优质skills推荐:复刻Manus,Planning with Files 让 AI 代理不再失忆
优质skills推荐:复刻Manus,Planning with Files 让 AI 代理不再失忆
文章目录
- 1. 把规划写进文件:Planning with Files 让 AI 代理不再失忆
- 2. 怎么落地:在 Claude Code 里用起来(也能迁移到 Cursor 等)
- 3. SKILL.md 重要性
- 4. 下一步:10 分钟上手
- 5. 自检清单
- 6. 参考文献
1. 把规划写进文件:Planning with Files 让 AI 代理不再失忆
地址:https://github.com/OthmanAdi/planning-with-files
它是什么:一个把“任务规划/进度/知识”落到三个 Markdown 文件里的工作流插件(支持 Claude Code/Cursor/Gemini CLI 等)。
解决什么:让 AI 在长任务里不漂移、不失忆,能持续对齐目标并留下可追溯的过程记录。
怎么用:安装后用 /plan 或 /planning-with-files:start 初始化三文件,之后按规则更新并让 hooks 强制校验。
1.1. 前言
你有没有这种体验:让 AI 帮你做一个“看起来不复杂但会有很多细节”的任务——写文章、做调研、改项目、排线上问题。
前 10 分钟很爽;50 次工具调用之后,AI 开始“忘了最初要做什么”、重复失败、把一堆信息塞在上下文里,最后还会在你没核对完之前说“搞定了”。
planning-with-files 就是专门解决这个问题的:它不靠更长的 prompt,而是把“重要信息”从上下文里搬到文件系统里,变成持久的工作记忆。
1.2. 背景与痛点:为什么你需要“文件化规划”
项目 README 把问题说得很直白:AI 代理的上下文像 RAM——有限、易失;而文件系统像 Disk——持久、容量近似无限(README)。
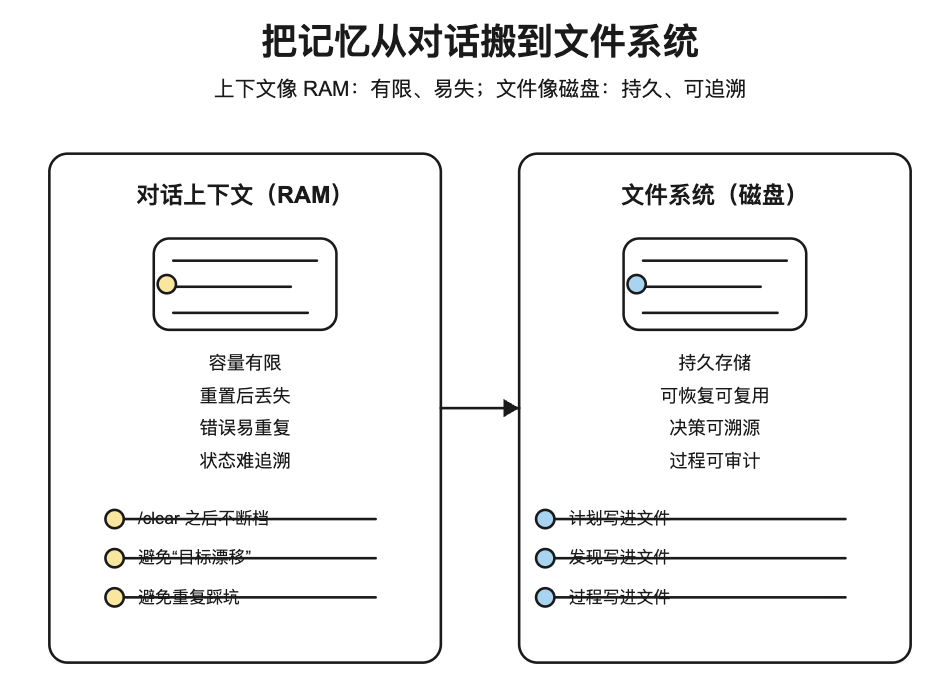
Claude Code(以及多数 agent)在长任务里常见的四个坑(来自项目 README):
| 坑 | 典型表现 | 结果 |
|---|---|---|
| 易失记忆 | 上下文重置//clear 后,计划和结论丢了 |
返工、重复问答 |
| 目标漂移 | 工具调用多了,开始偏题或“自说自话” | 交付不符合目标 |
| 错误不留痕 | 失败没被记录,下一次又踩同一个坑 | 效率雪崩 |
| 上下文塞爆 | 把资料堆到对话里,不写入文件 | 不可追溯、不可复用 |
这类问题,不靠“让 AI 更努力一点”解决,而靠把工作流改成“可持久化”。
1.3. 核心观点:3 文件 + hooks,把 AI 从聊天拉回工程流程
这个模式很简单(来自 README 与 SKILL.md):每个复杂任务只维护 3 个文件。
task_plan.md → 任务分阶段与状态(计划与对齐)
findings.md → 研究发现与关键决策(知识沉淀)
progress.md → 会话日志、操作记录、测试结果(过程可追溯)
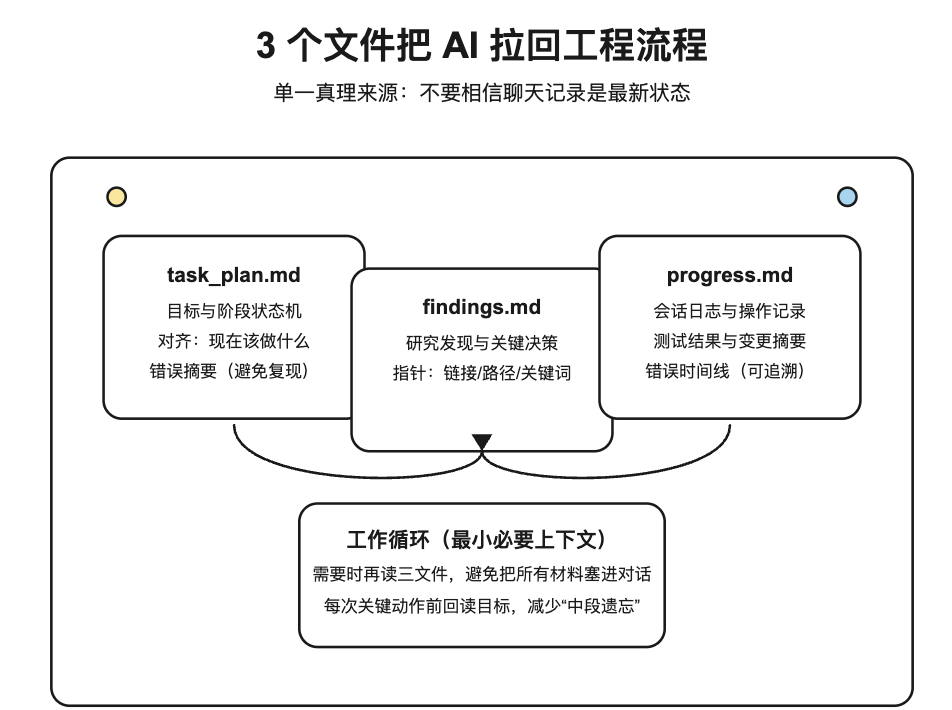
我看下来,这个项目基本就围着这三个文件转:hooks 负责在关键时点读/提醒,脚本负责初始化与校验,session recovery 负责在 /clear 后把遗漏信息补回这三个文件。
1.3.1. 这个项目与“上下文工程”是不是一回事?
算一类方法。更具体一点:planning-with-files 是一种偏工程实现的 上下文工程(Context Engineering) 方案。
