Agent开发(四) RAG和GraphRAG
RAG技术详细介绍
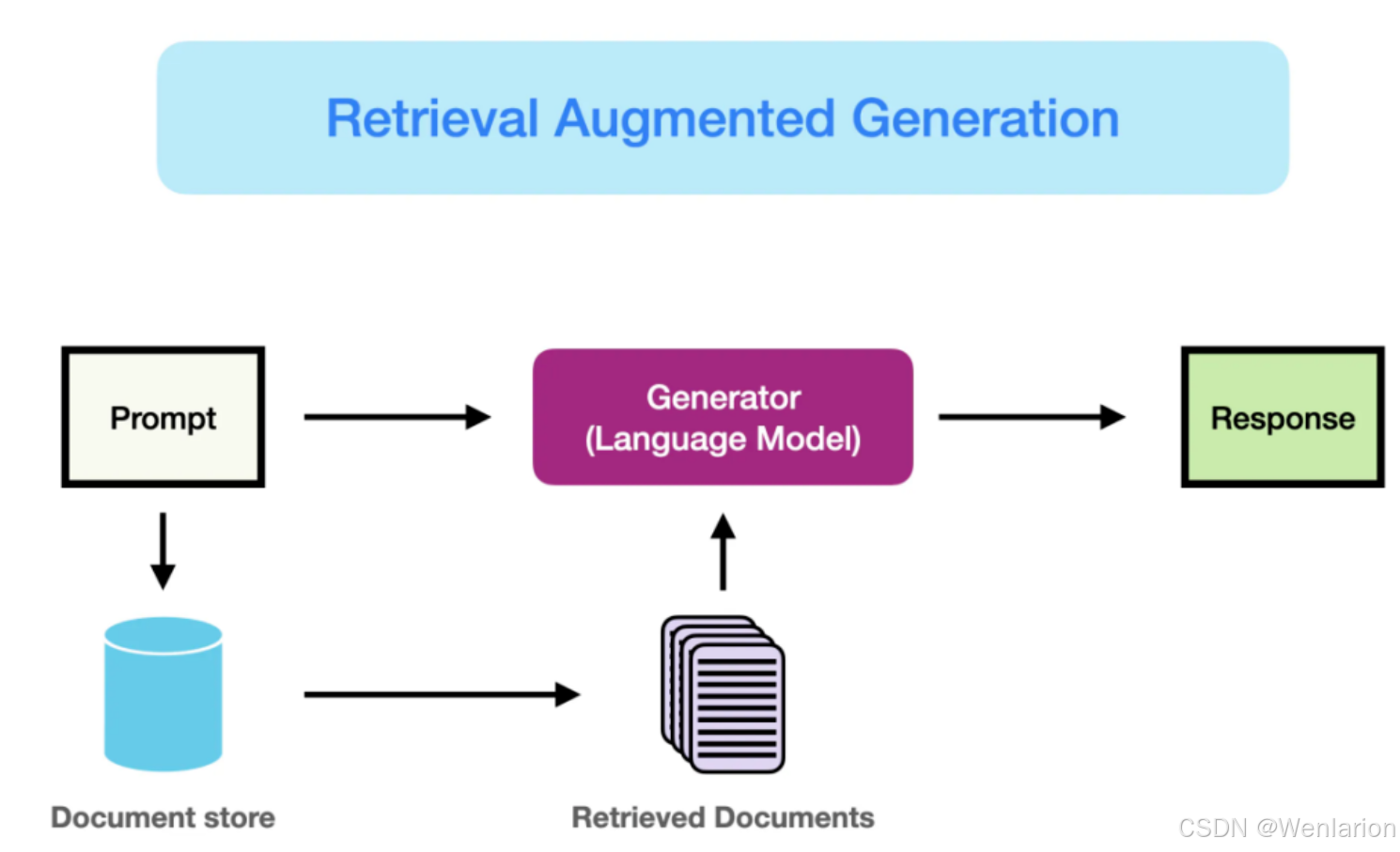
RAG(检索增强生成,Retrieval-Augmented Generation)核心是通过“检索外部知识库获取相关信息+大模型生成精准答案”的协同模式,解决纯大模型“知识滞后、幻觉严重、场景适配性弱”的核心痛点。其开发需遵循“业务对齐→数据筑基→架构搭建→模块开发→集成优化”的全流程,每一步均围绕“提升检索精准度、保障生成逻辑性、降低落地成本”三大核心目标展开。
一、前期准备阶段:对齐需求与夯实数据基础(开发前提)
本阶段核心是明确“为什么做RAG”“为谁做”“用什么数据做”,避免开发与业务脱节、数据质量不足导致后续返工,是RAG成功落地的基础前提。
步骤1:业务需求拆解与核心目标量化
-
拆解业务场景:明确RAG的核心应用场景(如K12知识点答疑、企业文档问答、客服知识库检索等)、目标用户(学生/员工/客户)、交互方式(语音/文本查询、批量问答等)。
-
梳理核心痛点:针对目标场景,提炼用户核心诉求(如“快速找到精准知识点”“答案逻辑完整”“支持模糊查询”),同时明确纯大模型或传统检索的不足(如传统关键词检索无法识别同义表述、大模型对冷门知识回答不准确)。
-
量化核心指标:制定可落地的评估指标,核心指标包括「检索召回率」(相关信息召回完整性)、「检索精准率」(召回信息与查询的匹配度)、「生成答案准确率」(答案符合事实且贴合需求)、「端到端延迟」(从查询到生成答案的总耗时),辅助指标包括用户满意度、幻觉率(答案虚假信息占比)。
实施原因
-
RAG开发的核心是“检索为生成服务,生成贴合业务需求”,若前期不拆解场景与痛点,易导致检索策略、模型选型与业务脱节(如K12场景需适配中小学生的通俗表述,而企业文档问答需精准匹配专业术语)。
-
量化指标是后续开发、测试、优化的“验收标准”,避免开发过程中“凭感觉判断效果”,同时能精准定位后续优化方向(如召回率低则优化检索策略,延迟高则优化索引或模型推理)。
-
明确纯大模型/传统检索的不足,才能精准发挥RAG“检索补全知识、生成优化表达”的核心价值,避免重复开发传统检索功能或盲目依赖大模型生成。
步骤2:知识库构建与数据预处理
-
数据采集:根据业务场景采集高质量数据源,优先选择结构化/半结构化数据(如K12教材PDF、习题解析JSON、企业FAQ文档、行业规范表格等),辅助采集非结构化数据(如名师讲解录音转写文本、客户咨询历史记录);同时需保障数据合法性(版权授权、隐私脱敏)与时效性(如K12知识点需匹配最新教材版本)。
-
数据清洗:对采集的数据进行去重(删除重复文档/段落)、去噪(剔除无意义内容如广告、乱码、格式符号)、脱敏(隐藏隐私信息如学生姓名、企业敏感数据)、格式标准化(统一文本编码、拆分多格式文档为纯文本)。
-
知识库结构化:将清洗后的数据按业务逻辑分类(如K12按“年级-学科-章节-知识点”分类,企业文档按“部门-业务类型-问题类型”分类),构建层级化知识库,便于后续检索时快速定位范围。
实施原因
-
