从RNN到LSTM:循环神经网络的进化之路
其实回顾两张图片的结构差异,就能明白循环神经网络的进化逻辑:RNN解决了“神经网络能否有记忆”的问题,而LSTM解决了“如何让记忆更持久、更精准”的问题。对于我们AI应用开发工程师来说,理解它们的原理,不仅能帮我们在项目中快速选对模型(比如短文本用RNN省资源,长文本用LSTM保效果),更能为后续学习GRU(LSTM的简化版)、Transformer(当前NLP的主流模型)打下基础——毕竟,所有复
目录
做深度学习、NLP相关开发的同学,肯定都被一个问题困扰过:如何让神经网络“记住”序列数据的上下文?比如处理一句话时,让模型知道开头的主语和结尾的谓语对应;处理时间序列时,捕捉前后时刻的关联。普通前馈神经网络做不到这一点——它把每个输入都当作独立个体,没有“记忆”能力。而循环神经网络(RNN)及其进化版LSTM,正是为解决这个问题而生的。今天就结合两张经典结构图,用通俗的语言拆解它们的核心原理,新手也能轻松看懂~
先跟大家同步下核心前提:我们下文提到的两张图片,分别对应「RNN展开结构图」和「LSTM内部门结构与细胞状态图」,后续会逐一结合图片细节拆解,帮大家把抽象的原理和直观的结构对应起来,理解更高效。
一、RNN:让神经网络拥有“短期记忆”的初代方案
在RNN出现之前,处理文本、语音这类带有序依赖的数据,一直是深度学习的痛点。直到RNN引入“隐藏状态”这一核心设计,才真正让神经网络拥有了“记住过去”的能力,而这一点,从第一张「RNN展开结构图」中就能清晰看明白。
1. 核心设计:隐藏状态(短期记忆载体)
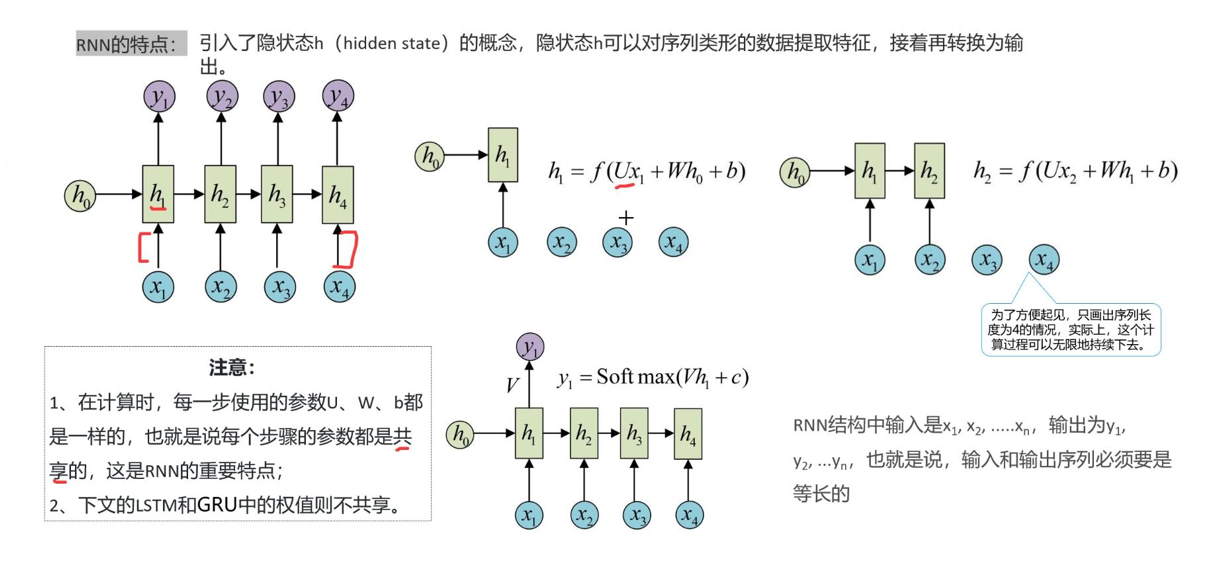
结合第一张RNN展开结构图,我们能直观看到它的工作流程:RNN的核心是「隐藏状态(hidden state)」,可以把它理解为网络的“短期记忆本”——它会记录当前输入与之前所有输入的关联信息,然后传递到下一个时间步,让网络能够串联起整个序列。
具体来说,结构图中清晰标注了三个关键元素:输入序列(x₁、x₂、…、xₜ)、隐藏状态(h₀、h₁、…、hₜ)、输出序列(y₁、y₂、…、yₜ),它们的计算逻辑的如下:
1. 初始隐藏状态为h₀(可理解为“空白记忆”),当输入第一个序列元素x₁时,网络会结合空白记忆,计算出新的隐藏状态h₁,公式如下:
h_1 = f(Ux_1 + Wh_0 + b)
其中f是激活函数(通常用tanh,用来做归一化,效果是把矩阵数值压缩到-1到1之间),U、W、b是网络的固定参数,核心作用就是“整合当前输入和过往记忆”。
