Efficient Leverage Score Sampling for Tensor Train Decomposition
张量列(Tensor Train, TT)分解作为一种高效压缩高维张量数据的流行工具,被广泛应用于机器学习和量子物理领域。在本文中,我们提出了一种高效算法,通过依赖精确杠杆得分采样(exact leverage scores sampling)的交替最小二乘(Alternating Least Squares, ALS)算法来加速计算 TT 分解。
文章目录
摘要
张量列(Tensor Train, TT)分解作为一种高效压缩高维张量数据的流行工具,被广泛应用于机器学习和量子物理领域。在本文中,我们提出了一种高效算法,通过依赖精确杠杆得分采样(exact leverage scores sampling)的交替最小二乘(Alternating Least Squares, ALS)算法来加速计算 TT 分解。
为此,我们提出了一种数据结构,允许我们以相对于张量尺寸呈对数级的时间复杂度(with time complexity logarithmic in the tensor size),高效地从张量中进行采样。我们的贡献具体利用了 T T TT TT 分解的规范形式(canonical form)。通过在 ALS 的每次迭代中维护该规范形式,我们可以高效地计算(并从中采样)杠杆得分,从而在求解每个草图最小二乘(sketched least-square)问题时实现显著加速。在针对稠密和稀疏张量的合成数据与真实数据上的实验表明,我们的方法优于基于 SVD 和基于 ALS 的算法。
由于张量的高维特性,设计用于计算 TT 分解的高效算法至关重要。
-
计算 N N N 维张量 X \mathcal{X} X 的 TT 分解的一种流行方法是 TT-SVD 算法 [Oseledets, 2011],该算法在张量展开矩阵上使用一系列奇异值分解,从而在单次遍历中生成 TT 表示。由于 TT-SVD 需要对 X \mathcal{X} X 的展开矩阵执行 SVD,其成本随 N N N 呈指数级增长。
-
交替最小二乘(ALS)是另一种寻找 TT 近似的流行方法 [Holtz et al., 2012]。ALS 从一个粗略的猜测开始,其每次迭代都涉及求解一系列最小二乘问题。虽然 ALS 是许多张量分解问题中的主力算法(the workhorse algorithm),但其计算成本在张量的阶数( N N N)上仍然是指数级的,因为每次迭代都需要求解涉及 X \mathcal{X} X 展开矩阵的最小二乘问题。
这些问题导致人们寻找基于随机化和采样技术的替代方案(based on randomization and sampling techniques)。
-
通过用经过充分研究的随机化对应版本(a well-studied randomized counterpart) [Halko et al., 2011, Huber et al., 2017] 替换精确奇异值分解(SVD),可以实现一种具有强精度保证的、比 TT-SVD 更廉价的替代方案。
-
TT-ALS 方法的随机化变体受到的关注较少。在 Chen et al. [2023] 中,作者提出了一种随机化 ALS 算法,该算法在每次迭代中使用 TensorSketch [Pham and Pagh, 2013]。
在这项工作中,我们也提出了一种新颖的 TT-ALS 算法的随机化变体,它依赖于精确杠杆得分采样(exact leverage score sampling)。值得注意的是,TensorSketch TT-ALS Chen et al. [2023] 中的草图大小对张量维度 I I I 具有指数依赖性,而(whereas)我们的算法避免了草图大小对 I I I 的任何依赖。
