【原创】万字长文介绍 AI 软件开发全链路实战
本文的核心思想是:“一行代码不用写”。这不是口号,而是通过 AI Agent(智能体)工具链实现的工程现实。从环境搭建、代码分析、架构设计到功能开发、自动化测试,AI 已经能够接管 90% 的执行层工作。
📚 2026 AI-Native 软件工程实战圣经
作者:黑夜路人
时间:2026 年 2 月
📖 前言:程序员的“毁灭”与重生
在 2026 年的今天,软件开发的范式已经发生了彻底的断裂。我们不再是代码的编写者(Coder),而是逻辑的编排者(Orchestrator)和 Agent 指挥者(Commander)。
本文的核心思想是:“一行代码不用写”。这不是口号,而是通过 AI Agent(智能体)工具链实现的工程现实。从环境搭建、代码分析、架构设计到功能开发、自动化测试,AI 已经能够接管 90% 的执行层工作。
本次分享涵盖从大模型基础到实战项目开发的完整知识体系。
预期效果:
通过正确使用 AI 工具,开发效率可提升 2-5 倍。
- 原本 2 个月的项目 → 2 周内完成
- 原本 1 周的功能 → 1 天内实现
如果你依然坚持手动配置 Golang、Python、PHP 环境、手动编写 CRUD SQL、手动画流程图,那么你已经是“上个时代的遗民”。本手册将手把手教你如何利用全球最顶尖的 AI 武器库,实现效率的“降维打击”。
本文核心内容整理:

🔍 第一章:大模型的解构与认知
要驾驭 AI,首先必须理解其本质。切忌将模型神话化,也不可将其工具化视之过低。
1.1 物理本质:模型即文件
大模型(LLM - Large Language Model)并非虚无缥缈的云雾,它有物理实体。
- 文件形态:大模型本质上是经过海量数据训练后得到的权重文件(Weights),通常以 .safetensors 或 .bin .gguf、格式存在。
- 组成结构:一个完整的模型通常包含:
- 配置文件 (Config):定义模型架构参数(层数、隐藏层大小等)。
- 分词器 (Tokenizer):将人类自然语言文本转换为模型可理解的数字序列。
- 张量权重 (Tensors):存储模型的“知识”与逻辑,是文件体积最大的部分。
- 开源圣地:Hugging Face (huggingface.co) 是全球 AI 模型的“GitHub”。你可以在上面找到几乎所有开源模型的源文件,并支持直接下载到本地运行。
1.2 常规的大模型 Chat 的运行过程:提示词到输出的完整链路
客户端-服务端架构 (C/S Architecture):
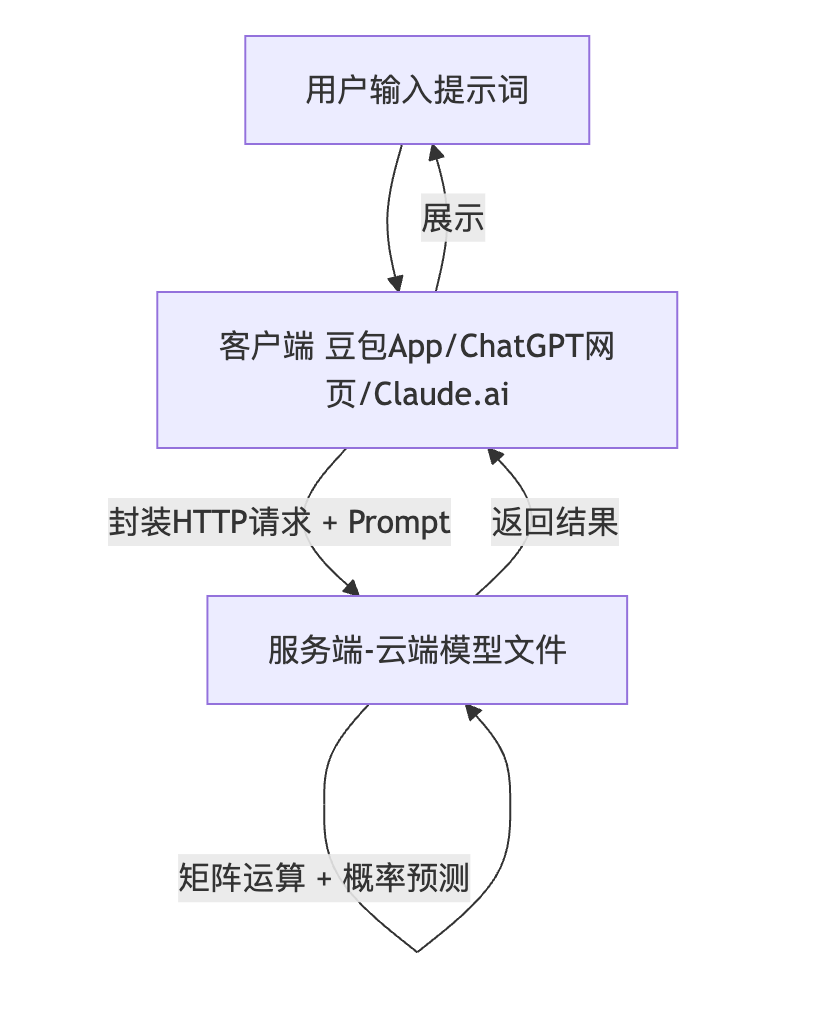
graph TD User[用户输入提示词] --> Client[客户端 (豆包App/ChatGPT网页/Claude.ai)] Client -->|封装HTTP请求 + Prompt| Server[服务端 (云端模型文件)] Server -->|矩阵运算 + 概率预测| Server Server -->|返回结果| Client Client -->|展示| User[用户看到回复]工作原理详解:
- 1.提示词 (Prompt):你输入的文字,类似于搜索引擎的关键词,但更加灵活,包含指令、上下文和约束。
- 2.Token化 (Tokenization):模型将你的文字切分成 Token(可以理解为词或字的片段)。
- 3.概率预测 (Probabilistic Prediction):模型不是在数据库中“查找”答案,而是根据上文计算“下一个字出现的概率分布”。
- 4.逐字生成 (Autoregressive Generation):模型基于概率采样一个字一个字地预测并输出,直到生成完整答案或遇到停止符。
与传统数据库的对比:
- 数据库查询:SELECT * WHERE ID=1 → 确定性结果(永远返回相同数据)。
- 大模型查询:你是什么模型? → 概率性结果(每次表述可能略有不同,甚至产生幻觉)。
关键概念 - Token:
- 1 个 Token ≈ 0.75 个英文单词
- 1 个 Token ≈ 0.5-1 个中文字
- Token 是计费单位,也是衡量上下文长度的标准单位。
1.3 参数量与模型能力
参数量 (Parameters):
- 衡量模型“智力”和体量的单位。
- 通常使用 B (Billion,十亿) 作为单位。