直白说:与其只在 prompt 里堆指令,不如系统性地设计 模型每一步看什么、看多少、按什么结构看,并且把重要信息放到“可恢复、可复用、可校验”的载体里。
planning-with-files 的做法正是把上下文从“聊天记录”迁移到“文件系统”,典型体现包括:
- 单一真理来源(Single Source of Truth):不再相信对话历史是最新状态,而是让
task_plan.md/findings.md/progress.md承担最新事实。 - 状态显式化:阶段状态(
pending/in_progress/complete)、决策、错误都被写在文件里,可读可查。 - 最小必要上下文:重要信息写入文件,需要时再读;避免把所有内容一直塞在对话里。
- 思考与行动分离:先把发现/决策写入
findings.md,再动手改文件/跑命令,减少“边想边改”导致的污染。
如果你看过“复刻 Manus 工作流”的那类文章,它们常把上下文工程总结成一些更通用的原则(例如:前缀稳定以利缓存、工具定义尽量稳定等)。你可以理解为:planning-with-files 把其中最关键、最容易落地的一部分(外部化记忆 + 状态机 + 可验证收尾)做成了开箱即用的工具。
在一些更底层的上下文工程实践里,还会提到 KV-cache 友好(保持前缀稳定)、工具集的掩码而非频繁删改等原则;它们和本项目的目标一致:降低上下文波动、提高稳定性与可控性。
1.3.2. Manus 六大上下文工程原则(reference.md)如何落到本项目
项目在 skills/planning-with-files/reference.md 里把“Manus 的 6 条原则”写得很直白。你不需要全部照抄,但我更建议把它当作“写/用 skills 的经验手册”,用来做自检。
| 原则 | 原文要点(节选) | 在本项目里的落地 | 给你使用 skills 的经验 |
|---|---|---|---|
| Design Around KV-Cache | “Keep prompt prefixes STABLE”“NO timestamps in system prompts” | 本项目通过“尽量稳定的流程与文件结构”减少上下文波动(更偏 workflow 侧) | 写你自己的 skill 时:把动态信息放在用户输入/项目文件里,不要写进固定前缀(例如 system 指令开头) |
| Mask, Don’t Remove | “Don’t dynamically remove tools (breaks KV-cache)” | allowed-tools 是稳定白名单;不要每轮改一套“可用工具” |
做能力收敛时尽量用“规则/ gating”而不是频繁改 prompt 结构(减少上下文漂移) |
| Filesystem as External Memory | “Markdown is my ‘working memory’ on disk.” | 三文件就是外部化记忆:计划/发现/过程分别落盘 | 把“结论 + 指针”写进文件:URL、文件路径、关键词,确保压缩后仍可回溯 |
| Manipulate Attention Through Recitation | “Re-read task_plan.md before each decision.” | PreToolUse 每次关键动作前回显 task_plan.md |
卡住时不要追加更多 prompt,先回读 task_plan.md 的 Goal/Current Phase,把目标拉回注意力窗口 |
