200 分钟网课压缩到 10 分钟:Python+FFmpeg+大模型,帮我省下 95% 学习时间
Context Window 限制:虽然现在有 128k context,但太长的输入会导致“Lost in the Middle”现象,中间的信息被遗忘。成本:全量输入的 Token 消耗巨大。通过以上不到 200 行的核心代码,我们实现了一个端到端的“视频练丹炉”。回顾我们的流水线mp4->wav(FFmpeg)wav->json(Whisper)json->summary(LLM)summa
摘要:在这个知识爆炸的时代,我们收藏了太多的视频教程,却往往止步于“收藏夹吃灰”。本文将手把手教你如何构建一个自动化视频知识提取系统。利用 Python 胶水语言的优势,结合 FFmpeg 的媒体处理能力、OpenAI Whisper 的语音识别模型以及 LLM 的语义总结能力,将长达数小时的枯燥网课浓缩成精炼的思维导图和文字摘要。本文不仅提供 7000+ 字的详细技术解析,还包含完整的工程代码(Audio Extraction -> ASR -> Summarization -> MindMap)。
第一章:视频时代的“信息过载”与“时间焦虑”
1.1 2倍速也救不了的“注水肉”
你是否也有这样的经历:打开一个 3 小时的技术讲座视频,前 20 分钟是讲师在调试麦克风和闲聊,中间穿插着大量的环境搭建(Configuration)等待时间,真正有价值的核心逻辑可能只有 15 分钟。
即使我们开启 2x 甚至 3x 倍速,依然需要消耗大量整块的时间(Chunk Time)去盯着屏幕。对于碎片化时间极其宝贵的现代程序员来说,这是一种巨大的浪费。
1.2 我们的目标:Knowledge Graph
我们要做的不是简单的“视频剪辑”,而是“知识提炼”。
输入:一个 2GB 的 .mp4 文件(例如:Go 语言并发编程实战)。
输出:
- 全文逐字稿(带时间戳,方便回溯)。
- 核心摘要(Markdown 格式,提取关键知识点)。
- 思维导图(Markmap/XMind,可视化知识结构)。
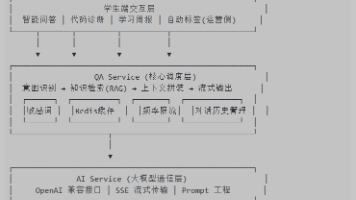
第二章:系统架构设计
这是一个经典的 ETL (Extract, Transform, Load) 流程,只不过处理的对象是非结构化的音视频数据。
技术栈选型:
- 媒体层:
ffmpeg-python(比 subprocess 更优雅的 wrapper)。 - 感知层:
openai-whisper(目前最强的开源 ASR 模型)。 - 认知层:
DeepSeek-Chat或GPT-4o(长上下文处理)。 - 展示层:
markmap-lib(将 Markdown 转为交互式导图)。
第三章:手术刀般的媒体处理 —— FFmpeg
在进行语音识别之前,我们需要将视频中的音频轨道提取出来。很多人会直接用视频文件喂给 Whisper,这会造成巨大的不必要 I/O 开销。
3.1 高效音频提取
ffmpeg 支持流式处理。我们要提取 16kHz 采样率、单声道的 WAV 文件(Whisper 的最佳输入格式)。
import ffmpeg
import os
import logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
class MediaProcessor:
def __init__(self, input_path):
self.input_path = input_path
self.filename = os.path.splitext(os.path.basename(input_path))[0]
def extract_audio(self, output_dir="temp_audio"):
"""
从视频中提取音频,转为 16k 采样率单声道
"""
if not os.path.exists(output_dir):
os.makedirs(output_dir)
output_path = os.path.join(output_dir, f"{self.filename}.wav")
try:
logger.info(f"正在提取音频: {self.input_path} -> {output_path}")
(
ffmpeg
.input(self.input_path)
.output(output_path, ac=1, ar='16k') # ac=audio channels, ar=audio rate
.overwrite_output()
.run(capture_stdout=True, capture_stderr=True)
)
return output_path
except ffmpeg.Error as e:
logger.error(f"FFmpeg 错误: {e.stderr.decode()}")
raise
3.2 进阶:静音检测 (VAD)
很多网课会有长时间的 silence(讲师思考、写代码过程)。直接识别这些静音段不仅浪费 GPU,还容易导致 Whisper 产生幻觉(Hallucination,不断重复上一句话)。
我们可以利用 ffmpeg 的 silencedetect 滤镜来预先切分音频,但这会增加系统复杂度。在本项目中,我们利用 Whisper V3 自带的 VAD 功能来简化流程。
第四章:听清每一个字 —— Whisper ASR 实战
4.1 模型选择与显存优化
Whisper 提供了从小到大多个模型:tiny, base, small, medium, large-v3。
对于技术类网课,由于包含大量专有名词(如 “Kubernetes”, “Polymorphism”),强烈建议使用 large-v3。
如果在本地运行(如 8G 显存的 Laptop),我们需要 float16 甚至 int8 量化。
import whisper
import torch
import json
class ASRWorker:
def __init__(self, model_size="large-v3", device=None):
if not device:
self.device = "cuda" if torch.cuda.is_available() else "cpu"
else:
self.device = device
logger.info(f"加载 Whisper 模型: {model_size} on {self.device}")
self.model = whisper.load_model(model_size, device=self.device)
def transcribe(self, audio_path):
"""
执行语音识别
"""
logger.info("开始语音识别,这可能需要一些时间...")