我们的贡献。 在本文中,我们提出了一种新的基于采样的 ALS 方法来计算 TT 分解:rTT-ALS。
- 通过使用精确杠杆得分采样,我们能够显著减小每个 ALS 最小二乘问题的大小,同时对近似误差提供强有力的保证。
- 在 rTT-ALS 的核心,我们利用 TT 规范形式来高效计算精确杠杆得分,并加速 ALS 每次迭代中最小二乘问题的求解。
- 据我们所知,rTT-ALS 是第一个依赖于杠杆得分采样 的、通过 ALS 算法实现的高效 TT 分解。
- 我们在合成的和真实的大规模稀疏及稠密张量上提供的实验表明,rTT-ALS 可以实现高达 26 × 26\times 26× 的加速比,与其非随机化对应版本相比,精度损失极小或没有损失。
我们的核心贡献是以下定理,它表明我们可以通过根据其平方行范数进行高效采样,来高效地计算 TT 张量核心的左正交链的子空间嵌入(有关技术定义和细节,请参阅第 3.1 3.1 3.1 小节)。
定义 3.2. 一个 TT 分解 TT ( ( A n ) n = 1 N ) ∈ R I 1 × ⋯ × I N \text{TT}((\mathcal{A}_n)_{n=1}^N) \in \mathbb{R}^{I_1 \times \dots \times I_N} TT((An)n=1N)∈RI1×⋯×IN 被称为相对于固定索引 j ∈ [ N ] j \in [N] j∈[N] 处于规范形式(is in a canonical format),如果对于所有 n < j n < j n<j 满足 A n L ⊤ A n L = I R n {A_n^L}^\top A_n^L = I_{R_n} AnL⊤AnL=IRn,并且对于所有 n > j n > j n>j 满足 A n R A n R ⊤ = I R n − 1 A_n^R {A_n^R}^\top = I_{R_{n-1}} AnRAnR⊤=IRn−1(见图 2)。

As a special case, we denote the left (resp. right) matricization of a 3-dimensional tensor A ∈ R I 1 × I 2 × I 3 \mathcal{A} \in \mathbb{R}^{I_1 \times I_2 \times I_3} A∈RI1×I2×I3 by A L = ( A ) ( 3 ) ⊤ ∈ R I 1 I 2 × I 3 A^L = (A)_{(3)}^\top \in \mathbb{R}^{I_1 I_2 \times I_3} AL=(A)(3)⊤∈RI1I2×I3 and A R = A ( 1 ) ∈ R I 1 × I 2 I 3 A^R = A_{(1)} \in \mathbb{R}^{I_1 \times I_2 I_3} AR=A(1)∈RI1×I2I3.
5 实验
所有实验均在 NERSC Perlmutter(一台 HPE Cray EX 超级计算机)和 Mila Quebec AI Institute 计算集群的 CPU 节点上进行。我们的代码可在 https://github.com/vbharadwaj-bk/ortho_tt_subspace_embedding 获取。在本节中,我们在两类张量上展示了所提出的 rTT-ALS 的有效性:(i) 合成和真实的稠密数据集,以及 (ii) 真实的稀疏数据集。
