SSA-RFR麻雀搜索算法优化随机森林回归预测MATLAB代码 代码注释清楚。 main为主程序
本项目实现了一种基于麻雀搜索算法(SSA)优化的随机森林回归(RFR)预测模型。该模型通过智能优化算法自动寻找随机森林的最优超参数组合,显著提升了预测精度和模型性能。整个系统采用MATLAB实现,包含数据预处理、参数优化、模型训练和性能评估等完整流程。本项目实现的SSA-RFR优化预测模型,将先进的群体智能算法与强大的集成学习模型相结合,提供了一种高效、准确的回归预测解决方案。通过自动化参数优化过
SSA-RFR麻雀搜索算法优化随机森林回归预测MATLAB代码 代码注释清楚。 main为主程序,可以读取EXCEL数据。 很方便,初学者容易上手。
1. 项目概述
本项目实现了一种基于麻雀搜索算法(SSA)优化的随机森林回归(RFR)预测模型。该模型通过智能优化算法自动寻找随机森林的最优超参数组合,显著提升了预测精度和模型性能。整个系统采用MATLAB实现,包含数据预处理、参数优化、模型训练和性能评估等完整流程。
2. 核心算法原理
2.1 麻雀搜索算法(SSA)
麻雀搜索算法是一种模拟麻雀群体觅食行为的元启发式优化算法。在算法中,麻雀被分为三个角色:
- 发现者:负责寻找食物源并为整个群体提供觅食方向
- 加入者:跟随发现者获取食物
- 警戒者:当察觉到危险时发出警报,引导群体逃离
算法通过模拟这三种角色的协作与竞争,在解空间中高效搜索最优解。
2.2 随机森林回归(RFR)
随机森林是一种集成学习方法,通过构建多棵决策树并进行组合预测。在回归任务中,随机森林通过平均各棵树的预测结果来获得最终输出,具有良好的泛化能力和抗过拟合特性。
3. 系统架构与工作流程