数据是RAG检索的核心“素材”,低质量数据(重复、噪声、隐私信息)会直接导致检索精准度下降(如召回重复内容、无关信息干扰),甚至引发合规风险(隐私泄露、版权纠纷),因此数据预处理是保障RAG效果与合规性的关键。
-
结构化知识库能缩小检索范围,避免全量数据扫描导致的检索延迟过高(如学生查询“初中数学一元二次方程”,可直接定位到“初中-数学-九年级-一元二次方程”分类下检索,无需遍历小学、高中所有知识点),同时提升检索结果的关联性。
-
优先选择结构化/半结构化数据,是因为其信息密度高、语义清晰,比纯非结构化数据(如杂乱的录音转写文本)更易后续分块、嵌入与检索,降低开发难度与成本。
二、核心架构设计阶段:搭建RAG技术底座(承上启下)
本阶段核心是设计“检索模块+生成模块+连接层”的全链路架构,明确各组件的选型与协同逻辑,为后续模块开发提供技术蓝图,避免开发过程中组件不兼容、流程断裂等问题。
步骤3:核心组件选型
-
检索组件选型:
-
检索策略:根据场景需求选择「向量检索」(适配语义查询,如“勾股定理怎么用”与“毕达哥拉斯定理的应用”)、「关键词检索」(适配精准匹配,如查询具体公式、法规条款),或「混合检索」(向量检索+关键词检索,兼顾语义匹配与精准度)。
-
向量数据库:选择支持高效向量存储与检索的数据库,中小规模场景(如K12校内使用、中小企业文档问答)可选Milvus、FAISS(轻量、部署简单、低延迟),大规模场景可选Pinecone、Weaviate(支持分布式部署、高并发)。
-
关键词检索工具:可选Elasticsearch、Solr(支持全文检索与关键词匹配,适配结构化字段检索)。
-
-
生成组件选型:
-
基座大模型:根据场景复杂度与部署需求选择,中小场景可选开源模型(ChatGLM-4、Llama 3、Mistral)(部署灵活、成本低),大规模/高要求场景可选闭源模型(GPT-4、文心一言企业版)(生成效果好、稳定性强)。
-
微调框架:若需适配特定场景(如K12解题规范、企业话术风格),选择支持轻量微调的框架(LlamaFactory、PEFT),避免全量微调的高成本与长周期。
-
-
连接层组件选型:
-
数据连接工具:选择LlamaIndex、LangChain(支持连接知识库、检索组件、大模型,简化全流程调度)。
-
向量嵌入模型:选择轻量、语义适配的模型(Sentence-BERT、m3e-base、E5),用于将文本转化为向量,适配中文场景的优先选择中文优化模型(如m3e-base)。
-
实施原因
-
组件选型直接决定RAG的效果、成本与可扩展性:如向量数据库选择不当会导致检索延迟过高(如大规模场景用FAISS单节点部署),大模型选型不当会导致生成效果差(如复杂推理场景用轻量模型)或成本过高(如中小场景用GPT-4批量生成)。
-
连接层工具(LlamaIndex/LangChain)能简化“检索结果传递给生成模型”的流程,避免手动开发接口导致的兼容性问题(如检索组件输出格式与大模型输入格式不匹配),提升开发效率。
-
中文场景选择中文优化的嵌入模型,是因为通用英文嵌入模型(如BERT-base)对中文语义(如多音字、歧义句)的理解不足,会导致向量嵌入偏差,进而影响检索精准度。
步骤4:全流程架构设计与协同逻辑定义
-
