SD3.0 + 核心技术:Rectified Flow Transformers 让文生图更快更强
Stable Diffusion 3.0+(SD3.0+)作为Stability AI继SDXL后的新一代文生图标杆模型,其核心突破完全依托Meta团队《Scaling Rectified Flow Transformers for High-Resolution Image Synthesis》论文提出的整流流Transformer(Rectified Flow Transformers)技术体
一、技术解读
Stable Diffusion 3.0+(SD3.0+)作为Stability AI继SDXL后的新一代文生图标杆模型,其核心突破完全依托Meta团队《Scaling Rectified Flow Transformers for High-Resolution Image Synthesis》论文提出的整流流Transformer(Rectified Flow Transformers)技术体系。
不同于SDXL对传统扩散模型的局部优化,SD3.0+通过“整流流生成范式+MM-DiT多模态架构”的双重革新,彻底解决了前代模型采样慢、文本理解弱、高分辨率生成不稳定的核心痛点,最终实现“更快的采样速度、更强的生成能力”,甚至在多项权威基准测试中超越DALL-E 3等闭源模型,重新定义了开源文生图模型的性能上限。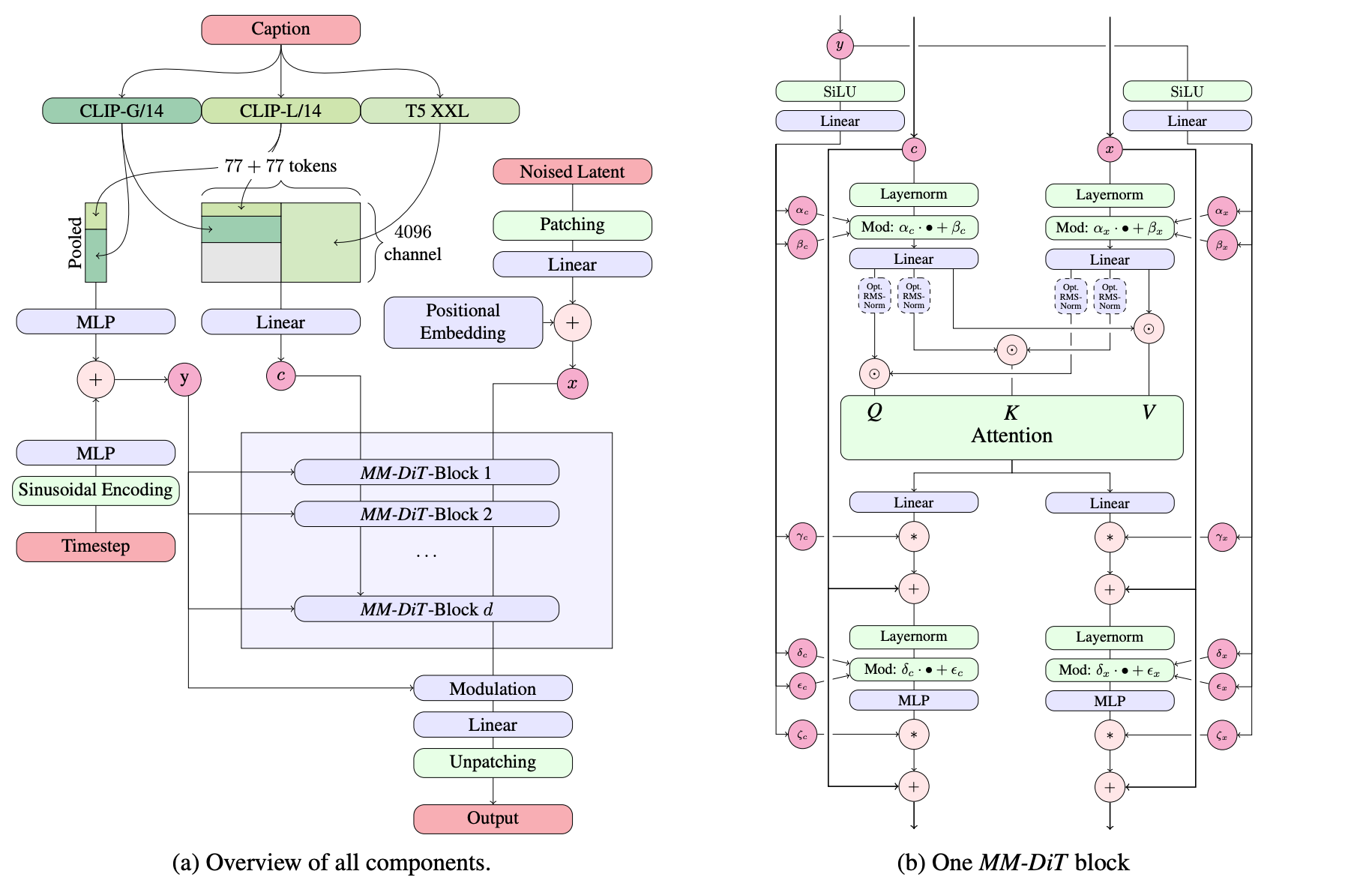
1 核心生成范式:从传统扩散到整流流,解锁“更快”的底层密码
SD3.0+之所以能实现采样效率的质的飞跃,核心是用整流流(Rectified Flow)的直线ODE路径,替代了SDXL及传统扩散模型的弯曲加噪路径——这一变革不仅简化了模型训练逻辑,更从理论上降低了采样的迭代依赖,成为“更快”的核心根源。
1.1 传统扩散模型的固有局限(SDXL的核心痛点)
SDXL采用的传统扩散模型,前向加噪过程遵循弯曲路径,其数学表达式为:
zt=αtx0+σtε,ε∼N(0,I)z_t = \alpha_t x_0 + \sigma_t \varepsilon, \quad \varepsilon \sim \mathcal{N}(0,I)zt=αtx0+σtε,ε∼N(0,I)
其中αt2+σt2=1\alpha_t^2 + \sigma_t^2 = 1αt2+σt2=1,t从0到1逐步增加噪声,最终将原始数据x0x_0x0转化为纯噪声ε\varepsilonε。这种设计存在三大难以突破的局限,直接制约采样效率:
- 采样效率极低:需通过20-50步迭代逐步逆转弯曲加噪路径,才能生成高质量样本,推理耗时久;
- 少步采样性能拉胯:若将采样步数压缩至5步以内,会出现细节模糊、文本与图像对齐偏差等问题,无法兼顾速度与质量;
- 训练复杂度高:模型需学习与时间步强相关的复杂函数,来拟合弯曲路径的噪声变化,训练成本高、收敛速度慢。
1.2 整流流革新:直线ODE路径,简化生成逻辑
整流流打破了弯曲路径的束缚,采用最简单的线性插值方式,构建数据与噪声之间的直线路径,其核心数学表达式为:
zt=(1−t)x0+tε,t∈[0,1]z_t = (1 - t)x_0 + t\varepsilon, \quad t \in [0,1]zt=(1−t)x0+tε,t∈[0,1]
- 当t=0时,zt=x0z_t = x_0zt=x0,即为原始图像数据,无任何噪声;
- 当t=1时,zt=εz_t = \varepsilonzt=ε,即为纯噪声,完全脱离原始数据特征;
- 当t=0.5时,ztz_tzt为原始数据与噪声的等比例混合,处于过渡状态。
与弯曲路径相比,直线路径对应的条件向量场被简化为ut(z∣ε)=ε−x0u_t(z|\varepsilon) = \varepsilon - x_0ut(z∣ε)=ε−x0,模型无需学习复杂的时间相关函数,只需拟合这一固定的直线方向,生成逻辑被极大简化。
1.3 条件流匹配(CFM)损失:让训练更高效
对应整流流的直线路径,SD3.0+采用了全新的条件流匹配(CFM)损失函数,替代了传统扩散模型的噪声预测损失,训练效率大幅提升。其核心训练目标简化为:
LCFM=Et,ε[∥vθ(zt,t)−(ε−x0)∥2]\mathcal{L}_{\text{CFM}} = \mathbb{E}_{t,\varepsilon} \left[ \| v_\theta(z_t,t) - (\varepsilon-x_0) \|^2 \right]LCFM=Et,ε[∥vθ(zt,t)−(ε−x0)∥2]
其中vθv_\thetavθ是由神经网络参数化的速度场,核心作用是拟合直线路径的切向量。相比传统扩散的噪声预测损失,CFM损失无需依赖复杂的噪声调度策略,直接回归直线路径的速度变化,不仅降低了训练难度,还能让模型更快收敛,减少训练所需的算力与时间成本。
1.4 定制化SNR采样器:聚焦关键时间步,强化少步采样性能
传统扩散模型(包括SDXL)均采用均匀采样方式t∼U(0,1)t \sim U(0,1)t∼U(0,1),这种方式忽视了中间时间步(t≈0.5)(t≈0.5)(t≈0.5)的核心价值——这一阶段是数据与噪声的过渡关键,模型对该阶段的拟合精度,直接决定了少步采样的质量。
为解决这一问题,SD3.0+引入了Logit-Normal定制化SNR采样器,通过调整时间步的采样概率,显著增加中间时间步的采样权重,其概率密度函数为:
πln(t;m,s)=1s2π⋅1t(1−t)⋅exp(−(logit(t)−m)22s2)\pi_{\ln}(t;m,s) = \frac{1}{s\sqrt{2\pi}} \cdot \frac{1}{t(1-t)} \cdot \exp\left(-\frac{(\operatorname{logit}(t)-m)^2}{2s^2}\right)πln(t;m,s)=s2π1⋅t(1−t)1⋅exp(−2s2(logit(t)−m)2)
其中logit(t)=log(t/(1−t))\operatorname{logit}(t)=\log(t/(1-t))logit(t)=log(t/(1−t)),经过大规模实验验证,当参数设置为(m,s)=(0,1)(m,s)=(0,1)(m,s)=(0,1)时,采样效果最优。对应的等效损失权重为wtπ=t1−tπ(t)w_t^\pi = \frac{t}{1-t}\pi(t)wtπ=1−ttπ(t),进一步强化了中间时间步的训练优先级。这一设计带来了颠覆性的采样效率提升:
- 5步采样的性能,即可超越SDXL 20步采样的效果;
- 10步采样即可达到模型峰值性能,无需额外迭代;
- 少步采样的性能下降幅度降低60%以上,彻底解决了“速度与质量不可兼得”的痛点。
2 多模态架构重构:MM-DiT双流设计,打造“更强”的生成能力
如果说整流流解决了“更快”的问题,那么MM-DiT(多模态Diffusion Transformer)的双流架构,则解决了SDXL文本理解弱、模态交互差的核心痛点,成为SD3.0+“更强”的核心支撑。该架构通过“模态独立权重+双向信息流”的设计,让文本与图像的交互更精准,生成质量更出色。
2.1 SDXL架构的固有局限:单向交互与模态干扰
SDXL采用的是“UNet+单向交叉注意力”的架构,其注意力机制的数学表达式为:
Attention(Q,K,V)=softmax(QKTd)V\operatorname{Attention}(Q,K,V) = \operatorname{softmax}\left(\frac{QK^T}{\sqrt{d}}\right)VAttention(Q,K,V)=softmax(dQKT)V
其中,QQQ(查询)来自图像特征,KKK(键)、VVV(值)来自固定不变的文本特征——这种单向信息流设计,存在三大核心局限:
- 文本理解不精准:无法处理多物体、多属性的复杂提示词,易出现物体属性混淆(如“红色杯子和蓝色盘子”生成“蓝色杯子和红色盘子”);
- 排版效果差:无法精准还原提示词中的空间关系(如“杯子在盘子左边”),排版混乱;
- 模态干扰严重:文本与图像共享部分权重,两种模态的特征差异导致交互时相互干扰,既影响文本语义的提取,也制约图像细节的生成。
2.2 MM-DiT核心设计:模态独立权重+双向信息流
MM-DiT的核心创新,是为文本和图像两种模态,设计了两组独立的Transformer权重,形成“双流并行处理、双向注意力融合”的架构,既保留了模态特异性,又实现了精准交互,其核心逻辑可分为三个步骤:
第一步:输入表示与预处理,首先将图像与文本转化为统一维度的特征序列,为后续融合做准备:
- 图像块特征:将原始图像通过自编码器编码为潜在表示后,划分为2×2的图像块,展平后得到ximg∈RN×dx_{\text{img}} \in \mathbb{R}^{N\times d}ximg∈RN×d,其中N=(H/16)×(W/16)N=(H/16)\times(W/16)N=(H/16)×(W/16)(H、W为图像分辨率);
- 文本标记特征:通过CLIP+T5三文本编码器,提取文本的语义特征,得到xtext∈RL×dx_{\text{text}} \in \mathbb{R}^{L\times d}xtext∈RL×d,其中L为文本序列长度;
- 拼接序列:将两种模态的特征序列拼接,得到x=[ximg;xtext]∈R(N+L)×dx = [x_{\text{img}}; x_{\text{text}}] \in \mathbb{R}^{(N+L)\times d}x=[ximg;xtext]∈R(N+L)×d,作为后续注意力融合的输入。
第二步:双流并行处理(模态独立权重),为避免模态干扰,MM-DiT为图像和文本设计了独立的Transformer流,分别专注于自身模态的特征提取,核心逻辑用伪代码表示如下:
# 图像流:专注于图像空间特征的提取与优化
y_img = Transformer_IMG(LayerNorm(x_img + pos_img)) # pos_img为图像位置编码