# initial_prompt 非常重要,用于引导模型输出正确的标点和专业术语风格
result = self.model.transcribe(
audio_path,
verbose=True,
initial_prompt="这是一段关于计算机编程的中文技术教程,包含 Python, Golang, Docker 等术语。"
)
# 保存原始结果
with open(f"{audio_path}.json", "w", encoding="utf-8") as f:
json.dump(result, f, ensure_ascii=False, indent=2)
logger.info(f"识别完成,文本长度: {len(result['text'])}")
return result
4.2 处理“长难句”与时间戳
result['segments'] 包含了带时间戳的分段文本。这对于我们后续生成“点击跳转”的摘要非常重要。因为我们希望生成的摘要是:
[05:20] 讲解了协程(Coroutine)与线程的区别…
第五章:AI 大脑 —— LLM 摘要生成
有了十万字的逐字稿,直接丢给 LLM 是不行的,原因有二:
- Context Window 限制:虽然现在有 128k context,但太长的输入会导致“Lost in the Middle”现象,中间的信息被遗忘。
- 成本:全量输入的 Token 消耗巨大。
5.1Map-Reduce 策略
针对长视频,最好的策略是 Map-Reduce:
- Map: 将长文本按每 10 分钟(或 4000 token)切块,分别总结。
- Reduce: 将所有块的总结再次汇总,生成最终的大纲。
from langchain.text_splitter import RecursiveCharacterTextSplitter
from openai import OpenAI
class Summarizer:
def __init__(self, api_key, base_url):
self.client = OpenAI(api_key=api_key, base_url=base_url)
def summarize_chunk(self, text_chunk):
"""
Map 阶段:总结片段
"""
response = self.client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": "你是一个专业的技术编辑。请总结以下课程片段的核心知识点,保留关键的技术名词。使用 Markdown 列表格式。"},
{"role": "user", "content": text_chunk}
]
)
return response.choices[0].message.content
def final_summary(self, chunk_summaries):
"""
Reduce 阶段:生成最终大纲
"""
combined_text = "\n".join(chunk_summaries)
response = self.client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": "你是一个技术专家。请根据以下的分段摘要,生成一份结构清晰、逻辑严密的完整课程笔记。不仅要列出知识点,还要解释其关联。最后生成一个 Mermaid 思维导图代码。"},
{"role": "user", "content": combined_text}
]
)
return response.choices[0].message.content
第六章:一图胜千言 —— 自动化生成思维导图
LLM 生成的 Mermaid 代码虽然好,但渲染需要插件。我们可以生成一个独立的 HTML 文件,利用 markmap 库来展示。
6.1 Markmap 模板注入
我们可以准备一个 HTML 模板,将 Markdown 内容注入进去。
def generate_html_mindmap(markdown_content, output_file="mindmap.html"):
template = """
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<script src="https://cdn.jsdelivr.net/npm/d3@7"></script>
<script src="https://cdn.jsdelivr.net/npm/markmap-view@0.15.4"></script>
<script src="https://cdn.jsdelivr.net/npm/markmap-lib@0.15.4/dist/browser/index.min.js"></script>
<style>
body, #mindmap { height: 100vh; margin: 0; padding: 0; }
</style>
</head>
<body>
<svg id="mindmap"></svg>
<script>
const transformer = new markmap.Transformer();
const markdown = `
MARKDOWN_PLACEHOLDER
`;
const { root } = transformer.transform(markdown);
const mm = markmap.Markmap.create('#mindmap', null, root);
</script>
</body>
</html>
"""
# 简单的字符串替换,实际生产可以用 Jinja2
safe_markdown = markdown_content.replace("`", "\`")
html_content = template.replace("MARKDOWN_PLACEHOLDER", safe_markdown)
with open(output_file, "w", encoding="utf-8") as f:
f.write(html_content)
logger.info(f"思维导图已生成: {output_file}")
现在,通过双击这个 HTML 文件,你就能看到一张这节课的完整知识拓扑图,并且可以自由缩放。
第七章:总结与展望
通过以上不到 200 行的核心代码,我们实现了一个端到端的“视频练丹炉”。
回顾我们的流水线:
mp4->wav(FFmpeg)wav->json(Whisper)json->summary(LLM)summary->html(Markmap)
未来优化方向:
- OCR 增强:结合
Video-LLaVA等多模态模型,提取视频画面中的 PPT 内容或代码演示,与语音内容互补。 - RAG 问答:将课程内容存入向量数据库(Vector DB),实现“与视频对话”,这才是终极的学习形态。
技术改变生活,也改变学习方式。希望这套系统能帮你省下那些被“水时长”浪费的生命,去探索更广阔的技术宇宙。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 21
21 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)