前OpenAI科学家&GPT之父:预训练精准数据过滤,极低成本削弱大模型危险能力数千倍
这项新研究提出:与其在模型学会危险知识后再试图让他遗忘,不如在学习过程中就精准地“删掉”那些关键的知识碎片,精准切除AI的危险能力。Claude价值观(安全对齐)的塑造者Neil Rathi,前OpenAI科学家、GPT之父Alec Radford共同发了一篇论文。这项新研究提出:与其在模型学会危险知识后再试图让他遗忘,不如在学习过程中就精准地“删掉”那些关键的知识碎片,精准切除AI的危险能力。
这项新研究提出:与其在模型学会危险知识后再试图让他遗忘,不如在学习过程中就精准地“删掉”那些关键的知识碎片,精准切除AI的危险能力。
Claude价值观(安全对齐)的塑造者Neil Rathi,前OpenAI科学家、GPT之父Alec Radford共同发了一篇论文。

这项新研究提出:与其在模型学会危险知识后再试图让他遗忘,不如在学习过程中就精准地“删掉”那些关键的知识碎片,精准切除AI的危险能力。
在预训练阶段通过精准的Token级数据过滤,以极低的计算成本将大模型的特定危险能力削弱数千倍,而且不损害模型的通用智能。
AI安全领域长期存在猫和老鼠的游戏,防御者试图在模型训练完成后修补漏洞,而攻击者总能找到新的越狱手段。
长久以来,业界习惯于先用海量数据把模型喂饱,让它学会所有知识,然后再通过人类反馈强化学习(RLHF)或者监督微调(SFT)给它套上紧箍咒,教它什么该说、什么不该说。
这种先污染后治理的模式已被证明极其脆弱,对抗性攻击和微调越狱就像无孔不入的水,总能绕过这些后天加上的护栏,诱导模型输出制造生物武器或策划网络攻击的方案。
这项研究表明,从预训练数据中精准剔除那些会导致危险能力的特定Token,比整篇删除文档更高效,而且随着模型规模的扩大,其防御效果呈现出惊人的指数级增长,对于18亿参数的模型,在特定领域恢复被过滤知识所需的计算量增加了7000倍。
Token级过滤实现精准外科手术
数据过滤并不是新鲜事,大多数前沿模型在训练前都会清洗掉有毒或低质量的数据。
传统做法往往是大刀阔斧地按文档进行删除,一旦检测到某篇文章包含不良内容,整篇文章连同其中的无害信息会被一并丢弃。
这种做法极其粗糙,造成了数据的浪费,还可能损害模型在相关但无害领域的通用能力。
该研究将颗粒度推进到了Token级别,这种微观层面的操作使得去其糟粕,取其精华成为可能。
研究人员构建了一个代理任务:在保留生物学知识的同时,移除医学知识。
