【收藏必备】小白也能学会的AI Agent架构:Python单文件实现六大核心模块
文章详细介绍了如何使用Python构建企业级AI Agent,重点解构了六大核心模块:感知模块(定义状态)、执行系统(定义工具)、专业大模型(加载大脑)、决策引擎(构建思考节点)、记忆管理(工作记忆流转)和反馈优化(闭环构建)。作者通过一个Python文件实现了这六大模块,展示了AI Agent本质上是一个被大模型驱动的while循环状态机,适合初级程序员学习和实践。
Agent 的本质是一个状态机(State Machine)。它不是一个有意识的生物,而是一个被大模型驱动的 while 循环。
今天,我将带你从 0 到 1,在一个 Python 文件中,把这六大模块全部通过代码落地。
这事不难。只要你会写 Python 函数,你就能构建 Agent。
PART 01
工程准备:技术栈
为了实现确定性工程,我们不使用低代码平台,而是使用代码。
LangGraph: 用于构建状态图(Graph)。
LangChain: 用于封装模型接口。
Python: 我们的逻辑载体。
你只需要这一个文件,就能跑通所有逻辑。
你需要先安装库:
pip install langchain-openai langgraph pydantic python-dotenv
PART 02
感知模块 (Perception):定义状态
理论回顾:感知是 Agent 的“感官”,负责处理文本、信号和上下文。
工程实现:在代码中,感知被具象化为 State(状态)。
Agent 本质上是无状态的,我们需要定义一个数据结构来“感知”当前聊到哪了。
解析 :这就是感知。只要在这个列表里的,Agent 就能“看见”;不在列表里的,对它来说就不存在。
from typing import TypedDict, Annotated, List
from langgraph.graph.message import add_messages
# [感知模块]
# 我们定义一个字典,作为 Agent 的"眼睛"和"耳朵"
# 所有的用户输入、工具返回结果,都会被 append 到这个 messages 列表中
class AgentState(TypedDict):
messages: Annotated[List, add_messages]
PART 03
执行系统 (Execution):定义工具
理论回顾 :执行系统是 Agent 的“手脚”,负责调用 API、查询数据库。
工程实现 :在代码中,就是标准的 Python 函数 。
不要让模型去猜,我们要明确定义函数。
# [执行系统]
# 这是 Agent 的"手",我们定义两个具体能力
def search(query: str) -> str:
"""当需要获取实时信息时调用,比如天气、新闻。"""
print(f" [执行动作] 正在搜索: {query}")
return f"搜索结果:'{query}' 的天气是 晴转多云,气温 20度。"
def add(a: int, b: int) -> int:
"""当需要计算数字时调用。"""
print(f" [执行动作] 正在计算: {a} + {b}")
return a + b
# 把工具打包成列表,后续喂给大脑
tools = [search, add]
PART 04
专业大模型 (LLM):加载大脑
理论回顾:这是底座,决定了 Agent 的智商上限。
工程实现:初始化 LLM 对象,并进行 Tool Binding(工具绑定)。
from langchain_openai import ChatOpenAI
# [专业大模型]
# 初始化大脑 (建议使用 GPT-4o 或类似智力水平的模型)
llm = ChatOpenAI(model="gpt-4o", temperature=0)
# [关键一步]
# 将"执行系统"(tools)绑定到"大脑"(llm)上
# 这一步,我们将概率性的文本生成,坍缩为确定性的函数调用请求
llm_with_tools = llm.bind_tools(tools)
PART 05
决策引擎 (Decision):构建思考节点
理论回顾:这是核心。Agent 需要通过思维链(CoT)规划下一步该干什么。
工程实现:编写一个 Node(节点) 函数。
# [决策引擎]
# 这是 Agent 的思考过程
def agent_node(state: AgentState):
messages = state["messages"]
# 大脑接收感知到的信息,进行推理
# 结果可能是:1. "我要调用工具" 2. "我回答完毕"
response = llm_with_tools.invoke(messages)
return {"messages": [response]}
PART 06
记忆管理 (Memory):工作记忆流转
理论回顾:Agent 需要记住刚才做过什么。
工程实现:LangGraph 的 Graph(图) 结构本身就是记忆流转的载体。
我们需要定义一个路由(Router),来决定记忆如何流转。
from langgraph.graph import END
# [决策路由]
# 判断下一步去哪:是去"执行",还是"结束"?
def should_continue(state: AgentState):
last_message = state["messages"][-1]
# 如果大脑决定调用工具,转入执行系统
if last_message.tool_calls:
return "tools"
# 否则,结束
return END
PART 07
反馈优化 (Feedback):闭环构建
理论回顾:Agent 需要根据执行结果进行自我修正。
工程实现:通过 Edge(边) 构建循环。
这是 Agent 区别于脚本的关键:它是一个闭环。
from langgraph.graph import StateGraph
from langgraph.prebuilt import ToolNode
# 1. 初始化图
workflow = StateGraph(AgentState)
# 2. 添加节点
workflow.add_node("agent", agent_node) # 思考节点
workflow.add_node("tools", ToolNode(tools)) # 执行节点 (LangGraph自带)
# 3. 设置入口
workflow.set_entry_point("agent")
# 4. [反馈闭环]
# 思考 -> 决定调用工具 -> 执行工具 -> 【跳回】思考
# 这一步 add_edge("tools", "agent") 就是反馈机制的核心
# Agent 会看到工具的执行结果,然后反思下一步该说什么
workflow.add_edge("tools", "agent")
# 5. 条件分支
workflow.add_conditional_edges(
"agent",
should_continue,
{
"tools": "tools",
END: END
}
)
# 6. 编译系统
app = workflow.compile()
PART 08
全貌:完整代码(Copy & Run)
把上面拆解的碎片拼起来,就是一个完整的、具备六大核心能力的 Agent。
保存为 agent demo.py,配置好你的 OPENAI API_KEY,直接运行。
import os
from typing import TypedDict, Annotated, List
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from langgraph.graph import StateGraph, END
from langgraph.graph.message import add_messages
from langgraph.prebuilt import ToolNode
# 加载环境变量
load_dotenv()
# ==========================================
# 模块1: 感知 (State)
# ==========================================
class AgentState(TypedDict):
messages: Annotated[List, add_messages]
# ==========================================
# 模块2: 执行系统 (Tools)
# ==========================================
def search(query: str) -> str:
"""模拟搜索工具"""
print(f" [执行系统] 调用搜索: {query}")
return f"搜索结果:'{query}' 的天气是 晴转多云,气温 20度。"
def add(a: int, b: int) -> int:
"""模拟计算工具"""
print(f" [执行系统] 调用计算: {a} + {b}")
return a + b
tools = [search, add]
# ==========================================
# 模块3: 专业大模型 (Brain)
# ==========================================
llm = ChatOpenAI(model="gpt-4o", temperature=0)
llm_with_tools = llm.bind_tools(tools)
# ==========================================
# 模块4: 决策引擎 (Node)
# ==========================================
def agent_node(state: AgentState):
return {"messages": [llm_with_tools.invoke(state["messages"])]}
tool_node = ToolNode(tools)
# ==========================================
# 模块5: 记忆流转 (Router)
# ==========================================
def should_continue(state: AgentState):
if state["messages"][-1].tool_calls:
return "tools"
return END
# ==========================================
# 模块6: 反馈闭环 (Graph)
# ==========================================
workflow = StateGraph(AgentState)
workflow.add_node("agent", agent_node)
workflow.add_node("tools", tool_node)
workflow.set_entry_point("agent")
workflow.add_conditional_edges("agent", should_continue, {"tools": "tools", END: END})
workflow.add_edge("tools", "agent") # 这里的 Edge 构成了反馈闭环
app = workflow.compile()
# ==========================================
# 运行测试
# ==========================================
if __name__ == "__main__":
print("🤖 System Initialized. Inputing task...")
# 这是一个需要多步推理的任务:先查天气,再根据天气做决定(虽然这里简单,但逻辑一致)
inputs = {"messages": [("user", "北京现在的天气适合去公园做早操吗?")]}
for output in app.stream(inputs):
pass # 这里的 pass 是因为我们在函数里已经 print 了,实际工程中这里处理日志
print("\nFinal Response:")
print(output['agent']['messages'][-1].content)
PART 09
总结:苦涩的教训
如果你是一个初级程序员,看完这段代码,你应该感到释然。
六大模块,听起来很吓人,落地到代码里:
感知 就是一个列表 (List)
决策 就是一次模型调用 (invoke)
执行 就是函数调用 (def)
记忆 就是数据传递 (State)
反馈 就是一个循环边 (Edge)
这事不难。 难的不是写代码,难的是如何设计清晰的工具定义,以及如何控制图的流转逻辑。
进阶:什么时候拆分文件?
当你从“学习者”变成“工程师”时,单文件就不够用了。
一旦你的项目符合以下任一特征,请立即进行 重构(Refactoring),将代码拆分到不同文件中:
-
工具变多了:你有 10+ 个工具,agent.py 里全是函数定义,干扰了看核心逻辑。
-
Prompt 变长了:你需要写很复杂的 System Prompt,字符串占了几百行。
-
团队协作:你的同事负责写工具,你负责写编排。
推荐的工程目录结构(Project Structure):

