Claude code让程序员消失,Anthropic却说用AI编程会让你变傻
Claude code带来了编程领域的奇点,手动编程的程序员或将消失。当人工智能以前所未有的速度重塑软件工程乃至各行各业的生产力时,我们是否正在支付昂贵的认知代价?Anthropic的科学家Judy Hanwen Shen和Alex Tamkin进行了一项引人深思的随机对照实验。研究人员没有着眼于AI产出了多少代码,而是将目光投向了更隐秘的过程。当一个新手过度依赖AI去完成从未接触过的任务时,他们
Claude code带来了编程领域的奇点,手动编程的程序员或将消失。
当人工智能以前所未有的速度重塑软件工程乃至各行各业的生产力时,我们是否正在支付昂贵的认知代价?
Anthropic的科学家Judy Hanwen Shen和Alex Tamkin进行了一项引人深思的随机对照实验。


研究人员没有着眼于AI产出了多少代码,而是将目光投向了更隐秘的过程。
当一个新手过度依赖AI去完成从未接触过的任务时,他们的大脑发生了什么?
实验结果揭示,那些依靠AI辅助的参与者在概念理解、代码阅读和调试能力上出现了显著退化。
而他们原本期待的效率提升却并未如期而至,这种“技能空心化”的现象,为我们在AI时代的人才培养敲响了警钟。
AI降低了技能掌握度
软件工程是观察人类与AI协作的最佳窗口,因为代码的逻辑容不得半点含糊,且新手往往从模仿和试错中成长。
研究团队设计了一项精巧的实验,他们招募了52名具有一定经验但从未接触过Python Trio库的开发者,这项任务要求参与者使用Trio库完成异步编程挑战。
Trio库的选择非常考究,它不像asyncio那样广为人知,包含了结构化并发等新颖概念,且文档清晰易用,这完美模拟了职场中工程师需要快速上手新工具的真实场景。
实验被设计为一个严谨的随机对照试验。
