Spring-Ai
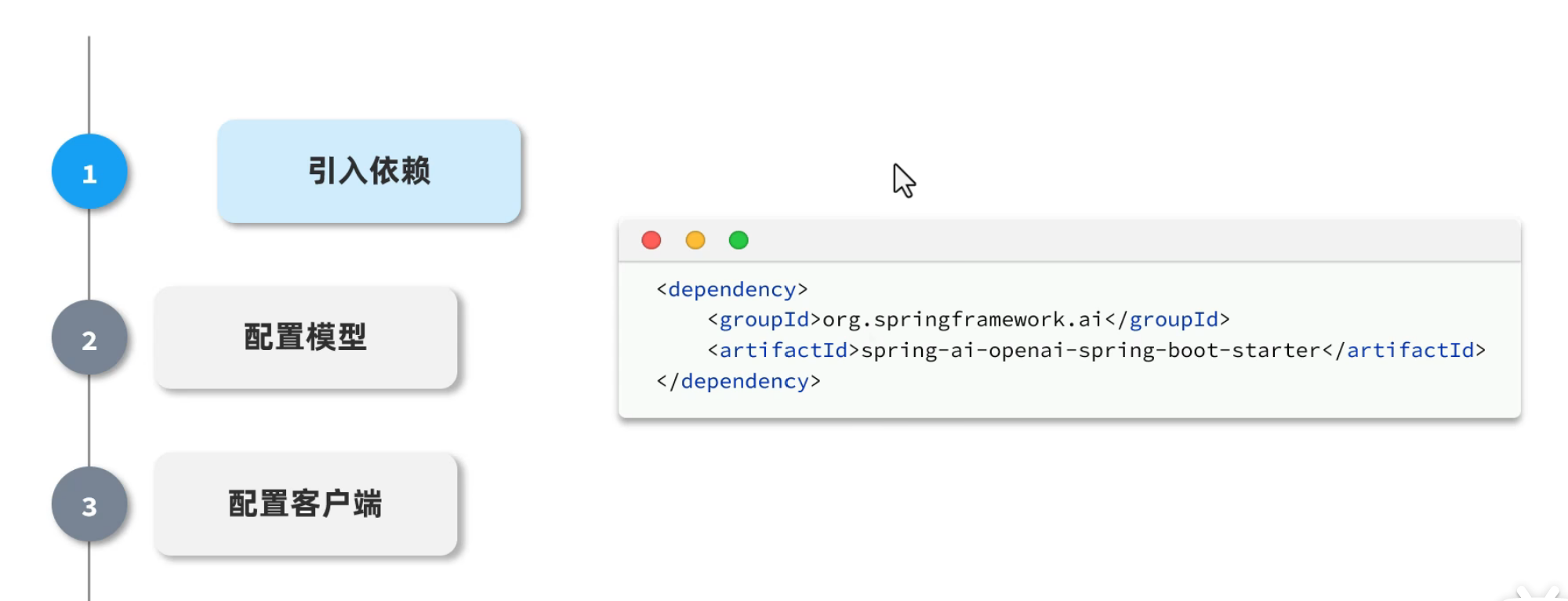
①引入依赖(自动完成)②配置模型③配置客户端。
(一)对话机器人
一,快速入门
1.准备
①引入依赖(自动完成)
②配置模型
③配置客户端
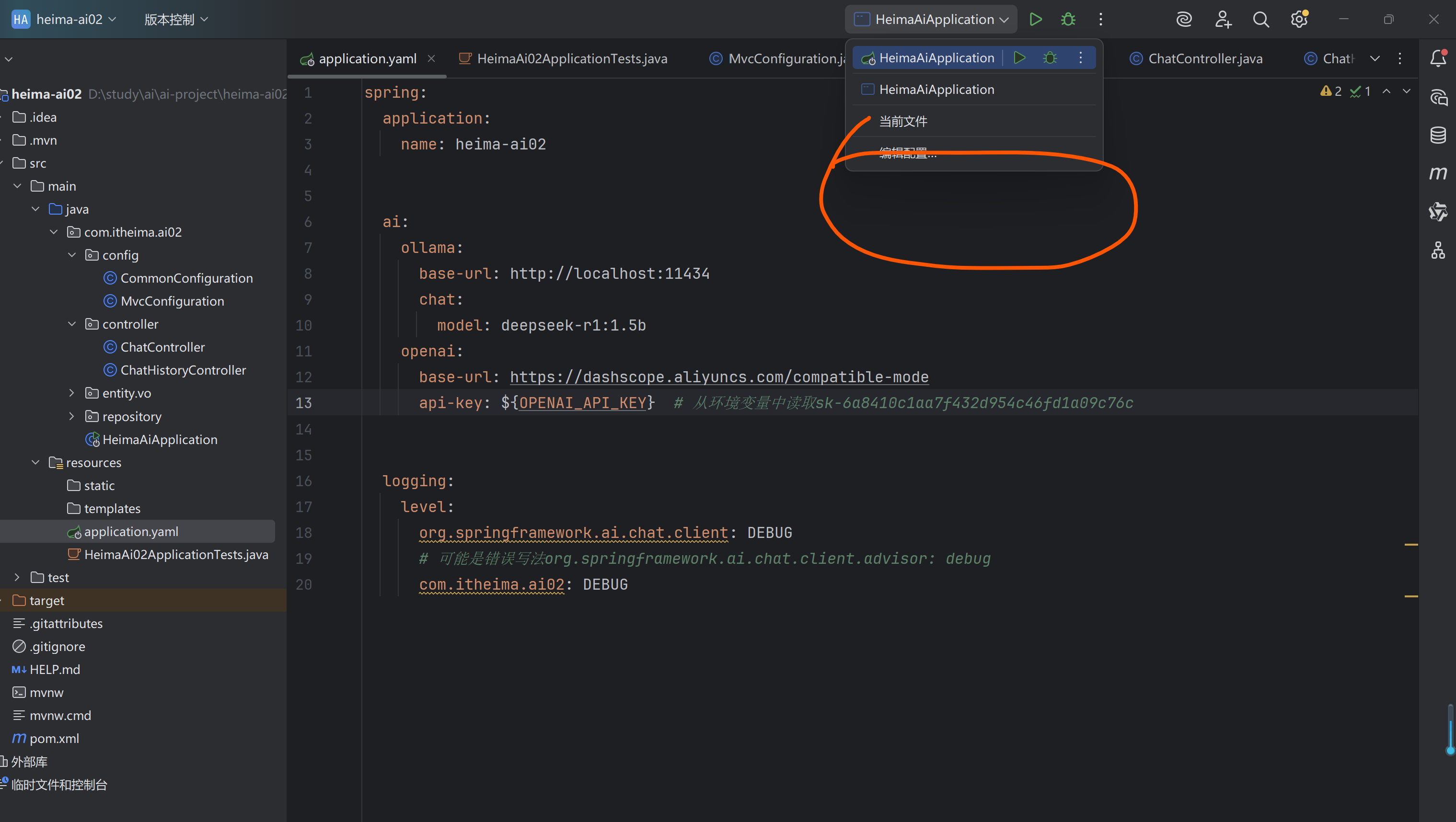
2.项目heima-ai02
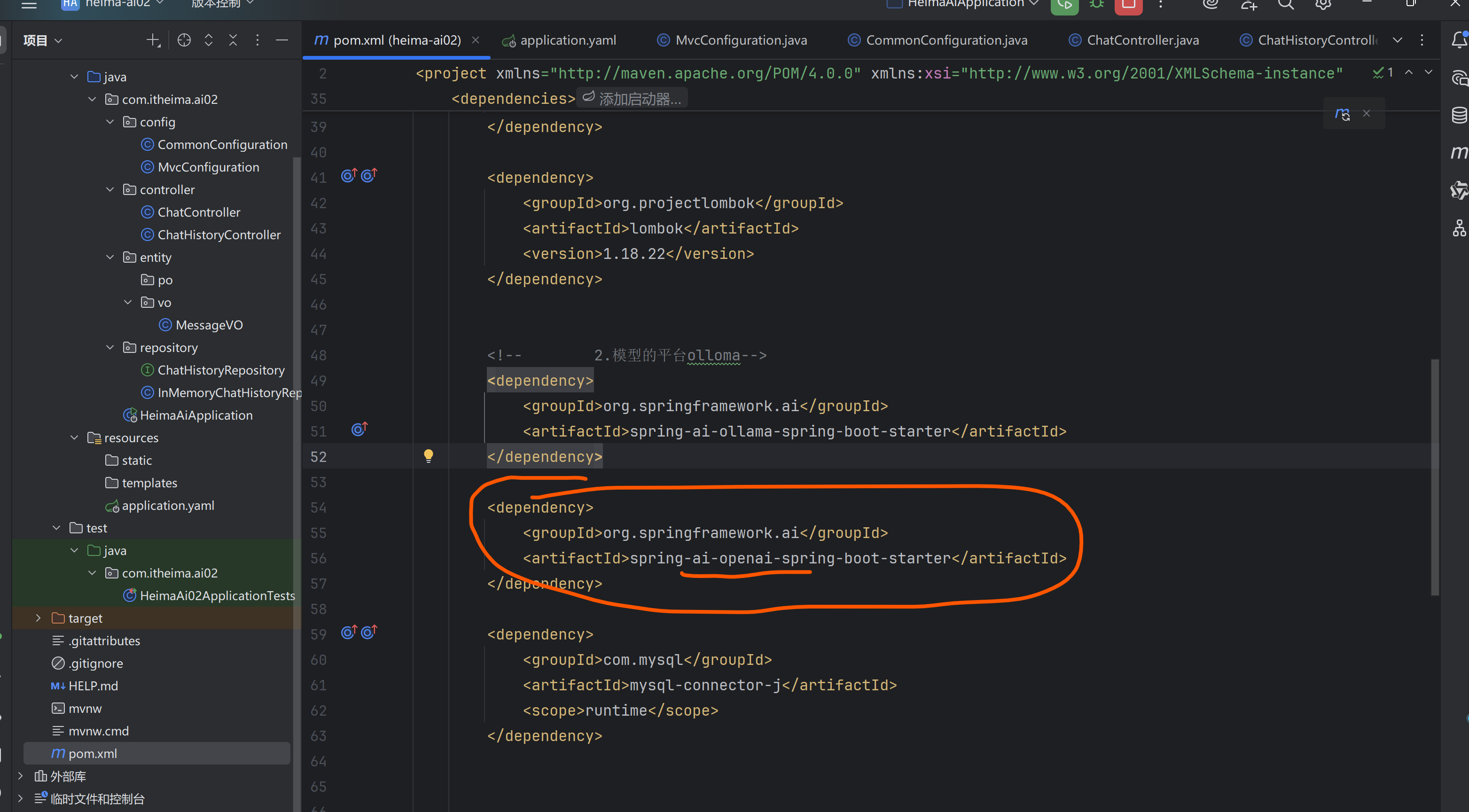
①创建新项目,引入依赖项Web 【Spring Web用于跟前端对接】,SQL 【MySQL Driver】,AI 【Ollama这里有SpringBoot版本兼容问题,改变它的版本就行了】
②配置application.yaml
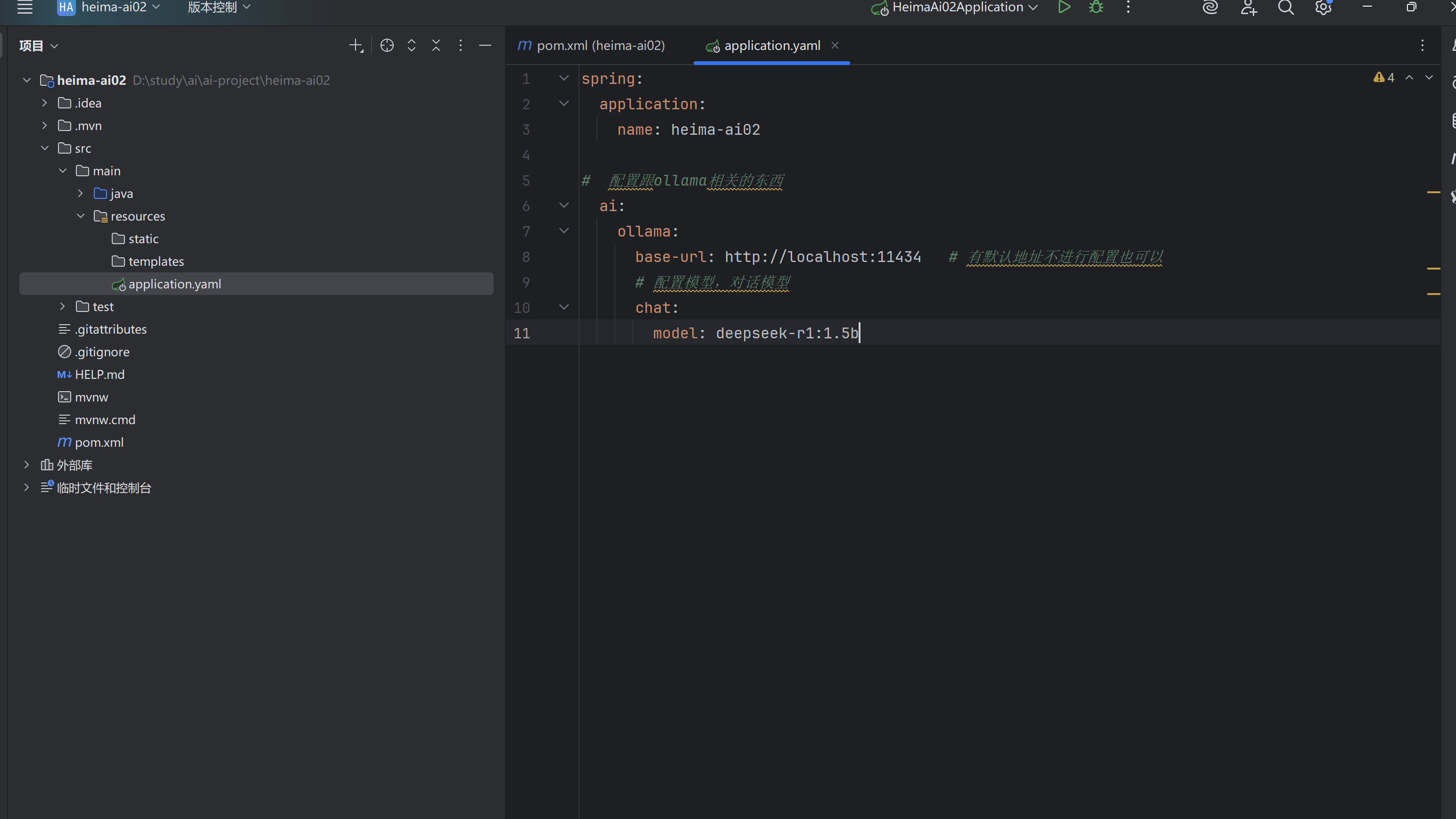
③配置客户端
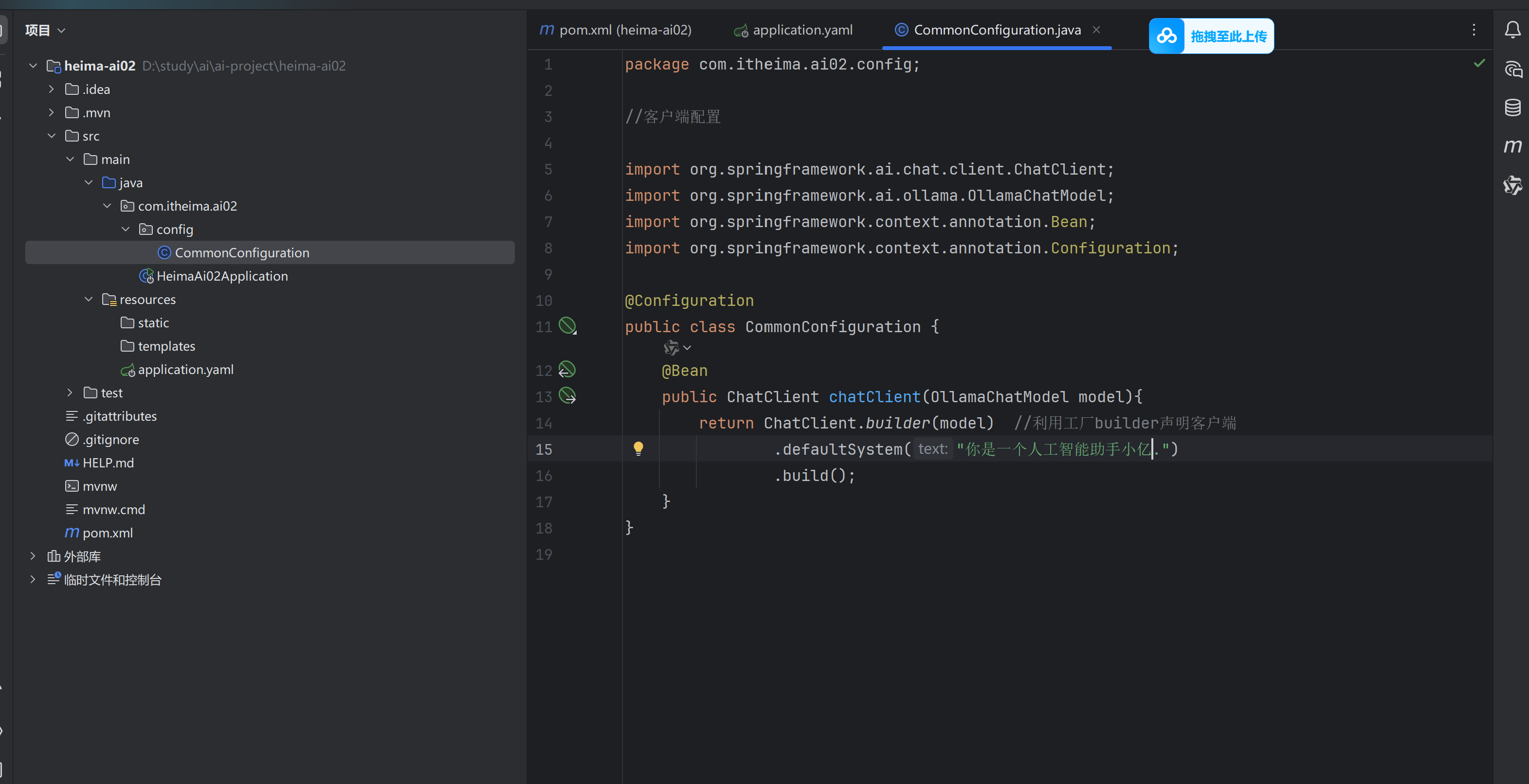
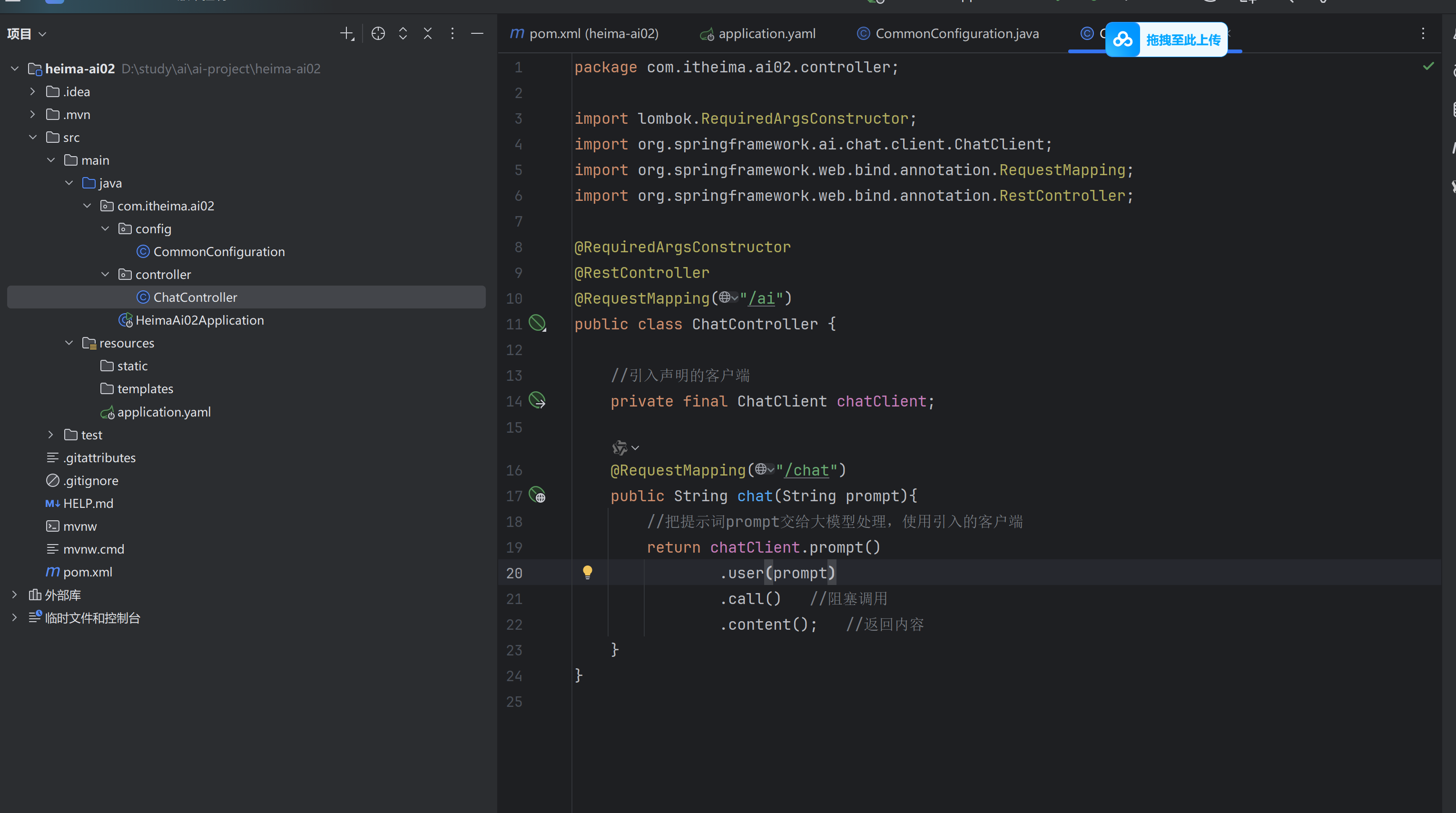
④接下来就可以进行模型对话
这里不进行单元测试对话,直接应用controller进行与前端的对话。
❗️如果出现这种情况
看ollama是否启动:ollama run deepseek-r1:1.5b
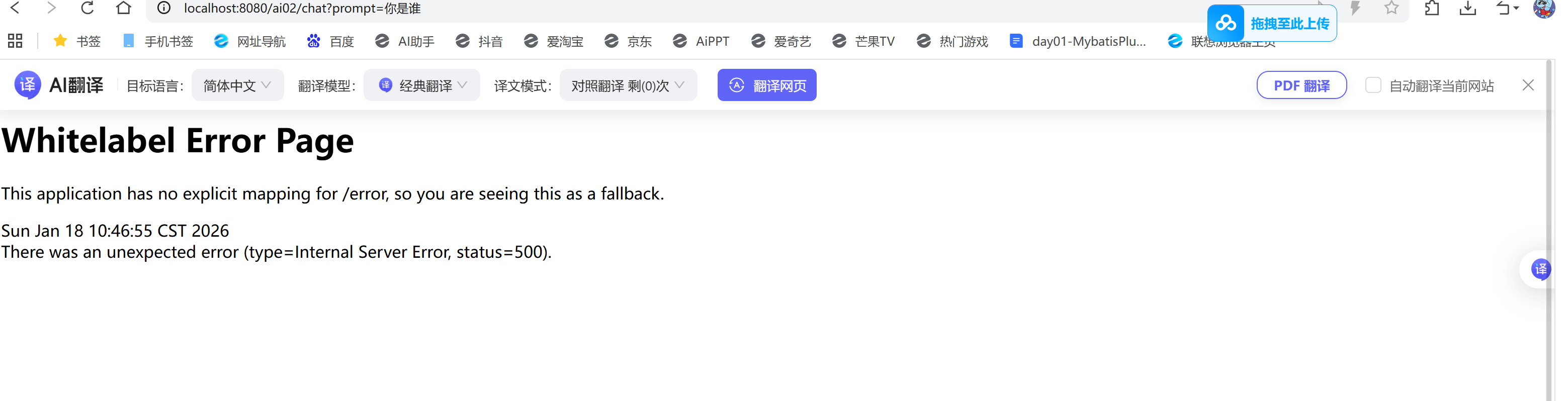
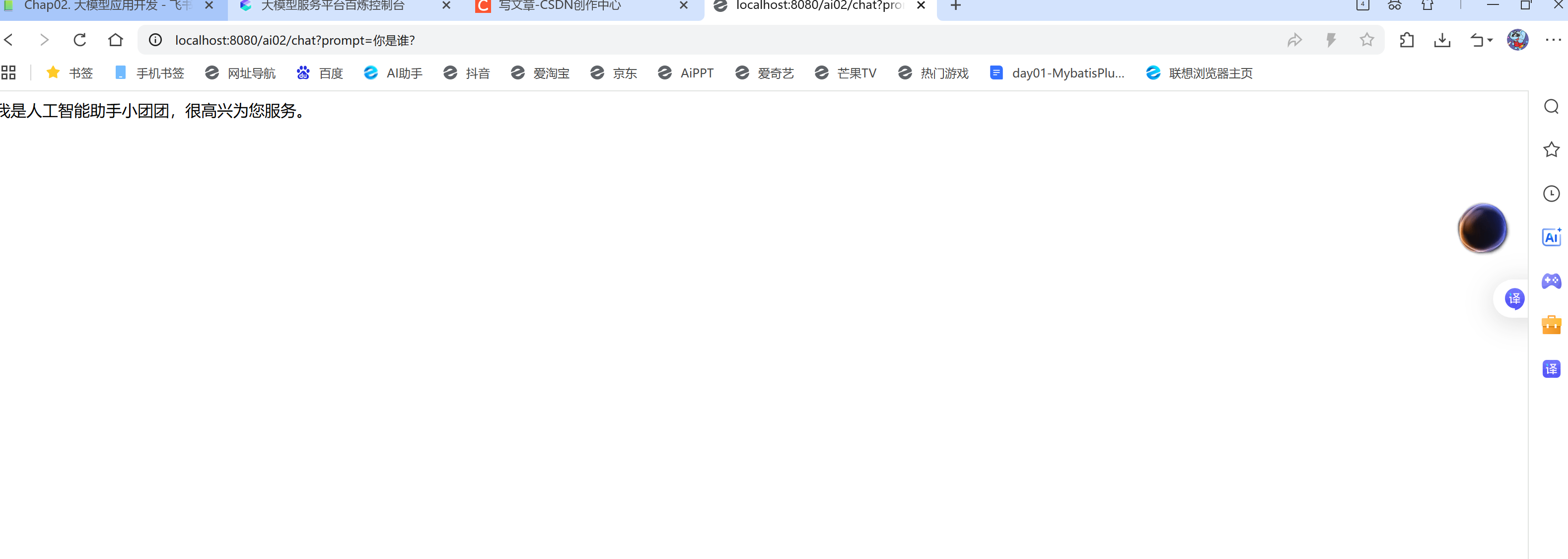
⑤前端测试:localhost:8080/ai02/chat?prompt=你是谁?(多刷新几遍)
二,会话日志