- 基本规律:参数量越大,模型推理能力越强,泛化性越好,但运行成本(显存、计算量)也呈指数级上升。
命名规范解析:
- 以 Qwen 3 Code 30B 为例:
- Qwen:模型名称(通义千问,阿里云出品)。
- 3:第三代版本。
- Code:专门为编程任务微调优化的变体。
- 30B:300亿参数(30 × 10亿)。
- 以 Qwen 3 VL 2B 为例:
- VL:Visual Language(视觉-语言多模态模型),支持图像识别。
- 2B:20亿参数,轻量级。
1.4 算力经济学:显存决定一切
在本地部署模型时,显存(VRAM)是核心瓶颈。而在云端使用时,它决定了你的 API 成本。
换算公式
FP16精度:1B 参数 ≈ 2GB 显存需求
FP8/INT8精度:1B 参数 ≈ 1GB 显存需求
INT4 量化精度:1B 参数 ≈ 0.5~0.7GB 显存需求
实际硬件需求对照表:(我们以为主流 DeepSeek 和 Qwen 的主流进度 FP8 来计算)
2026 大模型 FP8 部署规格多维对照表
| 模型名称 | 模型版本 / 参数量 | 最小显存需求 (FP8) | 推荐显存需求 (FP8) | 硬件配置(参考) |
| Qwen 3 | 0.6B (Dense) | 1.0 GB | 2.0 GB | 树莓派 5 / 入门级显卡 |
| Qwen 3 | 1.7B (Dense) | 2.5 GB | 4.0 GB | RTX 4050 (6G) / 移动端设备 |
| Qwen 3 | 4B (Dense) | 5.0 GB | 8.0 GB | RTX 4060 (8G) |
| Qwen 3 | 8B (Dense) | 9.0 GB | 14.0 GB | RTX 4060 Ti (16G) |
| Qwen 3 | 14B (Dense) | 16.0 GB | 24.0 GB | RTX 4090 (24G) |
| Qwen 3 | 32B (Dense) | 35.0 GB | 48.0 GB | 2x RTX 4090 / RTX 5090 (32G+) |
| Qwen 3 | 30B-A3B (MoE) | 34.0 GB | 45.0 GB | 2x RTX 4090 / Mac Studio (64G) |
| Qwen 3 | 235B-A22B (MoE) | 250.0 GB | 320.0 GB | 4x H100 (80G) / 8x A100 |
| Qwen 3 | Max-Thinking (1T MoE) | 1.1 TB | 1.3 TB+ | 8x B200 (192G) 节点集群 |
| DeepSeek 3.2 | OCR-2 (3B) | 4.0 GB | 6.0 GB | RTX 4060 Ti (16G) |
| DeepSeek 3.2 | VL2-Tiny (3B) | 4.0 GB | 6.0 GB | 消费级显卡均可 |
| DeepSeek 3.2 | VL2-Small (16B) | 18.0 GB | 28.0 GB | RTX 4090 (24G) / RTX 5080 |
| DeepSeek 3.2 | VL2-Full (27B) | 30.0 GB | 42.0 GB | 2x RTX 4090 / RTX 5090 (32G+) |
| DeepSeek 3.2 | V3.2 / R1 (685B MoE) | 750.0 GB | 850.0 GB+ | 8x H200 (141G) / 8x B200 |
| GLM 4.7 | Flash (30B MoE) | 32.0 GB | 42.0 GB | 2x RTX 4090 / RTX 5090 (32G+) |
| GLM 4.7 | Standard (355B MoE) | 380.0 GB | 480.0 GB | 6x H100 (80G) / 4x H200 |
| Minimax M2.1 | Flagship (230B MoE) | 245.0 GB | 300.0 GB | 4x H100 (80G) / 2x H200 |
| Kimi 2.5 | K2.5-Standard (1T MoE) | 1.1 TB | 1.3 TB+ | 8x B200 (192G) NVLink 节点 |