参与者首先完成一个与异步编程无关的热身任务,随后被随机分为两组。
处理组可以使用基于GPT-4o的AI编程助手,助手可以回答问题甚至生成完整代码;而控制组则只能依靠官方文档和搜索引擎,没有任何AI的介入。
为了量化学习成果,所有参与者在任务结束后都需要参加一场涵盖调试、代码阅读和概念理解的测验,这场测验被严格设计,禁止使用AI,以此来检验在大脑中真正留存了多少知识。
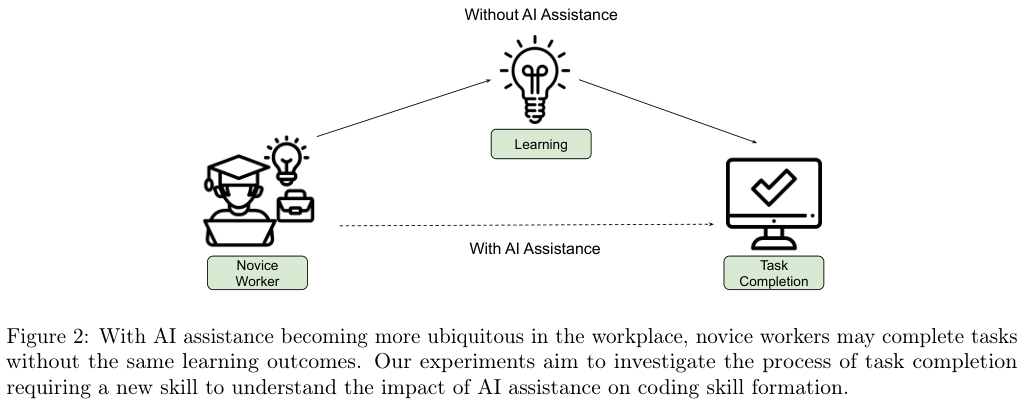
令人惊讶的数据出现在对任务完成时间的统计上。
尽管我们普遍认为AI是效率的倍增器,但在这次需要学习新知识的任务中,AI组的平均完成时间为19.5分钟,而无AI组为23分钟。
从统计学角度看,这两者并没有显著差异。也就是说,对于需要理解陌生概念的任务,AI并没有让人们跑得更快。
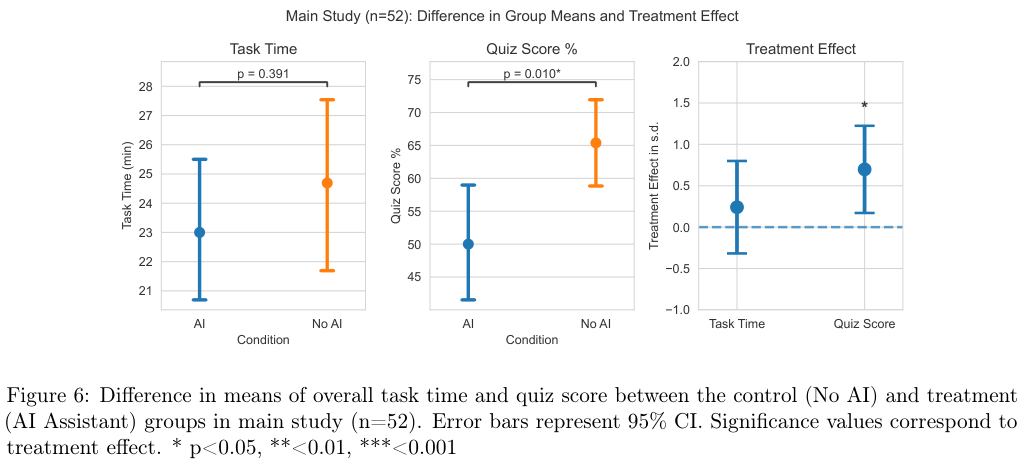
然而,真正的鸿沟出现在随后的技能测验中。
AI组的平均得分比无AI组低了17%,换算成学校的成绩,这相当于整整两个等级的差距(Cohen’s d = 0.738)。
这种能力的流失并非均匀分布,数据显示,AI组在调试(Debugging)类问题上的丢分最为严重。
这是一个极其危险的信号,因为在人机协作的未来,人类最重要的角色本应是AI生成代码的审核者和纠错者。
如果使用AI的过程本身就在削弱人类发现错误的能力,那么所谓“人是回路中的最后一道防线”将成为一句空话。
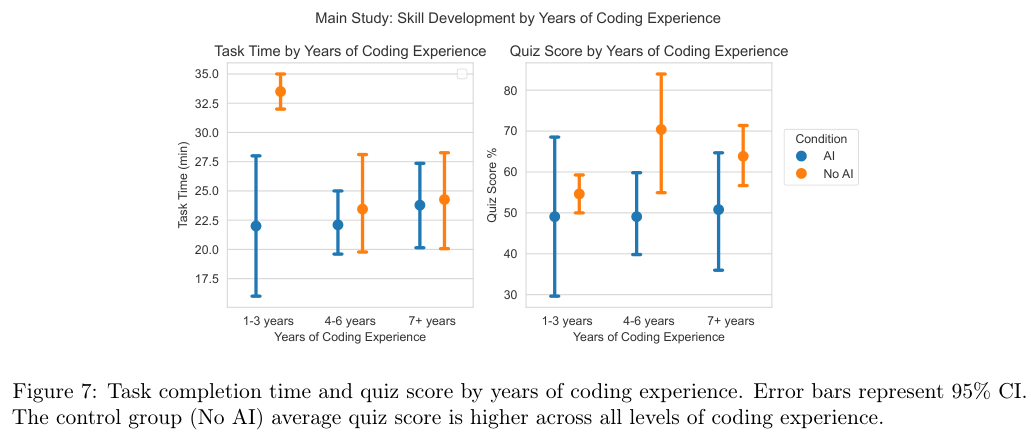
通过分析不同经验背景的参与者表现,研究发现这种负面影响是普遍存在的。
无论参与者有着1到3年的初级经验,还是7年以上的资深背景,只要在学习新库的过程中使用了AI,他们的测验成绩普遍低于那些完全依靠自己啃文档的同行。
