大模型训练新范式:从RLHF到DPO的简化之路(值得收藏)
本文详细介绍了大模型对齐技术从RLHF到DPO的演进过程。首先解释了RLHF的三阶段训练方法及其使用PPO算法的挑战,包括训练不稳定和成本高。随后,介绍了DPO如何从理论上消除奖励模型和强化学习环节,直接通过二元偏好数据优化模型。文章还提供了DPO的数学推导、代码实现和实际训练案例,以及相关扩展算法,为工程师提供了一种更高效的大模型对齐方法。
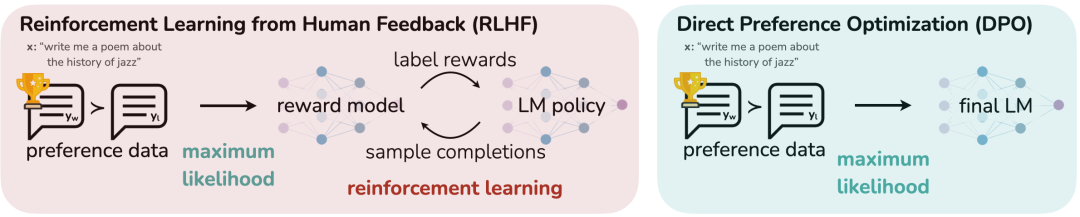
虽然大规模无监督语言模型能够学习广泛的世界知识,并拥有一些推理能力,但由于其训练的完全无监督性质,精确控制其行为是相对来说还是很困难的。而要想去实现这种精准控制,可以使用人类反馈强化学习,其简称为RLHF:是通过收集高质量的人工打标签的数据,并使用无监督微调训练来进行偏好一致对齐。然而强化学习是一个复杂且不稳定的训练过程,其过程表现为:首先我们要先拟合一个反映人类偏好的奖励模型,然后使用强化学习对大规模无监督LM进行微调,以最大化这个估计的奖励,同时又不偏离原始模型太远(RLHF原理),具体第二张下图所示,展示了RLHF的训练步骤 或者说是阶段吧。
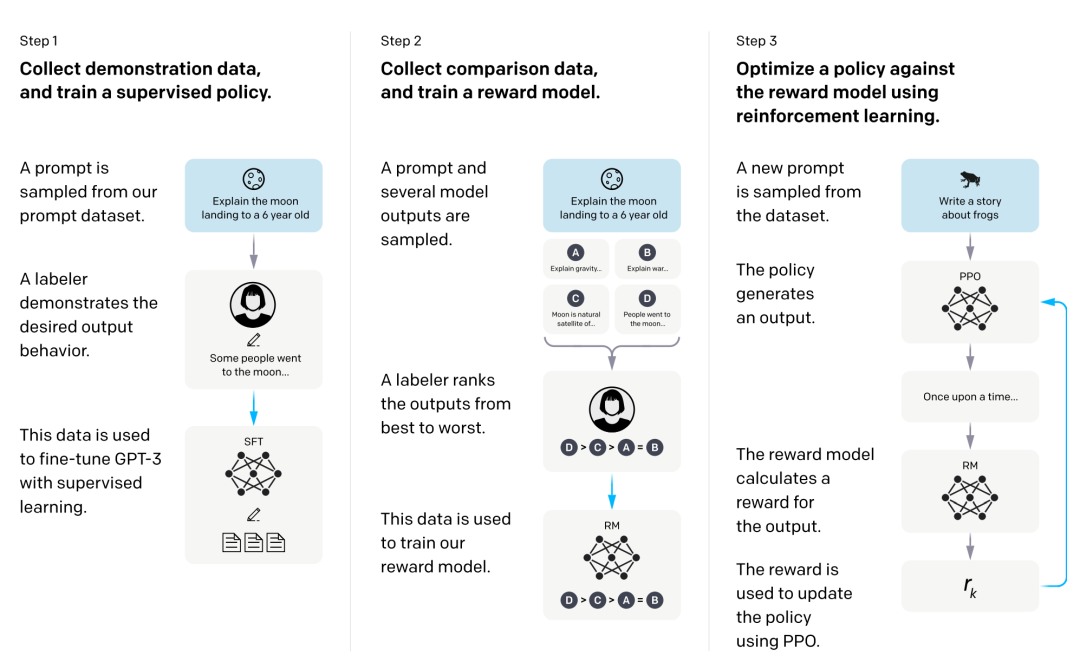
既然有了PPO,为啥还要有DPO呢?(既生瑜何生亮)可以看下图,答案不着急,后面也会讲解PPO以及其劣势,从而引出DPO的存在。
强化学习(RLHF)
openai在InstructGPT的技术报告指出:ChatGPT使用RLHF的 "三步走"策略,即:监督微调(SFT)、偏好采样和奖励学习(RM)、强化学习(PPO),对应了上图中三个训练阶段,现在我们来对这三个简单讲解下。
监督微调(SFT): 首先在下游感兴趣的任务使用高质量数据(对话、摘要等)和监督学习对预训练的 LM 进行微调,以获得一个模型(sft模型) 。
偏好采样和奖励学习(RM): 使用提示词方法,来生成偏好数据对(注意:第一阶段微调后的sft模型),那什么是偏好数据对呢?可以看这个数据示例。对数据格式感兴趣可以看我这篇:揭秘大模型训练数据的真实面貌:这篇文章值得一看
{
"conversations": [
{
"from": "human", #人类指令
"value": "老虎会吃哪一个,草还是树叶?"
}
],
"chosen": {
"from": "gpt", #优质回答
"value": "我很高兴能帮助你解答问题!不过,我必须指出,这个问题本身可能没有意义。老虎是食肉动物,通常不吃草或树叶。它们的饮食主要包括大型有蹄动物、小型哺乳动物和鸟类。\n\n如果你提出这个问题是出于好奇或有特定原因,我很乐意帮助你找到更多关于老虎饮食习惯的信息,或者建议资源让你更多了解这些壮丽的生物。请告诉我如何进一步协助你!"
},
"rejected": {
"from": "gpt", # 劣质回答
"value": "一只老虎是食肉动物,这意味着它的饮食主要是肉类。老虎主要猎捕和吃其他动物,如鹿和野猪。它们不会选择吃草或树叶,因为这些不是它们自然饮食的一部分。"
}
}
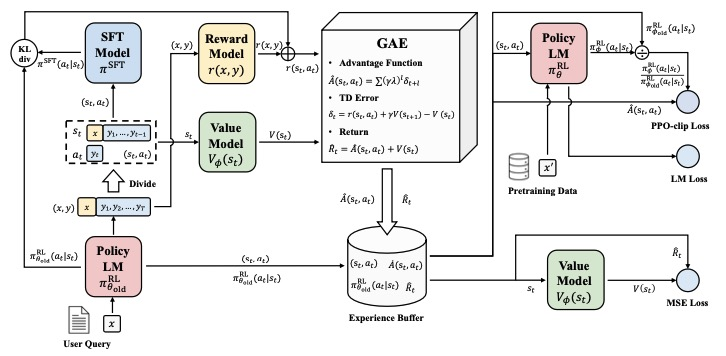
强化学习(PPO):RLHF训练过程主要有四个模型参与,分别是Actor Model 、Reference Model、Reward Model、Critic Model,他们在整个过程的角色如下:
Actor Model(动作模型):需要优化的语言模型,负责生成实际的文本回答,参数会在训练过程中不断更新。
Reference Model(参考模型):Actor Model 的初始副本,参数固定不变,用于计算 KL 散度,防止 Actor 与初始模型偏离太远。
Reward Model(奖励模型):经过人类偏好训练的评分模型,为 Actor 生成的文本提供奖励信号,指导 Actor 向更好的方向优化。
