GPU PRO 4 - 6.1 Bit-Trail Traversal for Stackless LBVH on DirectCompute 笔记
本笔记仅为个人的理解,如果有误欢迎指出。层次包围结构:这是一种树形的数据结构,一般常用于碰撞检测,游戏引擎中将场景的物体进行划分的时候就会将物体都划分成一个一个包围盒,由此生成了一个树形结构线性的层次包围结构:LBVH是一种使用了Morton Code(位交错编码/莫顿码)线性构建的BVH结构,一般LBVH的使用对象是网格上的三角形,LBVH用每个三角形的三个顶点坐标计算出三角形的重心坐标,再将三
本笔记仅为个人的理解,如果有误欢迎指出。
BVH(Bounding Volume Hierarchy)
层次包围结构:这是一种树形的数据结构,一般常用于碰撞检测,游戏引擎中将场景的物体进行划分的时候就会将物体都划分成一个一个包围盒,由此生成了一个树形结构
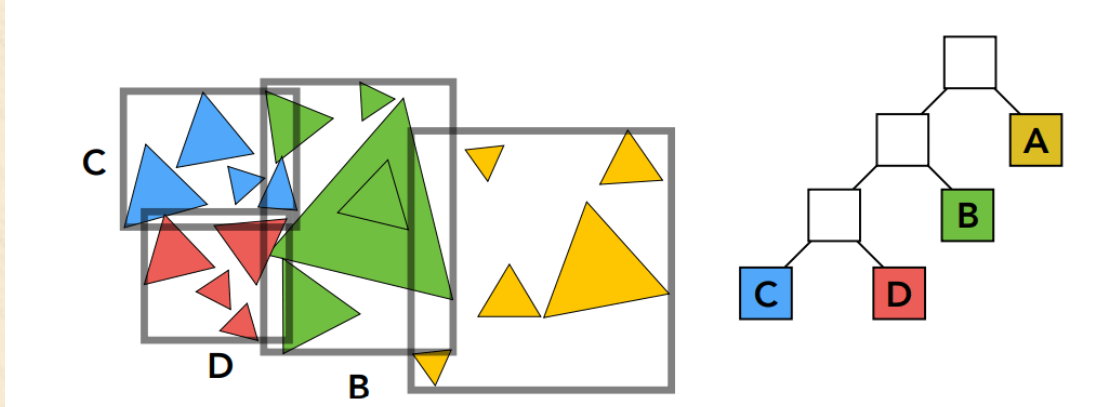
LBVH(Linear BVH)
线性的层次包围结构:LBVH是一种使用了Morton Code(位交错编码/莫顿码)线性构建的BVH结构,一般LBVH的使用对象是网格上的三角形,LBVH用每个三角形的三个顶点坐标计算出三角形的重心坐标,再将三角形重心坐标通过Morton Code映射成一串编码,再根据每个三角形编码的相似性进行包围层次包围结构的划分。可以预想的到,这种方法将三角形的面积信息省略,包围盒的划分具有一定的误差。
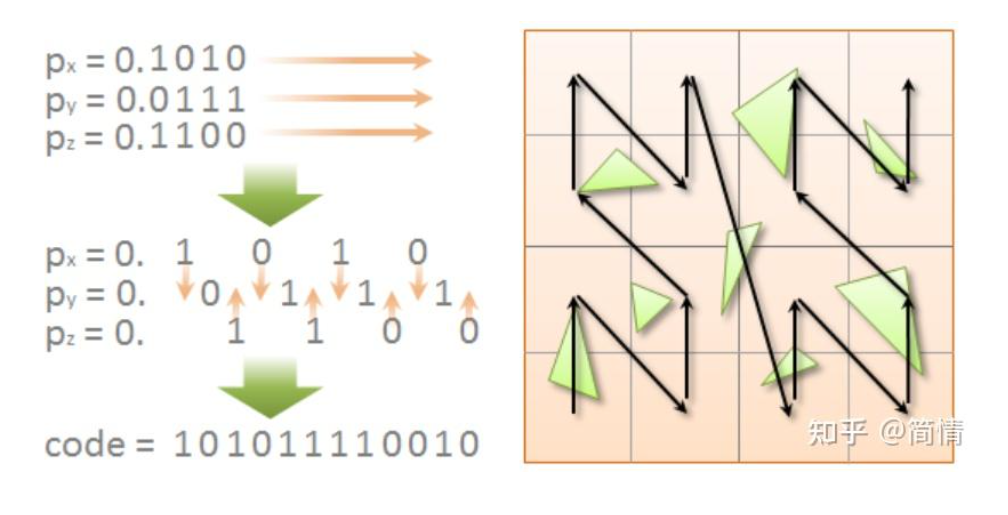
Stackless LBVH
无栈LBVH。当我们需要遍历一个树节点的时候一般我们都习惯用迭代或者递归的方式去遍历,这在CPU中非常普遍,每次在迭代和递归的时候都会在CPU的栈堆里压入函数,方便后续退出循环的时候回到代码上一次执行的位置。但是这种方式在GPU中是相当耗费性能的,GPU的计算单元没有那么高性能的栈去循环迭代,迭代和递归的代价很高,这也是shader编程中避免代码嵌套的原因之一,所以标题的Stackless(无栈)指的是不使用堆栈。
Bit-Trail Traversal
位前缀遍历,Bit-Trail这个概念指的是LBVH中Morton Code给每个三角形生成的编码,为了实现不使用堆栈的遍历,这篇文章考虑构建LBVH时三角形的编码规律来实现遍历,因为相近的三角形坐标相近,对应的他的编码前缀有相当一部分是相似的,这是这个遍历的核心思想之一。
Bit-Trail Traversal for Stackless LBVH on DirectCompute
基于DirectCompute实现的无栈LBVH的位前缀遍历
光追渲染:
这篇文章在使用SLBVH结构时渲染流程如下:
1,在 CPU 上初始化应用程序;
2,将数据发送到 GPU;