| Keep the Wrong Stuff In | “Leave the wrong turns in the context.” | 要求记录 Errors(并且不鼓励静默重试) | 失败要显式记录:错误是什么、尝试第几次、怎么修;这会显著减少“重复踩坑” |
| Don’t Get Few-Shotted | “Uniformity breeds fragility.” | 通过“阶段化 + 复读目标”减少漂移,但仍建议适度变体 | 当你发现自己在反复做同一套动作时,刻意引入变化:换检索关键词、换验证方式、重新陈述目标,避免机械循环 |
你会发现:planning-with-files 不等于把 Manus 的每条底层技巧都实现(例如 KV-cache 的统计与 logit masking),但它把其中“最能提高成功率、最不依赖底层平台能力”的那部分(外部化记忆 + 目标复读 + 错误留痕 + 可验证收尾)做成了工具。
如果你只想带走一套“立刻能用”的规则(同样来自 reference.md 的理念抽象),可以记这 5 条:
- 文件是记忆:重要信息必须落盘,聊天记录只是缓存。
- 压缩要可恢复:即使你删掉大段内容,也要保留 URL/文件路径/关键词这样的“指针”。
- 目标要复读:每次关键决策前回读
task_plan.md,对抗“lost in the middle”。 - 失败要留痕:不要静默重试;把错误和修复写进文件,下一轮就不会再撞同一堵墙。
- 动作要有变体:当你发现自己进入重复循环,主动换一种验证/检索方式,避免被“少样本模式”带偏。
配合 hooks(PreToolUse / PostToolUse / Stop),它会在关键时点强制你“回看目标、写入发现、验证完成”。(见 SKILL.md、workflow.md)
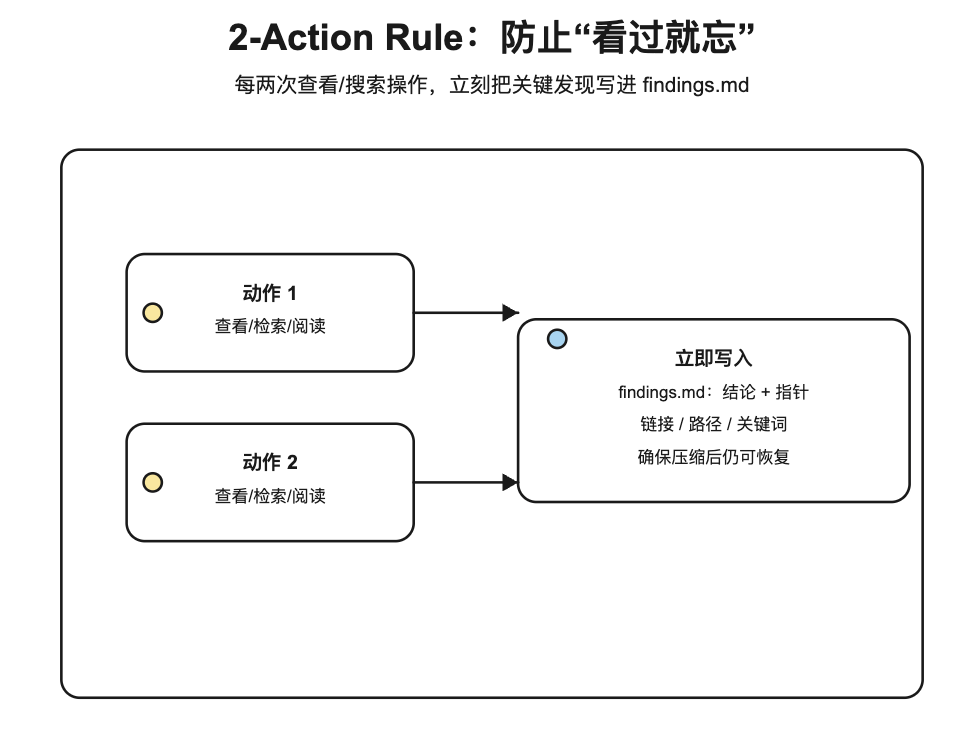
1.3.3. 2-Action Rule:防止“看过就忘”
项目里有个很“反直觉但有效”的硬规则:每做两次查看/浏览/搜索操作,就必须立刻把关键发现写进 findings.md。
原因很现实:图片、网页、零散片段不进入文本文件,就会在上下文压缩或重置后消失(quickstart.md、workflow.md)。
2. 怎么落地:在 Claude Code 里用起来(也能迁移到 Cursor 等)
2.1. 安装:一条命令把工作流装进 Claude Code
项目提供了 Claude Code 插件安装方式(来自 README):
claude plugins install OthmanAdi/planning-with-files
安装后会出现两个常用命令:
| 命令 | 更好记的输入 | 用途 |
|---|---|---|
/planning-with-files:plan |
/plan |
更短的规划命令(v2.11.0+) |
/planning-with-files:start |
/planning |
开始会话与规划流程 |
2.2. 五步工作流:从“开始干活”变成“先规划再执行”
五步流程的“为什么”和项目内部机制,我已经在后面的 # 3(拆解原版 SKILL.md) 和 2.5(examples 演示) 里拆开了。这里给你一个最短执行清单,照着做就能跑起来:
- 运行初始化脚本或复制模板,生成
task_plan.md/findings.md/progress.md - 在
task_plan.md写清 Goal,并拆 3–7 个 phases - 工作过程中按“发现/过程/计划”分别写进三个文件
- 每两次查看/搜索就更新一次
findings.md(2-Action Rule) - 收尾前用
check-complete.sh(或让 Stop hook 自动跑)确认 phases 全部 complete