我们使用拟合度作为评估指标(越高越好): fit ( X ~ , X ) = 1 − ∥ X ~ − X ∥ F / ∥ X ∥ F \text{fit}(\tilde{\mathcal{X}}, \mathcal{X}) = 1 - \|\tilde{\mathcal{X}} - \mathcal{X}\|_F / \|\mathcal{X}\|_F fit(X~,X)=1−∥X~−X∥F/∥X∥F
其中 X ~ \tilde{\mathcal{X}} X~ 是 TT 近似,而 X \mathcal{X} X 是目标张量。
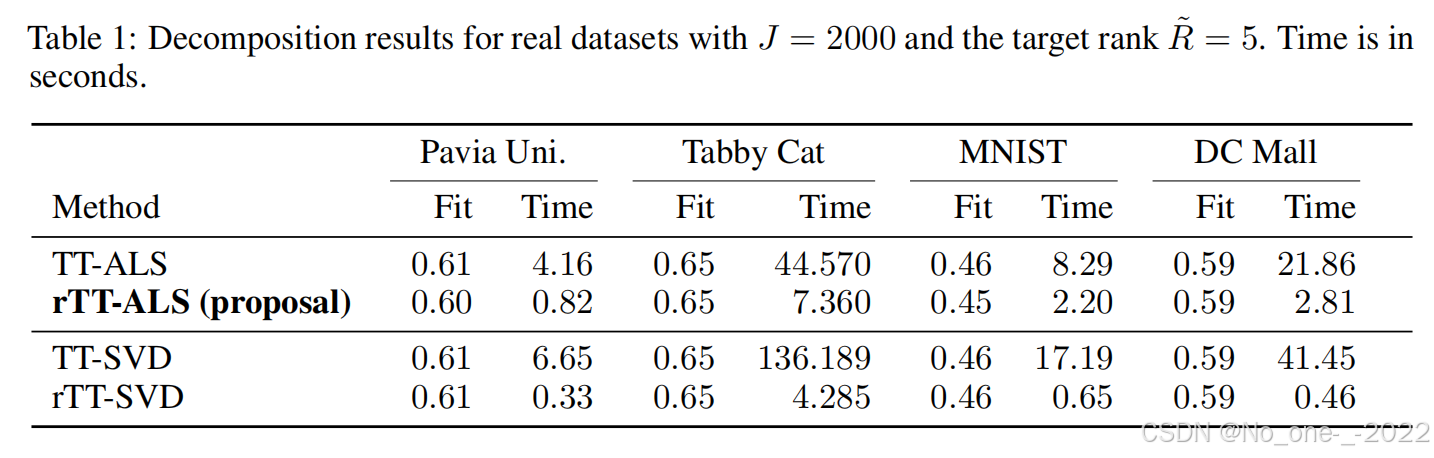
稠密张量实验的目标是展示 rTT-ALS 比 TT-ALS 和 TT-SVD 具有更好的时间复杂度,同时在拟合度方面与 rTT-SVD 相当。
稀疏张量实验表明,基于 SVD 的分解无法处理高阶(稀疏)张量。
我们将 rTT-ALS 与经典的 TT-ALS 进行了比较。运行时间的改进在大型稀疏张量上最为显著。图 4 4 4 比较了 rTT-ALS 与非随机化 ALS 的精度(y 轴,越高越好)相对于 ALS 迭代时间的关系。对于较低的秩,每次迭代的加速比可高达 26 × 26\times 26×。特别是对于 NELL-2 张量,该图显示,达到非随机化 ALS 三位有效数字以内的精度所需的时间,比优化的非随机化 ALS 基线大约快 3 − 4 × 3-4\times 3−4×。
5.1 Decomposition of Synthetic and Real Dense Datasets
我们将 rTT-ALS 与其他三种方法进行了比较:
- TT-SVD [Oseledets, 2011]、
- 随机化 TT-SVD (rTT-SVD) [Huber et al., 2017]
- 和 TT-ALS [Holtz et al., 2012]。
对于基于 SVD 的方法,我们使用 TensorLy [Kossaifi et al., 2019],而对于确定性 TT-ALS,我们使用自己的实现。为了简单起见,我们在所有实验中设定 R 1 = ⋯ = R N − 1 = R R_1 = \dots = R_{N-1} = R R1=⋯=RN−1=R。对于所有算法,我们通过拟合度和运行时间来说明性能质量。
5.1.1 Synthetic Data Experiments
对于合成数据实验,我们生成了大小为 I × I × I I \times I \times I I×I×I 的随机张量,其中 I ∈ { 100 , … , 500 } I \in \{100, \dots, 500\} I∈{100,…,500},TT 秩 R = 20 R = 20 R=20(通过从标准正态分布中独立同分布地抽取每个核心的组件)。向生成张量的每个条目添加均值为零且标准差为 10 − 6 10^{-6} 10−6 的微小高斯噪声。然后我们运行这四种方法来寻找目标张量的秩 R ~ = 5 \tilde{R} = 5 R~=5 近似。
基于 ALS 的方法使用其基于 SVD 的对应方法进行初始化(TT-ALS 使用 TT-SVD 的输出,rTT-ALS 使用 rTT-SVD 的输出),并运行 15 15 15 次迭代。对于所有 I I I 值,rTT-ALS 的样本数量固定为 J = 5000 J = 5000 J=5000。图 3 报告了所有四种算法在 5 5 5 次试验中的平均拟合度随维度的变化。对于 I = 500 I = 500 I=500,rTT-ALS 比 TT-ALS 快约 2 × 2\times 2×,比 TT-SVD 快 3 × 3\times 3×。虽然 rTT-SVD 是最快的方法,但其在拟合度方面的表现较差。
