打通 Claude Code 生态:如何让本地 Agent 共享 Commands、Subagents 与 Skills
本文介绍了一种轻量级架构方案"映射加载器"(Mapping Loader),旨在打通Claude Code与其他本地AI Agent(如Gemini CLI)之间的能力共享。通过"扫描→映射→加载"三步策略,将Claude Code中的Commands、Subagents、Skills等原子能力解耦为标准化的Markdown表格,实现一次编写多处复用。核心创
打通 Claude Code 生态:如何让本地 Agent 共享 Commands、Subagents 与 Skills
目标读者:使用多 Agent 协作开发(Claude Code + Gemini CLI 等)的开发者、DevOps 工程师。
核心价值:打破 Agent 间的能力孤岛,实现 Prompt、Skill 和 Command 的一次编写,多处复用。
阅读时间:6 分钟
一句话摘要:通过标准化映射层(Mapping Layer),将 Claude Code 的原子能力解耦为通用资产,赋能整个本地 Agent 生态。
💡 关联阅读:本文是 《打通任督二脉:让你的 GitHub Copilot 瞬间学会 Claude Code 的所有绝招》 的扩展。在前文中,我们实现了编辑器侧 Copilot 的能力注入;本文将进一步把这套“映射”哲学推广至所有本地 Agent(如 Gemini CLI、Codex CLI 等),构建一套通用的 Agent 互操作协议。
为什么你的 Agent 需要"外脑"?
在 AI 辅助开发的日常中,我们经常面临这样的尴尬场景:你在 Claude Code 中精心调教了一个 code-review 的 Skill,定义了完美的审查步骤和语气。然而,当你切换到 Gemini CLI 或 VS Code 时,这些能力"蒸发"了。你不得不复制粘贴 Prompt,或者容忍不同 Agent 表现出的能力参差。
这不仅仅是重复劳动的问题,更是上下文断裂。
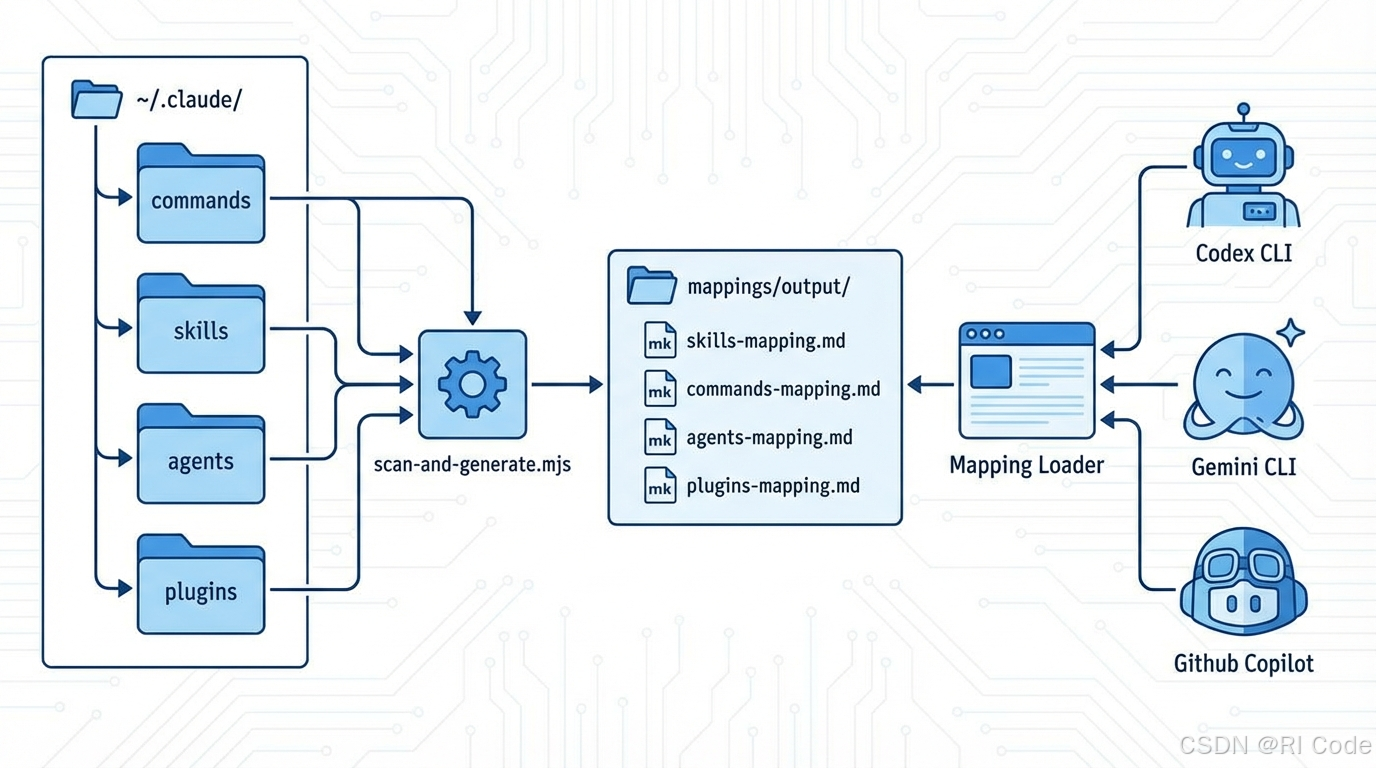
如果我们将 Claude Code 视为一个能力容器,那么 Commands(命令)、Subagents(子智能体)、Skills(技能) 和 Plugins(插件) 就是其中的原子能力。本文将介绍一种轻量级的架构方案——映射加载器(Mapping Loader),它能像"神经连接"一样,将这些能力导出并共享给所有本地 Agent。
核心架构:扫描、映射与加载
要实现能力共享,我们不需要复杂的微服务架构,只需要遵循 UNIX 哲学:一切皆文件。
我们采用 “Scan → Map → Load” 三步走策略:
- Scan(扫描):遍历 Claude Code 的配置目录,识别所有能力实体。
- Map(映射):生成标准化的元数据文档(Markdown Table),作为能力的"注册表"。
- Load(加载):其他 Agent 通过通用协议读取注册表,动态加载所需能力。
步骤一:构建扫描器 (The Scanner)
