生产级别AI 编程范式:从“看起来对”到“真的能用”
生产级别AI 编程范式
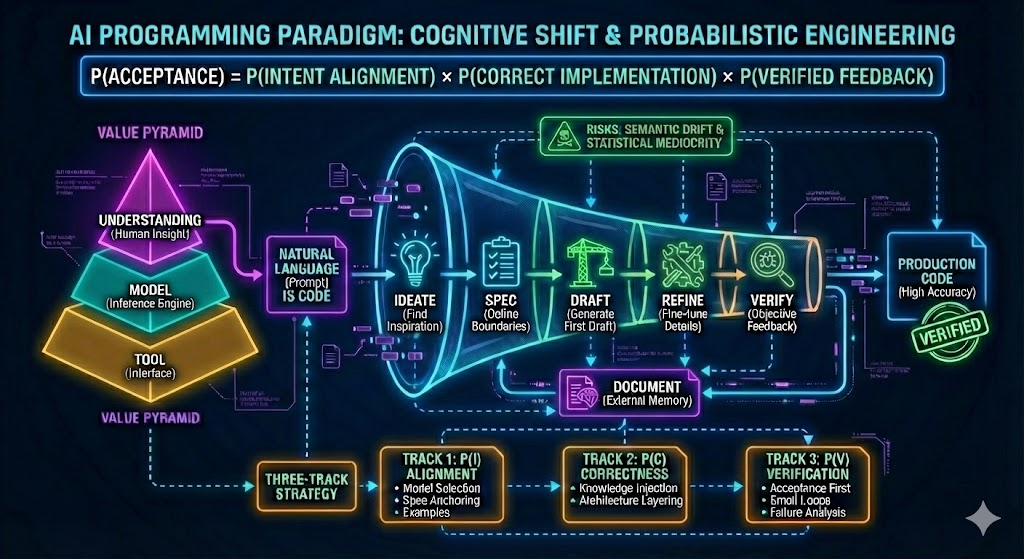
💡 核心摘要 (TL;DR)
🎯 一句话总结
AI 编程并非单纯的代码生成,而是一场关于 意图对齐、实现正确 与 验证闭环 的概率工程。核心目标不是代码本身,而是 获取可交付的项目 (Deliverable Project)——即建立高杠杆:用低信息量的 Prompt 换取可交付的 Running System。
- 🧠 心智模型:
交付 = 意图对齐 P(I) × 实现正确 P(C|I) × 验证闭环 P(V|I,C) - 🔑 关键路径:漏斗型工作流(Ideate 找灵感 -> Spec 定边界 -> Draft 生成初稿 -> Refine 修正细节)。
- ⚠️ 核心风险:警惕“语义漂移”带来的熵增,以及“统计学平庸”导致的代码同质化。
🧠 一、新范式&认知
1.1 自然语言即代码 (Natural Language is Code)
- 🗣️ 概念:提示词(Prompt)不仅仅是对话,它本质上是更高抽象层级的源代码。就像编译器将 C 语言转换为汇编一样,LLM 将你的自然语言“编译”为可执行的项目。
- 💥 推论:
- 歧义即 Bug:任何自然语言表达上的歧义(Ambiguity),在下游都会被放大为系统级的逻辑缺陷。
- 交付即正义:代码本身是负债,能稳定运行的可交付项目 (Deliverable Project) 才是资产。不要沉迷于生成的代码行数,要关注功能的完备性。
1.2 价值层级:理解 > 模型 > 工具
- 🏛️ 价值金字塔:
- 理解 (Understanding):是对业务领域、架构模式和问题本质的洞察。这是天花板。
- 模型 (Model):推理引擎(如 Claude , GPT)。它是杠杆,用于放大人的能力。
- 工具 (Tool):是交互界面(如 Cursor, CC)。它是介质。
- 🎯 结论:不要本末倒置。如果没有人的“理解”作为内核,再强的模型也只是在“高效地制造垃圾”;如果没有好模型支持,再好的工具也只是空壳。
1.3 熵增定律 (The Law of Entropy)