3,从零开始构建一个 SLBVH;
4,渲染阶段:
(a) 发射主光线(primary rays);
(b) 计算相交测试;
(c) 发射次级光线(secondary rays);
(d) 计算颜色;
5,重复步骤 3–4。
在发射主光线和次级光线时,遍历SLBVH时获取到的最近相交点,最佳的相交点会被保存。
全局光照的实现:
本文在生成全局光照时采用的是蒙特卡洛(Monte Carlo)方法,管线在生成当前帧的图像的时候会使用以前所生成的图像按比例混合生成最终结果。
当生成第 n 张图像时,累积图像中的每个像素 Pa 都会按照公式进行更新:
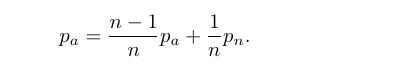
这种处理的实现思路在虚幻5引擎中就有广泛应用。
光线追踪算法需要在光线击中三角形表面后计算反射方向,然后再沿着反射方向进行下一次的碰撞检测。传统的光线追踪算法计算的反射方向的算法是固定的,在这里的光追算法对反射方向的计算有了区别。
在光线击中三角形进行反射计算的时候会判断要进行漫反射的计算还是镜面反射的计算。
在漫反射上,反射方向是从一个单位球面(Unitary sphere)上采样获得的。
在镜面反射中,则会根据击中点的法线向量来计算反射。
而判断是要漫反射还是镜面反射则通过一个介于0~1的Pdiff参数来判断。代码如下:

代码上看,它应该是先从单位球面上随机采样,然后再通过和Pdiff比较来判断区分漫反射和镜面反射,主打一个随机,有规律的糊弄。
Stackless LBVH 的结构
在这篇文章中解释SLBVH是用图元的Morton Code进行中值划分(middle split)构建的一种无栈、无指针的二叉堆结构。 简单来说他就是一个数组形式的完全二叉树,如果有做过用数组实现完全二叉树的话对这个结构就很熟悉。
正因为他本质是一个数组,他在获取下一个子节点的时候不需要通过递归访问左右节点来获取,而只需要通过当前索引再进行一个简单的数学计算就能知道下一个子节点的索引,从而实现了无栈遍历。
每个节点的大小为32字节,每个字节8位,即 8 x 32 。 6 x 32 用来存储AABB包围盒两个对角顶点,也就是两个xyz坐标(2 x 3),剩下 2 x 32 位用来记录当前包围盒的图元数量(PrimCount),以及图元偏移(PrimPos)。
其中PrimCount不单单只保存图元数量,他还保存当前节点是叶节点还是中间节点,Axis记录当前包围盒的划分轴

Stackless LBVH 的构建流程:
1,为每个图元生成 AABB 以及对应的 32 位 Morton Code(莫顿码);
2,使用 Morton Code 作为键,对图元进行排序;
3,构建树结构;
4,为每个节点生成对应的 AABB。
1,为每个图元生成 AABB 以及对应的 32 位 Morton Code(莫顿码);
这里利用GPU多线程计算图元的相关数据,代码如下:

2,使用 Morton Code 作为键,对图元进行排序;
这篇文章的排序算法使用了DX11开发工具提供的Bitonic Sort 的一个改良版本,将上一步每一个图元计算得到的Morton Code进行升序排序。
3,构建树结构;
构建树的时候每个线程会计算两个节点的数据,构建过程中,每一次遍历都只计算一层的节点,所以遍历的次数就等于树的深度,所以在刚开始的时候GPU并行度较差,第一层只能用一个线程来计算。
节点分为3类:无效节点,叶节点,内部节点/中间节点
在计算当前节点时,算法会检查父节点的信息,如果父节点的PrimCount 为负值,则说明父节点是无效节点,则当前计算的两个节点都是无效节点。
如果当前节点的索引小于 则说明这个节点是内部节点,否则则是叶子节点。具体判断代码如下:

内部节点会有两种情况被判断为叶子节点,然后将其子节点标为无效节点:
1),某个分支在达到最大树的深度D之前已经完成了几何划分。
2),两个或者更多的图元都有相同的Morton Code
在计算PrimCount时会将划分轴的信息(二进制表示下 x = 00、y = 01、z = 10)记录在最后两位,分割轴的信息有助于在遍历的时候和光线的方向信息结合快速判断下一个遍历节点。
4,为每个节点生成对应的 AABB。
这里会自底向上遍历这个树的节点,如果当前的节点是叶子节点则用每个图元的包围盒来构建这个节点的包围盒,如果是内部节点,则取两个子节点的包围盒来构建这个节点的包围盒。
遍历:
文章中遍历的算法有两个重要的特征:
1,记录遍历轨迹的方式不是用堆栈,而是用比特轨迹
2,光线重新开始遍历的时候是从最后命中的节点开始而不是从根节点开始
遍历的过程是从一条光线出发,与SLVBH各个节点的包围盒数据进行相交测试,直到到达叶节点的节点,然后再与该节点记录的图元进行相交测试,并存储到相机最近的交点。与其他遍历算法不同的是,光线如何去选择访问下一个节点,以及如何返回到之前没访问的节点。
比特轨迹(trail)定义:
比特轨迹取代了堆栈的作用,它是一个32位整数,每一位代表树中的一个层级。
当该比特位置为0的时候代表子树当前层级中还有未访问的节点。
当该比特位置为1的时候代表当前子树的当前层级的所有节点都已被访问。
轨迹(trail)的初始值为 1 << firstbithigh(nodeNum),firstbithigh函数是Shader Model 5中可用的DirectX内置函数。它返回从最高有效位开始向下查找第一个置位比特的位置。
比如:
uint input = 8; // 二进制表示为 0000 0000 0000 0000 0000 0000 0000 1000
int result = firstbithigh(input);
// 结果为 3,因为第4位(从右数第4位,即索引3)是第一个1nodeNum:表示最近一次命中的节点的节点编号,初始值为1.