一切的起点是 scan-and-generate.mjs 脚本。它的任务是建立索引。
Claude Code 的能力分散在不同的目录中:
commands/:.md形式的 Prompt 模板。skills/:包含SKILL.md的功能目录。agents/:定义 Agent 角色的 Prompt。plugins/:外部安装的扩展包。
扫描器通过 glob 模式匹配这些文件,提取 Frontmatter(元数据),并按类别分组。
// scan-and-generate.mjs 核心逻辑片段
const CONFIG = {
mappings: [
{
id: "skills",
name: "Local Skills",
outputFile: "skills-mapping.md",
sourceDir: ROOT_DIR + "/skills/",
sourcePattern: "*/SKILL.md",
// 提取关键元数据:描述、名称
frontmatterFields: ["description", "name"],
// ...
},
// ... 其他类型映射
],
};
关键点:插件(Plugins)的处理比较特殊。由于插件可能有多个版本,扫描器内置了语义版本(SemVer)过滤逻辑,确保只索引每个插件的最新版本,避免旧版本的干扰。
步骤二:生成映射表 (The Registry)
扫描的结果不是复杂的 JSON 数据库,而是人类可读的 Markdown 表格。
为什么要用 Markdown?
- AI 友好:LLM 阅读 Markdown 表格的能力极强,Token 消耗低且结构清晰。
- 自文档化:开发者可以直接打开文件查看有哪些可用能力。
- 易于调试:文本差异(Diff)清晰,版本控制方便。
生成的 skills-mapping.md 示例:
# Local Skills 映射表
| 名称 | 描述 | 完整路径 |
| --------------- | ----------------------- | ------------------------------------------- |
| git-diff-report | Git 变更报告生成技能... | `~/.claude/skills/git-diff-report/SKILL.md` |
| tech-blog | 技术博客文章创作工具... | `~/.claude/skills/tech-blog/SKILL.md` |
每一行就是一个能力的"句柄"(Handle),包含了 AI 调用所需的一切:它叫什么(Name)、它是干什么的(Description)、它在哪(Path)。
步骤三:通用加载器 (The Loader)
有了映射表,我们还需要一个机制来消费它。这就是 mapping-loader Skill 的作用。
这是一个元技能(Meta-Skill),它的唯一作用就是帮 Agent 查找并加载其他技能。它定义了一套通用的查询模式:
- 类型识别:用户想要的是 Command 还是 Skill?
