别跟风买Mac Mini了!国产算力跑OpenClaw,只需5分钟
让我们把视角拉高一点。说实话,我很少会对一个底层工具感到如此兴奋。而最近的兴奋,坦诚地讲,几乎都来自AI Agent。看着Clawdbot在屏幕上自动操作电脑,像拥有了生命一样,我确实被震撼到了。但震撼之余,更多的是焦虑和思考。因为我知道,这种流畅的体验目前主要集中在CUDA生态中。比如Ollama这样的工具,让大模型在常见设备上的部署变得非常简单。而我们手中的国产显卡,也同样值得拥有这样便捷的使
Clawdbot火爆全球,国产算力却不能用?AI Agent迎来高光时刻:Ollama只支持CUDA,中国团队直接把国产版开源了!正面硬刚Ollama,5分钟让国产芯片跑通OpenClaw!
最近几天,整个AI圈都被一个名叫「Clawdbot」的智能体刷屏了。
这个7×24小时永不下班的「AI贾维斯」,让全世界集体疯魔。
一时间,OpenClaw成为全网热词(原Clawdbot)的仓库更是涨到了夸张的13万Stars!
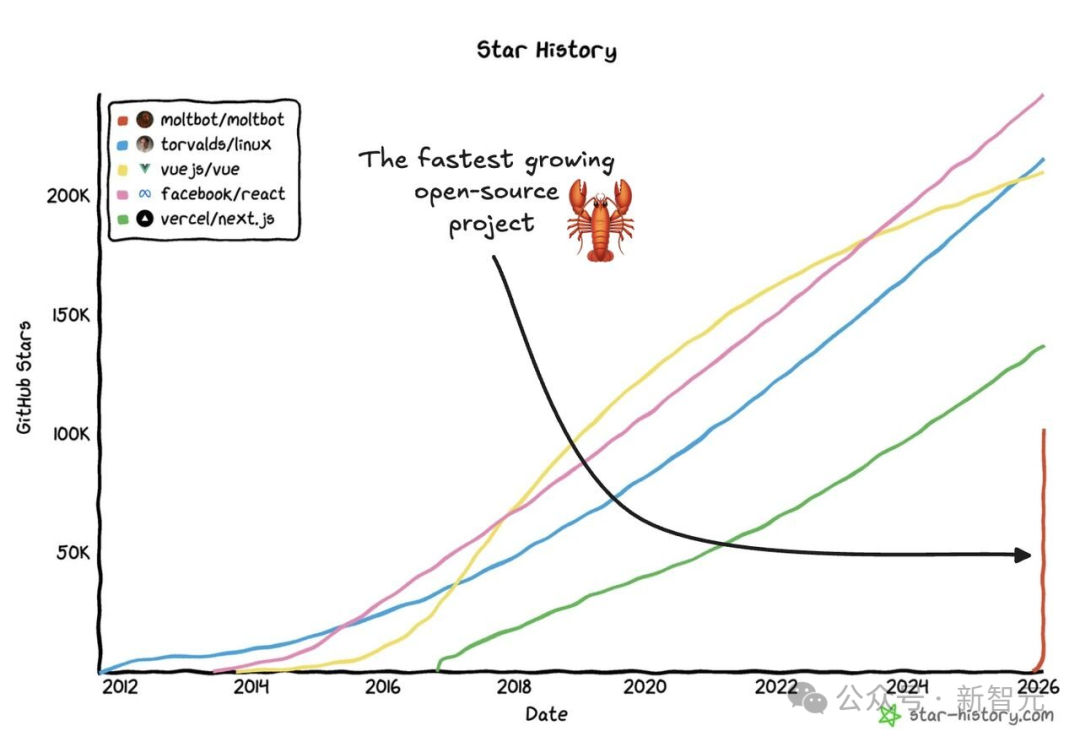
全世界的开发者都沉浸在这场2026开年的「智能体」革命中!
但Clawdbot要想跑得顺畅,会疯狂消耗大模型服务的tokens,尤其是部署到Moltbook中的智能体,它们正在疯狂发帖和评论。
这些tokens可都是钱啊!
网友们纷纷晒出巨额账单,即使轻量使用一天往往也要消耗数十美元!