通过环绕通知实现日志功能advisor
SpringAI利用APO原理提供了会话的拦截,增强功能,也就是Advisor。
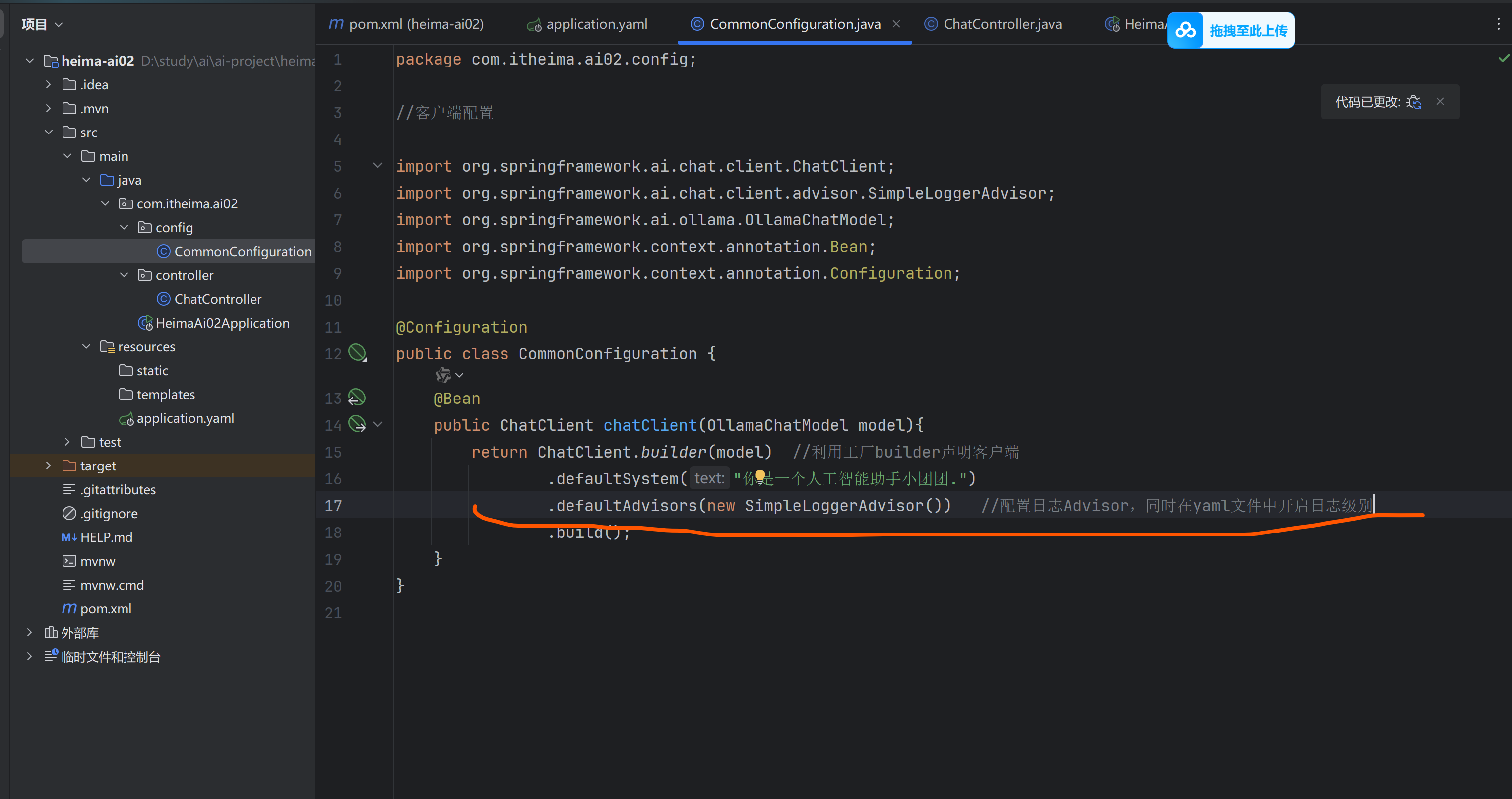
实现日志:用SimpleLoggerAdvisor的环绕通知实现
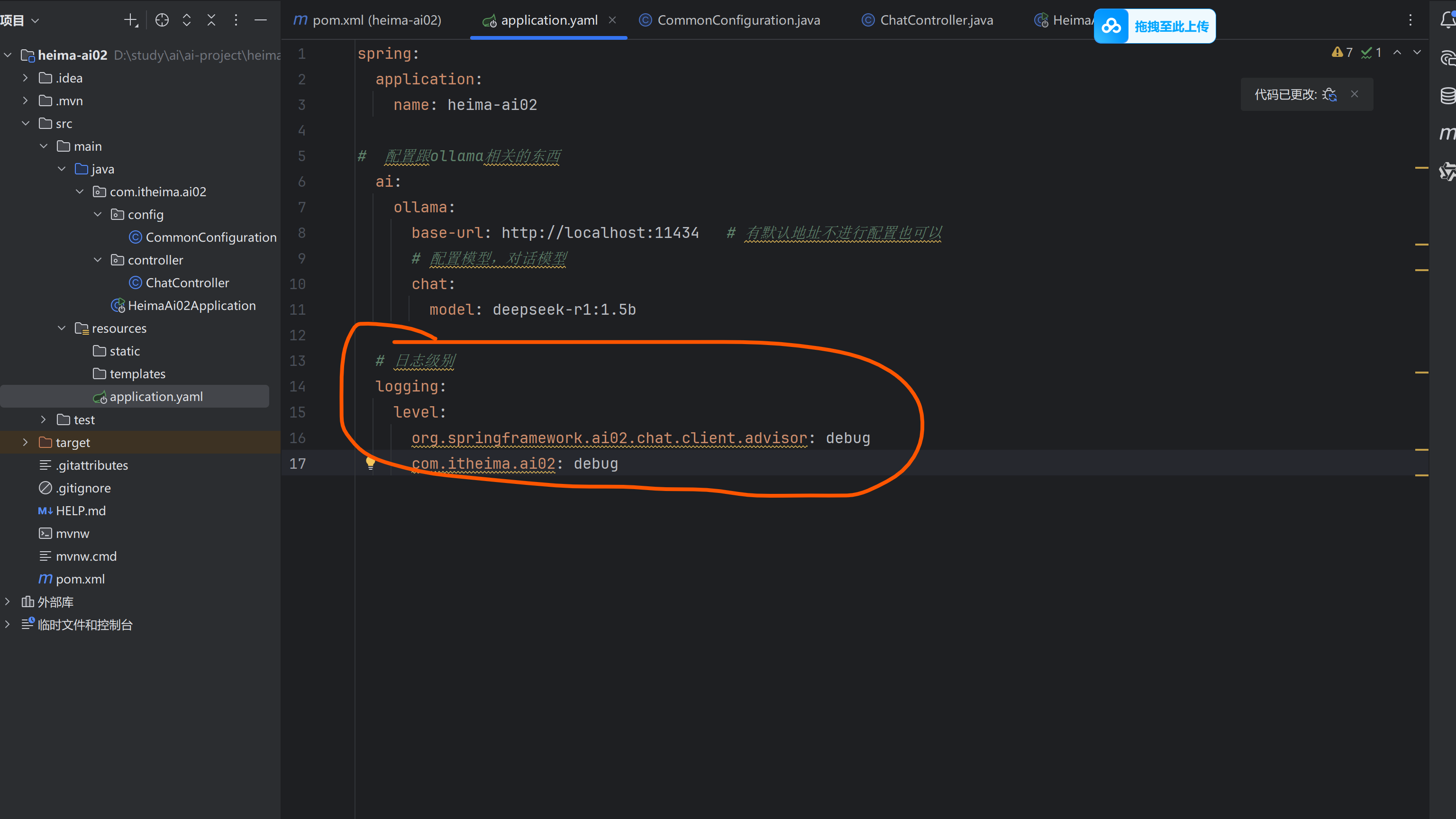
这里我的日志并没有显示。原因未知
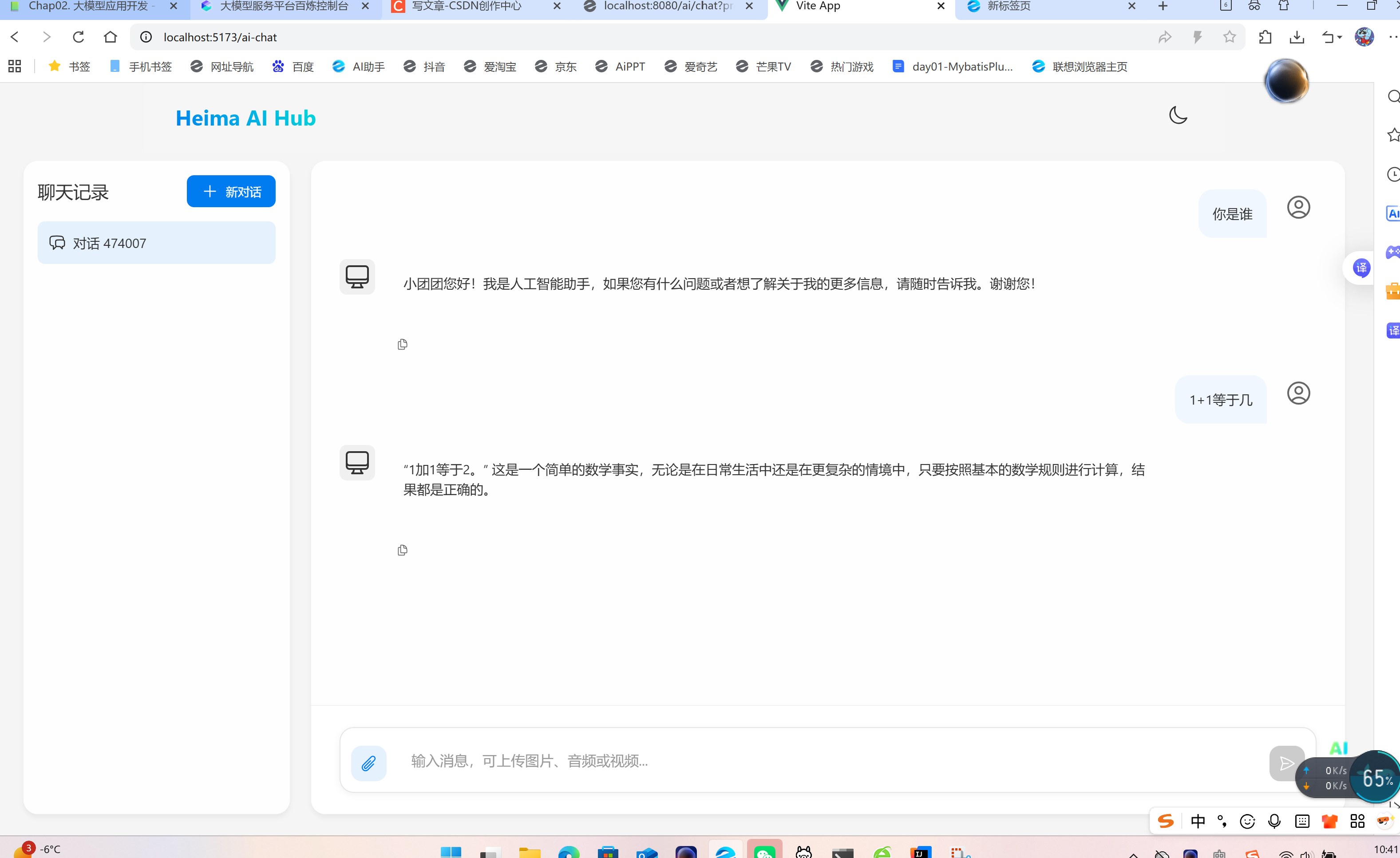
三,对接前端
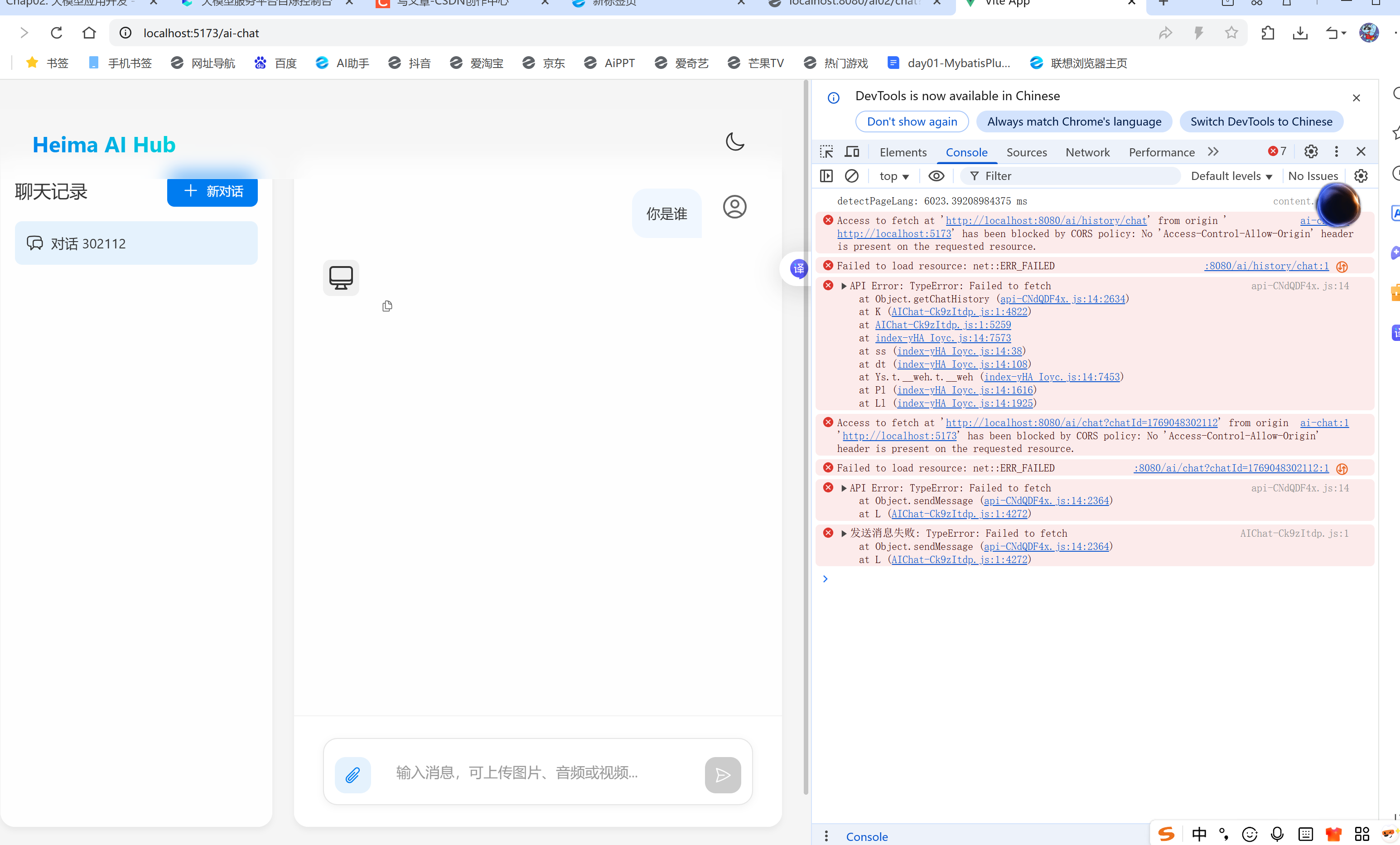
前端文件,利用nginx打开页面localhost:5173
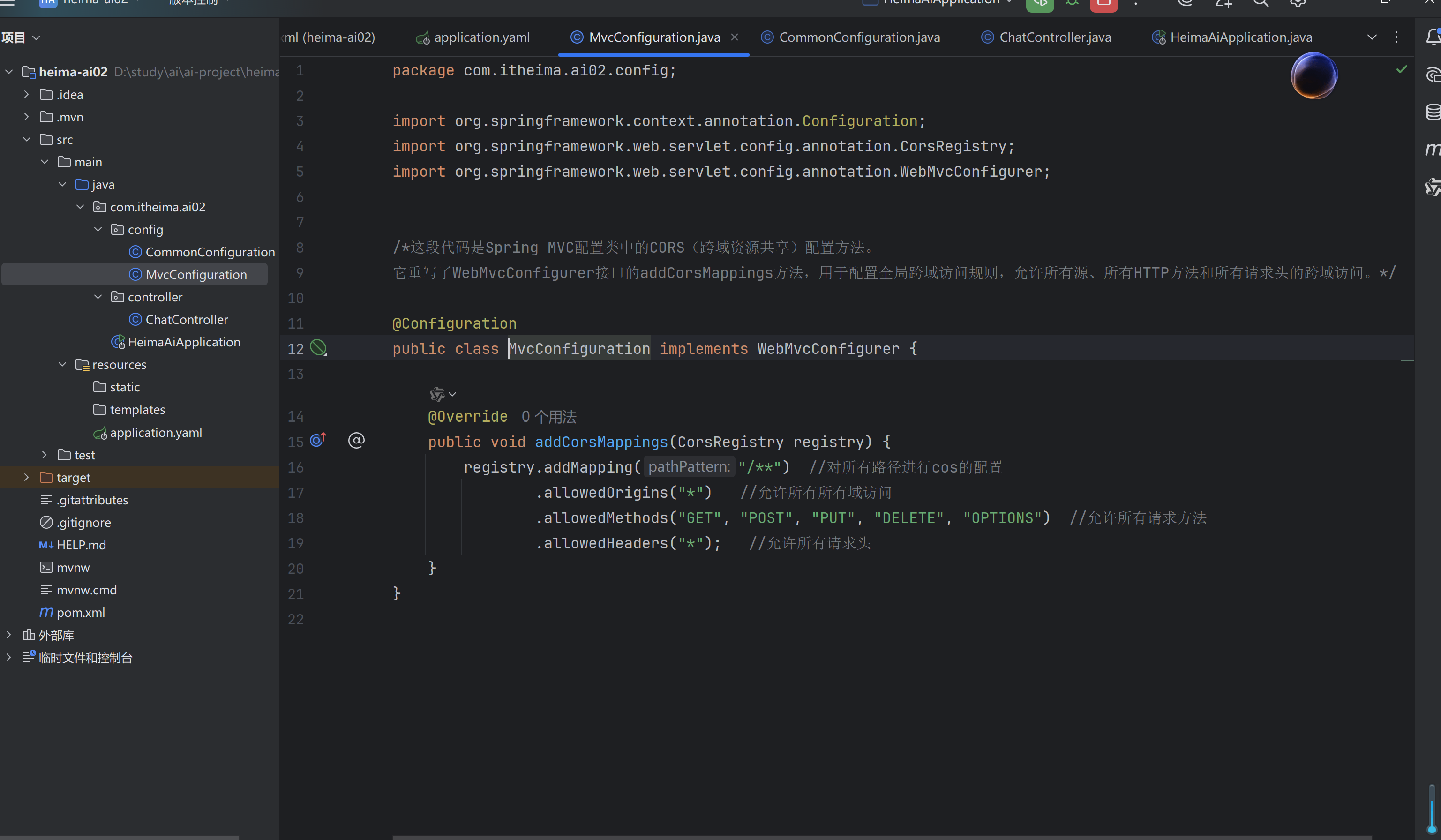
解决端口跨域问题:SpringMVC,进行config配置

之后进行会话
四,会话记忆功能
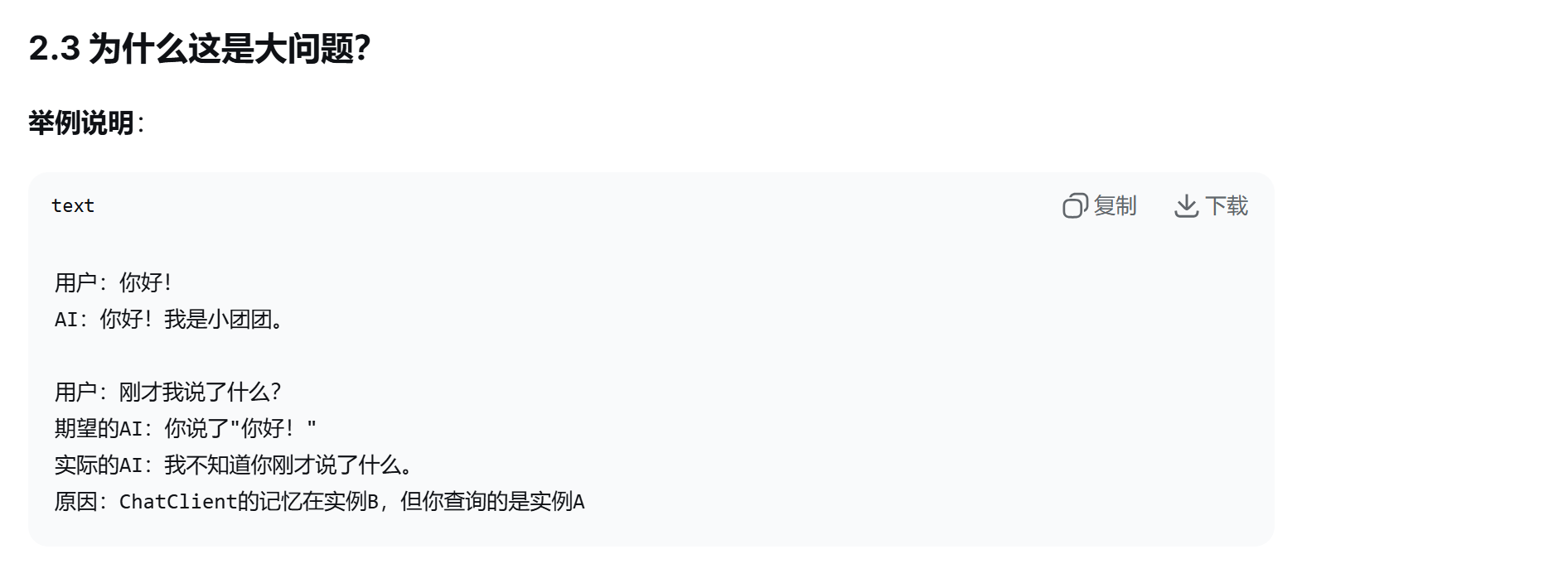
大模型本身没有记忆,需要自己写代码实现,把之前的聊天内容跟最新的提示词一起发给大模型。
与发送http请求到大模型有关,利用messages中的assistant