这表明,AI诱导的浅层认知加工并不会因为一个人的编程经验丰富而自动免疫。
深入探究AI组为何没有获得预期的速度优势,研究人员对屏幕录像进行了逐帧分析。
原来,原本用于编码的时间被大量转移到了与AI的对话上。
有的参与者花费了长达11分钟的时间来构思如何向AI提问,或者在反复修改提示词。
提示工程的过程本身就消耗了巨大的认知资源和时间。
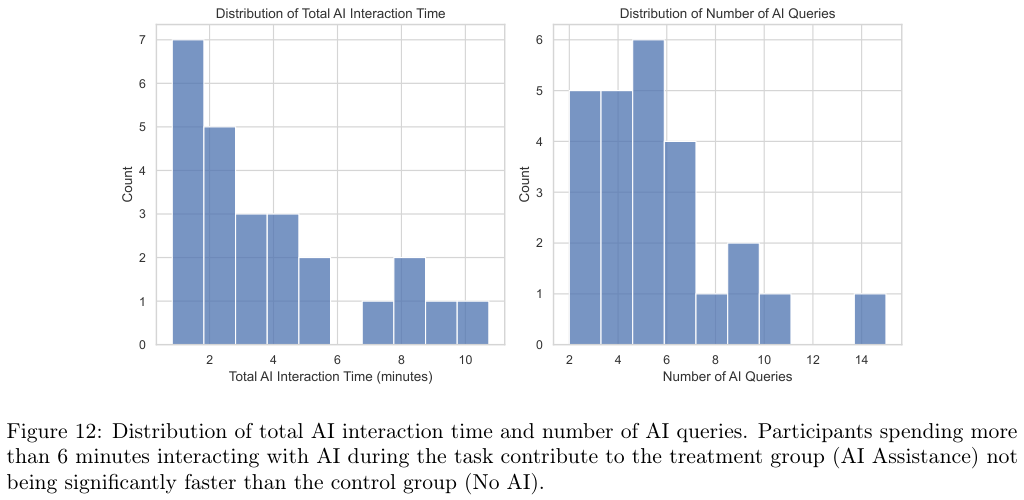
数据展示了一个反直觉的现象:那些花费大量时间与AI互动、试图通过精细化提示词来解决问题的参与者,实际上陷入了另一种形式的低效。
有些参与者在一个35分钟的任务中,竟然花了30%的时间在编写和调整给AI的问题。
虽然AI生成代码的速度很快,但人类阅读、理解、验证以及与AI进行多轮拉锯战的时间,完全抵消了代码生成的红利。
更重要的是,这种时间的转移并不是等价交换。
与文档死磕虽然痛苦且缓慢,但每一分钟都在加深对逻辑的理解;而与AI的对话往往停留在意图的表达上,大脑不再从底层构建知识体系,而是变成了一个发号施令却不懂原理的工头。
进一步的细分分析显示,技能掌握程度的下降在各个维度上都有体现。
无论是概念理解、代码阅读还是调试,AI组的表现都全面落后。
尤其是在调试环节,差距最大。
无AI组的参与者因为在做任务时必须亲自处理每一个报错,每一次失败都迫使他们回到文档中去寻找原理,这种反复的“遭遇错误-定位原因-修正代码”的循环,实际上是最有效的深度学习过程。
而AI组的参与者,因为AI往往能直接给出无错的代码,或者在遇到错误时直接把错误信息丢给AI去修复,他们失去了与错误“肉搏”的机会,自然也就无法建立起对代码运行机制的敏锐直觉。
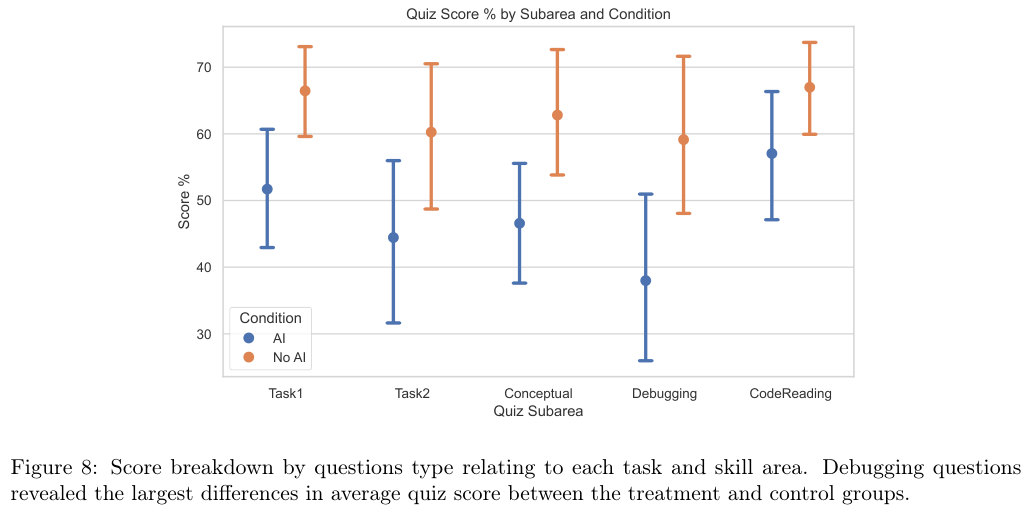