Critic Model(评论模型):估计价值函数,预测动作的长期收益,帮助 PPO 算法更好地优化 Actor。
四个模型之前具体的协作,这里就不做详细介绍,毕竟写的是DPO详解啊。
都知道PPO很好,为啥还要出来DPO呢?这是因为很多工程人员发现PPO很难训练,总结具体如下:
(1)奖励模型RM的准确率较低,在现有的偏好数据上只能训到70%~80%。这一方面是因为人类偏好较难拟合,另一方面是因为奖励模型一般较小,过大的奖励模型会引起PPO阶段训练的崩溃;
(2)PPO训练不稳定,相同的参数和数据也有可能出现不一样的结果;
(3)PPO阶段训练成本大。这是因为策略模型的更新依赖于奖励模型的显式反馈,所以每个训练step耗时长、GPU消耗大。
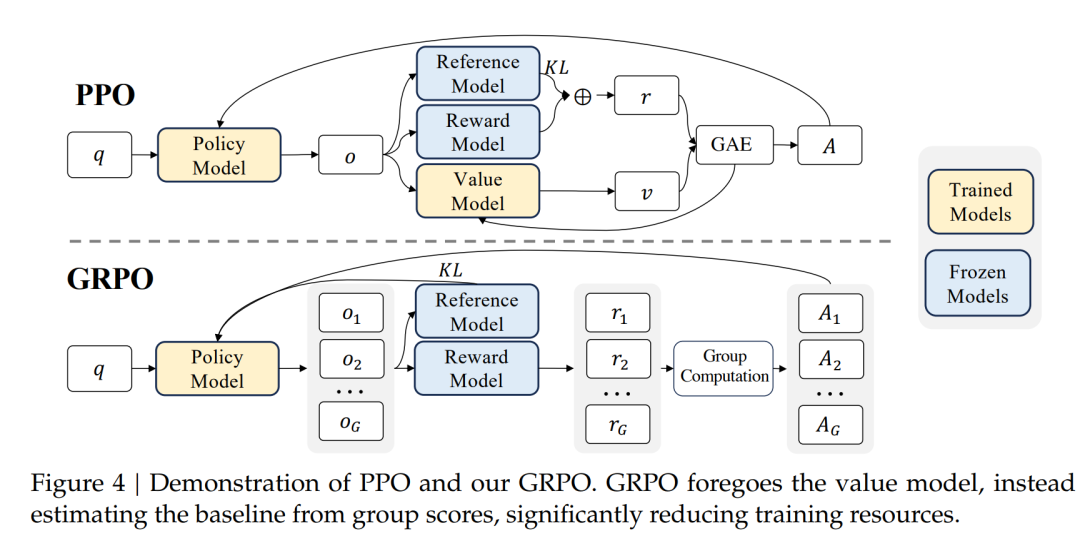
说白了就是PPO很难训练,并且消耗很大,看看上面的图就知道,四个模型都要参与,这谁顶得住啊?
正因为这些原因,斯坦福大学研究者提出了DPO,从理论上消除了奖励模型RM和与之相关的RL环节,直接采用二元偏好数据对LLMs进行参数更新。
DPO理论理解
之前我们说使用sft模型来生成偏好数据对,然后RM模型来进行评分并给出对应的奖励,让actor model来自适应调整。而DPO就是从理论来消除RM模型的存在,咱们就从Bradley-Terry模型开始(因为论文也是从这个模型开始的,哈哈),BT模型规定了人类偏好分布可以表示为:
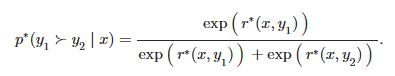
看着是不是好像也挺简单的,其实这个式子还可以简化。针对静态数据集D,上面的奖励模型通过对数极大似然估计可以表示为:
数据集:
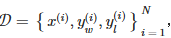
对数似然估计损失表示:
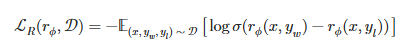
是的,通用损失函数数学表达式其实已经出来了,但是DPO其实是PPO的一个简化版,所以需要从PPO的损失来简化(DPO其实就是PPO的钙化版、或者说是简化版),直到推导出DPO的损失函数表达式
所以针对用于PPO的损失,上式可以优化为:
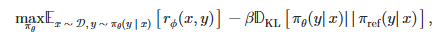
针对PPO而言,KL散度很重要,这是为啥?因为KL散度就表示Reference Model(参考模型) 和自己训练的Actor Model 有没有跑偏。大白话就是:这个训练就是让actor model训练,但是我也要拽着你,不然你偏离 reference model太远,如果太远,就训飞了。
因此针对KL散度优化,上面的式子可以进行推导为:
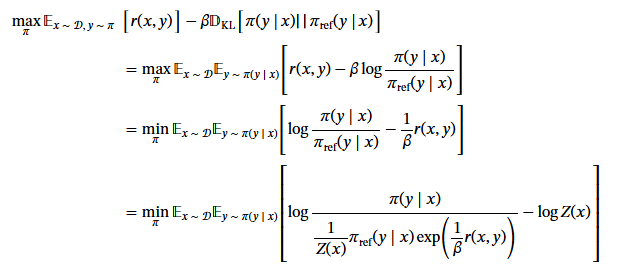
进一步简化:
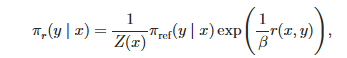
其中Z(x)表示为:
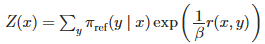
然后经过一顿数学操作和优化:
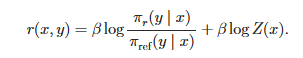
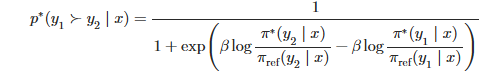
得到了最后的loss:
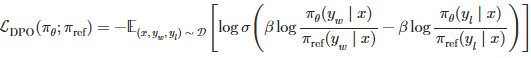
其中 ,πθ 是正在训练的模型 ;πref 是参考模型(通常是 SFT 模型);yw 是首选(获胜)的答案;yl 是被拒绝(输掉)的反应;β 是控制优化强度的温度参数;σ 是 sigmoid函数。
一开始看这些式子是不是挺容易的,但是后面的数学变换和优化操作下来,看懵了,但是不要紧,你就记住最后这个式子就行,因为DPO的损失优化就是通过这个式子来的。
DPO代码片段