结论:
- 个人电脑只能运行“蒸馏”后的小模型(0.5B-70B),适合简单任务或隐私数据处理。
- 顶级智力(70B+)必须依赖云端 API。
- 企业级私有化部署超大模型需要昂贵的专业算力集群。
1.5 上下文窗口:模型的"记忆力"
什么是上下文 (Context Window):
模型能够“记住”并处理的对话历史长度(包括输入的 Prompt 和生成的 Output)。
- 单位:K(千)或 M(兆)Token。
- 200K = 20万 Token ≈ 15万中文字。
- 1M = 100万 Token ≈ 75万中文字。
为什么上下文在编程中至关重要:
- 1.代码连续性:模型需要记住前面文件的代码结构、变量定义和函数签名。
- 2.避免遗忘:上下文短会导致模型“断片”,忘记之前的设计决策,导致前后代码不一致。
- 3.复杂项目支持:大项目往往涉及几十个文件,需要同时加载才能理解全貌。
对比示例:
- Claude Sonnet 4.5 (1M 上下文):
- 可以一次性加载整个项目的代码库(几十个文件)。
- 可以加载完整的技术文档和 API 手册。
- 可以保留几小时甚至几天的深度对话历史。
- GPT-5.2 (400K 上下文):
- 只能加载核心代码片段。
- 随着对话进行,容易“爆掉”,需要频繁手动清理历史。
实战意义:
上下文长的模型不容易“改错”代码,可以维护更复杂的业务逻辑,是处理大型遗留系统(Legacy System)的唯一解。
🌍 第二章:全球模型军备图谱 (2026 最新版)
选择模型如同赛车手选车,不同赛道需匹配不同引擎。本章基于实际使用经验和 OpenRouter 真实排名数据整理。
2.1 国际第一梯队 (S-Tier)
1.Claude 系列 (Anthropic) —— 编程之王 ⭐⭐⭐⭐⭐
- 核心型号:
- Claude 4.5 Sonnet(编程首选,性价比与能力平衡最好)。
- Claude 4.5 Opus(最顶级,逻辑最强但昂贵)。
- Claude 4.5 Haiku(轻量快速版,适合简单任务)。
- 上下文窗口对比:
| 模型 | 上下文 | 最大输出 | 适用场景 |
| Sonnet 4.5 | 1M | 64K | 编程开发(首选) |
| Opus 4.5 | 200K | 16K | 顶级复杂逻辑任务(昂贵) |
| Haiku 4.5 | 400K | 8K | 快速响应、简单问答 |
- 特点:
- 逻辑严密:在代码生成、架构设计、复杂逻辑推理方面全球无出其右。
- 超长上下文:Sonnet 4.5 支持 1M Token,是竞品的 2.5 倍以上。
- 代码质量高:生成的代码风格统一,错误率低,极少出现幻觉。
- Artifacts 功能:强大的代码预览和交互能力(在官方界面中)。
- 适用场景:复杂系统开发、Bug 调试与修复、架构设计与重构、技术文档生成。
- 价格参考 (OpenRouter):
- Sonnet 4.5:输入 $5/M Token,输出 $25/M Token。
- Opus 4.5:价格更贵,通常仅在 Sonnet 搞不定时使用。
- 重要提示:Claude 的创始人曾在百度硅谷实验室工作,因个人原因,Claude 官方不对中国大陆提供服务。必须通过 OpenRouter 等代理访问,且 IP 必须选择美国或新加坡。
2.Gemini 系列 (Google) —— 多模态与前端专家 ⭐⭐⭐⭐⭐
- 核心型号:
- Gemini 3 Pro(专业版,能力最强)。
- Gemini 3 Flash(快速版,免费额度大)。
- 上下文窗口:两个版本均支持 1M Token。
- 特点:
- 示例:给它一张 UI 设计图,直接生成 HTML/CSS 代码。
- 多模态理解 (Multimodal):可以“看懂”图片、截图、设计稿、PDF、PPT 等文档。
- 前端开发神器:擅长生成美观的网页界面,支持 SVG、Canvas 等复杂图形。可以生成赛博朋克、未来主义等风格的页面。
- 生活百科能力:在医疗健康咨询(如术后康复指导)、生活问题解答方面表现卓越。
- 生态整合:与 Google Workspace、Android Studio (IDX) 深度绑定,可以直接搜索最新网络信息。
- AI Studio (https://aistudio.google.com):Google 提供的网页工具,可以在线生成网页原型,支持实时预览和下载。