2. 当输入第二个元素x₂时,新的隐藏状态h₂不会“忘记”h₁,而是基于x₂和h₁重新计算,以此类推,直到处理完整个序列。
3. 每一步的隐藏状态hₜ,经过简单的线性变换和Softmax处理后,就会得到当前时间步的输出yₜ(比如文本分类中的“类别概率”、语音识别中的“字符预测”):
y_t = Softmax(Vh_t + c)
2. 关键优势:参数共享(轻量化核心)
第一张图中还有一个容易被忽略,但极其重要的细节:所有时间步的计算,使用的参数U、W、b都是完全共享的。这也是RNN的核心优势之一。
举个例子:如果我们处理一句包含10个单词的句子,普通前馈网络需要为每个单词单独设计一套参数,而RNN只需要一套参数就能应对——无论序列多长,参数量都不会增加。这既保证了模型的简洁性,也让RNN能够灵活处理任意长度的序列(比如一句话、一段语音、一组时间序列数据)。
3. 致命局限:天生“健忘”,扛不住长序列
虽然RNN解决了“记忆”的有无问题,但它的记忆只有“短期有效期”——当序列变长时(比如一段话超过20个单词),早期输入的信息会在隐藏状态的传递过程中被不断稀释,就像我们记很长的句子,记到结尾就忘了开头。
从技术层面来说,这是因为RNN训练时采用“通过时间反向传播(BPTT)”算法,早期时间步的梯度会被反复乘以权重矩阵W,容易出现「梯度消失或梯度爆炸」的问题——梯度太小,参数就无法有效更新,网络自然学不会记住早期的信息;梯度太大,模型训练会变得不稳定。
比如处理“我昨天去了北京,今天在那里吃了火锅”这句话,RNN可能无法将“那里”和“北京”关联起来,这就是它“健忘”的核心问题,也正是LSTM要解决的痛点。
二、LSTM:给“记忆”装开关,解决RNN的“健忘症”
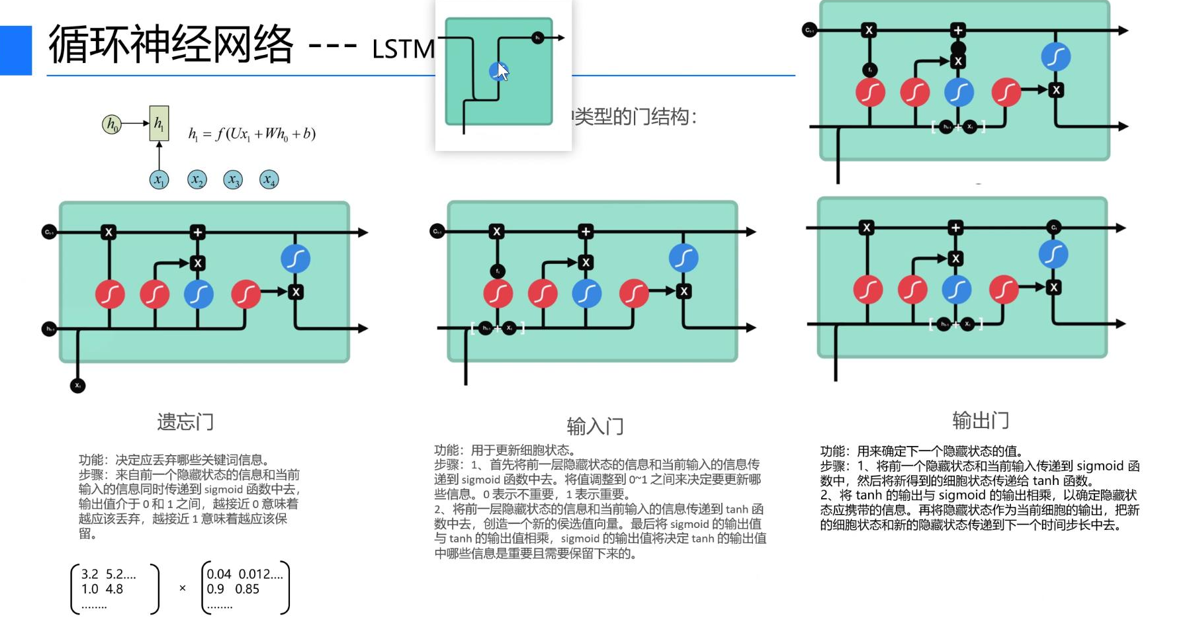
为了攻克RNN的长距离依赖难题,1997年研究者提出了LSTM(长短期记忆网络)——它并没有抛弃RNN的核心逻辑,而是在其基础上增加了“细胞状态”和“门结构”,相当于给神经网络的“记忆本”加上了“筛选开关”,让它能自主决定“忘记什么、记住什么、输出什么”。这一切,从第二张「LSTM内部门结构与细胞状态图」中就能清晰看懂。
1. 核心创新:细胞状态(信息高速公路)+ 三门结构
对比第一张RNN图,第二张LSTM图最明显的变化的是:多了一条贯穿整个序列的「细胞状态(cell state)」,以及三个独立的“门模块”(遗忘门、输入门、输出门)。