- 📉 概念:软件系统天生倾向于混乱(熵增)。而在 AI 编程中,这种倾向被指数级放大。随着对话轮次的增加和AI的多次代码生成,软件会不可避免的变得混乱。
- 🛡️ 结论:AI 编程是一场对抗熵增的战争。所有的 Spec、Lint、测试,本质上都是为了注入“负熵”,维持系统的有序性。
🧩 二、核心本质:人机协作的认知对齐
当你说“写一个 90 年代赛博朋克风格记事本”时,LLM 实际上是在进行一场大规模的 “语义解压” (Semantic Decompression)。它调用海量训练语料中的先验知识,将你寥寥数语还原成成千上万行的逻辑、样式与交互细节。
| 阶段 | 动作 | 信息量级 | 关键挑战 |
|---|---|---|---|
| 输入 | 用户描述意图 | 📉 低信息量 | 模糊、隐含假设多 |
| 转换 | LLM 先验补全 | 🔄 概率推演 | 可能产生幻觉或平庸解 |
| 输出 | 完整代码交付 | 📈 高信息量 | 需验证逻辑与风格是否符合预期 |
📐 三、理论框架:成功概率公式
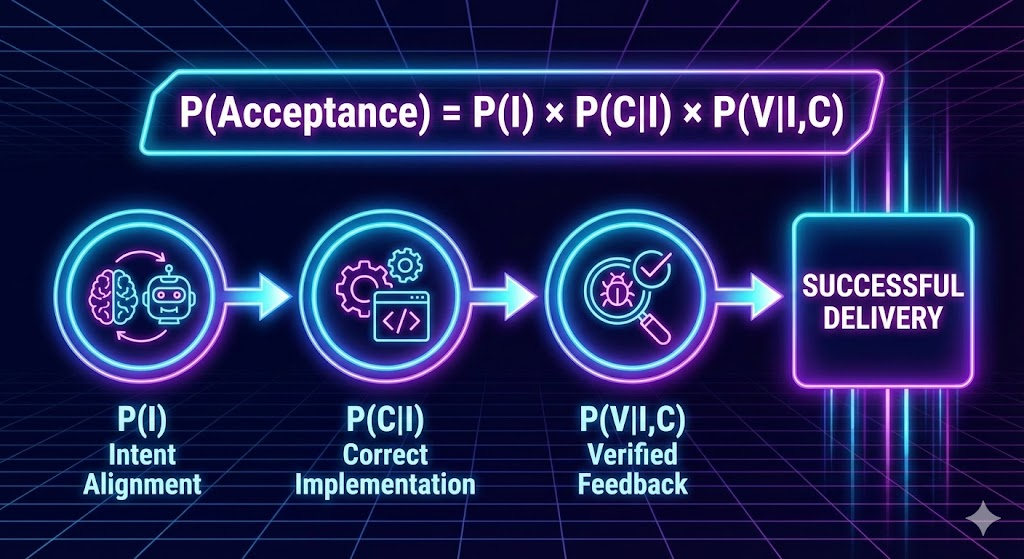
不要把 AI 编程看作确定性的逻辑推导,而要看作一个 概率工程。我们将“项目交付”定义为以下三个概率的乘积:
P(Acceptance)=P(I)⏟意图对齐×P(C∣I)⏟实现正确×P(V∣I,C)⏟验证闭环P(\text{Acceptance}) = \underbrace{P(I)}_{\text{意图对齐}} \times \underbrace{P(C|I)}_{\text{实现正确}} \times \underbrace{P(V|I,C)}_{\text{验证闭环}}P(Acceptance)=意图对齐 P(I)×实现正确 P(C∣I)×验证闭环 P(V∣I,C)
- 🎯 P(I)P(I)P(I) 意图对齐概率:模型是否真的理解了你的真实意图?
- Insight:意图没有对齐,代码写得再漂亮也是“垃圾生成”。
- ⚙️ P(C∣I)P(C|I)P(C∣I) 条件正确性概率:在意图理解正确的前提下,生成的代码逻辑是否无误?
- Insight:这取决于模型能力、上下文质量和架构清晰度。
- 🔍 P(V∣I,C)P(V|I,C)P(V∣I,C) 验证与纠错概率:当代码生成后,我们能否通过客观手段(非肉眼)发现并修正错误?
