JPEG AI模型学习
JPEG AI是一种基于学习的图像编码新标准,融合变分自编码器技术,在压缩效率和重建质量上超越传统VVC标准。其核心特点包括:1)单码流支持多分辨率解码;2)采用YCbCr色彩空间和多种子采样方案;3)通过多分支解码框架实现设备兼容性;4)创新性地结合主/次分量处理流程,包含分析变换、超先验编解码和多阶段上下文建模。该标准特别优化了CPU部署效率,支持4K图像在190ms内解码,同时具备色域编码、
JPEG AI模型学习
一、简介
JPEG AI是由( Joint Photographic Experts Group,JPEG)一种新兴的基于学习的图像编码标准。
官网:官网
原论文:论文
相关代码:源代码
JPEG AI的范围是创建一个实用的基于学习的图像编码标准,提供单流、紧凑的压缩域表示,同时针对人类可视化和机器消费。JPEG AI融合了各种设计特性,以支持跨不同设备和应用程序的部署。
key words: image compression, variational autoencoder.
**趋势:最近的研究表明,在MS - SSIM [ 15 ]和峰值信噪比( PSNR )指标方面,基于学习的图像压缩在主观和客观上都优于VVC(Versatile Video Coding)**标准,使得基于学习的图像压缩技术成为下一代图像编码标准的有力候选者。
**Jpeg Ai的优势:**JPEG AI标准采用了一些技术特征,即使在计算能力有限的设备上也能实现高效、广泛的实现,并且基于超先验架构的变分自编码器[ 10 ]。最新一版的Jpeg AI 保证了 高保真重建和高压缩效率。
功能用途:JPEG AI的第一个版本支持几个理想的特性,包括宽色域颜色编码、多种颜色表示、缩略图图像编码、低复杂度配置文件、感兴趣区域编码,以及基于瓦片和区域的编码,可以实现空间随机访问。空间随机访问功能是指仅传输、解码和显示整个编码图像的空间子集的能力。
一、设计理念
JPEG AI的设计理念强调在当前和未来的主流设备中广泛采用、互操作性和高效实现。
为了进一步支持高效部署,JPEG AI仅在熵解码流水线的末尾定义一个比特精确的一致性点- -具体是在算术解码阶段之后。
HOP为了高端终端:只有高工作点( HOP )包含更复杂的层,因为它针对的是高端和未来的硬件。
二、Jpeg ai编码设计与结构概述
1.2.1 Input:
JPEG AI通常采用**YCbCr颜色空间**,**采用4:2:0、4:2:2或4:4:4颜色空间子采样,将颜色表示分离为Y、Cb和Cr三个分量**。