明确核心协同流程:用户查询→查询预处理(分词、纠错、意图识别)→检索组件召回相关信息(向量检索/混合检索)→检索结果排序与过滤(按相关性得分排序,剔除低相关性内容)→连接层将检索结果与查询拼接为Prompt→大模型生成答案→答案输出(文本/语音等)。
-
定义各组件交互格式:规范检索组件的输出格式(如“相关文本块+相关性得分+来源(如教材章节)”)、Prompt拼接格式(如“基于以下信息回答用户问题,答案需简洁准确:{检索结果}\n用户问题:{用户查询}”)、大模型的输出格式(如结构化答案、分点解析)。
-
设计容错机制:针对检索失败(无相关结果)、检索结果过少(仅1条低相关性内容)等场景,定义降级策略(如检索失败时调用大模型原生知识库生成答案,并提示用户“未找到相关信息,以下为通用回答”)。
实施原因
-
清晰的协同流程能避免开发过程中“模块脱节”(如检索结果未传递给生成模型、Prompt拼接逻辑混乱),确保全链路顺畅,同时便于后续问题定位(如生成答案错误时,可追溯是检索环节还是生成环节的问题)。
-
统一交互格式能降低组件集成难度,避免因格式不统一导致的数据传递失败(如检索结果为JSON格式,大模型需文本格式,未转换则无法正常生成答案)。
-
容错机制是保障用户体验的关键:RAG开发中难免出现检索无结果的场景(如用户查询冷门知识点、表述不清晰),若无降级策略,会导致无法生成答案,影响用户使用,降级策略能兼顾体验与效果。
三、核心模块开发阶段:检索与生成模块落地(核心环节)
本阶段是RAG开发的核心,需分别实现检索模块(保障“找得准、找得快”)与生成模块(保障“答得对、答得好”),同时通过连接层实现两者协同,核心目标是解决“检索精准度不足、生成与检索脱节”的痛点。
模块1:检索模块开发(核心:精准召回相关信息)
步骤5:文本分块(Chunking)开发
-
选择分块策略:摒弃传统“固定长度分块”(如每200字分一块),采用“语义感知分块”(结合业务逻辑与文本语义),常用策略包括「知识点/段落边界分块」(如K12按知识点拆分,文档按段落拆分)、「滑动窗口分块」(重叠部分10%-20%,避免语义断裂)、「层次化分块」(先按大主题拆分,再拆分子知识点/段落)。
-
分块参数调试:根据文本类型调整分块大小(如知识点文本每块150-300字,长文档解析每块300-500字),确保每块文本语义完整(如一个知识点不拆分到两个块),同时避免块过大导致检索精准度下降、块过小导致检索结果碎片化。
-
分块后处理:为每个文本块添加元数据(如来源、年级、学科、章节、关键词),便于后续检索时过滤与排序(如优先召回同一章节的文本块)。
实施原因
-
文本分块是检索精准度的“基础前提”:传统固定长度分块会导致语义断裂(如将“勾股定理的公式”拆分到两个块),进而导致检索时召回不完整信息;语义感知分块能保障每块文本语义完整,让检索结果更贴合用户查询意图。
-
分块大小与参数直接影响检索效果:块过大则包含多个无关语义(如一个块包含多个知识点),检索时易召回无关信息;块过小则信息碎片化,生成答案时需整合多个块,增加逻辑梳理难度。
-
元数据能提升检索效率与精准度:通过元数据可快速过滤无关范围(如用户查询初中知识,直接过滤小学、高中的文本块),同时能让用户清晰了解答案来源,提升可信度(如K12场景中显示答案来自“初中数学九年级上册教材”)。
