RoboChemist:长范围且符合安全规范的机器人化学实验
25年9月来自BAAI、清华和新加坡南洋理工的论文“RoboChemist: Long-Horizon and Safety-Compliant Robotic Chemical Experimentation”。机器人化学家有望将人类专家从重复性工作中解放出来,并加速科学发现,但目前仍处于起步阶段。化学实验涉及对危险且易变形物质进行长时间的操作,成功不仅需要完成任务,还需要严格遵守实验规范。为了
25年9月来自BAAI、清华和新加坡南洋理工的论文“RoboChemist: Long-Horizon and Safety-Compliant Robotic Chemical Experimentation”。
机器人化学家有望将人类专家从重复性工作中解放出来,并加速科学发现,但目前仍处于起步阶段。化学实验涉及对危险且易变形物质进行长时间的操作,成功不仅需要完成任务,还需要严格遵守实验规范。为了应对这些挑战,提出Robo-Chemist,这是一个双环框架,它集成视觉-语言模型(VLM)和视觉-语言-动作(VLA)模型。与以往依赖深度感知且难以处理透明实验器材的基于VLM 系统(例如 VoxPoser、ReKep)以及缺乏复杂任务语义级反馈的现有VLA系统(例如 RDT、π0)不同,本方法利用 VLM 作为:(1)规划器,将任务分解为基本动作;(2)视觉提示生成器,引导 VLA 模型;(3)监控器,评估任务成功率和合规性。值得注意的是,其引入一个 VLA 接口,该接口可以接收来自 VLM 的基于图像视觉目标,从而实现精确的、目标导向的控制。系统能够成功执行基本动作并完成多步骤化学实验方案。结果显示,与最先进的 VLA 基线系统相比,平均成功率提高 23.57%,平均合规率提高 0.298,同时还展现出对不同物体和任务的良好泛化能力。
视觉语言模型(VLM)[8, 9, 10, 11, 12, 13, 14, 15, 16, 17] 和视觉语言动作(VLA)模型[18, 19, 20, 21, 22, 23] 的最新进展使得在各种环境中实现可扩展的机器人策略成为可能。然而,在化学实验室中,它们的局限性尤为突出。基于 VLM 的系统,例如 VoxPoser [24] 和 ReKep [25],严重依赖深度传感器和物体分割,难以处理透明容器和可变形物质 [26]。另一方面,VLA 模型,例如 π0 [21] 和 RDT [20],虽然擅长动作定位,但缺乏高层次的语义理解或闭环反馈,这常常导致在复杂任务中出现不安全或失败的行为。如图 (b) 所示,这些方法在简单的实验室任务中成功率和合规率都很低。