利用Advisor实现会话记忆
步骤
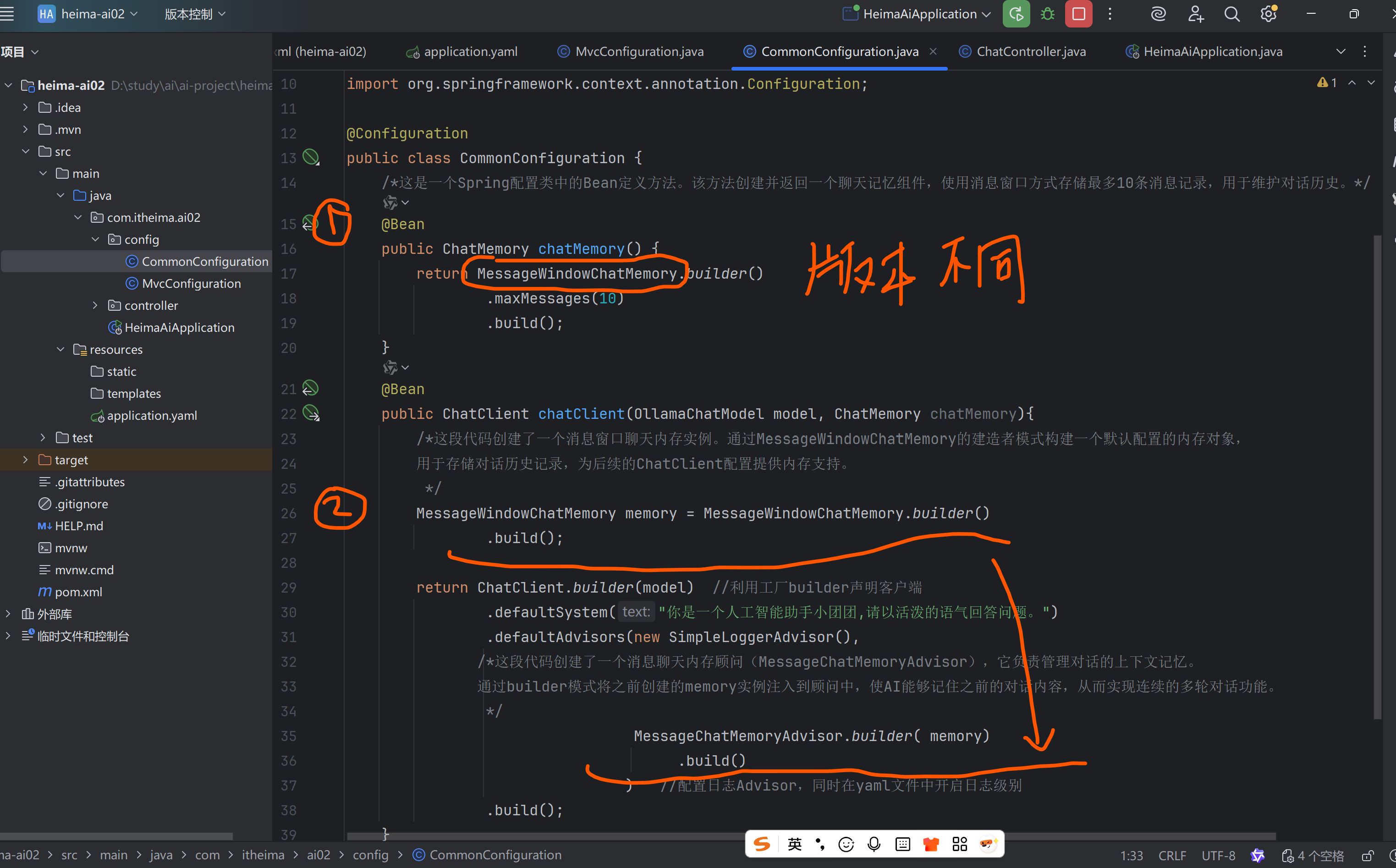
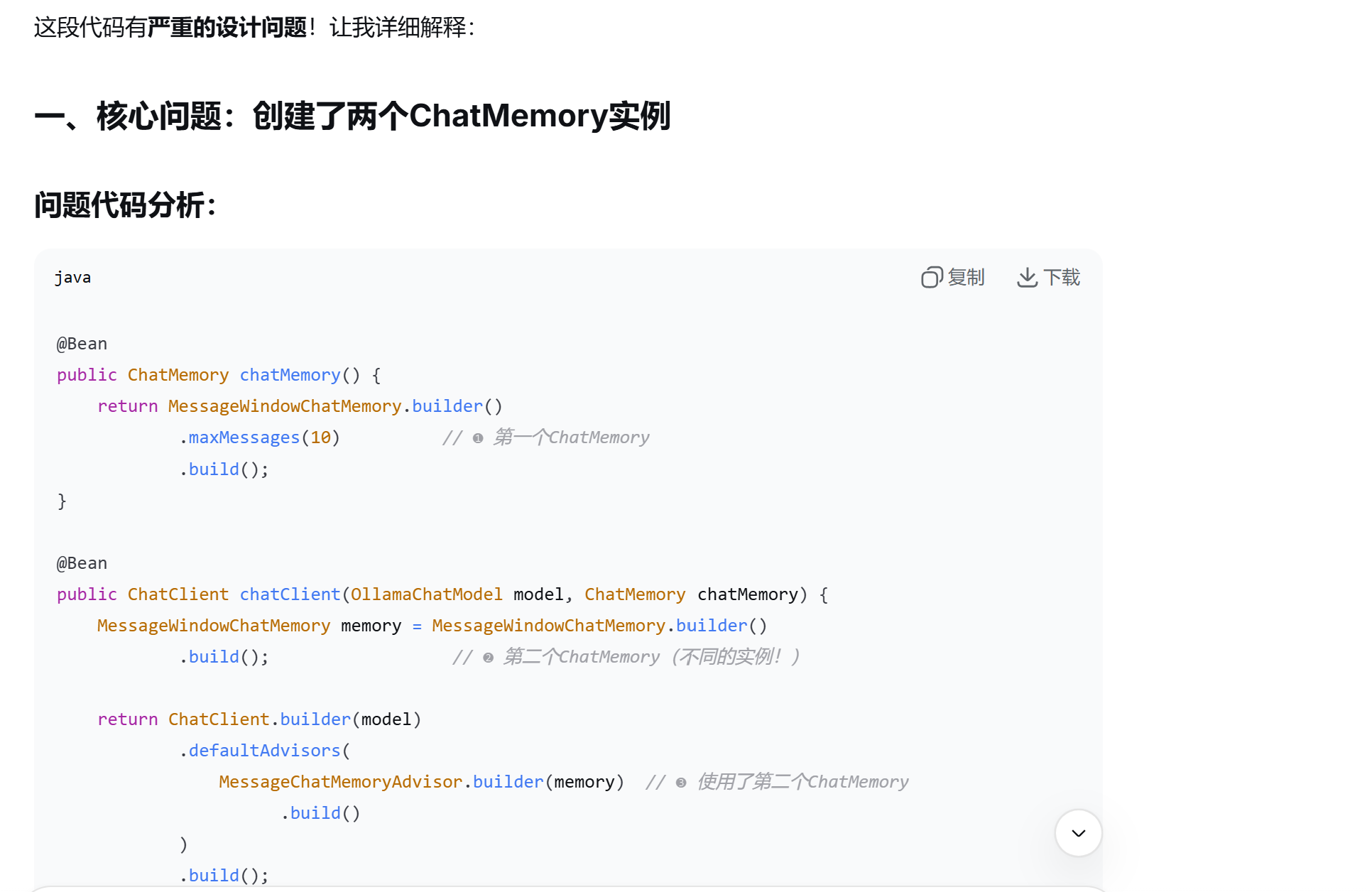
①定义会话存储的方式:
声明一个ChatMemory的Bean,创建ChatMemory的一个实现类对象
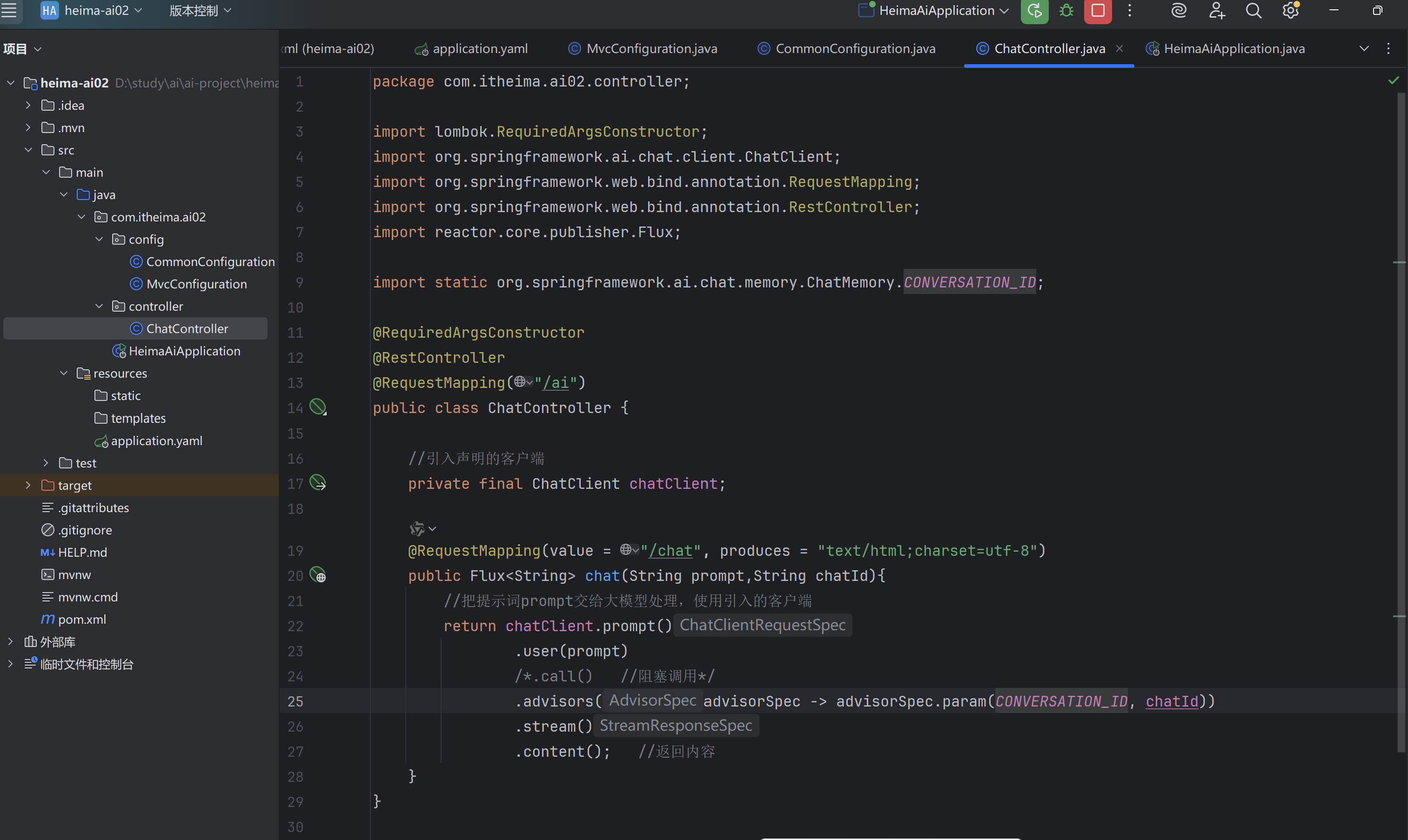
②配置会话记忆Advisor:拦截请求做会话记录,提示词拼接
将存储注入Advisor,然后在defaultAdvisor配置Advisor
这里做出修改:
修改:

③添加会话id:在发提示请求时操作,匿名环绕增强(添加会话id到上下文)
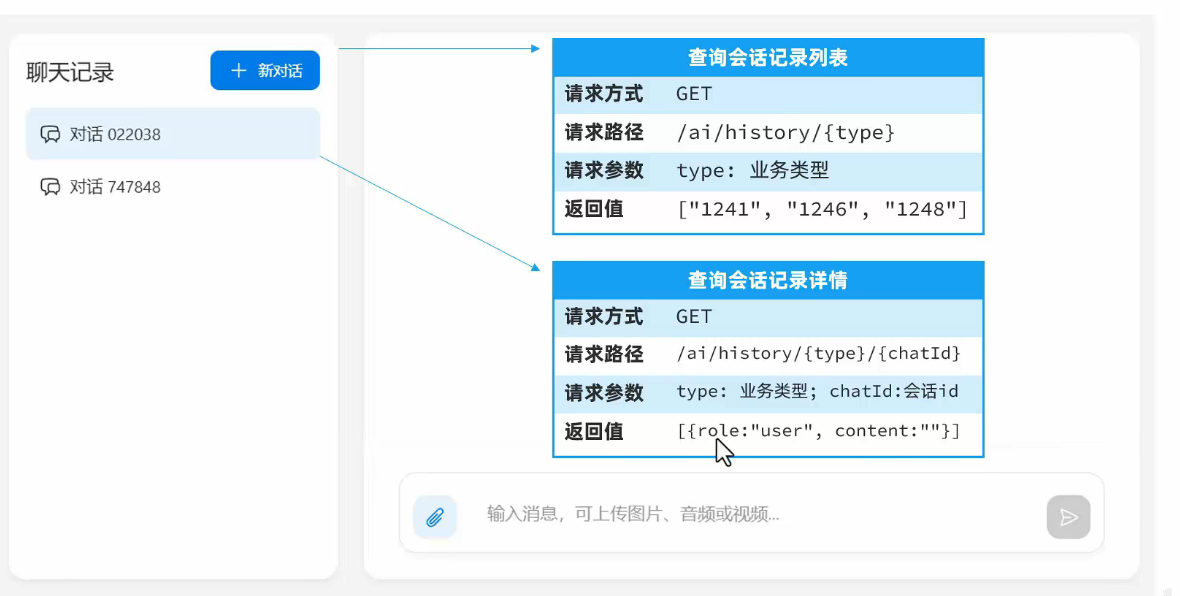
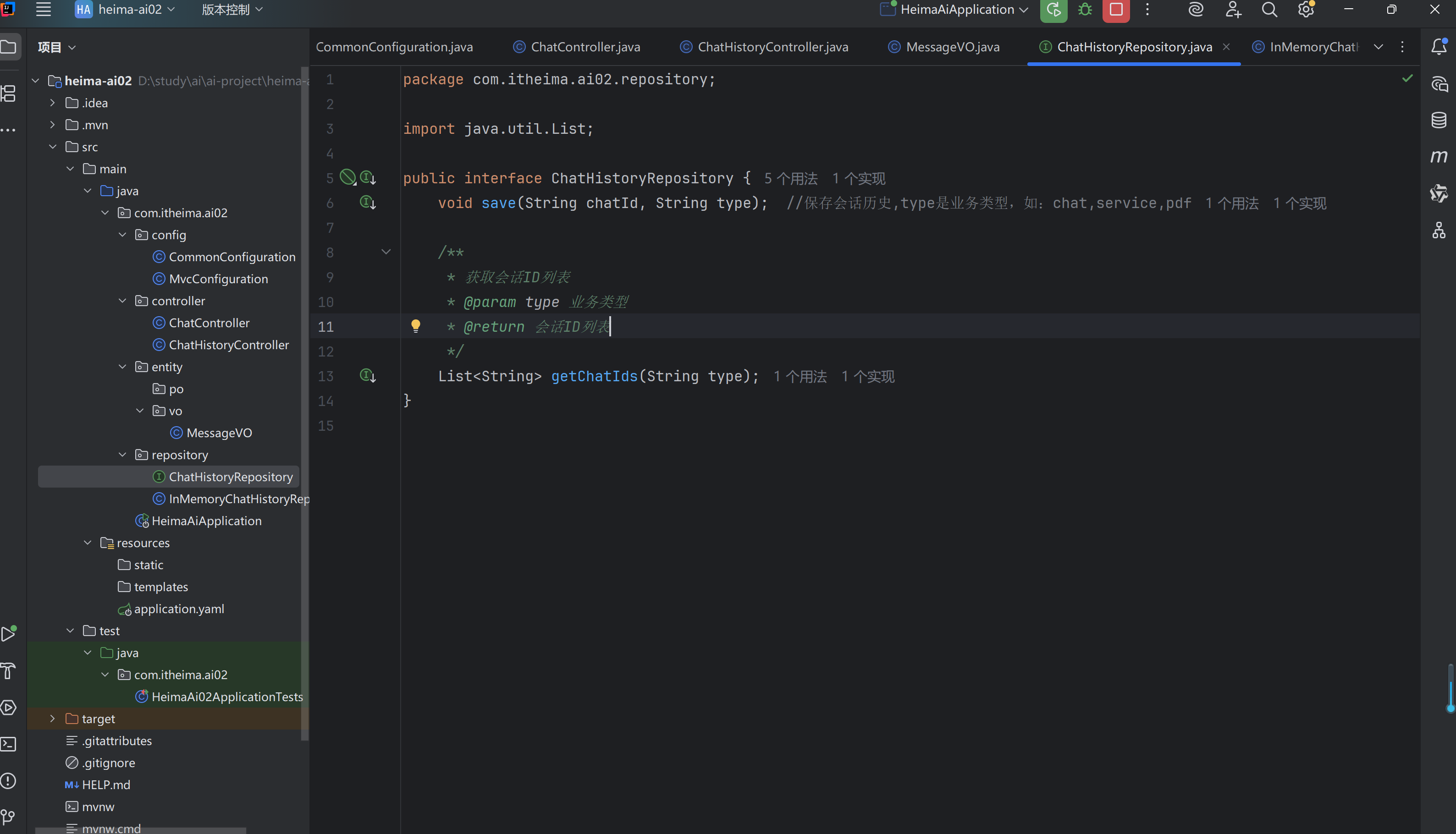
五,会话历史
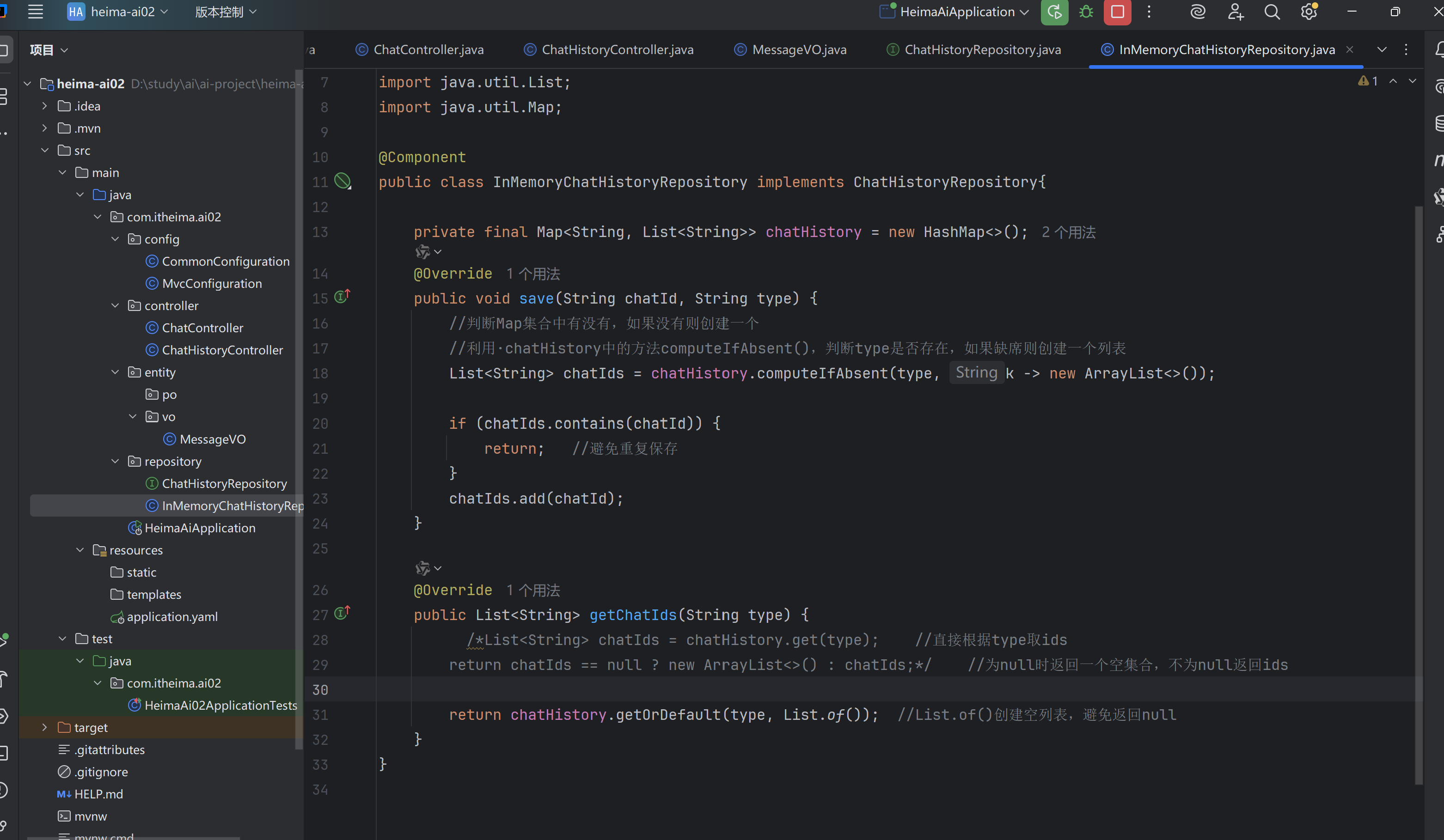
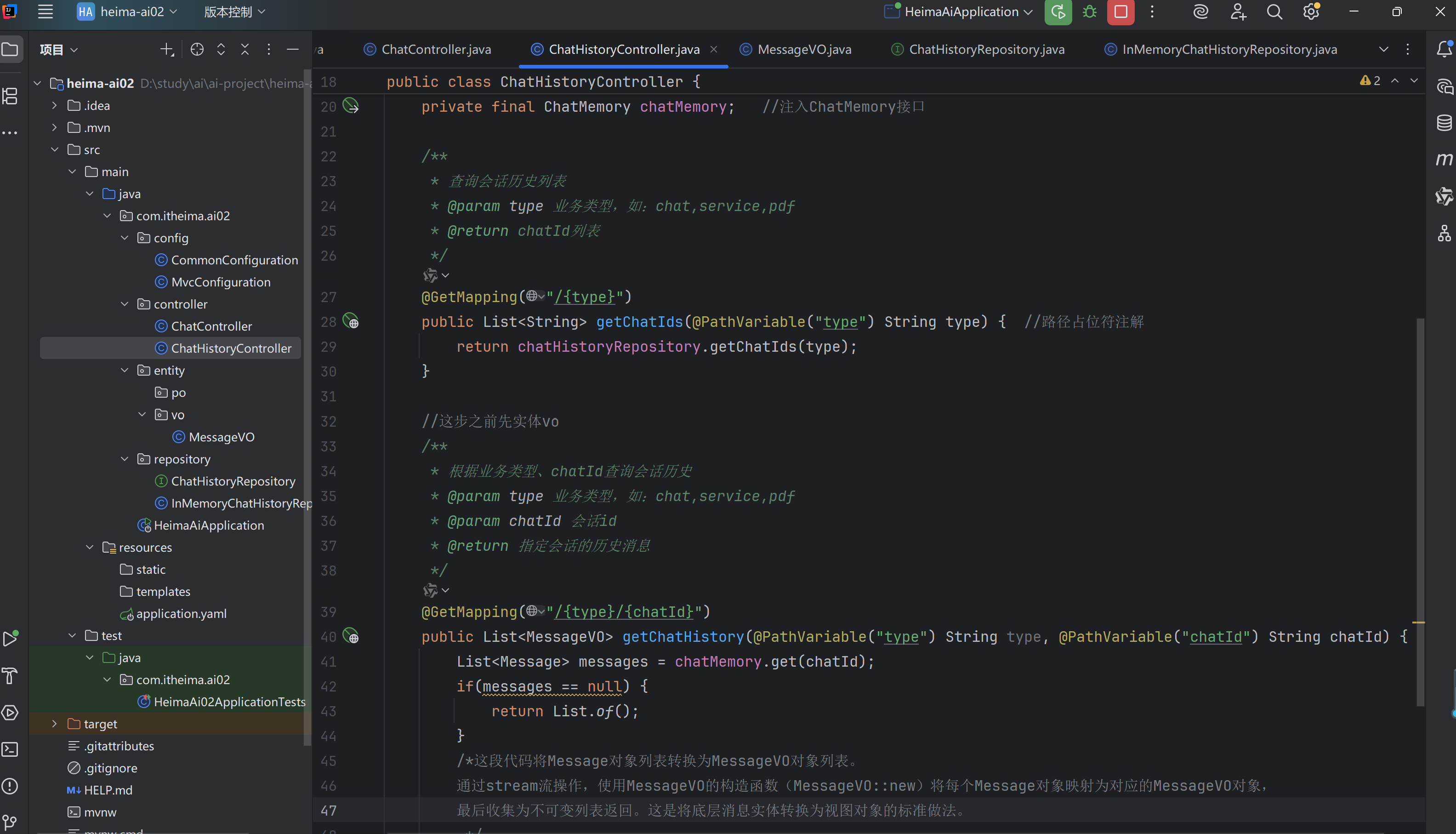
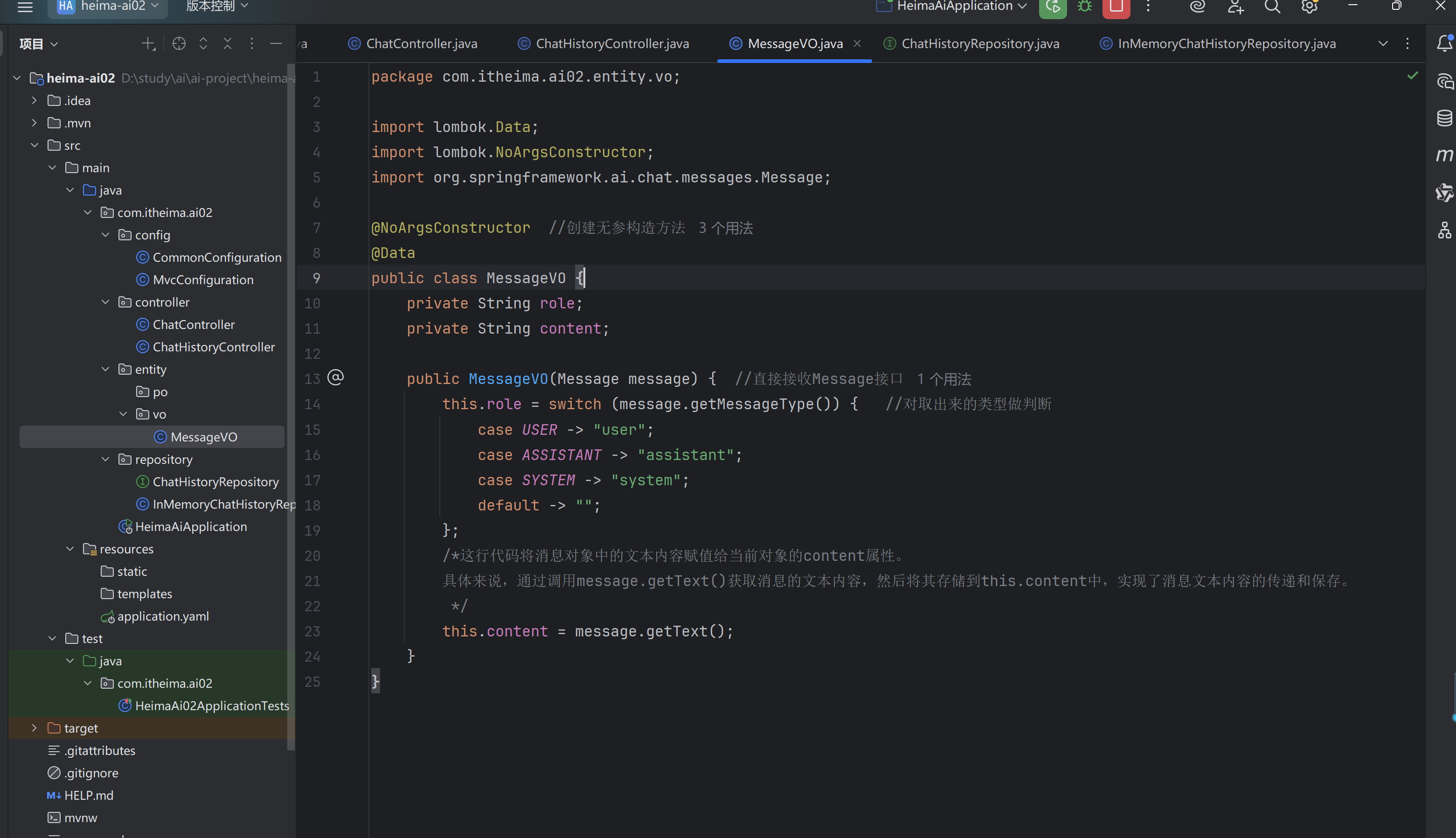
(二)哄哄模拟器
一,提示词工程
提示词工程:通过优化提示词,使大模型尽量生成理想内容。
1.清晰明确的指令
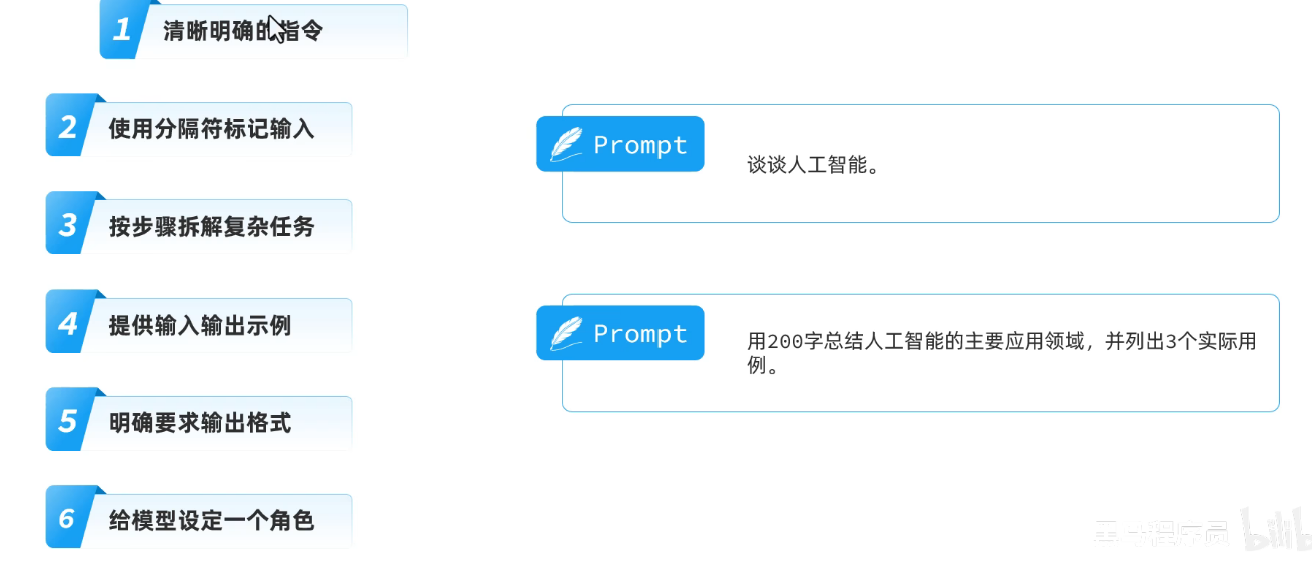
2.使用分隔符标记输入