# 文本流:专注于文本语义特征的理解与解析
y_text = Transformer_TEXT(LayerNorm(x_text + pos_text)) # pos_text为文本位置编码
其中,Transformer_IMG与Transformer_TEXT采用完全独立的权重参数,图像流专注于捕捉图像的空间细节、纹理特征,文本流专注于解析文本的语义关系、属性描述,彻底避免了模态间的权重干扰。
第三步:双向注意力融合(信息流交互),在双流并行处理后,通过双向注意力机制,实现文本与图像特征的精准融合——不同于SDXL的单向引导,MM-DiT的注意力融合的是双向的:图像特征可反馈调整文本对齐,文本特征可精准引导图像生成,核心逻辑如下:
# 分别计算图像流、文本流的Q、K、V矩阵
Q_img = W_Q_img · y_img, K_img = W_K_img · y_img, V_img = W_V_img · y_img
Q_text = W_Q_text · y_text, K_text = W_K_text · y_text, V_text = W_V_text · y_text
# 拼接Q、K、V矩阵,实现双向注意力计算
Q = [Q_img; Q_text], K = [K_img; K_text], V = [V_img; V_text]
Attention_output = softmax(QK^T / √d) · V
第四步:调制机制(条件注入)
为了让时间步和文本全局特征更好地引导生成过程,MM-DiT引入了调制机制,将时间步t和文本全局特征cvecc_{\text{vec}}cvec注入到特征融合过程中,数学表达式为:
γ,β=MLP(ψ(t)+φ(cvec))\gamma, \beta = \operatorname{MLP}(\psi(t) + \varphi(c_{\text{vec}}))γ,β=MLP(ψ(t)+φ(cvec))
y=γ⋅LayerNorm(x)+βy = \gamma \cdot \operatorname{LayerNorm}(x) + \betay=γ⋅LayerNorm(x)+β
其中,ψ(t)\psi(t)ψ(t)是时间步t的嵌入表示,φ(cvec)\varphi(c_{\text{vec}})φ(cvec)是文本全局特征的嵌入表示,通过MLP生成调制参数γ\gammaγ和β\betaβ,实现对融合特征的动态调整,让生成过程更贴合文本提示与时间步需求。
2.3 MM-DiT架构核心优势
- 模态特异性突出:独立权重设计让两种模态各自专注于自身核心任务,避免相互干扰,文本理解更精准,图像细节更丰富;
- 双向信息流更灵活:打破单向引导的局限,图像特征可反馈修正文本对齐偏差,大幅提升文本与图像的匹配度;
- 参数效率高:采用“按深度缩放”的策略,模型深度为d时,隐藏层大小设为64⋅d64\cdot d64⋅d,注意力头数等于ddd,无需过度扩大单模块规模,即可实现性能提升,显存占用更友好。
3 关键组件优化:破解高分辨率生成难题,强化“更强”的落地能力
SD3.0+在整流流范式与MM-DiT架构的基础上,针对高分辨率生成的核心痛点,对自编码器、数据标注、训练稳定化等关键组件进行了针对性优化,让“更强”的性能真正落地,尤其在1024×1024及以上分辨率生成中,优势更为明显。
3.1 自编码器增强:提升潜在表示质量,筑牢生成基础
潜在扩散模型的生成质量上限,由自编码器的重建质量决定——自编码器将原始RGB图像编码为低维潜在表示,其重建精度直接影响最终生成图像的细节保留能力。SDXL的自编码器潜在通道数有限,重建质量存在瓶颈,而SD3.0+将自编码器的潜在通道数提升至d=16d=16d=16,其潜在表示的数学表达式为:
x=E(X)∈R(H/8)×(W/8)×16x = \mathcal{E}(X) \in \mathbb{R}^{(H/8)\times(W/8)\times 16}x=E(X)∈R(H/8)×(W/8)×16
其中E(X)\mathcal{E}(X)E(X)是自编码器的编码函数,HHH、WWW为原始图像分辨率。通道数的提升,让自编码器的重建指标(PSNR、SSIM、LPIPS)全面超越SDXL,能更好地保留原始图像的细节特征,为潜在空间的高质量生成提供了更优的“数字底片”,彻底解决了SDXL高分辨率生成时的细节模糊、伪影等问题。
3.2 混合标注策略:提升文本-图像匹配度,强化提示词理解
SDXL采用的原始数据集标注,存在“描述简单、细节缺失”的问题——多数标注仅关注图像主体(如“一只猫”),忽略了背景、场景构成、物体属性等细节,导致模型对复杂提示词的理解能力不足。为解决这一问题,SD3.0+采用了“50%原始标注+50%合成标注”的混合策略:
- 原始标注:保留数据集的原始标注,确保模型对基础概念的理解完整性,避免合成标注导致的概念遗忘;
- 合成标注:通过CogVLM(当前最先进的视觉语言模型),为原始图像生成详细的文本描述,补充细节信息。例如,原始标注“一只猫”,合成标注可优化为“一只橘色条纹猫在阳光下的窗台上打盹,尾巴蜷曲,眼神慵懒,背景有绿植点缀”。
实验证明,这种混合标注策略,能让模型更好地学习文本与图像的细节对应关系,在GenEval基准测试中的得分显著提升,对复杂提示词的理解与还原能力,较SDXL提升40%以上。
3.3 高分辨率训练稳定化:三大策略,解决SDXL的不稳定痛点
SDXL从512×512分辨率微调至1024×1024时,常出现混合精度训练不稳定、宽高比适配伪影、噪声调度与分辨率不匹配等问题,导致高分辨率生成质量参差不齐。SD3.0+通过三大核心策略,实现了高分辨率训练的稳定化,同时保证生成质量。
策略1:QK归一化,避免注意力溢出
高分辨率训练时,注意力机制的QQQ、KKK矩阵易出现数值溢出,导致混合精度训练(bf16)发散。SD3.0+在MM-DiT的注意力层前,对QQQ和KKK进行带可学习尺度的RMSNorm归一化,数学表达式为:
Q′=QRMS(Q),K′=KRMS(K)Q' = \frac{Q}{\operatorname{RMS}(Q)},\quad K' = \frac{K}{\operatorname{RMS}(K)}Q′=RMS(Q)Q,K′=RMS(K)K
RMS(x)=mean(x2)+ϵ,ϵ=10−15\operatorname{RMS}(x)=\sqrt{\operatorname{mean}(x^2)+\epsilon},\quad \epsilon=10^{-15}RMS(x)=mean(x2)+ϵ,ϵ=10−15
这种归一化方式,能有效控制注意力logits的数值范围,避免溢出问题,确保bf16混合精度训练的稳定性,同时不影响模型性能——相比全精度训练,算力消耗降低50%,训练效率大幅提升。
策略2:多宽高比位置编码,避免插值伪影
SDXL采用简单的插值方式调整位置编码,适配不同宽高比时,易出现伪影。SD3.0+设计了“扩展+插值+中心裁剪”的多宽高比位置编码,其垂直坐标的计算方式为:
垂直坐标: [(p−hmax−s2)⋅256S]p=0hmax−1\text{垂直坐标: } \left[ \left(p - \frac{h_{\max}-s}{2}\right) \cdot \frac{256}{S} \right]_{p=0}^{h_{\max}-1}垂直坐标: [(p−2hmax−s)⋅S256]p=0hmax−1
其中,hmaxh_{\max}hmax是最大潜在高度,sss是当前潜在高度,SSS是目标像素分辨率。这种设计能灵活适配任意宽高比(如16:9、4:3、21:9),彻底避免插值伪影,让不同宽高比的生成图像质量一致。
策略3:分辨率相关时间步偏移,匹配噪声调度与分辨率
对于恒定图像zt=(1−t)c1+tεz_t = (1-t)c\mathbf{1} + t\varepsilonzt=(1−t)c1+tε(ccc为恒定像素值,1\mathbf{1}1为全1向量),模型恢复原始图像的误差为σ(t,n)=t1−t1n\sigma(t,n)= \frac{t}{1-t}\sqrt{\frac{1}{n}}σ(t,n)=1−ttn1(nnn为图像像素数)。为了让不同分辨率下的恢复误差保持一致,SD3.0+提出了分辨率相关的时间步偏移公式:
tm=m/n⋅tn1+(m/n−1)tnt_m = \frac{\sqrt{m/n} \cdot t_n}{1 + (\sqrt{m/n} - 1)t_n}tm=1+(m/n−1)tnm/n⋅tn
其中,tnt_ntn是预训练分辨率n的时间步,tmt_mtm是目标分辨率m的时间步,α=m/n\alpha=\sqrt{m/n}α=m/n是分辨率比例系数。经过大规模实验验证,当α=3.0\alpha=3.0α=3.0时,1024×1024分辨率的生成质量最优,既能保证足够的噪声破坏信号,又能避免细节缺失。
4 训练策略与可扩展性:让性能提升可预测、可落地
SD3.0+能实现“更快更强”,不仅依赖底层技术与架构革新,更得益于标准化的规模化训练策略——解决了SDXL训练数据噪声大、验证损失与性能相关性弱的问题,让模型性能随规模与训练步数增长而稳定提升,且无饱和迹象,为大规模部署奠定了基础。
4.1 数据预处理三重过滤:从源头提升训练质量
在SDXL数据处理的基础上,SD3.0+增加了三层精细化筛选,从源头提升训练数据质量,减少噪声干扰,强化模型泛化能力:
- NSFW过滤:通过专业的NSFW检测模型,移除训练数据中的露骨内容,提升模型生成的安全性,适配商业部署需求;
- 美学筛选:通过美学评分模型,保留高质量、高审美价值的图像,让模型学习更优的视觉特征,提升生成图像的美学表现;
- 聚类去重:采用基于特征聚类的方法,移除感知和语义上的重复样本,避免模型过拟合,强化模型对新场景、新物体的泛化能力。
同时,SD3.0+对图像的潜在表示和文本特征进行预计算并固定,训练时直接调用预处理后的特征,大幅提升训练效率,支持批大小4096的大规模训练,缩短训练周期。
4.2 验证损失与性能强相关:性能提升可预测
SDXL的规模化训练中,验证损失与模型实际生成性能的相关性较弱,无法通过验证损失判断模型效果,导致训练过程盲目性强。而SD3.0+通过大规模缩放实验(模型规模从浅层到80亿参数,训练FLOPs达5×10225×10^{22}5×1022),证明了验证损失与模型性能的强相关性,并得出幂律缩放关系:
L∝N−0.15D−0.25\mathcal{L} \propto N^{-0.15} D^{-0.25}L∝N−0.15D−0.25
其中,NNN为模型参数量,DDD为训练数据量。实验显示,验证损失与人类偏好评分的相关系数高达0.92,这意味着,只要监控验证损失的变化,就能精准预测模型的实际生成性能,让训练过程更高效、更可控。
4.3 采样效率随规模提升:更大模型,更快峰值性能
SD3.0+的规模化实验还得出一个重要结论:模型规模越大,学习到的速度向量场越精准,ODE积分误差越小,达到峰值性能所需的采样步数越少。具体数据如下表所示:
| 模型规模 | 最佳采样步数 | FID@256×256 (越低越好) |
|---|---|---|
| 2.5B 参数 | 25 步 | 8.2 |
| 8.0B 参数 | 12 步 | 6.7 |
这一特性让SD3.0+的大模型版本,实现了“质量与速度的双重提升”——不仅生成图像的质量更优,采样效率也更高,进一步拉开了与SDXL的差距。
5 LDMs、SDXL、SD3.0+ 核心技术对比表
| 技术维度 | LDMs (Latent Diffusion Models) | SDXL (Stable Diffusion XL) | SD3.0+ (Rectified Flow Transformers) | 核心差异与提升 |
|---|---|---|---|---|
| 核心生成范式 | 传统扩散模型,弯曲前向路径 | 传统扩散模型,弯曲前向路径 | 整流流(Rectified Flow),直线前向路径 | 从弯曲路径到直线路径,采样效率质变 |
| 数学公式 | zt=αtx0+σtεz_t = \alpha_t x_0 + \sigma_t \varepsilonzt=αtx0+σtε 其中αt2+σt2=1\alpha_t^2 + \sigma_t^2 = 1αt2+σt2=1 |
同LDMs | zt=(1−t)x0+tε,t∈[0,1]z_t = (1-t)x_0 + t\varepsilon,\quad t\in[0,1]zt=(1−t)x0+tε,t∈[0,1] | 简化ODE路径,降低采样迭代需求 |
| 训练损失 | 噪声预测损失 Lnoise=E∣εθ(zt,t)−ε∣2L_{\text{noise}} = \mathbb{E}|\varepsilon_\theta(z_t,t)-\varepsilon|^2Lnoise=E∣εθ(zt,t)−ε∣2 |
同LDMs | 条件流匹配(CFM)损失 LCFM=E∣vθ(zt,t)−(ε−x0)∣2L_{\text{CFM}} = \mathbb{E}|v_\theta(z_t,t)-(\varepsilon-x_0)|^2LCFM=E∣vθ(zt,t)−(ε−x0)∣2 |
直接回归速度场,训练更高效 |
| 架构基础 | UNet (卷积+注意力) | 3倍大的UNet,双文本编码器 | MM-DiT (多模态Diffusion Transformer) | 从卷积主导到纯Transformer架构 |
| 文本-图像交互 | 单向交叉注意力 Attention(Qimg,Ktext,Vtext)\text{Attention}(Q_{\text{img}},K_{\text{text}},V_{\text{text}})Attention(Qimg,Ktext,Vtext) |
同LDMs,但使用双文本编码器 | 双流双向注意力 模态独立权重,注意力连接所有token |
从单向到双向,模态权重分离 |
| 多模态处理 | 权重共享 | 权重共享 | 模态独立权重 文本流和图像流参数独立 |
避免模态干扰,提升理解精度 |
| 采样效率 | 慢,50-100步 | 较快,20-30步 (基础+细化) | 极快,5-10步 | 少步采样性能大幅提升 |
| 时间步采样策略 | 均匀采样或余弦调度 | 均匀采样 | Logit-Normal采样 πln(t)=1s2πt(1−t)e−(logit(t)−m)22s2\pi_{\ln}(t)=\frac{1}{s\sqrt{2\pi}t(1-t)}e^{-\frac{(\text{logit}(t)-m)^2}{2s^2}}πln(t)=s2πt(1−t)1e−2s2(logit(t)−m)2 |
聚焦中间时间步,优化训练 |
| 潜在空间维度 | 低维,通道数较少 | 较高维,但仍有瓶颈 | 通道数扩展至d=16 x∈R(H/8)×(W/8)×16x \in \mathbb{R}^{(H/8)×(W/8)×16}x∈R(H/8)×(W/8)×16 |
重建质量提升,细节保留更好 |
| 文本编码器 | 单CLIP编码器 | 双编码器:CLIP-L + OpenCLIP-BigG | 三编码器可选:CLIP-L + CLIP-G + T5-XXL | 支持灵活配置,平衡性能与效率 |
| 高分辨率适配 | 困难,需特殊微调 | 两阶段训练,高分辨率不稳定 | 稳定高分辨率训练 QK归一化+分辨率偏移+多宽高比编码 |
1024×1024+生成稳定无伪影 |
| 训练稳定性 | 中等 | 高分辨率训练易发散 | 极高 QK归一化防止注意力溢出 |
支持bf16混合精度稳定训练 |
| 宽高比支持 | 固定方形或有限宽高比 | 有限宽高比支持 | 任意宽高比 动态位置编码 |
灵活支持16:9、4:3、21:9等 |
| 数据标注 | 原始标注 | 原始标注 | 50%原始+50%合成标注 使用CogVLM增强 |
提示词理解更精准 |
| 验证损失相关性 | 弱,不可靠 | 中等 | 强相关 L∝N−0.15D−0.25L \propto N^{-0.15}D^{-0.25}L∝N−0.15D−0.25 |
性能提升可预测 |
| 可扩展性 | 一般,易饱和 | 较好,但有瓶颈 | 优秀 80亿参数无饱和迹象 |
持续缩放潜力大 |
| 开源状态 | 完全开源 | 开源 | 承诺开源 | 推动开源生态发展 |
| 峰值性能采样步数 | 50-100步 | 20-30步 | 5-10步 | 推理速度提升3-10倍 |
| 文本渲染能力 | 差 | 中等 | 优秀 可生成可读文字 |
解决文字生成难题 |
| 复杂提示词理解 | 有限 | 较好 | 优秀 多物体、属性、空间关系准确 |
接近闭源模型水平 |
| 基准测试表现 | 基础水平 | 接近DALL-E 2 | 超越DALL-E 3 多个基准领先 |
开源模型首次全面领先 |
LDMs → SDXL → SD3.0+ 代表了文生图技术的三次重大演进:
- LDMs:奠定了潜在空间生成的基础范式
- SDXL:通过规模扩展和架构优化提升了生成质量
- SD3.0+:通过范式革新(整流流)+架构创新(MM-DiT)+系统优化实现了全面的性能突破
二、论文翻译:Scaling Rectified Flow Transformers for High-Resolution Image Synthesis(缩放整流流变换器用于高分辨率图像合成)
0 摘要

扩散模型通过逆转从数据到噪声的前向路径,实现从噪声中创建数据的能力,并已成为一种强大的生成建模技术,适用于图像和视频等高维感知数据。整流流是一种近期的生成模型公式,它通过直线连接数据和噪声。尽管其具有更优的理论性质和概念简洁性,但它尚未被决定性地确立为标准实践。
在本工作中,我们通过使噪声采样技术偏向于感知相关尺度,改进了用于训练整流流模型的现有噪声采样技术。通过一项大规模研究,我们证明了在高分辨率文本到图像合成任务中,该方法的性能优于已建立的扩散公式。此外,我们提出了一种基于变换器的新型架构用于文本到图像生成,该架构为两种模态使用独立的权重,并实现了图像和文本令牌之间的双向信息流,从而改善了文本理解、排版效果和人类偏好评分。
我们证明该架构遵循可预测的缩放趋势,并且更低的验证损失与通过各种指标和人类评估衡量的、改进的文本到图像合成性能强相关。我们最大的模型性能优于最先进的模型,并且我们将公开提供我们的实验数据、代码和模型权重。
1. 引言
扩散模型从噪声中创造数据 [Song et al., 2020]。它们被训练来逆转从数据到随机噪声的前向路径,因此,结合神经网络的近似和泛化特性,可用于生成训练数据中不存在但遵循训练数据分布的新数据点 [Sohl-Dickstein et al., 2015; Song & Ermon, 2020]。这种生成建模技术已被证明对图像 [Ho et al., 2020] 等高维感知数据建模非常有效。近年来,扩散模型已成为从自然语言输入生成高分辨率图像和视频的事实上的方法,具有令人印象深刻的泛化能力 [Saharia et al., 2022b; Ramesh et al., 2022; Rombach et al., 2022; Podell et al., 2023; Dai et al., 2023; Esser et al., 2023; Blattmann et al., 2023b; Betker et al., 2023; Blattmann et al., 2023a; Singer et al., 2022]。由于其迭代性质和相关计算成本,以及推理过程中较长的采样时间,关于这些模型更高效训练和/或更快采样的公式研究有所增加 [Karras et al., 2023; Liu et al., 2022]。
虽然指定从数据到噪声的前向路径可以实现高效训练,但也引发了选择哪条路径的问题。这一选择可能对采样产生重要影响。例如,一个未能从数据中去除所有噪声的前向过程可能导致训练和测试分布之间的差异,并产生伪影,例如灰度图像样本 [Lin et al., 2024]。重要的是,前向过程的选择也会影响学习到的反向过程,从而影响采样效率。虽然弯曲路径需要许多积分步骤来模拟过程,但直线路径可以通过单个步骤模拟,并且不易出现误差累积。由于每个步骤对应于神经网络的一次评估,这直接影响采样速度。