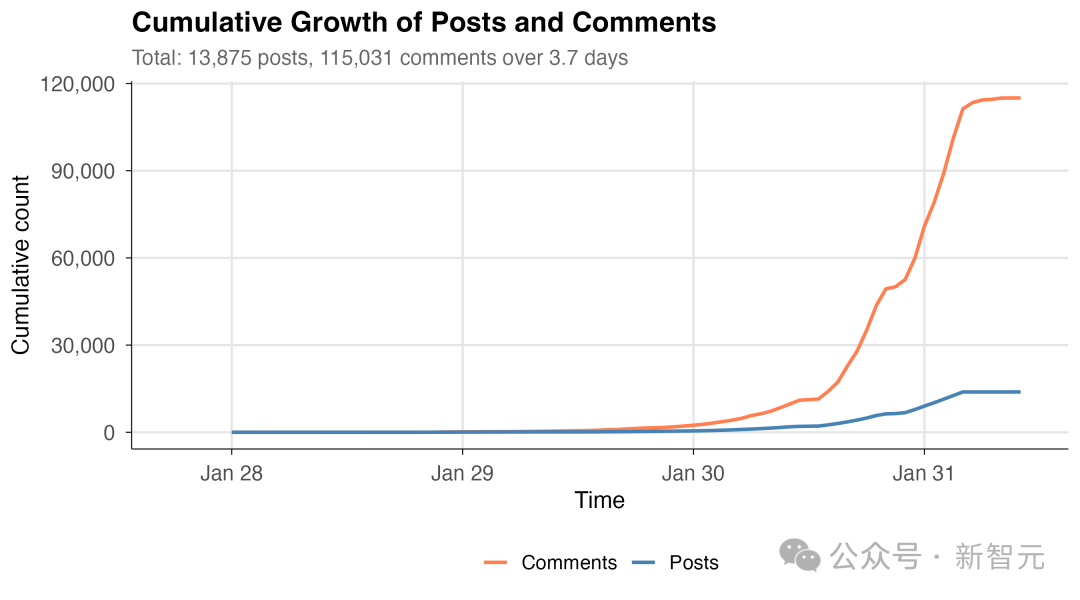
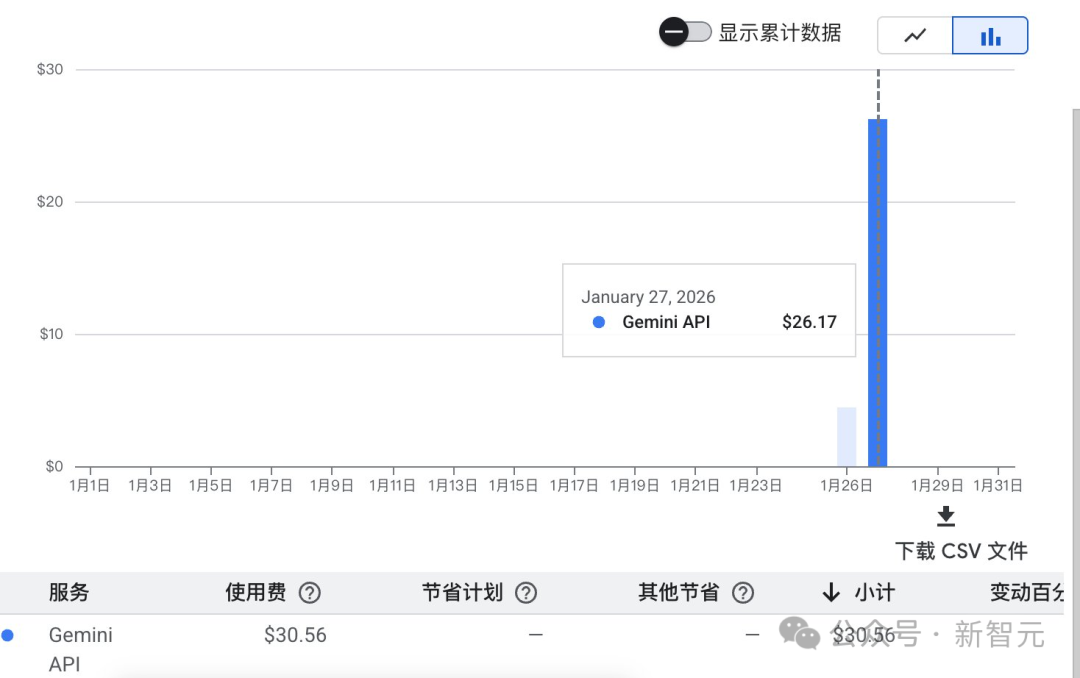
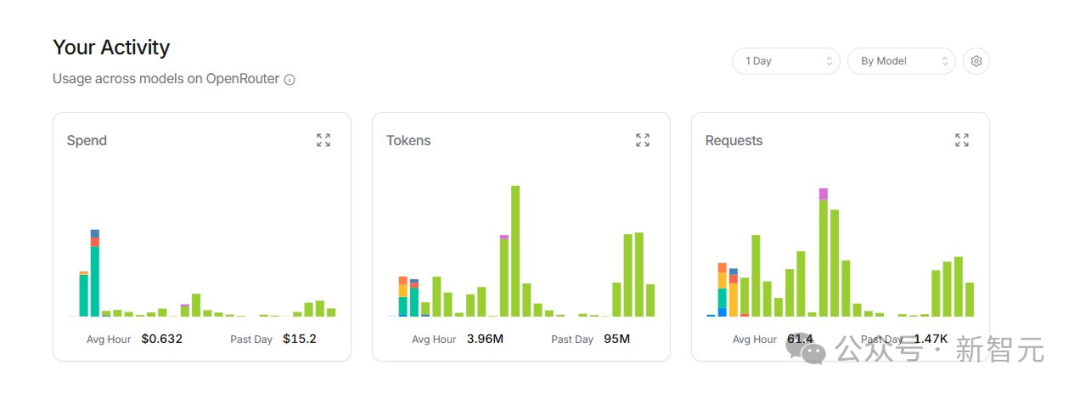
所以,很多极客和开发者开始用本地大模型提供服务。
比如用Ollama拉取一个本地模型,就完全免费了。
Ollama作为本地大模型部署的事实标准,通常只支持NVIDIA CUDA生态和MacBook等。
但问题来了,如果你手里有的是国产芯片和算力卡呢?
Ollama作为本地大模型部署的事实标准,通常只支持NVIDIA CUDA生态和MacBook等。
国产芯片用户?在这场AI智能体狂欢中,往往面临着更多的挑战。
但这本不该如此。
在Clawdbot们引爆全球的当下,国产算力不应该缺席。
在全球开发者借助Ollama或云服务便捷地加入智能体浪潮时,国产芯片用户却往往需要花费更多精力在驱动和环境配置上。
在别人已经让AI替自己干活的时候,我们还卡在「模型跑不起来」这一步。
国产芯片的架构差异与配置流程的复杂性,有时会让想要支持国产算力卡的开发者感到困扰。
在AI Agent爆发式增长的今天,国产算力不能缺席这场狂欢。
今天,终于有人带来了答案——玄武CLI,专为国产芯片打造的「国产版Ollama」。
5分钟启动模型服务,一行命令跑通大模型,让国产芯片也能跑起7×24小时的AI员工。
2026年2月2日,玄武CLI正式开源!