损失函数代码:
def preference_loss(policy_chosen_logps: torch.FloatTensor,
policy_rejected_logps: torch.FloatTensor,
reference_chosen_logps: torch.FloatTensor,
reference_rejected_logps: torch.FloatTensor,
beta: float,
label_smoothing: float = 0.0,
ipo: bool = False,
reference_free: bool = False) -> Tuple[torch.FloatTensor, torch.FloatTensor, torch.FloatTensor]:
"""Compute the DPO loss for a batch of policy and reference model log probabilities.
Args:
policy_chosen_logps: Log probabilities of the policy model for the chosen responses. Shape: (batch_size,)
policy_rejected_logps: Log probabilities of the policy model for the rejected responses. Shape: (batch_size,)
reference_chosen_logps: Log probabilities of the reference model for the chosen responses. Shape: (batch_size,)
reference_rejected_logps: Log probabilities of the reference model for the rejected responses. Shape: (batch_size,)
beta: Temperature parameter for the DPO loss, typically something in the range of 0.1 to 0.5. We ignore the reference model as beta -> 0.
label_smoothing: conservativeness for DPO loss, which assumes that preferences are noisy (flipped with probability label_smoothing)
ipo: If True, use the IPO loss instead of the DPO loss.
reference_free: If True, we ignore the _provided_ reference model and implicitly use a reference model that assigns equal probability to all responses.
Returns:
A tuple of three tensors: (losses, chosen_rewards, rejected_rewards).
The losses tensor contains the DPO loss for each example in the batch.
The chosen_rewards and rejected_rewards tensors contain the rewards for the chosen and rejected responses, respectively.
"""