5.1.2 Real Data Experiments.
对于真实数据实验,我们考虑了四个真实图像和视频数据集(关于数据集的更多详细信息在附录 C 中给出):
- (i) Pavia University 是大小为 ( 610 × 340 × 103 ) (610 \times 340 \times 103) (610×340×103) 的高光谱图像数据集,
- (ii) DC Mall 也是大小为 ( 1280 × 307 × 191 ) (1280 \times 307 \times 191) (1280×307×191) 的高光谱图像数据集。这两个数据集都是三维张量,其中前两个维度是图像的高度和宽度,第三个维度是光谱波段的数量,
- (iii) MNIST 数据集的大小为 ( 60000 × 28 × 28 ) (60000 \times 28 \times 28) (60000×28×28),
- 以及 iv) Tabby Cat 是大小为 ( 720 × 1280 × 286 ) (720 \times 1280 \times 286) (720×1280×286) 的三维张量,其中分别包含一个人坐在公园长椅上和一只猫的灰度视频。前两个维度是帧的高度和宽度,第三个维度是帧数。
对于所有数据集,预处理步骤是通过将数据张量张量化为更高维张量(tensorizing data tensors into higher-dimensional tensors)来完成的。表 1 说明了当 R ~ = 5 \tilde{R} = 5 R~=5 时单次试验的结果。对于所有数据集,我们将样本数量固定为 J = 2000 J = 2000 J=2000。与合成数据实验类似,rTT-ALS 比 TT-ALS 和 TT-SVD 更快(比 TT-ALS 快高达 10 × 10\times 10×)。
5.2 Approximate Sparse Tensor Train Decomposition
接下来,我们将 rTT-ALS 应用于来自 FROSTT [Smith et al., 2017] 的三个大型稀疏张量。表 2 给出了我们方法分解这些张量所达到的拟合度。这些张量中最大的 NELL-2 拥有约 7700 万个非零条目,其模态大小达到数万。稀疏张量分解的拟合度通常较低,但所得分解的因子已被成功用于挖掘模式 [Larsen and Kolda, 2022]。对于这些实验,我们选择所有分解秩相等,即 R 1 = ⋯ = R N = R R_1 = \dots = R_N = R R1=⋯=RN=R,并在 R R R 的一系列值上进行了测试。