基本遍历逻辑:
在整个遍历流程中只保存了两个变量,一个是当前命中的节点的nodeNum,一个是trail.
当命中一个内部节点的时候,trail会执行一次push,即一次左位移计算。
当未找到相交或者命中了叶节点是,trail会执行一次pop,即一次右位移计算。
整个遍历可以分为两个操作,一个是向下遍历,一个是向上回溯。
1) 向下遍历
向下遍历的时候算法会根据SLVBH构建时PrimCount保存的划分轴的符号判断是走左节点还是右节点,如果是正的则会在nodeNum追加0(左节点),如果是负的则会在nodeNum追加1(右节点),同时因为向下遍历相当于发生了相交,按照遍历逻辑左位移计算后trail追加了0.
另外一种等价的方式是简单的计算哪个节点的包围盒先被光线命中则优先访问哪个节点。
2)向上回溯
向上回溯的流程是这篇文章最重要的部分,在向上回溯的时候。
先将trail = trail + 1
统计trail中从LSB (least significant bit,最低有效位) 开始连续出现的0的个数,记录为n
n就是向上回溯的层数,然后:
trail = trail >> n (pop)
nodeNum = nodeNum >> n
反转 nodeNum 的 LSB (用于标记访问兄弟分支)
要理解这个算法的思想最重要的是理解二进制运算与节点访问标记如何契合的,这里尝试解释一下。
假如有个一轨迹为010,则说明当前在访问子树还有一个节点还没,trail + 1 后trail 变为 011,此时表明子树都已经被访问过了,此时trail 再 +1 ,因为二进制进位计算,trail 变为 100,按照计算流程这两个0就是回溯层数。
最后,如果遍历完所有节点且没有新的相交时,nodeNum则会重新变为1,则代表遍历结束。
例子:
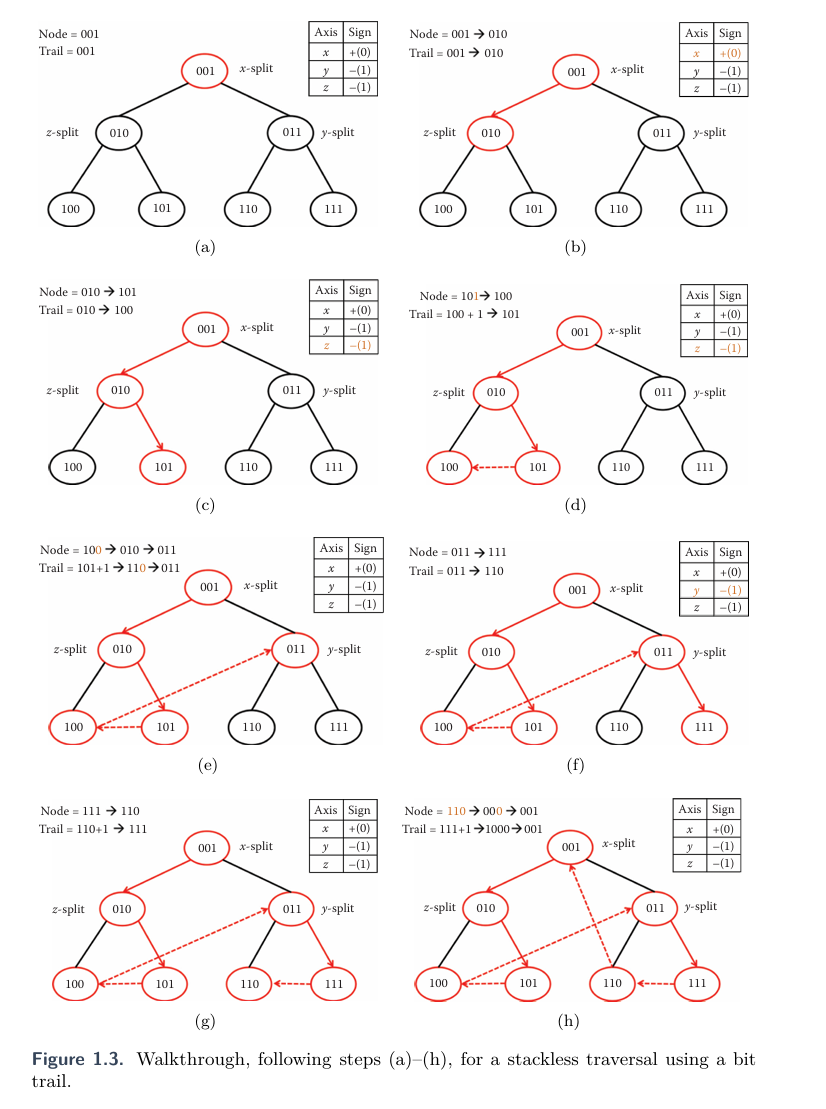