Y的样本被组织成三维主分量张量 x Y x_Y xY [ 1 , H , W],而Cb和Cr的样本被组织成二级分量张量 x U v x_Uv xUv ,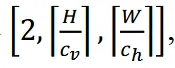 其中cv和ch (分别为编码图片的色度子采样因子,H,W分别为图像的高度和宽度。
其中cv和ch (分别为编码图片的色度子采样因子,H,W分别为图像的高度和宽度。
二、模型结构
整个模型分为Encoder和 Decoder 两部分 输入是png格式图片转换为YUV格式。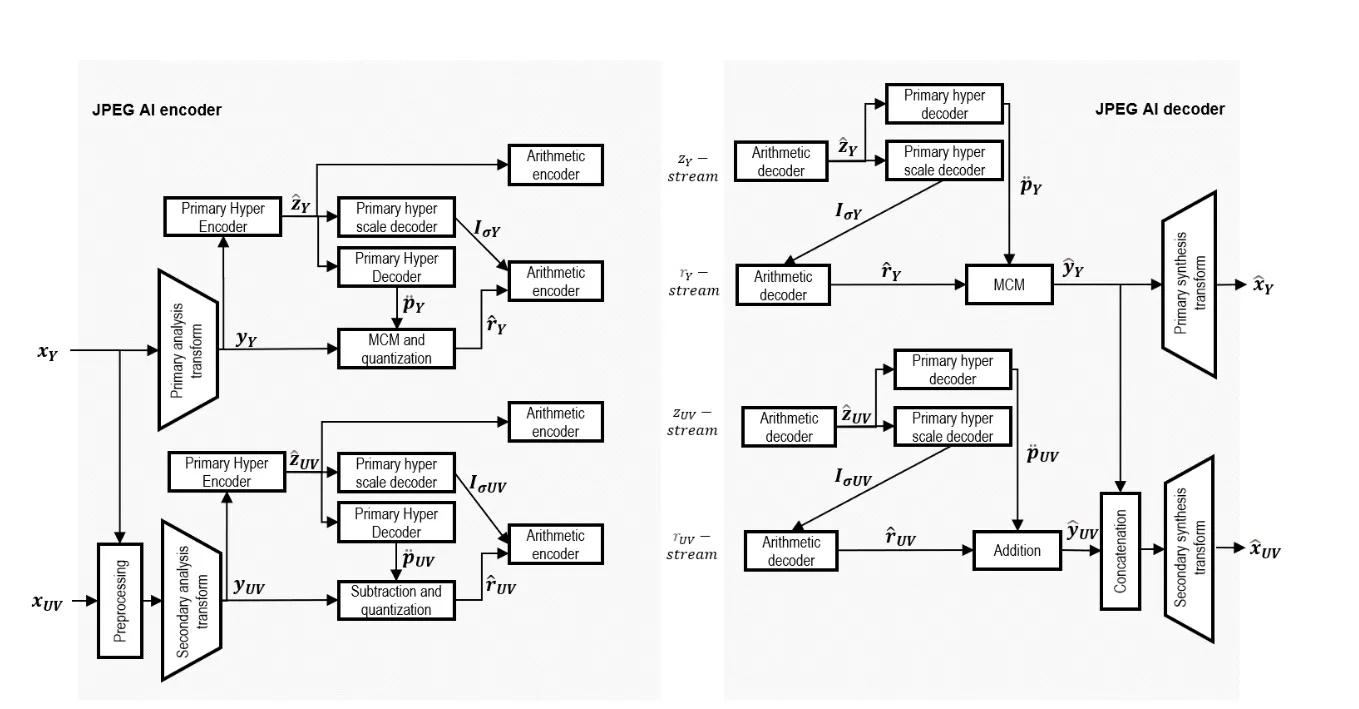 Jpeg AI 结构设计特点:
Jpeg AI 结构设计特点:
1. JPEG AI是建立在多分支解码框架之上的,其中,单个码流可以解码得到多个重构,具有不同的复杂度和质量折衷,便于在广泛的设备中解码码流的能力,以及在广泛的应用中的适用性。
2. 为了进一步支持高效的部署,JPEG AI只在熵解码流水线的末端定义了一个比特精确的一致性点- -具体是在算术解码阶段之后。
**3. 单个码流**可以解码得到多个重构:在以前 如果你需要一张图片的不同清晰度版本 比如低清、高清、超清,你需要在编码端编三个码流才行,现在Jpegai的功能是 单个码流就可以解码得到多个清晰度版本,减少存储。
**4.** 多分支解码框架 是处理这单个码流的机器,可以满足解码产生多个图像版本。
**5.** JPEG AI基本**基于变分自编码器架构**
**变分自编码器(Variational Autoencoder,VAE):目前 AI 图像压缩技术**,VAE 的目标不仅仅是把图片“压扁”再还原,它还要求压缩后的数据符合某种**数学分布,**把图片变为一个概率分布,他不会告诉你输出的隐变量为多少,而是会告诉你,这个特征的大概范围。
熵解码(Entropy Decoding):数学层面的逆运算。 去掉为了传输而做的“数字戏法”。绝对无损。 出来的数值必须和编码前一模一样。
完整解码 (Full Decoding):物理层面的还原。 将数字信息变回肉眼可见的像素。通常有损。 最终图像和原图会有微小差异。
**实际使用效率:**在已经上市的智能手机上,1024 × 1024的图像可以在20ms内被潜在解码,文献[ 38 ]报道了4K图像可以在190ms左右被解码。
2.1 Part1 Xy input to Primary analysis transform to get y Y y_Y yY
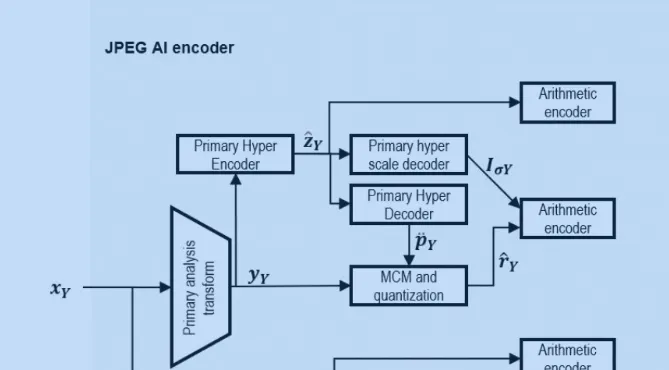
y Y y_Y yY 需要先对数据进行一次转换 转换为YUV格式的 ,然后是对数据进行提取 只提取Y部分也就是亮度。
img_bgr = cv2.imread("00049_TE_5566x3569_8bit_sRGB.png")
