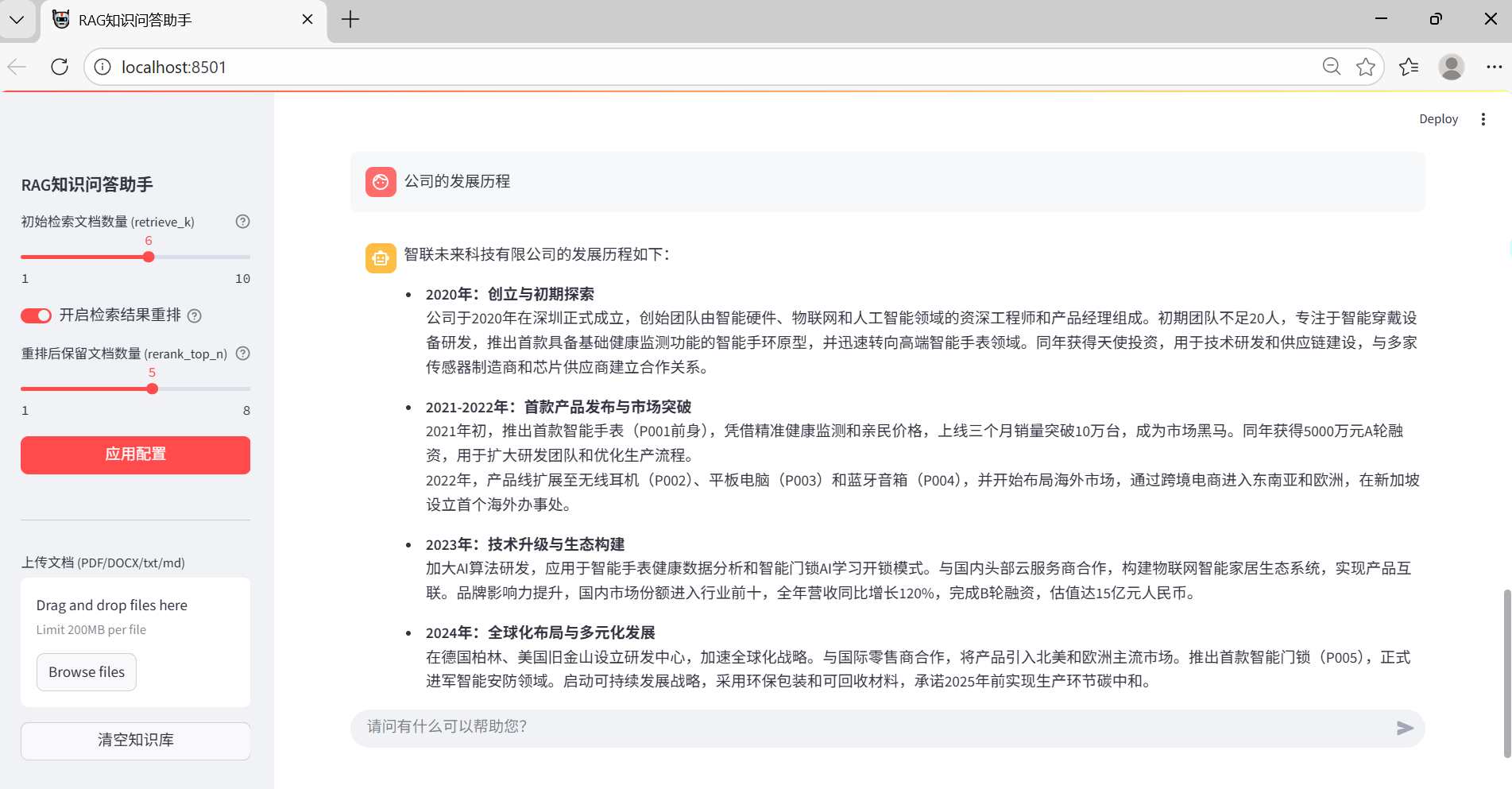
浏览器会自动打开界面,使用流程:
- 在侧边栏上传文档(支持多文件)。
- 等待文档处理完成(会显示处理成功提示)。
- 在底部输入框提问,助手会基于上传的文档内容回答。
完整代码位于项目根目录下:practice_cases/simple_rag_assistant
完整源码地址:
- GitHub 仓库:https://github.com/tinyseeking/tidy-agent-practice/tree/main/practice_cases/simple_rag_assistant
- Gitee 仓库(国内):https://gitee.com/tinyseeking/tidy-agent-practice/tree/main/practice_cases/simple_rag_assistant
4.7 总结
本项目构建了一个功能完整的基础 RAG 问答系统,采用模块化设计保证了代码的可维护性和可扩展性。你可以在此基础上,进一步拓展核心能力与使用体验,如:
- 增加更多文档格式支持(如 PPT、Excel)和多模态识别。
- 实现文档分段预览和定位。
- 添加用户认证和权限管理。
- 优化检索策略,实现更精准的内容匹配与高效召回。
- 增加模型选择功能,允许用户切换不同的 LLM。
通过该项目,你将掌握 RAG 技术的核心原理与工程化实现方法,为后续搭建更复杂的智能检索增强生成(RAG)应用奠定技术基础。
# 步骤3:将完整的助手回答添加到会话历史,供下次刷新时展示
st.session_state.history.append({"role": "assistant", "content": full_answer})
st.rerun()
交互流程如下:
1. **准备阶段**:用户打开网页,看到侧边栏的 “文档上传” 和主界面的聊天区域;
2. **上传文档**:用户在侧边栏选择 1 个或多个文档(PDF/DOCX 等),点击上传,系统显示 “正在处理文档...”,完成后提示 “处理成功”;
3. **提问交互**:用户在底部输入框提问(如 “公司的发展历程?”),点击发送;
4. **流式回答**:系统显示 “思考中”,并开始逐字 / 逐句显示回答(流式输出),同时将用户问题和助手回答保存到聊天历史;