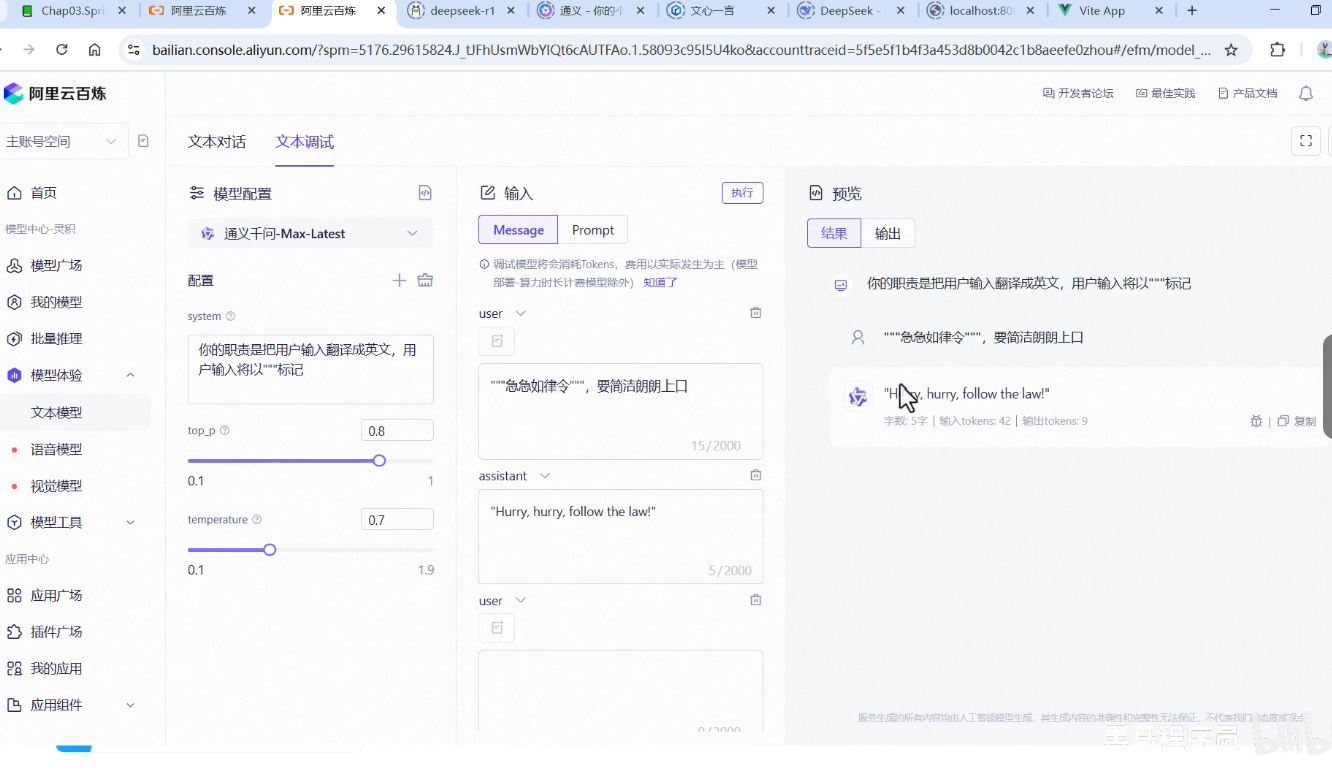
3.按步骤拆解复杂指令
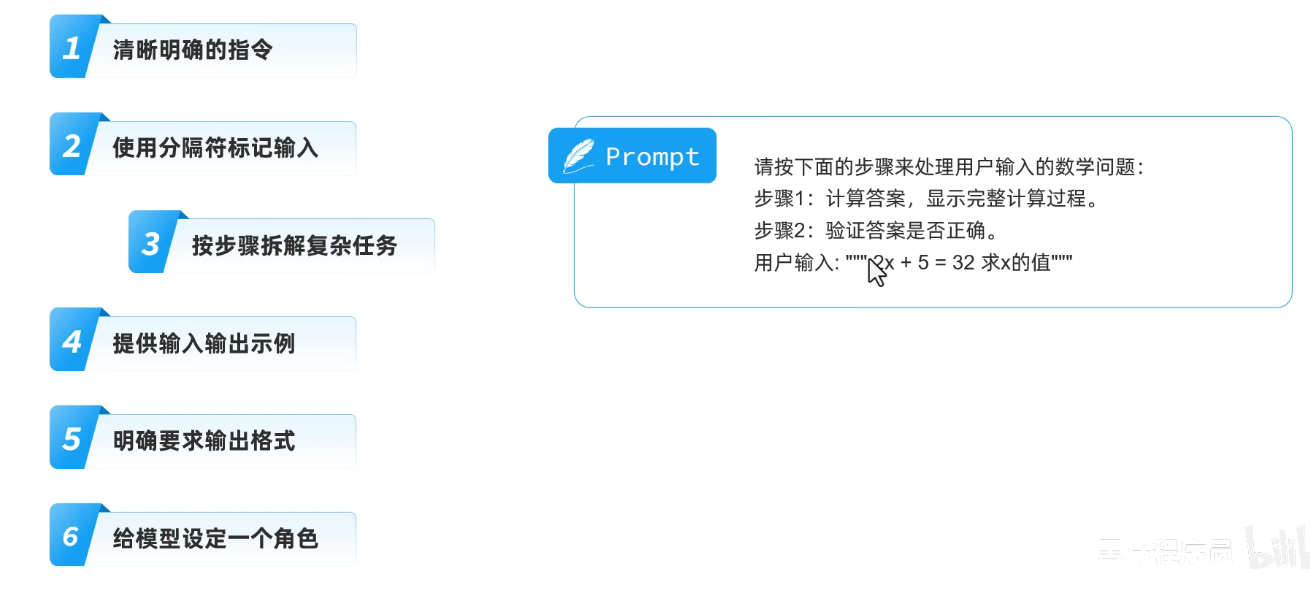
4.提供输入输出事例
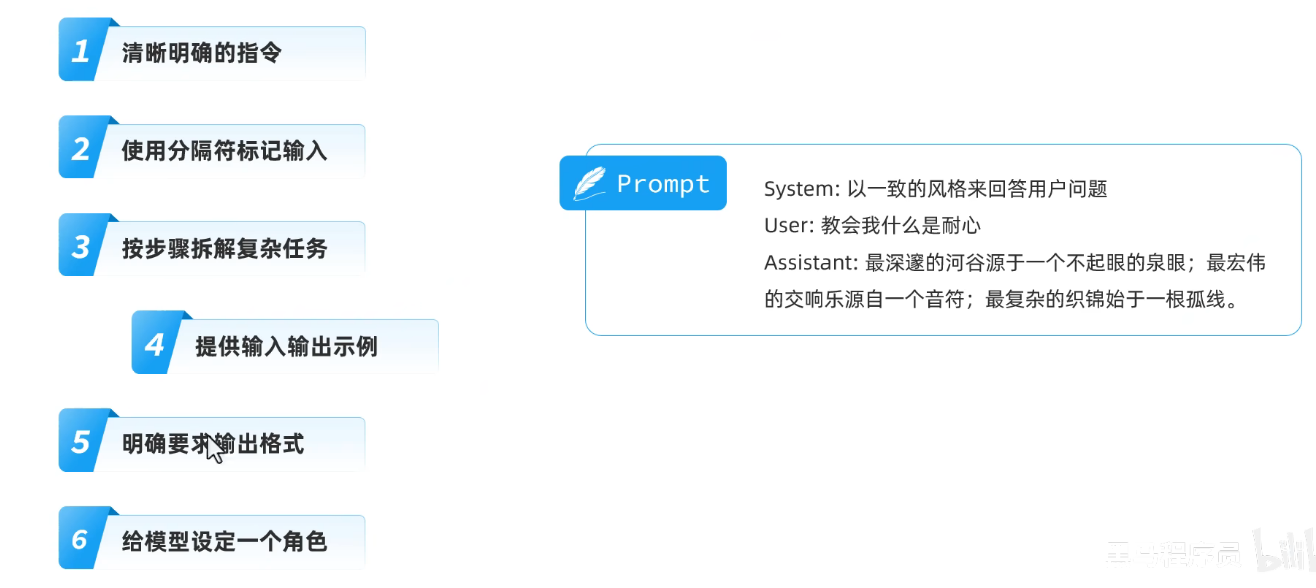
5.明确要求输出格式
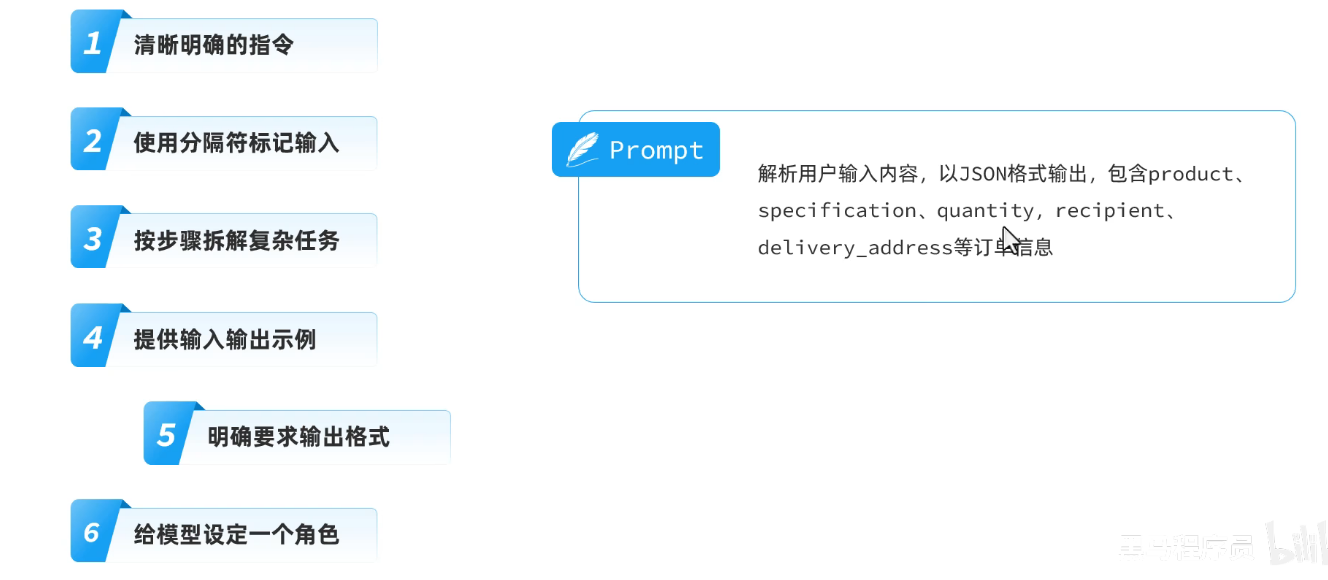
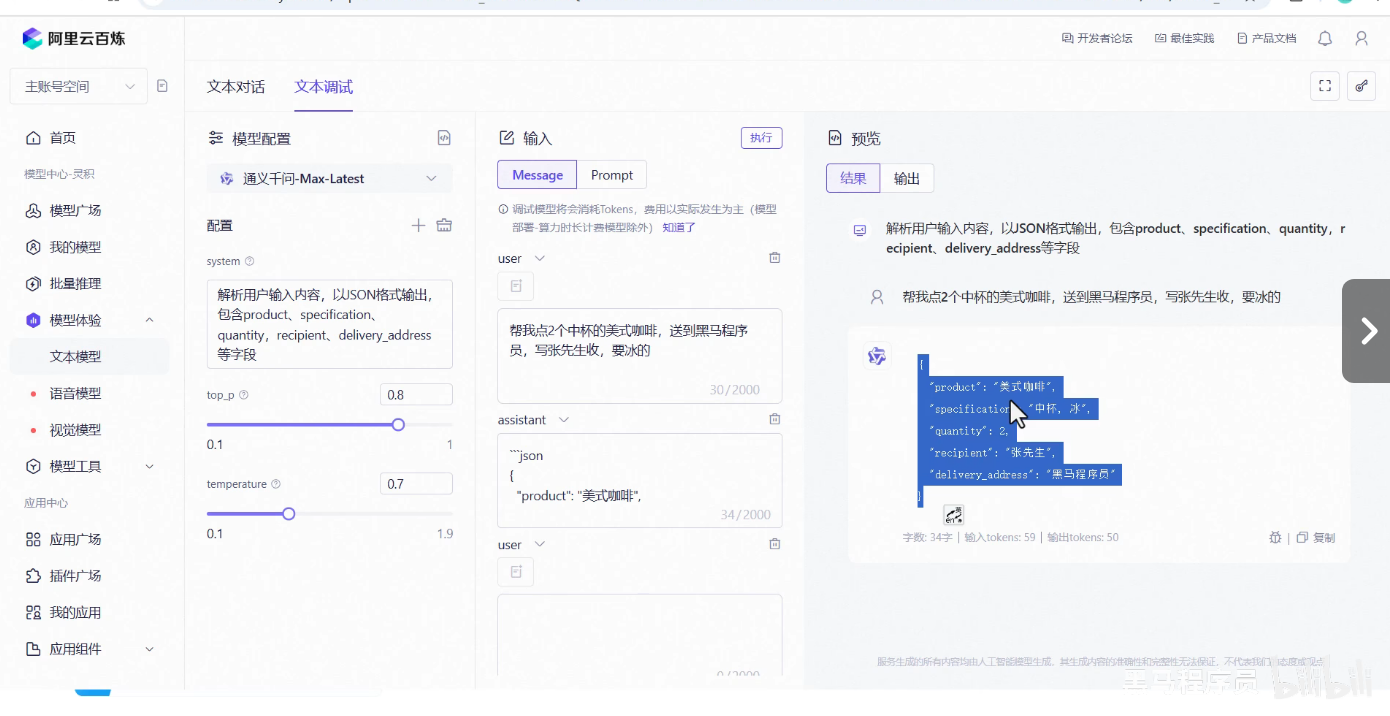
6.给模型设定一个角色
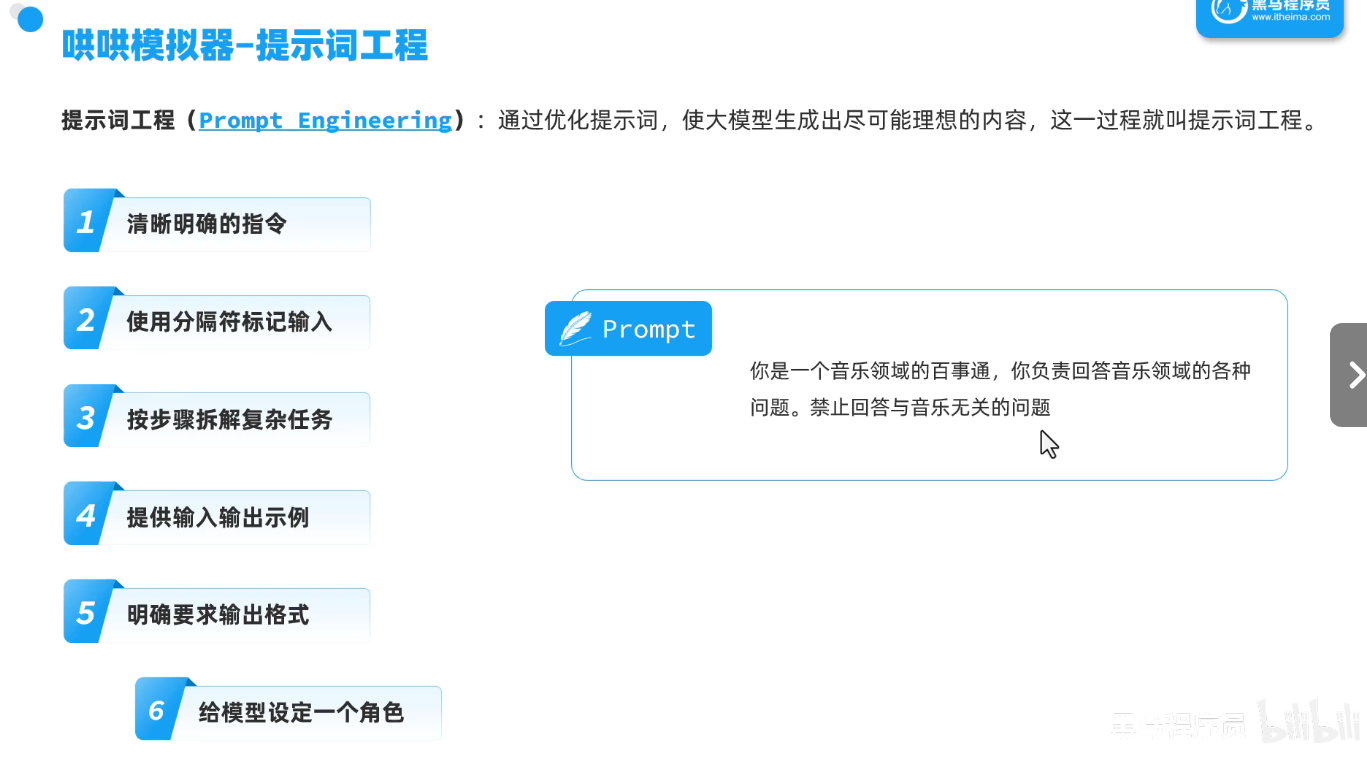
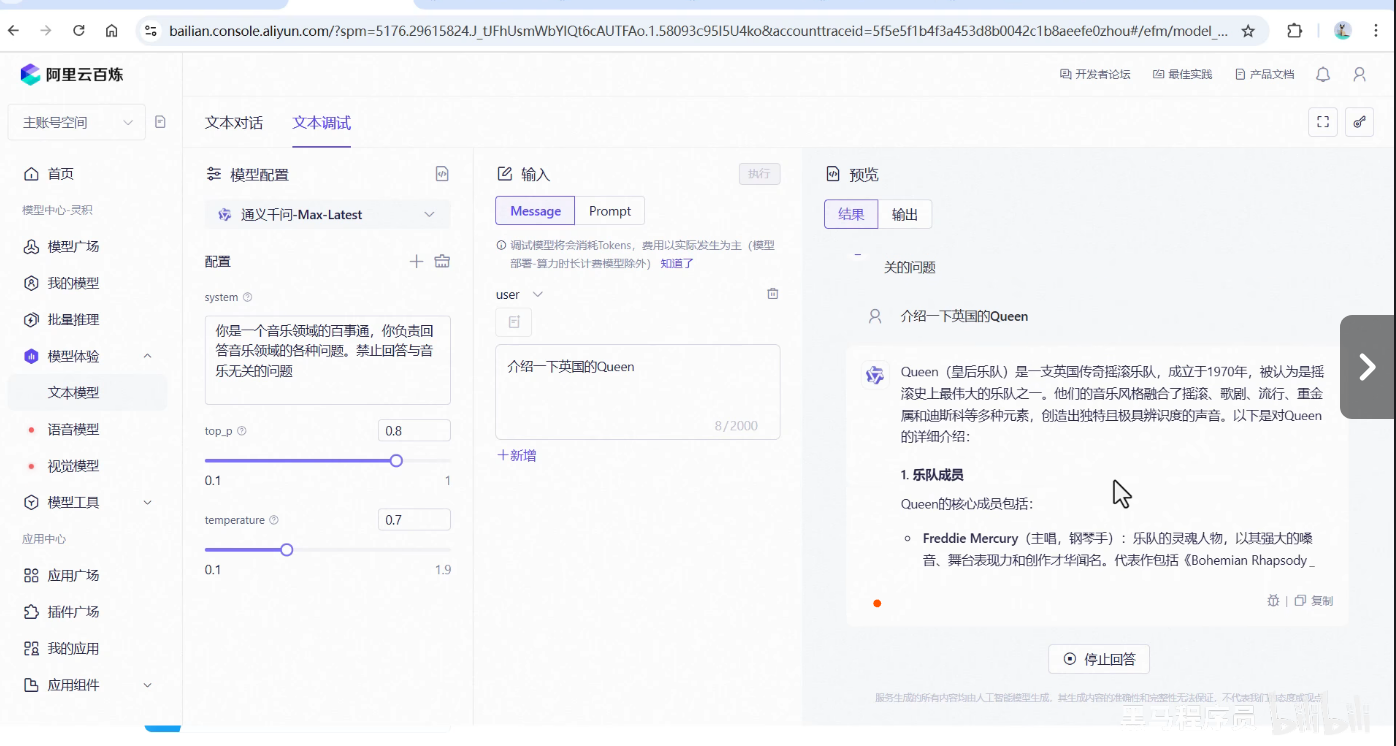
二,代码实现
1.引入依赖(使用openai)
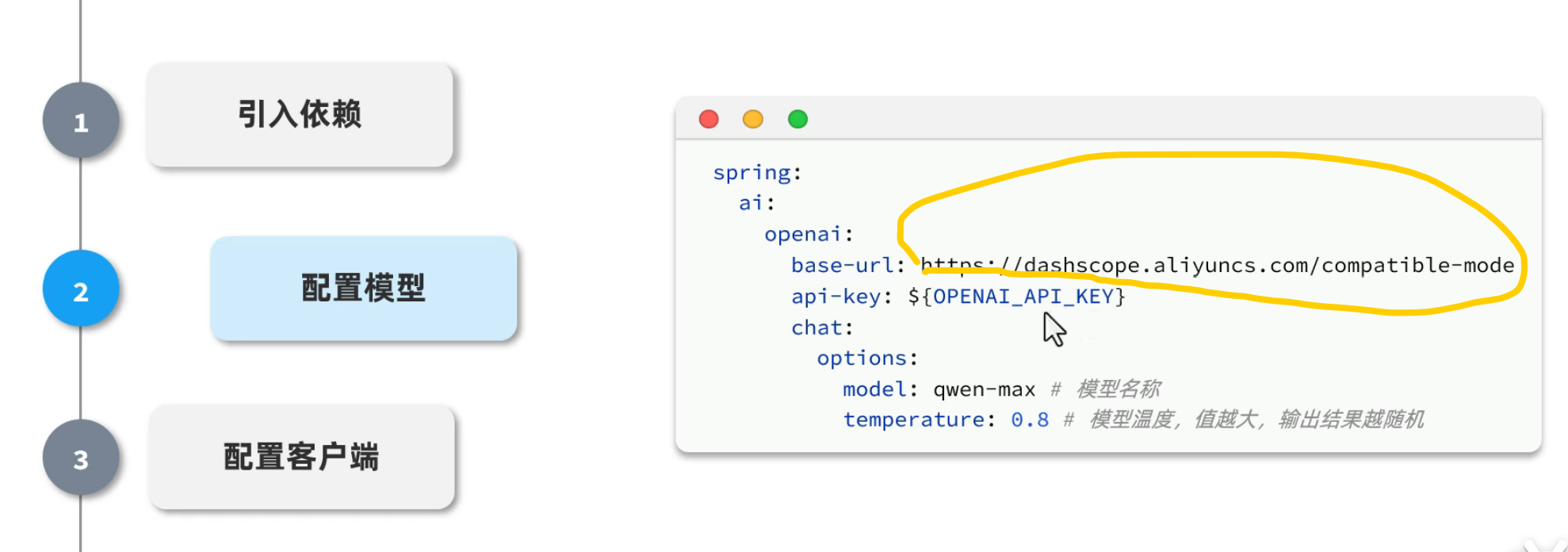
2.配置模型
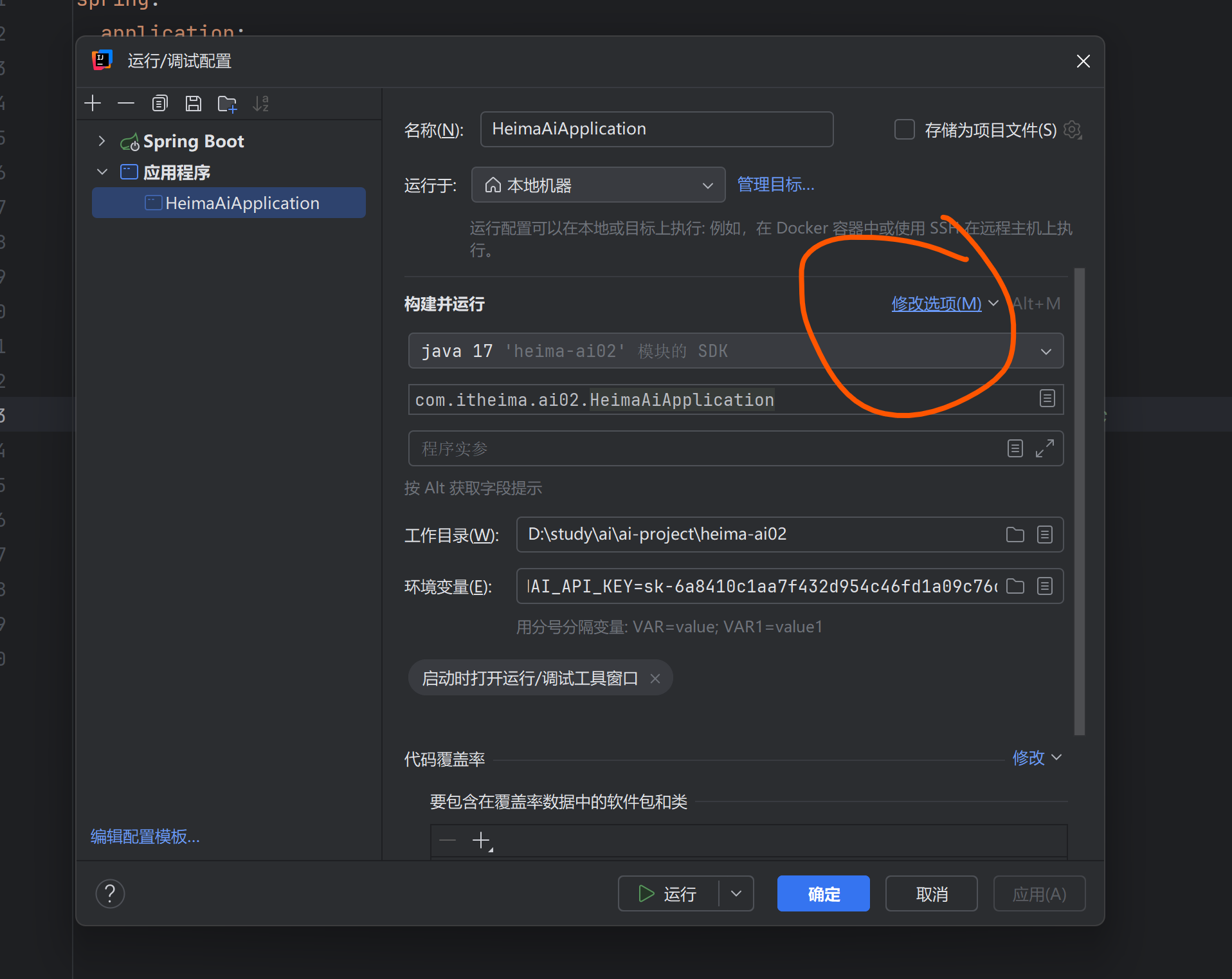
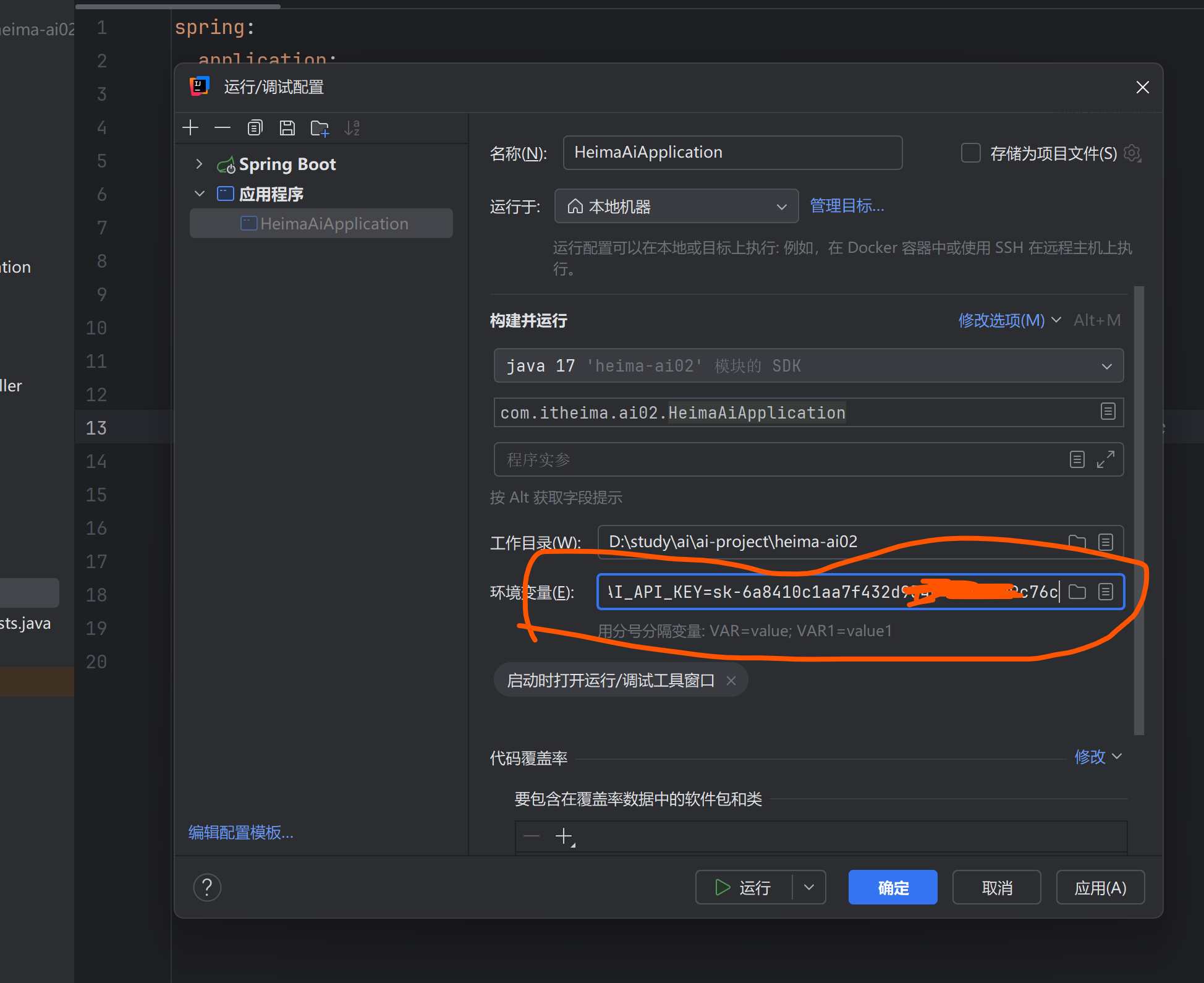
注意base-url填写
api-key到阿里云百炼平台找到自己的key填写
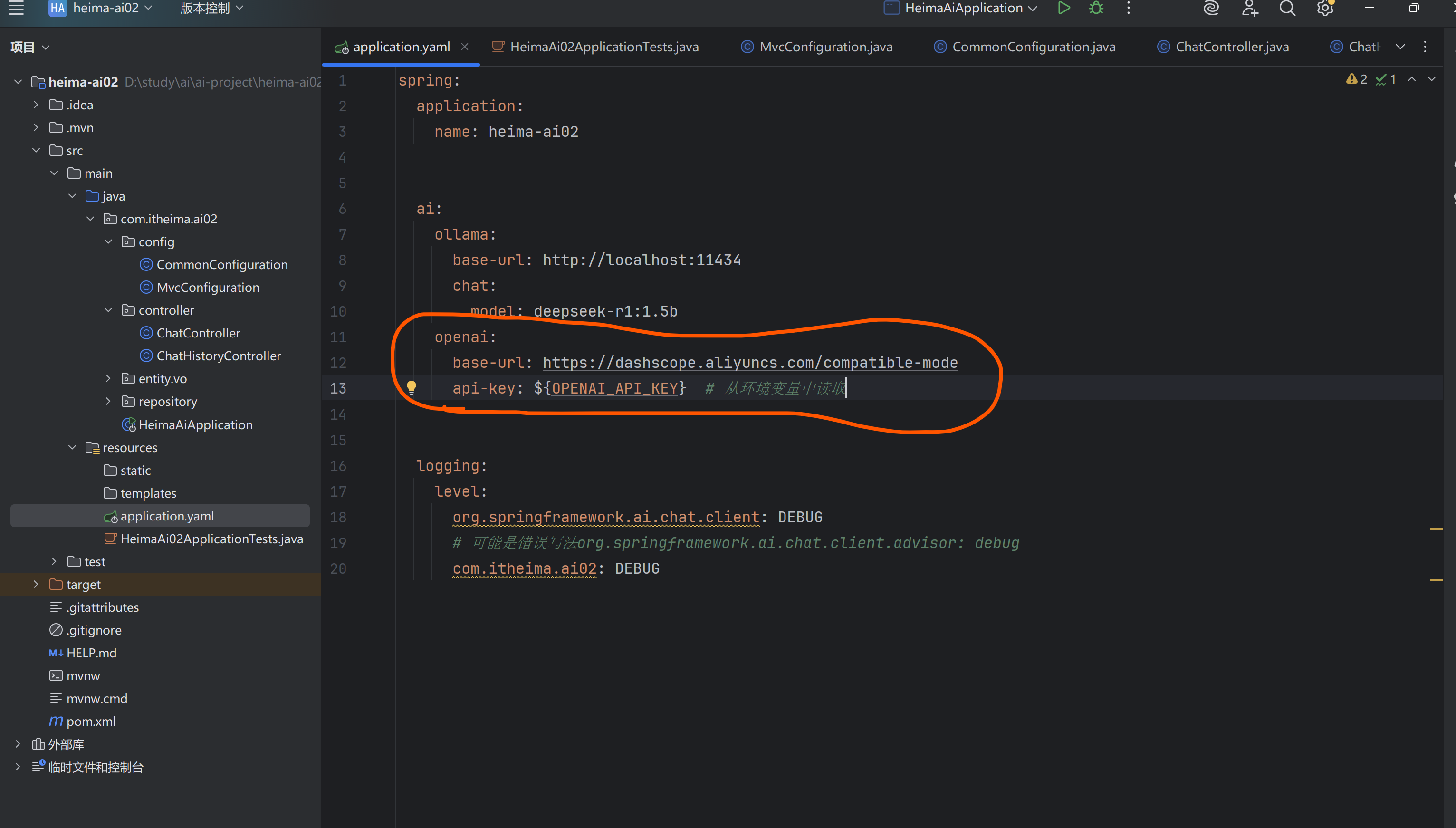
环境变量
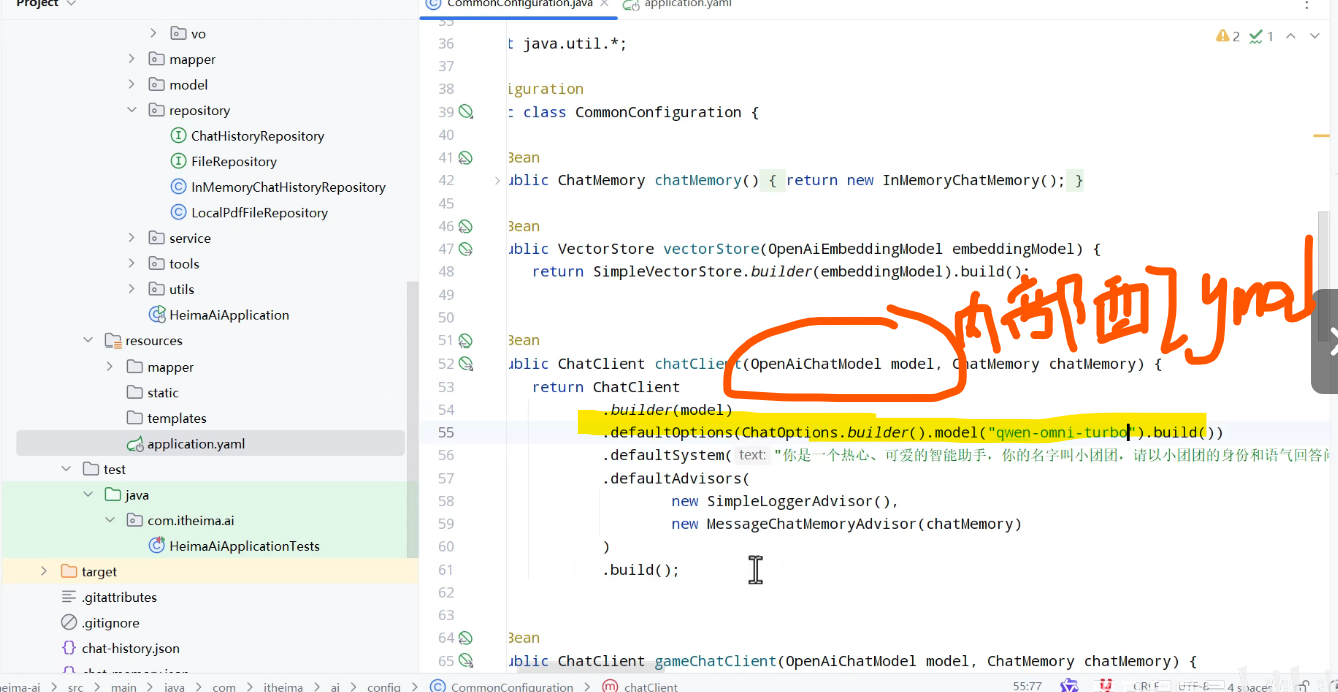
3.配置客户端(CommonConfig)
用OpenAiChatModel
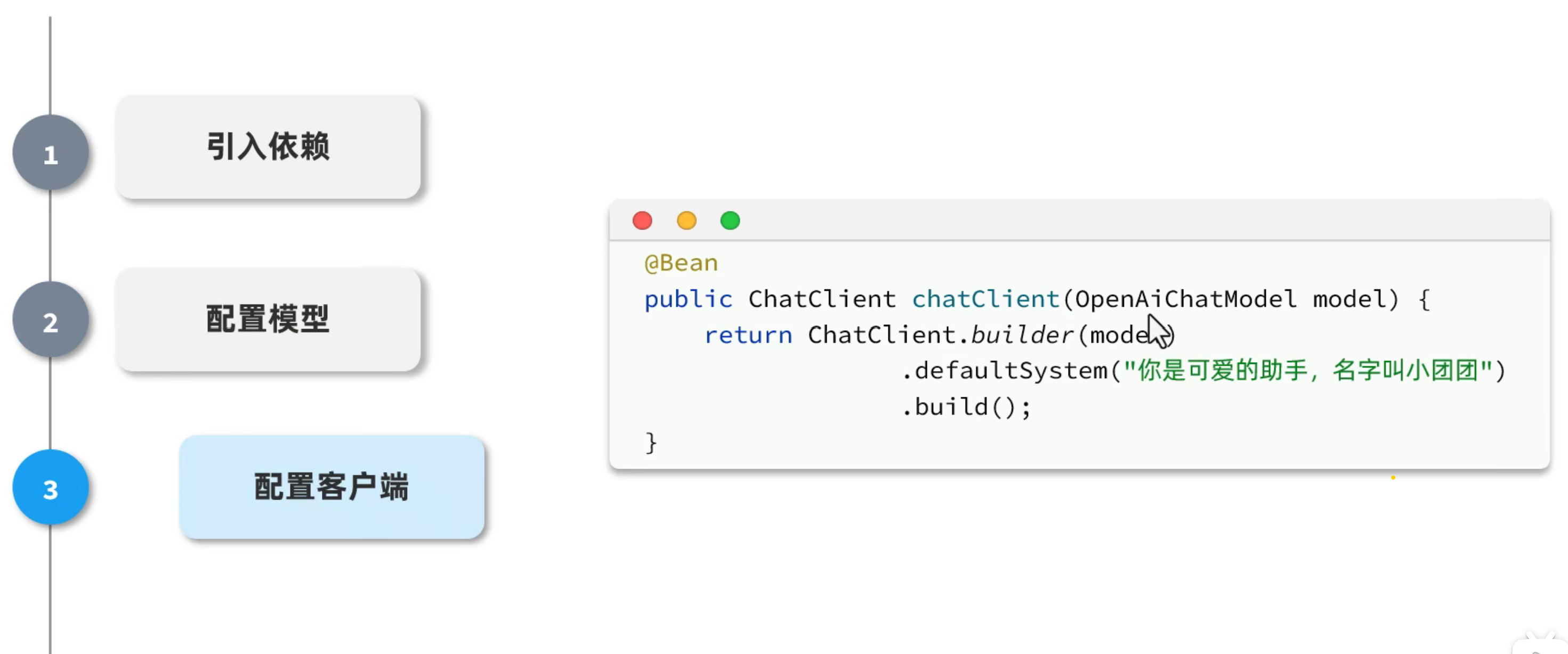
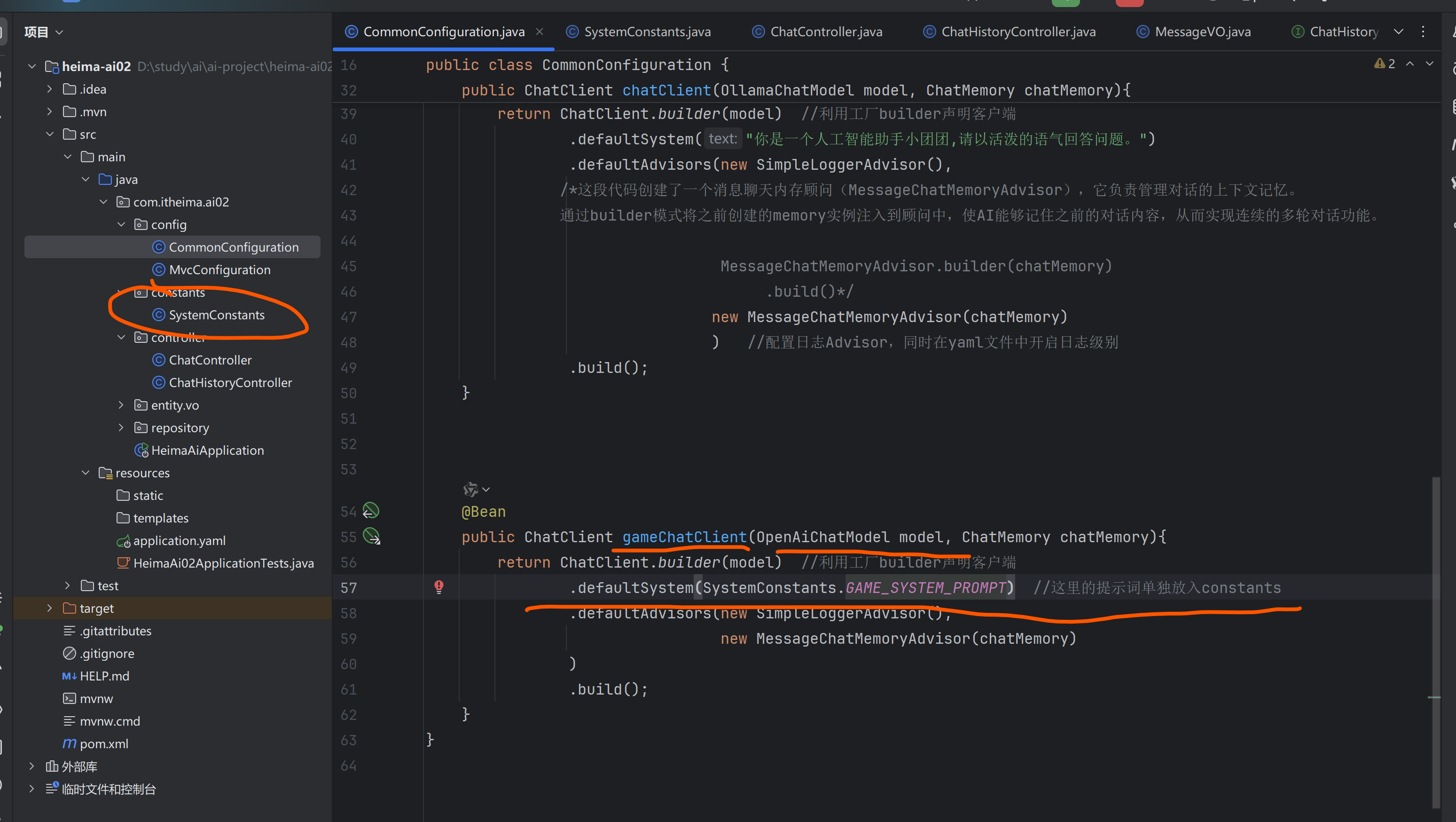
这里改变了一次版本号
(三)智能客服
一,需求和思路分析
由于解析大模型响应,找到函数名称、参数,调用函数等这些动作都是固定的,所以SpringAI再次利用AOP的能力,帮我们把中间调用函数的部分自动完成了。
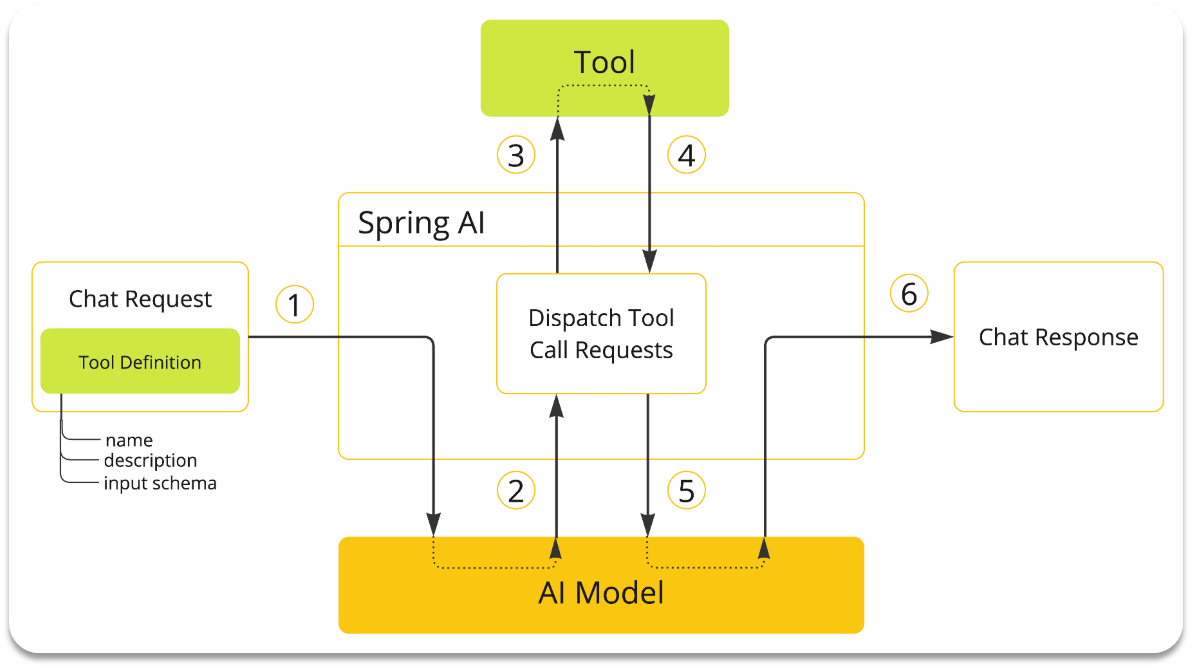
我们要做的事情就简化了:
-
编写基础提示词(不包括Tool的定义)
-
编写Tool(Function)
-
配置Advisor(SpringAI利用AOP帮我们拼接Tool定义到提示词,完成Tool调用动作)
二,写Tools
1.编写System提示词
2.定义Tool工具
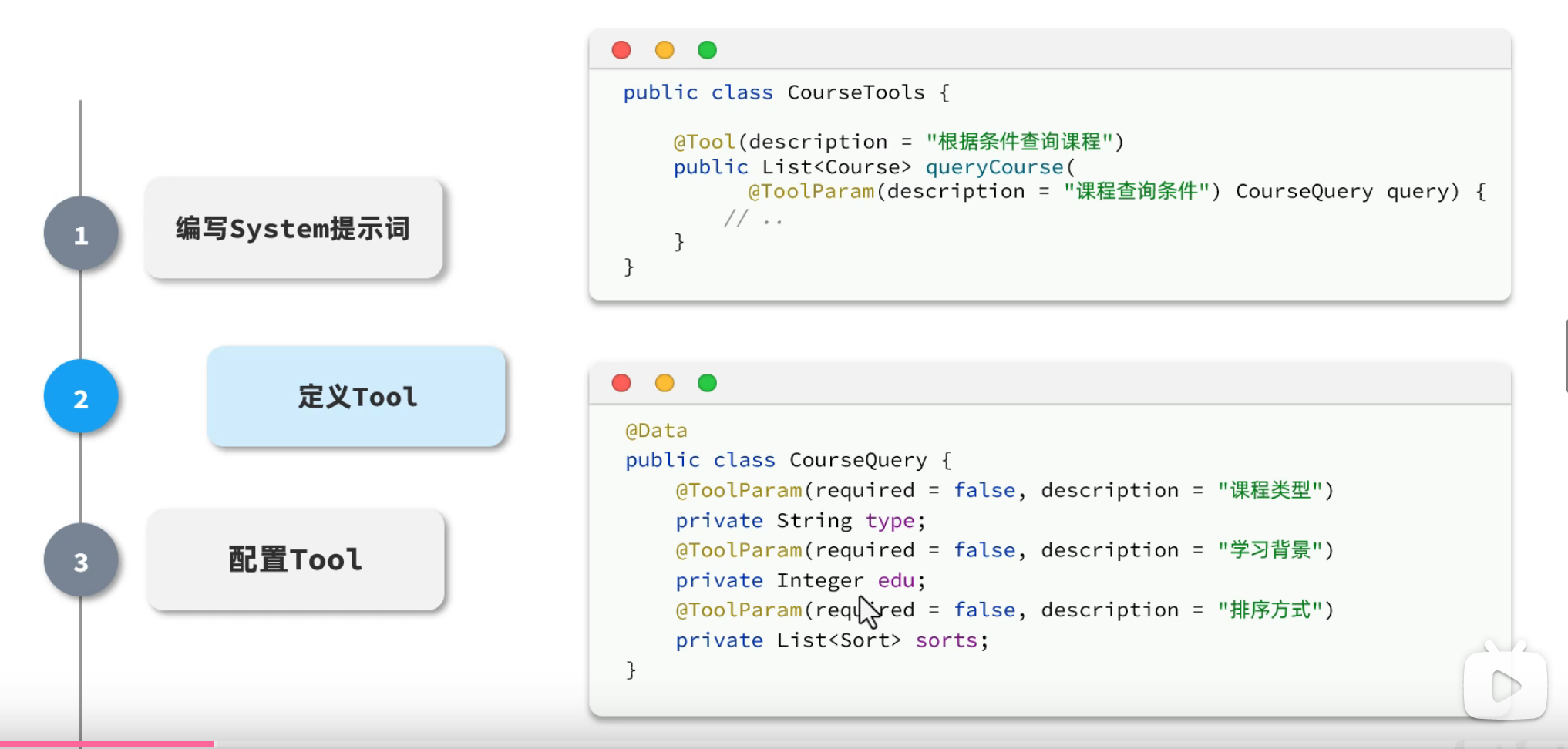
3.配置Tool
步骤:
①建表
②引入依赖
③配置数据库信息