"Run /git:sync"-> 查commands-mapping.md"Activate tech-blog"-> 查skills-mapping.md
- 模糊搜索:使用
grep在映射表中查找关键词。 - 动态加载:读取"完整路径"指向的文件内容,注入当前上下文。
这种设计的精妙之处在于解耦。
本地 Agent(如 Gemini CLI)不需要知道 Claude Code 的具体目录结构,也不需要维护复杂的配置同步。它只需要被告知:“去 ~/.claude/mappings/output/ 找答案”。
跨 Agent 调用的实战体验
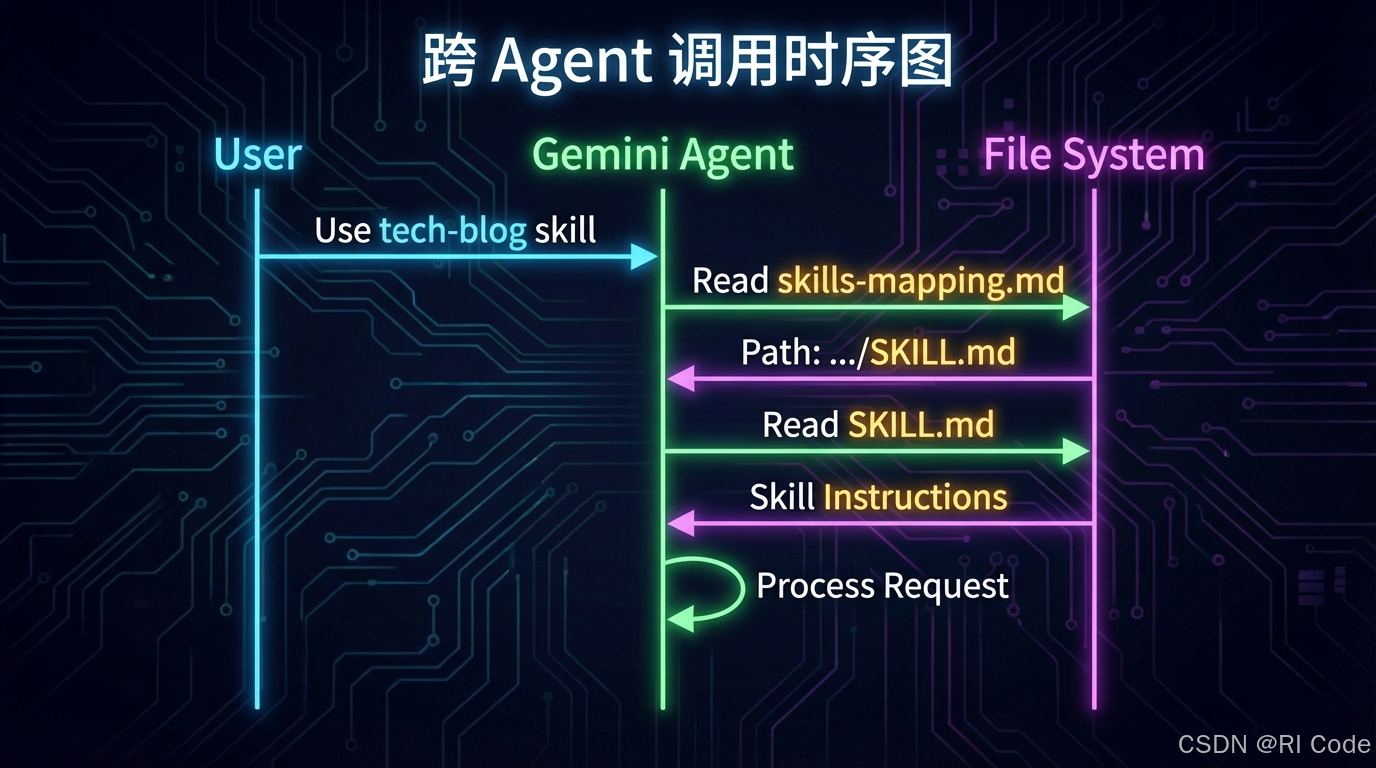
想象一下,你在 Gemini CLI 中:
User: “我想写一篇关于 React Hooks 的技术博客,用那个 tech-blog 技能。”
Gemini (with Mapping Loader):
- 思考:用户提到了 “tech-blog” 和 “技能”。
- 工具调用:
grep "tech-blog" ~/.claude/mappings/output/skills-mapping.md- 发现:找到路径
~/.claude/skills/tech-blog/SKILL.md。- 行动:读取该文件,激活技能。
- 响应:
<activated_skill name="tech-blog">...
整个过程流畅无感,仿佛 tech-blog 就是 Gemini 原生的一样。
总结:迈向 Agent 生态互联
通过 mapping-loader 和配套的扫描脚本,我们实际上定义了一套本地 Agent 的互操作协议(Local Agent Interoperability Protocol)。
这套方案不仅解决了能力复用的问题,更为未来的 Agent 协作打下了基础。今天的"共享"还停留在静态文件的读取,明天或许就是动态的运行时调用。
现在,去运行 node scan-and-generate.mjs,让你的 Agent 们开始对话吧。
参考资源
- skills/mapping-loader/SKILL.md: 加载器技能定义
mappings/scan-and-generate.mjs: 扫描生成脚本mappings/output/: 生成的映射文件目录

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 13
13 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)