在(a)~(c) 的过程中,是一个向下遍历的过程,Trail 始终追加0,并且nodeNum根据右上角的Axis - Sign 判断先往左节点还是右节点遍历,并追加0或1,在例子中则遍历到了101 节点,Trail 也变为了100。
在(c)~ (d)的过程中执行了向上回溯,Trail在+1 后,从LSB开始连续的0个数为0个,所以nodeNum不需要pop出最后位置,然后翻转nodeNum的LSB,也就从101 -> 100 ,在(d)里也就是去到了左节点。
在(d)~(e)的过程中同样执行了向上回溯,Trail在+1后,101 + 1 二进制计算到110 ,此时从LSB开始连续的0个数为1个,nodeNum弹出一位,100 -> 010 ,弹出一位则是回到了上一层,然后翻转nodeNum的LSB 从010 -> 011,去到另一个子节点。
在(e)~ (f)的过程与(a)~(c)类似。
在(f)~(g)的过程与(c)~ (d)类似。
在(g)~(h)的过程中,执行了向上回溯,Trail在+1后计算得到1000, ,此时从LSB开始连续的0个数为3个,nodeNum 从110 -> 000 ,在翻转最后一位,得到001,nodeNum= 1 ,此次未命中图元的遍历就结束了。
参考代码:

内存使用:
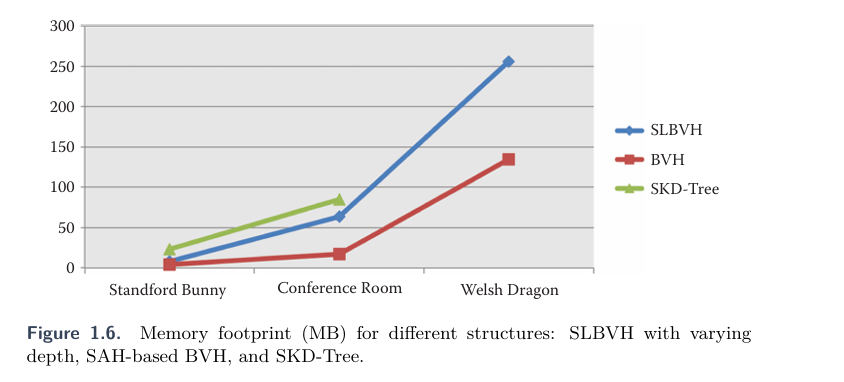
文章表示SLBVH的内存开销远低于SKD-Tree算法,但是比常规的BVH要大,可以看出该算法是用一部分空间换时间。
这大概率是因为该算法存储的空节点导致的,与常见的结构不同,SLBVH会存储空节点保证在没有堆栈的情况下去实现遍历,而且基于Morton Code的中位分割方案对于包围盒划分来说并不是最优,该划分算法对于非均匀图元分布的处理会导致许多图元最终共享同一个叶节点,这样树结构会不平衡。
光线能够快速遍历包围盒,但最最终是要与包围盒里的图元进行相交检测的,如果包围盒里的图元数量太多,那遍历包围盒省下来的时间反而微不足道
参考资料:

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)