参与者的主观反馈也印证了这一点。
虽然两组人都表示享受这个任务,但在学习感的自我评价上,无AI组显著高于AI组。
AI组的参与者在反馈中坦言,他们感觉自己变懒了,对代码的理解存在很多空白。
他们意识到,虽然任务完成了,但这种完成是建立在对细节的模糊之上的。
这揭示了一个心理学层面的真相:人类的学习往往伴随着一定程度的认知阻力,当AI把这种阻力消除得过于彻底,学习的过程也就随之瓦解了。
交互模式决定是学习还是偷懒
并非所有使用AI的人都注定学不到东西。
研究团队通过对屏幕录像的定性分析,识别出了六种截然不同的AI使用模式。
这些模式如同六种不同的人格画像,清晰地界定了为什么有的人能在AI辅助下依然保持高分,而有的人则彻底沦为工具的附庸。
我们将这六种模式分为低分行为群和高分行为群,它们之间的差异并不在于使用了多少AI,而在于在使用AI时,大脑是否依然在线。
低分行为群主要表现为一种认知卸载的倾向。
其中最典型的是AI托管者(AI Delegation)。
这群人完全把大脑交了出去,他们直接要求AI生成全部代码,然后复制粘贴了事。
虽然他们完成任务的速度最快,但在测验中的表现几乎是毁灭性的。
他们就像是搭乘了一辆自动驾驶的汽车,虽然准时到达了目的地,但对于沿途的路况和驾驶技巧一无所知。
另一种低分模式是渐进式依赖(Progressive AI Reliance)。
这类参与者起初还尝试自己思考,问一两个概念性的问题,但随着任务难度的增加或耐心的耗尽,他们迅速滑向了完全依赖,最终让AI接管了一切。
这种半途而废的思考比完全不思考好不了多少,因为在最关键的难点攻克上,他们选择了放弃。
还有一种被称为迭代式AI调试(Iterative AI Debugging)的模式。
这群人看起来很努力,他们与AI的互动非常频繁,但这是一种无效的忙碌。