img_ycrcb = cv2.cvtColor(img_bgr,cv2.COLOR_BGR2YCrCb)
y = img_ycrcb[:,:,0]
H, W = y.shape
print(y)
print(y.shape)
pad_h = (16 - H % 16) % 16
pad_w = (16 - W % 16) % 16
y_padded = cv2.copyMakeBorder(
y,
0, pad_h, 0, pad_w,
borderType=cv2.BORDER_REFLECT
)
x = torch.from_numpy(y_padded).float().unsqueeze(0).unsqueeze(0)
print(x.shape)
基本流程与数据流转。
- 主分量 x Y x_Y xY 会先输入Primary analysis transform 然后得到latent representation y Y y_Y yY 。
- 在潜在变量得到以后 y Y y_Y yY 会被流转到两个模块 一部分是 Hyper encoder 部分,一部分作为MCM的输入部分。其中Hpyer encoder 的作用是对 前面潜在变量的输出再做一次编码或者处理得到 z,对hyper encoder输出后的结果 进行一个均匀量化,得到量化后的超张量。得到 z ˆ Y \^{z}_Y zˆY。
- 使用预定义概率表的算术编码过程 将量化后的超张量 z ˆ Y \^{z}_Y zˆY 编码为子流 z Y − S t r e a m z_Y -Stream zY−Stream 。
- z ˆ Y \^{z}_Y zˆY 后续会被输入Hyper Decoder 模块,得到primary prediction tensor p ¨ Y \ddot{p}_Y p¨Y
- z ˆ Y \^{z}_Y zˆY 另一个分支会被 输入到Hyper Scale Decoder 得到输出the variance tensor in the logarithm domain I σ Y I_\sigma Y IσY
- 后续就是前面得到的latent representation y Y y_Y yY 和 前面得到的 p ¨ Y \ddot{p}_Y p¨Y 作为输入 经过MCM模块。多阶段上下文模型( MCM ) 输出是得到the quantized primary residual ,and latent tensors y ˆ Y \^{y}_Y yˆY 和 r ˆ Y \^{r}_Y rˆY
- 其中MCM多阶段上下文模型会分为四个stage 0-3,每个stage会生成 1/4的 r ˆ Y \^{r}_Y rˆY
