火山引擎正式上线 102.4T 自研交换机,构建 AI 网络新底座
大模型训练期间,成千上万的 GPU 需频繁同步数据,任何链路抖动导致的丢包都会使其他数千个 GPU 必须空转等待,形成“木桶效应”,极大地降低 GPU 利用率,造成算力资源浪费。随着 AI 技术的飞速发展,从 800G 到 1.6T,从万卡到更大规模的算力集群,网络基础设施的演进之路永无止境。然而在实际场景中(如图 6 所示),由于 BGP 路由仍然可达,且传统负载均衡无法感知全局拓扑变化,导致业
从 AI 大模型训练到多模态推理,算力规模持续放大。网络已成为决定 AI 系统上限的关键因素:不仅需要更高带宽,还需更少层级以实现低成本、低时延互联。基于对超大规模 AI 集群的长期实践与思考,火山引擎正式上线 102.4T 自研交换机,并以此支撑新一代 HPN 6.0 架构,可支持十万卡级 GPU 集群的高效互联。
火山引擎自研的 102.4T 交换机凭借多维度的硬件技术创新和细节打磨,以高性能、高稳定、低成本的核心优势成为下一代 AI 网络的关键硬件底座。

图1 火山引擎 102.4T 自研交换机
其核心特性如下:
-
全端口 LPO 支持:实现低时延、低功耗、低成本,兼顾性能、稳定与成本。
-
创新的高速系统设计:使用 3 层扣板架构,在 4U 空间实现了 128 个 800G OSFP 端口。高速系统首创 SerDes PCB RDL 设计,MAC 板仅为 36 层,结合 M8N+M7 叠层,实现了小于 20dB 的 Bump-Bump 损耗 ,在无 Cable 和 PHY 的条件下极致支持 800G LPO。