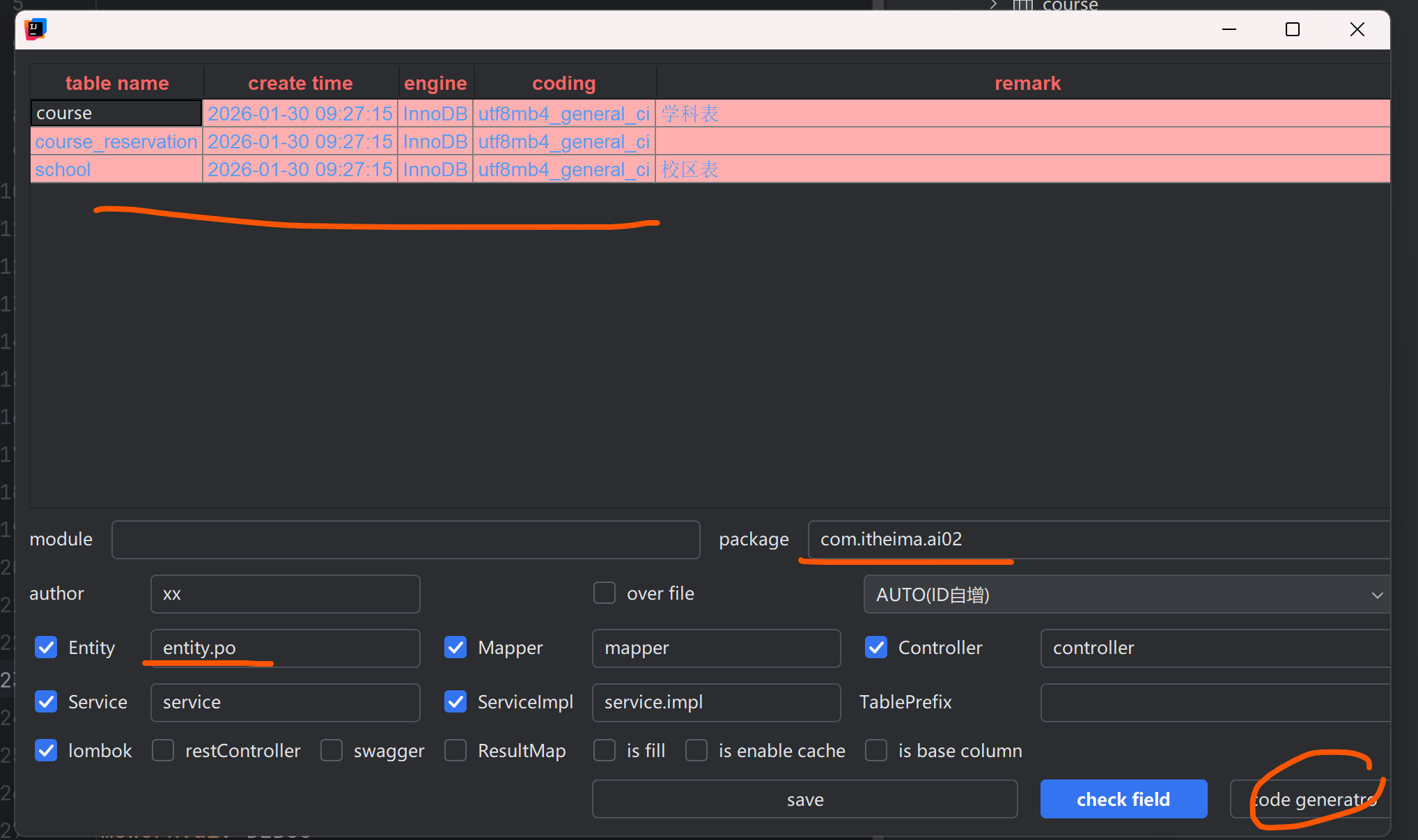
④基于MybatisPlus的CRUD的基础代码(po里面的三张表)学科表 校区表 课程预约表
MybatisPlus自动生成即可
Tools——>Config Database
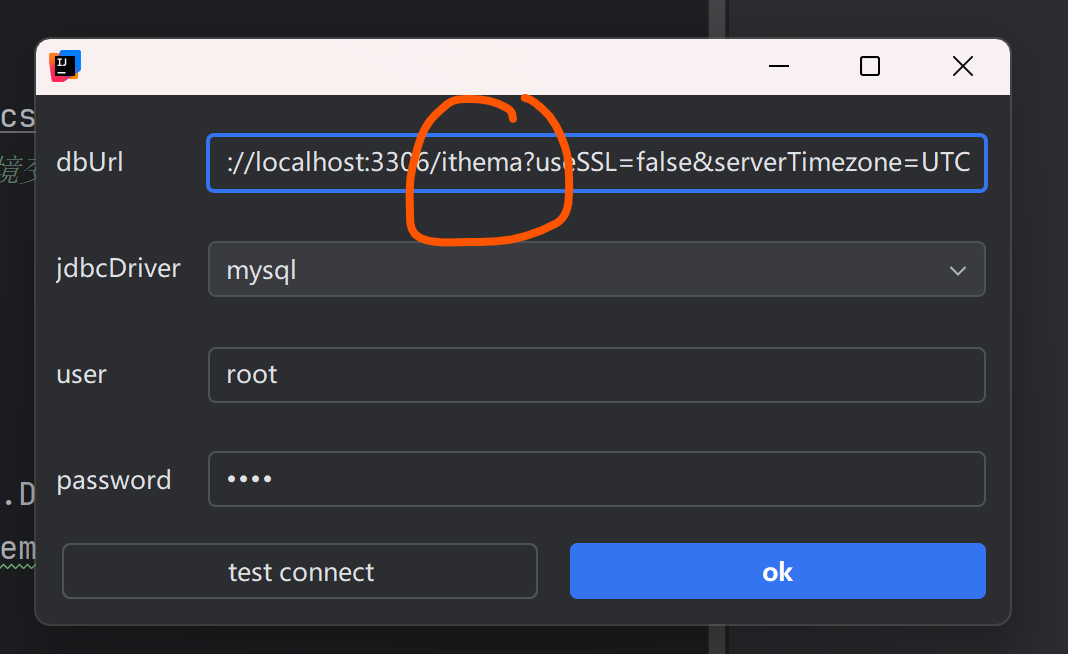
Tools——>Config Generator
⑤定义AI要用到的Function,在SpringAI中叫做Tool
我们需要定义三个Function:
-
根据条件筛选和查询课程
-
查询校区列表
-
新增试听预约单
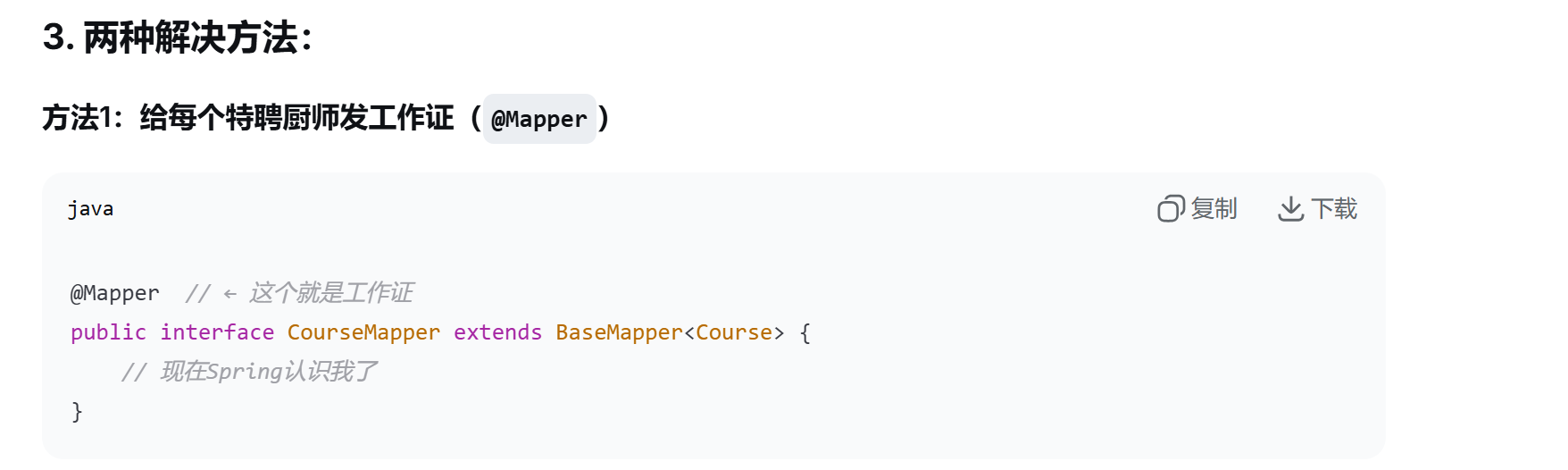
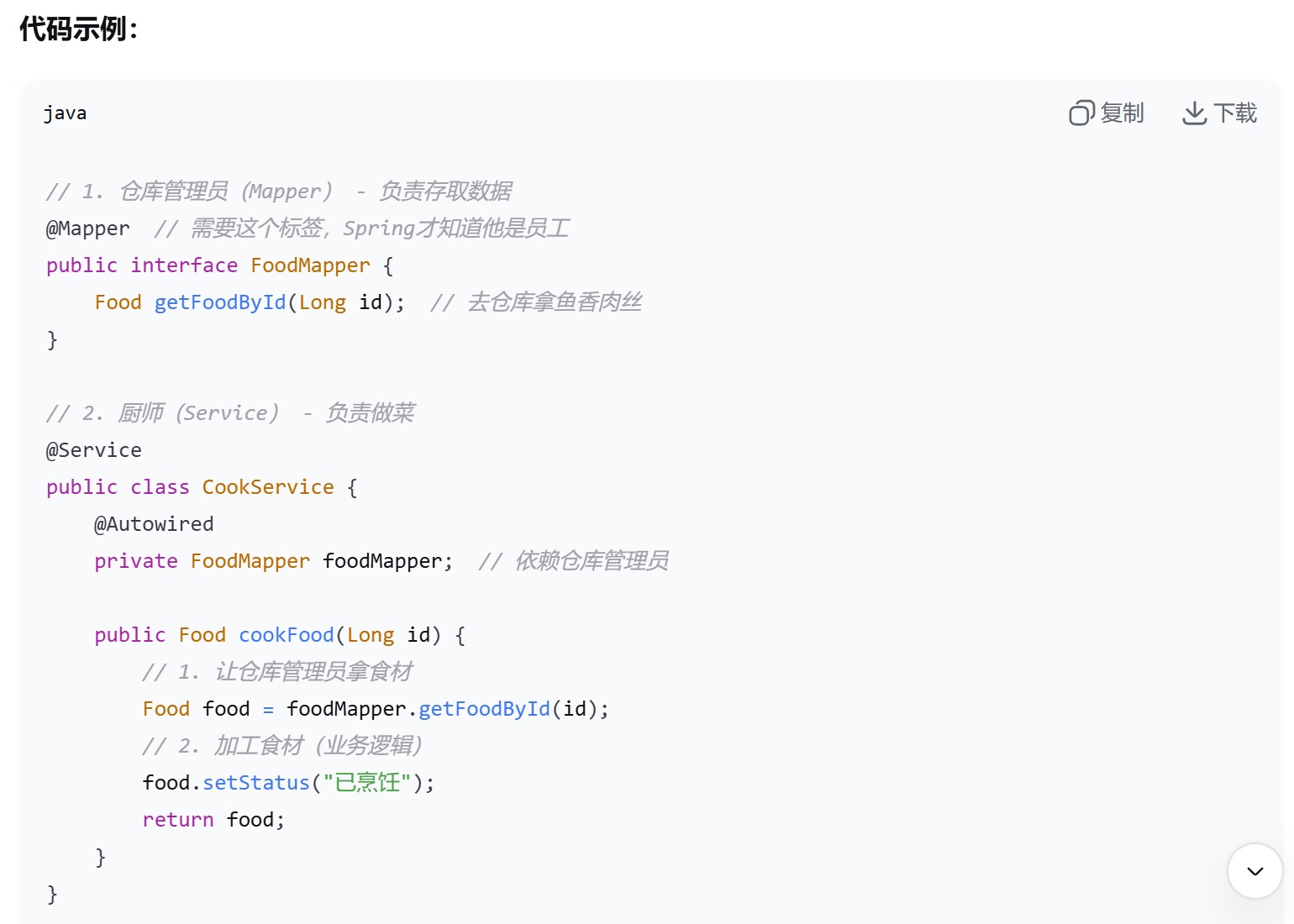
这里运行时报错,发现是没有加@Mapper注解