5. **重置操作**:若用户想切换文档,可点击侧边栏 “清空知识库”,系统删除所有文档和聊天历史,恢复初始状态。
## 4.6 运行测试
1. 确保`.env`文件已正确配置 API 密钥
2. 在项目根目录下,打开终端执行命令:
```bash
cd simple_rag_assistant
streamlit run main.py
[外链图片转存中…(img-lTtPN4zA-1770195091217)]
系统将启动 Web 服务,默认地址为 http://localhost:8501
-
浏览器会自动打开界面,使用流程:
- 在侧边栏上传文档(支持多文件)。
- 等待文档处理完成(会显示处理成功提示)。
- 在底部输入框提问,助手会基于上传的文档内容回答。
[外链图片转存中…(img-TPMjIyMY-1770195091217)]
[外链图片转存中…(img-VjrMFHTk-1770195091219)]
完整代码位于项目根目录下:practice_cases/simple_rag_assistant
完整源码地址:
- GitHub 仓库:https://github.com/tinyseeking/tidy-agent-practice/tree/main/practice_cases/simple_rag_assistant
- Gitee 仓库(国内):https://gitee.com/tinyseeking/tidy-agent-practice/tree/main/practice_cases/simple_rag_assistant
4.7 总结
本项目构建了一个功能完整的基础 RAG 问答系统,采用模块化设计保证了代码的可维护性和可扩展性。你可以在此基础上,进一步拓展核心能力与使用体验,如:
- 增加更多文档格式支持(如 PPT、Excel)和多模态识别。
- 实现文档分段预览和定位。
- 添加用户认证和权限管理。
- 优化检索策略,实现更精准的内容匹配与高效召回。
- 增加模型选择功能,允许用户切换不同的 LLM。
通过该项目,你将掌握 RAG 技术的核心原理与工程化实现方法,为后续搭建更复杂的智能检索增强生成(RAG)应用奠定技术基础。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 11
11 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)