深度学习篇---HDE
我用最通俗的方式介绍HED——这是用深度学习做边缘检测的里程碑。
一句话核心思想
HED = “用AI学画画的小孩”
传统的Canny、Sobel是老师教规则(“看到颜色突变就画线”),而HED是让AI自己看千万张图,学会“物体的轮廓应该怎么画”。
一、最生动的比喻:美术班的故事
传统方法班(Canny/Sobel):
-
老师:拿出一张苹果照片
-
教法:“同学们,记住规则:哪里亮暗变化大,就在哪里画线”
-
结果:所有学生都按照这个固定规则画出了苹果的亮暗边界
-
问题:有人把苹果上的反光高光也当成轮廓画了,有人把影子边缘也画进去了
HED深度学习班:
-
老师:拿出1万张各种物体的照片和对应的“完美轮廓线稿”
-
不说任何规则,只让学生自己看、自己琢磨
-
学生(AI):看了几个月后,自己总结出:
-
“哦,原来物体和背景交界处通常要画线”
-
“物体表面的纹理(如苹果斑点)通常不画线”
-
“影子边缘不算物体轮廓”
-
“反光高光内部不画线,但反光与物体的交界有时要画”
-
-
结果:这个学生画出的轮廓更接近人眼理解的“物体边界”,而不是简单的“颜色突变处”
二、HED到底是什么?
HED = Holistically-Nested Edge Detection
-
Holistically:整体的
-
Nested:嵌套的
-
整体嵌套边缘检测
通俗解释:让一个深度神经网络同时看图像的“整体”和“细节”,然后把不同尺度的理解融合起来,预测哪里是边缘。
三、HED的核心创新:多尺度感受野
1. 传统方法的局限
Canny、Sobel只用固定大小的窗口(如3×3)看局部:
-
看到纹理细节,但看不到大结构
-
容易把树叶纹理误认为边缘,却漏掉整棵树的轮廓
2. HED的做法:让网络“既见树木,又见森林”
HED使用VGG-16网络作为主干,它有5个不同深度的阶段:
输入图像 → 网络前传 → 第1层:看到3×3像素的小细节(如毛发) 第2层:看到稍大的局部(如眼睛轮廓) 第3层:看到更大区域(如整张脸) 第4层:看到半身像 第5层:看到整个人体轮廓
关键:HED让每一层都输出自己的边缘预测图,然后把5张图融合!
四、HED的网络结构(通俗版)
想象一个五层楼的观察塔:
每层楼的观察员:
-
一楼观察员:拿着放大镜,只看几毫米范围
-
能看到:皮肤毛孔、发丝末端
-
输出的边缘图:非常精细,但杂乱(全是纹理)
-
-
三楼观察员:透过窗户看
-
能看到:眼睛、鼻子、嘴巴的局部
-
输出的边缘图:中等尺度的特征
-
-
五楼观察员:站在楼顶俯瞰
-
能看到:整个人体的整体轮廓
-
输出的边缘图:很粗的轮廓线,但抓住了大结构
-
总指挥(HED):
-
收集各楼报告:拿到5张不同尺度的边缘图
-
加权融合:
-
给高层(大尺度)的预测更高权重(因为更接近“语义边界”)
-
但也会参考低层(小尺度)的精细信息
-
-
输出最终地图:一张既包含整体轮廓、又有精细细节的边缘图
这就是“嵌套”的含义:不同尺度的理解被嵌套在一起,共同决策。
五、HED的训练:怎样教AI?
训练数据是关键!
需要大量“图像-边缘图”配对数据:
-
输入:普通照片
-
标签:人工精心标注的边缘图(只画人眼认为的重要边界)
-
物体与背景的边界 ✓
-
物体的内部结构边界(如衣服褶皱)有时画 ✓
-
纹理细节(如牛仔布料纹理)不画 ✗
-
阴影边界不画 ✗
-
损失函数的设计智慧
HED不是只监督最终输出,而是监督每一层的输出!