三,FuncationCalling
配置Tool(CommonConfignation)
①System系统提示词
②ServiceChatClient编写
③编写与前端对接的Controller,与前端对接
测试时报错,未解决toolInput cannot be null or empty
这里变成将流式输出变为String解决
四,解决百联平台兼容性问题
智能客服不支持Stream流的输出方式
(四)ChatPDF
一,向量模型
1.解释
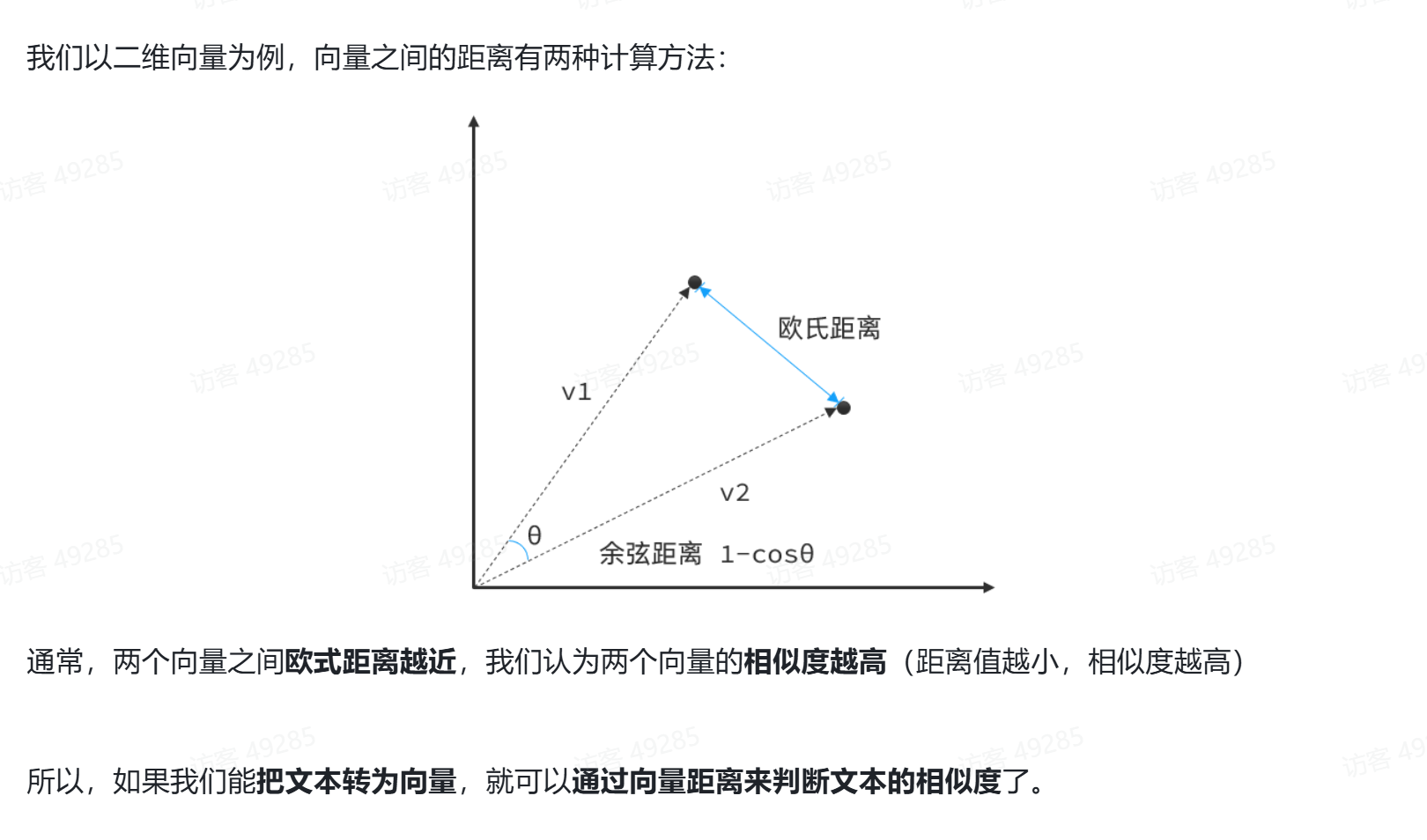
2.使用
这里我们选择通用文本向量-v3,这个模型兼容OpenAI,所以我们采用OpenAI的配置,但地址和API_KEY都采用阿里云百炼平台的地址。
①引入依赖