pi_logratios = policy_chosen_logps - policy_rejected_logps
ref_logratios = reference_chosen_logps - reference_rejected_logps
if reference_free:
ref_logratios = 0
logits = pi_logratios - ref_logratios # also known as h_{\pi_\theta}^{y_w,y_l}
if ipo:
losses = (logits - 1/(2 * beta)) ** 2 # Eq. 17 of https://arxiv.org/pdf/2310.12036v2.pdf
else:
# Eq. 3 https://ericmitchell.ai/cdpo.pdf; label_smoothing=0 gives original DPO (Eq. 7 of https://arxiv.org/pdf/2305.18290.pdf)
losses = -F.logsigmoid(beta * logits) * (1 - label_smoothing) - F.logsigmoid(-beta * logits) * label_smoothing
chosen_rewards = beta * (policy_chosen_logps - reference_chosen_logps).detach()
rejected_rewards = beta * (policy_rejected_logps - reference_rejected_logps).detach()
return losses, chosen_rewards, rejected_rewards
可以看看第26、27、32、35行,这几行都是DPO核心,也完全按照这篇DPO论文来实现的。为了方便整合在一起看就是:
losses = (((policy_chosen_logps - policy_rejected_logps) - (reference_chosen_logps - reference_rejected_logps)) - 1/(2 * beta)) ** 2
DPO训练案例
下列代码使用了TRL库来进行微调训练,方式也比较简单,目的就是打造人人可学大模型,哈哈。
from trl import DPOConfig, DPOTrainer
from transformers import AutoModelForCausalLM, AutoTokenizer
from datasets import load_dataset
# 加载 model and tokenizer
model = AutoModelForCausalLM.from_pretrained("HuggingFaceTB/SmolLM3-3B")
tokenizer = AutoTokenizer.from_pretrained("HuggingFaceTB/SmolLM3-3B")
# 配置 DPO training
training_args = DPOConfig(
beta=0.1, # Temperature parameter
learning_rate=5e-7, # Lower LR for stability
max_prompt_length=512, # Maximum prompt length
max_length=1024, # Maximum total length
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
num_train_epochs=1,
)
# 加载数据集
preference_dataset = load_dataset("argilla/ultrafeedback-binarized", split="train_prefs")