- 实战案例:输入“请检索关于黑夜路人谢华亮的资料,生成一个关于他个人的深度介绍网页。必须酷炫、赛博朋克风格、有科技感、详细、不要捏造信息。”
- 执行结果:Gemini 自动搜索 -> 提取资料 -> 设计结构 -> 编写 HTML/CSS/JS -> 实时预览 -> 提供下载。
- 适用场景:前端 UI/UX 开发、网页原型快速生成、图片识别与分析、生活与健康咨询、文档 OCR 与解析。
3.GPT 系列 (OpenAI) —— 基准标杆 ⭐⭐⭐⭐
- 核心型号:GPT-5.2(最新版本)、GPT-5.2 Codex(编程专用版)。
- 上下文窗口:均为 400K Token。
- 特点:综合能力均衡,知名度最高,用户基数大。但在 2026 年的编程垂直领域,尤其是上下文长度和逻辑严密性上,略逊于 Claude 4.5。
- 适用场景:通用对话、文案创作、简单数据分析。
4.Grok (xAI - 马斯克) —— 新兴力量 ⭐⭐⭐⭐
- 背景:伊隆·马斯克创立的 xAI 公司,2023 年成立,发展迅速。
- 核心模型:Grok Code、Grok-3。
- 特点:OpenRouter 排名第三,综合能力强劲,特别擅长实时信息获取(接入 X 平台数据)。
2.2 国内第一梯队 (A-Tier)
国内模型进步神速,且具有网络访问优势和价格优势。
1.豆包 (Doubao - 字节跳动) ⭐⭐⭐⭐⭐
- 定位:日常使用首选,完全免费。
- 特点:
- 文生图:输入描述生成图片。
- 视频生成:可以将图片转换为短视频。
- 语音识别与合成:语音交互体验极佳。
- 免费且强大:无需付费即可使用,功能丰富。
- 多模态能力:
- 网络搜索:可以搜索最新信息,适合信息检索。
- 实战案例:
- 提示:"帮我画一个叫做黑夜路人的男子,他徒手打死一只老虎" → 生成图片。
- 提示:"请把黑夜路人打老虎这个变成一个视频" → 生成动态视频(消耗积分)。
- 适用场景:日常问答、快速检索、图片/视频生成、学习辅助。
2.千问 (Qwen - 阿里云) ⭐⭐⭐⭐⭐
- 特点:
- Qwen Code:专门的编程模型。
- Qwen VL:多模态视觉模型。
- Qwen Math:数学专用模型。
- 开源生态最完善:所有模型版本都开源,可以在 Hugging Face 下载,支持本地部署。
- 专业版本丰富:
- 版本迭代快:Qwen 3 持续更新,参数规模从 0.5B 到 235B 全覆盖。
- 适用场景:本地部署需求、隐私数据处理、编程开发、成本敏感场景。
3.DeepSeek (深度求索) ⭐⭐⭐⭐
- 特点:
- 开源且性价比极高。
- 全尺寸版本:DeepSeek V3(671B 参数)。
- 编程能力:虽然不如 Claude,但在国内模型中表现优秀。
- 注意事项:编程能力相对较弱,不推荐作为主力编程工具,更适合通用对话和逻辑推理。
4.GLM (智谱清言 - 清华系) ⭐⭐⭐⭐
- 特点:学术底蕴深厚,长文本处理能力强,开源版本可用。
5.MiniMax
- 特点:语音和文本模型都不错
6.Kimi
- 特点:长文本、Agent 调度、tool call 等能力
2.3 模型能力排行榜 (OpenRouter 实时数据)
查看方式:访问 openrouter.ai -> 点击 Ranking。
Top 10 排名 (截至分享时):
- 1.Claude Sonnet 4.5 ⭐ (霸榜)
- 2.Gemini 3 Flash Preview
- 3.DeepSeek V3.2
- 4.Kimi K2.5
- 5.Gemini 2.5 Flash
- 6.Grok Code Fast 1
- 7.Claude Opus 4.5
- 8.Grok 4.1 Fast
- 9.Gemini 2.5 Flash Lite
- 10.gpt-oss-120b
- 11.MiniMax M2.1
- 12.GLM 4.7
- 13.Gemini 2.0 Flash
- 14.Gemini 3 Pro Preview
- 15.Grok 4 Fast
- 16.GPT-5.2
- 17.GPT-4o-mini
- 18.GPT-5 Nano
- 19.Claude Haiku 4.5
2.4 模型选择决策树 & 价格对比
编程开发?