之所以选择这两个领域,是因为它们在知识图谱上高度重叠,如果过滤方法不够精准,移除医学知识很容易连累生物学常识,导致模型变笨,这完美模拟了现实中移除制造生物武器知识(危险)同时保留疫苗研发知识(有益)的困境。
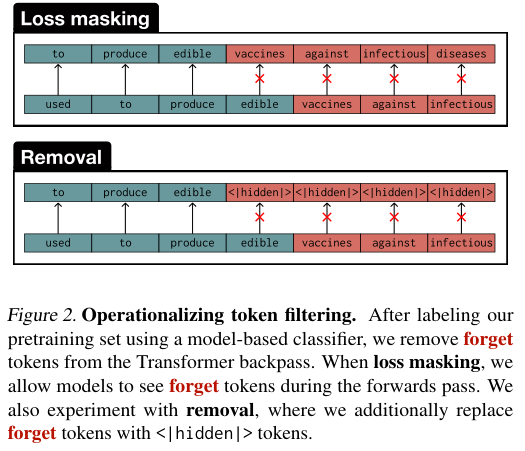
操作方法分为两种,一种是损失屏蔽(Loss Masking),模型在阅读文本时能看到所有词,但在计算梯度进行学习时,系统会忽略那些被标记为医学的敏感词。
这就像是让学生阅读课本,但不考这些知识点,也不计入成绩。
另一种是直接移除(Removal),将敏感词替换为特殊的<|hidden|>占位符,不仅不学,连看都不让看。
相比于按文档过滤,Token级过滤在同等程度削弱医学能力的情况下,对生物学能力的保留效果要好得多。
这是一次帕累托改进,意味着我们在不牺牲安全性的前提下获得了更高的性能,或者在同等性能下获得了更高的安全性。
通常人们认为随着模型变大,它会变得更聪明,也更难被限制,模型可能会从残留的蛛丝马迹中推理出被隐藏的知识。
但这里的情况恰恰相反,数据过滤在大模型上表现得更加有效。
研究人员定义了一个相对缩放法则,通过计算在过滤数据上训练的模型需要多少计算量才能达到未过滤模型在特定领域的损失值,来衡量过滤的有效性。
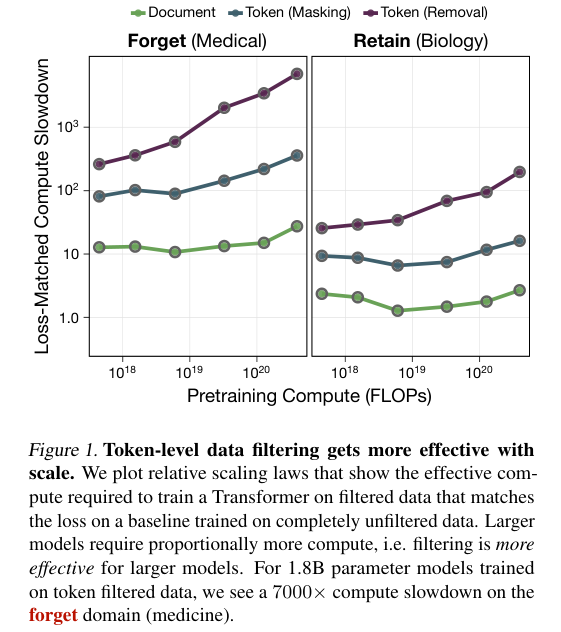
数据表明,对于18亿参数的模型,攻击者想要通过微调让模型重新学会被过滤掉的医学知识,其难度相当于在原始数据上训练的计算成本增加了7000倍。
这个倍数随着模型规模的增加而急剧上升,相比之下,传统的文档级过滤只能带来约30倍的阻碍。
在多项选择题的基准测试中,经过Token过滤的模型在医学问题(如MedMCQA和MedQA-USMLE)上的表现降到了接近随机猜测的水平。
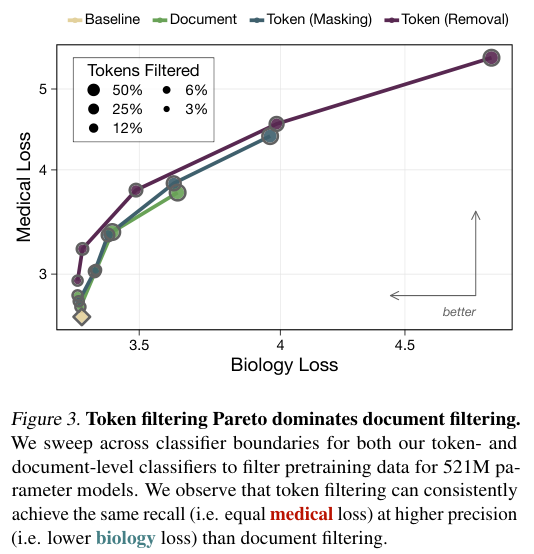
它彻底忘了怎么做医生,但在MMLU的生物学子集上,它的表现几乎没有下降,这种精准的切割能力,正是构建未来安全AI系统所急需的手术刀。
预训练干预构建坚固安全盾
一个安全机制如果能被几行微调代码轻易绕过,那它就是摆设。
现有的遗忘学习(Unlearning)技术是在模型训练好之后,试图通过反向优化让模型忘记特定知识。
这种方法在面对对抗性微调时显得极其脆弱,攻击者只需提供少量的相关数据进行再训练,被压抑的知识就会像弹簧一样反弹回来。
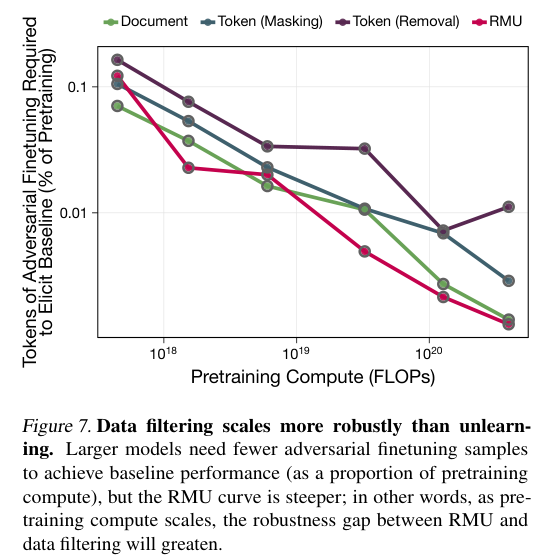