为了应对这些挑战,提出 RoboChemist,这是一个双环框架,它通过视觉提示和语义监督集成VLM和VLA。如图 (a) 所示,RoboChemist 使用 VLM 作为:(1) 规划器;(2) 视觉提示生成器,通过边框或关键点突出显示特定任务的抓取或目标区域;以及 (3) 监控器,评估子任务的成功并强制执行闭环修正。VLA 模型使用提示图像、观察的状态和文本指令来执行每个基本任务,从而实现目标导向和安全合规的控制。这种设计使系统能够在局部执行的同时进行全局推理,将高级语义结构与低级灵巧性相结合。执行的任务如图(c)所示。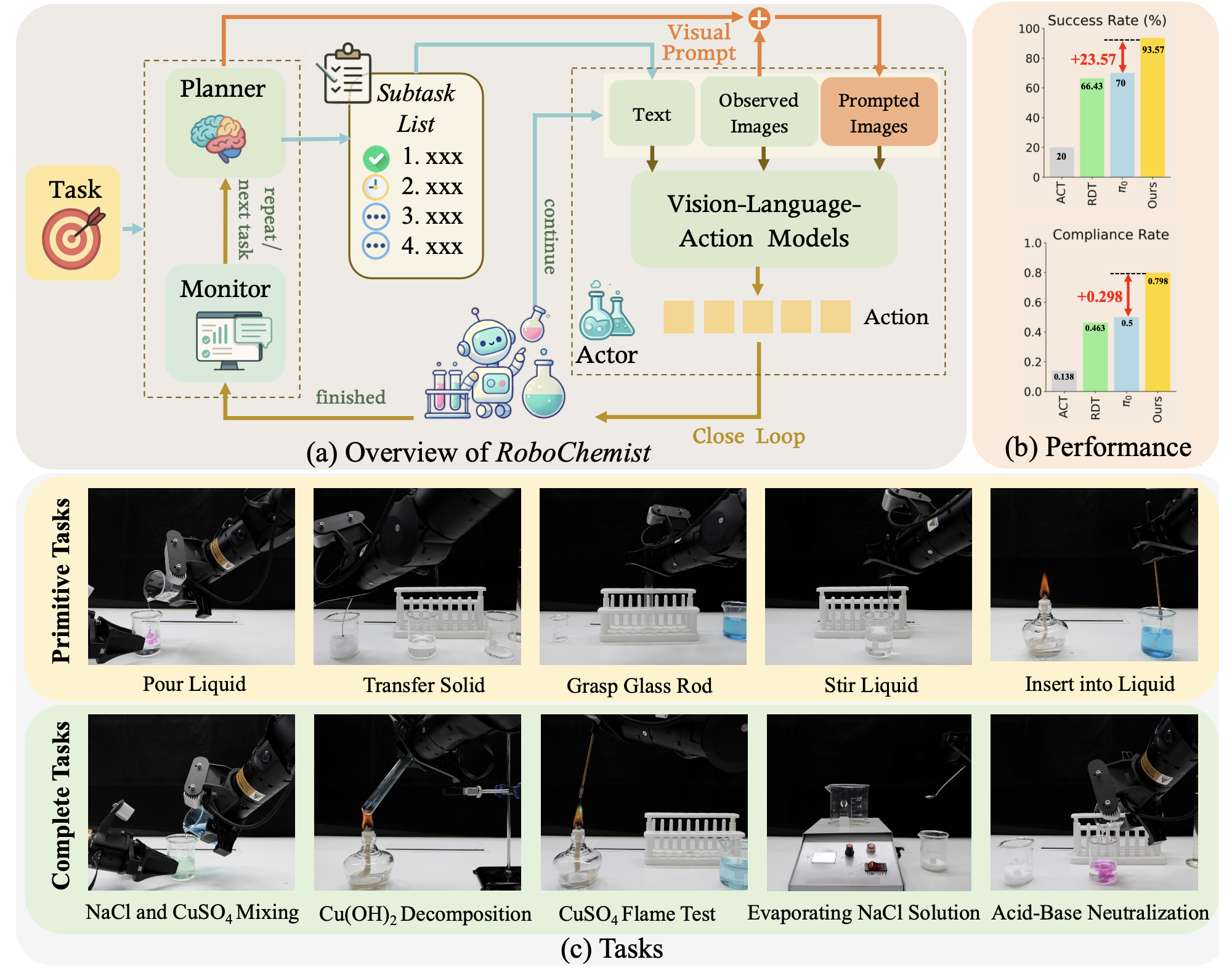
化学领域的机器人自动化取得显著进展,涵盖有机合成[4, 7]、材料合成[2]、微孔板操作[74]以及移动式化学探索器[1, 75, 3]等领域。然而,这些系统通常依赖于专用硬件和预定义指令,限制其在不同任务间的灵活性和通用性[5, 6]。近期的一些研究,例如Organa[76]、ArChemist[77]以及液体处理方法[78, 79],在一定程度上解决这些局限性,但仍然主要局限于单臂操作,且针对特定场景。Chemistry3D基准测试[80]引入一个模拟环境来评估化学领域的通用操作,但未能解决真实化学实验的复杂性。
相比之下,本文工作提出了一种利用基础VLA模型的通用双臂协作方法。这使得在各种化学实验中进行灵活操作成为可能,而无需依赖专门的硬件或严格的特定任务编程,旨在提高机器人实验室应用的实用性和可扩展性。
概述
上图 (a) 展示 RoboChemist 的整体流程,该流程由 VLM 和 VLA 模型构成的闭环系统组成。当研究人员指定化学实验任务以及所需的仪器和试剂时,VLM 作为规划器,将任务分解为一系列可执行的基本任务。对于每个子任务,VLM 会根据化学实验的具体操作规程生成详细的指导原则,然后使用视觉提示在正面视图中突出显示抓取点、目标点或边框(如下图所示)。