2.2.1. FIRST:为什么一开始要“检查上一会话”(Session Catchup)
这一段想做的事很简单:先确认“上一次会话有没有没写进三文件的关键信息”。如果你从来没用过 /clear,或者这就是第一次使用,可以先跳过。
推荐习惯是:每次开始一个预计会很长的任务,先跑一次 session-catchup.py;它会告诉你“从上一次更新 task_plan.md/findings.md/progress.md 之后,你们还聊了什么、做了什么”。
2.2.2. Important:模板文件与三文件分别放哪(新手最常踩坑)
这一点在 skills.sh 的页面写得很清楚:
- Templates 在插件/skill 安装目录(例如
${CLAUDE_PLUGIN_ROOT}/templates/) - 你的三文件 必须放在当前项目目录(project root)
可以这么记:安装目录是“工具箱”,项目目录是“工作台”。
2.3. 会话恢复:/clear 之后怎么不断档
当上下文满了你需要 /clear,最容易发生的事是:你完成了一堆研究/修改,但还没来得及把“结论/状态”写进三文件。
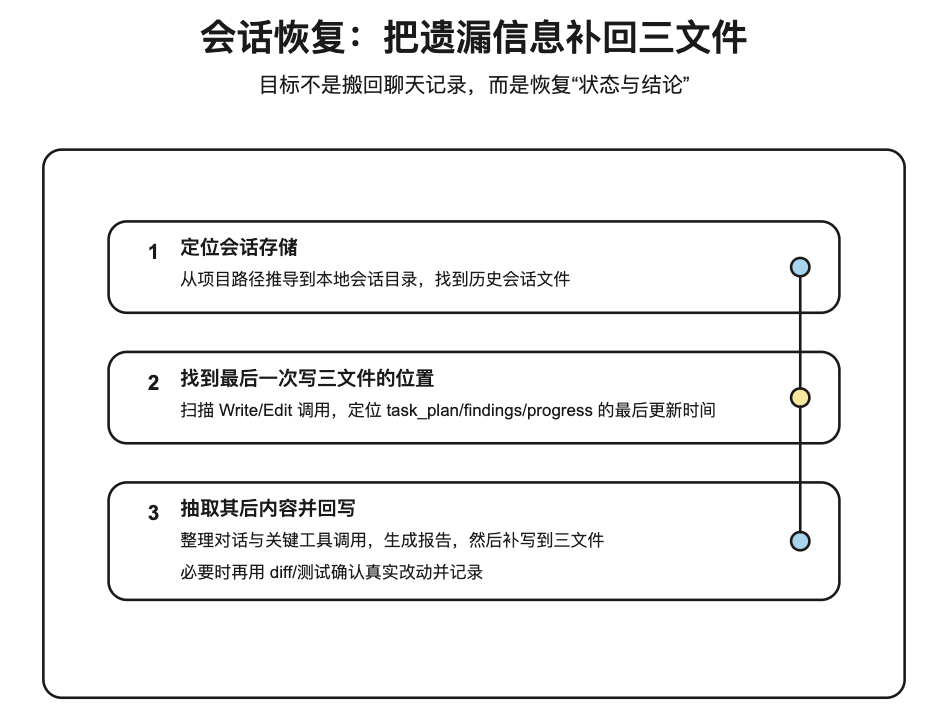
session-catchup.py 的机制(来自仓库脚本 scripts/session-catchup.py)可以概括成三步:
- 定位会话存储:它会把“项目路径”转成 Claude 本地的项目目录名,然后去
~/.claude/projects/<sanitized-project>/下面找历史会话文件(*.jsonl)。 - 找“最后一次写三文件”的位置:它会在历史会话里扫描
Write/Edit工具调用,如果写入路径以task_plan.md/findings.md/progress.md结尾,就认为这是一次 planning files 更新,并记录最后一次更新发生在哪一行。 - 抽取那之后的对话与工具调用:从“最后一次更新”之后开始,把用户消息、助手消息、以及关键工具调用(例如
Write/Edit/Bash)整理成一份 catchup 报告。
新手怎么用这个机制(最稳的操作顺序):
- 先读一遍当前项目里的
task_plan.md/findings.md/progress.md,确认三文件现在的状态。 - 跑
session-catchup.py看报告,把“报告里出现但三文件里没有”的信息补进去。 - 如果你在做代码任务,再跑一次
git diff --stat(或同等方式)确认有哪些真实改动,然后把关键变更也写进progress.md。
记住一句话:恢复不是为了把聊天记录搬回来,而是为了把“状态与结论”补回三文件,让它们继续做单一真理来源。
2.4. 边界条件与取舍:什么时候别用
这套流程不是“越严格越好”。更适合把它当成一种“工程化的写作/开发/研究模板”,在这些情况下跳过:
| 不建议用 | 原因 | 替代 |
|---|---|---|
| 一句话问答/单文件小改 | 创建三文件的成本高于收益 | 直接问/直接改 |
| 你不打算落盘任何过程 | 那它就失去意义 | 至少写 task_plan.md |
| 团队不需要可追溯过程 | 复盘成本无处回收 | 只保留关键 decisions |
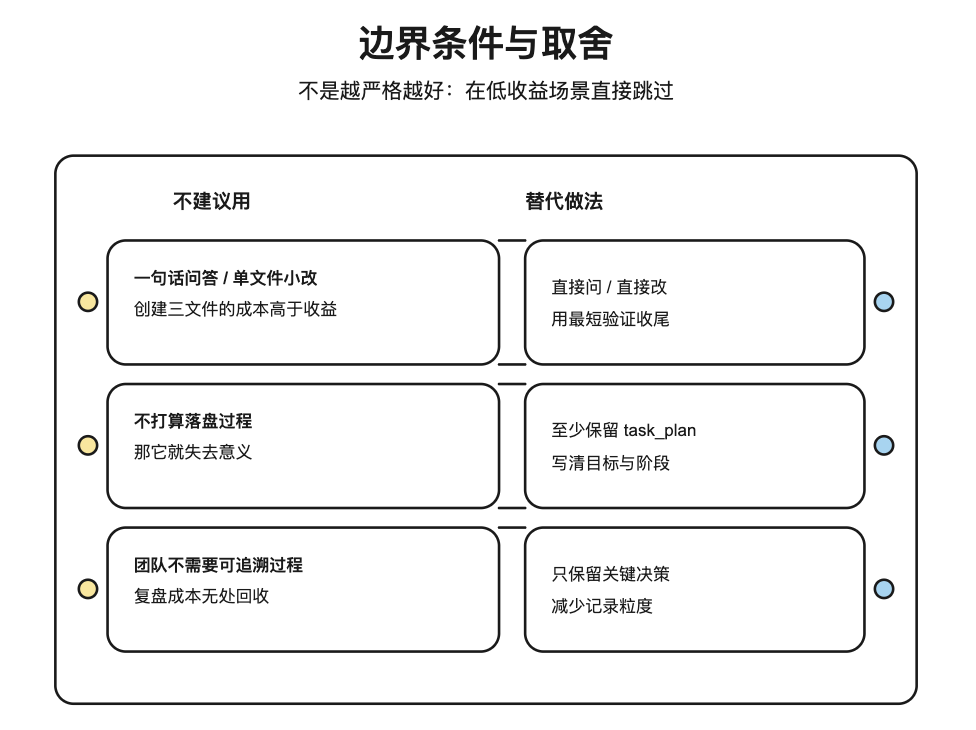
反过来,只要你预计会超过 5 次工具调用,或者任务要跨多个会话,它通常就很值。
2.5. examples/README.md 里的真实演示:三文件如何“一起长大”