前向路径的一个特定选择是所谓的整流流 [Liu et al., 2022; Albergo & Vanden-Eijnden, 2022; Lipman et al., 2023],它通过直线连接数据和噪声。尽管此类模型具有更好的理论特性,但尚未在实践中决定性确立。到目前为止,一些优势已在中小型实验中得到实证证明 [Ma et al., 2024],但这些主要局限于类条件模型。在这项工作中,我们通过引入整流流模型中噪声尺度的重新加权来改变这一现状,类似于噪声预测扩散模型 [Ho et al., 2020]。通过一项大规模研究,我们将我们的新公式与现有的扩散公式进行比较,并证明其优势。
我们表明,广泛使用的文本到图像合成方法,即将固定文本表示直接输入模型(例如,通过交叉注意力 [Vaswani et al., 2017; Rombach et al., 2022]),并不理想,并提出了一种新架构,该架构为图像和文本令牌引入了可学习流,使得它们之间能够实现双向信息流。我们将其与我们改进的整流流公式相结合,并研究其可扩展性。我们证明了验证损失存在可预测的缩放趋势,并表明较低的验证损失与通过自动和人类评估衡量的改进的文本到图像合成性能强相关。
我们最大的模型在定量评估 [Ghosh et al., 2023] 提示理解和人类偏好评分方面均优于最先进的开放模型,如 SDXL [Podell et al., 2023]、SDXL-Turbo [Sauer et al., 2023]、Pixart-α [Chen et al., 2023] 以及闭源模型,如 DALL-E 3 [Betker et al., 2023]。
我们工作的核心贡献是:
(i) 我们对不同的扩散模型和整流流公式进行了大规模、系统性的研究,以确定最佳设置。为此,我们为整流流模型引入了新的噪声采样器,其性能优于先前已知的采样器。
(ii) 我们设计了一种新颖、可扩展的文本到图像合成架构,允许在网络内实现文本和图像令牌流之间的双向混合。我们展示了其相对于已确立的主干网络(如 UViT [Hoogeboom et al., 2023] 和 DiT [Peebles & Xie, 2023])的优势。
最后,
(iii) 对我们的模型进行了缩放研究,并证明其遵循可预测的缩放趋势。我们研究表明,较低的验证损失与通过 T2I-CompBench [Huang et al., 2023]、GenEval [Ghosh et al., 2023] 等指标和人类评分评估的改进的文本到图像性能强相关。我们将公开提供结果、代码和模型权重。
2 流的无模拟训练
我们考虑定义从噪声分布 p1p_{1}p1 的样本 x1x_{1}x1 到数据分布 p0p_{0}p0 的样本 x0x_{0}x0 之间映射的生成模型,该映射由常微分方程(ODE)表示:
dyt=vΘ(yt,t) dt,(1) dy_{t} = v_{\Theta}(y_{t}, t) \, dt, \qquad (1) dyt=vΘ(yt,t)dt,(1)
其中速度 vvv 由神经网络的权重 Θ\ThetaΘ 参数化。Chen 等人 (2018) 的先前工作建议通过可微分的 ODE 求解器直接求解方程 (1)。然而,这个过程计算成本高昂,特别是对于参数化 vΘ(yt,t)v_{\Theta}(y_{t}, t)vΘ(yt,t) 的大型网络架构。一种更有效的替代方法是直接回归一个在 p0p_{0}p0 和 p1p_{1}p1 之间生成概率路径的向量场 utu_{t}ut。为了构建这样的 utu_{t}ut,我们定义一个前向过程,对应于 p0p_{0}p0 和 p1=N(0,1)p_{1}=\mathcal{N}(0,1)p1=N(0,1) 之间的概率路径 ptp_{t}pt,如下所示:
zt=atx0+btϵ其中ϵ∼N(0,I).(2) z_{t} = a_{t}x_{0} + b_{t}\epsilon \quad \text{其中} \quad \epsilon \sim \mathcal{N}(0,I). \qquad (2) zt=atx0+btϵ其中ϵ∼N(0,I).(2)
当 a0=1,b0=0,a1=0a_{0}=1, b_{0}=0, a_{1}=0a0=1,b0=0,a1=0 且 b1=1b_{1}=1b1=1 时,边缘分布,
pt(zt)=Eϵ∼N(0,I) pt(zt∣ϵ),(3) p_{t}(z_{t}) = \mathbb{E}_{\epsilon \sim \mathcal{N}(0,I)} \, p_{t}(z_{t} \mid \epsilon), \qquad (3) pt(zt)=Eϵ∼N(0,I)pt(zt∣ϵ),(3)
与数据和噪声分布一致。
为了表达 ztz_{t}zt、x0x_{0}x0 和 ϵ\epsilonϵ 之间的关系,我们引入 ψt\psi_{t}ψt 和 utu_{t}ut 如下:
ψt(⋅∣ϵ):x0↦atx0+btϵ(4) \psi_{t}(\cdot \mid \epsilon): x_{0} \mapsto a_{t}x_{0} + b_{t}\epsilon \qquad (4) ψt(⋅∣ϵ):x0↦atx0+btϵ(4)
ut(z∣ϵ):=ψt′(ψt−1(z∣ϵ)∣ϵ)(5) u_{t}(z \mid \epsilon) := \psi_{t}'(\psi_{t}^{-1}(z \mid \epsilon) \mid \epsilon) \qquad (5) ut(z∣ϵ):=ψt′(ψt−1(z∣ϵ)∣ϵ)(5)
由于 ztz_{t}zt 可以写成 ODE zt′=ut(zt∣ϵ)z_{t}' = u_{t}(z_{t} \mid \epsilon)zt′=ut(zt∣ϵ) 的解,其初始值为 z0=x0z_{0} = x_{0}z0=x0,因此 ut(⋅∣ϵ)u_{t}(\cdot \mid \epsilon)ut(⋅∣ϵ) 生成了 pt(⋅∣ϵ)p_{t}(\cdot \mid \epsilon)pt(⋅∣ϵ)。值得注意的是,我们可以构建一个边缘向量场 utu_{t}ut,生成边缘概率路径 ptp_{t}pt(Lipman 等人,2023)(见 B.1),使用条件向量场 ut(⋅∣ϵ)u_{t}(\cdot \mid \epsilon)ut(⋅∣ϵ):
ut(z)=Eϵ∼N(0,I) ut(z∣ϵ)pt(z∣ϵ)pt(z)(6) u_{t}(z) = \mathbb{E}_{\epsilon \sim \mathcal{N}(0,I)} \, u_{t}(z \mid \epsilon) \frac{p_{t}(z \mid \epsilon)}{p_{t}(z)} \qquad (6) ut(z)=Eϵ∼N(0,I)ut(z∣ϵ)pt(z)pt(z∣ϵ)(6)
虽然使用流匹配目标直接回归 utu_{t}ut
LFM=Et,pt(z)∥vΘ(z,t)−ut(z)∥22(7) \mathcal{L}_{FM} = \mathbb{E}_{t, p_{t}(z)} \| v_{\Theta}(z,t) - u_{t}(z) \|_{2}^{2} \qquad (7) LFM=Et,pt(z)∥vΘ(z,t)−ut(z)∥22(7)
由于公式 (6) 中的边缘化而难以处理,但条件流匹配(见 B.1),
LCFM=Et,pt(z∣ϵ),p(ϵ)∥vΘ(z,t)−ut(z∣ϵ)∥22,(8) \mathcal{L}_{CFM} = \mathbb{E}_{t, p_{t}(z \mid \epsilon), p(\epsilon)} \| v_{\Theta}(z,t) - u_{t}(z \mid \epsilon) \|_{2}^{2}, \qquad (8) LCFM=Et,pt(z∣ϵ),p(ϵ)∥vΘ(z,t)−ut(z∣ϵ)∥22,(8)
与条件向量场 ut(z∣ϵ)u_{t}(z \mid \epsilon)ut(z∣ϵ) 一起提供了一个等价但易于处理的目标。
为了将损失转化为显式形式,我们将 ψt′(x0∣ϵ)=at′x0+bt′ϵ\psi_{t}'(x_{0} \mid \epsilon) = a_{t}' x_{0} + b_{t}'\epsilonψt′(x0∣ϵ)=at′x0+bt′ϵ 和 ψt−1(z∣ϵ)=z−btϵat\psi_{t}^{-1}(z \mid \epsilon) = \frac{z - b_{t}\epsilon}{a_{t}}ψt−1(z∣ϵ)=atz−btϵ 代入 (5):
zt′=ut(zt∣ϵ)=at′atzt−ϵbt(at′at−bt′bt).(9) \begin{align*} z_{t}' = u_{t}(z_{t} \mid \epsilon) = \frac{a_{t}'}{a_{t}} z_{t} - \epsilon b_{t} \left( \frac{a_{t}'}{a_{t}} - \frac{b_{t}'}{b_{t}} \right). \end{align*} \qquad (9) zt′=ut(zt∣ϵ)=atat′zt−ϵbt(atat′−btbt′).(9)
现在,考虑信噪比 λt:=logat2bt2\lambda_{t} := \log \frac{a_{t}^{2}}{b_{t}^{2}}λt:=logbt2at2。由于 λt′=2(at′at−bt′bt)\lambda_{t}' = 2 \left( \frac{a_{t}'}{a_{t}} - \frac{b_{t}'}{b_{t}} \right)λt′=2(atat′−btbt′),我们可以将方程 (9) 重写为:
ut(zt∣ϵ)=at′atzt−bt2λt′ϵ(10) \begin{align*} u_{t}(z_{t} \mid \epsilon) = \frac{a_{t}'}{a_{t}} z_{t} - \frac{b_{t}}{2} \lambda_{t}' \epsilon \end{align*} \qquad (10) ut(zt∣ϵ)=atat′zt−2btλt′ϵ(10)
接下来,我们使用方程 (10) 将方程 (8) 重新参数化为噪声预测目标:
LCFM=Et,pt(z∣ϵ),p(ϵ)∥vΘ(z,t)−at′atz+bt2λt′ϵ∥22(11) \begin{align*} \mathcal{L}_{CFM} = \mathbb{E}_{t, p_{t}(z \mid \epsilon), p(\epsilon)} \left\| v_{\Theta}(z,t) - \frac{a_{t}'}{a_{t}} z + \frac{b_{t}}{2} \lambda_{t}' \epsilon \right\|_{2}^{2} \end{align*} \qquad (11) LCFM=Et,pt(z∣ϵ),p(ϵ)
vΘ(z,t)−atat′z+2btλt′ϵ
22(11)
=Et,pt(z∣ϵ),p(ϵ)(−bt2λt′)2∥ϵΘ(z,t)−ϵ∥22(12) = \mathbb{E}_{t, p_{t}(z \mid \epsilon), p(\epsilon)} \left( -\frac{b_{t}}{2} \lambda_{t}' \right)^{2} \| \epsilon_{\Theta}(z, t) - \epsilon \|_{2}^{2} \qquad (12) =Et,pt(z∣ϵ),p(ϵ)(−2btλt′)2∥ϵΘ(z,t)−ϵ∥22(12)
其中我们定义了 ϵΘ:=−2λt′bt(vΘ−at′atz)\epsilon_{\Theta} := \frac{-2}{\lambda_{t}' b_{t}} (v_{\Theta} - \frac{a_{t}'}{a_{t}} z)ϵΘ:=λt′bt−2(vΘ−atat′z)。
请注意,当引入时间相关的加权时,上述目标的最优解不会改变。因此,可以推导出各种加权损失函数,这些函数为期望解提供信号,但可能会影响优化轨迹。为了统一分析不同方法(包括经典扩散公式),我们可以将目标写成以下形式(遵循 Kingma & Gao (2023)):
Lw(x0)=−12Et∼U(t),ϵ∼N(0,I)[wtλt′∥ϵΘ(zt,t)−ϵ∥2] \mathcal{L}_{w}(x_{0}) = -\frac{1}{2} \mathbb{E}_{t \sim \mathcal{U}(t), \epsilon \sim \mathcal{N}(0,I)} \left[ w_{t} \lambda_{t}' \| \epsilon_{\Theta}(z_{t}, t) - \epsilon \|^{2} \right] Lw(x0)=−21Et∼U(t),ϵ∼N(0,I)[wtλt′∥ϵΘ(zt,t)−ϵ∥2]
其中 wt=−12λt′bt2w_{t} = -\frac{1}{2} \lambda_{t}' b_{t}^{2}wt=−21λt′bt2 对应于 LCFM\mathcal{L}_{CFM}LCFM。
3 流轨迹
在本工作中,我们考虑了上述形式体系的不同变体,以下将对其进行简要描述。
整流流 整流流 [Liu et al., 2022; Albergo & Vanden-Eijnden, 2022; Lipman et al., 2023] 将前向过程定义为数据分布与标准正态分布之间的直线路径,即:
zt=(1−t)x0+tϵ,(13) z_t = (1 - t)x_0 + t\epsilon, \qquad (13) zt=(1−t)x0+tϵ,(13)
并使用 LCFM\mathcal{L}_{CFM}LCFM,其对应的权重为 wtRF=t1−tw_t^{RF} = \frac{t}{1-t}wtRF=1−tt。网络输出直接参数化速度 vΘv_{\Theta}vΘ。
EDM EDM [Karras et al., 2022] 使用形式为
zt=x0+btϵ(14) z_t = x_0 + b_t \epsilon \qquad (14) zt=x0+btϵ(14)
的前向过程,其中 [Kingma & Gao, 2023] bt=exp(FN−1(t∣Pm,Ps2))b_t = \exp(F_{\mathcal{N}}^{-1}(t \mid P_m, P_s^2))bt=exp(FN−1(t∣Pm,Ps2)),FN−1F_{\mathcal{N}}^{-1}FN−1 是均值为 PmP_mPm、方差为 Ps2P_s^2Ps2 的正态分布的分位数函数。请注意,这种选择导致
λt∼N(−2Pm,(2Ps)2)当t∼U(0,1)时。(15) \lambda_t \sim \mathcal{N}(-2P_m, (2P_s)^2) \quad \text{当} \quad t \sim \mathcal{U}(0,1) 时。\qquad (15) λt∼N(−2Pm,(2Ps)2)当t∼U(0,1)时。(15)
网络通过 F-prediction [Kingma & Gao, 2023; Karras et al., 2022] 进行参数化,损失可以写成 LwtEDM\mathcal{L}_{w_t^{\text{EDM}}}LwtEDM,其中
wtEDM=N(λt∣−2Pm,(2Ps)2)(e−λt+0.52)。(16) w_t^{EDM} = \mathcal{N}(\lambda_t \mid -2P_m, (2P_s)^2)(e^{-\lambda_t} + 0.5^2)。\qquad (16) wtEDM=N(λt∣−2Pm,(2Ps)2)(e−λt+0.52)。(16)
Cosine [Nichol & Dhariwal, 2021] 提出了形式为
zt=cos(π2t)x0+sin(π2t)ϵ。(17) z_t = \cos\left(\frac{\pi}{2}t\right) x_0 + \sin\left(\frac{\pi}{2}t\right) \epsilon。\qquad (17) zt=cos(2πt)x0+sin(2πt)ϵ。(17)
的前向过程。结合 ϵ\epsilonϵ-参数化和损失,这对应于权重 wt=sech(λt/2)w_t = \operatorname{sech}(\lambda_t / 2)wt=sech(λt/2)。当与 v-prediction 损失 [Kingma & Gao, 2023] 结合时,权重由 wt=e−λt/2w_t = e^{-\lambda_t / 2}wt=e−λt/2 给出。
(LDM-)Linear LDM [Rombach et al., 2022] 使用了 DDPM 调度 [Ho et al., 2020] 的修改版本。两者都是方差保持调度,即 bt=1−at2b_t = \sqrt{1 - a_t^2}bt=1−at2,并根据扩散系数 βt\beta_tβt 为离散时间步 t=0,…,T−1t = 0, \ldots, T-1t=0,…,T−1 定义 ata_tat 为 at=(∏s=0t(1−βs))12a_t = \left( \prod_{s=0}^{t} (1 - \beta_s) \right)^{\frac{1}{2}}at=(∏s=0t(1−βs))21。对于给定的边界值 β0\beta_0β0 和 βT−1\beta_{T-1}βT−1,DDPM 使用 βt=β0+tT−1(βT−1−β0)\beta_t = \beta_0 + \frac{t}{T-1}(\beta_{T-1} - \beta_0)βt=β0+T−1t(βT−1−β0),而 LDM 使用 βt=(β0+tT−1(βT−1−β0))2\beta_t = \left( \sqrt{\beta_0} + \frac{t}{T-1}(\sqrt{\beta_{T-1}} - \sqrt{\beta_0}) \right)^2βt=(β0+T−1t(βT−1−β0))2。
3.1 针对 RF 模型的定制化 SNR 采样器
RF 损失函数在 [0,1][0,1][0,1] 区间内的所有时间步上以均匀分布的方式对速度 vΘv_{\Theta}vΘ 进行训练。然而,直观上看,所得到的速度预测目标 ϵ−x0\epsilon - x_0ϵ−x0 对于 ttt 落在区间 [0,1][0,1][0,1] 中部的情况而言,学习难度更大。这是因为当 t=0t=0t=0 时,最优预测是 p1p_1p1 分布的均值;而当 t=1t=1t=1 时,最优预测是 p0p_0p0 分布的均值。
一般来说,将时间 ttt 的采样分布从常用的均匀分布 U(t)\mathcal{U}(t)U(t) 更改为具有密度函数 π(t)\pi(t)π(t) 的分布,等价于使用以下加权的损失函数 Lwtπ\mathcal{L}_{w_{t}^{\pi}}Lwtπ:
wtπ=t1−tπ(t)(18) w_t^\pi=\frac{t}{1-t}\pi(t) \qquad (18) wtπ=1−ttπ(t)(18)
因此,我们的目标是通过更频繁地对中间时间步进行采样,从而给予它们更大的权重。接下来,我们将描述用于训练模型的几种时间步密度分布 π(t)\pi(t)π(t)。
Logit-Normal 采样
一种能够对中间时间步赋予更大权重的分布选项是 logit-normal 分布 [Atchison & Shen, 1980]。其密度函数为:
πln(t;m,s)=1s2π1t(1−t)exp(−(logit(t)−m)22s2) \pi_{\ln}(t; m, s)=\frac{1}{s\sqrt{2\pi}}\frac{1}{t(1-t)}\exp\left(-\frac{(\operatorname{logit}(t)-m)^{2}}{2 s^{2}}\right) πln(t;m,s)=s2π1t(1−t)1exp(−2s2(logit(t)−m)2)
其中 logit(t)=logt1−t\operatorname{logit}(t)=\log\frac{t}{1-t}logit(t)=log1−tt。该分布具有位置参数 mmm 和尺度参数 sss。位置参数使我们能够将训练时间步偏向于数据分布 p0p_0p0(当 mmm 为负时)或噪声分布 p1p_1p1(当 mmm 为正时)。尺度参数 sss 控制分布的宽窄程度。
在实际操作中,我们从正态分布 u∼N(u;m,s)u\sim\mathcal{N}(u; m, s)u∼N(u;m,s) 中采样随机变量 uuu,然后通过标准的 logistic 函数 t=11+e−ut = \frac{1}{1+e^{-u}}t=1+e−u1 将其映射为时间 ttt。
