【ACP-LLM】RAG提示词篇 1
本章回顾了RAG方法,介绍了提示词框架和LllamaIndx提示词模板。
2.3 优化提示词改善问答质量
🚄 前言
上一节,你学习了上下文工程 (Context Engineering) 的一种关键技术——RAG,通过为大模型提供外部知识来扩展其能力。
但这仅仅是构建优秀用户体验的第一步。
用户往往期待更个性化、更精准的交互。
本节将深入探索上下文工程的另一重要方面:
如何通过优化提示词 (Prompt) 来精细地控制大模型的输出,例如调整语气、规范格式,甚至赋予它处理文本总结、推断、转换等多种任务的能力。
1. 前文回顾
上一节中通过RAG方法,大模型已经获取到了公司的私有知识。
为了方便调用,将其封装成了几个函数,并保存在了 chatbot/rag.py , chatbot/llm.py 中。
现在你可以通过如下代码来快速调用。
加载索引
from chatbot import rag
query_engine = rag.create_query_engine(index=rag.load_index())
注
上小节已经建立了索引,因此这里可以直接加载索引。
如果需要重建索引,可以增加一行代码:rag.indexing()
定义问答函数
# 定义问答函数
def ask_llm(question, query_engine):
streaming_response = query_engine.query(question)
streaming_response.print_response_stream()
2. 优化提示词以改善大模型回答质量
上一节,你已经成功地让答疑机器人通过 RAG 掌握了公司的内部知识。
现在,你可以测试一下它的实际效果。
一位新同事想了解项目管理工具,于是他向机器人发起了提问:
# 仅使用RAG时,机器人的表现
question = "我们公司项目管理应该用什么工具?"
ask_llm(question, query_engine)
模型预期输出(示例):
对于项目管理,推荐使用 `Jira` 或 `Trello`。这两个工具都非常适合管理和跟踪项目进度,确保团队成员之间的高效协作。
- **`Jira`** 是一个非常强大的项目管理工具,特别适用于软件开发项目。它可以帮助你跟踪问题和任务,管理项目进度。你可以访问 [Atlassian官网](https://www.atlassian.com/software/jira) 获取更多信息或下载。
- **`Trello`** 则是一个更加灵活的看板式项目管理工具,适合各种类型的项目。通过卡片和列表的形式,可以直观地看到项目的进展。你可以访问 [Trello官网](https://trello.com/) 获取更多信息或注册使用。
思考
问题似乎解决了。
但……真的解决了吗?
你需要考虑另一个场景,当用户问一个跟工具无关的问题时:
# 看看这个“补丁”在其他问题上的表现
question_2 = "我们公司的年假有多少天?"
instruction = " 回答时请务必附带上工具的官方网站或下载链接。"
new_question_2 = question_2 + instruction
ask_llm(new_question_2, query_engine)
模型预期输出(示例):
您的问题涉及到具体的公司福利政策,特别是年假天数,但提供的信息中并没有直接提到这一点。
通常这类详细信息会记录在员工手册或者公司内部的人力资源政策文件中。
建议您直接联系人力资源部获取准确的信息。
人力资源部的联系人是熊伟,您可以发送邮件至xiongwei@educompany.com询问具体事宜。
至于您要求的工具官方网站或下载链接,由于您的问题并未提及需要使用哪个工具,因此无法提供相关链接。
这种一刀切拼接指令的方式非常脆弱。
它不仅可能让模型的回答变得啰嗦和奇怪,而且每次提问都要手动判断该拼接哪句指令,这在真实的应用中是完全不可行的。
这正是深入学习提示词工程(Prompt Engineering)的原因。
它属于 上下文工程(Context Engineering) 的一部分,教你如何不再使用这种临时的“补丁”,而是系统性地、智能地构建与模型的对话上下文,精确地“指导”模型如何根据不同的情况来回答问题。
3. 提示词框架