Token级过滤展现出了卓越的防御深度,实验对比了当前最先进的表示去学习方法RMU(Representation Misalignment via Unlearning)。
在面对对抗性微调攻击时,数据过滤表现出了高得多的抵抗力,随着模型规模的增大,这种差距还在拉大。
对于18亿参数的模型,RMU仅需极少量的微调数据就会失效,而Token过滤训练出的模型则像是一个从未学过医学的人,即使给他看几本医书,他也无法立刻成为专家,他需要从头开始积累基础概念。
人们通常担心如果模型完全不知道什么是危险知识,它就无法有效地拒绝有害请求,毕竟,不知道毒药是什么,怎么能拒绝制造毒药的请求呢。
以往的研究也支持这一观点,认为减少有毒数据的训练会让模型更难识别毒性,然而,这项研究得出了相反的结论。
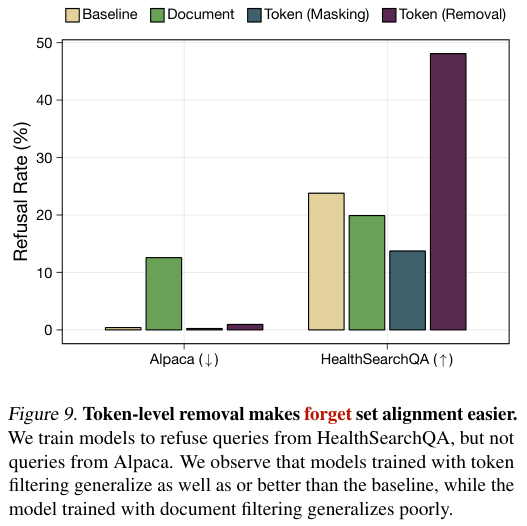
在进行拒绝能力训练时,经过Token过滤的模型表现甚至优于基线模型。
在面对HealthSearchQA中的医学问题时,使用移除策略训练的模型产生拒绝回复的比率是基线模型的两倍,同时在处理普通问题(如Alpaca数据集)时并没有表现出过度的拒绝倾向。
这表明,模型虽然没有掌握具体的医学知识,但它学会了区分已知领域和未知领域。
这种机制类似于人类的认知边界,一个不懂核物理的人,当被问及如何制造原子弹时,他能很清楚地知道这超出了他的知识范围,从而自然地无法回答或选择拒绝。
相比之下,文档级过滤训练的模型在拒绝任务上表现挣扎,经常错误地拒绝无害的请求,这可能是因为文档级过滤切断了上下文的连续性,让模型难以建立清晰的领域边界。
Token级过滤特别是将敏感词替换为<|hidden|>的做法,似乎帮助模型建立了一种这里有知识缺失的元认知,这种元认知成为了安全对齐的天然盟友。
对模型内部表征的探测进一步证实了这一点。
尽管模型无法回答具体的医学问题,但通过线性探针(Linear Probe)分析发现,模型依然能够极其准确地识别出哪些Token属于医学领域。
这说明模型构建了一个高质量的分类器,能够区分我学过的和我没学过的。
这正是实现可靠拒绝机制的基础,我们不需要教会模型如何作恶才能让它不作恶,我们只需要让它清楚地知道自己的知识边界在哪里。
弱分类器在大规模计算中创造奇迹
实施Token级过滤的最大工程挑战在于标签的获取。
互联网上的文本数据是海量的,我们不可能雇佣成千上万的医学专家去给每一个词打标签,也不可能在预训练过程中实时运行一个巨大的昂贵模型来判断当前词是否敏感。
因此,必须有一种廉价、自动化且足够准确的方法来生成大规模的Token级标签。