- Insight:“写得像对”不等于“真的对”。如果你无法低成本验证,错误就会累积。
⚙️ 四、推荐生产级工作流:漏斗型交付
(Ideate → Spec → Draft → Refine → Verify)
- ✨ Ideate(构思发散):用自然语言对话把想法摊开。让 AI 提建议、列方案,你负责做选择题,明确大致方向。
- 📝 Spec(定边界):这是最关键的一步。将模糊的意图固化为文档(目标、接口、数据结构、验收标准)。Spec 是实现的锚点。
- 🏗️ Draft(初稿实现):漏斗的宽口。基于 Spec,让 LLM 一次性生成可运行的项目原型(Runnable Draft)。目标不是完美的片段,而是打通核心链路的最小交付物 (MVP),确保架构一致性。
- 🔧 Refine(小范围修正):漏斗的窄口。针对细节、Bug 或边缘情况进行局部微调,便于定位问题。
- ✅ Verify(客观反馈):运行测试、Lint、类型检查。把“看起来对”变成“证据链支持的对”。
- 📚 Document(外置记忆):更新文档和规则文件,降低下一次交互的认知成本。
🚑 五、常见陷阱与“急救包”
🌪️ 5.1 语义漂移 (Semantic Drift)
- 📉 症状:代码库越写越乱,结构松散。出现大量“看起来很厉害但没啥用”的冗余功能,核心业务逻辑反而被稀释。
- 🔍 病因:缺乏持续的锚定信号,LLM 在多次对话中逐渐偏离初始目标(熵增)。
🚑 急救包(从上到下执行):
- 🧊 冻结范围:将本轮目标限制为 3 条以内 的可执行验收标准。
- ⚓️ 退回锚点:强制要求模型重新阅读 Spec/接口定义,并复述当前任务。
- ⏮️ 小步回滚:果断 Reset 到上一个“测试全绿”的版本。
😐 5.2 统计学平庸 (Statistical Mediocrity)
- 📉 症状:代码毫无亮点,采用最大公约数解法,性能平平,安全性一般,全是套话代码。
- 🔍 病因:完全交出选择权,模型就会收敛到概率分布的“平均值”。
🚑 急救包(从上到下执行):
- 🔀 强制多选:要求 AI 提供 2-3 个不同维度的方案(如:一个追求性能,一个追求可读性),由你来指定方向。
- 💉 注入偏好:明确告知“必须使用 X 库”或“禁止使用 Y 模式”。
- 🚫 设定反例:明确列出 Non-Goals(不做什么),切断平庸解的退路。
🏚️ 5.3 架构坍塌 (Architectural Collapse)
- 📉 症状:修一个 Bug 出三个 Bug,模块边界模糊,出现循环依赖。
- 🔍 病因:模型通常只关注“局部最优”(这段代码能跑),缺乏“全局最优”(架构整洁)的视角。
🚑 急救包(从上到下执行):
- 🔌 接口先行:禁止直接写实现。先定义模块的输入、输出和错误处理接口。
- 🔄 重写优于修补:当代码因反复修补变得混乱时,利用 Spec 要求 AI 重新生成整个文件。AI 的“一次性生成”往往比“多次修补”更能保证逻辑闭环。
- 📜 契约测试:补全集成测试,守住模块间的边界。
🔄 5.4 局部循环 (Local Loop)
- 📉 症状:AI 反复生成无效的修复方案,或者明明改了代码却怎么也跑不通,陷入死循环。
- 🔍 病因:模型已知的上下文不足以解决当前问题,正在“瞎猜”。
🚑 急救包(从上到下执行):
- 🔬 最小复现:停止修改业务代码,先写一个最小可复现脚本(Reproduction Script)。
- 🪵 补充上下文:喂入具体的错误栈、日志、甚至相关的源码片段。
- 🙋 人工介入:这时候不要迷信 AI,主动提供解题思路或伪代码。