最后唠两句
为什么AI大模型成为越来越多程序员转行就业、升职加薪的首选
很简单,这些岗位缺人且高薪
智联招聘的最新数据给出了最直观的印证:2025年2月,AI领域求职人数同比增幅突破200% ,远超其他行业平均水平;整个人工智能行业的求职增速达到33.4%,位居各行业榜首,其中人工智能工程师岗位的求职热度更是飙升69.6%。
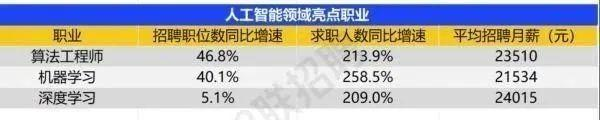
AI产业的快速扩张,也让人才供需矛盾愈发突出。麦肯锡报告明确预测,到2030年中国AI专业人才需求将达600万人,人才缺口可能高达400万人,这一缺口不仅存在于核心技术领域,更蔓延至产业应用的各个环节。
那0基础普通人如何学习大模型 ?
深耕科技一线十二载,亲历技术浪潮变迁。我见证那些率先拥抱AI的同行,如何建立起效率与薪资的代际优势。如今,我将积累的大模型面试真题、独家资料、技术报告与实战路线系统整理,分享于此,为你扫清学习困惑,共赴AI时代新程。
我整理出这套 AI 大模型突围资料包【允许白嫖】:
-
✅从入门到精通的全套视频教程
-
✅AI大模型学习路线图(0基础到项目实战仅需90天)
-
✅大模型书籍与技术文档PDF
-
✅各大厂大模型面试题目详解
-
✅640套AI大模型报告合集
-
✅大模型入门实战训练
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

①从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点

② AI大模型学习路线图(0基础到项目实战仅需90天)
全过程AI大模型学习路线

③学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的

④各大厂大模型面试题目详解

⑤640套AI大模型报告合集

⑥大模型入门实战训练

如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。
👉获取方式:
有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 2
2 0
0- 0



 已为社区贡献507条内容
已为社区贡献507条内容

所有评论(0)