具有重尾的众数采样
Logit-normal 密度在端点 0 和 1 处的值始终为零。为了研究这是否会对性能产生不利影响,我们也使用了一个在 [0,1][0,1][0,1] 区间上密度严格为正的时间步采样分布。对于尺度参数 sss,我们定义:
fmode(u;s)=1−u−s⋅(cos2(π2u)−1+u).(20) f_{\text{mode}}(u; s)=1-u-s\cdot\left(\cos^{2}\left(\frac{\pi}{2} u\right)-1+u\right). \quad (20) fmode(u;s)=1−u−s⋅(cos2(2πu)−1+u).(20)
当 −1≤s≤2π−2-1 \leq s \leq \frac{2}{\pi-2}−1≤s≤π−22 时,该函数是单调的。我们可以用它从隐含的密度 πmode(t;s)=∣ddtfmode−1(t)∣\pi_{\text{mode}}(t;s)= |\frac{d}{dt}f_{\text{mode}}^{-1}(t)|πmode(t;s)=∣dtdfmode−1(t)∣ 中进行采样。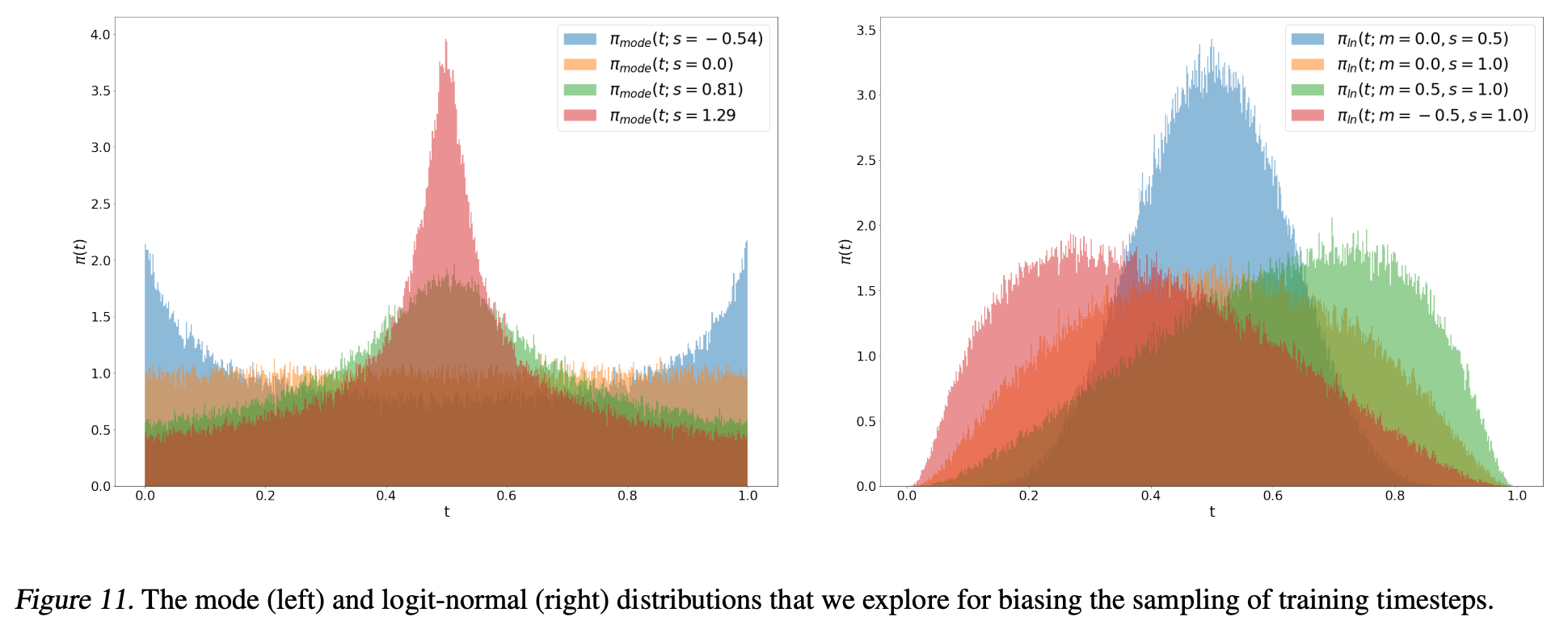
如图 11 所示,尺度参数 sss 控制着在采样过程中是更偏向于中点(sss 为正时)还是端点(sss 为负时)。该公式也包含了均匀加权的情况,即当 s=0s=0s=0 时,πmode(t;s=0)=U(t)\pi_{\text{mode}}(t; s=0)=\mathcal{U}(t)πmode(t;s=0)=U(t),该加权方式在之前的整流流研究工作中被广泛使用 [Liu et al., 2022; Ma et al., 2024]。
CosMap
最后,我们也在 RF 框架下考虑了第 3 节中提到的余弦调度 [Nichol & Dhariwal, 2021]。具体来说,我们寻找一个映射 f:u↦f(u)=tf: u \mapsto f(u) = tf:u↦f(u)=t,其中 u∈[0,1]u \in [0,1]u∈[0,1],使得对应的对数信噪比(log-SNR)与余弦调度的对数信噪比相匹配:2logcos(π2u)sin(π2u)=2log1−f(u)f(u)2\log\frac{\cos(\frac{\pi}{2} u)}{\sin(\frac{\pi}{2} u)} = 2\log\frac{1-f(u)}{f(u)}2logsin(2πu)cos(2πu)=2logf(u)1−f(u)。通过求解 f(u)f(u)f(u),我们得到对于 u∼U(u)u \sim \mathcal{U}(u)u∼U(u),有:
t=f(u)=1−1tan(π2u)+1,(21) t=f(u)=1-\frac{1}{\tan(\frac{\pi}{2} u)+1}, \qquad (21) t=f(u)=1−tan(2πu)+11,(21)
由此我们得到其密度函数为:
πCosMap(t)=∣ddtf−1(t)∣=2π−2πt+2πt2.(22) \pi_{\text{CosMap}}(t)=\left| \frac{d}{d t} f^{-1}(t) \right| = \frac{2}{\pi-2\pi t+2\pi t^2}. \qquad (22) πCosMap(t)=
dtdf−1(t)
=π−2πt+2πt22.(22)
4. 文本到图像架构
对于文本条件的图像生成,我们的模型必须同时考虑文本和图像这两种模态。我们使用预训练模型来获得合适的表示,然后描述我们的扩散主干架构。图2展示了其概述。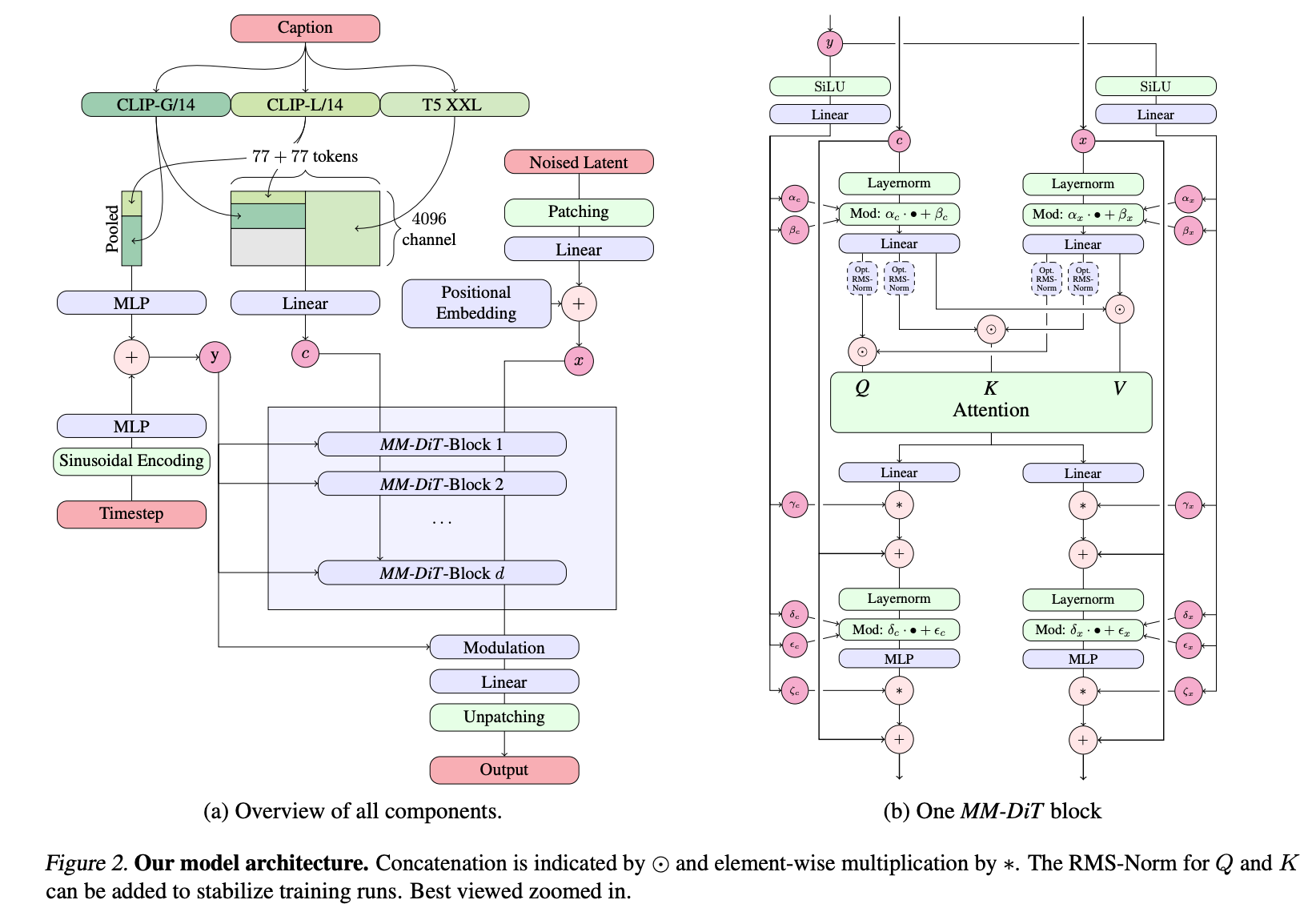
我们的通用设置遵循LDM[Rombach et al., 2022],在预训练自编码器的潜在空间中训练文本到图像模型。与将图像编码为潜在表示类似,我们也遵循先前的方法[Saharia et al., 2022b; Balaji et al., 2022],使用预训练的、冻结的文本模型对文本条件 ccc 进行编码。详细信息见附录B.2。
多模态扩散主干 我们的架构基于DiT[Peebles & Xie, 2023]架构。DiT仅考虑类条件图像生成,并使用调制机制将扩散过程的时间步 ttt 和类别标签作为条件输入网络。类似地,我们使用时间步 ttt 和 cvecc_{\text{vec}}cvec 的嵌入作为调制机制的输入。然而,由于汇集后的文本表示仅保留文本输入的粗粒度信息[Podell et al., 2023],网络还需要来自序列表示 cctxtc_{\text{ctxt}}cctxt 的信息。
我们构建一个由文本和图像输入的嵌入组成的序列。具体来说,我们添加位置编码,并将潜在像素表示 x∈Rh×w×cx \in \mathbb{R}^{h \times w \times c}x∈Rh×w×c 的 2×22 \times 22×2 图像块展平为长度为 12⋅h⋅12⋅w\frac{1}{2} \cdot h \cdot \frac{1}{2} \cdot w21⋅h⋅21⋅w 的图像块编码序列。在将图像块编码和文本编码 cctxtc_{\text{ctxt}}cctxt 嵌入到一个共同的维度后,我们将这两个序列连接起来。然后我们遵循DiT,应用一系列调制注意力层和MLP。
由于文本和图像嵌入在概念上差异很大,我们对这两种模态使用两组独立的权重。如图2b所示,这等价于为每种模态使用两个独立的变换器,但在注意力操作中将两种模态的序列连接起来,使得两种表示可以在各自的空间中工作,同时又能考虑到另一种模态的信息。
对于我们的缩放实验,我们根据模型的深度 ddd(即注意力块的数量)来参数化模型的大小,将隐藏层大小设置为 64⋅d64 \cdot d64⋅d(在MLP块中扩展到 4⋅64⋅d4 \cdot 64 \cdot d4⋅64⋅d 个通道),并将注意力头数设置为等于 ddd。
5. 实验
5.1 改进整流流
我们旨在理解第2章方程(1)中所述的标准化流的无模拟训练方法中,哪种方法最有效。为了在不同方法之间进行公平比较,我们控制了优化算法、模型架构、数据集和采样器。此外,不同方法的损失函数不仅难以直接比较,而且其数值未必与输出样本的质量相关。因此,我们需要能够对不同方法进行比较的评估指标。我们在 ImageNet [Russakovsky et al., 2014] 和 CC12M [Changpinyo et al., 2021] 上训练模型,并在训练过程中使用验证损失、CLIP 分数 [Radford et al., 2021; Hessel et al., 2021] 和在不同采样器设置(不同引导尺度 and 采样步数)下计算的 FID [Heusel et al., 2017] 来评估模型及其 EMA 权重。我们按照 [Sauer et al., 2021] 提出的方法,基于 CLIP 特征计算 FID。所有指标均在 COCO-2014 验证集 [Lin et al., 2014] 上进行评估。训练和采样的完整超参数细节见附录 B.3。
5.1.1 结果
我们在两个数据集上分别训练了 61 种不同配置的模型。我们包含了第 3 章中所述的以下变体:
- 具有线性(eps/linear,v/linear)(eps/linear, v/linear)(eps/linear,v/linear)和余弦(eps/cos,v/cos)(eps/cos, v/cos)(eps/cos,v/cos)调度机制的 ϵ\epsilonϵ-预测 和 vvv-预测 损失。
- 使用 πmode(t;s)\pi_{\text{mode}}(t; s)πmode(t;s) 的 RF 损失(rf/mode(s))(rf/mode(s))(rf/mode(s)),其中 sss 在 -1 到 1.75 之间均匀选择了 7 个值,另外还包括 s=1.0s=1.0s=1.0 和 s=0s=0s=0(对应均匀时间步采样,即 rf/mode)的情况。
- 使用 πln(t;m,s)\pi_{\ln}(t; m, s)πln(t;m,s) 的 RF 损失(rf/lognorm(m,s))(rf/lognorm(m, s))(rf/lognorm(m,s)),其中 (m,s)(m, s)(m,s) 在 mmm 介于 -1 和 1 之间、sss 介于 0.2 和 2.2 之间的网格中选择了 30 个值。
- 使用 πCosMap(t)\pi_{\text{CosMap}}(t)πCosMap(t) 的 RF 损失(rf/cosmap)(rf/cosmap)(rf/cosmap)。
- EDM (edm (Pm,Ps)(P_m, P_s)(Pm,Ps)),其中 PmP_mPm 在 −1.2-1.2−1.2 到 1.21.21.2 之间均匀选择了 15 个值,PsP_sPs 在 0.6 到 1.8 之间均匀选择。注意 Pm,Ps=(−1.2,1.2)P_m, P_s = (-1.2, 1.2)Pm,Ps=(−1.2,1.2) 对应于 [Karras et al., 2022] 中的参数。
- 使用调度机制使其对数信噪比(log−SNR)(log-SNR)(log−SNR)权重与rfrfrf匹配的 EDM(edm/rf)(edm/rf)(edm/rf),以及与 v/cosv/cosv/cos 匹配的 EDM(edm/cos)(edm/cos)(edm/cos)。
对于每次运行,我们选择在使用 EMA 权重评估时验证损失最小的训练步数,然后收集在 6 种不同采样器设置(使用和不使用 EMA 权重)下获得的 CLIP 分数和 FID。
对于所有 24 种采样器设置、EMA 权重和数据集选择的组合,我们使用非支配排序算法对不同的配置进行排名。具体来说,我们反复计算在 CLIP 和 FID 指标上帕累托最优的变体,为这些变体分配当前迭代的排名,然后移除这些变体,并对剩余的变体继续此过程,直到所有变体都获得排名。最后,我们将这些排名在 24 种不同的控制设置下取平均。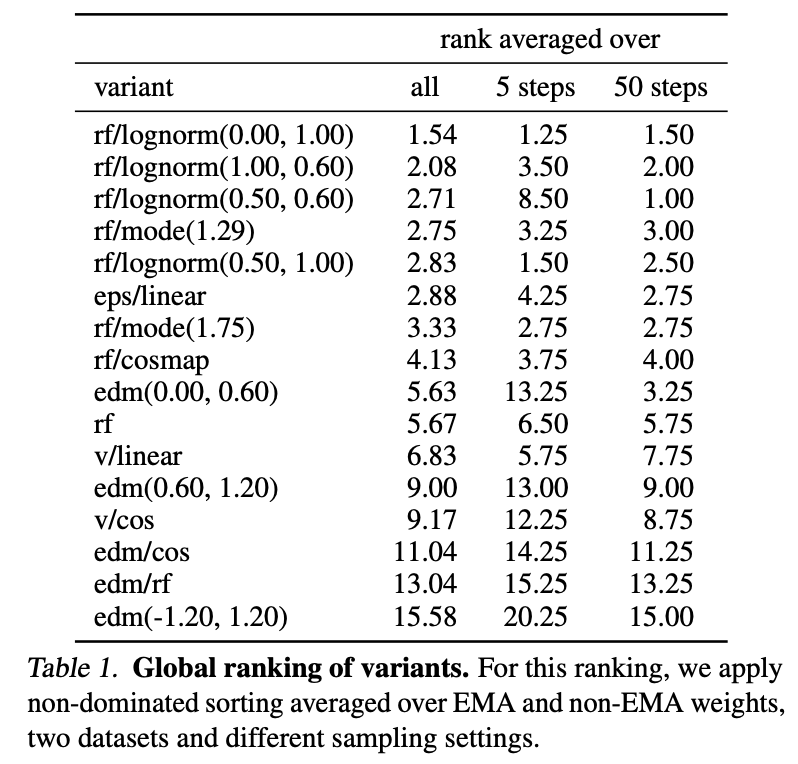