🛠️ 六、解决策略:三轨并发提升
既然 P(Success)P(\text{Success})P(Success) 由三个因子决定,我们的优化策略也应分为三条轨道:
🛤️ 轨道一:提升意图对齐 P(I)P(I)P(I)
- 🧠 模型选择:尽可能使用 高智能模型,GPT 5.2 Thinking、Gemini3 Pro。
- 📑 分层对齐:需求文档 -> 技术文档 -> 接口文档 -> 开始代码前的 TODO list。
- 🗣️ 先确认再写:让模型复述需求、列出不确定点并反问;你确认后再开始实现(Human-in-the-loop)。
- 📌 Spec 固化边界:Goal / Non-Goals / Constraints / Interfaces / Acceptance Criteria,把“想要什么”变成可审查的边界。
- ⚓️ 示例锚定:提供 1-2 个正例 + 1 个反例/边界例,用输入输出把语义钉住(比抽象形容词更可靠)。
- 📏 上下文与规则:只提供必要上下文(剪枝);把“不可违背约束”写进项目规则文件,减少跑偏与返工。
🛤️ 轨道二:提升代码正确性 P(C)P(C)P(C)
- 💻 模型选择:尽可能使用 Coding 模型:Codex、Claude、GLM。
- 💉 知识注入:利用
@Docs(llms.txt)或 MCP (context7) 工具等,让模型读取最新的框架文档,减少幻觉。 - 🏗️ 架构分层:先生成类型定义(Type Definition),再生成逻辑实现。
🛤️ 轨道三:提升验证与纠错 P(V)P(V)P(V)
- ✅ 验收先行:先写可执行的验收标准(测试用例/断言/示例输入输出),再写实现。
- 🔁 小步反馈闭环:每轮只改一小块,并立刻跑 lint/typecheck/test。
- 📍 失败优先定位:先复现 → 最小修复 → 回归验证,避免“越修越乱”。
- 🆘 卡住就补信息:进入局部陷阱后,主动请求人类提供关键上下文/算法思路/约束边界。
- 🛡️ 安全也要验证:敏感信息(密钥/Token)扫描、依赖与许可证风险检查、工具/Prompt 注入防护(最小权限 + allowlist)。
⚖️ 七、Vibe Coding vs Spec Coding
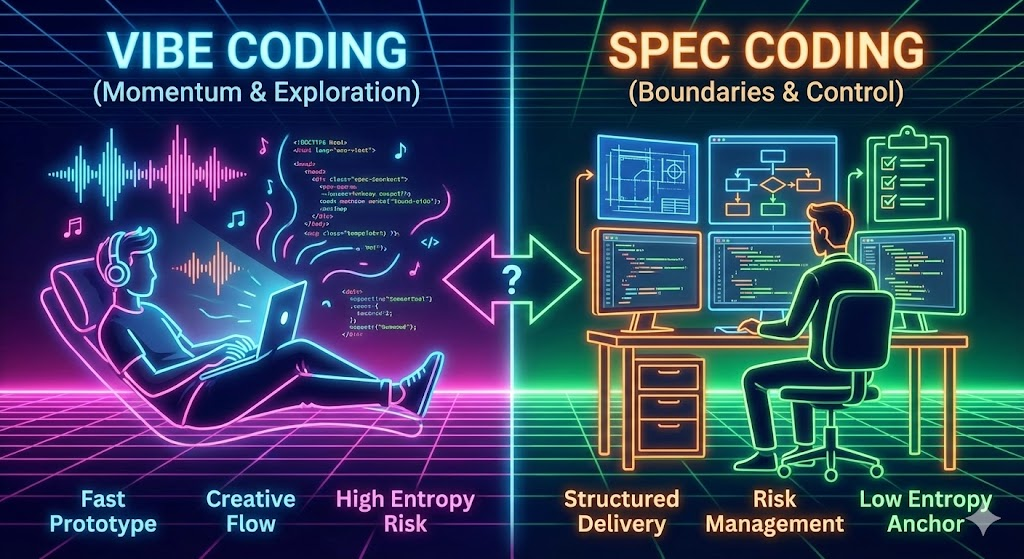
前面我们把 AI 编程拆成三条可优化的轨道:先提升意图对齐 P(I)P(I)P(I),再提升实现正确性 P(C∣I)P(C|I)P(C∣I),最后用验证闭环提升纠错能力 P(V∣I,C)P(V|I,C)P(V∣I,C)。但在真实工作里,你往往不会“先把三条都做到极致”才开始写代码,而是需要选择一种更符合当前阶段的工作方式。
这一章用两个常见范式来承接上文:
- 🎸 Vibe Coding:更偏“找方向/加动量”,适合探索与快速原型,但对 P(V∣I,C)P(V|I,C)P(V∣I,C) 的要求更高(否则很容易看起来对、实际错)。
- 📐 Spec Coding:更偏“定边界/控风险”,适合交付与长期维护,通过 Spec 把 P(I)P(I)P(I) 固化为可审查、可回归的锚点。
7.1 Vibe Coding(氛围编程)
“你完全沉浸在氛围里,拥抱指数式增长,甚至忘记代码本身的存在。” — Andrej Karpathy
- 定义:用自然语言与 AI 对话,让 AI 生成代码,开发者完全沉浸在"氛围"里的开发方式。
- 特点:
- ⚡️ 快速原型、探索性开发
- 🤝 低门槛(PM、设计师均可参与)