仓库的 examples/README.md 给了一个很完整的端到端 walkthrough(以“做一个 Python CLI Todo App”为例),它最大的价值不是那个 Todo App,而是让你看到:
task_plan.md怎么从“Phase 1”推进到“Phase 5”findings.md怎么沉淀需求/研究/决策progress.md怎么记录行动与错误,并在卡住时快速恢复
下面摘取几段关键片段(省略无关行),你会更直观。
2.5.1. 一开始:task_plan.md 先把阶段状态机立起来
## Current Phase
Phase 1
### Phase 1: Requirements & Discovery
- [ ] Understand user intent
- [ ] Document findings in findings.md
- **Status:** in_progress
### Phase 2: Planning & Structure
- **Status:** pending
解读:它就是一个可读的状态机。后面所有自动化(提示、校验、复盘)都围绕它转。

2.5.2. 做完调研:findings.md 把“为什么这么选”固定下来
## Research Findings
- Python's `argparse` module is perfect for CLI subcommands
- `json` module handles file persistence easily
## Technical Decisions
| Use JSON for storage | Simple, human-readable, built-in Python support |
| argparse with subcommands | Clean CLI: `python todo.py add "task"` |
解读:如果你只在聊天里说“用 argparse + JSON”,下一轮很可能就忘了为什么;写在这里,后面任何人(包括 AI)都能复盘这次选择。
2.5.3. 遇到错误:为什么必须把 error 写进 plan 和 progress
示例里故意演示了两类常见错误:FileNotFoundError、JSONDecodeError。它的记录方式是“双写入”:
- 在
task_plan.md的Errors Encountered里记录“错误/尝试次数/解决方案”(避免重复踩坑) - 在
progress.md的Error Log里记录“时间戳/错误/解决方案”(便于追溯发生顺序)
解读:同一个错误写两处并不重复,它分别服务于“避免复现”和“追溯过程”。
2.6. skills/planning-with-files/examples.md:最小循环(Loop)长什么样,为什么有效
除了 examples/README.md 的长篇 walkthrough,项目在 skills/planning-with-files/examples.md 里还给了更抽象的“循环模板”,挺适合你在不同任务间复用。
它把一次任务拆成多个 loop,每个 loop 只做几件事,典型结构类似:
Loop N:
1) Read task_plan.md # 把目标/当前阶段塞回注意力窗口
2) 做一件事(搜索/读文件/写实现/写总结)
3) Write/Edit files # 把新发现/新状态写回文件系统
在 examples.md 的“Research Task”示例里,它甚至用“命令序列”把节奏写死了(节选):
Read task_plan.md
WebSearch "morning exercise benefits"
Write notes.md