他们遇到报错就直接把错误信息丢给AI,AI给出一个修复,他们试运行,如果不通再丢回去。
整个过程他们只是一个信息的搬运工,没有尝试去理解错误为什么发生。
这种盲目的试错循环导致他们既没有效率,也没有学到东西,测验成绩同样惨不忍睹。
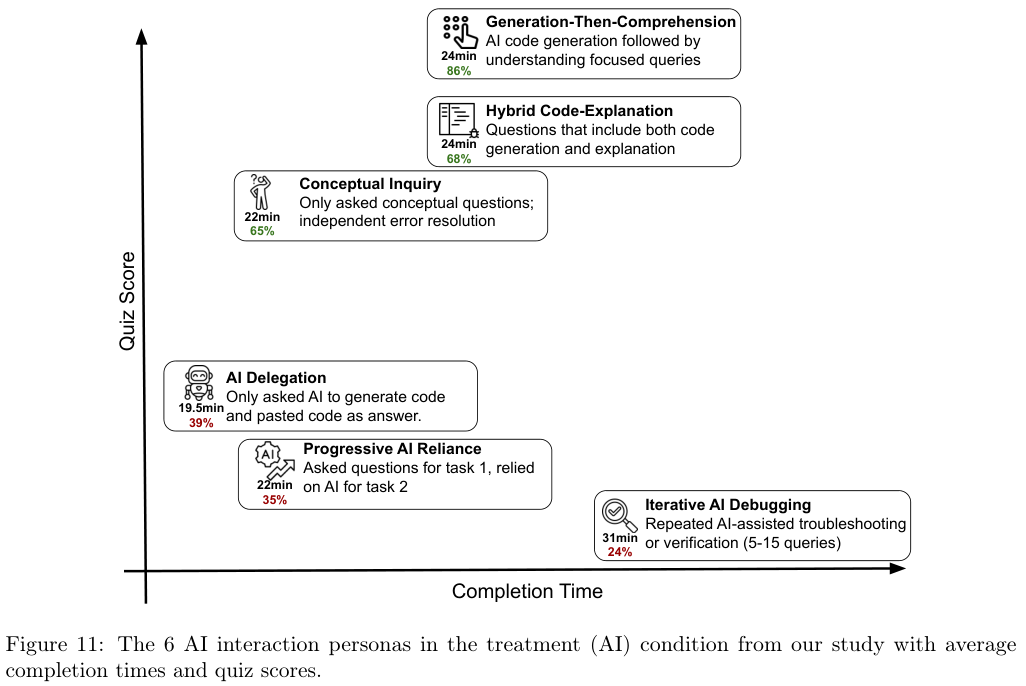
相反,高分行为群展现出了完全不同的特质,他们在使用AI时保留了极高的认知参与度。
得分最高的一类人采用的是先生成后理解(Generation-Then-Comprehension)的策略。
他们也会让AI生成代码,但在拿到代码后,他们并没有急着运行,而是停下来,仔细阅读,甚至反过来向AI提问,要求解释代码中某一行为什么要这么写。
他们把AI生成的结果当作了一个学习的范本,而不是直接的答案。
这种“事后诸葛亮”式的复盘,让他们在享受效率的同时,填补了认知的鸿沟。
另一类高分模式是混合解释(Hybrid Code-Explanation)。
他们在提问时就显得很有策略,不仅要求生成代码,还明确要求AI附带解释。
他们在阅读AI回复时,花在文字解释上的时间甚至超过了看代码的时间。
这种主动寻求知其所以然的态度,是保护技能不被AI侵蚀的关键护城河。
最后一种高分模式是概念性探究(Conceptual Inquiry)。
这群人几乎把AI当成了高配版的百科全书,他们只问原理、概念和逻辑,坚决不让AI直接写代码。
他们利用AI快速补齐知识短板,然后自己动手实现功能。
这种模式下,代码的每一行都出自人类之手,AI只是起到了一个旁征博引的导师作用。
虽然这种方式在速度上没有优势,但他们的测验成绩是所有AI使用者中最高的,甚至可以媲美无AI组。
研究还发现了一个有趣的细节:关于手动抄写是否有助于记忆。
有人认为,即使是AI生成的代码,只要我一行行敲进去,总比直接复制粘贴能学到更多吧?