- 💬 依赖连续的 Prompt 对话
- 风险与局限(业界争议):
- 🕸️ 代码难以维护和调试
- 🐢 性能问题(如滥用
SELECT *查询) - 🎲 不可靠行为(难以保证一致性)
- 🚫 不适合生产级系统
- 经验法则(建议):
- ✅ 适用场景:原型验证、周末项目、概念验证(POC)
- ❌ 避免场景:生产环境核心功能、高可用系统、需要长期维护的代码库
- 🔗 必须结合:测试、代码审查、文档
📢 业界争议:Dave Farley(持续交付先驱)公开批评 Vibe Coding 是"2025 年最糟糕的想法",强调编程核心在于问题理解与精确表达,AI 编程仍面临规格、验证与演进三大难题。
7.2 Spec Coding(规格驱动编程)
“Spec 是意图的来源(Source of Intention),而非真相的来源(Source of Truth)。” — Rachel Stephens, RedMonk
- 定义:在编写代码前先编写结构化的"规格"(Spec)文档,该文档作为 AI 和人类开发者共同的工作依据(“Documentation First”)。
三个实现层次:
| 层次 | 描述 | 人类角色 |
|---|---|---|
| Spec-First | 先写规格,再用 AI 辅助开发 | 编辑 Spec 和代码 |
| Spec-Anchored | 规格作为功能演进的锚点持续维护 | 编辑 Spec 和代码 |
| Spec-as-Source | 规格是主文件,人类只编辑 Spec | 只编辑 Spec,代码由 AI 生成 |
-
核心价值:
- 🎯 意图对齐:结构化表达需求,减少语义漂移
- 👥 团队协作:创建人类可读的设计与意图文档
- 🏰 可维护性:Spec 作为"意图的来源"长期留存
-
代表工具:
- Kiro (AWS):Requirements → Design → Tasks 工作流
- spec-kit (GitHub):Constitution → Specify → Plan → Tasks
-
争议与挑战:
- 🏗️ 过度工程:小任务使用 SDD 如同"用大锤敲坚果"
- 👀 审查负担:大量 Markdown 文件审查成本高
- 🎭 虚假控制感:即使有大量指令,AI 仍可能忽略
- 🔄 与 MDD 的类比:是否在重复模型驱动开发的覆辙?
7.3 对比总结
| 维度 | 🎸 Vibe Coding | 📐 Spec Coding |
|---|---|---|
| 开发模式 | 即兴式、对话式 | 结构化、文档先行 |
| 意图对齐 | 连续 Prompt 对话 | 规格文档作为单一意图锚点/验收基准 |
| 适用阶段 | 早期探索、原型 | 生产开发、长期维护 |
| 团队协作 | 依赖 Chat History | 人类可读的 Spec 文档 |
| 验证机制 | 运行时反馈 | 需求/设计阶段的验收标准 |
| 主要风险 | 语义漂移、架构坍塌 | 过度工程、审查负担 |
💡 实践建议
“Vibe Coding 和 Spec-Driven Development 不是对立阵营,而是创作过程不同阶段的工具。Vibe Coding 解锁动量——它是火花;Spec-Driven Development 帮助团队慢下来,清晰地思考正在构建什么以及为什么。”
end
如果感觉对你有用,你可以点个赞👍

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)