Edit task_plan.md
给新手的解读:
- 这里的
Read/Write/Edit/WebSearch不是某种神秘语法,它就是在说“读计划/查资料/写笔记/更新状态”。 notes.md在这个示例里扮演的是“发现与资料库”的角色,和我们文章里一直用的findings.md本质等价。- 最关键的不是你用哪个文件名,而是保持职责稳定:计划(plan)负责阶段状态机,发现(notes/findings)负责证据与结论,过程(progress)负责可追溯日志。
如果你照着仓库示例走,看到 notes.md 不要慌:把它当作“findings 的别名”就行。命名可以不同,但职责最好别混。
我会直接抄走的一点,是它对“失败恢复”的强调(节选):
Action: Read config.json
Error: File not found
# Update task_plan.md:
## Errors Encountered
- config.json not found → Will create default config
解读:失败不只是“需要修复的 bug”,它还是给 agent 的关键信号。你把失败写进文件,就等于把“新的世界模型”写进了可持久化记忆里。
3. SKILL.md 重要性
很多人看到这个项目会以为它只是“提供了 3 个模板文件”。但真正起作用的是 SKILL.md 里的行为约束:它把“先计划、再执行、再验证”的流程,通过 hooks 和脚本变成可重复、可校验的机制。
下面用仓库里的真实内容来拆解(仓库相对路径:skills/planning-with-files/SKILL.md)。
3.1. Frontmatter:这个 skill 先声明了什么能力边界
原版 SKILL.md 的头部包含这些关键信息(节选):
---
name: planning-with-files
version: "2.10.0"
description: Implements Manus-style file-based planning for complex tasks. Creates task_plan.md, findings.md, and progress.md. Use when starting complex multi-step tasks, research projects, or any task requiring >5 tool calls. Now with automatic session recovery after /clear.
user-invocable: true
allowed-tools:
- Read
- Write
- Edit
- Bash
- Glob
- Grep
- WebFetch
- WebSearch
hooks:
...
---
3.1.1. 为什么是 YAML格式:它解决的是“机器可读的配置”
这段 YAML 不是为了好看,它是所谓的 frontmatter(头部元数据):用一段结构化配置告诉“skill 运行时”这份文件的身份、能力边界和触发机制。
YAML 在这里的优点主要有三点:
- 人读起来直观:缩进 + 列表就能表达层级,比 JSON 更适合手写和审阅。
- 机器解析稳定:运行时可以明确读出
name/description/allowed-tools/hooks等字段,用于路由与执行。 - 配置与正文分离:正文部分可以专注写“行为与流程”,配置部分专注写“元信息”。
可以这么理解:YAML 是“skill 的说明书封面(元数据)”,下面的 Markdown 才是“正文(怎么做)”。
3.1.2. allowed-tools 这些动作是什么?如何识别?