GitHub:
https://github.com/TsingmaoAI/xw-cli
Gitcode:
https://gitcode.com/tsingmao/xw-cli
欢迎Star、Fork、提Issue、提PR,一起让国产芯片跑模型这件事变得更简单。
国产芯片跑模型:行路难,行路难
先来让我们聊聊国产芯片用户到底「有多难」。
架构碎片化+配置门槛高+问题无处求援+等等,这些问题往往劝退了很多想要支持国产算力卡的开发者。
华为昇腾CANN、沐曦MACA、摩尔线程MUSA...每家芯片都是独立生态,互不兼容。
装驱动、配环境、编译源码,一个模型折腾一周是常态。有位老哥吐槽:
不是不爱国,是真的装不动了。
开发者的诉求很简单:我不想当运维专家,我只想一行命令跑模型。
在这个AI Agent已经爆发增长的时候,如何让我们的国产算力不缺席这场狂欢?
玄武CLI:国产芯片的Ollama时刻
针对这些痛点,清昴智能推出了玄武CLI——一个专为国产芯片打造的大模型部署工具。
如果要简单一句话介绍玄武CLI,它就是国产版Ollama,专为国产算力而生。
如果你用过Ollama,5分钟就能上手玄武。
如果你没用过,10分钟也够了。
零门槛上手,1分钟部署
玄武CLI的部署有多简单?
解压即运行。 基于Docker极简部署,告别繁琐的环境配置。只要装好基础驱动和Docker,最快1分钟启动服务。
而对于32B参数量及以内的模型,模型启动可以在30s内完成。
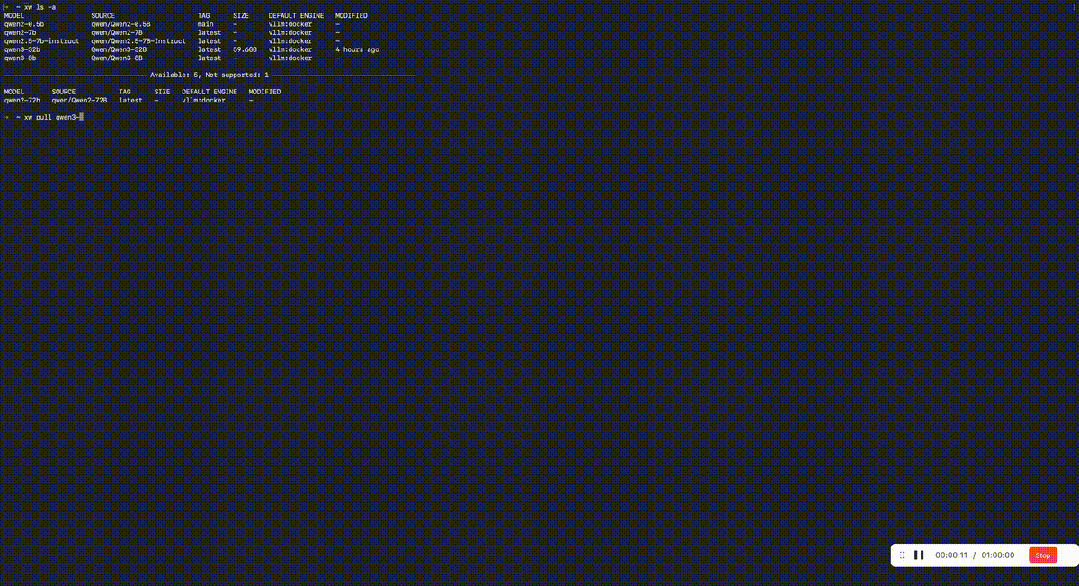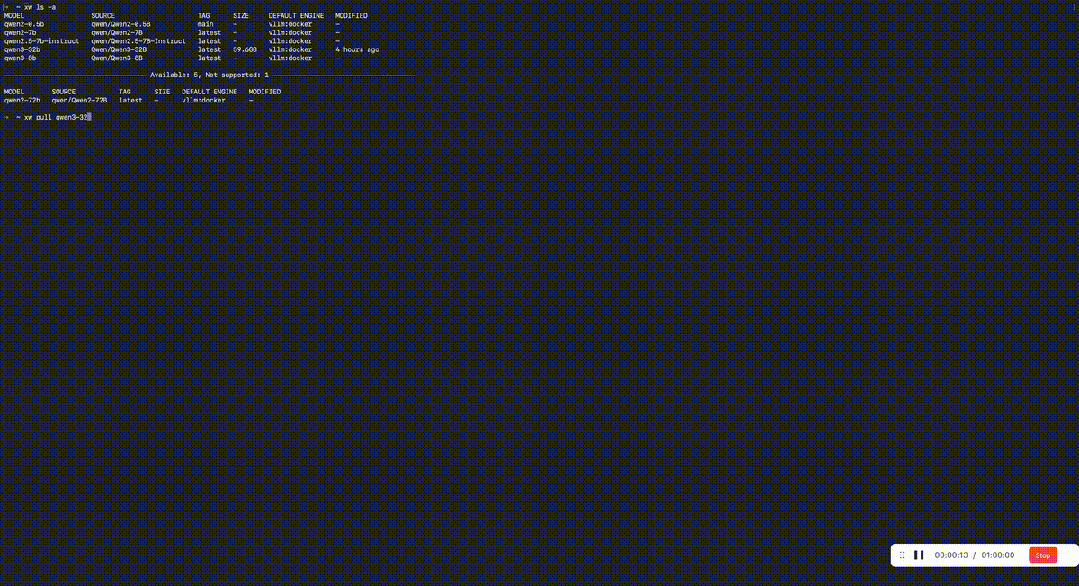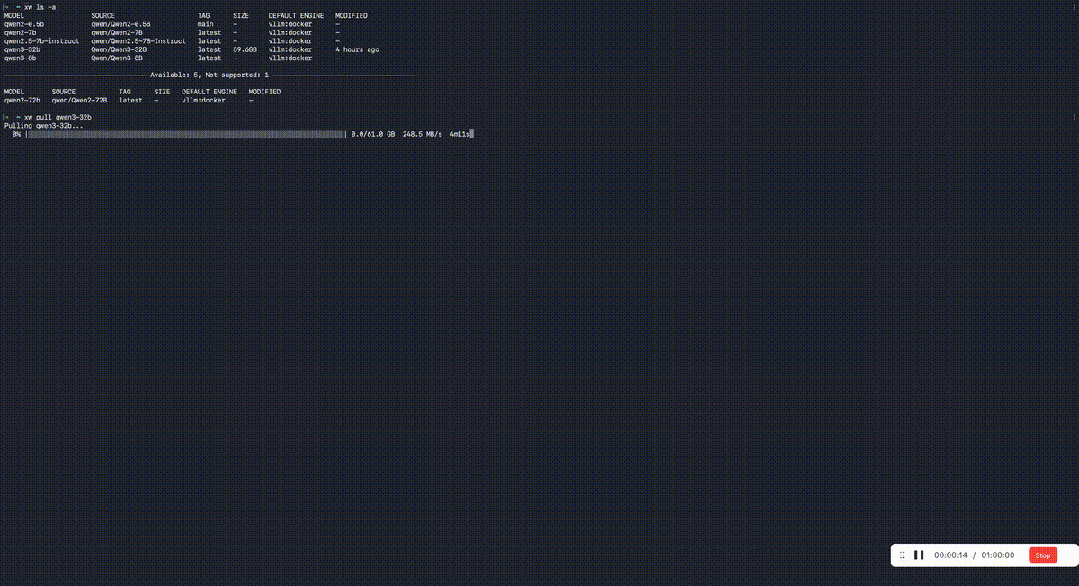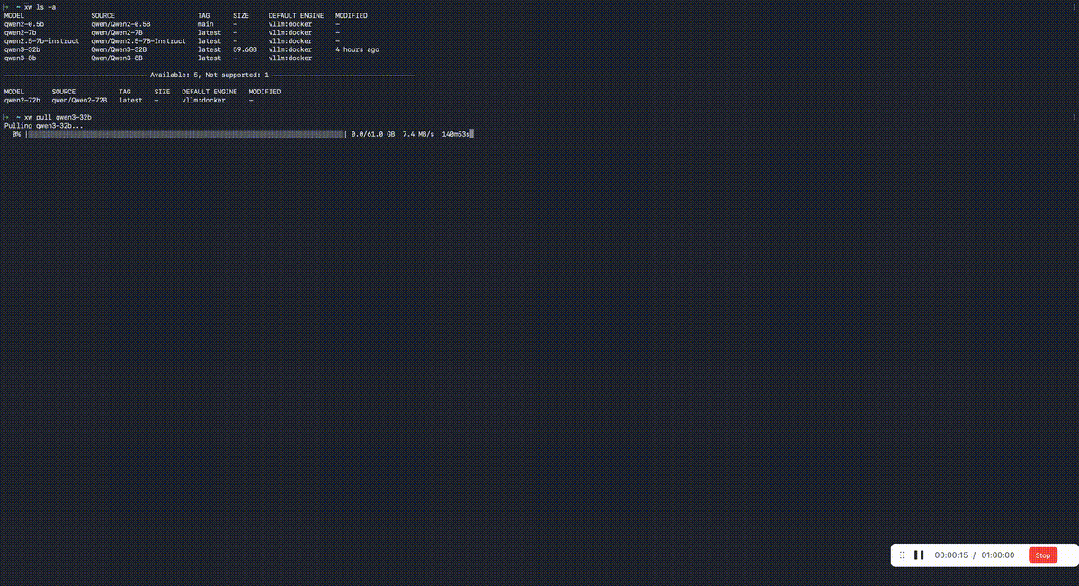
更爽的是,玄武CLI的命令集与Ollama高度一致:
xw serve # 启动服务
xw pull # 下载模型
xw run # 运行模型
xw list # 查看模型列表
xw ps # 查看运行状态
会用Ollama?那你已经会用玄武了,零学习成本迁移。
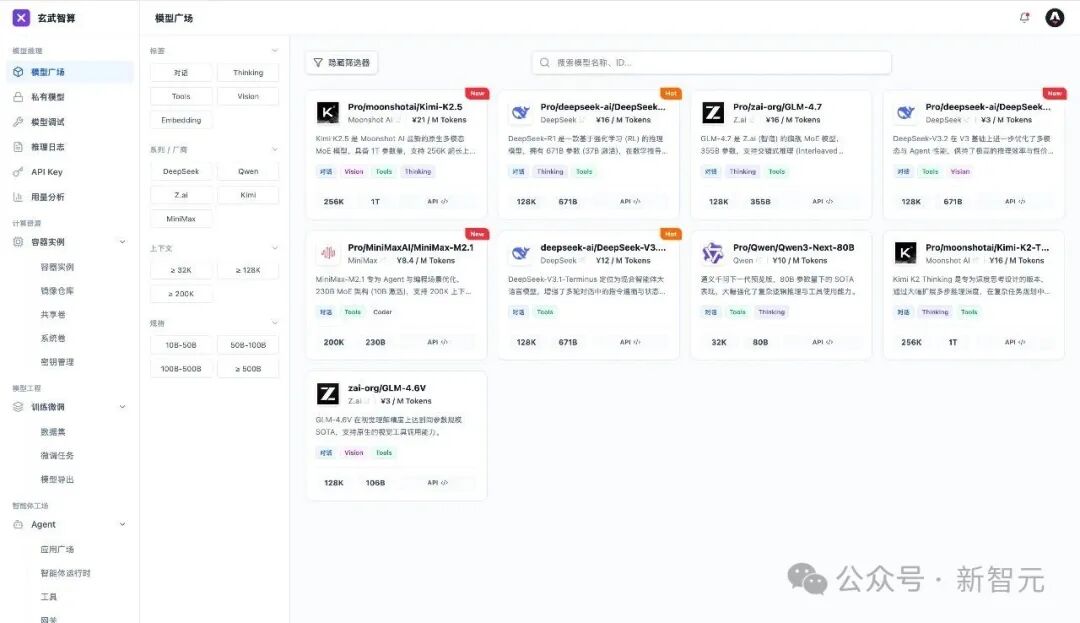
只需一句命令xw pull qwen3-32b,即可快速下载对应模型。
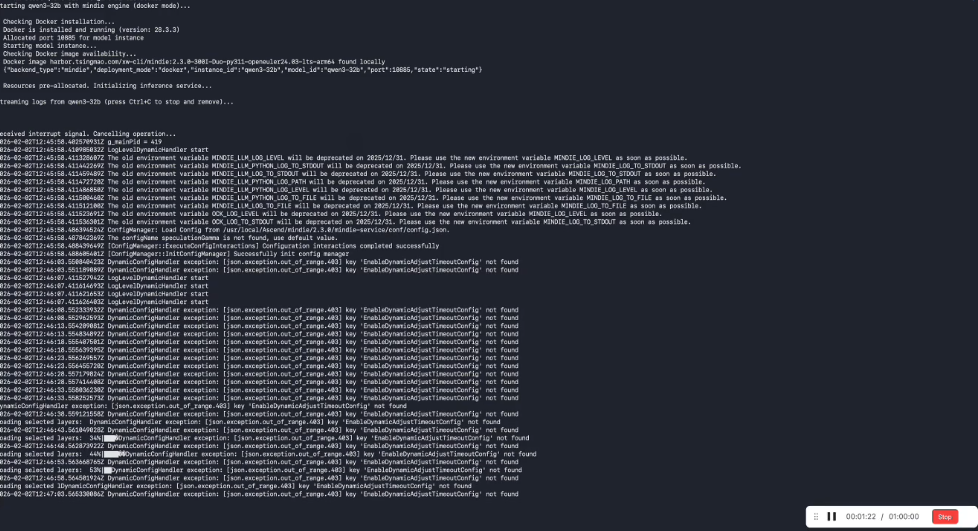
以前在国产算力卡上跑通模型非常麻烦,环境配置和代码调试往往要占据不少时间。
有时候大家调侃说:「需要配环境3天,改代码500行」。
但有了玄武CLI,只需要一行命令马上运行。
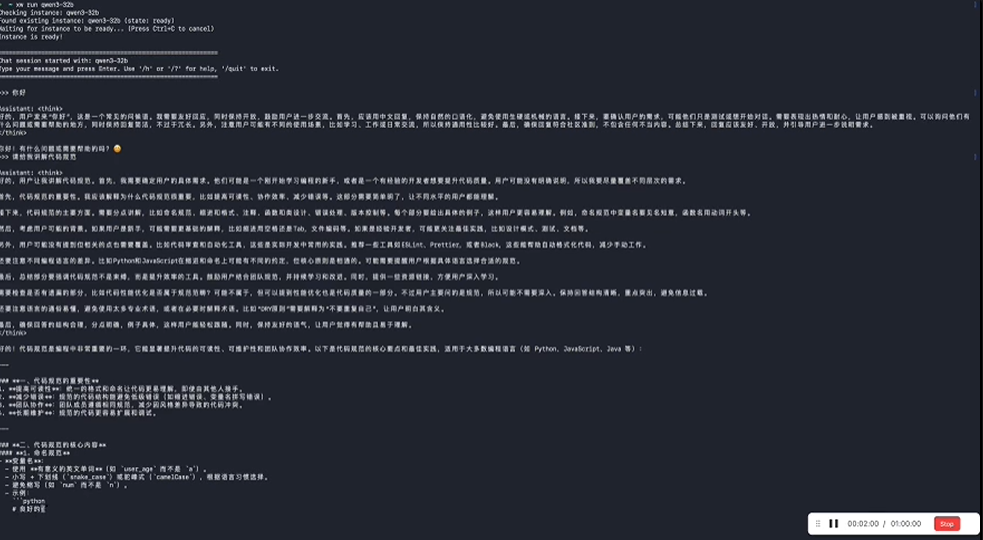
与Clawdbot联动,国产芯片也能玩AI智能体
回到开头的问题:Clawdbot这么火,国产芯片用户能玩吗?