步骤6:向量嵌入与索引构建
-
文本块向量嵌入:调用选定的嵌入模型(如m3e-base),将分块后的文本与用户查询均转化为固定维度的向量(如768维),确保向量能精准表征文本语义(如“一元二次方程求解”与“ax²+bx+c=0的解法”向量相似度高)。
-
向量存储:将文本块向量与元数据批量导入向量数据库(如Milvus),建立向量存储集合,设置向量维度、距离计算方式(常用余弦相似度,适配语义匹配)。
-
索引构建:
-
向量索引:选择适配场景的索引类型(如中小规模场景用IVF_FLAT、LVF_FLAT,检索速度快、精准度高;大规模场景用HNSW,兼顾速度与召回率),优化索引参数(如IVF_FLAT的nlist参数,控制聚类数量)。
-
混合索引(可选):若采用混合检索,同时构建关键词索引(如用Elasticsearch建立文本块关键词索引),实现向量检索与关键词检索的协同。
-
-
索引优化:定期更新索引(如知识库新增内容后重新构建增量索引,避免全量重建导致的服务中断),清理无效索引(如删除已删除文档的向量索引)。
实施原因
-
向量嵌入是实现“语义检索”的核心:文本与查询转化为向量后,可通过计算向量相似度(如余弦相似度)判断语义关联度,解决传统关键词检索无法识别同义表述、歧义句的痛点(如“怎么解一元二次方程”与“一元二次方程的求解步骤”关键词不同但语义一致)。
-
索引能大幅提升检索速度:无索引时需遍历全量向量计算相似度,延迟极高(如万级文本块检索需秒级);构建索引后可快速定位相似向量(如毫秒级召回),满足实时交互需求(如K12学生查询习题需快速得到答案)。
-
增量索引优化能保障RAG的时效性与可用性:知识库内容会持续更新(如K12教材改版、企业新增业务文档),增量索引可避免全量重建索引导致的服务中断,同时减少资源消耗。
步骤7:检索策略实现与优化
-
基础检索功能开发:根据选型的检索策略,实现向量检索(计算查询向量与文本块向量的相似度,召回Top-K个相似文本块,K值通常取5-10,兼顾召回率与效率)或混合检索(先通过关键词检索缩小范围,再进行向量检索;或同时执行两种检索,融合结果排序)。
-
检索结果排序与过滤:按“相关性得分(向量相似度/关键词匹配度)+元数据优先级(如同一来源、同一章节优先)+时效性(最新文档优先)”排序,过滤低相关性内容(如相关性得分低于阈值0.6的文本块)、重复内容。
-
检索增强策略开发(可选):针对模糊查询、同义查询,添加「查询扩展」功能(如用户查询“勾股定理”,扩展为“勾股定理、毕达哥拉斯定理、勾股定理公式、勾股定理应用”);针对多轮对话场景,添加「上下文感知检索」(结合历史对话内容优化检索,避免重复查询)。
实施原因
-
基础检索功能是RAG的“核心能力”:向量检索解决语义匹配问题,关键词检索解决精准匹配问题,混合检索能兼顾两者优势(如K12场景中,用户查询“一元二次方程 x²-4=0 的解”,关键词检索定位“一元二次方程”,向量检索匹配“求解步骤”)。
-
排序与过滤能提升检索精准度:仅召回Top-K个结果可避免无关信息干扰,按元数据优先级排序能让结果更贴合用户场景(如学生查询本年级知识点,优先召回本年级文本块),过滤低相关性内容能减少生成模型的无效处理。