3.1 基本要素
当和大模型在交流时,可以将它想象是一个经过“社会化训练的”人,交流方式应当和人与人之间传递信息的方式一样。
你的需求需要清晰明确,不能有歧义。
你的提问方式(Prompt)越清晰明确,大模型越能抓住问题的关键点,回复就越符合你的预期。
为了系统性地构建高效的上下文,我们可以遵循一个包含多个基本要素的提示词框架:任务目标、上下文、角色、受众、样例、输出格式。
这些要素共同构成了一个完整的上下文“蓝图”,能帮助你构建一个完整、有效的提示词。
| 要素 | 含义 |
|---|---|
任务目标(Object) |
明确要求大模型完成什么任务,让大模型专注具体目标 |
上下文(Context) |
任务的背景信息,比如操作流程、任务场景等,明确大模型理解讨论的范围 |
角色(Role) |
大模型扮演的角色,或者强调大模型应该使用的语气、写作风格等,明确大模型回应的预期情感 |
受众(Audience) |
明确大模型针对的特定受众,约束大模型的应答风格 |
样例(Sample) |
让大模型参考的具体案例,大模型会从中抽象出实现方案、需要注意的具体格式等信息 |
输出格式(Output Format) |
明确指定输出的格式、输出类型、枚举值的范围。 通常也会明确指出不需要输出的内容和不期望的信息,可以结合样例来进一步明确输出的格式和输出方法 |
当然,除了上面讲的提示词框架,许多问题分析的思维范式都可以用来帮助你描述清晰具体的需求。
例如,SWOT分析法、5W2H分析法等。
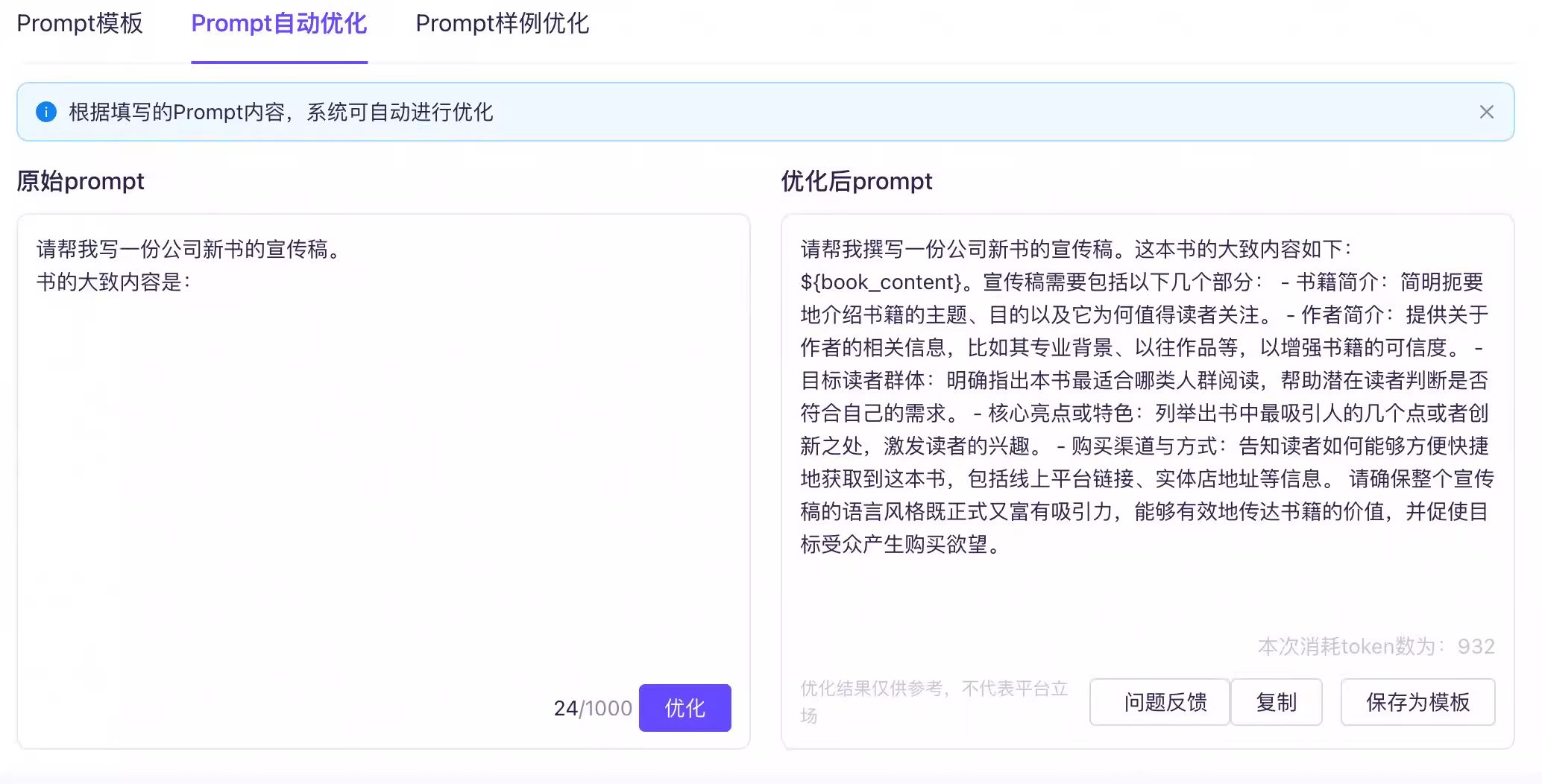
另外,你也可以考虑使用阿里云百炼提供的提示词自动优化工具,来帮助你完善提示词。
3.2 提示词模板
在开发大模型应用时,直接让用户根据框架书写提示词并非最佳选择。
你可以参考各种提示词框架中的要素,构建一个提示词模板。
提示词模板可以预设部分信息,如大模型的角色、注意事项等,以此来约束大模型的行为。
开发者只需在模板中配置输入参数,便能创建标准化的大模型的应用。
使用 LlamaIndex 中创建的 RAG应用中,有个默认的提示词模板,如下所示:
- 默认的模板可以使用代码查看,你可以参考LlamaIndex官网的代码。
LlamaIndex原始prompt模板为:
Context information is below.
---------------------
{context_str}
---------------------
Given the context information and not prior knowledge, answer the query.
Query: {query_str}
Answer:
其中,context_str和query_str都表示变量。
在进行向量检索和提问过程中,context_str将替换为从向量库中检索到的上下文信息,query_str则替换为用户的问题。
由于原模板是通用模板,不适合用来约束答疑机器人的行为。
你可以通过下列示例代码重新调整提示词模板,其中prompt_template_string表示新的提示词模板,你可以根据自己的场景自行修改。
构建提示词模板
prompt_template_string = (
"你是公司的客服小蜜,你需要简明扼要的回答用户的问题"
"【注意事项】:\n"
"1. 依据上下文信息来回答用户问题。\n"
"2. 你只需要回答用户的问题,不要输出其他信息\n"
"以下是参考信息。"
"---------------------\n"
"{context_str}\n"
"---------------------\n"
"问题:{query_str}\n。"
"回答:"
)
更新提示词模板
rag.update_prompt_template(query_engine,prompt_template_string)
rag.ask("你是谁", query_engine)
模型输出:
我是公司的客服小蜜。
测试成功,说明已更新提示词模板。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 17
17 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)