vLLM、SGLang 融资背后,AI 推理正在走向系统化与治理
最近,推理引擎领域出现了两件具有标志意义的事件:vLLM 和 SGLang 相继走向公司化。vLLM 核心团队成立 Inferact,完成 1.5 亿美元融资,估值达 8 亿美元:图源:InferactSGLang 团队也成立了 RadixArk,同样获得融资,估值达到 4 亿美元:图源:RadixArk这并不是两起孤立的创业故事,而是在同一个时间点,对同一件事情给出了市场层面的确认:推理已经正式
最近,推理引擎领域出现了两件具有标志意义的事件:vLLM 和 SGLang 相继走向公司化。vLLM 核心团队成立 Inferact,完成 1.5 亿美元融资,估值达 8 亿美元:

图源:Inferact
SGLang 团队也成立了 RadixArk,同样获得融资,估值达到 4 亿美元:

图源:RadixArk
这并不是两起孤立的创业故事,而是在同一个时间点,对同一件事情给出了市场层面的确认:推理已经正式进入 AI 基础设施的核心层,而不再是模型之后的附属环节。
如果把过去几年 AI 的发展理解为模型能力竞赛,那么现在正在发生的,是一场系统工程能力竞赛。模型决定上限,推理系统决定规模化能力。一个模型是否有商业价值,越来越取决于它是否能被低成本、稳定、可持续地运行。
vLLM 和 SGLang 的融资,本质上是在为推理层重新定价。
一、推理引擎已经从工具升级为基础设施内核
早期的推理引擎更像是工具链的一部分,目标很简单:把模型跑起来,并尽量提升吞吐和降低延迟。它们解决的是局部性能问题,而不是系统性问题。
但今天的 vLLM 已经完全不同。它必须同时面对两条不断加速的演化曲线:
一条来自模型侧:Dense、MoE、多模态、Agent、超长上下文不断出现;
一条来自硬件侧:GPU、NPU、定制加速器、不同 CUDA/驱动/编译链并存。
在工程上,这意味着推理引擎被迫承担一个新的角色:
成为模型与硬件之间的通用适配层。
当一个系统需要同时满足:
- 支持大量模型架构
- 覆盖多种异构硬件
- 承载从科研验证到大规模生产负载
它的属性就已经不再是“工具”,而是基础设施内核。
SGLang 从另一个方向推动了同一件事。它把推理从“函数调用”扩展为“可编程执行流程”,特别适合 Agent、强化学习和复杂工作流场景。这说明推理系统正在同时向两个方向演进:
一方面更像操作系统内核,负责资源与性能;
另一方面更像运行时与编程模型,负责表达能力。
这两种属性叠加,正是基础设施系统的典型特征。
二、推理成本已经成为 AI 商业化的决定性因素
在真实工程中,一个简单的事实越来越清晰:
训练决定模型能不能出现,
推理决定模型能不能活下去。
对绝大多数公司来说:
- 训练是阶段性成本
- 推理是长期、持续、不可回避的成本
随着模型规模扩大、调用频率上升,推理成本已经从“次要支出”变成“核心账单项”。很多场景里,推理成本远高于训练成本。
这使推理系统具备了极强的经济敏感性:
- 5% 的吞吐提升
- 10% 的显存利用率优化
- 一点点调度效率提升
都会直接反映为真实的资金节省。
因此,推理引擎的价值不再只是“技术好不好”,而是“能不能直接影响 AI 服务的成本结构”。
这也是资本真正愿意为其高估值买单的原因。
三、推理系统的复杂性已经不可逆转
推理问题越来越难,并不是因为模型“更大”,而是因为系统维度在急剧膨胀:
- 模型形态更加复杂:Dense、MoE、多模态、Agent
- 推理形态更加复杂:长上下文、推理时计算、RL 循环
- 硬件环境更加碎片化:多 GPU、多 NPU、多编译链
工程上已经出现一个明显现象:
很多模型在理论上“可以跑”,
但系统在现实中“跑不动、跑不稳、跑不起”。
Inferact 提出的愿景非常关键:
部署前沿模型应该像创建一个 Serverless 数据库一样简单。
这句话的真实含义是:
推理系统必须吞掉所有复杂性,而不是把复杂性留给使用者。
四、推理系统治理问题会持续放大
当 vLLM、SGLang 进入快速演进之后,一个确定会发生的变化是:
新模型适配、新硬件支持、新优化策略都会更频繁进入主线版本。这对行业是好事,但对使用者来说,复杂度反而会上升。
在真实工程中很快会遇到这些问题:
- 同一模型在不同引擎版本下表现差异明显
- 不同硬件对引擎版本的支持程度不一致
- 升级引擎可能带来性能提升,也可能带来稳定性风险
推理引擎不再是“选一次就结束”的组件,而是进入持续治理阶段。
五、多引擎并存是工程必然,而不是选择题
现实生产环境中几乎不可能存在万能引擎:
- 有的模型适合 vLLM
- 有的模型适合 SGLang
- 有的场景适合 TRT-LLM
- 有的设备只能跑 llama.cpp