我们可以这样类比:细胞状态就像一条“信息高速公路”,信息可以在上面稳定传递,不被轻易稀释(解决RNN记忆易丢失的问题);而三个门结构,就像高速公路上的“收费站”,精准控制信息的“进、出、留”,对应第二张图中的三个核心模块,逐一拆解如下:
(1)遗忘门:决定“忘记什么”(筛选旧信息)
遗忘门的核心作用,是筛选细胞状态中需要保留或丢弃的旧信息,对应第二张图中最左侧的模块。
它的工作逻辑很简单:接收前一步的隐藏状态hₜ₋₁(过往记忆)和当前输入xₜ(当前信息),经过sigmoid激活层处理后,输出一个0~1之间的值——0表示“完全丢弃该信息”,1表示“完全保留该信息”。
举个实际场景:处理文本时,当话题从“北京旅游”切换到“美食推荐”,遗忘门会输出接近0的值,丢弃“北京景点”等无关旧信息,避免无关记忆干扰后续判断;而如果话题一直围绕“北京”,遗忘门会输出接近1的值,保留相关记忆。
(2)输入门:决定“记住什么”(筛选新信息)
输入门对应第二张图中间的模块,核心作用是筛选当前输入中,哪些新信息需要存入细胞状态(相当于给“记忆本”添加新内容),分为三步:
1. 第一步:用sigmoid层“筛选”——判断当前输入xₜ中,哪些信息是有用的(输出接近1),哪些是无用的(输出接近0);
2. 第二步:用tanh层“生成候选信息”——将当前输入xₜ和过往记忆hₜ₋₁整合,生成一套“候选新记忆”;
3. 第三步:将“筛选结果”和“候选新记忆”相乘,得到最终需要添加到细胞状态的内容,相当于“只把有用的新信息,写入记忆本”。
场景示例:处理“今天在故宫吃了文创雪糕”这句话,输入门会筛选出“故宫”“文创雪糕”这些关键信息,存入细胞状态,而忽略“今天”“在”这类无关虚词。
(3)输出门:决定“输出什么”(筛选待传递信息)
输出门对应第二张图最右侧的模块,核心作用是筛选细胞状态中,哪些信息需要作为当前隐藏状态hₜ,传递到下一个时间步(相当于“从记忆本中,提取有用的内容,留给下一次使用”),同样分为三步:
1. 第一步:将前一步隐藏状态hₜ₋₁和当前输入xₜ传入sigmoid层,得到“筛选系数”;
2. 第二步:将更新后的细胞状态,经过tanh层处理(让信息范围归一化,更易计算),生成“候选输出”;
3. 第三步:将“筛选系数”和“候选输出”相乘,得到当前的隐藏状态hₜ——它会被传递到下一个时间步,同时作为当前时间步的输出yₜ。
2. 核心优势:轻松捕捉长距离依赖
结合第二张图的结构,我们就能明白LSTM为什么能解决RNN的“健忘症”:
1. 细胞状态(信息高速公路)保证了信息可以稳定传递,不会像RNN的隐藏状态那样,被反复处理后稀释;
2. 三个门结构精准控制信息的“遗忘、存入、输出”,避免了无关信息的干扰,同时有效缓解了梯度消失问题——早期有用的信息,可以通过细胞状态稳定传递到后期,不会被轻易丢弃;
3. 实际应用中,LSTM能轻松捕捉长距离依赖:比如机器翻译中,记住一句话开头的主语(如“小明”),在结尾生成对应的谓语(如“去了”);文本生成中,保证上下文语义连贯;时间序列预测中,捕捉早期数据对后期的影响。
三、RNN vs LSTM:实际开发中该怎么选?
很多同学在项目中会纠结,到底该用RNN还是LSTM?结合两张图的结构差异和实际开发经验,整理了一张对比表,一目了然(建议收藏):
|
对比维度 |
RNN |
LSTM |
|---|---|---|
|
结构复杂度 |
简单(仅隐藏状态,无门结构) |
复杂(细胞状态+三个门结构) |
|
计算效率 |
高(参数量少,计算步骤简单) |
稍低(参数量多,门结构需多步计算) |
|
长距离依赖 |
难以捕捉(梯度消失/爆炸) |
轻松捕捉(细胞状态+门结构) |
|
适用场景 |
短序列、低依赖场景(如短文本分类、简单时序预测) |
长序列、高依赖场景(如机器翻译、文本生成、语音识别、复杂时序预测) |
写在最后:从RNN到LSTM,本质是“让记忆更聪明”
其实回顾两张图片的结构差异,就能明白循环神经网络的进化逻辑:RNN解决了“神经网络能否有记忆”的问题,而LSTM解决了“如何让记忆更持久、更精准”的问题。
对于我们AI应用开发工程师来说,理解它们的原理,不仅能帮我们在项目中快速选对模型(比如短文本用RNN省资源,长文本用LSTM保效果),更能为后续学习GRU(LSTM的简化版)、Transformer(当前NLP的主流模型)打下基础——毕竟,所有复杂模型的核心,都是从这些基础结构演变而来的。
看到这里,相信你已经能结合两张图片,理清RNN和LSTM的核心逻辑了~ 你在实际开发中用过这两种模型吗?有没有遇到过梯度消失、参数调优的坑?欢迎在评论区交流你的实践经验!
#深度学习 #RNN原理 #LSTM详解 #NLP基础 #AI开发实战

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 16
16 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)