现在可以了。
玄武CLI可以作为Clawdbot等AI智能体的模型后端服务,提供低门槛的本地推理能力。
玄武CLI,再加上Clawdbot,就相当于是国产芯片用户的AI贾维斯。
你的华为昇腾、沐曦、燧原...终于也能跑起7×24小时的AI员工了。
在这波AI智能体风暴中,国产算力不再缺席。
应用无缝替换,多引擎可供选择
玄武CLI完全兼容OpenAI API标准。
意味着什么?你之前基于LangChain、LlamaIndex、或者各种IDE插件开发的应用,只需要改一行API地址,就能无缝切换到玄武CLI后端。
不需要重构应用栈,不需要改业务逻辑,换个URL就完事了。
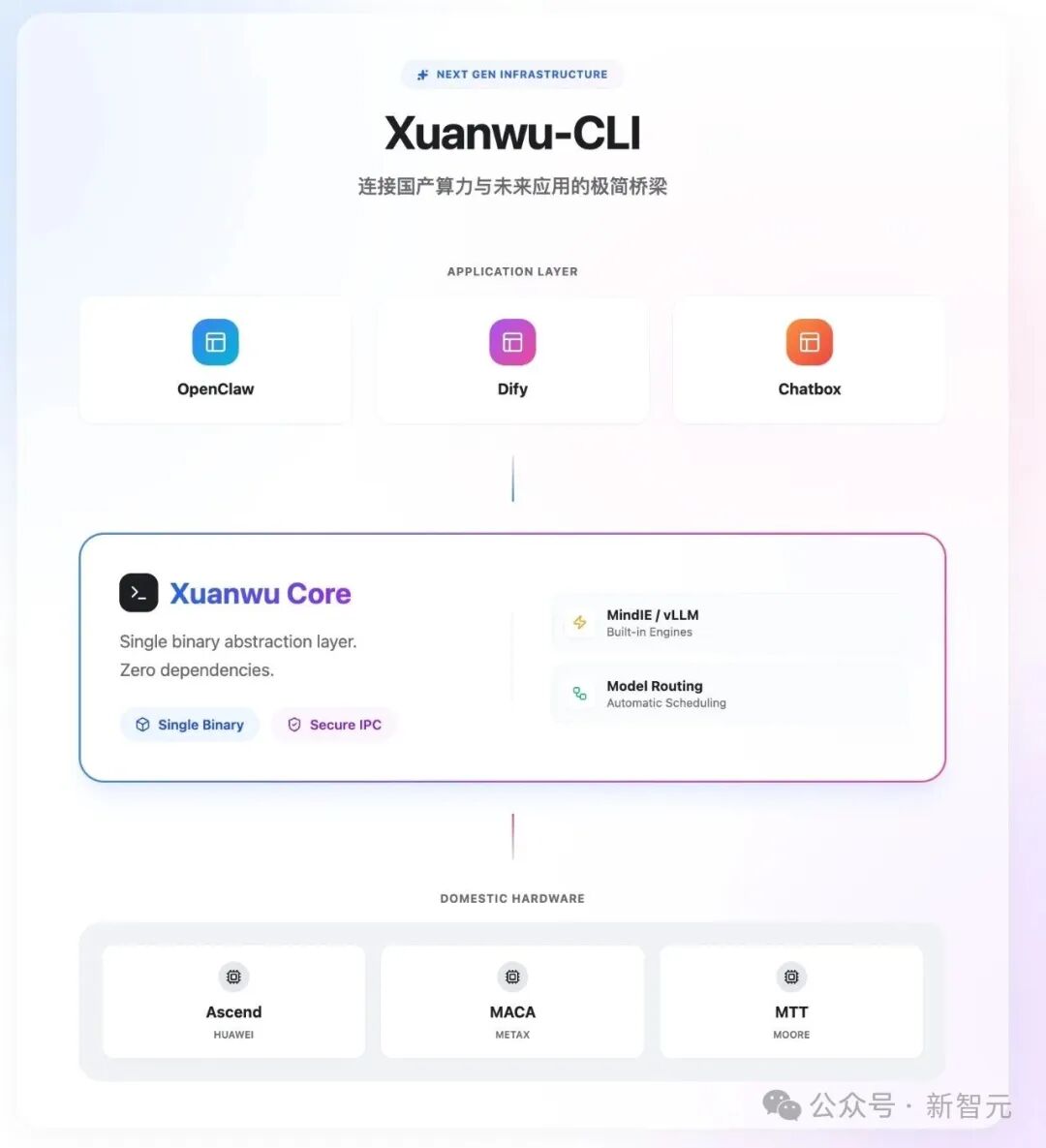
这对企业用户来说太友好了。现有的AI应用资产,可以直接复用。
多推理引擎深度适配优化,实现超强性能与超多模型覆盖
玄武CLI不仅仅是一个工具,更是一个打通硬件与模型的「全能引擎中枢」。
通过自研的MLGuider推理引擎,彻底解决企业级部署中性能与兼容性的矛盾。同时,玄武CLI也支持芯片原生框架和社区广泛使用的推理引擎,如昇腾原生MindIE、社区框架vLLM等,支持开发者针对多引擎进行性能最优选择。
玄武CLI支持完全离线运行,无需联网、不依赖云端。
对于对数据隐私敏感的企业用户来说,这一点至关重要。所有的推理都在本地完成,模型权重不上云,推理数据不外传。
国产原生适配,告别配置噩梦
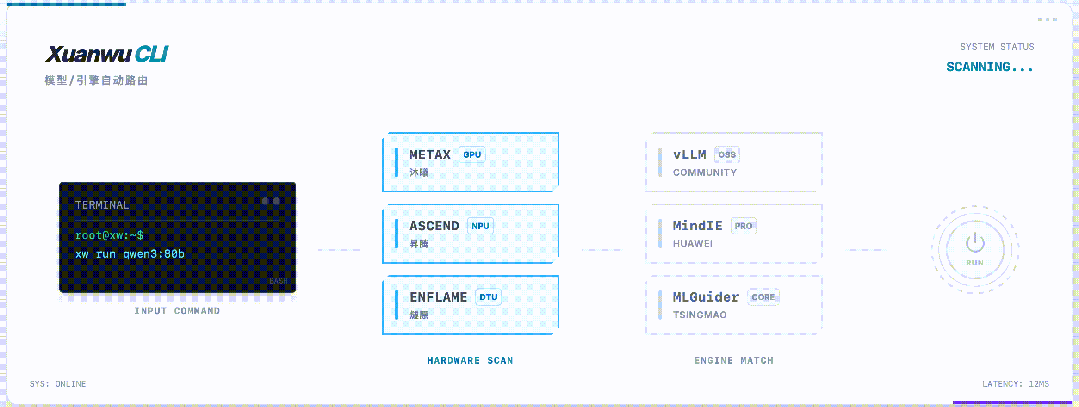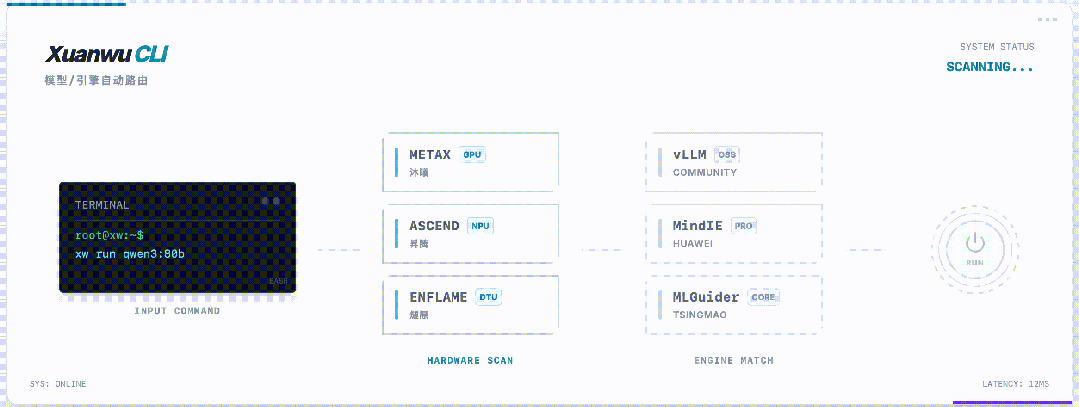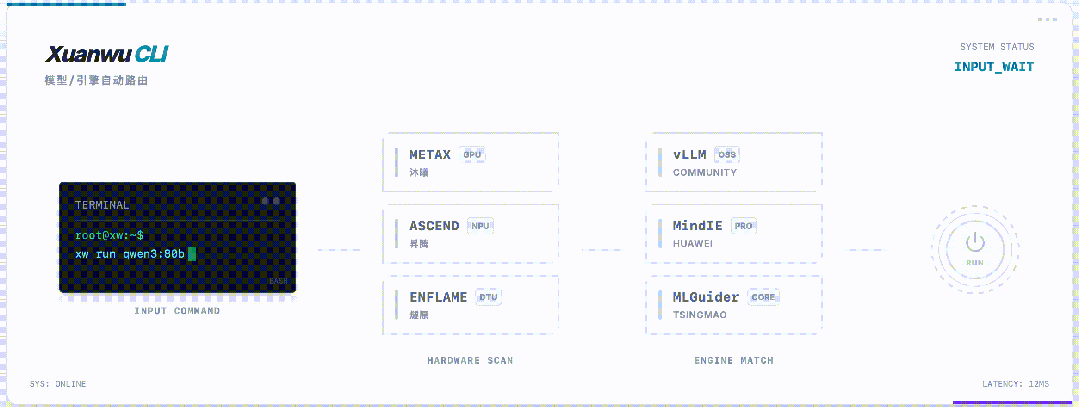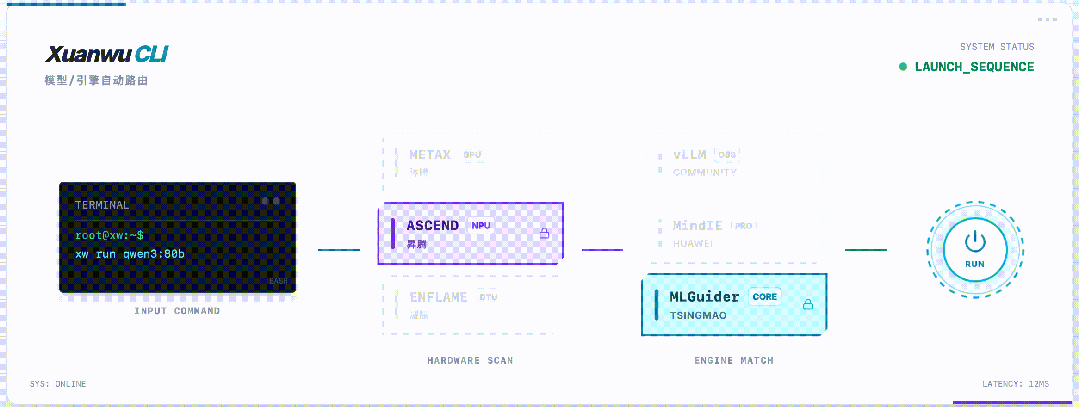