- Claude Sonnet 4.5 (首选,平衡性价比,质量高,上下文 1M)
- Claude Opus 4.5(最顶级编程模型,非常牛,上下文稍小,代码质量非常高)
- OpenAI GPT 5.2 或 GPT 5.2 Codex (找 bug,深度解决问题非常强,可以作为 Claude 备选)
预算特别紧张:
- 那就考虑 Kimi 2.5、Grok Code fast、GLM-4.7、Qwen 3、MiniMax m2.1 等等
日常使用:
- 免费:豆包、千问、元宝 (日常简单常规用用)
- 综合能力最强:Gemini (强烈推荐)
🛠️ 第三章:工具搭建和本机运行大模型
工欲善其事,必先利其器。如果你还在用裸机写代码,请立即停止。
3.1 硬件环境:Mac 是唯一正解
- 为什么必须用 Mac:
- AI 工具链深度依赖 Unix 环境:Claude Code、Cursor、Codex、各类 CLI Agent 都是基于 Unix 开发,在 Mac 上运行最顺畅。
- 命令行兼容性:Bash/Zsh 脚本原生支持,无缝衔接服务器环境。
- Windows 的劣势:PowerShell 兼容性差,Docker 调度复杂,环境变量配置繁琐,WSL2 仍有坑点。
- 配置建议:
- 推荐:MacBook Pro M3/M4,24G~32GB 内存。
- 最低:MacBook Pro M1,16GB 内存。
- 团队统一:所有开发人员必须统一配备 Mac,避免环境差异导致的协作问题。
3.2 包管理器:Homebrew
- 定义:macOS 的包管理器,类似于 Linux 的 apt 或 yum。
- 安装:
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"- 常用命令:
- brew search/install/upgrade/uninstall 软件名
- 实战:brew install ollama (安装模型运行环境), brew install node, brew install python@3.11.
3.3 本地模型运行时:Ollama
Ollama 是什么:
AI 时代的 Docker。它标准化了模型的下载、运行和接口暴露,让本地运行大模型像运行容器一样简单。
核心概念对比:
- 镜像 (Image) → 模型 (Model)
- 容器 (Container) → 运行实例
- docker pull → ollama pull
- docker run → ollama run
基本使用流程:
- 1.启动服务:ollama serve
- 2.拉取模型:
- ollama pull qwen3:0.6b (0.6B,最小,适合测试)
- ollama pull qwen3:7b (7B,主流)
- ollama pull deepseek-coder:6.7b
- 3.运行模型:
- ollama run qwen3:0.6b
- 进入交互式对话:>>> 用 Golang 写一个红黑树
Ollama 的优势与局限:
- 优势:完全离线(断网可用)、数据隐私(不上传云端)、免费。
- 局限:智力有限(本地小模型无法与云端 70B+ 模型相比),速度受硬件限制。
3.4 网络与代理:通向世界的钥匙
IP 选择策略:
| 地区 | 兼容性 | 速度 | 推荐度 |
| 新加坡 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | 首选 ⭐ |
| 美国 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | 备选 |
| 日本 | ⭐⭐⭐ | ⭐⭐⭐ | 可用 |
| 香港 | ❌ | ⭐⭐⭐⭐⭐ | 不可用 (被封禁) |
关键配置:TUN 模式:
- 定义:系统级全局魔法,所有应用流量(包括终端命令行)都走魔法。
- 必须开启:否则命令行工具(如 ollama, pip, git)无法连接外部服务器。
- 验证:curl https://api.openai.com 或 curl https://ipinfo.io。
3.5 API 聚合平台:模型超市
OpenRouter (全球最大) ⭐⭐⭐⭐⭐
- 网址:https://openrouter.ai