- 最后采用算术编码方法再将 r ˆ Y \^{r}_Y rˆY 编码 为子流 r Y − S t r e a m r_Y - Stream rY−Stream 。
在两个算术解码过程(即量化超张量和残差张量的解码)之间交错的主超尺度解码过程和次超尺度解码过程被设计为计算轻量级,以便在CPU上高效地实现整个熵解码流水线。
也就是说这个Primary Hyper decoder 设计的起点就是一个轻量级的计算设计 本意就是为了能够再CPU上运行。
2.2 Part2 Xuv input to Primary analysis transform to get
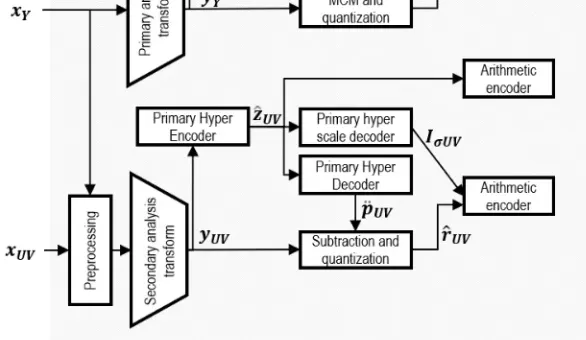
首先需要从图片中提取得到 ${x}_{UV} $ 分量 然后和 $x_Y $ 分量一起做一个预处理 才能作为最开始的输入 。
x U V {x}_{UV} xUV 分量的获取:
一定是Y,Cr,Cb 三个分量之间处理然后进行通道的叠加。
对于一张PNG图片: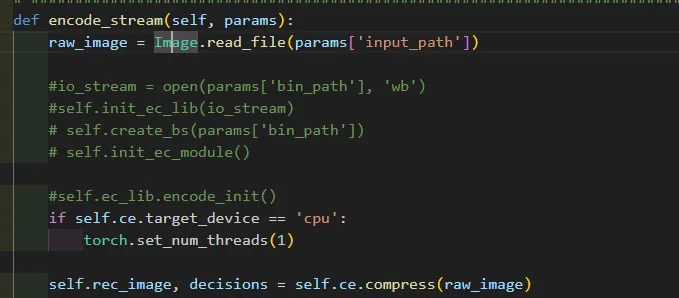
代码在这里进行读取图片,使用了自己写的一个类Image。read_file 对于普通的PNG图片都是统一按444格式度,这边只是构建了一个普通的Tensor,然后定义了一些数据会用到的信息,比如bit是几位这种,defult是8比特。然后再compress部分主要是执行以下过程: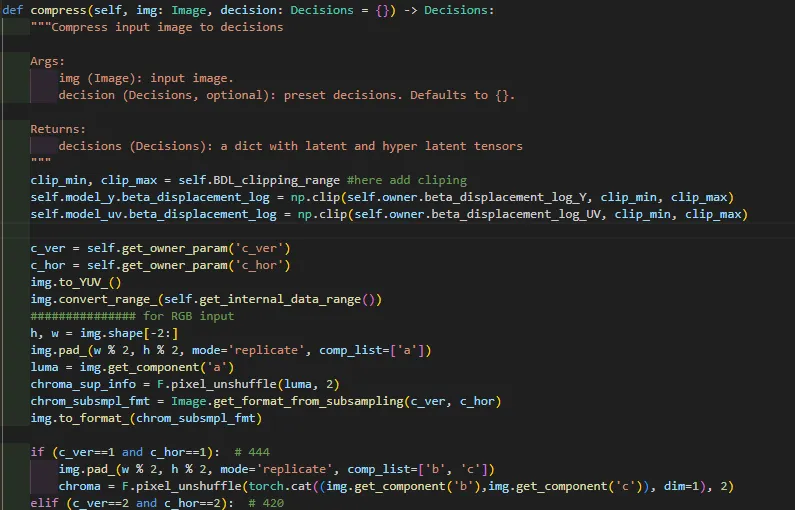
img.pad_(w % 2, h % 2, mode='replicate', comp_list=['a']) ## 边缘填充
# 所以这部分不用管了
luma = img.get_component('a') #luma变量就是 Y变量部分
chroma_sup_info = F.pixel_unshuffle(luma, 2)
"""在执行一种**“空间换通道”的重排操作,其核心目的是在不丢
失任何像素信息的前提下,将亮度(Luma)图像的分辨率降低,
同时增加通道数,以便和色度(Chroma)分量进行特征对齐。"""
# 它把 2*2 的局部方块中的 4 个像素,分别抽出来,放到新张量的 4 个通道中
chrom_subsmpl_fmt = Image.get_format_from_subsampling(c_ver, c_hor)
img.to_format_(chrom_subsmpl_fmt)
# 这两句是在检查转换 图像格式到底是否已经是444了
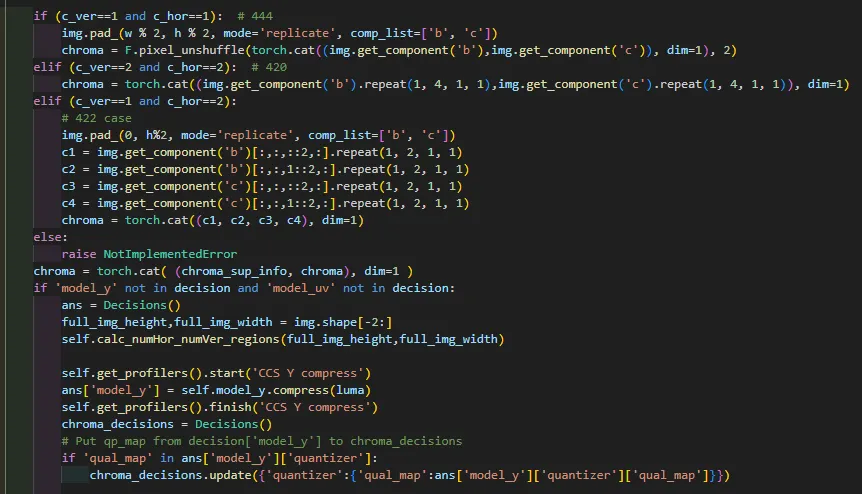
if (c_ver==1 and c_hor==1): # 444