-
对一楼、三楼、五楼…每个观察员的预测都进行评分
-
强迫网络在每一层都学到有用的边缘信息
-
最终融合时自然更好
就像教学生:不仅要看他最终考试成绩,还要检查他每章的学习笔记。
六、HED vs. 传统方法的直观对比
| 场景 | Canny/Sobel会怎样 | HED会怎样 |
|---|---|---|
| 一个人穿格子衬衫 | 把每个格子纹都检测为边缘 (满身都是线) |
只检测人体轮廓和主要褶皱 (忽略格子纹理) |
| 树丛 | 每片叶子边缘都检测 (一团乱麻) |
检测树冠的整体轮廓 (忽略大部分叶子细节) |
| 玻璃杯 | 检测所有反光和折射 (内部很多乱线) |
检测玻璃杯的外轮廓 (理解这是透明物体的边界) |
| 模糊照片 | 几乎检测不到边缘 | 凭借“经验”脑补出可能的边缘 |
核心区别:传统方法检测低层特征(颜色突变),HED学习检测高层语义边界(物体/部分的交界)。
七、HED的实际效果
优点:
-
更符合认知:边缘更像是“人画的轮廓线”
-
抗纹理干扰:能忽略衣服纹理、树叶纹理等
-
处理模糊图像:有一定“脑补”能力
-
端到端:输入图像,直接输出边缘图,无需调参
缺点:
-
需要大量训练数据
-
计算量大(比Canny慢得多)
-
可能过度“脑补”:在非常模糊的地方画出不存在的边缘
-
训练好后固定:不像Canny可以调节参数适应不同场景
八、HED的应用场景
1. 图像编辑与设计
-
智能抠图:边缘更准确,特别是毛发、透明物体
-
自动生成线稿:用于漫画、插画创作
-
照片转素描:效果更艺术
2. 计算机视觉研究
-
作为其他任务的预处理(如实例分割)
-
研究“人类如何感知边缘”的模型
3. 医学图像分析
-
分割器官边界时更准确
-
能区分组织纹理和真实边界
4. 自动驾驶(辅助)
-
帮助理解场景的语义结构
-
但实时性不够,通常作为离线分析工具
九、一个有趣的思想实验
给你看两张图:
图A:用Canny处理的人像
-
你能看到:脸部轮廓、眼睛轮廓、鼻孔、每根睫毛、皮肤毛孔、头发丝…
-
问题:太多细节!分不清主次
图B:用HED处理的人像
-
你能看到:脸部轮廓、眼睛和嘴巴的整体形状、头发的大致区域边界
-
特点:简洁、像简笔画、抓住了“神韵”
HED学会了“概括”和“取舍”——这是人类画家的核心技能!
十、HED的后续发展
HED(2015年提出)启发了更多深度学习边缘检测方法:
-
RCF:更密集的多尺度融合,边缘更精细
-
BDCN:双重监督,更好地区分“对象边界”和“普通边缘”
-
最新的Transformer方法:利用注意力机制,理解全局上下文
发展趋势:从“检测所有突变” → “检测语义边界” → “理解不同层次的边界含义”。
终极生活化总结
把HED想象成一个“看了百万张素描的AI画家”:
-
它不是按规则画(不像Canny有固定数学公式)
-
它是凭感觉画(基于从海量数据中学到的“经验”)
-
它懂得取舍:
-
重要的边界(物体轮廓) → 用力画
-
次要的细节(表面纹理) → 轻轻带过或忽略
-
无关的变化(阴影、反光) → 基本不画
-
-
它多尺度观察:
-
既看细节(确保精准)
-
又看整体(确保结构正确)
-
-
最终效果:画出来的边缘图更像人画的,而不是机器算的。
记住这个核心:HED代表着边缘检测从“低层信号处理” 到“高层语义理解” 的范式转变。它不再问“这里颜色突变大吗?”,而是问“这里是人眼会认为是物体边界的地方吗?”