- 特点:支持几乎所有主流模型,价格透明,API 接口标准化。
- 控制台:Usage (消费记录), Keys (密钥管理), Models (模型列表)。
- 团队管理:可为成员分配独立 Key,设置消费上限。
备选平台:
- Requesty:支持 cc 协议等,可以作为 OpenRouter 备选。
- OneAPI (自建):开源项目,适合有技术能力的团队深度定制。
3.6 飞书:知识管理中枢
飞书妙记 (重点):
- 功能:会议录音录屏、自动转文字、智能摘要、会后提问(如“会议提到了哪些工具?”)。
- 使用:会议中开启录制 -> 会后自动生成记录 -> 导出知识点。
飞书截图 (Mac 神器):
- 快捷键:Cmd + Shift + A。
- 核心功能:滚动截图。可以截取长代码、长网页、长文档,直接喂给 AI 分析。
💻 第四章:AI-Native IDE(集成开发环境)介绍
IDE 已经从单纯的代码编辑器进化为“AI 结对编程工作台”。
4.1 工具演进关系
Cursor (2023) → Windsurf (Codeium) → Kilocode (国内优化版) → Augment → Claude Code / Codex
4.2 Augment —— 比较强 (Tier 0) ⭐⭐⭐⭐⭐
定位:深度集成的 AI 编程助手,具备极强的上下文感知能力。
核心功能详解:
- 1.会话类型 (Critical):
- Chat 模式:纯问答,不修改代码。适合询问技术问题、学习概念。
- Agent 模式:具备文件读写权限、终端执行权限。适合功能开发、Bug 修复、环境配置。
- 创建方法:点击 + 号 -> 选择 New Agent Thread。
- 2.工作模式:
- Architect (架构师):生成技术方案,不写代码。
- Code (编程):直接修改文件。
- Ask (问答):只回答问题。
- Debug (调试):分析报错,定位 Bug。
- Auto-arrange (自动编排):自动规划任务并执行。
- 3.Auto 模式:
- 开启:全自动执行,无需人工确认,一路狂奔。适合简单任务。
- 关闭:每步停下等待确认。适合复杂任务。
- 4.Task 管理 (重要):
- AI 会自动将大任务分解为可视化 Task 列表(如:检查环境 -> 安装 PHP -> 安装 MySQL)。
- 状态:⚪待执行,🟢执行中,✅已完成,❌失败。
- 支持手动添加、删除、调整 Task 顺序。
- 5.Checkpoint (检查点):
- 类似游戏存档。AI 改乱代码时,可以一键 Restore to this point 回滚。
- 最佳实践:配合 Git 使用,每完成一个功能点就 commit。
- 6.模型选择:
- 默认/日常:Claude 4.5 Sonnet。
- 复杂/关键:Claude 4.5 Opus。
- 快速/简单:Claude 4.5 Haiku。
4.3 Cursor —— 主流之选 (Tier 1) ⭐⭐⭐⭐
定位:VS Code 的 AI 魔改版。
核心特性:
- 1..cursorrules 文件 (重点):
- 项目级的系统提示词,每次对话自动加载。
- 用于固化开发规范(如:“使用 PHP 7.4”,“遵循 PSR-12”)。
- 2.Composer (多文件编辑):
- Cmd + I 唤起,支持同时修改多个文件,保持上下文连贯。
- 3.Tab 补全:极其智能的代码预测,支持多行补全。
4.4 终端 Agent:Claude Code / Codex(革命性) ⭐⭐⭐⭐⭐
定位:未来的 AI 开发形态,纯命令行界面,权限极高。
网址:https://code.claude.ai
配置:需要 Anthropic 官方 Key 或 OpenRouter 配置。
强大能力:
- 1.自动环境搭建:
- 指令:"请检查当前机器环境...帮我安装 PHP 7.4..."
- 执行:自动检查 -> 安装 Homebrew -> 安装依赖 -> 配置服务 -> 验证。
- 2.自动代码提交:
- 指令:"请把当前项目提交到 Git,信息为:完成用户登录"
- 执行:git add . -> git commit -> git push。
- 3.浏览器自动化:
- 指令:"请使用 Playwright 打开百度搜索..."