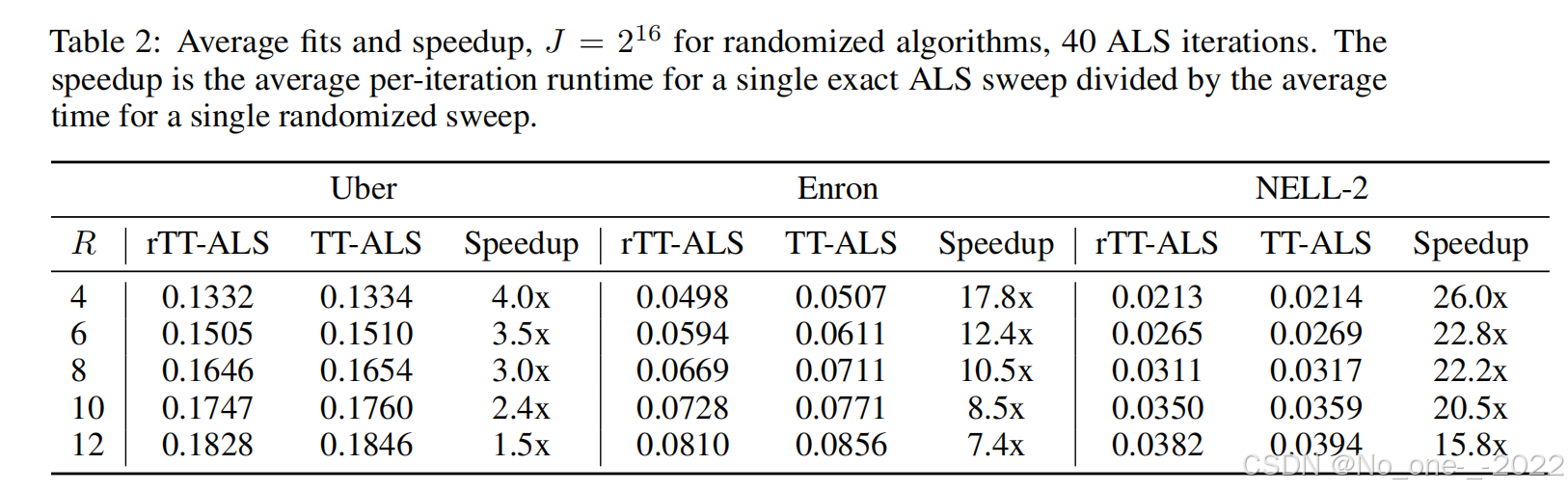
对于 Uber 和 NELL-2,rTT-ALS 产生的拟合度与非随机化 ALS 方法产生的拟合度在第三位有效数字范围内是匹配的,而在 Enron 张量上的误差略高。在整个实验中,我们将随机化算法的样本数量固定为 J = 2 16 J = 2^{16} J=216。结果是,随着目标秩的增加,随机化方法和精确方法(the randomized and exact methods)之间拟合度的差距也随之增大,这符合我们理论的预测。
表 2 还报告了 rTT-ALS 相比于精确算法在每次 ALS 扫描(sweep)中的平均加速比。在目标秩为 12 的 NELL-2 稀疏张量上,非随机化 ALS 算法每次 ALS 扫描平均需要 29.4 秒,而 rTT-ALS 仅需 1.87 秒。图 4 显示,在所有三个张量上,我们的方法比非随机化对应方法进展更快。
于我们无法找到文档齐全且高性能的稀疏张量列分解库,我们用 C++ 编写了一个快速多线程实现,作为这些图表中的基线方法(代码将公开)。
图 5 显示了改变样本数量对最终拟合度的影响。我们发现,随着样本数量增加 5 倍(从 J = 2 15 J = 2^{15} J=215 开始),Uber 和 NELL-2 的精度均有适度提高。增加 J J J 对 Enron 张量的影响较小,该张量通常更难通过独立同分布(i.i.d.)随机因子初始化进行分解 [Larsen and Kolda, 2022]。
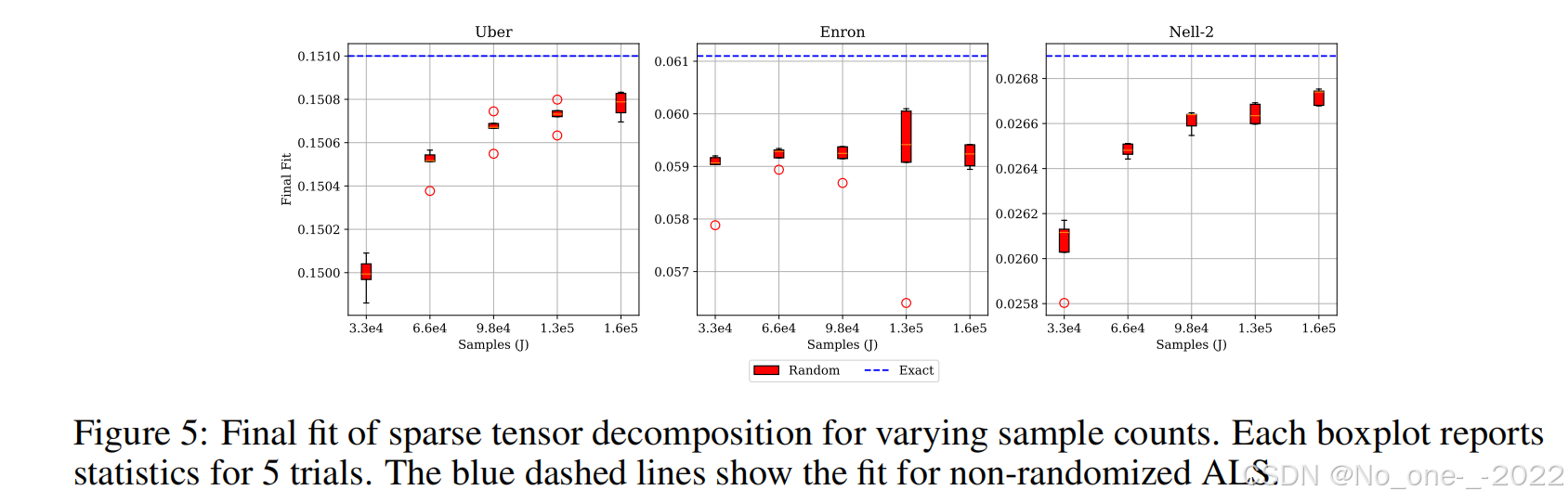
红色圆圈(离群值):当某次实验的结果超出了箱体须的范围(通常定义为超过 1.5 1.5 1.5 倍四分位距)时,就会被单独画出来,成为那个红色圆圈。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 29
29 0
0- 0



 已为社区贡献27条内容
已为社区贡献27条内容

所有评论(0)