数据无情地打破了这个幻想。
那些看着AI代码手动输入的参与者,在测验分数上与直接粘贴的人并没有显著差异,而且因为打字速度慢,他们的整体效率甚至更低。
这再次证明,机械的肌肉记忆无法替代深层的认知加工。
如果你只是在把屏幕左边的字符搬运到右边,大脑没有在这个过程中进行逻辑重构,那么这种忙碌就是徒劳的。
唯有大脑的主动思考,才是技能形成的唯一途径。
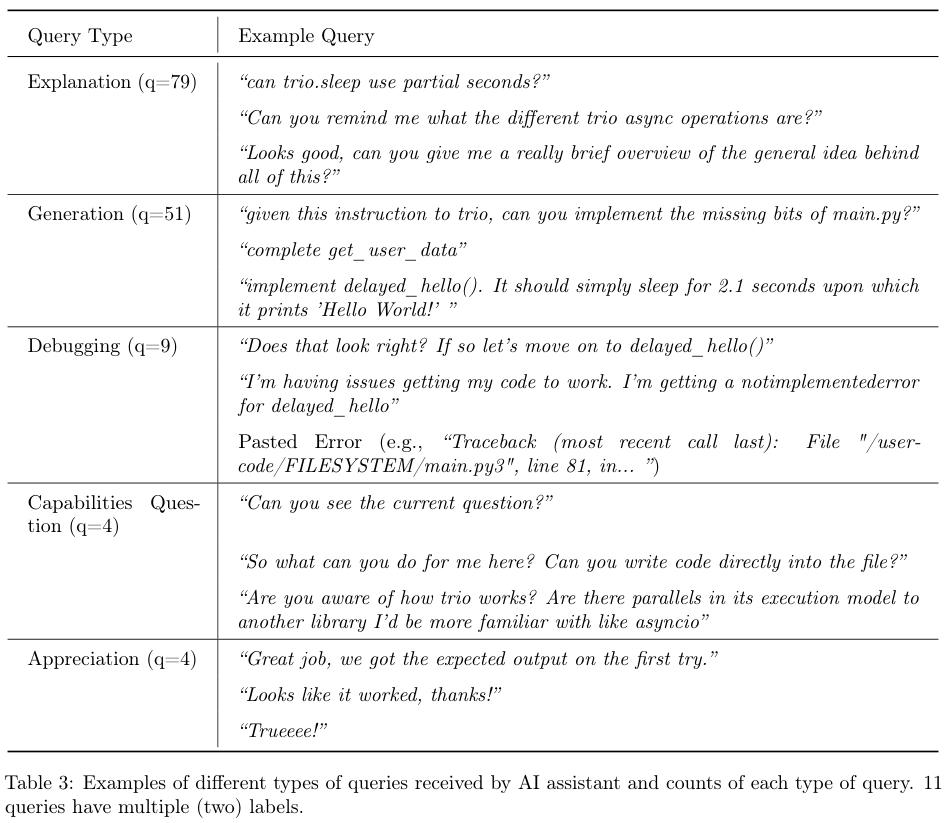
AI查询类型的分布也进一步佐证了这一点。
在所有与AI的对话中,解释性请求(Explanation)虽然数量最多,但往往集中在高分人群中。
而低分人群的查询记录里,充斥着“帮我写这个”、“修复这个错误”等直接的指令。
更有趣的是,还有极少数人把时间花在了调戏AI或者询问AI能力边界上,这种对于工具本身的关注超过了对任务关注的现象,也是导致效率降低的一个旁支因素。
职业成长的核心催化剂
在这项研究中,错误(Errors)不再是阻碍任务完成的绊脚石,而是通往精通之路的垫脚石。
通过对比两组参与者的错误日志,发现了一个鲜明的反差:无AI组的参与者遭遇了大量的报错,而AI组则一路绿灯。
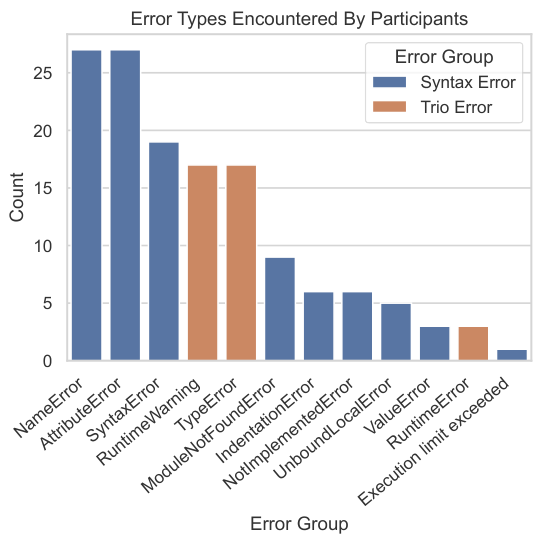
在无AI组中,绝大多数人都遇到了Python的TypeError或Trio库特有的RuntimeWarning。
这些红色的报错信息迫使他们停下来思考:为什么这个协程没有被等待?为什么这个函数调用参数不对?