-
检索增强策略能解决复杂场景痛点:模糊查询(如用户表述不清晰)、同义查询(如不同表述同一意图)是RAG常见场景,查询扩展能提升召回率;多轮对话场景中,上下文感知检索能让后续回答更连贯(如用户先问“勾股定理是什么”,再问“怎么用”,检索时结合历史对话,优先召回勾股定理应用相关内容)。
模块2:生成模块开发(核心:基于检索信息生成优质答案)
步骤8:大模型适配与微调(可选)
-
基座模型部署:将选定的大模型(如ChatGLM-4)部署至服务器/终端,配置推理参数(如max_new_tokens、temperature,temperature控制生成随机性,场景越严谨值越小,如K12场景设0.3-0.5)。
-
场景化微调(按需):若基座模型输出不符合业务需求(如K12答案不够通俗、企业回答不符合话术风格),基于场景数据集(如K12优质解题样本、企业FAQ问答样本)进行轻量微调(LoRA/QLoRA),冻结模型大部分权重,仅训练少量参数,降低训练成本与周期。
-
微调效果验证:用测试集(如1000条场景化查询)验证微调后模型的输出效果,核心验证“答案准确性、风格适配性、无幻觉”,调整微调参数(如学习率、训练轮次)直至达标。
实施原因
-
基座模型部署与参数配置是生成效果的基础:推理参数设置不当会导致生成效果差(如temperature过高导致答案杂乱,max_new_tokens过小导致答案不完整),需结合场景优化参数(严谨场景降低随机性,开放场景适当提升)。
-
场景化微调能解决“通用模型适配特定场景”的问题:基座大模型是通用训练的,无法精准适配特定场景的风格与需求(如K12场景需贴合学生认知水平,语言通俗、步骤清晰;企业场景需专业、规范),轻量微调能在低成本前提下实现场景适配。
-
微调效果验证能避免“微调过度/不足”:过度微调会导致模型过拟合(仅能回答训练集中的问题),不足则无法达到场景适配效果,测试验证能确保微调后模型的泛化能力与效果达标。
步骤9:Prompt工程开发
-
基础Prompt模板设计:模板需包含“角色定义、检索结果、用户查询、输出要求”四核心要素,示例(K12场景):“你是一名K12中小学辅导老师,需基于以下检索到的知识点信息,简洁、准确地回答学生问题,答案需分步骤、通俗易懂,必要时引用知识点来源。检索信息:{检索结果}\n学生问题:{用户查询}\n输出要求:1. 答案步骤清晰;2. 语言贴合初中学生认知;3. 标注答案来源。”
-
Prompt优化:根据生成效果调整模板,优化方向包括「明确输出格式」(如分点、结构化)、「限制幻觉」(如“仅基于检索到的信息回答,未检索到的信息需明确说明,不得编造”)、「引导逻辑梳理」(如“先给出核心答案,再分步骤解析”)。
-
多场景Prompt适配:针对不同查询类型(如知识点讲解、习题答疑、流程查询)设计专属模板,避免通用模板导致的输出不适配(如习题答疑需步骤清晰,知识点讲解需全面)。
实施原因
-
Prompt是“检索结果与生成模型的桥梁”:优质Prompt能引导模型正确利用检索结果,避免模型忽略检索信息、直接调用原生知识库生成答案(失去RAG的核心价值),同时能限制模型幻觉(编造未检索到的信息)。
-