img.pad_(w % 2, h % 2, mode='replicate', comp_list=['b', 'c'])
chroma = F.pixel_unshuffle(torch.cat((img.get_component('b'),img.get_component('c')), dim=1), 2)
chroma = torch.cat( (chroma_sup_info, chroma), dim=1 ) # 后续又做了一个concat 对数据concat
# 最后得到chroma 亮度
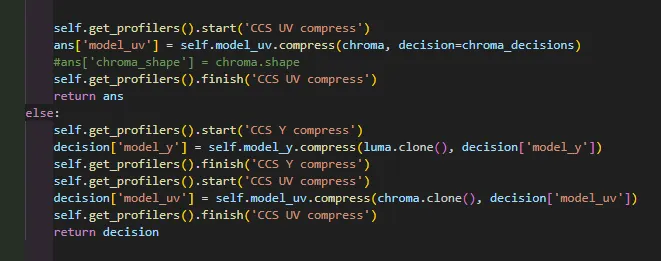
已经确定png就是用444格式了 说一concat就是使用这样的concat
在外部复现这个分支步骤的Processing 过程。
import cv2
import numpy as np
import torch
import torch.nn.functional as F
def reproduce_chroma_with_cv2(img_path):
img_bgr = cv2.imread(img_path)
img_yuv = cv2.cvtColor(img_bgr, cv2.COLOR_BGR2YCrCb)
y_comp = torch.from_numpy(img_yuv[:, :, 0]).float().unsqueeze(0).unsqueeze(0)
u_comp = torch.from_numpy(img_yuv[:, :, 2]).float().unsqueeze(0).unsqueeze(0)
v_comp = torch.from_numpy(img_yuv[:, :, 1]).float().unsqueeze(0).unsqueeze(0)
luma = y_comp / 255.0
u_comp = u_comp / 255.0
v_comp = v_comp / 255.0
chroma_sup_info = F.pixel_unshuffle(luma, 2)
uv_cat = torch.cat((u_comp, v_comp), dim=1)
chroma_data = F.pixel_unshuffle(uv_cat, 2)
final_chroma = torch.cat((chroma_sup_info, chroma_data), dim=1)
return final_chroma

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 23
23 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)