正是这种被迫的停顿和思考,构成了深层学习的契机。
当一个开发者面对RuntimeWarning: coroutine '...' was never awaited这样的警告时,他必须去理解异步编程中await关键字的含义,必须去搞清楚Trio的事件循环机制。
这个过程虽然痛苦,充满了挫败感,但每一次问题的解决,都是对大脑神经连接的一次强化。
相比之下,AI组的体验过于顺滑了。
AI生成的代码通常在语法上是完美的,即便逻辑有瑕疵,AI也能在追问下迅速修复。
中位数显示,AI组的参与者在整个任务中只遇到了1次报错,而无AI组则是3次。
许多AI组的参与者甚至一次错误都没遇到就跑通了代码。
这种无摩擦的体验剥夺了他们犯错的权利,也剥夺了他们从错误中学习的机会。
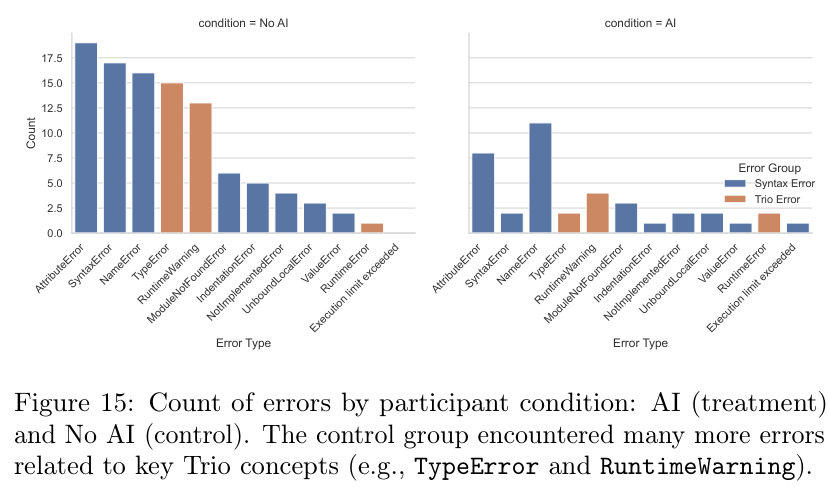
通过分析具体的错误类型,发现无AI组遇到的错误高度集中在与Trio库核心概念相关的领域。
意味着他们的挣扎是具有高度针对性的,他们正在与新知识中最难啃的骨头进行搏斗。
而AI组偶尔遇到的错误,更多是像变量名拼写错误(NameError)这样的低级失误,这种错误的修正几乎不需要任何深层的逻辑思考。
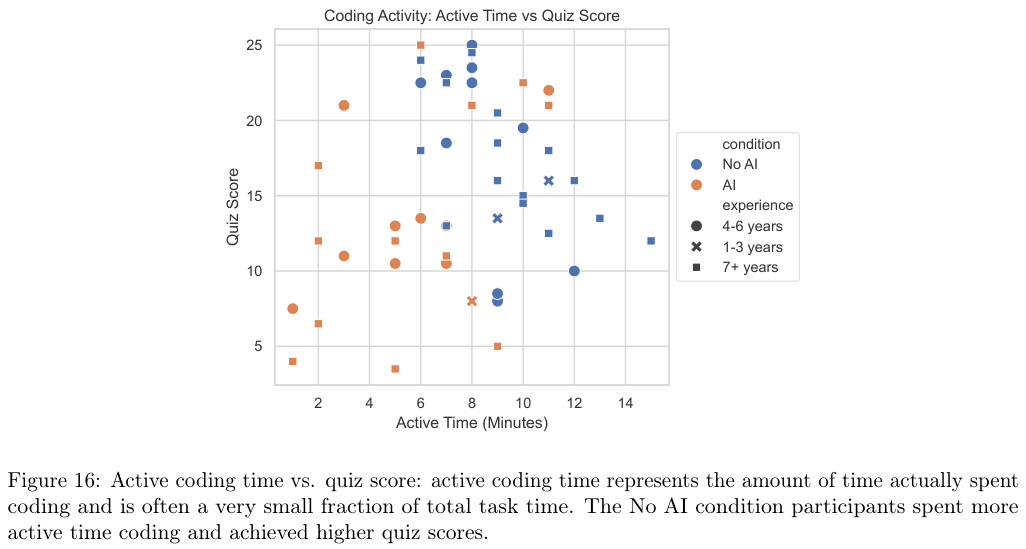
这种差异直接映射到了活跃编程时间(Active Coding Time)上。
无AI组的参与者把大量时间花在了阅读文档、编写代码、运行、报错、修改代码的循环中。
他们的手始终在键盘上,大脑始终在代码逻辑中穿梭。
而AI组的活跃编程时间大幅减少,他们的大部分时间变成了被动的阅读者和等待者。
图表显示,活跃编程时间与测验成绩之间存在正相关关系(在考虑经验水平的前提下)。