-
精密的结构与装配:创新的板载定位与多级导向精准装配方案大幅提升了组装效率。通过优化连接器同向布局释放容差能力,累计公差减少 50%,为长期稳定运行筑牢基础。
-
极致的风冷散热:为应对单芯片超过 1600 W 的散热压力,散热器融合了非牛顿流体材料、石墨烯导热材料与强化毛细结构,并配合系统级定向风场设计,最终实现 40℃ 环温下 1800m 海拔满配稳定运行,将风冷技术潜力挖掘至极致。
-
超大尺寸芯片焊接:通过仿真和推导热形变数据,在板图设计与生产中实现精确热补偿,成功攻克超大尺寸芯片的 SMT 焊接难题,目前焊接良率达到 100%。
-
模块化与成本效益:机电结构、管理板等核心部件复用上一代成熟设计,仅需更换端口板即可适配不同应用需求,显著降低后续升级与维护成本。

图2 102.4T 自研交换机内部构成
极致的软件特性
Lambda OS 是火山引擎自主研发的网络操作系统,它以开源 SONiC 系统为基础,结合业务场景和大规模网络运维经验,进行了深度产品化定制与创新。
全局负载均衡
AI 大模型的流量特征呈现为大流(Elephant Flow)和少流(Paucity of Flows),网络负载不均会导致部分链路空闲而部分链路拥塞丢包,使带宽利用率从设计的 90% 降至 50% 以下。传统 Hash 算法的不均可能导致部分链路延迟飙升,拖慢整个集群的参数同步。例如,某链路拥塞导致同步延迟增加 10 ms,迭代 1000 次后总延迟将增加 10s,严重影响模型训练效率及推理用户体感。