这就是深度学习的魔力——让机器学会人类的“直觉”。
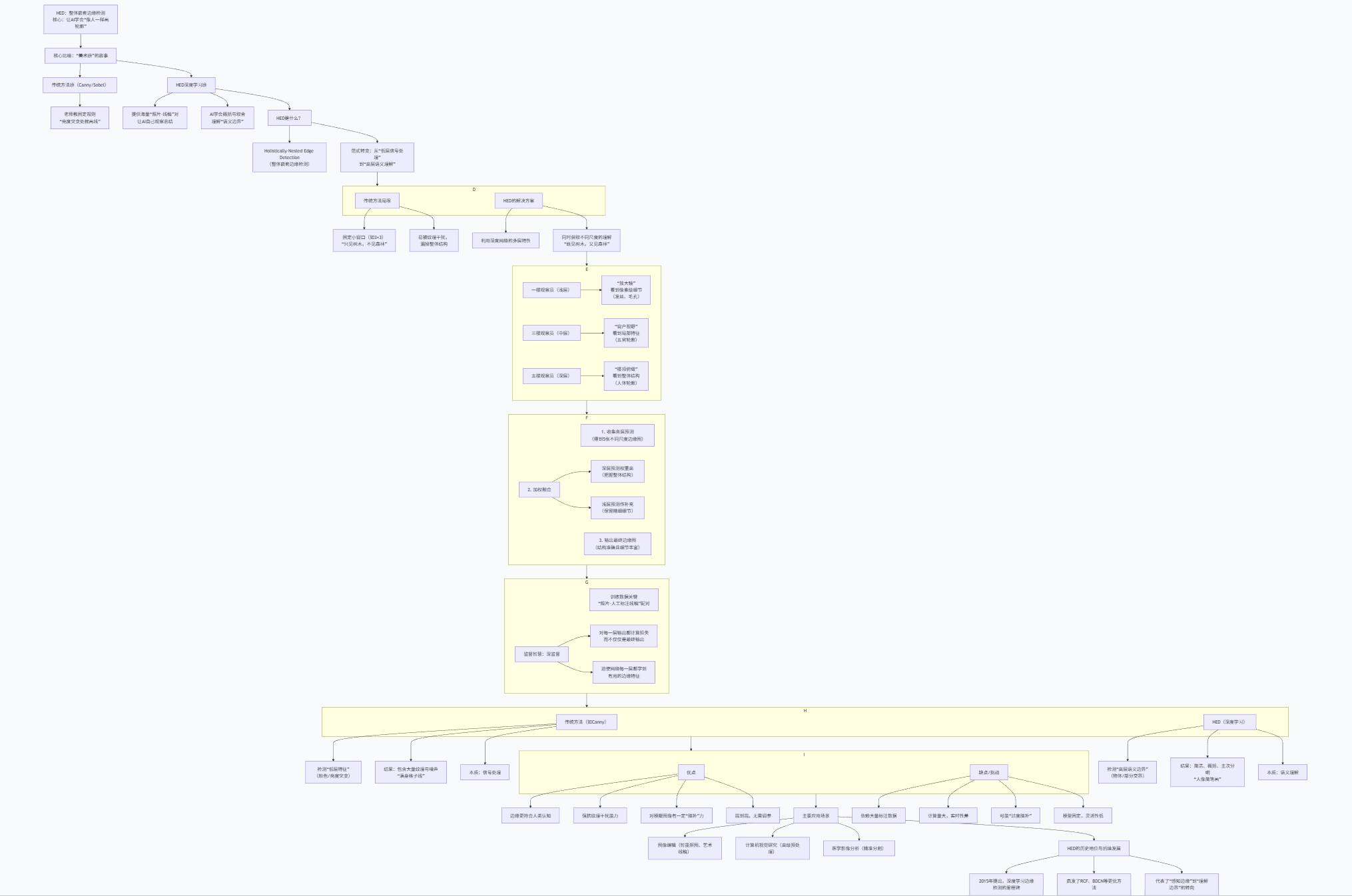
框图核心解读
这张框图清晰地展示了HED如何通过深度学习实现了边缘检测的范式革命:
-
根本性转变:HED的核心不是提出一个新算法,而是开启了一种新范式——从基于手工规则和低层信号处理的“检测”,转向基于数据驱动和高层语义理解的“学习”。这是框图中反复强调的“从信号处理到语义理解”。
-
创新在于“嵌套”结构:HED的“Nested”(嵌套)是其技术精髓。它不是简单地将一个深度网络作为黑盒,而是巧妙地利用了CNN天然的多尺度特性,将浅层(细节)、中层(局部)、深层(整体)的特征同时提取并融合。这模仿了人类观察事物时“既看局部细节,又看整体关系”的认知方式。
-
训练策略的智慧:“深监督”是成功的关键。它通过在网络的每一层都施加监督信号,引导网络在每一级抽象层次上都能学到与边缘相关的特征,确保最终融合时每一层的贡献都是高质量的。
-
效果对比鲜明:框图通过与传统方法的对比,直观地展现了HEd的优势:“概括”与“取舍”。传统方法力求全面(检出所有突变),而HED学习的是画出人脑认为重要的、具有语义意义的轮廓,其结果更简洁、更干净,也更接近艺术创作。
-
客观看待其角色:框图也指出了HED的缺点:数据依赖、计算成本、缺乏灵活调节性。因此,它并未取代Canny等传统方法,而是在需要高质量、语义化边缘的特定应用场景(如高级图像编辑、研究)中大放异彩。它更像是一个“专用艺术家”而非“通用工具”。
一句话总结:HED通过一个具有深监督的多尺度深度网络,从海量数据中学习了“如何像人类一样勾勒物体的语义边界”,实现了边缘检测从“物理突变探测”到“视觉感知模拟”的跃升,是计算机视觉走向理解的重要一步。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 13
13 0
0- 0



 已为社区贡献63条内容
已为社区贡献63条内容

所有评论(0)