- 执行:自动安装 Playwright -> 启动浏览器 -> 操作页面 -> 提取结果。
4.5 其他工具
- Google Antigravity:有 Gemini 账号可以免费用,免费集成 Gemini 3、Claude、Gpt 等模型,适合 Android/Flutter 开发。
- Windsurf/Kiro/Trae:Cursor 竞品,需付费,各有优势
- 终端开发工具可选:OpenCode、Codex、Claude Code
- 国产工具:Qode、CodeBuddy、Baidu Comate、CodeGeeX
工具选择决策树:
- 有预算/公司报销? → Augment (首选) / Cursor/ Kilocode(OpenRouter)+ Claude Code / Codex(辅助)。
- 预算有限? → Trae / Codebuddy / KiloCode / Qoder (配置便宜模型或国产模型:Claude Haiku 4.5/ Gemini 3 Flash / Grok Code Fast 1,或 DeepSeek 3.2 / Kimi 2.5 / GLM 4.7 / Minimax M2.1 / Qwen 3 Max) + OpenCode。
- 体验 Google 生态? → Antigrivaty (有 Pro 可以免费使用 Claude / Geminie / GPT 120B 等模型)。
⚔️ 第五章:实战AI-Native 开发过程
本章演示如何利用 AI 完成一个项目的全生命周期开发。严禁上来就写代码!
正确流程:Plan(规划)→ Act(执行)→ Verify(验证)→ Iterate(迭代)。
5.1 场景一:环境自动化构建 (Infrastructure as Code)
痛点:手动配置环境耗时且易报错。
AI 模式 (Augment/Claude Code):
- 1.输入指令:
- 2.“请检查当前机器环境。我需要运行一个老旧的 PHP 项目。请帮我安装:PHP 7.4、Apache、MySQL 8.0、Memcached 及所有常用扩展(Redis, GD, PDO等)。
- 3.要求:1. 自动解决版本冲突;2. 自动安装缺失工具(如 Brew);3. 配置服务自启动;4. 编写测试脚本验证环境。”
- 4.AI 执行:
- Task 1: 检查 Homebrew(无则安装)。
- Task 2: brew install php@7.4。
- Task 3: brew install mysql@8.0(自动设置密码)。
- Task 4: pecl install redis。
- Task 5: 生成 test.php 并运行验证。
- 5.结果:10-15 分钟内,环境全自动就绪。
5.2 场景二:遗留项目逆向分析 (Legacy Code Analysis)
痛点:接手无文档的“屎山”代码。
AI 模式:
- 1.全量扫描:
- 提示词:“请扫描当前项目(路径:...)。分析技术栈(确认是 PHP 7.x 还是 5.x)、目录结构、核心业务逻辑、数据库表结构。生成详细的Markdown报告(包含目录树、文件说明、技术栈),保存在 /docs/analysis/ 目录下。”
- 2.数据库还原:
- 提示词:“根据代码中的 Model 和 SQL 逻辑,逆向生成完整的 init_db.sql 建表语句。要求 MySQL 8.0 格式,包含索引、外键和详细注释。”
- 验证:使用 GPT-5 和 Claude 交叉验证 SQL 的正确性。
- 3.流程可视化:
- 提示词:“请梳理‘用户登录’和‘订单支付’的完整业务链路,生成 SVG 格式 的流程图,保存在 /docs/flowcharts/。”
- 查看:直接在浏览器打开 SVG 文件预览。
5.3 场景三:功能开发 (The Plan-Execute Cycle)
案例:新增“多语言发布”功能。
Step 1: 需求对齐与规划 (Plan)
- 提示词:“目标:新增多语言发布和评论功能。要求:1. 先学习现有代码;2. 给出详细执行计划(数据库、API、前端);3. 不要修改代码,只生成设计文档保存在 /docs/plan/。”
- 产出:执行计划.md, 数据库设计.md, API设计.md。
Step 2: 方案评审 (Review)
- 人工检查 AI 生成的计划,确认无误后回复:“批准执行”。
Step 3: 分步执行 (Execute)
- 阶段 1 - 数据库:“执行数据库设计阶段。创建 Migration,编写 SQL,生成 Seeder,执行迁移并验证。” -> 完成后 Git Commit。
- 阶段 2 - 后端 API:“执行后端开发。创建 Model,编写 Controller 和 API 路由,实现 CRUD,必须编写单元测试。” -> 完成后 Git Commit。
- 阶段 3 - 前端页面:“执行前端开发。改造发布页面支持多语言切换,保持现有样式风格。” -> 完成后 Git Commit。
Step 4: 集成测试 (Verify)
- 提示词:“编写集成测试用例,测试完整业务流程(创建文章 -> 添加翻译 -> 评论)。生成测试报告。”
📜 第六章:AI 编程“八荣八耻” (Rules of AI IDE)