该参考图像以及来自其他摄像头视角的观察结果和相应的语言指令被提供给 VLA 模型,以执行每个基本任务。每个子任务完成后,VLM 作为监控器,评估当前状态。如果子任务成功完成,系统将进入下一步;否则,将重复当前任务直至成功完成。这形成了一个完整的闭环反馈系统,既保证了安全性,又提高了成功率,并且具有高度可解释性。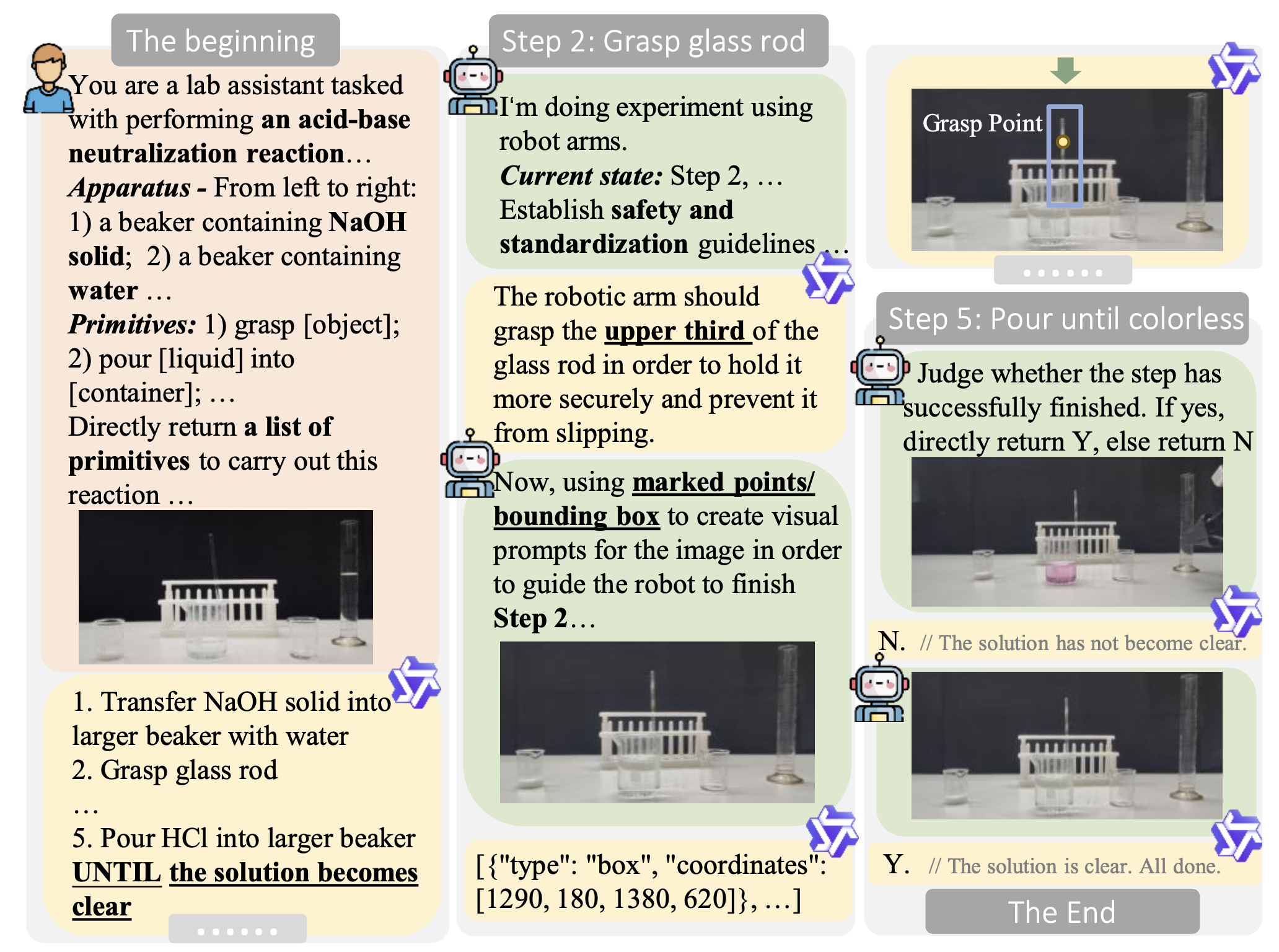
上图中展示的实验详细步骤如下:1)步骤 1:研究人员提供完整的任务说明、初始场景设置和可用的基本任务,随后由RoboChemist进行任务分解。2)步骤2:在抓取玻璃棒的步骤中,RoboChemist使用视觉提示突出显示边框和抓取点,以确保符合安全准则,并为后续操作提供参考。3)步骤5:RoboChemist的闭环系统观察实验状态,并持续添加酸,直至溶液变为无色,此时任务完成,实验终止。
视觉提示
动机。虽然VLA模型在感知场景方面表现出强大的能力,但当仅依赖文本提示作为指令时,其能力仍然有限[81, 44],尤其是在存在许多视觉相似物体的环境中,例如涉及多个容器的化学实验。在这种情况下,视觉提示可以极大地缓解这一问题。将独立VLA模型与基于视觉提示的方法RoboChemist在液体倾倒任务上的性能进行比较。该任务要求在两到三个杯子中,将液体从两个特定的杯子转移出去。下表的结果表明,随着杯子数量的增加,性能会下降,这凸显了视觉提示的必要性。
然而,尽管存在多种基于视觉提示的方法,但大多数方法在重建透明物体或确保安全可控的执行方面都面临挑战[26]。为了说明这一点,设计一个实验,其中指示机械臂在火焰上加热固体,如图所示。在该实验中,ReKep[25]难以重建透明试管,导致抓取失败,如图(a)所示。预先计算抓取候选点而不考虑文本指令的方法通常在标准设置下有效,但可能无法满足化学实验中至关重要的安全性和程序要求。如图(b)所示,MOKA[73]选择中心作为抓取点,导致不安全的操作。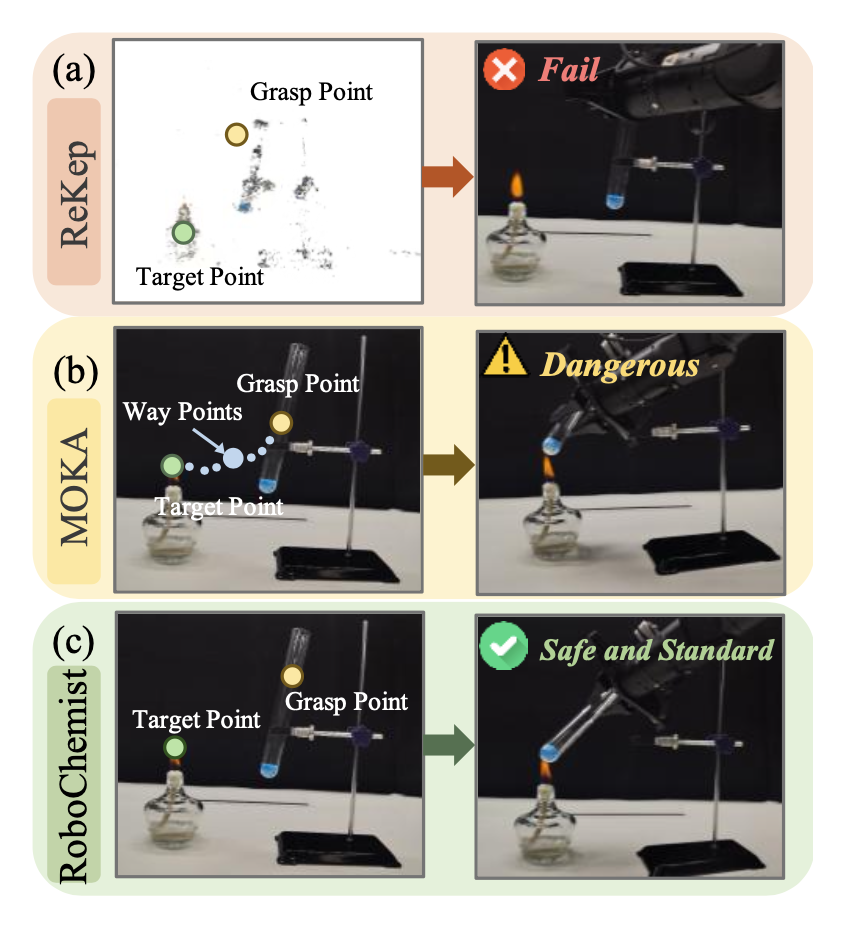
提出的方法。为了克服现有方法的局限性,引入一个框架,用于自主生成特定任务的安全指南和视觉提示。该方法首先将实验的当前状态(包括待执行的具体基本任务和实验台图像)作为输入,提供给VLM,以生成详细的安全指南。这些生成的指南涵盖诸如透明实验器皿上的安全抓取区域或化学品处理注意事项等注意事项,所有这些都无需人工干预。接下来,模型利用这些信息生成以边界框或关键点形式呈现的视觉提示。得益于 Qwen-2.5-VL [12] 的精细定位能力,即使在视觉上模糊不清的情况下,也能可靠地识别关键点/区域。