为此,火山引擎与芯片厂商深度合作,联合开发了业界首个可扩展的全局网络负载均衡技术——SGLB(可扩展且稳健的全局负载均衡)。SGLB 基于全局拓扑,能够微秒级感知链路拥塞状态,并计算端到端最优路径。实测性能表明,相较于传统 Hash 选路,GPU 网络带宽可提升 40%。更多技术细节,可参阅 SIGCOMM 2025 的相关论文:https://dl.acm.org/doi/10.1145/3718958.3750527。
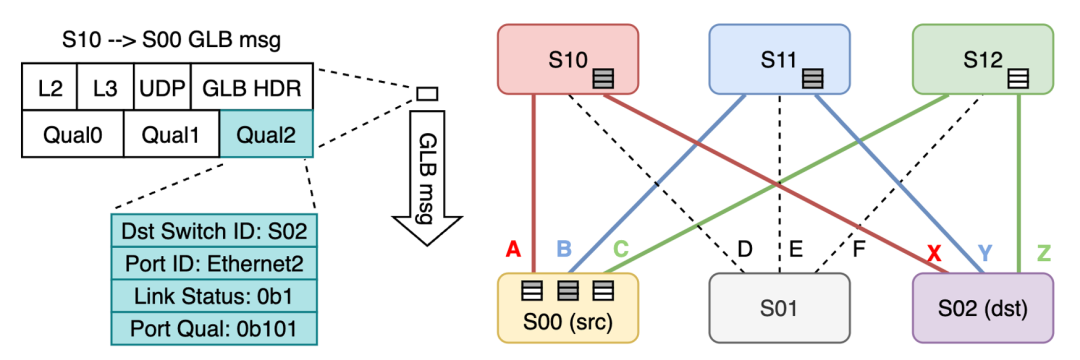
图3 SGLB 示意图
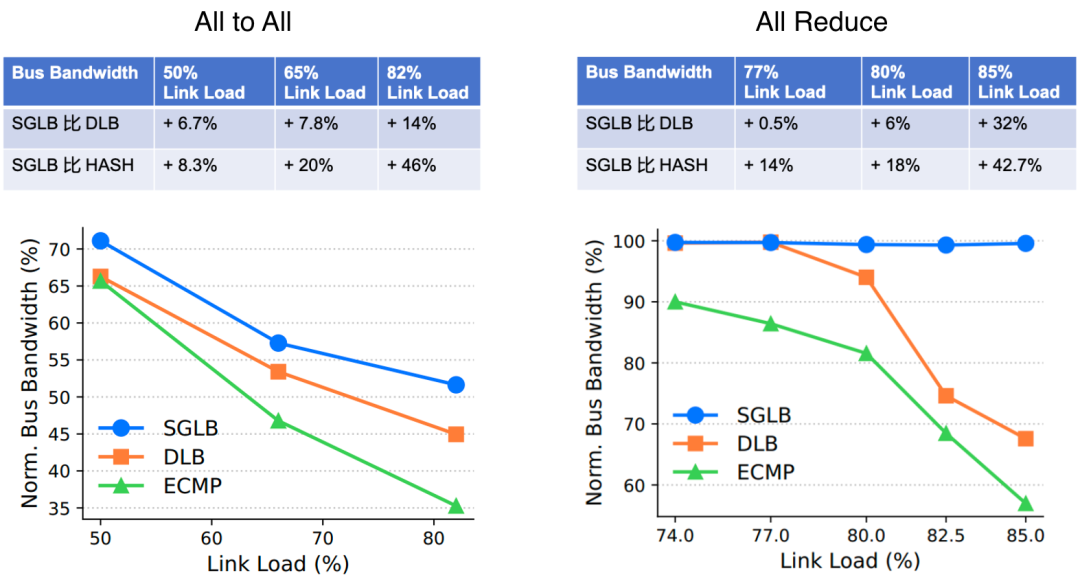
图4 SGLB 性能数据
带宽对称性负载均衡
在小规模网络集群中,设备间通常存在多链路互联,带宽具有对称性。如图 5 所示的拓扑,当一条 800G 链路断开时,理想情况下业务带宽也应相应损失 800G。然而在实际场景中(如图 6 所示),由于 BGP 路由仍然可达,且传统负载均衡无法感知全局拓扑变化,导致业务带宽损失被不成比例地放大,损失值可能是物理带宽损失的数倍,最高可达 32 倍。
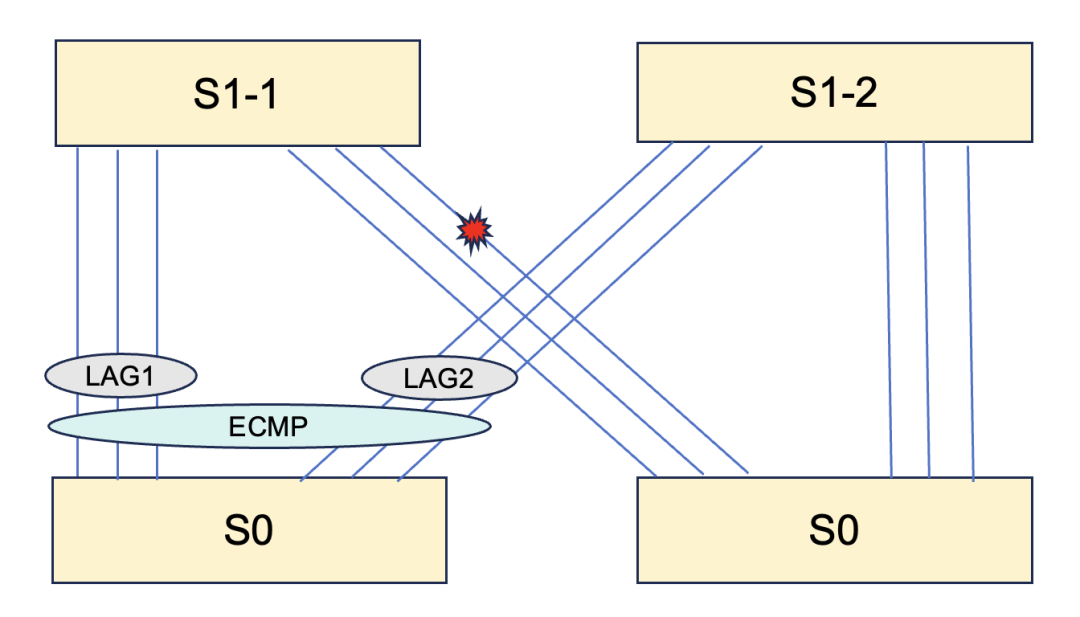