为了防止 AI “幻觉”导致的代码灾难,必须将以下规则写入项目的 .cursorrules 或 Augment 的 Rules 中。这是团队开发的底线。
配置文件模板 (.cursorrules / .IDE-NAME/rules/coding-rules.md)
---name: ai-ide-8-rulesdescription: AI IDE 助手配置规则,定义输出格式、代码规范和交互约束,帮助开发者更高效地开发代码---### AI IDE 遵守的八荣八耻- 以瞎猜接口为耻,以认真查询为荣。- 以模糊执行为耻,以寻求确认为荣。- 以臆想业务为耻,以人类确认为荣。- 以创造接口为耻,以复用现有为荣。- 以跳过验证为耻,以主动测试为荣。- 以破坏架构为耻,以遵循规范为荣。- 以假装理解为耻,以诚实无知为荣。- 以盲目修改为耻,以谨慎重构为荣。### AI IDE 遵守的八条军规1. 不猜接口,先查文档。2. 不糊里糊涂干活,先把边界问清。3. 不臆想业务,先跟人类对齐需求并留痕。4. 不造新接口,先复用已有。5. 不跳过验证,先写用例再跑。6. 不动架构红线,先守规范。7. 不装懂,坦白不会。8. 不盲改,谨慎重构。如何固化
- Cursor:在根目录创建 .cursorrules 文件,或者在 .cursor/rules 里粘贴上述内容。
- Augment:在设置或根目录创建 .augment/rules/coding-rules.md。
- 效果:AI 每次回答前都会自动加载并遵守这些规则,极大降低“写飞”的概率。
- 也可以统一放在 .XXX(AI IDE)目录下面的 rules 目录下,可以自动加载
├── .augment # Augment Code 配置入口├── .claude # Anthropic Claude Code 配置入口├── .codebuddy # 腾讯 Codebuddy Code 配置入口├── .cursor # Cursor IDE 配置入口├── .codex # Codex IDE 配置入口├── .kilocode # Kilocode IDE 配置入口├── .opencode # Opencode IDE 配置入口├── .agent/ # Antigrvatiy 配置入口~/.XXX/├── AGENTS.md # AI IDE 全局配置指令(AI 行为规范、技术栈信息)├── mcp.json # MCP (Model Context Protocol) 配置├── agents/ # Sub Agents 和 AI Agents 的存放目录├── commands/ # Slash Command 斜杆命令存放目录├── docs/ # 各种需要存储的文档、标准、工作流描述等存放目录├── hooks/ # Claude Code、Codebuddy Code 的钩子配置目录├── prompts/ # 提示词模板和 AI 通用规则├── rules/ # AI 遵循规则存储目录(claudecode/codex 等会自动加载,请勿过多放置避免上下文溢出)├── scripts/ # 通用运行脚本与工具├── sessions/ # 运行会话历史保存目录├── skills/ # AI 技能配置└── workflows/ # 通用工作流,Antigrvity 下的类 Slash Command- 这些上面一级目录,下面参考的二级目录(就是在入口 IDE 配置路径下一级目录列表)
- 参考配置文件路径:可以配置在 ~/.IDE-NAME 或者是 项目目录/.IDE-NAME 目录下,都可以加载(下面就是 IDE 可能的配置目录入口名称)
🏁 结语:新时代的生存法则
在这场 AI 革命中,未来只有两类程序员:
- 1.超级个体:熟练掌握 Prompt Engineering,利用 AI 能够一人抵十人,专注于架构、业务价值和创新。
- 2.被淘汰者:坚持手写每一行代码,拒绝接触新工具,最终被效率的洪流淹没。
行动清单 (Action Items):
- 1.[ ] 硬件:配置好 Mac 电脑。(推荐 MacBook Pro M3+、Mac Mini M3+ 等机器设备)
- 2.[ ] 账号:注册 OpenRouter,获取 Claude 4.5 Sonnet 权限。
- 3.[ ] 工具:安装 Augment 和 Claude Code,配置好代理。
- 4.[ ] 规范:在项目中部署 .cursorrules 或者 .AI-IDE-NAME/rules/ “八荣八耻”。
- 5.[ ] 实战:下周尝试用“Plan-Execute”流完整重构一个旧模块。
下一步:
- 立即开始行动
- 完成第一个实战项目
- 体验效率提升
- 成为 AI-Native 开发者
记住:
> 工具没有感情,效率不讲情面,你不跟进别人会跟进。
> 拥抱变化,或者被变化吞噬。
> The future is now. 未来已来。
祝你在 AI 时代大放异彩! 🚀
【想要讨论AI编程和AI技术加群,搜索同名 WX 公众号 】

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 11
11 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)