多引擎并存不是过渡状态,而是长期结构。
如果没有统一治理层,系统最终一定会退化为:
- 脚本堆叠
- 手工配置
- 版本失控
- 故障不可回溯
这是大型系统必然的退化路径。
六、GPUStack 的本质:推理系统的控制平面
GPUStack 并不是另一个推理引擎,它解决的是“引擎治理问题”。
在 GPUStack 的视角里:
- 引擎是可插拔资源
- 引擎版本是可调度对象
- 模型实例是可编排单元
推理引擎从“写死在系统里的依赖”,变成了“运行时可切换的能力”。
这在工程上的意义非常大:
- 可以并行运行多个引擎与版本
- 可以灰度升级
- 可以快速回滚
- 可以做真实可控的性能对比
支持自定义使用任意推理引擎:
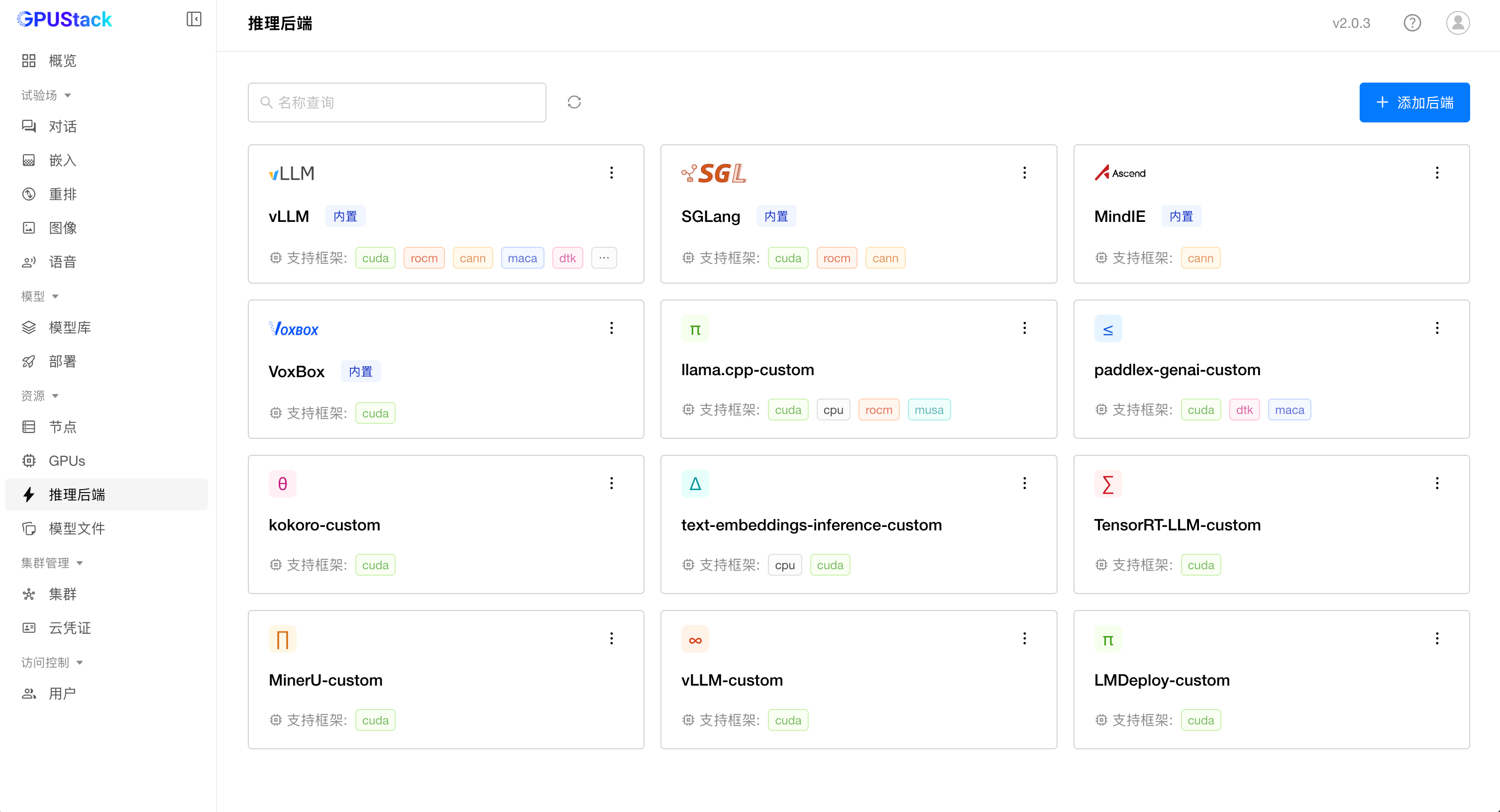
自由切换任意推理引擎:
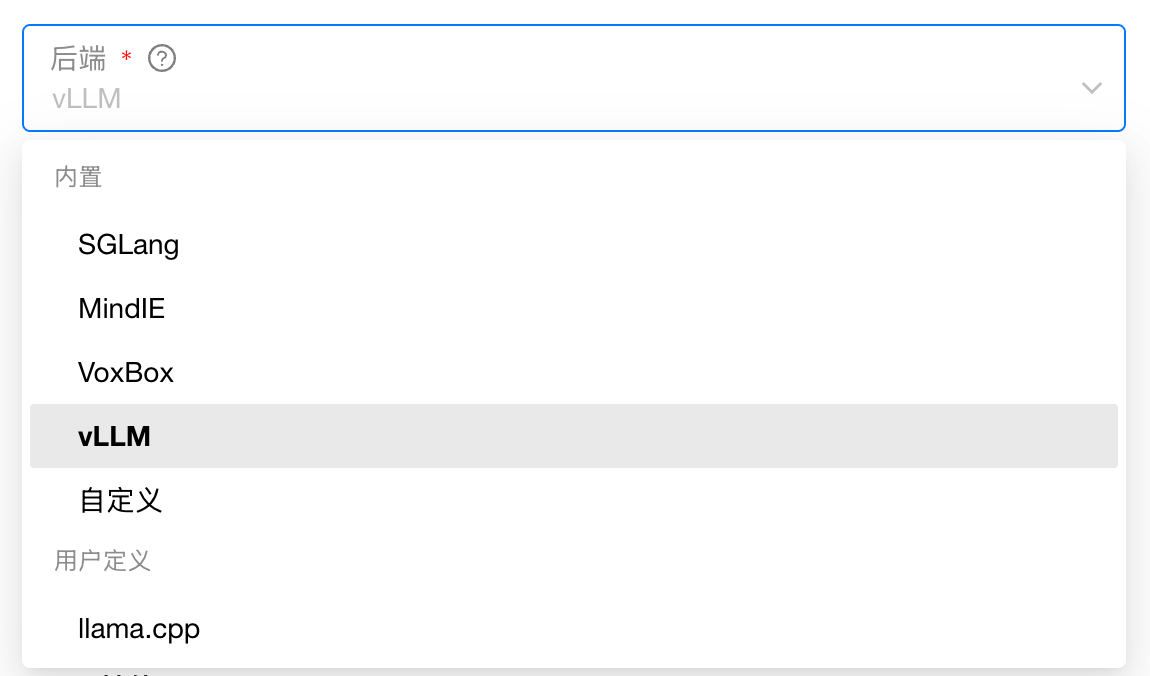
自由切换推理引擎版本:
推理系统开始具备云原生系统应有的治理能力。
七、引擎与版本切换,本质是 AI 推理世界的运行时治理
当推理引擎成为基础设施之后:
“要不要升级”不再是问题,
“如何安全升级、如何可控回退”才是问题。
这在工程上与:
- 数据库内核升级
- 容器运行时升级
- Kubernetes 升级
是完全同一类问题。
GPUStack 做的事情,本质是把这种“运行时治理”能力引入推理系统。
八、真正的信号不是融资,而是系统层级的改变
vLLM 与 SGLang 的融资,不是某两个项目的成功,而是行业完成了一次角色确认:
推理层已经从“模型附属组件”,升级为 AI Infra 核心层。
而 GPUStack 的出现,也不是产品机会,而是工程必然:
当底层能力高速进化、多引擎并存成为常态,没有控制平面的系统一定会失控。
从工程视角看,GPUStack 把推理系统从“项目级资产”升级为“平台级资产”;
从组织视角看,它让推理能力不再依赖少数专家,而成为团队可复用的基础能力。
这正是推理基础设施真正成熟的标志。
如果觉得对你有帮助,欢迎点赞、转发、关注。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 14
14 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)