图5 小规模集群网络
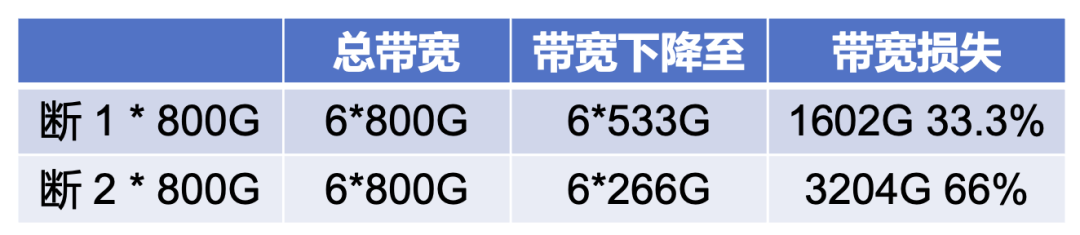
图6 非对称下的业务带宽损失
因此,Lambda OS 设计了带宽对称性负载均衡机制。该机制能够感知拓扑中的带宽对称性,确保物理带宽损失与业务带宽损失呈线性关系,从而提升网络的可预期性。
微秒级路由收敛
在 AI 网络中,链路抖动对模型训练和推理有直接影响。大模型训练期间,成千上万的 GPU 需频繁同步数据,任何链路抖动导致的丢包都会使其他数千个 GPU 必须空转等待,形成“木桶效应”,极大地降低 GPU 利用率,造成算力资源浪费。公开资料显示,一个万卡 AI 集群每年因链路故障导致的训练中断约 60 次;谷歌在 OFC 2025 的报告中也指出,百万级链路规模下,每日故障约 40 次,月均约 1200 次。因此,在链路故障时快速切换路由、减少丢包至关重要。
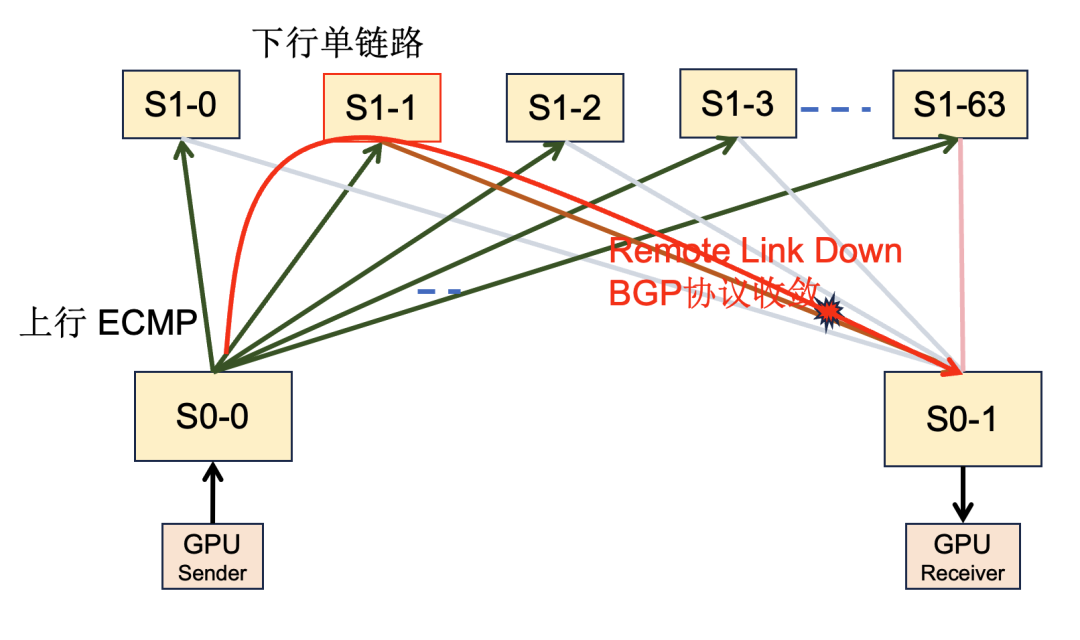
图7 路由收敛示意图
链路故障时,快速切换流量的瓶颈在于跨设备的远端链路中断(Down)时的路由收敛。业界通过协议优化,通常能实现秒级收敛。例如,AWS 在 re:Invent 2024 上介绍其自研的 SIDR 协议,将路由收敛时间从 10s 优化至 1s。
基于在 SGLB 实践中积累的微秒级端到端路径感知能力,火山引擎设计并实现了自研的 SyncMesh 路由协议,其特点如下:
-