最后,玄武CLI还藏了一个大招:自动识别芯片,智能匹配引擎。
华为昇腾全系列、沐曦...不管你用哪张卡,玄武CLI都能自动识别,并匹配最优的推理引擎。
无需查文档,无需改参数,无需编译源码。
「架构碎片化」这个国产芯片最大的痛点,玄武CLI就用一个自动检测功能,直接干掉了。
玄武集群版
千卡级国产智算底座
如果说玄武CLI解决的是单机部署问题,但对于智算中心、大型企业来说,还需要更强大的集群管理能力。
这就是玄武智算平台(集群版)的用武之地:国产异构算力的统一管理中枢。
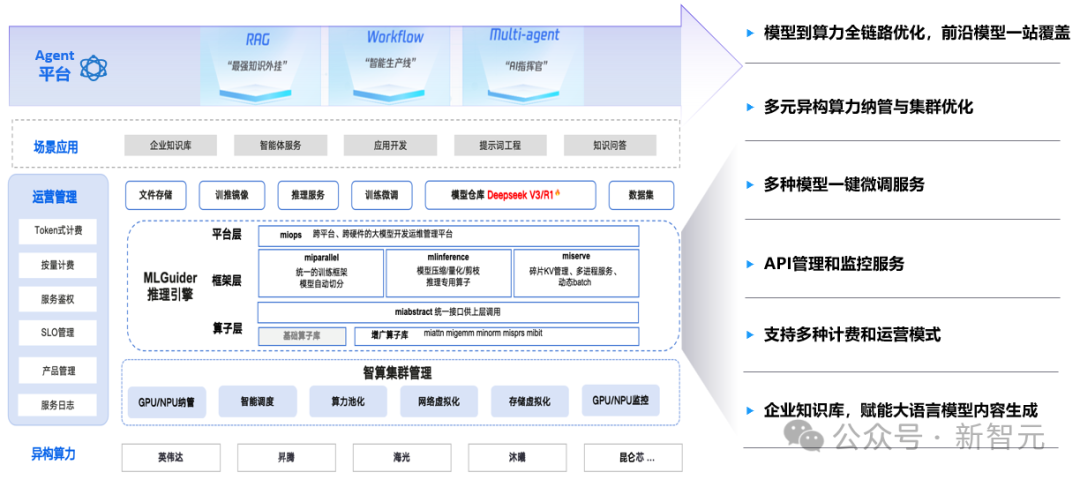
玄武集群版首要解决的是多芯异构,统一纳管的难题,它打破了不同厂商芯片各自为战的局面,将华为、寒武纪、昆仑芯、摩尔线程、沐曦、燧原等十余款国产芯片纳入统一调度体系。
简单说,这是一套从芯片到智能体的全栈解决方案。
不同厂商的芯片,以往需要各自独立管理。
玄武集群版提供了统一的异构算力纳管能力,一套平台管理所有芯片。
在构建千P级大规模异构算力底座的同时,平台通过全栈自动化技术实现了高稳定性与易运营,为企业提供了一个久经实战考验、性能极致的生产级智算中枢。
这才是「国产芯片生态」应该有的样子——不是各自为战,而是统一调度。
玄武集群版还实现了从技术底座到「运营平台」的跨越。除了兼容多模型与多引擎,它还内置了完善的API管理和计量计费模块,助力企业和智算中心像公有云厂商一样,实现算力资源的对内精细管理与对外商业化运营。
写在最后
这不只是一个工具,这是一场卡位战
让我们把视角拉高一点。
说实话,我很少会对一个底层工具感到如此兴奋。
而最近的兴奋,坦诚地讲,几乎都来自AI Agent。看着Clawdbot在屏幕上自动操作电脑,像拥有了生命一样,我确实被震撼到了。
但震撼之余,更多的是焦虑和思考。