3.1 数据预处理模块
系统首先读取外部Excel格式的数据集,并进行以下预处理步骤:
% 数据读取与划分
data = xlsread('Folds5x2_pp.xlsx','Sheet1','A2:E500');
input = data(:,1:end-1); % 输入特征
output = data(:,end); % 输出目标
% 训练集与测试集划分
testNum = 100; % 测试集样本数
trainNum = N - testNum; % 训练集样本数数据归一化处理采用mapminmax函数,将数据映射到[-1,1]区间,消除量纲影响,提高模型训练稳定性。
3.2 参数优化模块
麻雀搜索算法被用于优化随机森林的两个关键超参数:
- n_trees:随机森林中决策树的数量,搜索范围[5,40]
- n_layers:树的层数(深度),搜索范围[2,10]
优化过程通过迭代更新麻雀位置(即参数组合),并评估每个位置的适应度值:
% 适应度函数定义
function error = fitness(x, inputn, outputn, output_train, outputps)
n_trees = x(1);
n_layers = x(2);
% 构建随机森林模型并计算预测误差
model = regRF_train(inputn, outputn, n_trees, n_layers);
train_simu = regRF_predict(inputn, model);
Train_simu = mapminmax('reverse', train_simu, outputps);
error = sum((Train_simu - output_train).^2) / size(inputn, 1);
end3.3 模型训练与预测模块
获得最优参数后,系统使用优化后的参数重新训练随机森林模型,并对测试集进行预测:
% 使用最优参数构建最终模型
n_trees = Best_pos(1);
n_layers = Best_pos(2);
model = regRF_train(inputn, outputn, n_trees, n_layers);
% 测试集预测
t_sim = regRF_predict(inputn_test, model);
T_sim2 = mapminmax('reverse', t_sim, outputps);4. 性能评估体系
系统提供全面的预测性能评估指标,包括:
- 平均绝对误差(MAE):预测值与真实值绝对差的平均值
- 均方误差(MSE):预测值与真实值偏差的平方和与样本总数的比值
- 均方根误差(RMSE):MSE的平方根,反映预测值与真实值的偏差程度
- 平均绝对百分比误差(MAPE):消除量纲影响的相对误差指标
这些指标通过专门的calc_error函数计算,为用户提供模型性能的全面视角。
5. 可视化输出
系统生成多种可视化结果,帮助用户直观理解模型性能:
- SSA进化收敛曲线:展示优化过程中适应度值的变化趋势
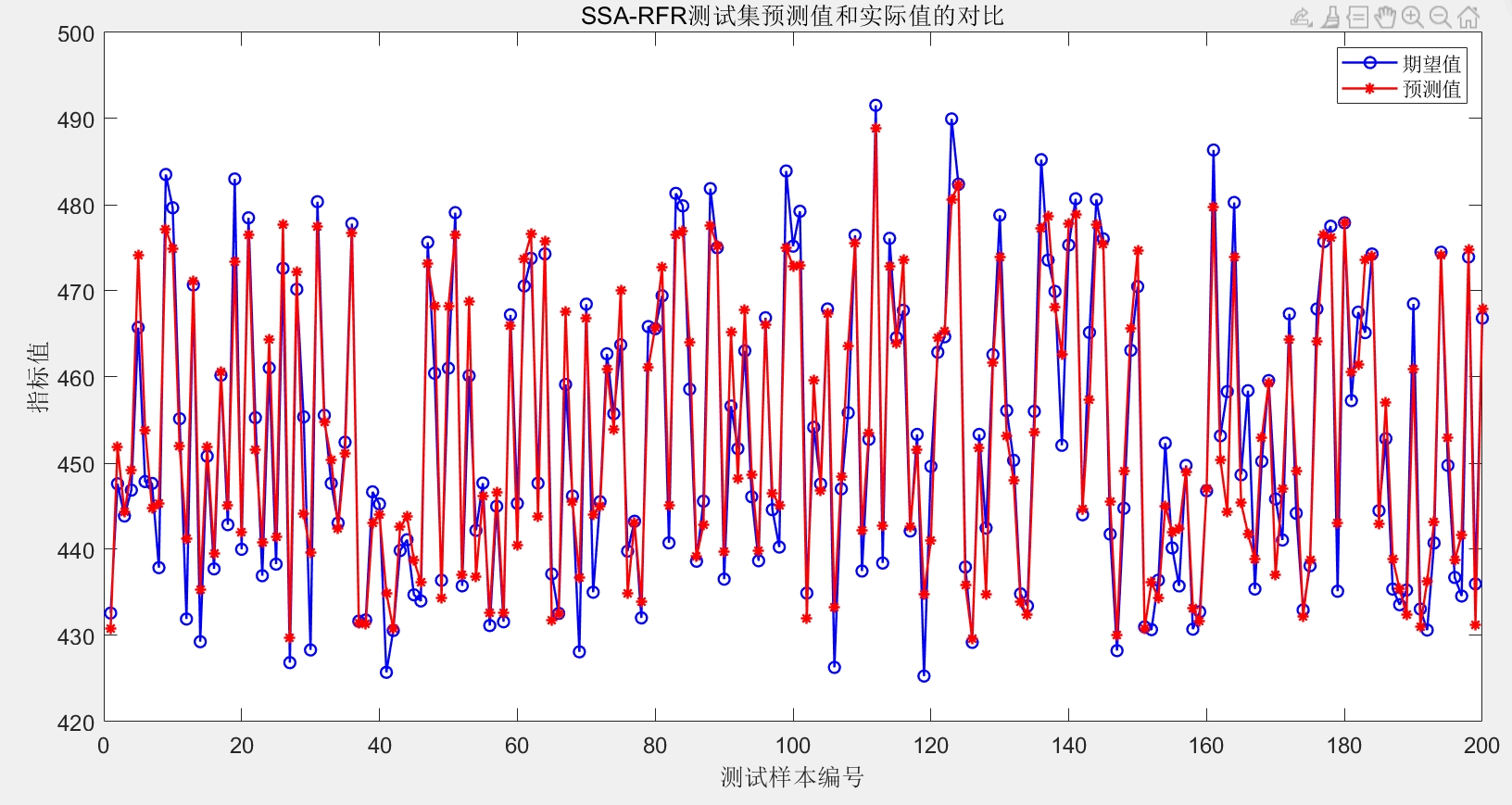
- 预测值与实际值对比图:直观显示模型预测效果
- 预测残差图:分析预测误差的分布特征
6. 技术特点与优势
6.1 创新性特点
- 智能参数优化:传统随机森林需要手动调参,本系统通过SSA自动寻找最优参数组合,大幅提升模型性能