明确的输出要求与格式能提升用户体验:不同场景对输出格式的需求不同(如K12学生需要分步骤解析,企业员工需要简洁的流程说明),专属模板能让输出更贴合用户习惯,降低理解成本。
-
限制幻觉是RAG的核心目标之一:纯大模型易生成虚假信息(幻觉),通过Prompt明确“仅基于检索信息回答”,能大幅降低幻觉率,提升答案可信度(如K12场景中避免给学生错误的解题步骤)。
步骤10:检索结果融合与答案生成
-
检索结果整合:将排序后的Top-K检索结果(如5-10个文本块)进行去重、合并,提取核心信息(剔除重复表述、冗余内容),按语义逻辑重组(如按“知识点定义→核心内容→应用步骤”重组),避免生成答案逻辑混乱。
-
动态Prompt拼接:将整合后的检索信息与用户查询、场景化Prompt模板动态拼接,确保Prompt长度在模型输入限制内(如ChatGLM-4输入限制2048/4096 tokens),避免超长导致截断。
-
答案生成与后处理:调用大模型生成答案,对生成结果进行后处理(如格式优化、错别字修正、冗余内容删减、来源标注),确保输出清晰、准确、合规。
实施原因
-
检索结果整合能避免生成答案碎片化:Top-K检索结果可能包含重复、冗余信息(如多个文本块重复讲解同一知识点),整合与重组能让信息更有条理,生成的答案逻辑更连贯,避免“堆砌检索内容”。
-
动态Prompt拼接能适配不同长度的检索结果:检索结果长度不固定(如简单查询召回3个文本块,复杂查询召回10个文本块),动态拼接能确保Prompt不超长(避免截断关键信息),同时让模型聚焦核心检索内容。
-
答案后处理能提升输出质量与合规性:大模型生成的答案可能存在格式混乱、错别字、冗余表述等问题,后处理能优化用户体验;来源标注能提升答案可信度,同时满足合规要求(如引用教材需标注来源)。
四、集成测试与优化阶段:保障RAG稳定落地(闭环环节)
本阶段核心是通过全流程测试发现问题,持续迭代优化,确保RAG的效果、性能、稳定性满足业务需求,避免上线后出现检索不准、生成错误、延迟过高等问题。
步骤11:模块集成与端到端测试
-
模块集成:通过连接层工具(LlamaIndex/LangChain)将检索模块、生成模块、用户交互接口(如API、Web界面)集成,打通“用户查询→预处理→检索→生成→输出”全链路,确保各模块数据交互顺畅。
-
功能测试:
-
效果测试:用测试集(覆盖简单查询、复杂查询、模糊查询、同义查询、冷门查询)测试核心指标(召回率、精准率、生成准确率、幻觉率),对比基线(纯大模型、传统检索)效果。
-
场景测试:在真实业务场景中测试(如邀请K12学生、教师试用,企业员工测试文档问答),收集主观反馈(如答案是否清晰、是否符合需求、使用是否流畅)。
-
-
性能测试:测试端到端延迟(目标:中小场景≤800ms,大规模场景≤1.5s)、并发能力(支持同时查询用户数)、资源占用(CPU、GPU、内存使用率),确保在峰值场景下稳定运行。
-
合规测试:检查数据隐私(如无隐私泄露)、版权(如引用内容标注来源)、输出合规(如无违规信息、错误引导)。
实施原因
-
模块集成能验证“各组件协同性”:单独测试检索模块、生成模块可能均达标,但集成后可能出现数据传递失败、流程断裂等问题(如检索结果无法传递给生成模型),全链路集成测试是保障RAG正常运行的关键。