因为我知道,这种流畅的体验目前主要集中在CUDA生态中。
比如Ollama这样的工具,让大模型在常见设备上的部署变得非常简单。
而我们手中的国产显卡,也同样值得拥有这样便捷的使用体验,而不是因为生态差异而被搁置。
这不仅是产品的竞争,更是标准的竞争。
历史无数次证明:生态的壁垒,远比算力的壁垒更难攻破。
当开发者面对复杂的文档与不兼容的驱动,难免会消磨热情。
面对海外成熟的AI生态标准,国产算力也在努力追赶,逐步解决各家标准不一、兼容性挑战等问题。
这正是我们要解决的关键问题。我们不缺硬算力,我们缺的是那个能把所有珍珠串起来的「线」。
而清昴,把这个进程,硬生生拽回了国产算力的轨道上。
并且直接选择开源,造福所有被生态墙挡在门外的开发者。
玄武CLI的出现,不仅仅是多了一个工具。
它是让AI从云端神坛,真正落地到每一块国产芯片、每一台国产服务器、每一个开发者手中的关键一步。
以前我们总说,国产算力缺生态。
现在,生态来了。
当玄武CLI跑通的那一刻,我仿佛看到了未来的样子:
数以万计的AI智能体,不再受限于它人的硬件,而是在我们自己的算力上,7×24小时地思考、执行、创造。
而那时,才是我心中,国产算力真正的AI时代。
玄武CLI,就是其中的一个答案。
如果你也认同这个方向,如果你也想参与这场变革,欢迎Star、Fork、提PR。
让我们一起,用代码改变AI算力格局。
github:
https://github.com/TsingmaoAI/xw-cli
gitcode:
https://gitcode.com/tsingmao/xw-cli

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 6
6 0
0- 0



 已为社区贡献181条内容
已为社区贡献181条内容

所有评论(0)