硬件卸载与微秒级切换:SyncMesh 支持芯片卸载,实现微秒级端到端状态感知与路径切换。
-
收敛性能与路由规模解耦:在万级路由规模下,仍能保证微秒级的收敛速度。
与业界 1s 级的路由收敛性能相比,SyncMesh 将其提升至 50 μs,实现了 5 个数量级的性能飞跃。
微秒级可视化监控
HFT(高频遥测)支持对全量端口带宽、队列长度等多个统计指标进行微秒级监控,解决了传统秒级监控难以观测和分析业务流量细节的问题。
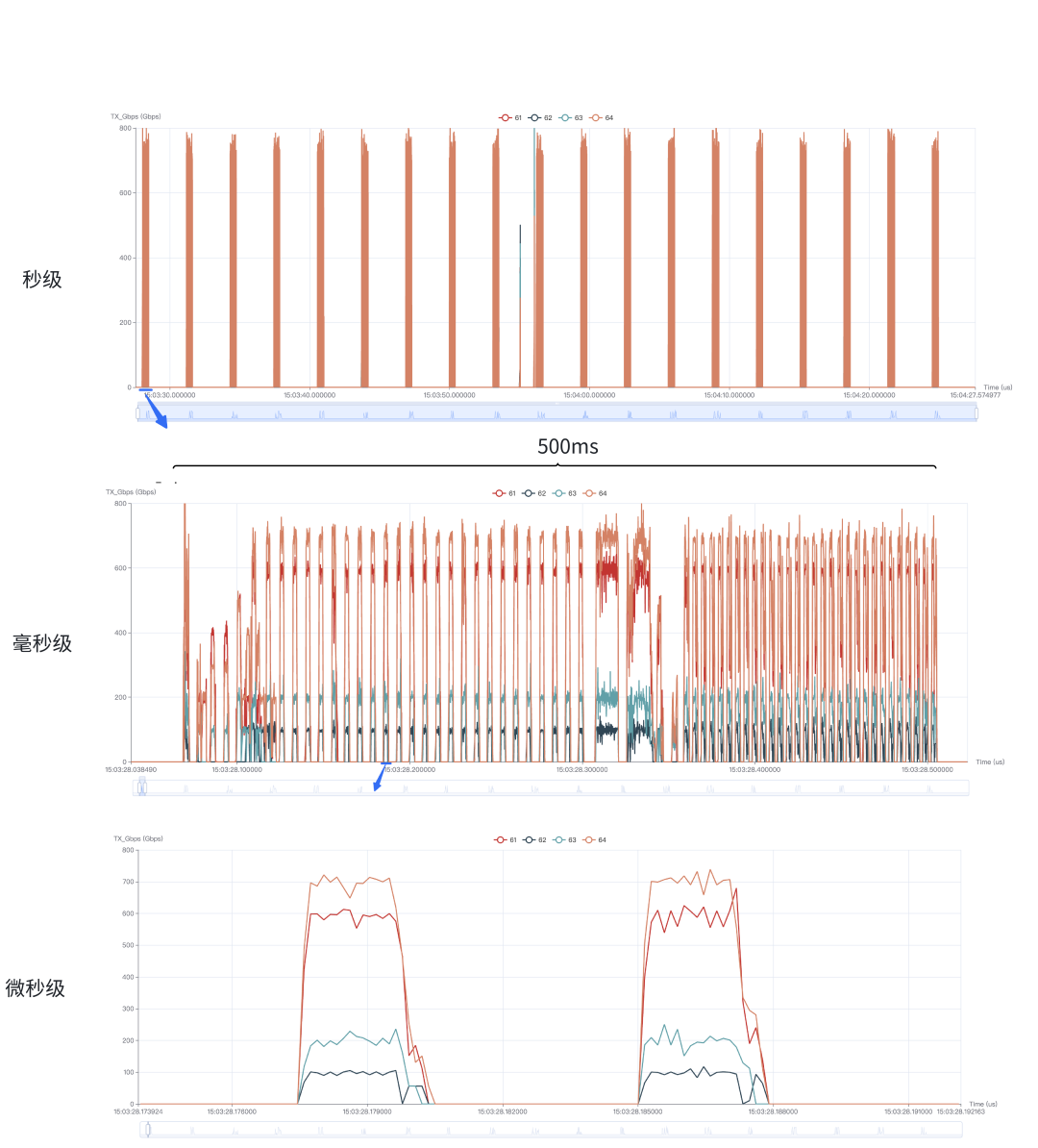
图8 LLaMA 流量模型下的微秒级监控数据
新一代的 HPN 网络架构
基于 102.4T 自研交换机在软硬件一体化方面的能力积累,火山引擎推出了面向训推一体场景的融合网络架构——HPN 6.0。围绕“规模、融合、确定性”三个核心目标,HPN 6.0 重新定义了超大规模算力集群的网络底座。
- 超大规模演进能力
-
采用三层 Clos 架构,单 POD 最大支持 65k 规模组网,集群能力可线性扩展至百万级。在不引入额外层级的前提下,HPN 6.0 兼顾了规模扩展性与网络时延可控性,为十万卡、百万卡时代提供了可持续演进的网络基础。
- 面向训推一体的深度融合设计
-
网络支持 200G/400G/800G RDMA NIC 的混速组网,并针对不同速率、不同代际 GPU 间的带宽不对等与通信模式差异引入了创新优化方案,确保多代算力与多类型业务能够稳定协同。
-