-
效果测试与场景测试能验证“RAG是否贴合业务需求”:核心指标达标是基础,但真实场景的主观反馈更重要(如K12学生觉得答案太晦涩,即使准确率达标也不符合需求),需通过场景测试优化用户体验。
-
性能测试能保障“上线后稳定性”:上线后会面临多用户并发查询(如K12场景下课后答疑高峰期),若延迟过高、并发能力不足,会导致用户体验差;资源占用测试能避免服务器过载。
-
合规测试是RAG落地的“前提条件”:教育、企业等场景对数据隐私、版权合规要求极高,若存在隐私泄露、版权纠纷,会导致项目下线,甚至承担法律责任。
步骤12:迭代优化与运维监控
-
问题定位与优化:针对测试中发现的问题,精准定位根源并优化:
-
检索类问题(召回率低/精准度低):优化分块策略、调整嵌入模型、优化索引参数、升级检索策略(如改用混合检索)、扩展查询扩展词库。
-
生成类问题(答案不准确/逻辑混乱/幻觉):优化Prompt模板、微调大模型、加强检索结果整合逻辑、限制生成范围(仅基于检索信息)。
-
性能类问题(延迟高/并发不足):优化索引、增加缓存(如高频查询结果缓存)、分布式部署组件、模型量化(如4-bit/8-bit量化大模型,降低推理延迟)。
-
-
上线后运维监控:搭建监控体系,实时监控核心指标(检索指标、生成指标、性能指标、用户满意度)、组件运行状态(服务器、数据库、模型服务),设置告警机制(如延迟超标、服务中断时告警)。
-
持续迭代:定期更新知识库(如新增内容、删除过期内容)、优化模型与策略(如根据用户反馈微调大模型、更新查询扩展词库)、适配业务变化(如K12教材改版后调整分块与检索逻辑)。
实施原因
-
RAG开发是“闭环迭代”的过程,单次开发无法满足所有场景需求:测试中发现的问题(如检索不准、生成幻觉)需针对性优化,才能让效果达标;上线后用户反馈与业务变化(如知识库更新、场景扩展)也需要持续迭代,确保RAG长期适配需求。
-
运维监控能及时发现上线后问题:上线后可能出现突发场景(如并发量激增、服务器故障),实时监控与告警能快速响应,避免问题扩大(如服务中断导致大量用户无法使用)。
-
持续迭代能延长RAG的生命周期:知识库内容、用户需求、业务场景会随时间变化(如K12教材改版、企业新增业务),若不持续优化,RAG会逐渐失效(如检索不到新增知识点、生成答案不符合新业务需求)。
五、RAG开发核心总结
RAG开发的核心逻辑是“以业务需求为导向,以数据质量为基础,以检索精准为核心,以生成优质为目标,以闭环优化为保障”。关键核心点包括:1)前期准备需对齐需求与夯实数据,避免后续返工;2)检索模块的核心是“语义感知分块+精准向量检索+高效索引”,解决“找得准、找得快”的问题;3)生成模块的核心是“场景化适配+优质Prompt+检索结果融合”,解决“答得对、答得好”的问题;4)全流程需通过测试与迭代,保障效果、性能、稳定性与合规性。
每一步开发的核心原因,均围绕“解决业务痛点、提升用户体验、降低落地成本”三大目标,避免技术堆砌,确保RAG真正适配业务场景,发挥“检索补全知识、生成优化表达”的核心价值。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)