所提出的方法展现其端到端的简洁性和高精度。如上图 © 所示,抓取点位于试管的上部(避开加热区域),而目标点则确保材料加热的正确位置。在前面提到的实验步骤中,步骤 2的机械臂任务是抓取一根玻璃棒。
闭环系统设计
利用失败试验增强内环。VLA 模型本身具有一个闭环,它获取实时图像和状态信息作为输入,并生成动作来干扰环境。然而,该循环会在一次失败尝试后终止。为了增强循环的自纠错能力和鲁棒性,在训练数据中引入一些场景:在一次失败的尝试后,系统会自动尝试第二次执行。这种方法并非仅仅依赖于成功的单次任务,而是提高VLA 模型的反馈能力,从而增强内环。
利用监控器建立外环。内环缺乏明确的反馈机制,因此无法区分成功和失败,也无法支持需要持续监控的长时程行为。RoboChemist 引入一个外环,将 VLM 集成为监控器。每次内环循环结束后,当前场景图像会被输入到 VLM,由 VLM 评估每个基本任务是否达到预期目标,并实现从失败中恢复。对于复杂的、需要多次重复的任务,外层循环还可以提供持续的反馈。例如,在实验的步骤 9 中,最初尝试倒入酸液并没有完全中和碱液——酚酞指示剂仍然呈粉红色即可证明这一点。因此,外层循环会触发重新执行倒入酸液的操作,直到溶液澄清为止。通过这种机制,外层循环将多个离散的动作组合成一个连贯的序列,从而近似于连续行为。
此外,外环还起到规划器的作用,将复杂任务分解成一系列基本子任务。如实验步骤开头所示,RoboChemist 利用已知的装置配置将酸碱中和反应分解成一系列基本步骤。
实验设置
硬件平台。该系统采用 Cobot Magic ALOHA 双臂机器人,每条手臂具有 7 个自由度。它配备了四个 D435 深度摄像头,但仅使用位于两个手腕、前方和俯视视角的摄像头采集的 RGB 数据。NVIDIA RTX 4090 GPU 负责数据采集和模型推理。
数据采集。为了对 VLA 模型进行微调,为每个基本任务采集 400 个数据样本。为了确保任务的泛化能力,针对每个基本动作,在实验场景设置和物体选择上都引入多样性。例如,在液体倾倒任务中,改变液体的颜色(例如,蓝色、红色、无色等)、体积(例如,小、中、大等)、容器类型(例如,烧杯、试管、量筒等)以及周围环境的布局。数据采集频率与推理频率一致,均设置为 20 Hz。所有数据均以 Parquet 或 HDF5 格式存储用于训练。