同时,HPN 6.0 提供算子级与任务级双粒度 QoS 能力,使网络资源能够精准匹配训练、推理等不同阶段的通信特征,为大规模分布式训练提供可预期、可验证的高性能通信。
- 以确定性为目标的稳定性体系
-
通过多平面容灾架构与芯片级 Fast Failover 能力,实现微秒级故障收敛,将网络异常对算力任务的影响控制在最小范围内。
-
结合微秒级流量可视化与亿万分之一丢包级别的可感知能力,使网络问题从“事后定位”转变为“事前感知”,为超大规模 HPN 网络的长期稳定运行提供底层保障。
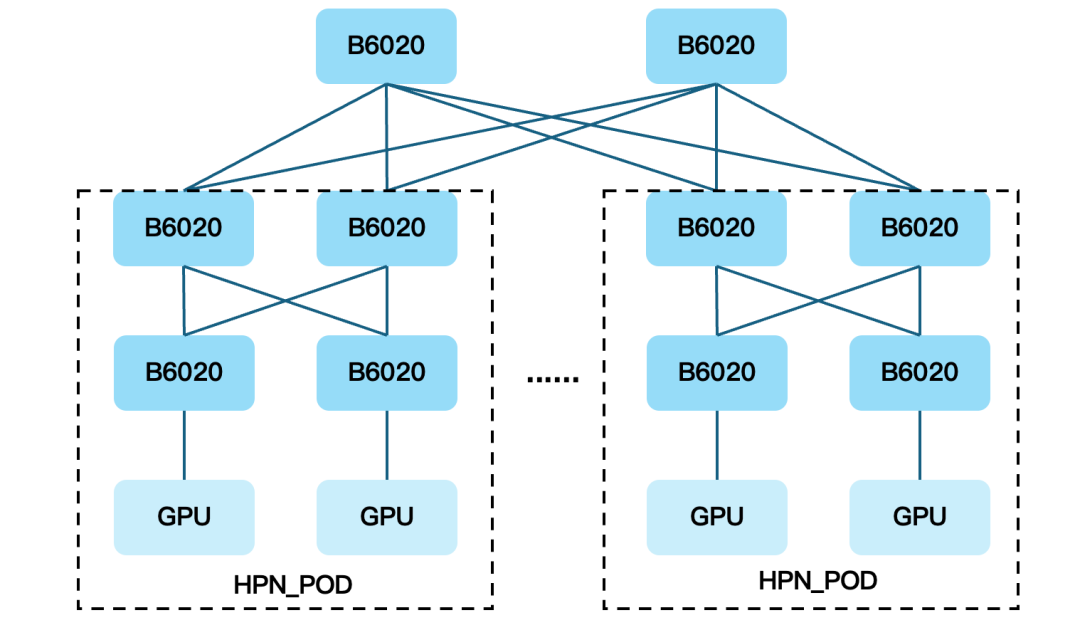
图9 火山引擎 HPN 6.0 网络架构
结束语
102.4T 自研交换机和 HPN 6.0 网络架构的上线,是火山引擎 AI 网络架构演进中的一个重要里程碑。它不仅满足了当前大规模 GPU 集群的严苛需求,也为未来的网络升级奠定了坚实的基础。随着 AI 技术的飞速发展,从 800G 到 1.6T,从万卡到更大规模的算力集群,网络基础设施的演进之路永无止境。火山引擎将继续在硬件、软件和系统架构上不断探索与创新,构建更高效、更稳定、更可持续演进的 AI 网络底座,推动 AI 技术浪潮向前发展。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 0
0 0
0- 0



 已为社区贡献27条内容
已为社区贡献27条内容

所有评论(0)