这里的 Read/Write/Edit/Bash/Glob/Grep/WebFetch/WebSearch 不是随便写的词,它们对应的是 agent 环境里可用的“工具名”。
- 它们是什么动作:例如
Read代表读文件,Edit/Write代表写入/修改文件,Grep/Glob代表在项目内检索定位,Bash代表执行命令。 - 动作背后发生什么:skill 运行时会按“工具调用”来执行;
allowed-tools充当白名单,限制这份 skill 只能做这些类型的操作。 - 如何识别这些动作:当你在 IDE/CLI 里触发一个工具调用(例如执行一次文件读取、一次检索、一次命令),运行时会知道“当前调用的工具名是什么”,据此判断是否允许执行,以及是否触发 hooks。
解读
user-invocable: true:意味着你可以手动触发它,而不是只能“被动命中”。这对流程型 skill 很关键。allowed-tools:它把可用工具显式列出来,就是在做“能力白名单”。文件规划这类 workflow,需要读/写文件 + 搜索定位,所以Glob/Grep和Read/Write/Edit基本少不了。description的触发条件写得很具体:>5 tool calls。这不是玄学,它是在避免把复杂流程用在简单任务上。
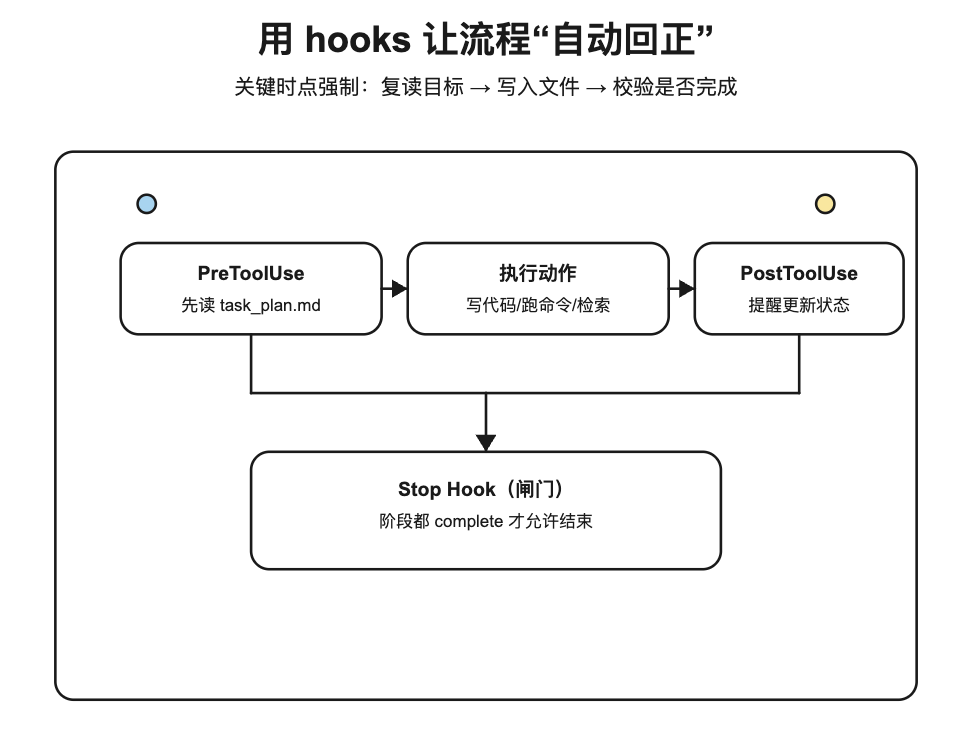
3.2. PreToolUse:每次重要动作前,先把目标塞回注意力窗口
原版配置(节选):
PreToolUse:
- matcher: "Write|Edit|Bash|Read|Glob|Grep"
hooks:
- type: command
command: "cat task_plan.md 2>/dev/null | head -30 || true"
3.2.1. 这种 YAML 配置怎么“生效”:matcher + hook 的运行逻辑
把 hooks 当成“生命周期回调”就行:在某些事件发生时自动跑一段动作。
- 什么是 hooks:在
PreToolUse/PostToolUse/Stop这些时机触发的自动化动作。 - matcher 是什么:一个匹配规则(这里看起来像正则),用来判断“当前发生的工具调用是不是我关心的那类动作”。
- 如何触发:当你准备执行一次工具调用,比如
Read或Edit,运行时先检查是否有PreToolUsehook 的 matcher 命中;命中了,就先执行command。
这段配置的效果就是:每次你要做关键动作(写/改/跑命令/读/检索)之前,先把 task_plan.md 的前 30 行输出出来,强行把 Goal/当前阶段塞回注意力窗口。
解读
matcher覆盖了“会改变状态/会推动任务”的关键动作:写文件、改文件、跑命令、读文件、搜索定位。- hook 做的事很简单:每次先输出
task_plan.md前 30 行。 - 这里的关键不是 30 行这个数字,而是“只读前面最关键的 Goal/Current Phase/前几个 phase”。它通过强制回显,减少目标漂移。
普通用户怎么用这个思路:哪怕不用 hooks,也可以把它变成手动规则——“准备大改之前先读一遍 task_plan 的 Goal”。
3.3. PostToolUse:写完文件就提醒你更新阶段状态
原版配置(节选):
PostToolUse:
- matcher: "Write|Edit"
hooks:
- type: command
command: "echo '[planning-with-files] File updated. If this completes a phase, update task_plan.md status.'"