- 高效搜索机制:SSA算法具有收敛速度快、全局搜索能力强的特点,适合高维参数优化问题
- 完整流程集成:从数据预处理到模型评估的完整机器学习流程一体化实现
6.2 应用优势
- 用户友好:主程序结构清晰,注释详细,适合初学者学习和使用
- 灵活可扩展:模块化设计便于功能扩展和算法替换
- 实用性强:可直接应用于各类回归预测问题,如能源负荷预测、股票价格预测、销售量预测等
7. 应用场景
该优化预测模型适用于多种实际场景:
- 工业领域:设备故障预测、产品质量指标预测
- 金融领域:股票价格预测、风险评估
- 能源领域:电力负荷预测、可再生能源出力预测
- 商业领域:销售量预测、客户行为分析
8. 总结
本项目实现的SSA-RFR优化预测模型,将先进的群体智能算法与强大的集成学习模型相结合,提供了一种高效、准确的回归预测解决方案。通过自动化参数优化过程,不仅提升了模型性能,也降低了使用门槛,为各行业的预测分析任务提供了有力的工具支持。
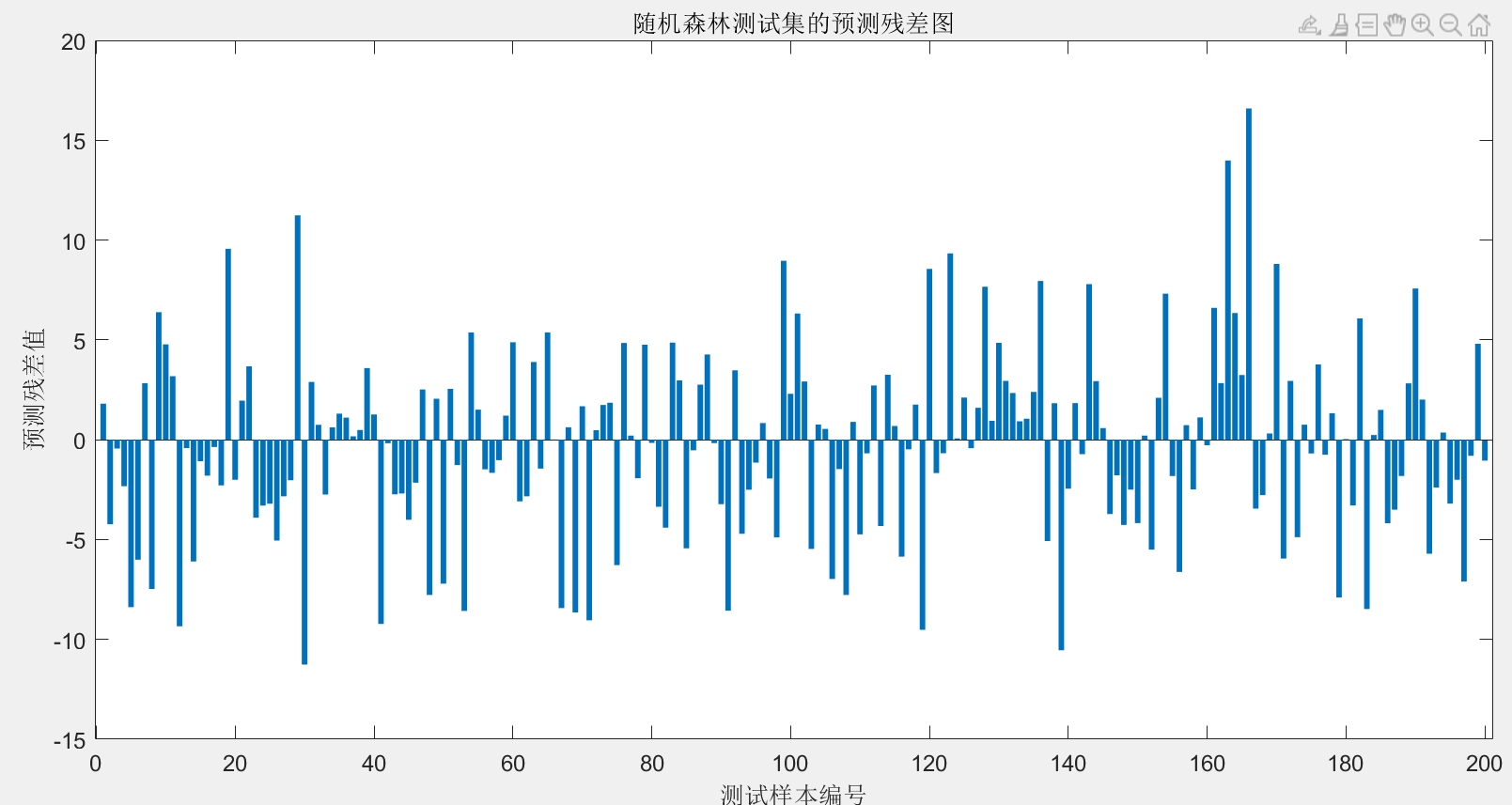
SSA-RFR麻雀搜索算法优化随机森林回归预测MATLAB代码 代码注释清楚。 main为主程序,可以读取EXCEL数据。 很方便,初学者容易上手。
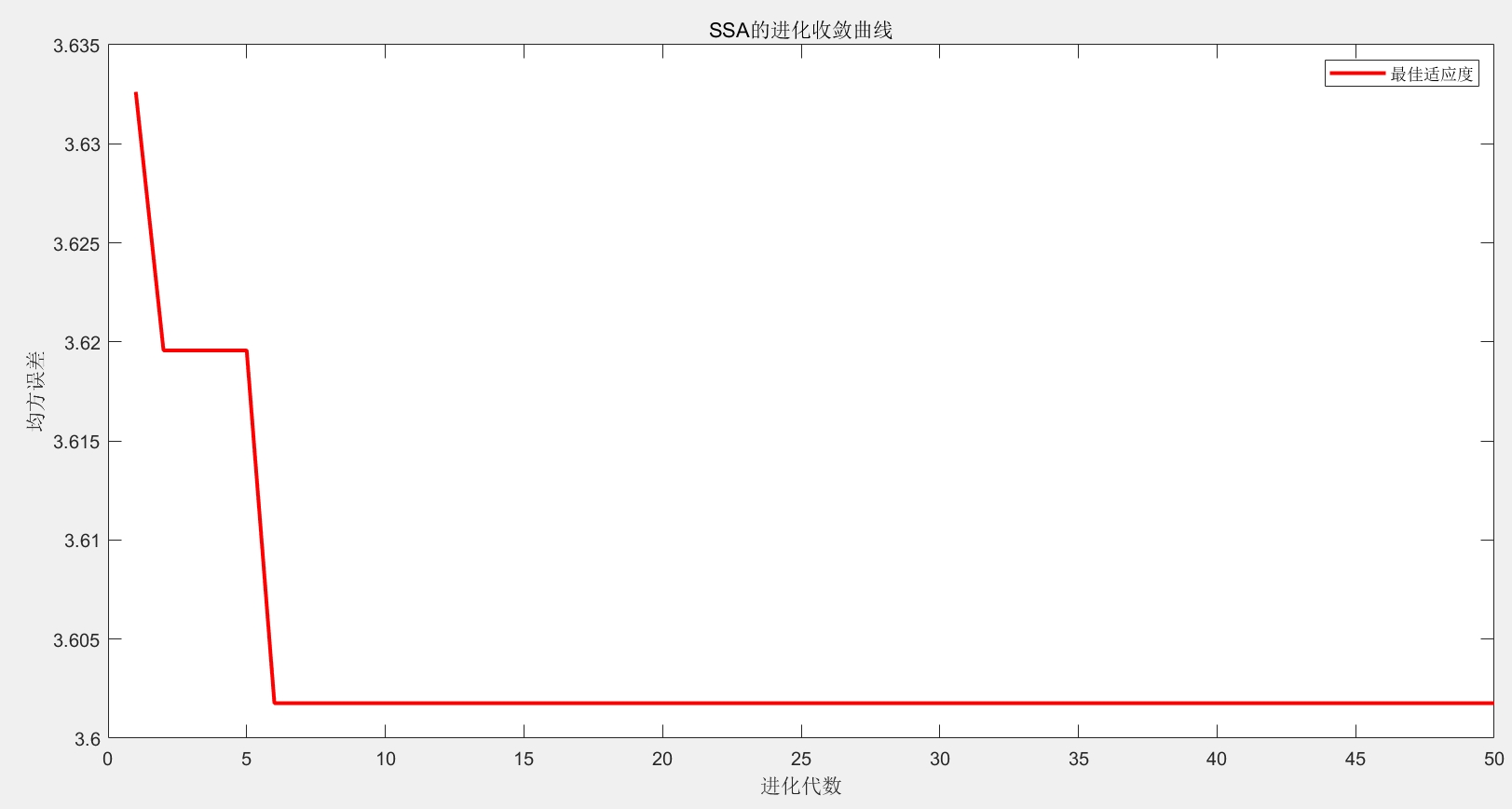
系统的模块化设计和详细注释使得代码易于理解和修改,用户可以根据具体需求调整算法参数或替换优化算法,进一步扩展系统功能。该实现为智能优化算法在机器学习中的应用提供了一个优秀范例。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)