你的向量数据库是个垃圾场
我们花了数小时辩论 GPT-4 与 Claude 3。我们为完美的温度设置而苦恼。我们将提示调整到完美。然后我们将一个 5000 页的原始 PDF 扔进分块器,将其切成 512 字符的小块,并想知道为什么 AI 会产生幻觉。AI 的脏秘密是,80% 的性能提升来自于处理数据清理的 0% 代码。您的向量数据库不是图书馆;它目前是一个垃圾场,充满了 HTML 表格、页面标题(“第 1 页,共 50 页

我们花了数小时辩论 GPT-4 与 Claude 3。我们为完美的温度设置而苦恼。我们将提示调整到完美。
然后我们将一个 5000 页的原始 PDF 扔进分块器,将其切成 512 字符的小块,并想知道为什么 AI 会产生幻觉。
AI 的脏秘密是,80% 的性能提升来自于处理数据清理的 0% 代码。
您的向量数据库不是图书馆;它目前是一个垃圾场,充满了 HTML 表格、页面标题(“第 1 页,共 50 页”)、导航栏和版权声明。每次您搜索答案时,模型都必须穿过这些噪音来找到信号。
停止优化模型。开始清理数据。
1、核心知识:信噪比
在信息论中,信道的容量受噪音限制。
其中:
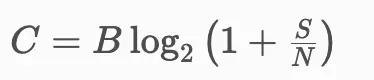
- C 是容量(有用信息)。
- S 是信号(实际文本)。
- N 是噪音(页眉、页脚、HTML 伪影)。
如果您取一个干净的句子并用"机密——请勿分发"和"第 45 页"包围它,向量嵌入会偏移。块的几何中心会从它所代表的概念移开,向格式噪音的方向移动。
当用户搜索"如何重置密码?"时,您不希望最接近"第 45 页:机密请勿分发"的向量。但这正是天真分块创建的内容。
2、流程:"脏"与"净"管道
大多数教程向您展示"脏"路径。这就是生产 RAG 失败的原因。
"脏"路径(朴素 RAG)
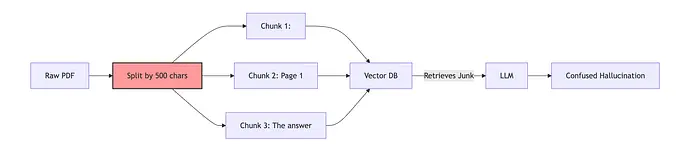
"净"路径(生产级 RAG)

注意差异。我们不只是切片数据;我们是在重构它。
3、代码:不要切片,要解析
RAG 中最大的罪过是在原始 PDF 文本上使用 RecursiveCharacterTextSplitter。您不可避免地会将句子切成两半。
问题(朴素切片):
from langchain.text_splitter import RecursiveCharacterTextSplitter
text = """
重要通知:本文件是机密的。
密码重置程序需要管理员访问权限。
第 1 页,共 5 页
"""
# 这盲目地按字符数拆分
splitter = RecursiveCharacterTextSplitter(chunk_size=50, chunk_overlap=0)
docs = splitter.split_text(text)
# 结果:
# 块 1:"重要通知:本文件是 conf"
# 块 2:"idential. 密码重置程序 r"
# 块 3:"equires admin access. 第 1 页,共 5 页"
您刚刚创建了三个毫无意义的块。“机密"的向量并不意味着"密码重置”。
解决方案(启发式清理):
在嵌入之前,您必须运行清理管道。
import re
def clean_text(text):
# 1. 移除页眉/页脚(启发式)
lines = text.split('\n')
cleaned_lines = []
for line in lines:
# 删除常见的页眉/页脚的短行(根据您的文档自定义)
if len(line) < 5 and "Page" in line:
continue
# 如果"机密"警告杂乱视野,则移除它们
if "CONFIDENTIAL" in line or "Copyright" in line:
continue
cleaned_lines.append(line)
text = "\n".join(cleaned_lines)
# 2. 移除电子邮件地址/电话号码(个人身份信息)
text = re.sub(r'\S+@\S+', '', text)
# 3. 折叠空白
text = re.sub(r'\s+', ' ', text).strip()
return text
# 现在我们拆分清洁后的文本
# 理想情况下,使用语义分块器或至少使用句子分词器
import nltk
sentences = nltk.sent_tokenize(clean_text(raw_pdf))
# 现在我们将句子分组为块,确保不将句子切成两半
chunk_size = 3 # 每块 3 个句子
chunks = []
for i in range(0, len(sentences), chunk_size):
chunk = " ".join(sentences[i:i+chunk_size])
chunks.append(chunk)
# 现在的块是:
# "密码重置程序需要管理员访问权限。"
# (干净、有意义、语义单元)
4、高级秘密:元数据预过滤
这是您可以实现的最有效的优化。
向量搜索是 O(1),具有较大的常数因子(它很快,但不是免费的)。SQL 过滤是瞬时的。
在您要求向量数据库找到"最近邻居"之前,使用元数据过滤器移除 90% 的垃圾。
错误的方式:
“在整个 100 万个块的数据库中搜索’2023 年财务报告’。” 向量数据库搜索 100 万个向量。-> 慢。
正确的方式:
"使用 SQL 过滤
year == 2023ANDcategory == 'finance'(返回 500 个块)。" 向量数据库搜索 500 个向量。-> 快 1000 倍且更准确。
代码(SQL + 向量):
# 我们假设存储了元数据:{'year': 2022, 'topic': 'marketing'}
def hybrid_search(query, year, topic):
# 1. 用 SQL 预过滤(廉价过滤器)
candidates = db.query("SELECT id, content FROM docs WHERE year = ? AND topic = ?", [year, topic])
if not candidates:
return []
# 2. 仅在候选上进行向量搜索(昂贵的精确度)
query_embedding = embed(query)
best_match = None
highest_score = -1
for doc in candidates:
doc_embedding = db.get_embedding(doc['id'])
score = cosine_similarity(query_embedding, doc_embedding)
if score > highest_score:
highest_score = score
best_match = doc
return best_match
这会自动移除"第 1 页,共 50 页"的噪音,因为如果那些页面没有正确的元数据标签,它们会在数学开始之前被排除。
5、结束语
您无法在泥浆基础上建造摩天大楼。
下次您想要调整 temperature 或 top_p 时,停下来。去查看您的数据摄取管道。
- 您是否在剥离 HTML?
- 您是否在移除页眉?
- 您是否按日期预过滤?
- 您是否按句子而不是字符拆分?
如果您输入的数据是垃圾,世界上最好的 LLM 也是无用的。
做清洁工作。其余的会自己解决。
原文链接:你的向量数据库是个垃圾场 - 汇智网

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 7
7 0
0- 0



 已为社区贡献168条内容
已为社区贡献168条内容

所有评论(0)