②配置向量模型yaml

③使用EmbeddingModel
写一个单元测试进行试用
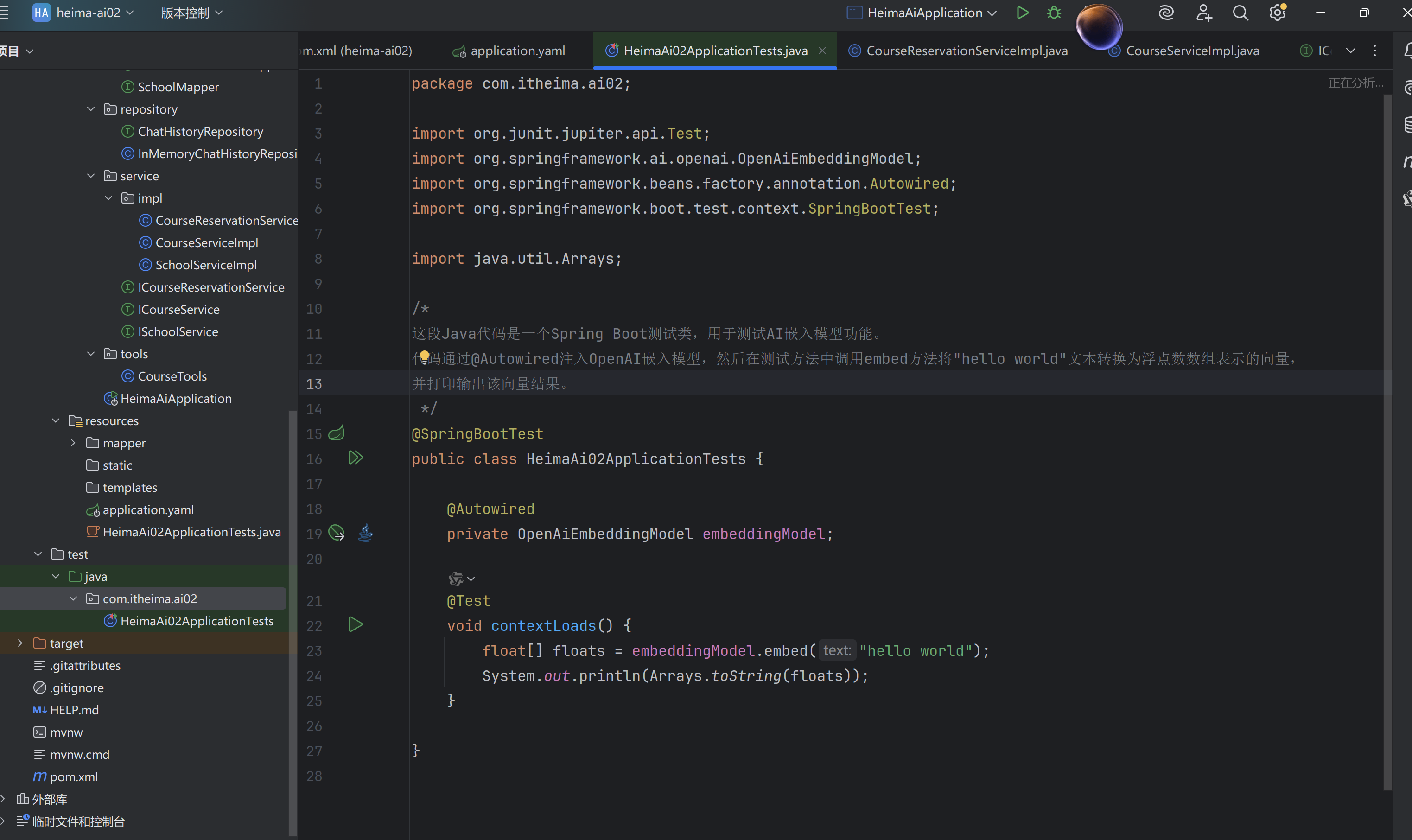
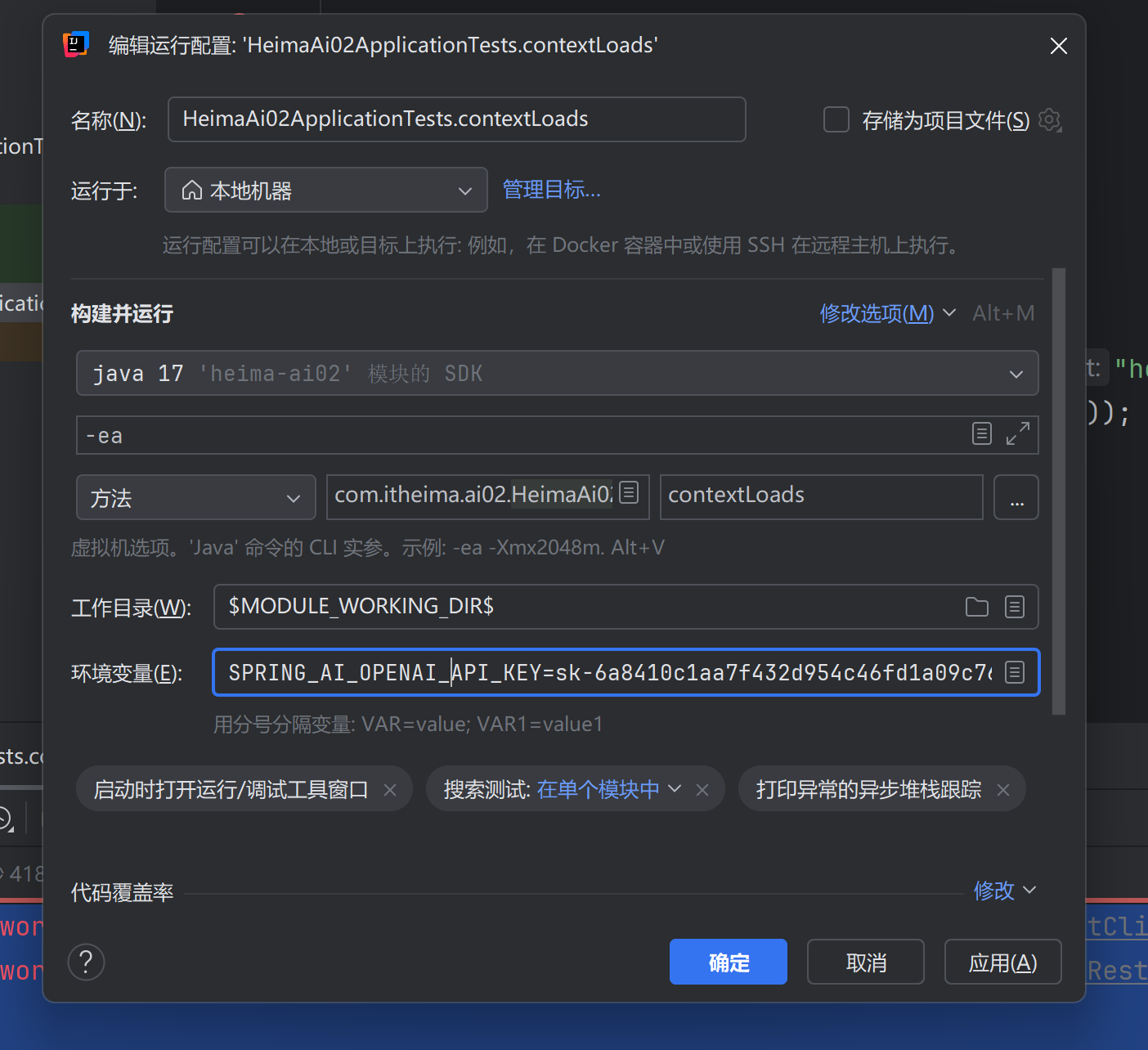
环境变量
二,向量数据库和PDF处理
1.向量数据库
向量数据库的主要作用有两个:
-
存储向量数据
-
基于相似度检索数据

步骤:
1.引入依赖:以Redis为例
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-redis-store-spring-boot-starter</artifactId>
</dependency>
2.配置向量数据库

3.读写数据
2.PDF处理
SimpleVectorStore向量库是基于内存实现,是一个专门用来测试、教学用的库。
1.引入依赖
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-pdf-document-reader</artifactId>
</dependency>
2.读取和拆分文档
3.写入向量数据库
(五)ChatGPT
一,读取PDF和向量搜索
因为用的本地向量库,此处的依赖不用引。
配一个向量库的Bean。

因为SimpleVectorStore()是一个抽象类,不能实例化。要用工厂。

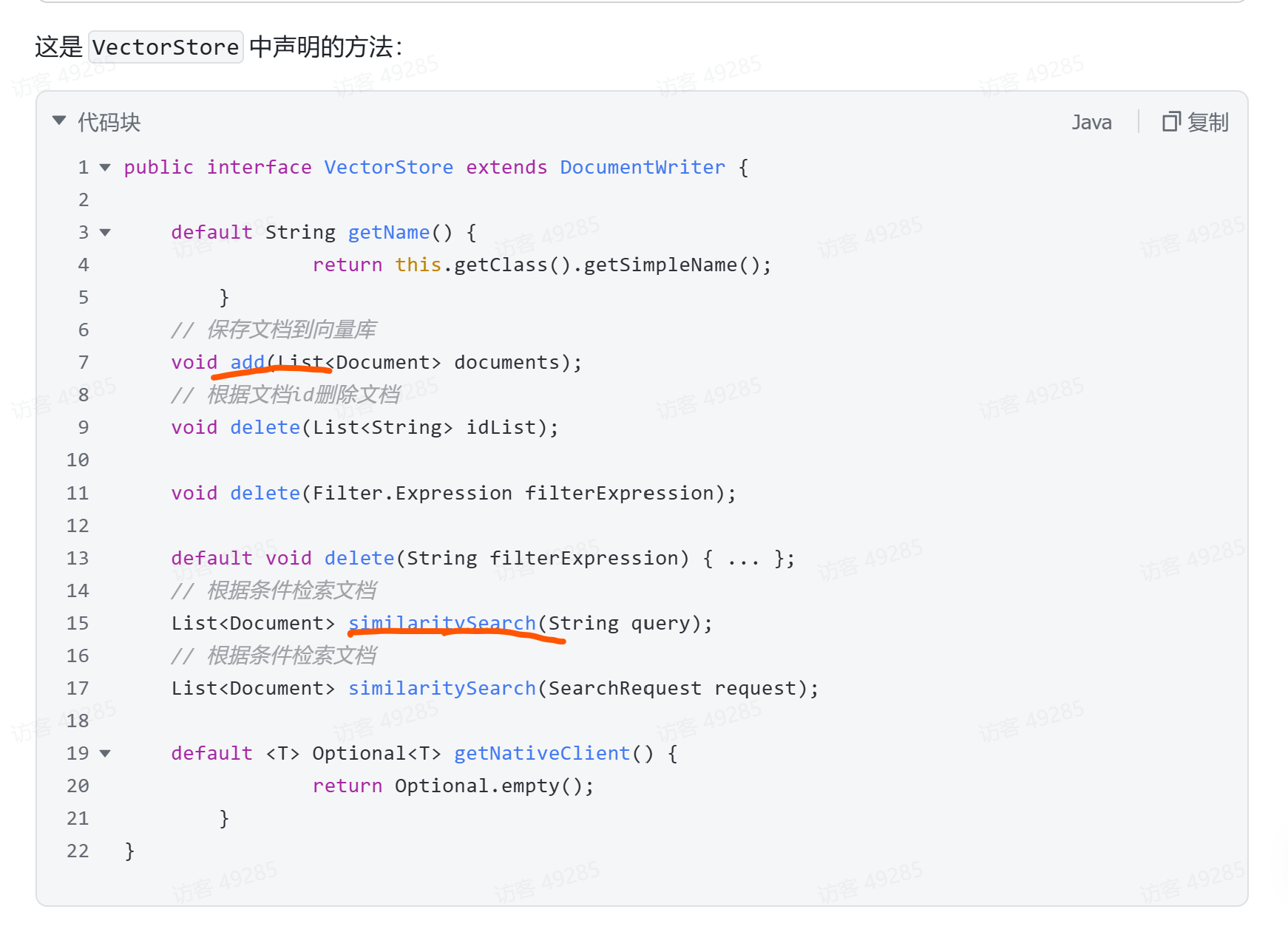
写一个单元测试
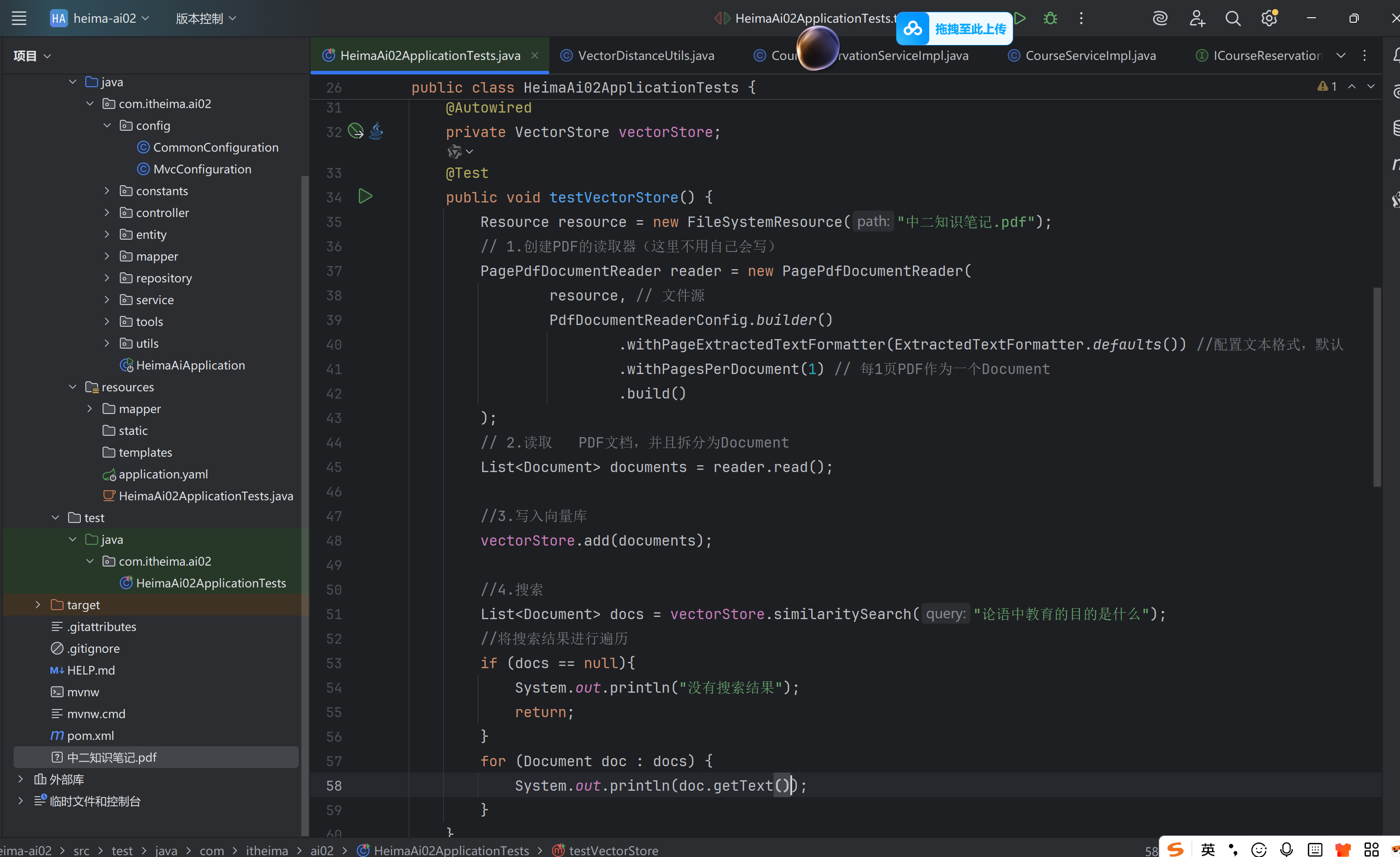
配环境变量
二,实现GPT应用
1.PDF上传下载、向量化
需要先实现一个上传PDF的接口,在接口中实现下列功能:
-
校验文件格式是否为PDF
-
保存文件信息
-
保存文件(可以是oss或本地保存)
-
保存会话ID和文件路径的映射关系(方便查询会话历史的时候再次读取文件)
-
-
文档拆分和向量化(文档太大,需要拆分为一个个片段,分别向量化)
将来用户查询会话历史,我们还需要返回pdf文件给前端用于预览,所以需要实现一个下载PDF接口,包含下面功能:
-
读取文件
-
返回文件给前端
操作
①PDF文件管理
要实现PDF下载功能,我们需要记住每一个chatId对应的PDF文件名称。
定义一个类,记录chatId与pdf文件的映射关系,同时实现基本的文件保存、文件向量化。
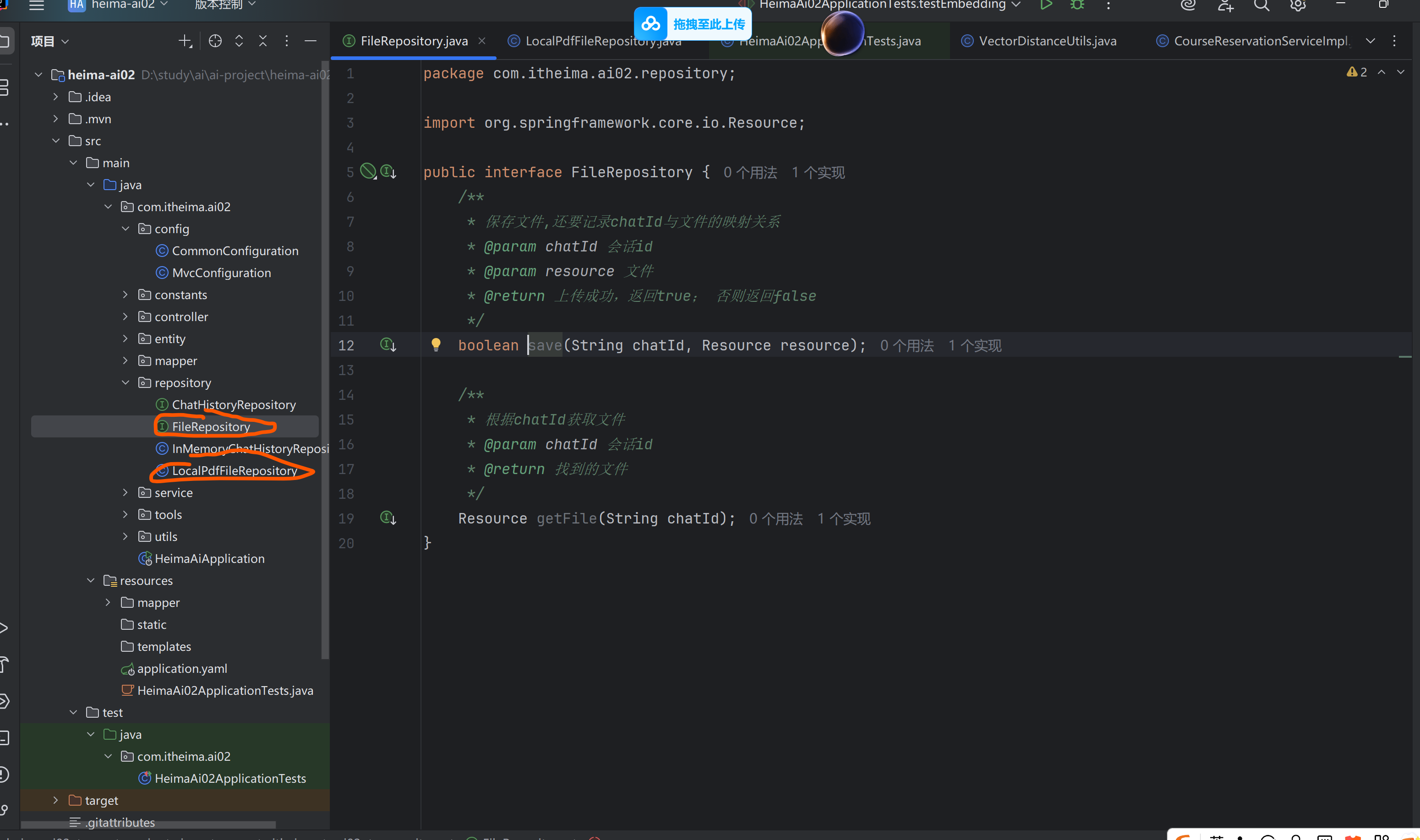
②上传文件响应结果
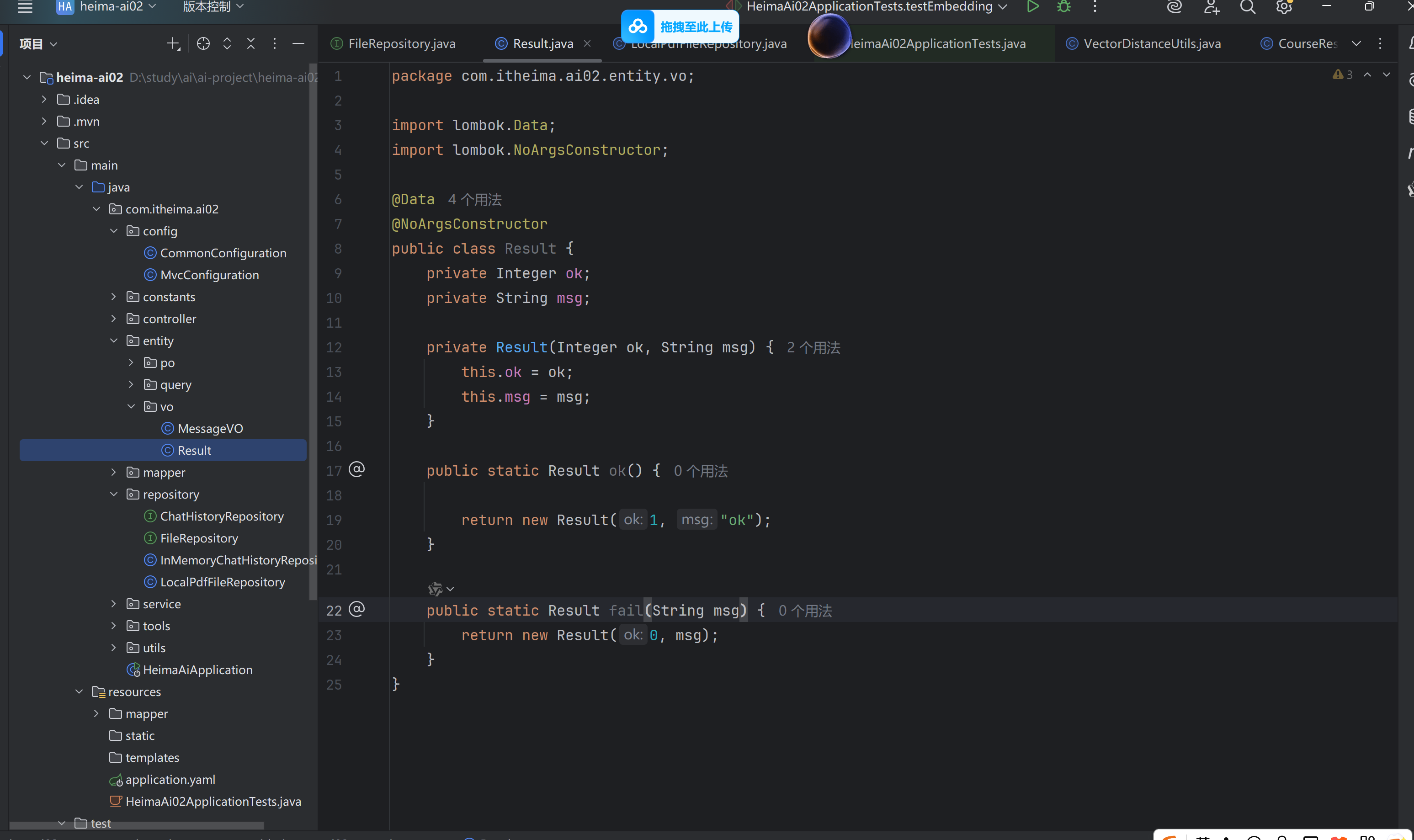
③实现上传和下载文件接口
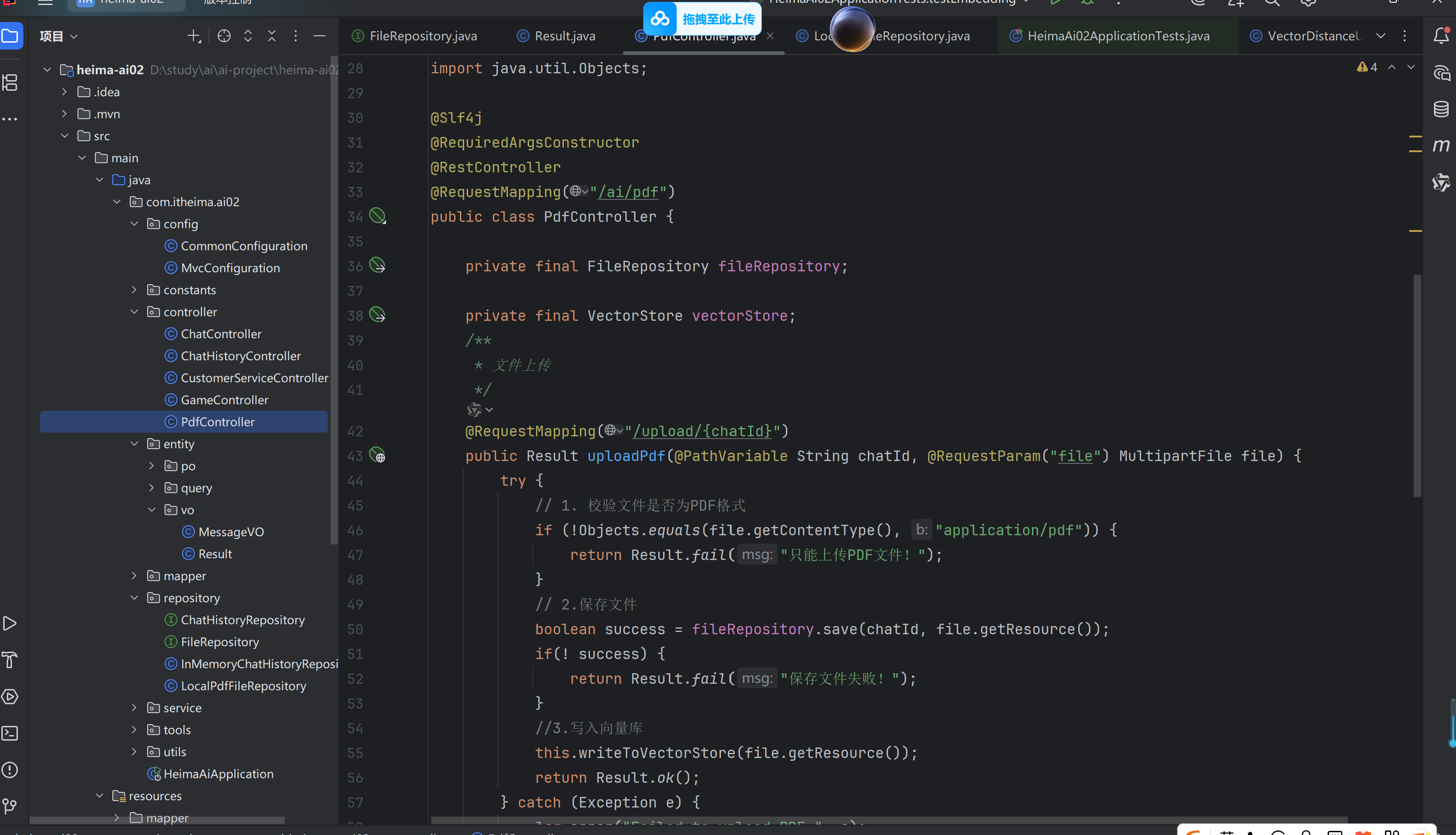
④
SpringMVC有默认的文件大小限制,只有10M,很多知识库文件都会超过这个值,所以我们需要修改配置,增加文件上传允许的上限。
修改application.yaml文件,添加配置
⑤默认情况下跨域请求的响应头是不暴露的,这样前端就拿不到下载的文件名,我们需要修改CORS配置,暴露响应头
2.配置ChatClient
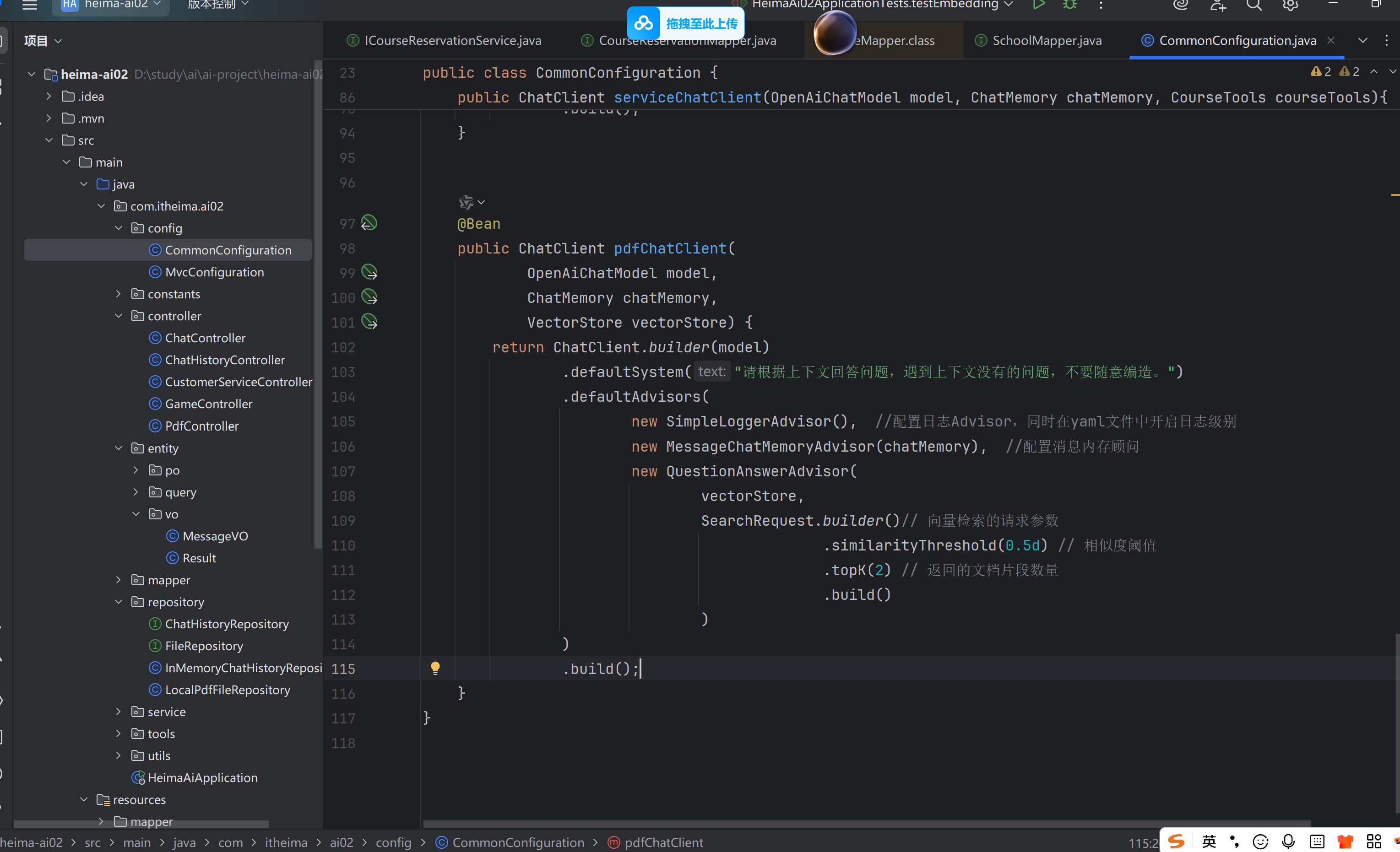
3.对话接口
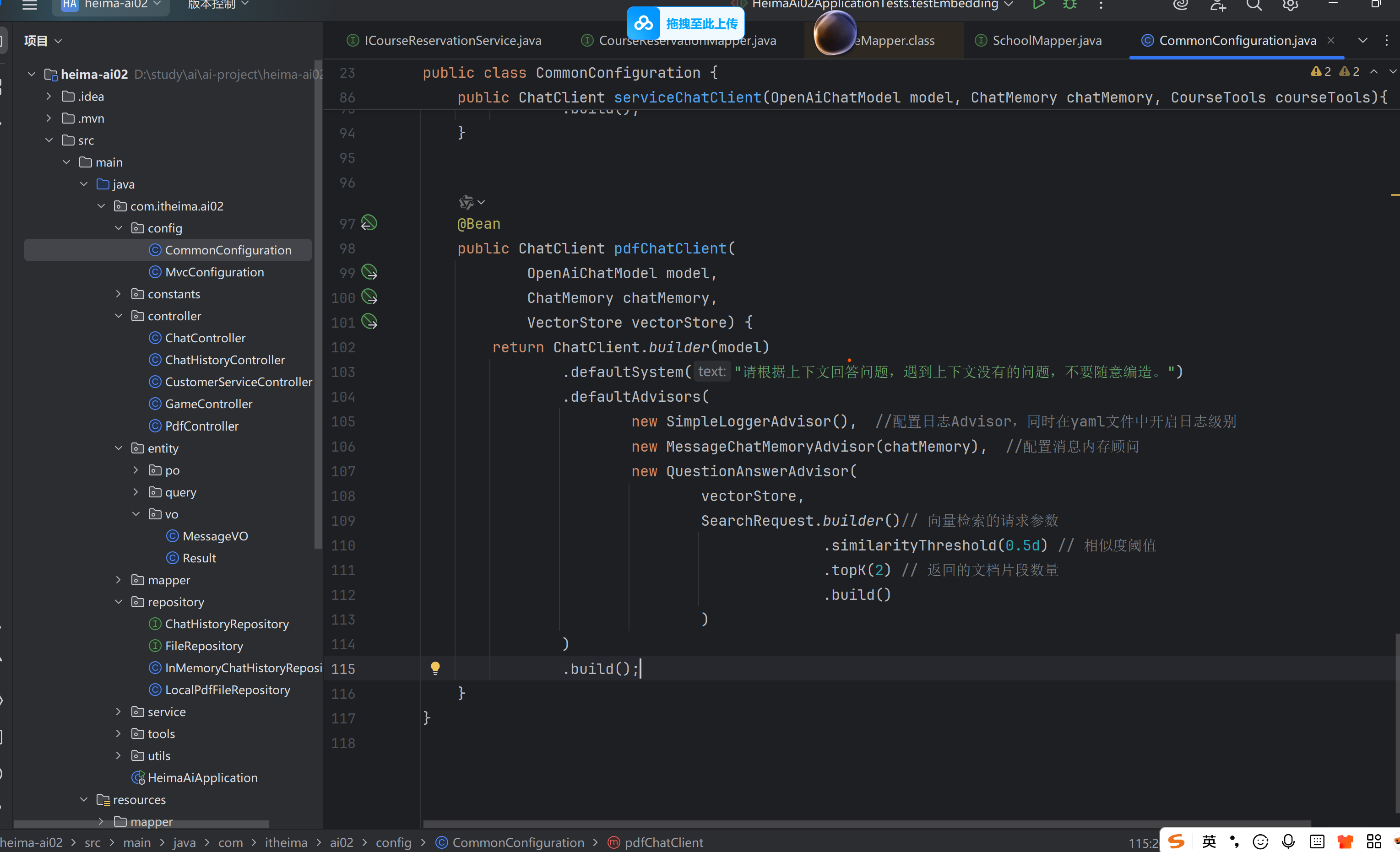
4.测试
存在错误,需要禁用一个EmbeddingModel
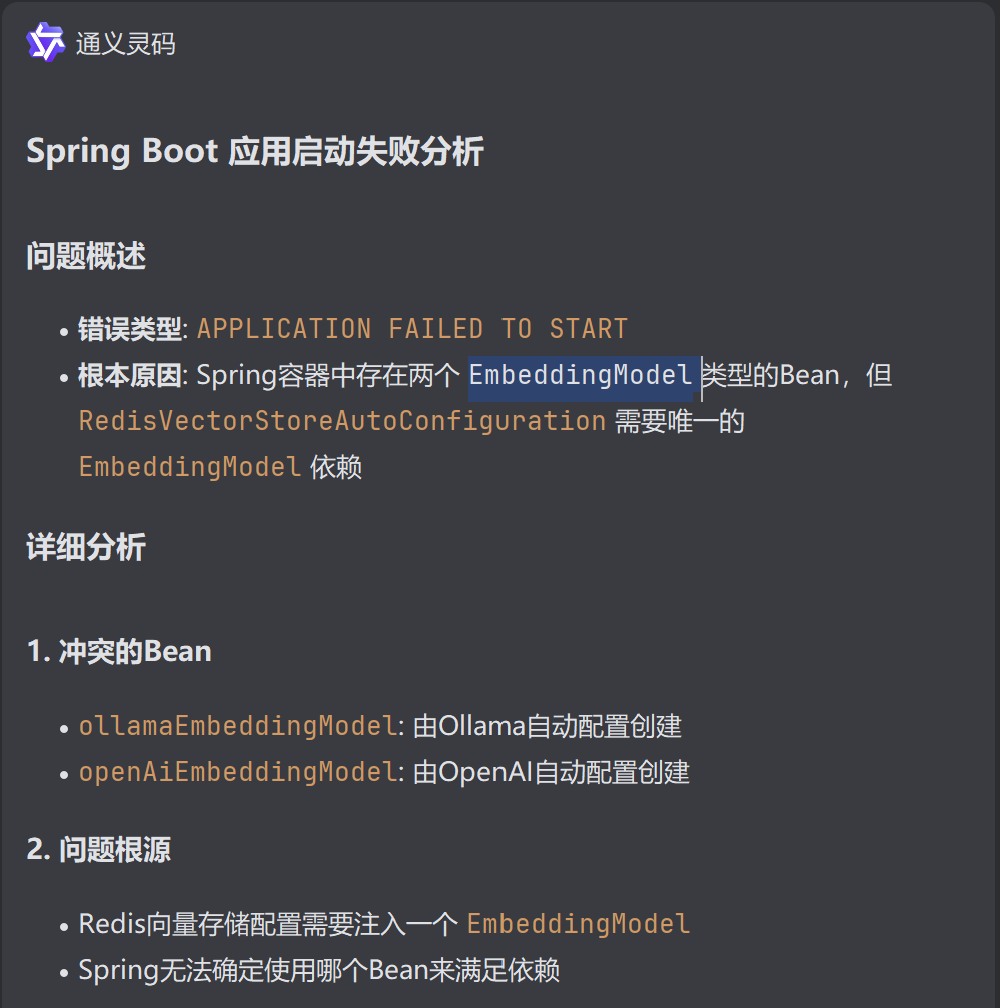
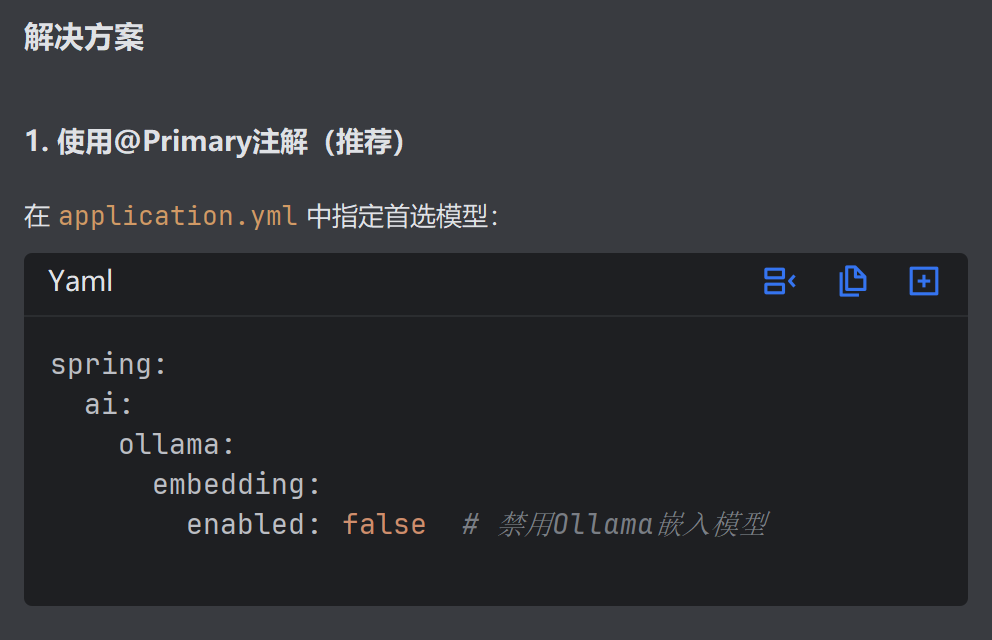
由于缺少Redis无法完成测试