解读
- 这不是“无意义的提示”,它是在对抗两个常见问题:
- 你写完了东西,但忘了把 phase 从
in_progress改成complete; - 你以为自己会记得更新,结果下一轮又忘。
- 你写完了东西,但忘了把 phase 从
- 这个 hook 不强制你更新,但把“提醒”变成每次写入后的默认行为。
普通用户怎么借鉴:如果你不用 Claude Code,也可以在自己的流程里加一个“写完就更新状态”的固定动作(比如写完 PRD 就在 task_plan 打个勾)。
3.4. Stop Hook:用脚本把“是否完成”变成可计算的闸门
原版 Stop hook 会调用 check-complete 脚本(节选 + 解释):
- 它会根据 OS 判断是 Windows 还是类 Unix,然后选择
check-complete.ps1或check-complete.sh。 - 在 Linux/macOS 下,本质执行的是:
sh "$SCRIPT_DIR/check-complete.sh"。
而 check-complete.sh 的核心逻辑很直接(仓库相对路径:scripts/check-complete.sh):
TOTAL=$(grep -c "### Phase" "$PLAN_FILE" || true)
COMPLETE=$(grep -cF "**Status:** complete" "$PLAN_FILE" || true)
if [ "$COMPLETE" -eq "$TOTAL" ] && [ "$TOTAL" -gt 0 ]; then
exit 0
else
exit 1
fi
解读
- 这一步是在对抗“80% 完成就宣布结束”。只要 phase 没全部
complete,就判定未完成。 - 它把“完成”从主观感受,变成了可验证规则。
- 对普通用户最有价值的启发:你也可以给任何交付设一个“硬闸门”,比如写文章必须满足:表格 + Mermaid + 代码块 + 参考文献齐全,才允许发布。
3.5. Session Recovery:/clear 后它怎么把“丢失上下文”捞回来
这个项目在 SKILL.md 里专门写了“先检查上一会话”的流程,并提供脚本:
scripts/session-catchup.py:生成 catchup 报告- 建议流程:先看
git diff --stat,再读 planning files,再把 catchup 要点同步回三个文件
解读
- 它承认“上下文一定会丢”,所以把恢复流程工程化:用脚本告诉你“丢了什么”。
- 这背后其实是一个更通用的思路:把重要状态写到可恢复介质里(文件/数据库),把聊天上下文当缓存。
4. 下一步:10 分钟上手
如果你只想最小成本体验一次这套 workflow,不要从“大项目”开始。挑一个 10–30 分钟能结束的小任务(写一段说明文、修一个小 bug、做一次调研)。
- 安装并触发
/plan(或/planning-with-files:start) - 在项目根目录生成三文件:
task_plan.md/findings.md/progress.md - 在
task_plan.md写一句话 Goal,并拆 3 个 phase(理解/执行/验证) - 做两次阅读/搜索后,立刻把要点写进
findings.md(2-Action Rule) - 每做完一个 phase:更新
task_plan.md状态 + 在progress.md记录你做了什么 - 收尾时跑
check-complete.sh(或让 Stop hook 自动检查),直到 phases 全部 complete
你会得到的不是“又一个模板”,而是一个可复用的习惯:以后任何复杂任务,你都能在三文件里 30 秒恢复状态并继续推进。
5. 自检清单
- 标题是否为
# 1.、## 1.1.、### 1.1.1.这种编号层级? - 是否有 1 张表格 + 1 段 Mermaid + 1 个代码块?
- 是否解释了 3 文件分别写什么、什么时候写?
- 是否写了边界条件/取舍?
- 是否有至少 2 个可核查锚点(版本号、命令、规则、链接)?
- 参考文献是否为
[标题](URL)且集中在文末?
6. 参考文献
- Planning with Files(项目仓库)
- Quick Start Guide
- Workflow Diagram
- planning-with-files SKILL.md
- Reference: Manus Context Engineering Principles
- Examples (skill-level): Planning with Files in Action
- Examples: Planning with Files in Action
- skills.sh: planning-with-files
- Planning-with-Files 完全指南:复刻 Manus(源码七号站)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 14
14 0
0- 0



 已为社区贡献119条内容
已为社区贡献119条内容

所有评论(0)