# 初始化DPO
trainer = DPOTrainer(
model=model,
args=training_args,
train_dataset=preference_dataset,
processing_class=tokenizer,
)
# 训练
trainer.train()
这一套是完全可以使用的,如果你有自己的数据集,只需要将数据集改成自己的数据集即可。
当然DPO现在也有很多扩展算法,这些算法都是去优化或改进loss目标函数:
IPO (Identity Preference Optimization)
KTO:Kahneman-Tversky Optimization
RSO:Rejection Sampling Optimization
SamPO:Down-Sampled DPO
参考:
https://github.com/eric-mitchell/direct-preference-optimization/blob/main/trainers.py
https://huggingfae.co/learn/smol-course/unit2/2
https://arxiv.org/html/2305.18290v3#A2
https://zhuanlan.zhihu.com/p/642569664
https://huggingface.co/blog/Junrulu/dpo-and-variants
最后唠两句
为什么AI大模型成为越来越多程序员转行就业、升职加薪的首选
很简单,这些岗位缺人且高薪
智联招聘的最新数据给出了最直观的印证:2025年2月,AI领域求职人数同比增幅突破200% ,远超其他行业平均水平;整个人工智能行业的求职增速达到33.4%,位居各行业榜首,其中人工智能工程师岗位的求职热度更是飙升69.6%。
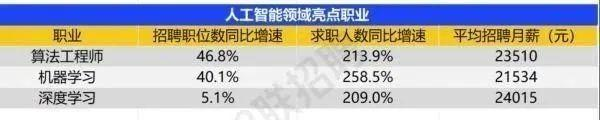
AI产业的快速扩张,也让人才供需矛盾愈发突出。麦肯锡报告明确预测,到2030年中国AI专业人才需求将达600万人,人才缺口可能高达400万人,这一缺口不仅存在于核心技术领域,更蔓延至产业应用的各个环节。
那0基础普通人如何学习大模型 ?
深耕科技一线十二载,亲历技术浪潮变迁。我见证那些率先拥抱AI的同行,如何建立起效率与薪资的代际优势。如今,我将积累的大模型面试真题、独家资料、技术报告与实战路线系统整理,分享于此,为你扫清学习困惑,共赴AI时代新程。
我整理出这套 AI 大模型突围资料包【允许白嫖】:
-
✅从入门到精通的全套视频教程
-
✅AI大模型学习路线图(0基础到项目实战仅需90天)
-
✅大模型书籍与技术文档PDF
-
✅各大厂大模型面试题目详解
-
✅640套AI大模型报告合集
-
✅大模型入门实战训练
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

①从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点

② AI大模型学习路线图(0基础到项目实战仅需90天)
全过程AI大模型学习路线

③学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的

④各大厂大模型面试题目详解

⑤640套AI大模型报告合集

⑥大模型入门实战训练

如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。
👉获取方式:
有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 5
5 0
0- 0



 已为社区贡献507条内容
已为社区贡献507条内容

所有评论(0)