我们在表 1 中展示了结果,其中对于具有不同超参数的变体,我们只展示了表现最好的两个。我们还展示了在将平均范围限制在 5 步和 50 步采样器设置时的排名。
我们观察到,rf/lognorm(0.00,1.00)consistentlyrf/lognorm(0.00, 1.00) consistentlyrf/lognorm(0.00,1.00)consistently取得了良好的排名。它的表现优于采用均匀时间步采样的整流流配置(rf)(rf)(rf),这证实了我们的假设,即中间时间步更为重要。在所有变体中,只有修改了时间步采样的整流流配置的表现优于先前使用的 LDM-Linear [Rombach et al., 2022] 配置(eps/linear)(eps/linear)(eps/linear)。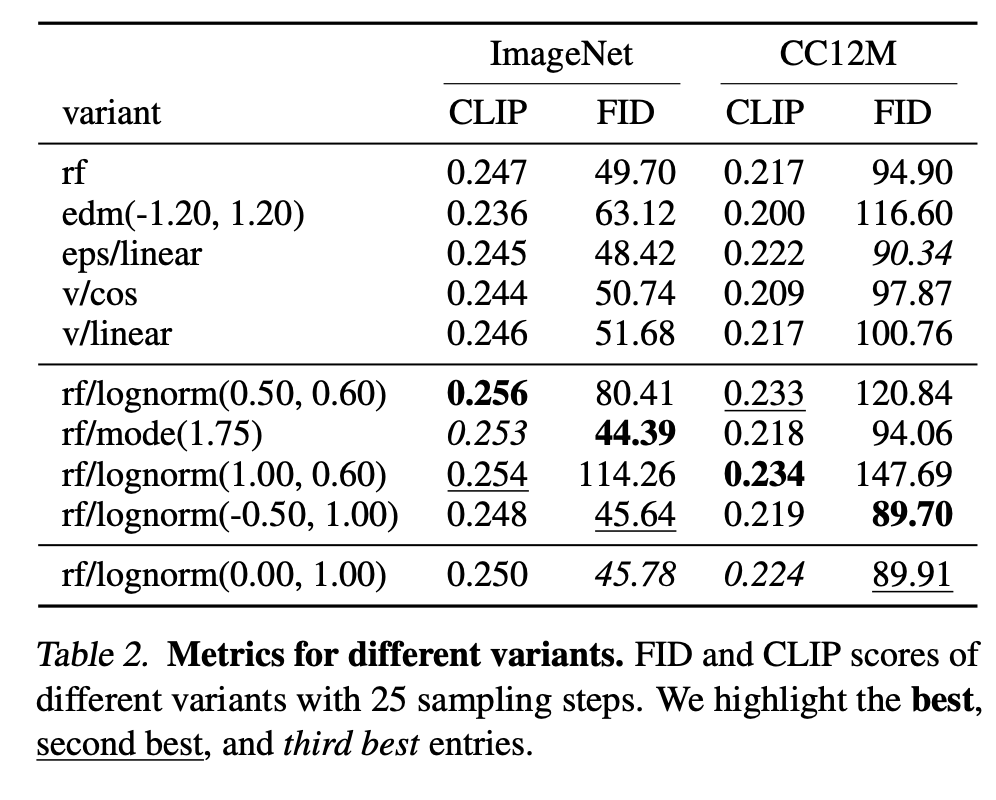
我们还观察到,某些变体在某些设置下表现良好,但在其他设置下表现较差,例如rf/lognorm(0.50,0.60)rf/lognorm(0.50, 0.60)rf/lognorm(0.50,0.60) 在 50 个采样步数时是表现最佳的变体,但在 5 个采样步数时表现要差得多(平均排名 8.5)。我们在表 2 的两个指标上也观察到了类似的行为。第一组展示了具有代表性的变体及其在 25 个采样步数下在两个数据集上的指标。下一组展示了达到最佳 CLIP 和 FID 分数的变体。除了 rf/mode(1.75)rf/mode(1.75)rf/mode(1.75) 之外,这些变体通常在其中一个指标上表现非常好,但在另一个指标上相对较差。相比之下,我们再次观察到 rf/lognorm(0.00,1.00)rf/lognorm(0.00, 1.00)rf/lognorm(0.00,1.00) 在指标和数据集上均取得了良好的性能,在四个评估项中两次获得第三佳分数,一次获得第二佳性能。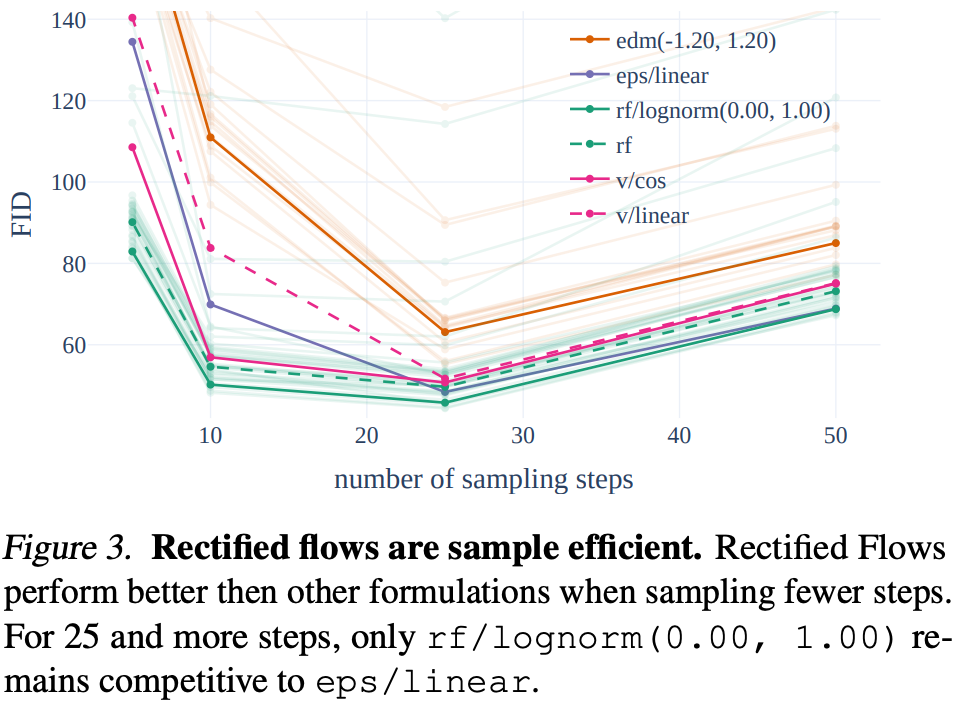
最后,我们在图 3 中展示了不同配置的定性行为,其中我们为不同组的配置(edm,rf,eps和v)(edm, rf, eps 和 v)(edm,rf,eps和v)使用了不同的颜色。整流流配置通常表现良好,并且与其他配置相比,当减少采样步数时,其性能下降较少。
5.2 改进模态特定表示
在第5.1节中,我们找到了一种训练方法,使得整流流模型不仅能够与成熟的扩散公式(如LDM-Linear [Rombach et al., 2022] 或 EDM [Karras et al., 2022])竞争,甚至能够超越它们。现在,我们将把我们的方法应用于高分辨率文本到图像合成。因此,我们算法的最终性能不仅取决于训练方法,还取决于神经网络的参数化以及我们使用的图像和文本表示的质量。在下面的章节中,我们将描述如何改进所有这些组件,然后在第5.3节中扩展我们的最终方法。
5.2.1 改进的自编码器
潜在扩散模型通过在与预训练的自编码器相关的潜在空间中进行操作来实现高效率 [Rombach et al., 2022],该自编码器将输入RGB图像 X∈RH×W×3X \in \mathbb{R}^{H \times W \times 3}X∈RH×W×3 映射到低维空间 x=E(X)∈Rh×w×dx = \mathcal{E}(X) \in \mathbb{R}^{h \times w \times d}x=E(X)∈Rh×w×d。这种自编码器的重建质量设定了潜在扩散训练后可达图像质量的上限。与Dai等人 [2023] 类似,我们发现增加潜在通道数 ddd 可以显著提高重建性能,见表3。
直观上,预测具有更高 ddd 的潜在表示是一项更困难的任务,因此,具有增加容量的模型应该能够对更大的 ddd 表现更好,最终实现更高的图像质量。我们在图10中证实了这一假设,图中显示 d=16d=16d=16 的自编码器在样本FID方面表现出更好的缩放性能。在本文的剩余部分,我们因此选择 d=16d = 16d=16。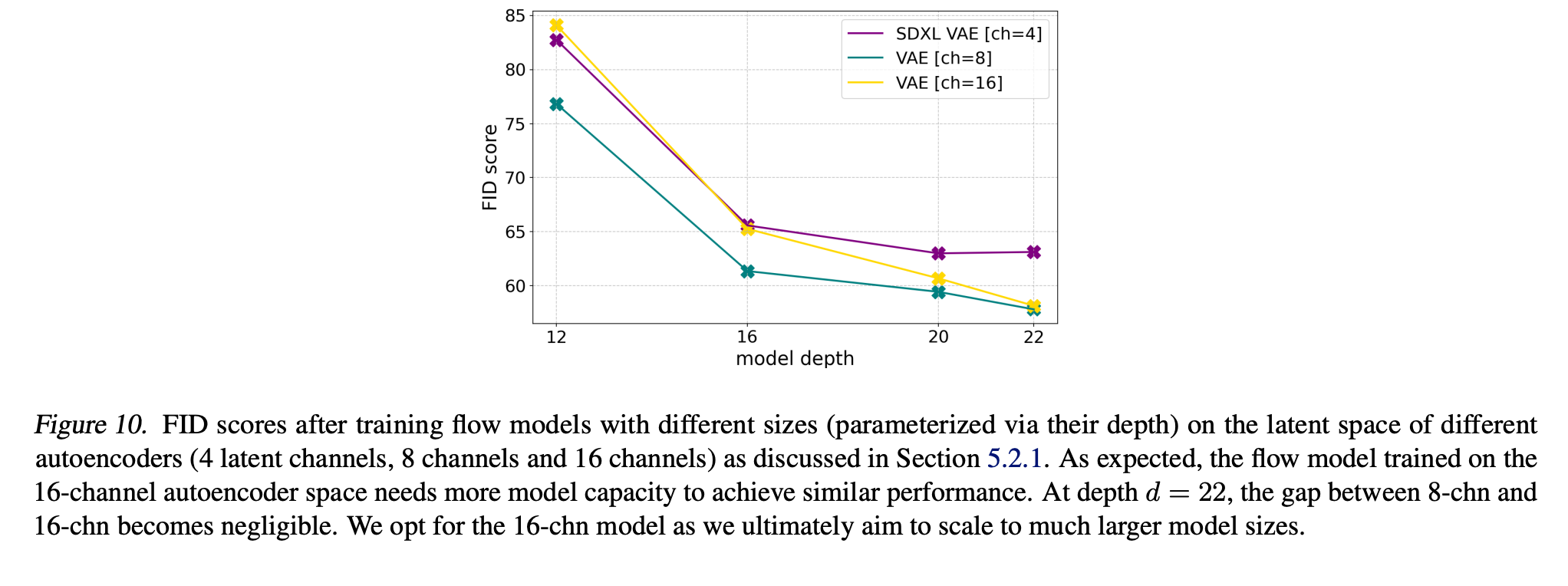
5.2.2 改进的标注
Betker等人 [2023] 证明,合成的标注可以极大地改善大规模训练的文本到图像模型。这是因为大规模图像数据集附带的人工生成标注通常过于简单,过分关注图像主体,而忽略描述背景或场景构成的细节,或者(如果适用)忽略显示的文本 [Betker et al., 2023]。我们遵循他们的方法,使用最先进的现成视觉语言模型 CogVLM [Wang et al., 2023] 为我们的大规模图像数据集创建合成标注。由于合成标注可能导致文本到图像模型遗忘视觉语言模型知识库中不存在的某些概念,我们使用原始标注和合成标注各50%的混合比例。
为了评估在这种标注混合上进行训练的效果,我们训练了两个 d=15d=15d=15 的MM-DiT模型,各训练250k步,一个仅使用原始标注,另一个使用50/50混合标注。我们在表4中使用GenEval基准测试 [Ghosh et al., 2023] 评估训练好的模型。结果表明,使用合成标注训练的模型明显优于仅使用原始标注的模型。因此,在本文的后续工作中,我们使用50/50的合成/原始标注混合。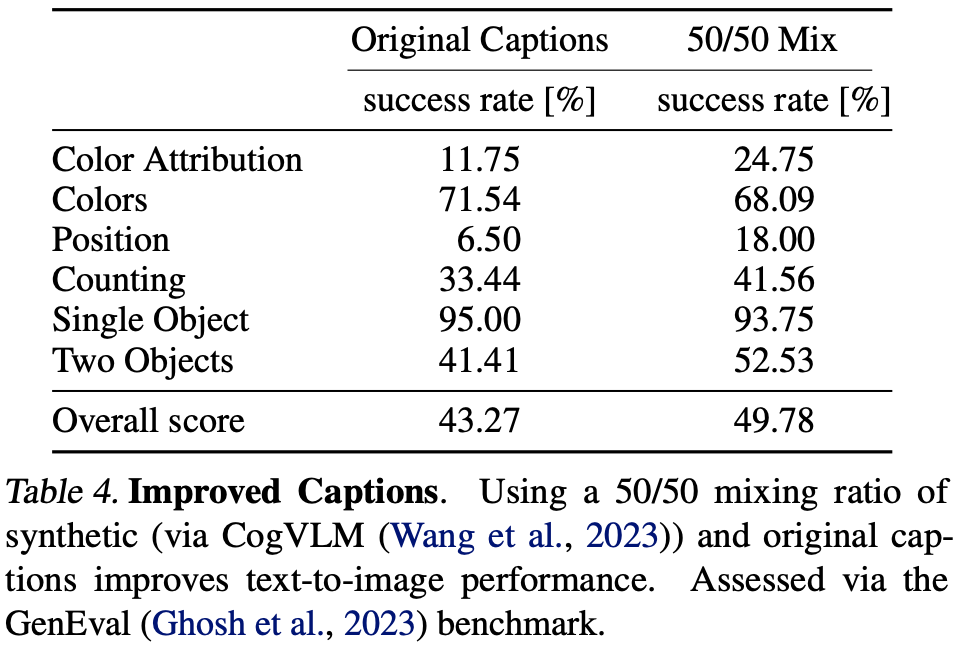
5.2.3 改进的文本到图像骨干网络
在本节中,我们将现有的基于Transformer的扩散骨干网络与我们新颖的多模态基于Transformer的扩散骨干网络MM-DiT(在第4节中介绍)的性能进行比较。MM-DiT专门设计为使用(两组)不同的可训练模型权重来处理不同领域(此处为文本和图像标记)。更具体地说,我们遵循第5.1节的实验设置,并在CC12M上比较DiT、CrossDiT(DiT但使用交叉注意力处理文本标记,而不是序列连接 [Chen et al., 2023])和我们的MM-DiT的文本到图像性能。对于MM-DiT,我们比较使用两组权重和三组权重的模型,后者分别处理CLIP [Radford et al., 2021] 和T5 [Raffel et al., 2019] 标记(参见第4节)。请注意,DiT(如第4节所述,将文本和图像标记连接起来)可以解释为MM-DiT的一个特例,即所有模态共享一组权重。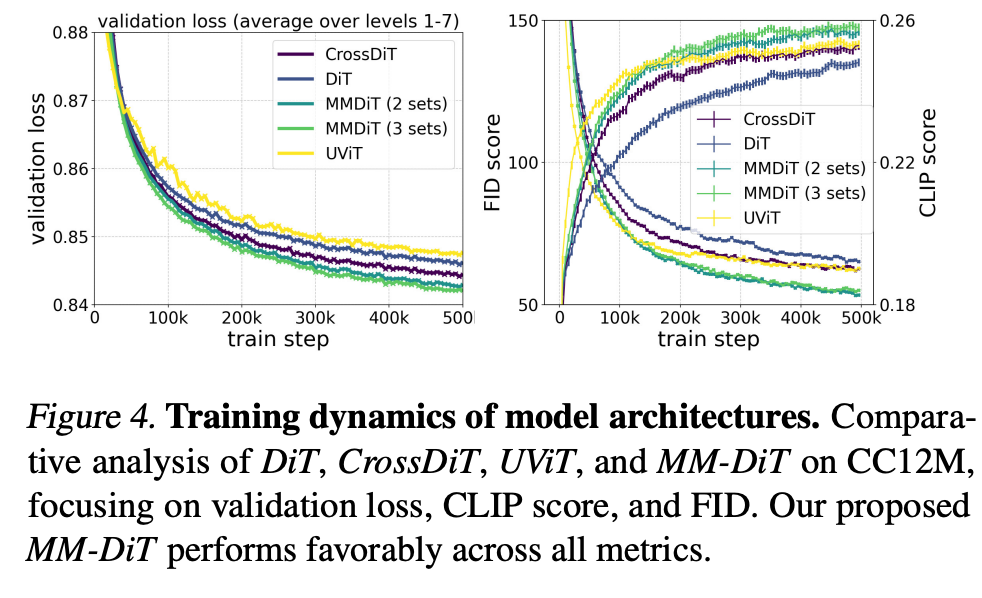
我们还在图4中分析了这些架构的收敛行为:普通的DiT表现不及UViT。使用交叉注意力的DiT变体CrossDiT实现了比UViT更好的性能,尽管UViT最初似乎学习得更快。我们的MM-DiT变体显著优于交叉注意力和普通变体。我们观察到,使用三组参数而不是两组(以增加参数数量和VRAM使用为代价)只能带来很小的收益,因此在本文的后续工作中,我们选择前者。
5.3 大规模训练
在扩大规模之前,我们对数据进行筛选和预编码,以确保预训练的安全性和效率。然后,前面所有关于扩散公式、架构和数据的考量将在最后一节中汇合,我们将模型规模扩大到80亿参数。
5.3.1 数据预处理
预训练缓解措施
训练数据显著影响生成模型的能力。因此,数据过滤能有效限制不良能力的产生[Nichol, 2022]。在规模化训练之前,我们对数据进行了以下类别的筛选:
(i) 性内容:我们使用NSFW检测模型来过滤露骨内容。
(ii) 美学:我们移除了根据我们的评分系统预测为低分的图像。
(iii) 记忆 regurgitation:我们使用基于聚类的去重方法,从训练数据中移除感知和语义上的重复项;详见附录E.2。
预计算图像和文本嵌入
我们的模型使用多个预训练的冻结网络的输出作为输入(自编码器潜在表示和文本编码器表示)。由于这些输出在训练期间是恒定的,我们为整个数据集预计算一次。我们在附录E.1中详细讨论了我们的方法。
5.3.2 高分辨率微调
QK归一化
通常,我们在256²像素分辨率的低分辨率图像上预训练所有模型。接下来,我们在具有混合宽高比的更高分辨率上对模型进行微调(详见下一段)。我们发现,当转移到高分辨率时,混合精度训练可能会变得不稳定,损失会发散。这可以通过切换到全精度训练来解决——但与混合精度训练相比,会导致性能下降约2倍。一个更有效的替代方案在(判别式)ViT文献中有所报道:Dehghani等人[2023]观察到,大型视觉Transformer模型的训练会发散,因为注意力熵不受控制地增长。为了避免这种情况,Dehghani等人[2023]提出在注意力操作之前对Q和K进行归一化。我们遵循这种方法,并在我们MMDiT架构的两个流中使用具有可学习尺度的RMSNorm[Zhang & Sennrich, 2019],见图2。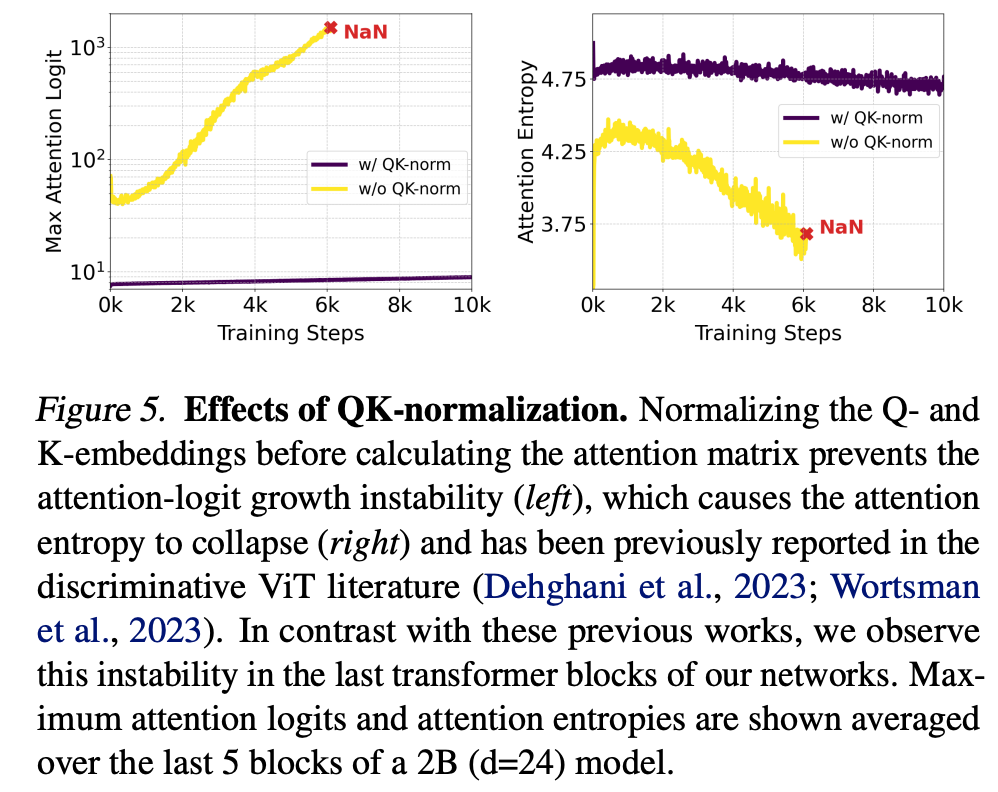
如图5所示,额外的归一化防止了注意力logit增长的不稳定性,证实了Dehghani等人[2023]和Wortsman等人[2023]的发现,并在与AdamW优化器中的ϵ=10−15\epsilon=10^{-15}ϵ=10−15结合时,实现了bf16混合精度下的高效训练。该技术也可以应用于在预训练期间未使用qk归一化的预训练模型:模型能快速适应额外的归一化层,并且训练更稳定。最后,我们想指出,虽然这种方法通常有助于稳定大型模型的训练,但它并非通用方案,可能需要根据具体的训练设置进行调整。
多宽高比的位置编码
在固定256×256分辨率上训练后,我们的目标是(i)提高分辨率,和(ii)实现推理时支持灵活的宽高比。由于我们使用2D位置频率嵌入,我们必须根据分辨率调整它们。在多宽高比设置中,直接像[Dosovitskiy等人, 2020]那样对嵌入进行插值将无法正确反映边长。相反,我们使用扩展和插值位置网格的组合,随后进行频率嵌入。