也就是说,你越是亲手去折腾代码,你学到的就越多。
如果我们习惯了由AI来帮我们扫清所有的障碍,我们是否正在退化成温室里的花朵?
当未来的某一天,面对一个AI无法解决的复杂边缘情况,或者在一个安全攸关的系统中需要人工排查隐患时,那些从未在报错信息中摸爬滚打过的工程师,是否还有能力力挽狂澜?
研究中的定性反馈令人深思。
无AI组虽然过程曲折,但在任务结束后普遍表现出了更高的成就感和自信心。
他们觉得自己真正掌握了一些东西。
而AI组的参与者虽然轻松交卷,却在反馈中流露出了不安。
一位参与者坦诚地说:“我觉得自己学到的东西支离破碎,我只是在拼凑答案。”
这种自我感知的差距,或许比分数的差距更值得我们警惕。人类内心深处清楚地知道,真正的能力是无法通过捷径获得的。
我们正在进入一个AI无处不在的时代,这项研究并不是要我们因噎废食地拒绝AI,而是必须正视的权衡。
在追求极致效率的同时,我们必须为人脑的训练保留必要的“摩擦力”。
对于新手而言,过早、过度地依赖AI,就像是在学会走路之前就坐上了轮椅。
那些看似节省下来的时间,最终都将变成能力账单上的高额债务。
在人机协作的未来,只有那些愿意主动跳出舒适区,坚持用大脑去审视、去质疑、去解构AI生成内容的人,才能真正驾驭这项强大的工具,而不是被工具所驾驭。
参考资料:
https://arxiv.org/pdf/2601.20245
https://www.anthropic.com/research/AI-assistance-coding-skills

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 5
5 0
0- 0



 已为社区贡献236条内容
已为社区贡献236条内容

所有评论(0)