研究团队设计了一套精巧的弱监督流水线。
他们首先利用稀疏自编码器(Sparse Autoencoders, SAE)来自动发现模型中的概念特征。
SAE能够将神经网络复杂的激活模式分解为可解释的概念,例如药物副作用或生化反应,通过选取与目标领域(如医学)高度相关的SAE潜在特征,研究者可以自动标注出一部分高质量的种子数据。
接下来,利用这些种子数据,他们训练了一个小型的双向语言模型(biLM)作为分类器。
选择双向模型至关重要,因为一个词的含义往往取决于上下文,单词Virus在计算机上下文中是病毒代码,在生物学上下文中是病原体,只有同时看前文和后文,才能做出准确判断。
这个小型的biLM参数量仅为2.24亿,运行成本极低,仅占预训练总计算的一小部分,完全可以部署在数据处理流水线中。

如果这个廉价分类器不够准确怎么办?
在海量数据中,哪怕只有1%的误判,累积起来也是巨大的噪音,可能会误删重要信息或者漏掉危险知识。
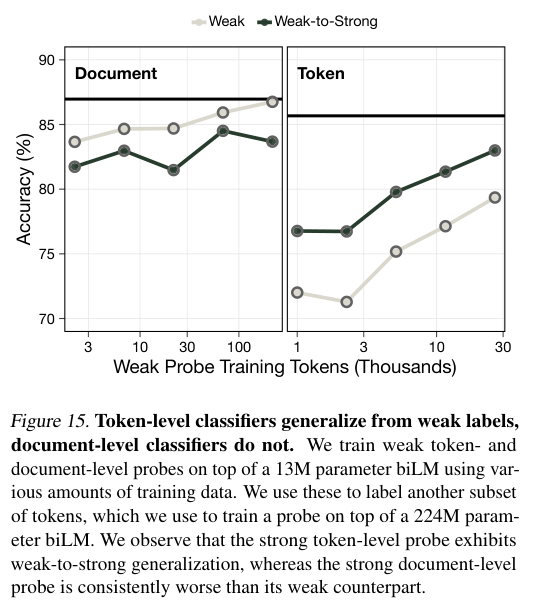
研究者模拟了标签噪声的影响,发现虽然低质量的标签确实会降低过滤效率,但只要我们足够激进,依然可以达成目标。
这里存在一种弱到强(Weak-to-Strong)的泛化效应,即使分类器只能识别出部分明显的医学词汇,或者使用较粗粒度的标签(如整句标注),只要我们在过滤时设定更严格的阈值,宁可错杀不可放过,大模型依然能够展现出惊人的适应性。
实验表明,即便分类器的错误率很高,只要过滤掉足够比例的Token,模型就能有效地遗忘危险知识。
大模型本身具有强大的恢复能力,对于那些被误删的通用知识(非危险的Retain部分),只要它们在数据集中其他地方以未被过滤的形式出现过,大模型就有能力通过上下文学习自行填补空白。
这种特性保证了我们在进行高强度过滤时,不会过度损害模型的通用智能。
最终,通过SAE引导的标签生成,结合高效的小型双向分类器,获得了一套可扩展的工业级解决方案。
它不需要完美的数据标注,也不需要昂贵的人工审核,仅凭机器生成的弱信号,就能在万亿级别的Token海洋中,精准地为大模型从源头阻断危险知识的摄入。
未来的AI安全或将深入到数据基因层面的编辑。
在AI不断变强的路上,我们可以有选择地让它在某些特定领域保持无知,这种有选择的无知,或许正是人类与超级智能共存的安全基石。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 3
3 0
0- 0



 已为社区贡献181条内容
已为社区贡献181条内容

所有评论(0)