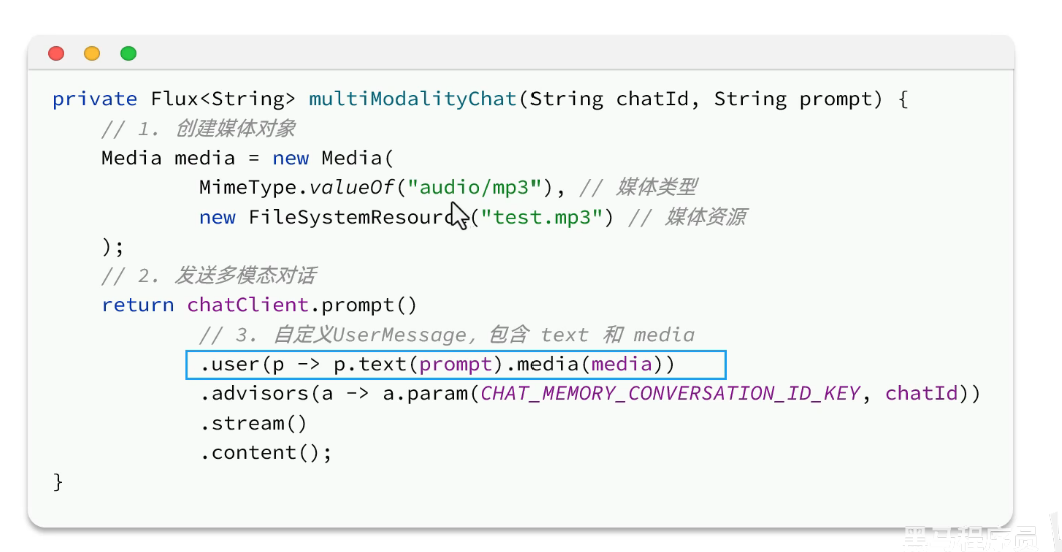
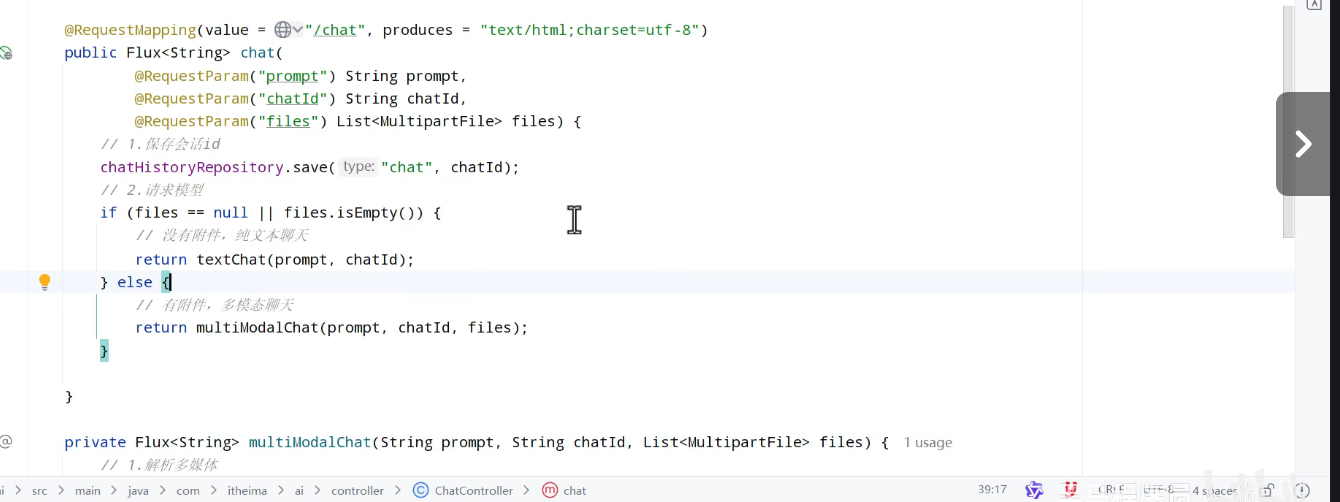
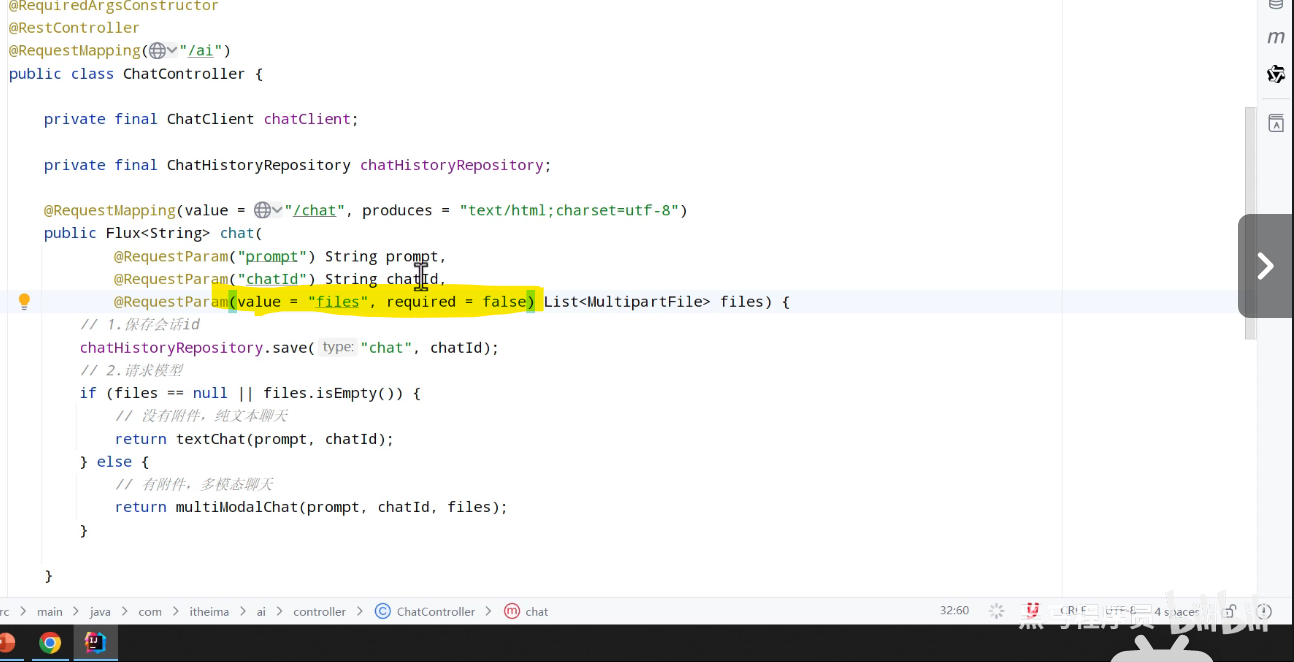
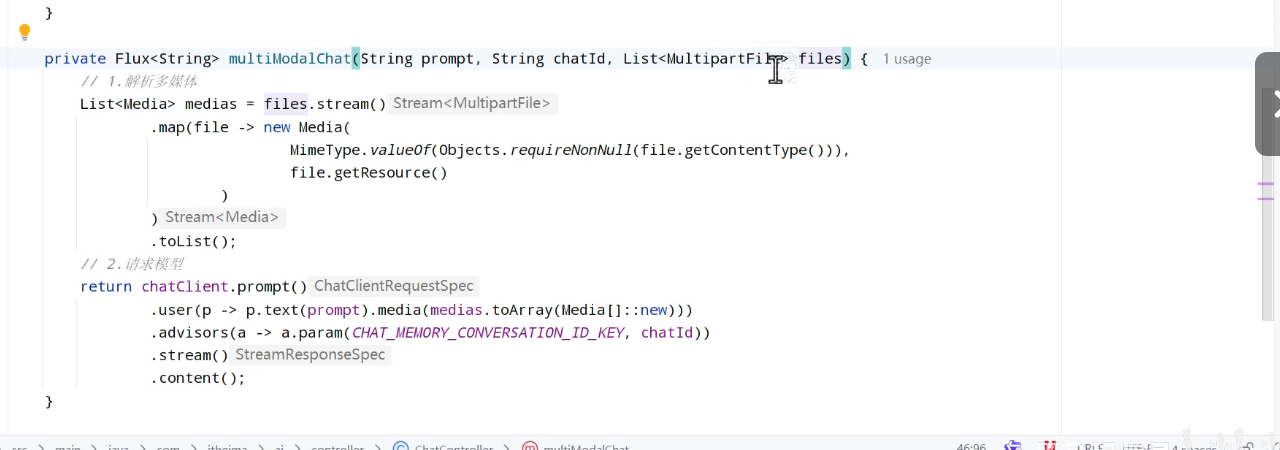
(六)多模态会话

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)