对于目标像素数为S2S^2S2的情况,我们使用分桶采样[NovelAI, 2022; Podell等人, 2023],使得每个批次由相同尺寸H×WH \times WH×W的图像组成,其中H⋅W≈S2H \cdot W \approx S^2H⋅W≈S2。对于最大和最小训练宽高比,这会产生将遇到的最大宽度值WmaxW_{\max}Wmax和高度值HmaxH_{\max}Hmax。设hmax=Hmax/16h_{\max}=H_{\max}/16hmax=Hmax/16, wmax=Wmax/16w_{\max}=W_{\max}/16wmax=Wmax/16和s=S/16s=S/16s=S/16为经过分块(下采样因子为2)和自编码器(下采样因子为8)处理后的潜在空间中的对应尺寸。基于这些值,我们构建一个垂直位置网格,其值为((p−hmax−s2)⋅256S)p=0hmax−1\left(\left(p-\frac{h_{\max}-s}{2}\right) \cdot \frac{256}{S}\right)_{p=0}^{h_{\max}-1}((p−2hmax−s)⋅S256)p=0hmax−1,水平位置同理。然后我们在嵌入生成的2D位置网格之前进行中心裁剪。
时间步调度与分辨率相关的偏移
直观上,由于更高分辨率有更多像素,我们需要更多噪声来破坏它们的信号。假设我们在一个具有n=H⋅Wn=H \cdot Wn=H⋅W像素的分辨率下工作。现在考虑一个"恒定"图像,即每个像素值都为ccc。前向过程产生zt=(1−t)c1+tϵz_t = (1-t)c\mathbf{1} + t\epsilonzt=(1−t)c1+tϵ,其中1\mathbf{1}1和ϵ∈Rn\epsilon \in \mathbb{R}^{n}ϵ∈Rn。因此,ztz_tzt提供了随机变量Y=(1−t)c+tηY=(1-t)c + t\etaY=(1−t)c+tη的nnn个观测值,其中ccc和η\etaη在R\mathbb{R}R中,η\etaη服从标准正态分布。因此,E(Y)=(1−t)c\mathbb{E}(Y)=(1-t)cE(Y)=(1−t)c且σ(Y)=t\sigma(Y)=tσ(Y)=t。于是我们可以通过c=11−tE(Y)c=\frac{1}{1-t}\mathbb{E}(Y)c=1−t1E(Y)恢复ccc,并且ccc与其样本估计c^=11−t∑i=1nzt,i\hat{c}=\frac{1}{1-t}\sum_{i=1}^{n} z_{t,i}c^=1−t1∑i=1nzt,i之间的误差标准差为σ(t,n)=t1−t1n\sigma(t, n)=\frac{t}{1-t}\sqrt{\frac{1}{n}}σ(t,n)=1−ttn1(因为YYY的均值的标准误差具有标准差tn\frac{t}{\sqrt{n}}nt)。因此,如果已经知道图像z0z_0z0在其像素上是恒定的,那么σ(t,n)\sigma(t, n)σ(t,n)代表了关于z0z_0z0的不确定度。例如,我们立即看到,将宽度和高度加倍会导致在任何给定时间0<t<10<t<10<t<1的不确定度减半。但是,我们现在可以将分辨率nnn处的时间步tnt_ntn映射到分辨率mmm处的时间步tmt_mtm,使得不确定度相同,即通过σ(tn,n)=σ(tm,m)\sigma(t_n, n)=\sigma(t_m, m)σ(tn,n)=σ(tm,m)。解出tmt_mtm得到:
tm=mntn1+(mn−1)tnt_m = \frac{ \sqrt{\frac{m}{n}} t_n }{ 1 + (\sqrt{\frac{m}{n}} - 1) t_n }tm=1+(nm−1)tnnmtn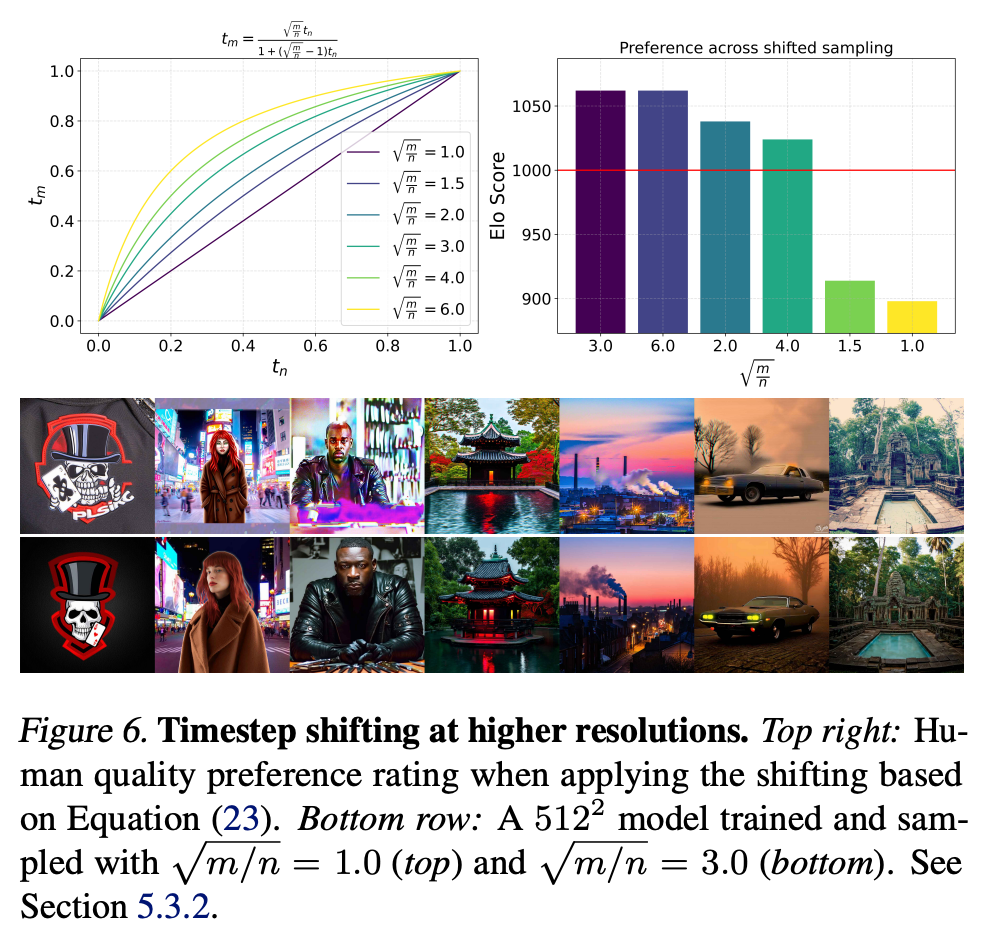
我们在图6中可视化这个偏移函数。请注意,恒定图像的假设并不现实。为了在推理期间找到偏移值α:=mn\alpha:=\sqrt{\frac{m}{n}}α:=nm的良好值,我们将其应用于在1024×10241024 \times 10241024×1024分辨率下训练的模型的采样步骤,并进行人类偏好研究。图6中的结果显示,对于大于1.5但小于更高偏移值的偏移值,样本有强烈的偏好。因此,在后续实验中,我们在1024×10241024 \times 10241024×1024分辨率的训练和采样中都使用偏移值α=3.0\alpha=3.0α=3.0。使用和不使用这种偏移的训练样本之间的定性比较可以在图6中找到。最后,请注意公式(23)意味着对数信噪比偏移为lognm\log\frac{n}{m}logmn,类似于[Hoogeboom等人, 2023]:
λtm=2log1−tnmntn=λtn−2logα=λtn−logmn\lambda_{t_m} = 2\log\frac{1-t_n}{\sqrt{\frac{m}{n}}t_n} = \lambda_{t_n} - 2\log\alpha = \lambda_{t_n} - \log\frac{m}{n}λtm=2lognmtn1−tn=λtn−2logα=λtn−lognm
在1024×10241024 \times 10241024×1024分辨率下进行偏移训练后,我们使用附录C中描述的直接偏好优化(DPO)对齐模型。
5.3.3 结果
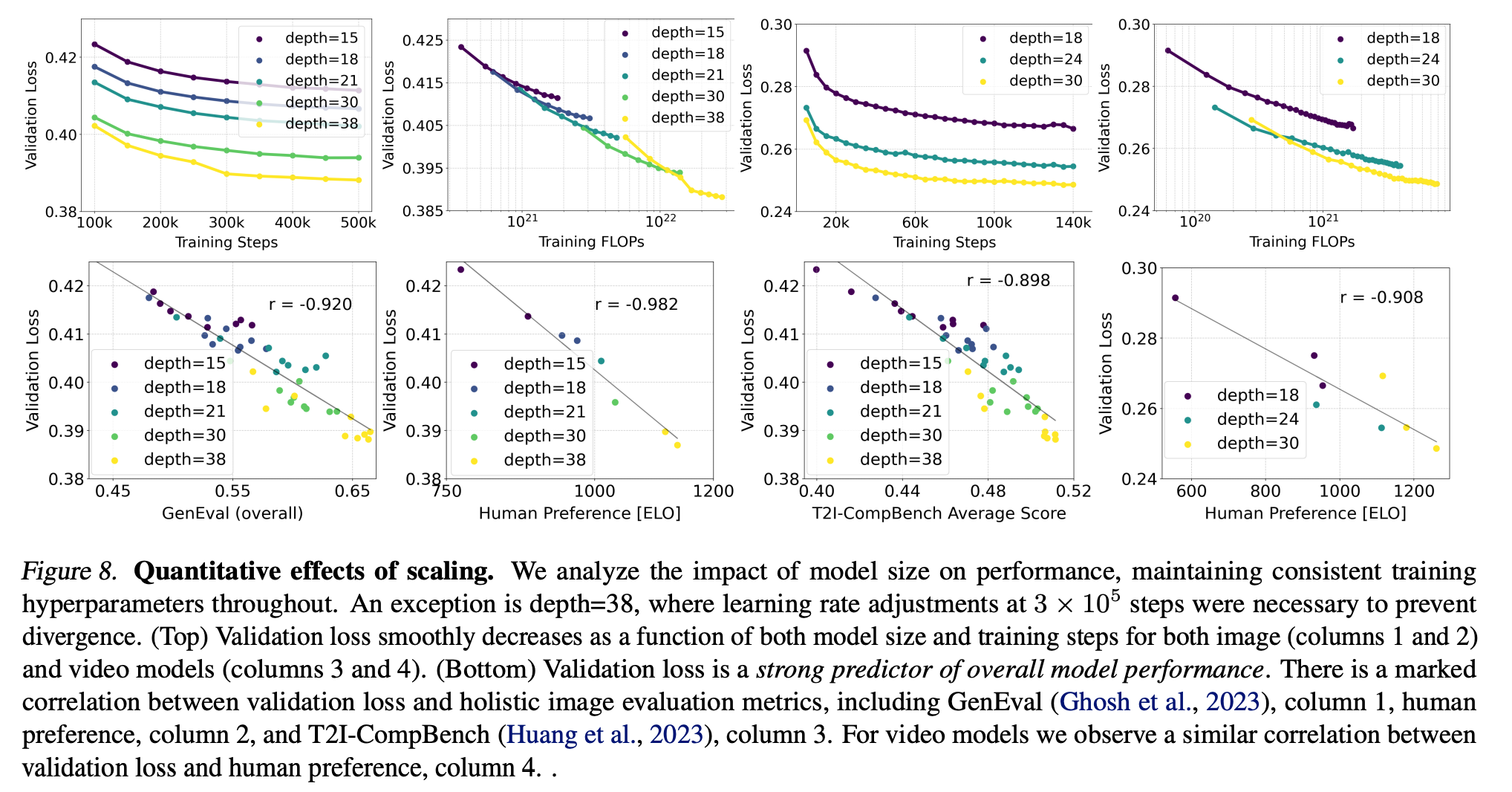
在图8中,我们研究了我们的MM-DiT规模化训练的效果。对于图像,我们进行了一项大规模的扩展研究,在2562256^22562像素分辨率下,使用预编码数据(参见附录E.1),批大小为4096,训练了不同参数数量的模型50万步。我们在2×22 \times 22×2图像块上训练[Peebles & Xie, 2023],并每5万步在COCO数据集[Lin等人, 2014]上报告验证损失。特别是,为了减少验证损失信号中的噪声,我们在t∈(0,1)t \in (0,1)t∈(0,1)内等间距采样损失水平,并分别计算每个水平的验证损失。然后我们对除最后一个水平(t=1t=1t=1)之外的所有水平的损失进行平均。
类似地,我们对我们的MM-DiT在视频上进行了初步的扩展研究。为此,我们从预训练的图像权重开始,并额外使用了2倍的时间分块。我们遵循Blattmann等人[2023b]的方法,将时间轴折叠到批次维度中,将数据输入预训练模型。在每个注意力层中,我们在空间注意力操作之后、最终前馈层之前,重新排列视觉流中的表示,并在所有时空令牌上添加全注意力。我们的视频模型在包含16帧256²像素的视频上训练了14万步,批大小为512。我们每5千步在Kinetics数据集[Carreira & Zisserman, 2018]上报告验证损失。请注意,图8中报告的视频训练的FLOPs仅来自视频训练,不包括图像预训练的FLOPs。
对于图像和视频领域,我们都观察到当增加模型大小和训练步数时,验证损失平滑下降。我们发现验证损失与综合评估指标(Comp-Bench [Huang等人, 2023], GenEval [Ghosh等人, 2023])以及人类偏好高度相关。这些结果支持将验证损失作为模型性能的一个简单而通用的度量。我们的结果在图像和视频模型上都没有显示饱和迹象。
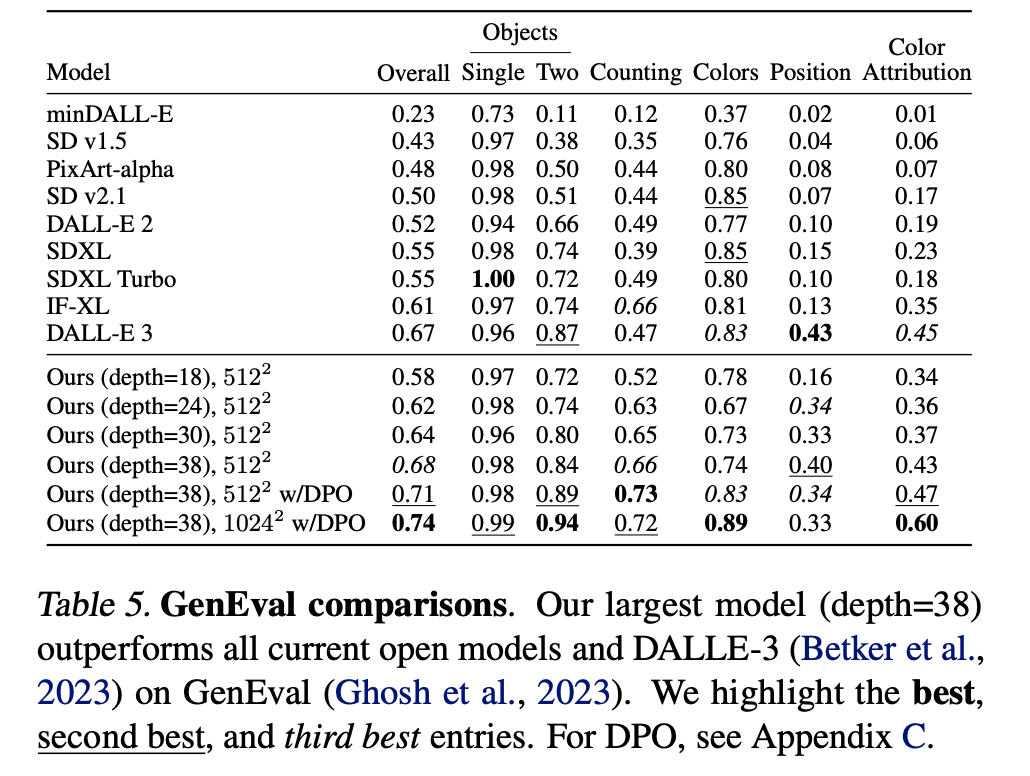
图12说明了训练一个更大的模型更长时间如何影响样本质量。表5显示了GenEval的完整结果。当应用第5.3.2节中介绍的方法并增加训练图像分辨率时,我们最大的模型在大多数类别中表现出色,并且在总分上超过了DALL-E 3 [Betker等人, 2023]——目前在提示词理解方面的最新技术。
我们的d=38d=38d=38模型在Parti-prompts基准测试[Yu等人, 2022]的人类偏好评估中,在视觉美学、提示词遵循度和文字生成类别上,优于当前专有[Betker等人, 2023; ide, 2024]和开源[Sauer等人, 2023; pla, 2024; Chen等人, 2023; Pernias等人, 2023]的最先进生成图像模型。参见图7。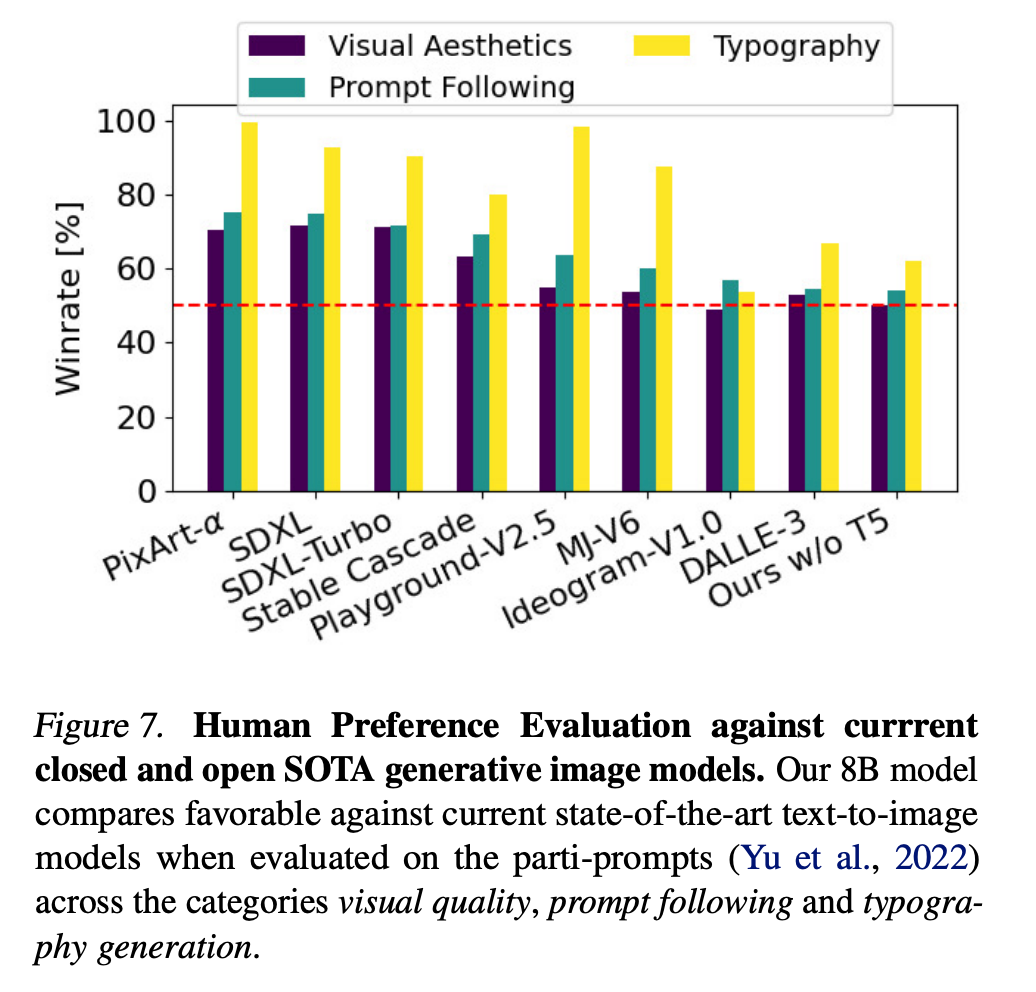
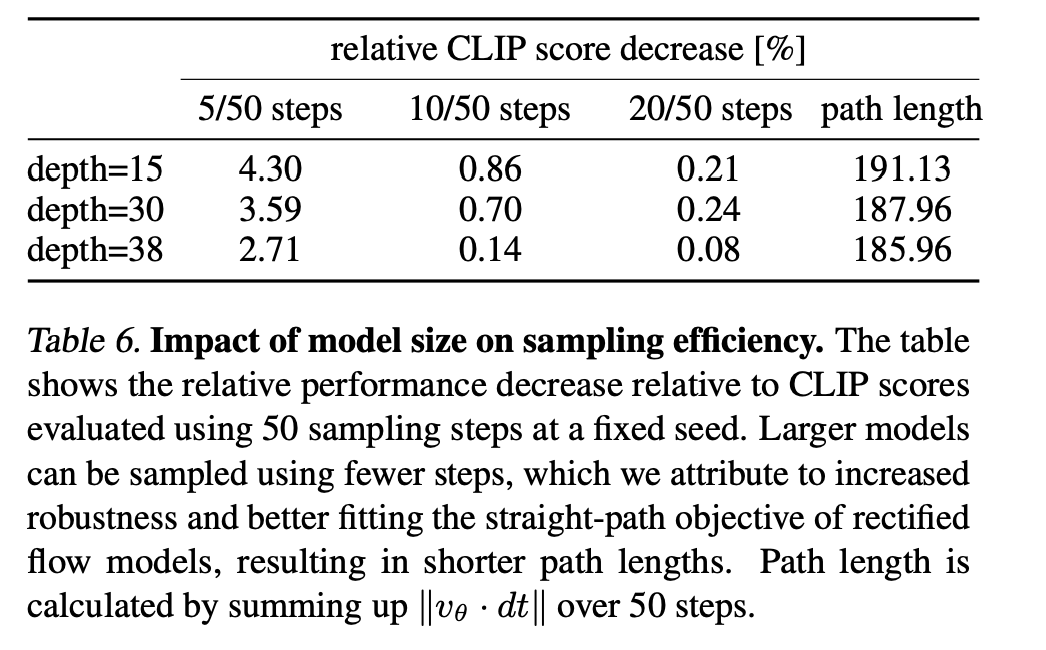
最后,表6强调了一个有趣的结果:不仅更大的模型性能更好,而且它们达到峰值性能所需的采样步数也更少。
灵活的文本编码器
虽然使用多个文本编码器的主要动机是提高整体模型性能[Balaji等人, 2022],但我们现在证明这种选择还增加了我们基于MM-DiT的整流流在推理时的灵活性。如附录B.3所述,我们使用三个文本编码器训练模型,每个编码器的丢弃率为46.3%。因此,在推理时,我们可以使用任意三个文本编码器的子集。这为在内存效率和提高模型性能之间进行权衡提供了手段,这对于需要大量VRAM的T5-XXL [Raffel等人, 2019]的47亿参数尤其相关。有趣的是,我们发现当仅使用两个基于CLIP的文本编码器进行文本提示,并将T5嵌入替换为零时,性能下降有限。
我们在图9中提供了定性可视化。只有当提示涉及高度详细的场景描述或大量书面文本时,我们才发现使用所有三个文本编码器会带来显著的性能提升。这些观察结果也在图7(Ours w/o T5)的人类偏好评估结果中得到验证。移除T5对美学质量评分没有影响(胜率50%),对提示词遵循度只有很小的影响(胜率46%),而其生成书面文字的能力贡献更为显著(胜率38%)。
6. 结论
在本工作中,我们对用于文本到图像合成的整流流模型进行了缩放分析。我们提出了一种用于整流流训练的新型时间步采样方法,该方法针对潜在扩散模型改进了先前的扩散训练公式,并在少步采样区域保留了整流流的有利特性。我们还展示了我们基于变换器的 MM-DiT 架构的优势,该架构考虑了文本到图像任务的多模态性质。最后,我们对这种组合进行了缩放研究,模型规模达到 80 亿参数,训练 FLOPs 达到 5×10225 \times 10^{22}5×1022。我们证明了验证损失的改进与现有的文本到图像基准测试以及人类偏好评估均具有相关性。生成建模和可扩展多模态架构方面的这些改进相结合,实现了与最先进的专有模型相竞争的性能。缩放趋势没有显示出饱和的迹象,这使我们有信心在未来继续提高模型的性能。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 37
37 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)