基线模型。为了评估 RoboChemist,考虑机器人双臂操作领域的高级基线模型:ACT [82]、RDT [20] 和 π0 [21]。所有模型均使用收集的数据在相同设置下进行微调。ACT 是双臂操作领域最先进的方法,它利用 Transformer 进行动作分块。RDT-1B 使用 DiT 架构,这是最新的双臂基础模型。π0 使用 VLA 架构,展现出跨任务和机器人平台的强大泛化能力。
评价指标。用两个指标评估每个基本任务:成功率 (SR) 和执行率 (CR)。对于每个任务,进行 20 次试验。SR 的计算方法是成功试验次数与总试验次数的比值。为了评估化学实验中动作的精确度,引入 CR。例如,在抓取玻璃棒任务中,抓取失败记为 0 分,抓取位置错误(例如,不在玻璃棒的 1/3 处)记为 0.5 分,成功且符合指令的抓取记为 1 分。
模型训练和推理。用收集的数据对 π0 [21] 模型进行微调,在四个 L20 GPU 上对每个任务进行 3 万步的训练。在训练过程中,除了用于数据收集的四个摄像头视角拍摄的图像外,还应用 Qwen2.5-VL-72B-Instruct [12] 视觉提示来标记每个基本任务初始实验场景中的抓取点和目标点。这些图像以及语言指令和本体感觉状态被用作微调 VLA 模型的输入。为了使语言指令多样化,用 GPT-4o [83] 生成各种命令变型。推理在 NVIDIA RTX 4090 GPU 上以 20 Hz 的频率实时执行。
化学任务
基本任务。为了实现更广泛的化学实验,将标准化学任务分解为 7 个基本任务,包括抓取玻璃棒、加热铂丝、将铂丝插入溶液、倾倒液体、用玻璃棒搅拌溶液、转移固体以及按下按钮。
完整任务。在训练完基本任务后,开始执行完整的实验任务。选择五个完整的化学实验任务,每个任务依次包含1到5个基本任务。如图展示RoboChemist完成任务的实验过程和现象。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 5
5 0
0- 0



 已为社区贡献199条内容
已为社区贡献199条内容

所有评论(0)